 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
AcME-AD: Accelerated Model Explanations for Anomaly Detection
Mar 02, 2024
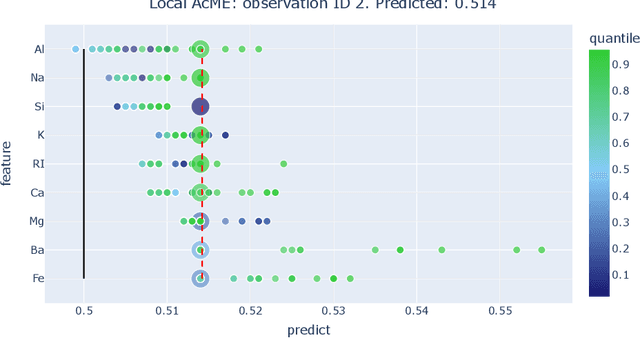

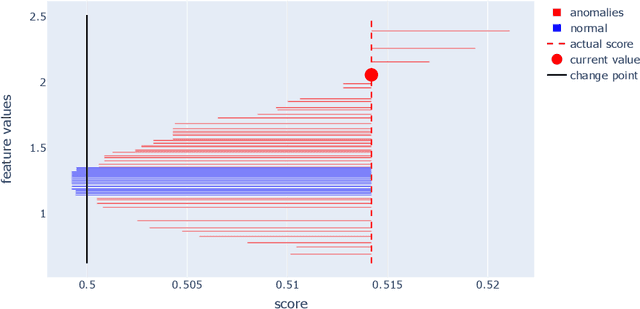

Pursuing fast and robust interpretability in Anomaly Detection is crucial, especially due to its significance in practical applications. Traditional Anomaly Detection methods excel in outlier identification but are often black-boxes, providing scant insights into their decision-making process. This lack of transparency compromises their reliability and hampers their adoption in scenarios where comprehending the reasons behind anomaly detection is vital. At the same time, getting explanations quickly is paramount in practical scenarios. To bridge this gap, we present AcME-AD, a novel approach rooted in Explainable Artificial Intelligence principles, designed to clarify Anomaly Detection models for tabular data. AcME-AD transcends the constraints of model-specific or resource-heavy explainability techniques by delivering a model-agnostic, efficient solution for interoperability. It offers local feature importance scores and a what-if analysis tool, shedding light on the factors contributing to each anomaly, thus aiding root cause analysis and decision-making. This paper elucidates AcME-AD's foundation, its benefits over existing methods, and validates its effectiveness with tests on both synthetic and real datasets. AcME-AD's implementation and experiment replication code is accessible in a public repository.
Multi-Source Interactive Resilient Fusion Algorithm Based on RIEKF
Mar 02, 2024
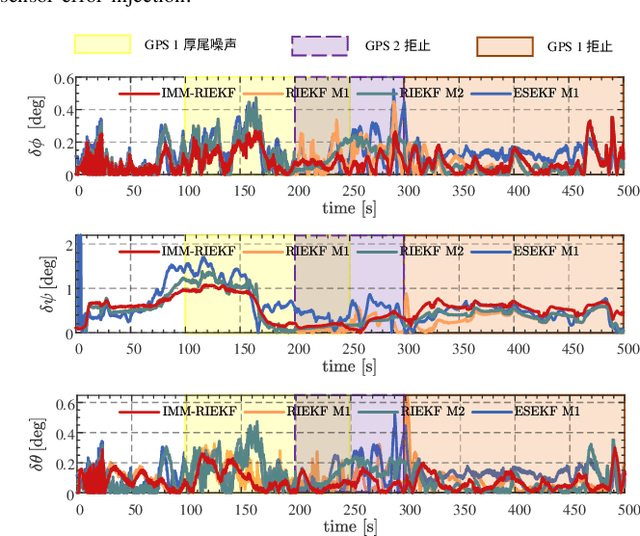
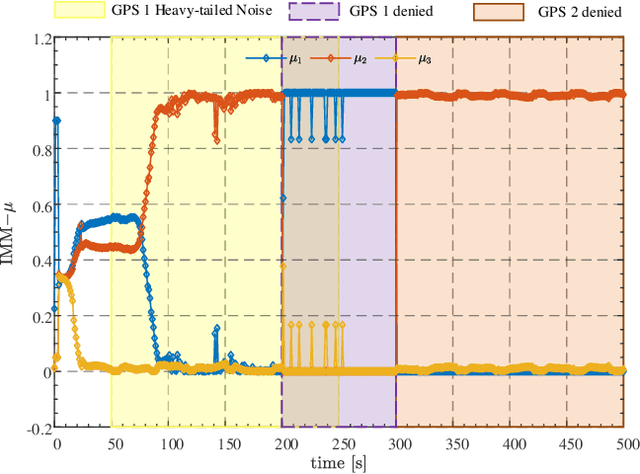
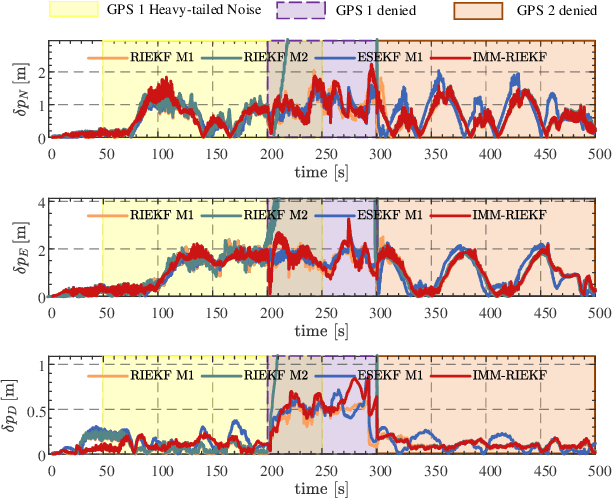
As the number of heterogeneous redundant sensors on unmanned aerial vehicle (UAV) increases, onboard sensors require a more rational and efficient credibility evaluation system and a resilient fusion framework to achieve the essence of seamless sensor group switching. A simple and efficient sensor credibility evaluation system is proposed to guide the selection of the optimal multi-source sensor submodel combination, thereby providing key model prior knowledge for multi-source resilient fusion. Furthermore, a multi-model interactive resilient fusion framework based on RIEKF is proposed, utilizing the defined sensor credibility indexes to guide the design of the model transition probability matrix, thereby reducing the sensitivity of submodel weights to fusion stability and solving the problem of the model transition matrix lacking a basis for adjustment. Model weights are updated in real time through credibility prior information and submodel posterior probabilities, thus leveraging the adaptive resilience advantage between models to achieve seamless switching between submodels in complex environments. Experimental results show that the algorithm presented in this paper, without using any sensor fault diagnosis and isolation logic, without setting any complex detection timing and thresholds, demonstrates a resilience advantage, thereby enhancing the adaptability of the state estimation system in complex environments.
Path Planning for a Cooperative Navigation Aid Vehicle to Assist Multiple Agents Intermittently
Feb 26, 2024This paper considers the problem of planning a path for a single underwater cooperative navigation aid (CNA) vehicle to intermittently aid a set of N agents to minimize average navigation uncertainty. Both the CNA and agents are modeled as constant-velocity vehicles. The agents traverse along known nominal trajectories and the CNA plans a path to sequentially intercept them. Navigation aiding is modeled by a scalar discrete time Kalman filter. During path planning, the CNA considers surfacing to reduce its own navigation uncertainty. A greedy planning algorithm is proposed that uses a heuristic based on an optimal time-to-aid, overall navigation uncertainty reduction, and transit time, to assign agents to the CNA. The approach is compared to an optimal (exhaustive enumeration) algorithm through a Monte Carlo experiment with randomized agent nominal trajectories and initial navigation uncertainty.
MGE: A Training-Free and Efficient Model Generation and Enhancement Scheme
Feb 27, 2024To provide a foundation for the research of deep learning models, the construction of model pool is an essential step. This paper proposes a Training-Free and Efficient Model Generation and Enhancement Scheme (MGE). This scheme primarily considers two aspects during the model generation process: the distribution of model parameters and model performance. Experiments result shows that generated models are comparable to models obtained through normal training, and even superior in some cases. Moreover, the time consumed in generating models accounts for only 1\% of the time required for normal model training. More importantly, with the enhancement of Evolution-MGE, generated models exhibits competitive generalization ability in few-shot tasks. And the behavioral dissimilarity of generated models has the potential of adversarial defense.
Inherent Diverse Redundant Safety Mechanisms for AI-based Software Elements in Automotive Applications
Feb 29, 2024This paper explores the role and challenges of Artificial Intelligence (AI) algorithms, specifically AI-based software elements, in autonomous driving systems. These AI systems are fundamental in executing real-time critical functions in complex and high-dimensional environments. They handle vital tasks like multi-modal perception, cognition, and decision-making tasks such as motion planning, lane keeping, and emergency braking. A primary concern relates to the ability (and necessity) of AI models to generalize beyond their initial training data. This generalization issue becomes evident in real-time scenarios, where models frequently encounter inputs not represented in their training or validation data. In such cases, AI systems must still function effectively despite facing distributional or domain shifts. This paper investigates the risk associated with overconfident AI models in safety-critical applications like autonomous driving. To mitigate these risks, methods for training AI models that help maintain performance without overconfidence are proposed. This involves implementing certainty reporting architectures and ensuring diverse training data. While various distribution-based methods exist to provide safety mechanisms for AI models, there is a noted lack of systematic assessment of these methods, especially in the context of safety-critical automotive applications. Many methods in the literature do not adapt well to the quick response times required in safety-critical edge applications. This paper reviews these methods, discusses their suitability for safety-critical applications, and highlights their strengths and limitations. The paper also proposes potential improvements to enhance the safety and reliability of AI algorithms in autonomous vehicles in the context of rapid and accurate decision-making processes.
ICP-Flow: LiDAR Scene Flow Estimation with ICP
Feb 27, 2024Scene flow characterizes the 3D motion between two LiDAR scans captured by an autonomous vehicle at nearby timesteps. Prevalent methods consider scene flow as point-wise unconstrained flow vectors that can be learned by either large-scale training beforehand or time-consuming optimization at inference. However, these methods do not take into account that objects in autonomous driving often move rigidly. We incorporate this rigid-motion assumption into our design, where the goal is to associate objects over scans and then estimate the locally rigid transformations. We propose ICP-Flow, a learning-free flow estimator. The core of our design is the conventional Iterative Closest Point (ICP) algorithm, which aligns the objects over time and outputs the corresponding rigid transformations. Crucially, to aid ICP, we propose a histogram-based initialization that discovers the most likely translation, thus providing a good starting point for ICP. The complete scene flow is then recovered from the rigid transformations. We outperform state-of-the-art baselines, including supervised models, on the Waymo dataset and perform competitively on Argoverse-v2 and nuScenes. Further, we train a feedforward neural network, supervised by the pseudo labels from our model, and achieve top performance among all models capable of real-time inference. We validate the advantage of our model on scene flow estimation with longer temporal gaps, up to 0.5 seconds where other models fail to deliver meaningful results.
Empowering Time Series Analysis with Large Language Models: A Survey
Feb 05, 2024Recently, remarkable progress has been made over large language models (LLMs), demonstrating their unprecedented capability in varieties of natural language tasks. However, completely training a large general-purpose model from the scratch is challenging for time series analysis, due to the large volumes and varieties of time series data, as well as the non-stationarity that leads to concept drift impeding continuous model adaptation and re-training. Recent advances have shown that pre-trained LLMs can be exploited to capture complex dependencies in time series data and facilitate various applications. In this survey, we provide a systematic overview of existing methods that leverage LLMs for time series analysis. Specifically, we first state the challenges and motivations of applying language models in the context of time series as well as brief preliminaries of LLMs. Next, we summarize the general pipeline for LLM-based time series analysis, categorize existing methods into different groups (i.e., direct query, tokenization, prompt design, fine-tune, and model integration), and highlight the key ideas within each group. We also discuss the applications of LLMs for both general and spatial-temporal time series data, tailored to specific domains. Finally, we thoroughly discuss future research opportunities to empower time series analysis with LLMs.
Enhancing Programming Error Messages in Real Time with Generative AI
Feb 12, 2024Generative AI is changing the way that many disciplines are taught, including computer science. Researchers have shown that generative AI tools are capable of solving programming problems, writing extensive blocks of code, and explaining complex code in simple terms. Particular promise has been shown in using generative AI to enhance programming error messages. Both students and instructors have complained for decades that these messages are often cryptic and difficult to understand. Yet recent work has shown that students make fewer repeated errors when enhanced via GPT-4. We extend this work by implementing feedback from ChatGPT for all programs submitted to our automated assessment tool, Athene, providing help for compiler, run-time, and logic errors. Our results indicate that adding generative AI to an automated assessment tool does not necessarily make it better and that design of the interface matters greatly to the usability of the feedback that GPT-4 provided.
Multi-Sensor and Multi-temporal High-Throughput Phenotyping for Monitoring and Early Detection of Water-Limiting Stress in Soybean
Feb 28, 2024Soybean production is susceptible to biotic and abiotic stresses, exacerbated by extreme weather events. Water limiting stress, i.e. drought, emerges as a significant risk for soybean production, underscoring the need for advancements in stress monitoring for crop breeding and production. This project combines multi-modal information to identify the most effective and efficient automated methods to investigate drought response. We investigated a set of diverse soybean accessions using multiple sensors in a time series high-throughput phenotyping manner to: (1) develop a pipeline for rapid classification of soybean drought stress symptoms, and (2) investigate methods for early detection of drought stress. We utilized high-throughput time-series phenotyping using UAVs and sensors in conjunction with machine learning (ML) analytics, which offered a swift and efficient means of phenotyping. The red-edge and green bands were most effective to classify canopy wilting stress. The Red-Edge Chlorophyll Vegetation Index (RECI) successfully differentiated susceptible and tolerant soybean accessions prior to visual symptom development. We report pre-visual detection of soybean wilting using a combination of different vegetation indices. These results can contribute to early stress detection methodologies and rapid classification of drought responses in screening nurseries for breeding and production applications.
Inferring Dynamic Networks from Marginals with Iterative Proportional Fitting
Feb 28, 2024A common network inference problem, arising from real-world data constraints, is how to infer a dynamic network from its time-aggregated adjacency matrix and time-varying marginals (i.e., row and column sums). Prior approaches to this problem have repurposed the classic iterative proportional fitting (IPF) procedure, also known as Sinkhorn's algorithm, with promising empirical results. However, the statistical foundation for using IPF has not been well understood: under what settings does IPF provide principled estimation of a dynamic network from its marginals, and how well does it estimate the network? In this work, we establish such a setting, by identifying a generative network model whose maximum likelihood estimates are recovered by IPF. Our model both reveals implicit assumptions on the use of IPF in such settings and enables new analyses, such as structure-dependent error bounds on IPF's parameter estimates. When IPF fails to converge on sparse network data, we introduce a principled algorithm that guarantees IPF converges under minimal changes to the network structure. Finally, we conduct experiments with synthetic and real-world data, which demonstrate the practical value of our theoretical and algorithmic contributions.