 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
QNet: A Quantum-native Sequence Encoder Architecture
Oct 31, 2022
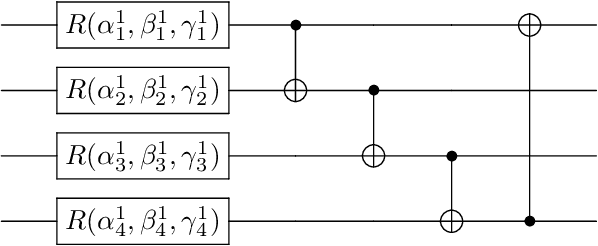
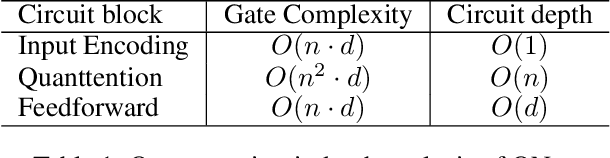
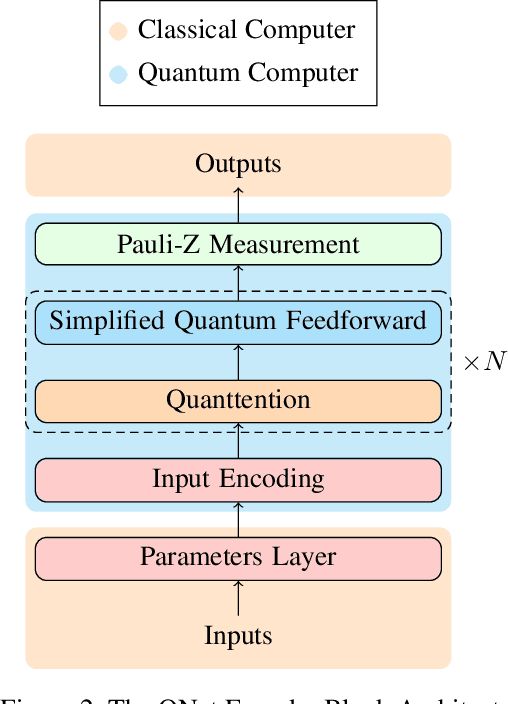
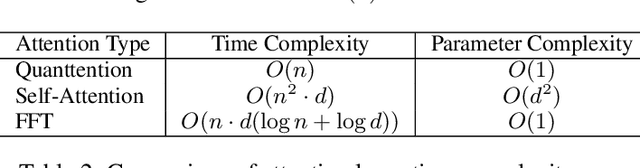
This work investigates how current quantum computers can improve the performance of natural language processing tasks. To achieve this goal, we proposed QNet, a novel sequence encoder model entirely inferences on the quantum computer using a minimum number of qubits. QNet is inspired by Transformer, the state-of-the-art neural network model based on the attention mechanism to relate the tokens. While the attention mechanism requires time complexity of $O(n^2 \cdot d)$ to perform matrix multiplication operations, QNet has merely $O(n+d)$ quantum circuit depth, where $n$ and $d$ represent the length of the sequence and the embedding size, respectively. To employ QNet on the NISQ devices, ResQNet, a quantum-classical hybrid model composed of several QNet blocks linked by residual connections, is introduced. We evaluate ResQNet on various natural language processing tasks, including text classification, rating score prediction, and named entity recognition. ResQNet exhibits a 6% to 818% performance gain on all these tasks over classical state-of-the-art models using the exact embedding dimensions. In summary, this work demonstrates the advantage of quantum computing in natural language processing tasks.
AutoBag: Learning to Open Plastic Bags and Insert Objects
Oct 31, 2022


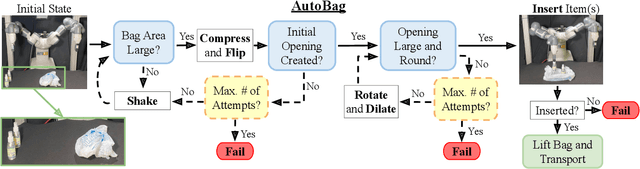
Thin plastic bags are ubiquitous in retail stores, healthcare, food handling, recycling, homes, and school lunchrooms. They are challenging both for perception (due to specularities and occlusions) and for manipulation (due to the dynamics of their 3D deformable structure). We formulate the task of manipulating common plastic shopping bags with two handles from an unstructured initial state to a state where solid objects can be inserted into the bag for transport. We propose a self-supervised learning framework where a dual-arm robot learns to recognize the handles and rim of plastic bags using UV-fluorescent markings; at execution time, the robot does not use UV markings or UV light. We propose Autonomous Bagging (AutoBag), where the robot uses the learned perception model to open plastic bags through iterative manipulation. We present novel metrics to evaluate the quality of a bag state and new motion primitives for reorienting and opening bags from visual observations. In physical experiments, a YuMi robot using AutoBag is able to open bags and achieve a success rate of 16/30 for inserting at least one item across a variety of initial bag configurations. Supplementary material is available at https://sites.google.com/view/autobag .
Learning Modular Robot Locomotion from Demonstrations
Oct 31, 2022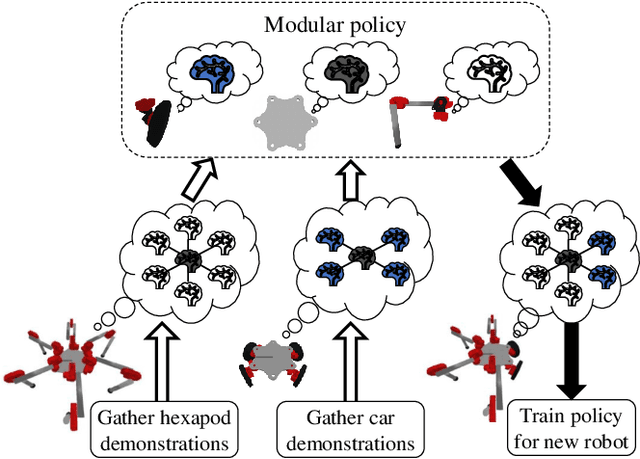
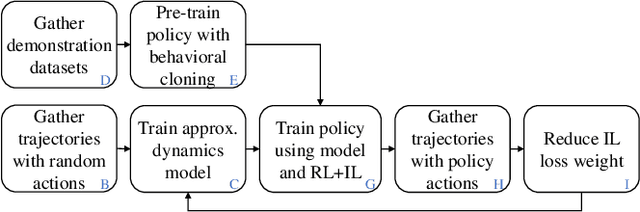
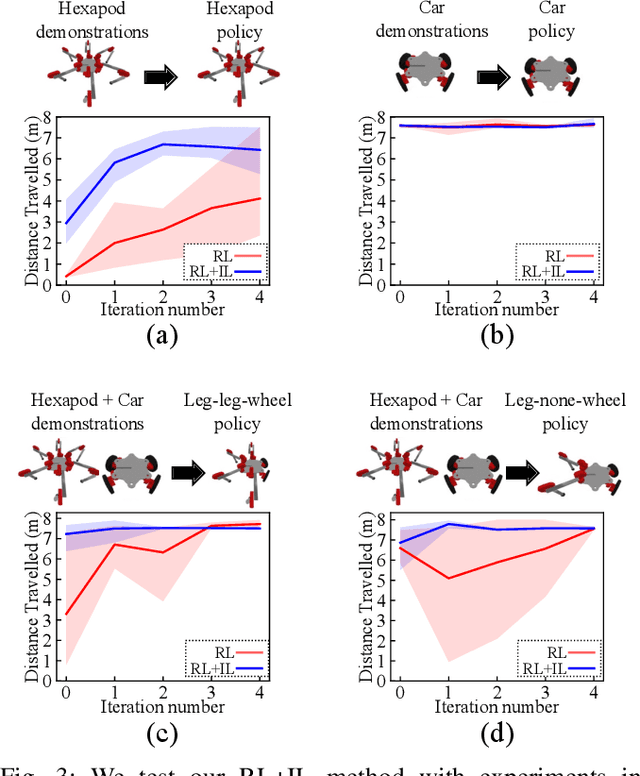
Modular robots can be reconfigured to create a variety of designs from a small set of components. But constructing a robot's hardware on its own is not enough -- each robot needs a controller. One could create controllers for some designs individually, but developing policies for additional designs can be time consuming. This work presents a method that uses demonstrations from one set of designs to accelerate policy learning for additional designs. We leverage a learning framework in which a graph neural network is made up of modular components, each component corresponds to a type of module (e.g., a leg, wheel, or body) and these components can be recombined to learn from multiple designs at once. In this paper we develop a combined reinforcement and imitation learning algorithm. Our method is novel because the policy is optimized to both maximize a reward for one design, and simultaneously imitate demonstrations from different designs, within one objective function. We show that when the modular policy is optimized with this combined objective, demonstrations from one set of designs influence how the policy behaves on a different design, decreasing the number of training iterations needed.
Average-Case Complexity of Tensor Decomposition for Low-Degree Polynomials
Nov 10, 2022Suppose we are given an $n$-dimensional order-3 symmetric tensor $T \in (\mathbb{R}^n)^{\otimes 3}$ that is the sum of $r$ random rank-1 terms. The problem of recovering the rank-1 components is possible in principle when $r \lesssim n^2$ but polynomial-time algorithms are only known in the regime $r \ll n^{3/2}$. Similar "statistical-computational gaps" occur in many high-dimensional inference tasks, and in recent years there has been a flurry of work on explaining the apparent computational hardness in these problems by proving lower bounds against restricted (yet powerful) models of computation such as statistical queries (SQ), sum-of-squares (SoS), and low-degree polynomials (LDP). However, no such prior work exists for tensor decomposition, largely because its hardness does not appear to be explained by a "planted versus null" testing problem. We consider a model for random order-3 tensor decomposition where one component is slightly larger in norm than the rest (to break symmetry), and the components are drawn uniformly from the hypercube. We resolve the computational complexity in the LDP model: $O(\log n)$-degree polynomial functions of the tensor entries can accurately estimate the largest component when $r \ll n^{3/2}$ but fail to do so when $r \gg n^{3/2}$. This provides rigorous evidence suggesting that the best known algorithms for tensor decomposition cannot be improved, at least by known approaches. A natural extension of the result holds for tensors of any fixed order $k \ge 3$, in which case the LDP threshold is $r \sim n^{k/2}$.
TridentSE: Guiding Speech Enhancement with 32 Global Tokens
Oct 24, 2022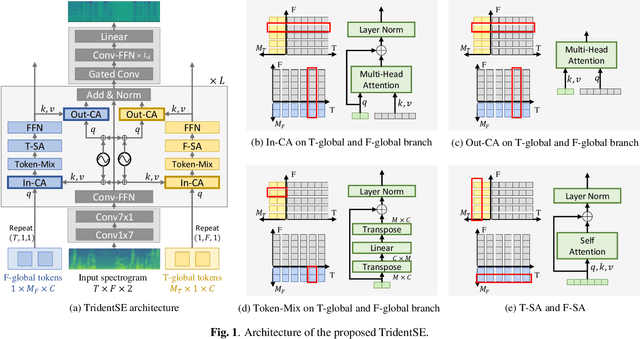
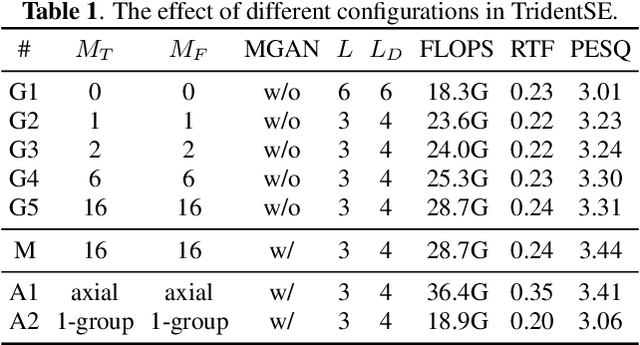
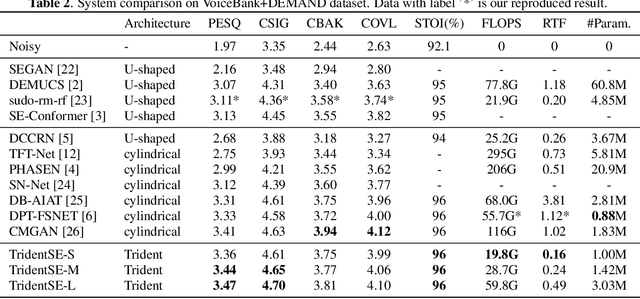
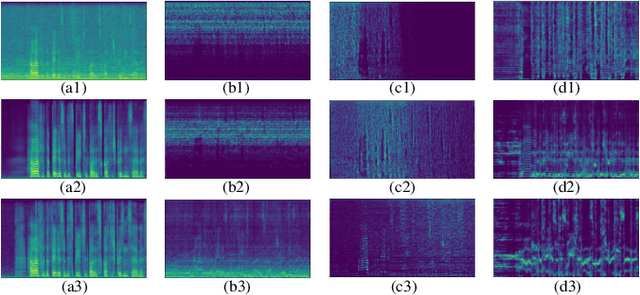
In this paper, we present TridentSE, a novel architecture for speech enhancement, which is capable of efficiently capturing both global information and local details. TridentSE maintains T-F bin level representation to capture details, and uses a small number of global tokens to process the global information. Information is propagated between the local and the global representations through cross attention modules. To capture both inter- and intra-frame information, the global tokens are divided into two groups to process along the time and the frequency axis respectively. A metric discriminator is further employed to guide our model to achieve higher perceptual quality. Even with significantly lower computational cost, TridentSE outperforms a variety of previous speech enhancement methods, achieving a PESQ of 3.47 on VoiceBank+DEMAND dataset and a PESQ of 3.44 on DNS no-reverb test set. Visualization shows that the global tokens learn diverse and interpretable global patterns.
Relaxing the Feature Covariance Assumption: Time-Variant Bounds for Benign Overfitting in Linear Regression
Feb 12, 2022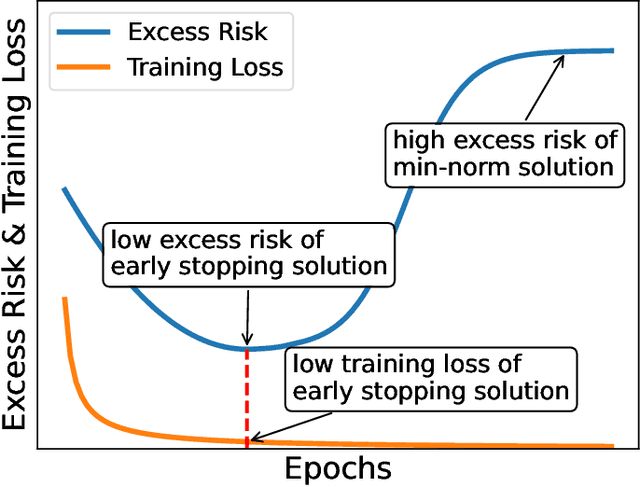
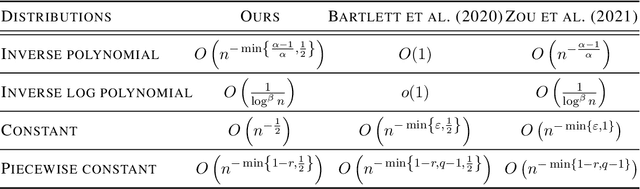
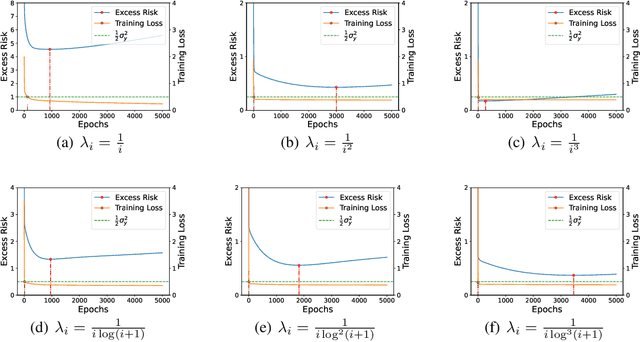
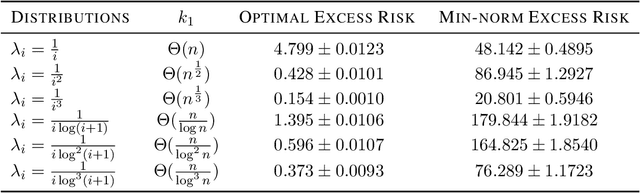
Benign overfitting demonstrates that overparameterized models can perform well on test data while fitting noisy training data. However, it only considers the final min-norm solution in linear regression, which ignores the algorithm information and the corresponding training procedure. In this paper, we generalize the idea of benign overfitting to the whole training trajectory instead of the min-norm solution and derive a time-variant bound based on the trajectory analysis. Starting from the time-variant bound, we further derive a time interval that suffices to guarantee a consistent generalization error for a given feature covariance. Unlike existing approaches, the newly proposed generalization bound is characterized by a time-variant effective dimension of feature covariance. By introducing the time factor, we relax the strict assumption on the feature covariance matrix required in previous benign overfitting under the regimes of overparameterized linear regression with gradient descent. This paper extends the scope of benign overfitting, and experiment results indicate that the proposed bound accords better with empirical evidence.
Changepoint Detection for Real-Time Spectrum Sharing Radar
Jun 30, 2022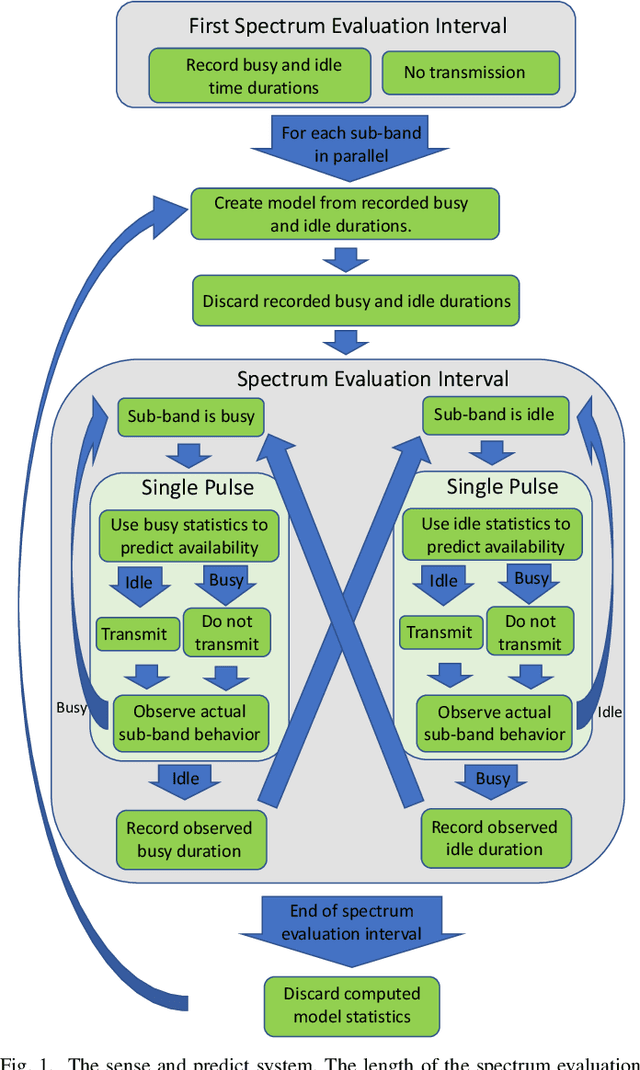
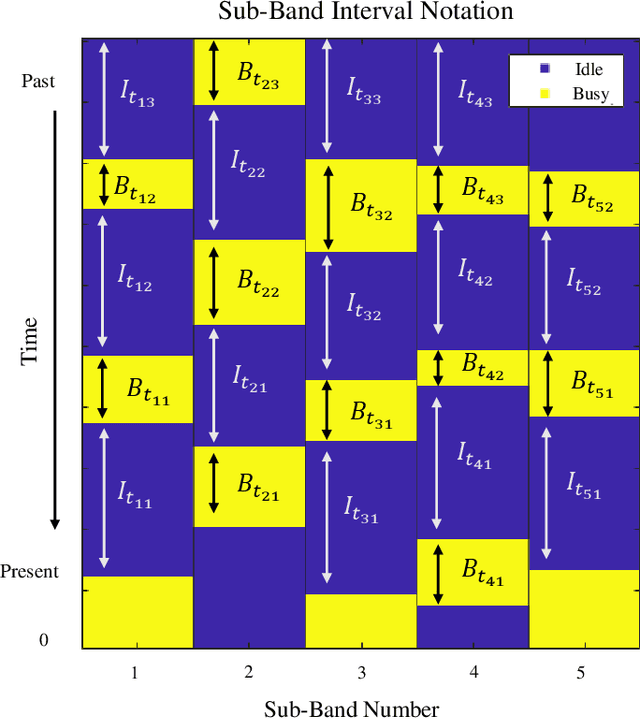
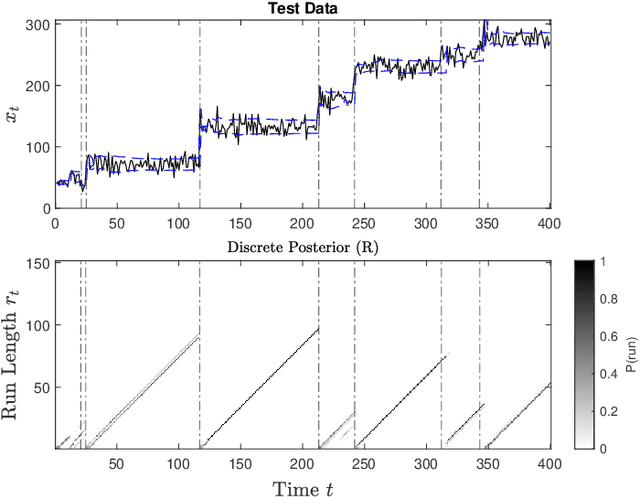
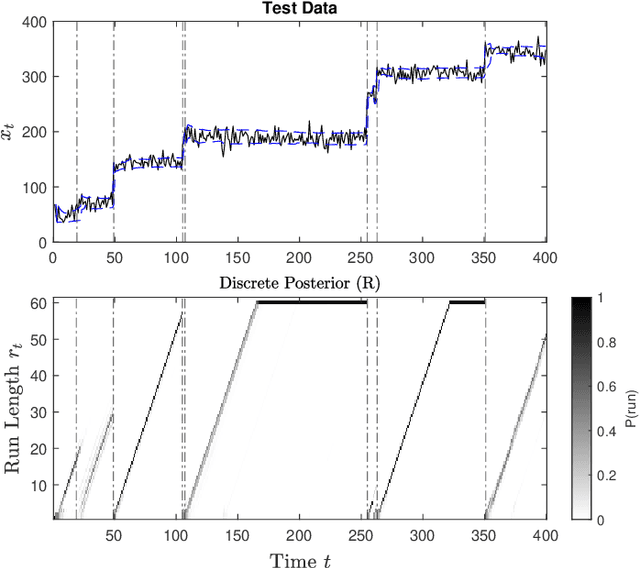
Radar must adapt to changing environments, and we propose changepoint detection as a method to do so. In the world of increasingly congested radio frequencies, radars must adapt to avoid interference. Many radar systems employ the prediction action cycle to proactively determine transmission mode while spectrum sharing. This method constructs and implements a model of the environment to predict unused frequencies, and then transmits in this predicted availability. For these selection strategies, performance is directly reliant on the quality of the underlying environmental models. In order to keep up with a changing environment, these models can employ changepoint detection. Changepoint detection is the identification of sudden changes, or changepoints, in the distribution from which data is drawn. This information allows the models to discard "garbage" data from a previous distribution, which has no relation to the current state of the environment. In this work, bayesian online changepoint detection (BOCD) is applied to the sense and predict algorithm to increase the accuracy of its models and improve its performance. In the context of spectrum sharing, these changepoints represent interferers leaving and entering the spectral environment. The addition of changepoint detection allows for dynamic and robust spectrum sharing even as interference patterns change dramatically. BOCD is especially advantageous because it enables online changepoint detection, allowing models to be updated continuously as data are collected. This strategy can also be applied to many other predictive algorithms that create models in a changing environment.
Integrated Sensing and Communications with Reconfigurable Intelligent Surfaces
Nov 02, 2022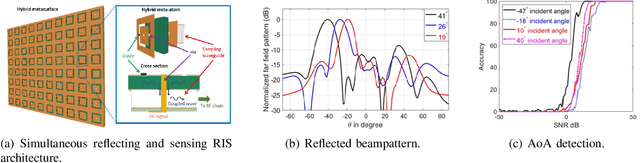
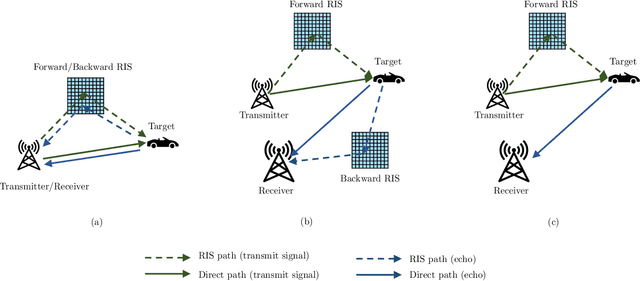
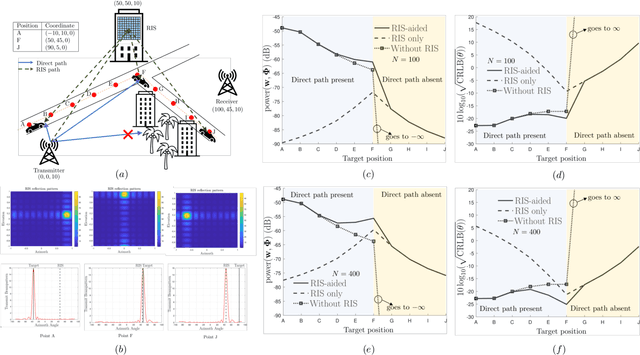
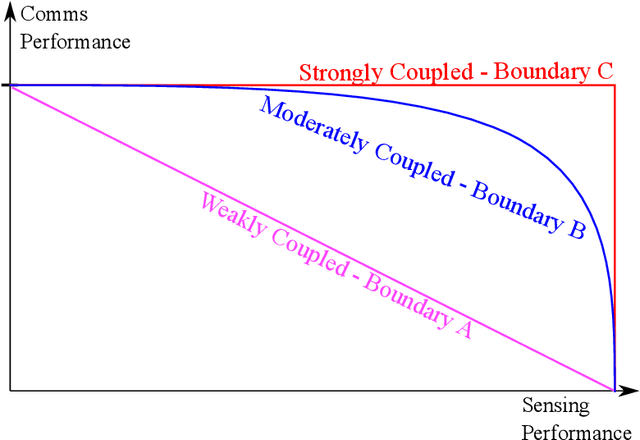
Integrated sensing and communications (ISAC) are envisioned to be an integral part of future wireless networks, especially when operating at the millimeter-wave (mmWave) and terahertz (THz) frequency bands. However, establishing wireless connections at these high frequencies is quite challenging, mainly due to the penetrating pathloss that prevents reliable communication and sensing. Another emerging technology for next-generation wireless systems is reconfigurable intelligent surfaces (RISs), which are capable of modifying harsh propagation environments. RISs are the focus of growing research and industrial attention, bringing forth the vision of smart and programmable signal propagation environments. In this article, we provide a tutorial-style overview of the applications and benefits of RISs for sensing functionalities in general, and for ISAC systems in particular. We highlight the potential advantages when fusing these two emerging technologies, and identify for the first time that: i) joint sensing and communications designs are most beneficial when the channels referring to these operations are coupled, and that ii) RISs offer means for controlling this beneficial coupling. The usefulness of RIS-aided ISAC goes beyond the individual obvious gains of each of these technologies in both performance and power efficiency. We also discuss the main signal processing challenges and future research directions which arise from the fusion of these two emerging technologies.
Distributed Massive MIMO for LEO Satellite Networks
Nov 02, 2022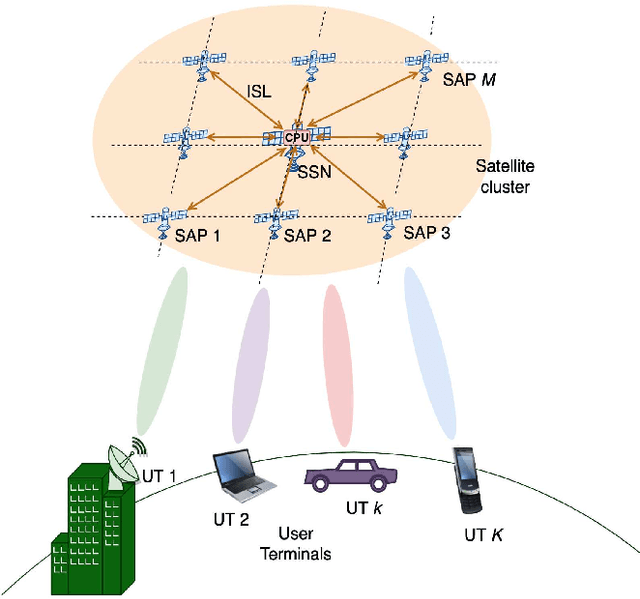
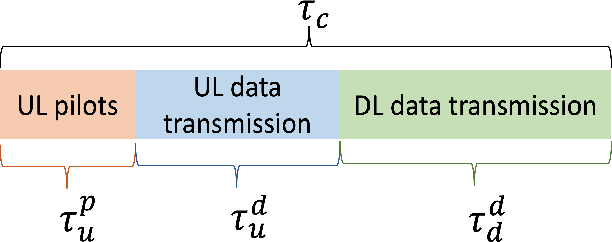
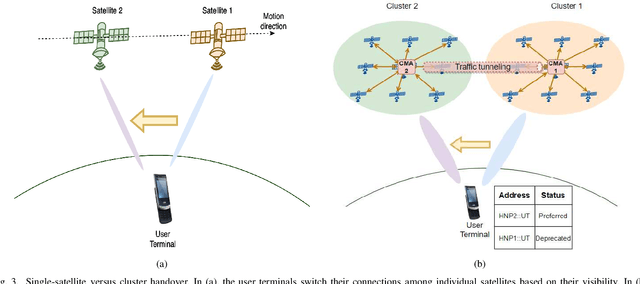
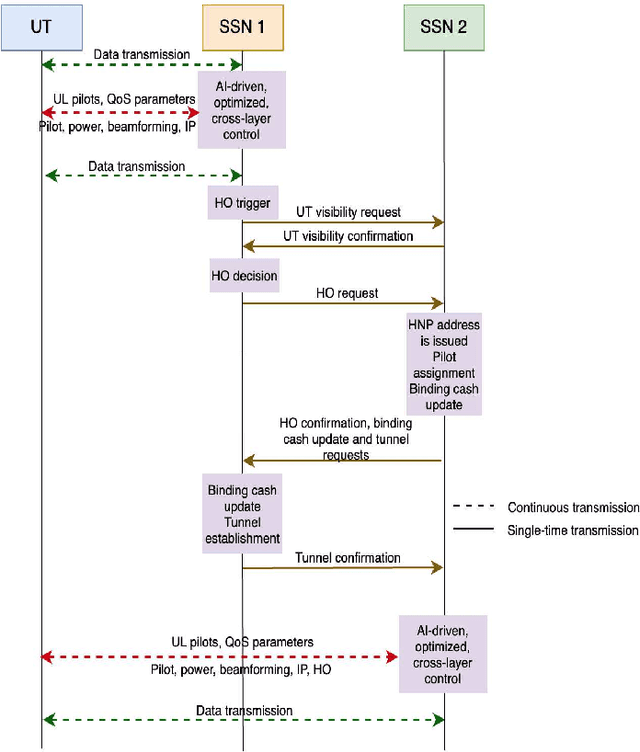
The ultra-dense deployment of interconnected satellites will characterize future low Earth orbit (LEO) mega-constellations. Exploiting this towards a more efficient satellite network (SatNet), this paper proposes a novel LEO SatNet architecture based on distributed massive multiple-input multiple-output (DM-MIMO) technology allowing ground user terminals to be connected to a cluster of satellites. To this end, we investigate various aspects of DM-MIMO-based satellite network design, the benefits of using this architecture, the associated challenges, and the potential solutions. In addition, we propose a distributed joint power allocation and handover management (D-JPAHM) technique that jointly optimizes the power allocation and handover management processes in a cross-layer manner. This framework aims to maximize the network throughput and minimize the handover rate while considering the quality-of-service (QoS) demands of user terminals and the power capabilities of the satellites. Moreover, we devise an artificial intelligence (AI)-based solution to efficiently implement the proposed D-JPAHM framework in a manner suitable for real-time operation and the dynamic SatNet environment. To the best of our knowledge, this is the first work to introduce and study DM-MIMO technology in LEO SatNets. Extensive simulation results reveal the superiority of the proposed architecture and solutions compared to conventional approaches in the literature.
Deep Reinforcement Learning for Power Control in Next-Generation WiFi Network Systems
Nov 02, 2022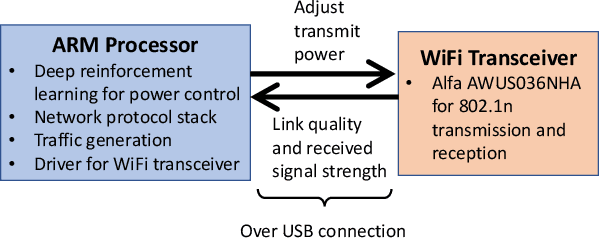
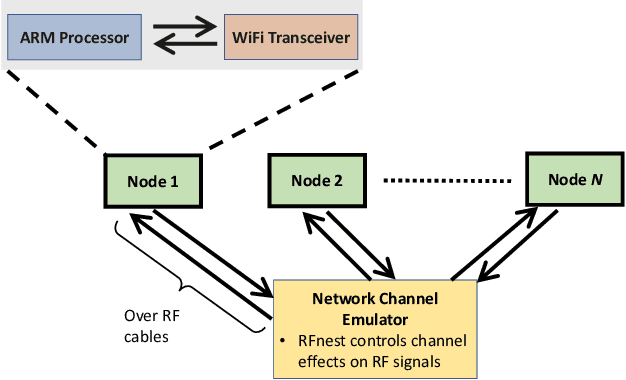
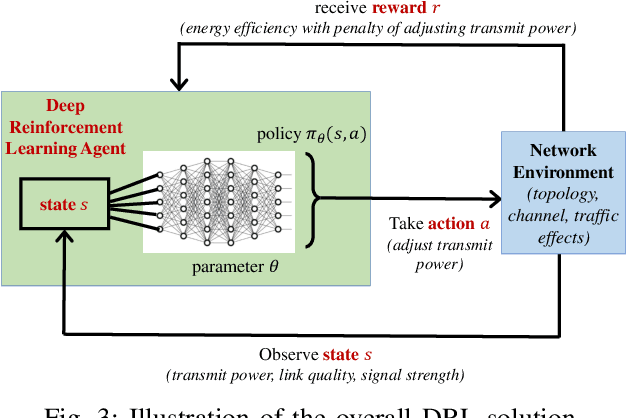
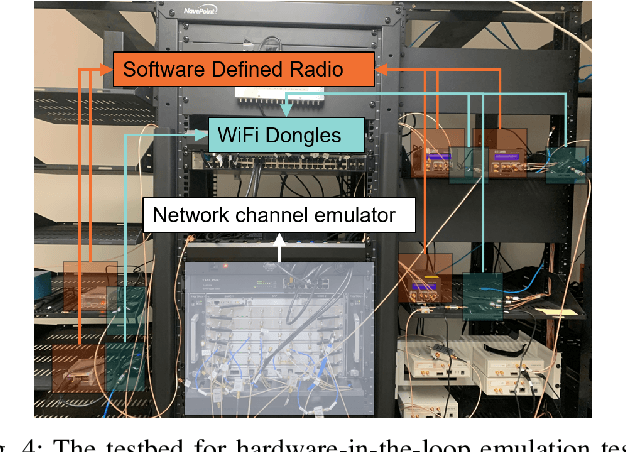
This paper presents a deep reinforcement learning (DRL) solution for power control in wireless communications, describes its embedded implementation with WiFi transceivers for a WiFi network system, and evaluates the performance with high-fidelity emulation tests. In a multi-hop wireless network, each mobile node measures its link quality and signal strength, and controls its transmit power. As a model-free solution, reinforcement learning allows nodes to adapt their actions by observing the states and maximize their cumulative rewards over time. For each node, the state consists of transmit power, link quality and signal strength; the action adjusts the transmit power; and the reward combines energy efficiency (throughput normalized by energy consumption) and penalty of changing the transmit power. As the state space is large, Q-learning is hard to implement on embedded platforms with limited memory and processing power. By approximating the Q-values with a DQN, DRL is implemented for the embedded platform of each node combining an ARM processor and a WiFi transceiver for 802.11n. Controllable and repeatable emulation tests are performed by inducing realistic channel effects on RF signals. Performance comparison with benchmark schemes of fixed and myopic power allocations shows that power control with DRL provides major improvements to energy efficiency and throughput in WiFi network systems.
* 5 pages, 6 figures, 1 table