 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Offline Policy Optimization with a Learned Model
Oct 12, 2022
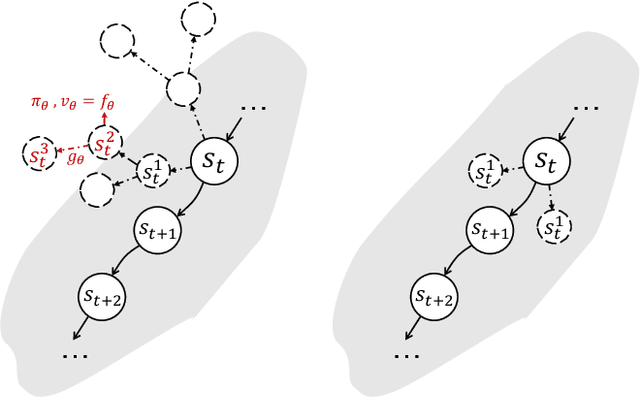
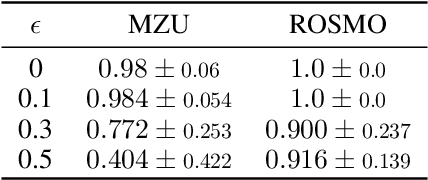
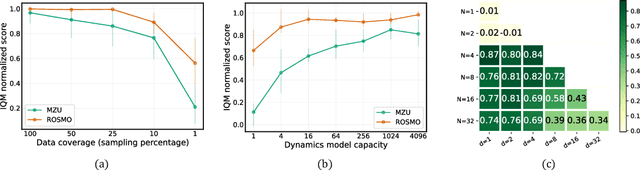
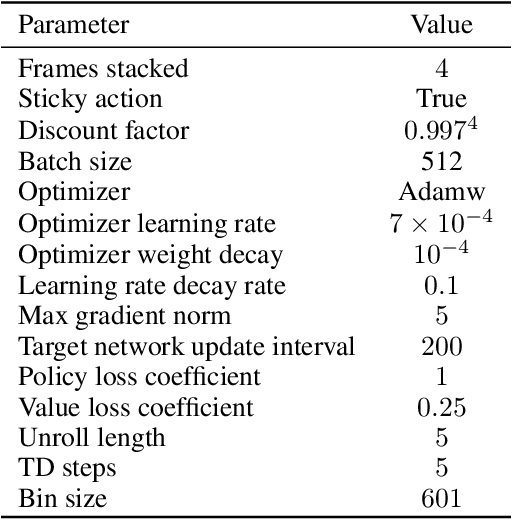
MuZero Unplugged presents a promising approach for offline policy learning from logged data. It conducts Monte-Carlo Tree Search (MCTS) with a learned model and leverages Reanalyze algorithm to learn purely from offline data. For good performance, MCTS requires accurate learned models and a large number of simulations, thus costing huge computing time. This paper investigates a few hypotheses where MuZero Unplugged may not work well under the offline RL settings, including 1) learning with limited data coverage; 2) learning from offline data of stochastic environments; 3) improperly parameterized models given the offline data; 4) with a low compute budget. We propose to use a regularized one-step look-ahead approach to tackle the above issues. Instead of planning with the expensive MCTS, we use the learned model to construct an advantage estimation based on a one-step rollout. Policy improvements are towards the direction that maximizes the estimated advantage with regularization of the dataset. We conduct extensive empirical studies with BSuite environments to verify the hypotheses and then run our algorithm on the RL Unplugged Atari benchmark. Experimental results show that our proposed approach achieves stable performance even with an inaccurate learned model. On the large-scale Atari benchmark, the proposed method outperforms MuZero Unplugged by 43%. Most significantly, it uses only 5.6% wall-clock time (i.e., 1 hour) compared to MuZero Unplugged (i.e., 17.8 hours) to achieve a 150% IQM normalized score with the same hardware and software stacks.
Auxo: Heterogeneity-Mitigating Federated Learning via Scalable Client Clustering
Oct 29, 2022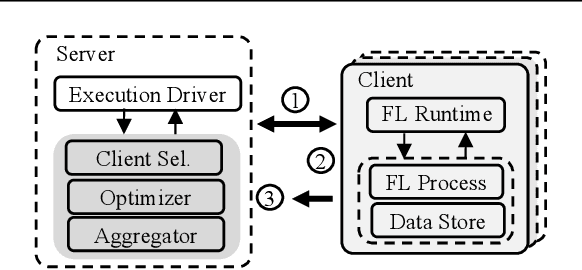
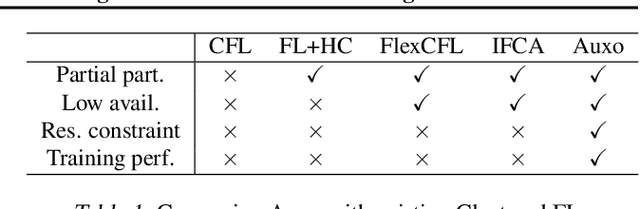
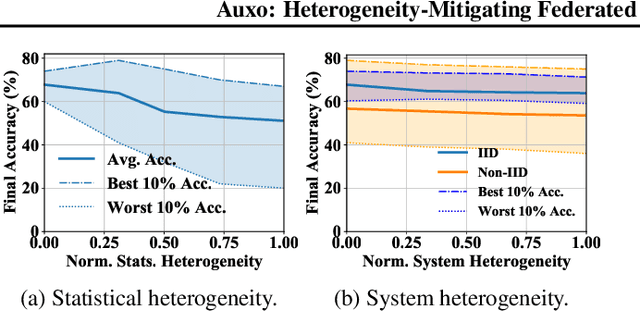
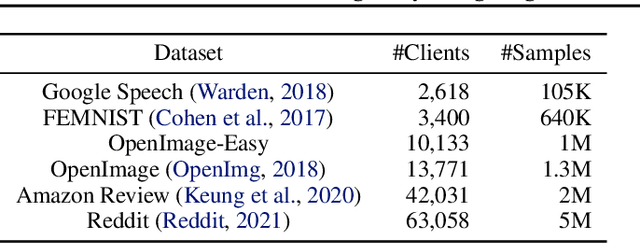
Federated learning (FL) is an emerging machine learning (ML) paradigm that enables heterogeneous edge devices to collaboratively train ML models without revealing their raw data to a logically centralized server. Heterogeneity across participants is a fundamental challenge in FL, both in terms of non-independent and identically distributed (Non-IID) data distributions and variations in device capabilities. Many existing works present point solutions to address issues like slow convergence, low final accuracy, and bias in FL, all stemming from the client heterogeneity. We observe that, in a large population, there exist groups of clients with statistically similar data distributions (cohorts). In this paper, we propose Auxo to gradually identify cohorts among large-scale, low-participation, and resource-constrained FL populations. Auxo then adaptively determines how to train cohort-specific models in order to achieve better model performance and ensure resource efficiency. By identifying cohorts with smaller heterogeneity and performing efficient cohort-based training, our extensive evaluations show that Auxo substantially boosts the state-of-the-art solutions in terms of final accuracy, convergence time, and model bias.
Mutual Information Alleviates Hallucinations in Abstractive Summarization
Oct 29, 2022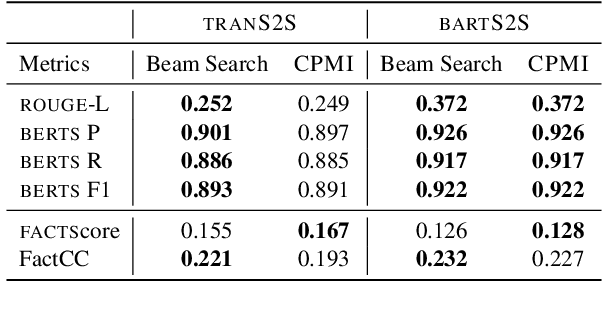

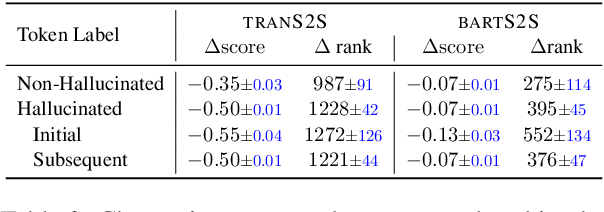
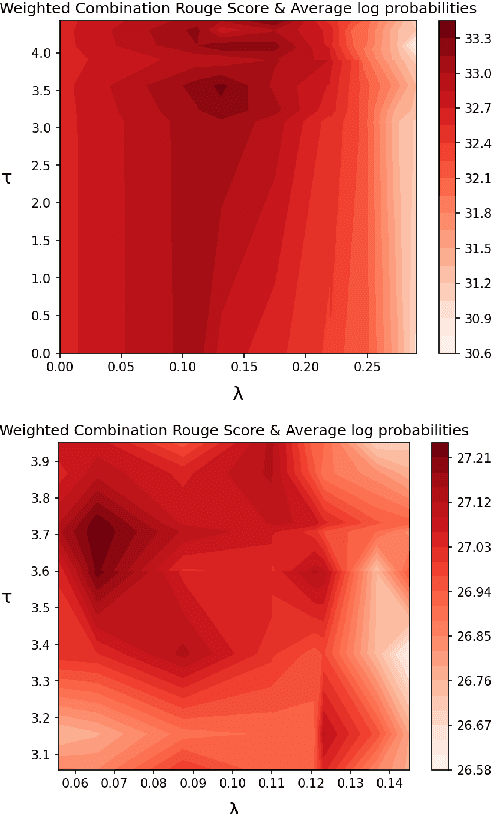
Despite significant progress in the quality of language generated from abstractive summarization models, these models still exhibit the tendency to hallucinate, i.e., output content not supported by the source document. A number of works have tried to fix--or at least uncover the source of--the problem with limited success. In this paper, we identify a simple criterion under which models are significantly more likely to assign more probability to hallucinated content during generation: high model uncertainty. This finding offers a potential explanation for hallucinations: models default to favoring text with high marginal probability, i.e., high-frequency occurrences in the training set, when uncertain about a continuation. It also motivates possible routes for real-time intervention during decoding to prevent such hallucinations. We propose a decoding strategy that switches to optimizing for pointwise mutual information of the source and target token--rather than purely the probability of the target token--when the model exhibits uncertainty. Experiments on the XSum dataset show that our method decreases the probability of hallucinated tokens while maintaining the Rouge and BertS scores of top-performing decoding strategies.
Causal Discovery of Dynamic Models for Predicting Human Spatial Interactions
Oct 29, 2022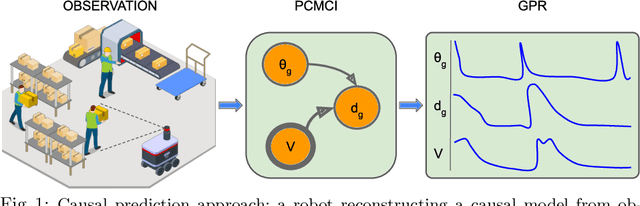
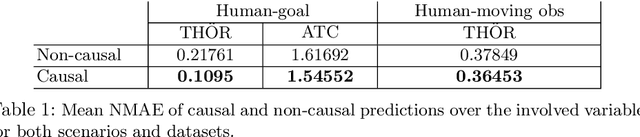
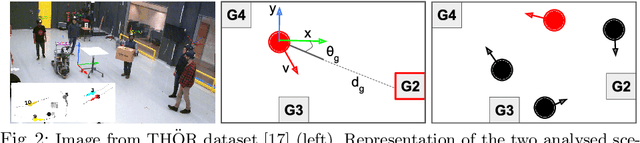
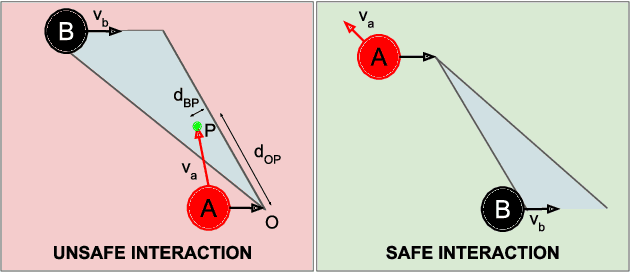
Exploiting robots for activities in human-shared environments, whether warehouses, shopping centres or hospitals, calls for such robots to understand the underlying physical interactions between nearby agents and objects. In particular, modelling cause-and-effect relations between the latter can help to predict unobserved human behaviours and anticipate the outcome of specific robot interventions. In this paper, we propose an application of causal discovery methods to model human-robot spatial interactions, trying to understand human behaviours from real-world sensor data in two possible scenarios: humans interacting with the environment, and humans interacting with obstacles. New methods and practical solutions are discussed to exploit, for the first time, a state-of-the-art causal discovery algorithm in some challenging human environments, with potential application in many service robotics scenarios. To demonstrate the utility of the causal models obtained from real-world datasets, we present a comparison between causal and non-causal prediction approaches. Our results show that the causal model correctly captures the underlying interactions of the considered scenarios and improves its prediction accuracy.
Single-Shot Domain Adaptation via Target-Aware Generative Augmentation
Oct 29, 2022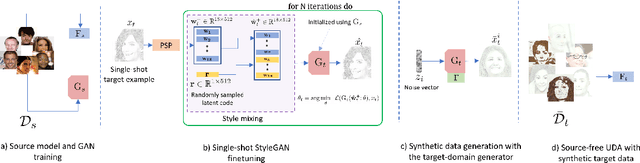
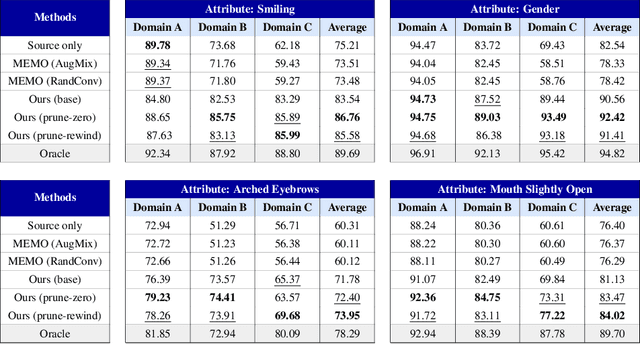


The problem of adapting models from a source domain using data from any target domain of interest has gained prominence, thanks to the brittle generalization in deep neural networks. While several test-time adaptation techniques have emerged, they typically rely on synthetic data augmentations in cases of limited target data availability. In this paper, we consider the challenging setting of single-shot adaptation and explore the design of augmentation strategies. We argue that augmentations utilized by existing methods are insufficient to handle large distribution shifts, and hence propose a new approach SiSTA (Single-Shot Target Augmentations), which first fine-tunes a generative model from the source domain using a single-shot target, and then employs novel sampling strategies for curating synthetic target data. Using experiments with a state-of-the-art domain adaptation method, we find that SiSTA produces improvements as high as 20\% over existing baselines under challenging shifts in face attribute detection, and that it performs competitively to oracle models obtained by training on a larger target dataset.
A Hybrid Continuity Loss to Reduce Over-Suppression for Time-domain Target Speaker Extraction
Mar 31, 2022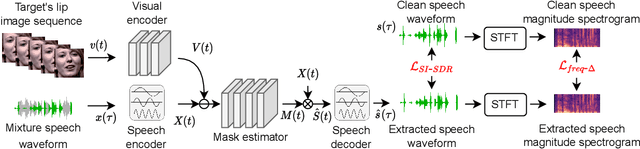
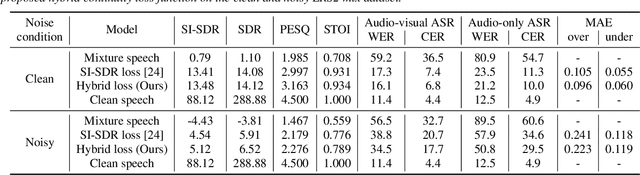
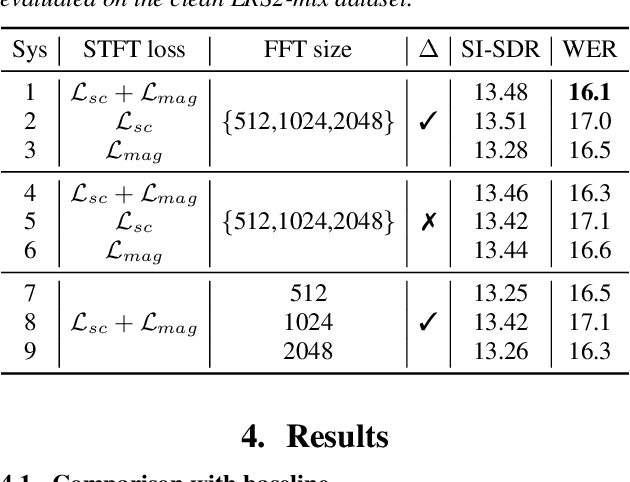
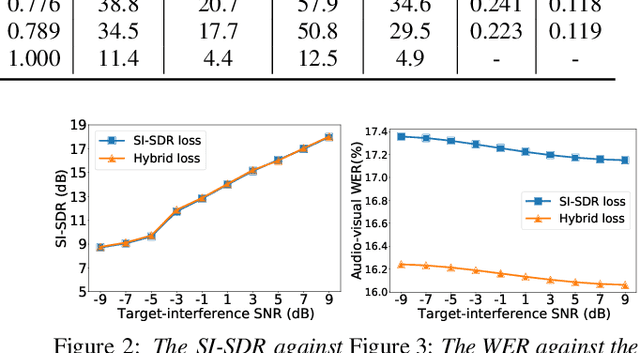
Speaker extraction algorithm extracts the target speech from a mixture speech containing interference speech and background noise. The extraction process sometimes over-suppresses the extracted target speech, which not only creates artifacts during listening but also harms the performance of downstream automatic speech recognition algorithms. We propose a hybrid continuity loss function for time-domain speaker extraction algorithms to settle the over-suppression problem. On top of the waveform-level loss used for superior signal quality, i.e., SI-SDR, we introduce a multi-resolution delta spectrum loss in the frequency-domain, to ensure the continuity of an extracted speech signal, thus alleviating the over-suppression. We examine the hybrid continuity loss function using a time-domain audio-visual speaker extraction algorithm on the YouTube LRS2-BBC dataset. Experimental results show that the proposed loss function reduces the over-suppression and improves the word error rate of speech recognition on both clean and noisy two-speakers mixtures, without harming the reconstructed speech quality.
Dual-Domain Cross-Iteration Squeeze-Excitation Network for Sparse Reconstruction of Brain MRI
Oct 05, 2022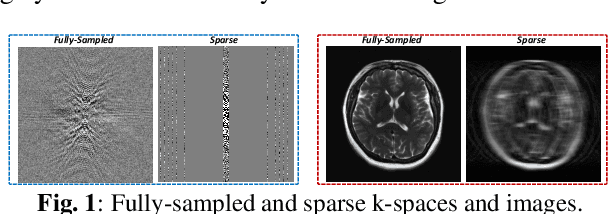
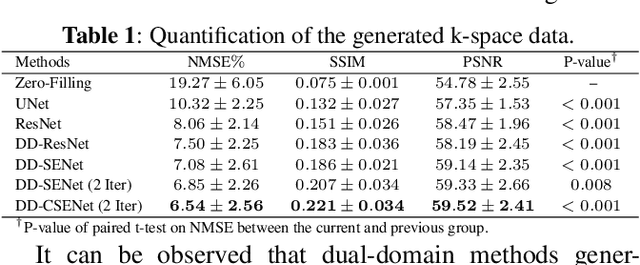
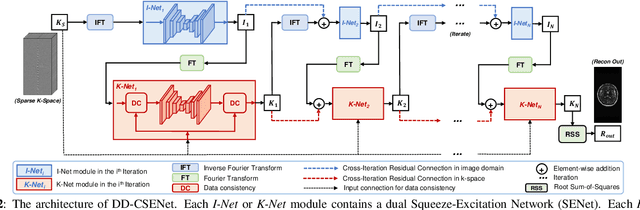
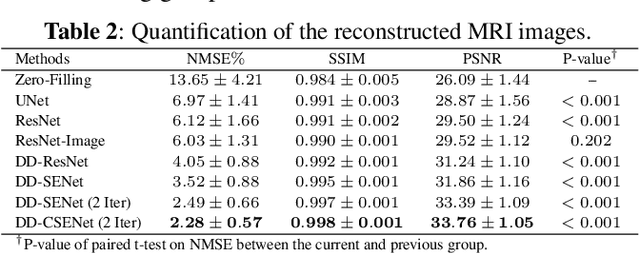
Magnetic resonance imaging (MRI) is one of the most commonly applied tests in neurology and neurosurgery. However, the utility of MRI is largely limited by its long acquisition time, which might induce many problems including patient discomfort and motion artifacts. Acquiring fewer k-space sampling is a potential solution to reducing the total scanning time. However, it can lead to severe aliasing reconstruction artifacts and thus affect the clinical diagnosis. Nowadays, deep learning has provided new insights into the sparse reconstruction of MRI. In this paper, we present a new approach to this problem that iteratively fuses the information of k-space and MRI images using novel dual Squeeze-Excitation Networks and Cross-Iteration Residual Connections. This study included 720 clinical multi-coil brain MRI cases adopted from the open-source deidentified fastMRI Dataset. 8-folder downsampling rate was applied to generate the sparse k-space. Results showed that the average reconstruction error over 120 testing cases by our proposed method was 2.28%, which outperformed the existing image-domain prediction (6.03%, p<0.001), k-space synthesis (6.12%, p<0.001), and dual-domain feature fusion (4.05%, p<0.001).
Token Classification for Disambiguating Medical Abbreviations
Oct 05, 2022
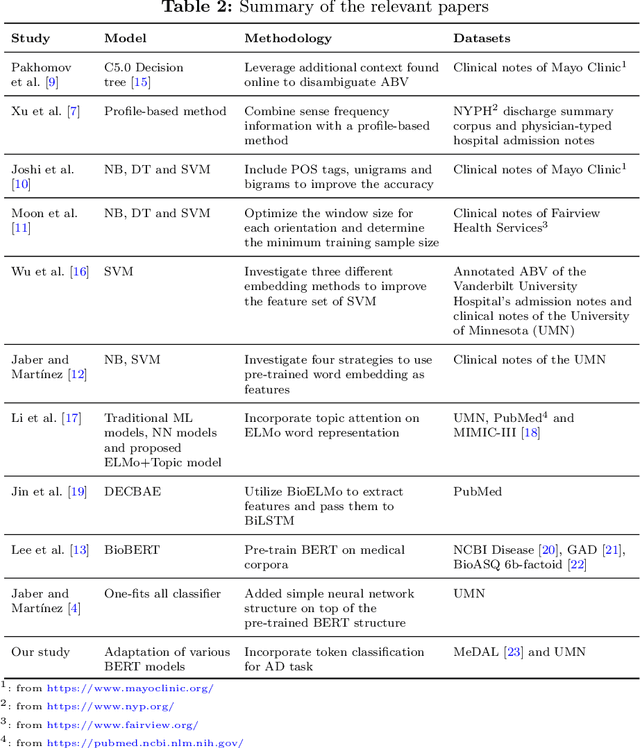
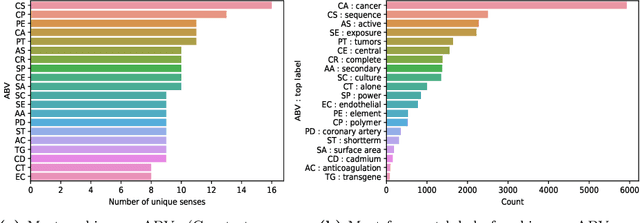
Abbreviations are unavoidable yet critical parts of the medical text. Using abbreviations, especially in clinical patient notes, can save time and space, protect sensitive information, and help avoid repetitions. However, most abbreviations might have multiple senses, and the lack of a standardized mapping system makes disambiguating abbreviations a difficult and time-consuming task. The main objective of this study is to examine the feasibility of token classification methods for medical abbreviation disambiguation. Specifically, we explore the capability of token classification methods to deal with multiple unique abbreviations in a single text. We use two public datasets to compare and contrast the performance of several transformer models pre-trained on different scientific and medical corpora. Our proposed token classification approach outperforms the more commonly used text classification models for the abbreviation disambiguation task. In particular, the SciBERT model shows a strong performance for both token and text classification tasks over the two considered datasets. Furthermore, we find that abbreviation disambiguation performance for the text classification models becomes comparable to that of token classification only when postprocessing is applied to their predictions, which involves filtering possible labels for an abbreviation based on the training data.
iSDF: Real-Time Neural Signed Distance Fields for Robot Perception
Apr 05, 2022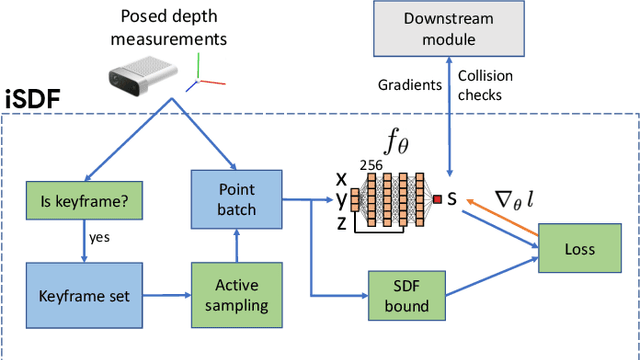
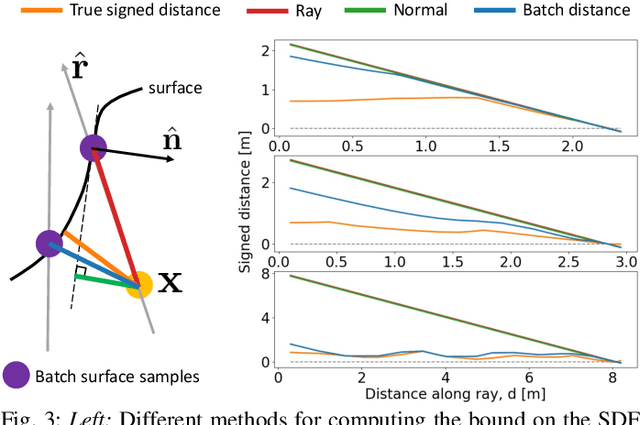
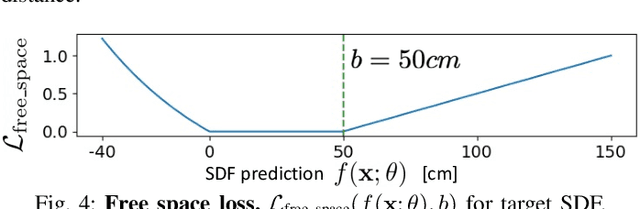
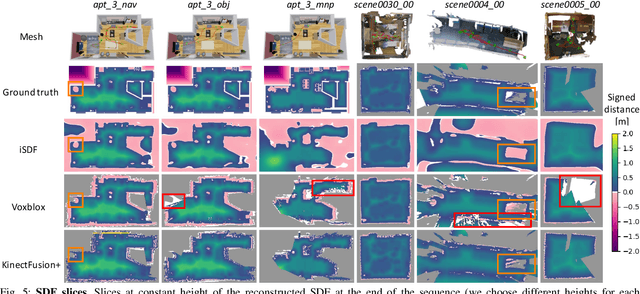
We present iSDF, a continual learning system for real-time signed distance field (SDF) reconstruction. Given a stream of posed depth images from a moving camera, it trains a randomly initialised neural network to map input 3D coordinate to approximate signed distance. The model is self-supervised by minimising a loss that bounds the predicted signed distance using the distance to the closest sampled point in a batch of query points that are actively sampled. In contrast to prior work based on voxel grids, our neural method is able to provide adaptive levels of detail with plausible filling in of partially observed regions and denoising of observations, all while having a more compact representation. In evaluations against alternative methods on real and synthetic datasets of indoor environments, we find that iSDF produces more accurate reconstructions, and better approximations of collision costs and gradients useful for downstream planners in domains from navigation to manipulation. Code and video results can be found at our project page: https://joeaortiz.github.io/iSDF/ .
STPOTR: Simultaneous Human Trajectory and Pose Prediction Using a Non-Autoregressive Transformer for Robot Following Ahead
Sep 20, 2022
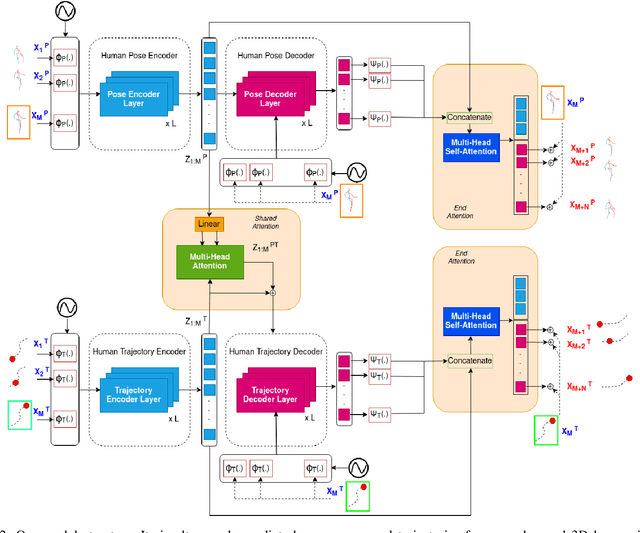


In this paper, we develop a neural network model to predict future human motion from an observed human motion history. We propose a non-autoregressive transformer architecture to leverage its parallel nature for easier training and fast, accurate predictions at test time. The proposed architecture divides human motion prediction into two parts: 1) the human trajectory, which is the hip joint 3D position over time and 2) the human pose which is the all other joints 3D positions over time with respect to a fixed hip joint. We propose to make the two predictions simultaneously, as the shared representation can improve the model performance. Therefore, the model consists of two sets of encoders and decoders. First, a multi-head attention module applied to encoder outputs improves human trajectory. Second, another multi-head self-attention module applied to encoder outputs concatenated with decoder outputs facilitates learning of temporal dependencies. Our model is well-suited for robotic applications in terms of test accuracy and speed, and compares favorably with respect to state-of-the-art methods. We demonstrate the real-world applicability of our work via the Robot Follow-Ahead task, a challenging yet practical case study for our proposed model.