 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Unified Framework for Pun Generation with Humor Principles
Oct 24, 2022
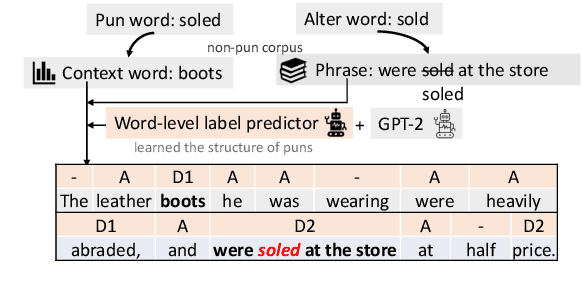

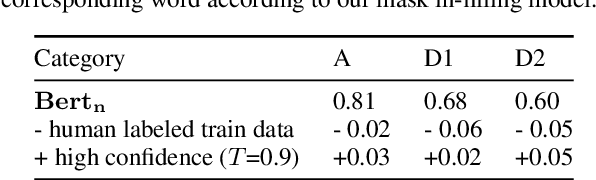
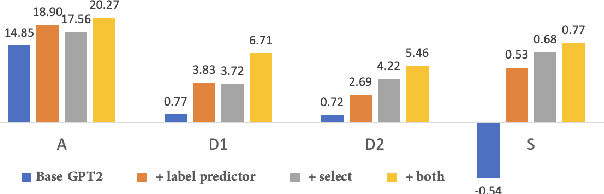
We propose a unified framework to generate both homophonic and homographic puns to resolve the split-up in existing works. Specifically, we incorporate three linguistic attributes of puns to the language models: ambiguity, distinctiveness, and surprise. Our framework consists of three parts: 1) a context words/phrases selector to promote the aforementioned attributes, 2) a generation model trained on non-pun sentences to incorporate the context words/phrases into the generation output, and 3) a label predictor that learns the structure of puns which is used to steer the generation model at inference time. Evaluation results on both pun types demonstrate the efficacy of our model over strong baselines.
Speeding Up Question Answering Task of Language Models via Inverted Index
Oct 24, 2022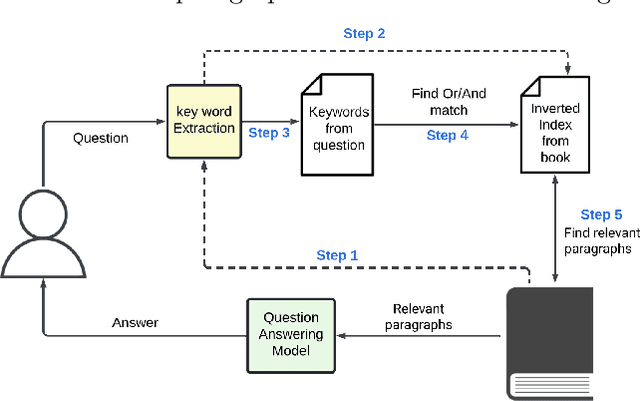
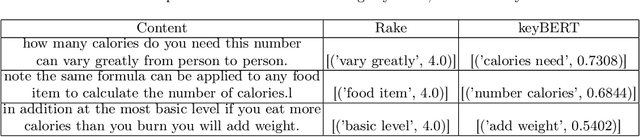
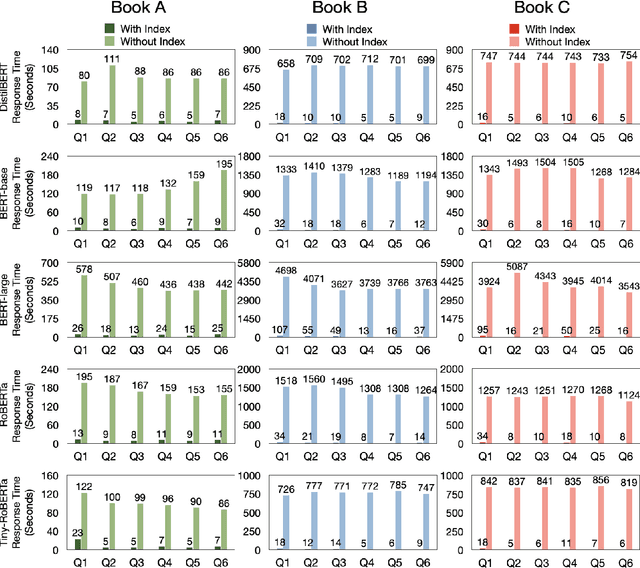
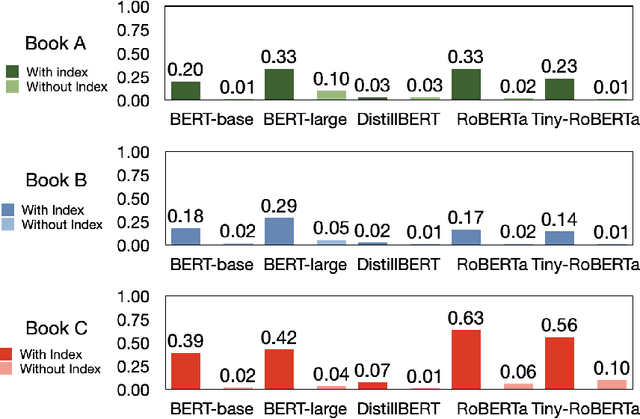
Natural language processing applications, such as conversational agents and their question-answering capabilities, are widely used in the real world. Despite the wide popularity of large language models (LLMs), few real-world conversational agents take advantage of LLMs. Extensive resources consumed by LLMs disable developers from integrating them into end-user applications. In this study, we leverage an inverted indexing mechanism combined with LLMs to improve the efficiency of question-answering models for closed-domain questions. Our experiments show that using the index improves the average response time by 97.44%. In addition, due to the reduced search scope, the average BLEU score improved by 0.23 while using the inverted index.
HAQJSK: Hierarchical-Aligned Quantum Jensen-Shannon Kernels for Graph Classification
Nov 08, 2022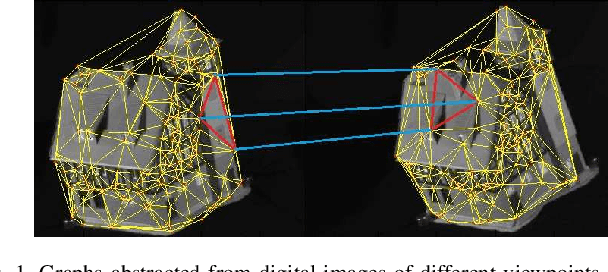
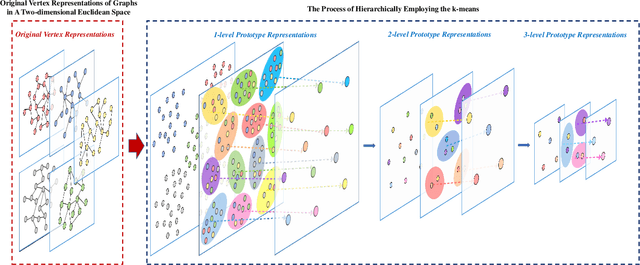
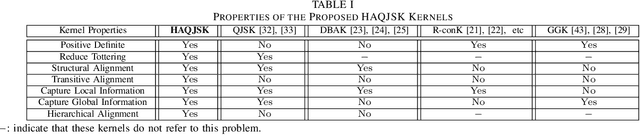
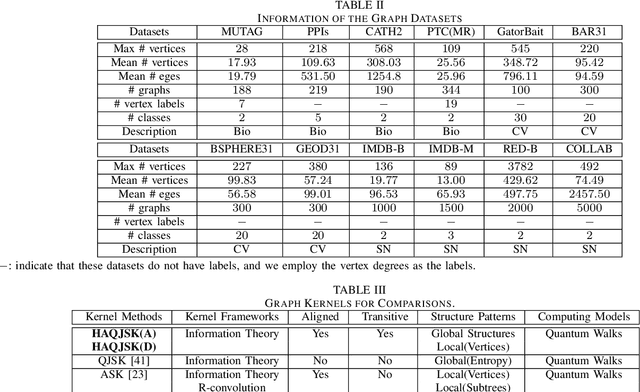
In this work, we propose a family of novel quantum kernels, namely the Hierarchical Aligned Quantum Jensen-Shannon Kernels (HAQJSK), for un-attributed graphs. Different from most existing classical graph kernels, the proposed HAQJSK kernels can incorporate hierarchical aligned structure information between graphs and transform graphs of random sizes into fixed-sized aligned graph structures, i.e., the Hierarchical Transitive Aligned Adjacency Matrix of vertices and the Hierarchical Transitive Aligned Density Matrix of the Continuous-Time Quantum Walk (CTQW). For a pair of graphs to hand, the resulting HAQJSK kernels are defined by measuring the Quantum Jensen-Shannon Divergence (QJSD) between their transitive aligned graph structures. We show that the proposed HAQJSK kernels not only reflect richer intrinsic global graph characteristics in terms of the CTQW, but also address the drawback of neglecting structural correspondence information arising in most existing R-convolution kernels. Furthermore, unlike the previous Quantum Jensen-Shannon Kernels associated with the QJSD and the CTQW, the proposed HAQJSK kernels can simultaneously guarantee the properties of permutation invariant and positive definiteness, explaining the theoretical advantages of the HAQJSK kernels. Experiments indicate the effectiveness of the proposed kernels.
Efficient Compressed Ratio Estimation using Online Sequential Learning for Edge Computing
Nov 08, 2022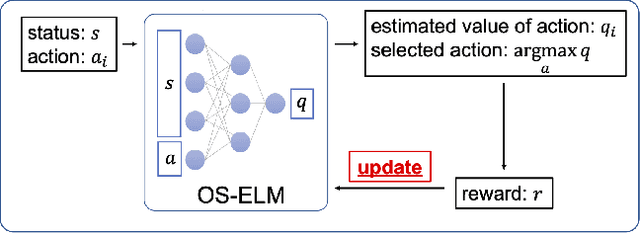
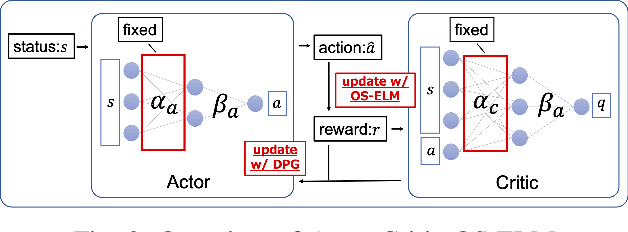
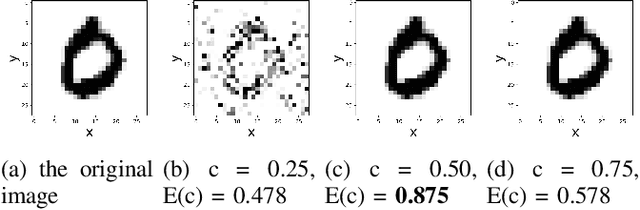
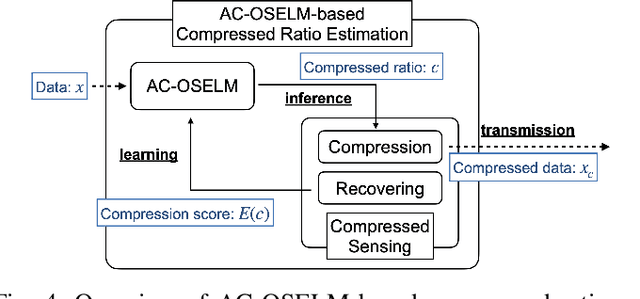
Owing to the widespread adoption of the Internet of Things, a vast amount of sensor information is being acquired in real time. Accordingly, the communication cost of data from edge devices is increasing. Compressed sensing (CS), a data compression method that can be used on edge devices, has been attracting attention as a method to reduce communication costs. In CS, estimating the appropriate compression ratio is important. There is a method to adaptively estimate the compression ratio for the acquired data using reinforcement learning. However, the computational costs associated with existing reinforcement learning methods that can be utilized on edges are expensive. In this study, we developed an efficient reinforcement learning method for edge devices, referred to as the actor--critic online sequential extreme learning machine (AC-OSELM), and a system to compress data by estimating an appropriate compression ratio on the edge using AC-OSELM. The performance of the proposed method in estimating the compression ratio is evaluated by comparing it with other reinforcement learning methods for edge devices. The experimental results show that AC-OSELM achieved the same or better compression performance and faster compression ratio estimation than the existing methods.
Parameter and Data Efficient Continual Pre-training for Robustness to Dialectal Variance in Arabic
Nov 08, 2022
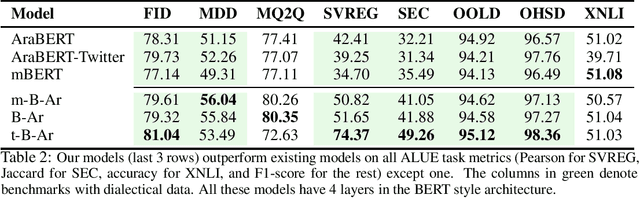
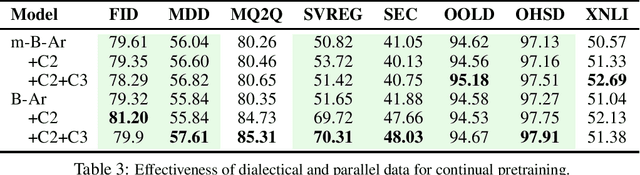
The use of multilingual language models for tasks in low and high-resource languages has been a success story in deep learning. In recent times, Arabic has been receiving widespread attention on account of its dialectal variance. While prior research studies have tried to adapt these multilingual models for dialectal variants of Arabic, it still remains a challenging problem owing to the lack of sufficient monolingual dialectal data and parallel translation data of such dialectal variants. It remains an open problem on whether the limited dialectical data can be used to improve the models trained in Arabic on its dialectal variants. First, we show that multilingual-BERT (mBERT) incrementally pretrained on Arabic monolingual data takes less training time and yields comparable accuracy when compared to our custom monolingual Arabic model and beat existing models (by an avg metric of +$6.41$). We then explore two continual pre-training methods -- (1) using small amounts of dialectical data for continual finetuning and (2) parallel Arabic to English data and a Translation Language Modeling loss function. We show that both approaches help improve performance on dialectal classification tasks ($+4.64$ avg. gain) when used on monolingual models.
Creating a Safety Assurance Case for an ML Satellite-Based Wildfire Detection and Alert System
Nov 08, 2022
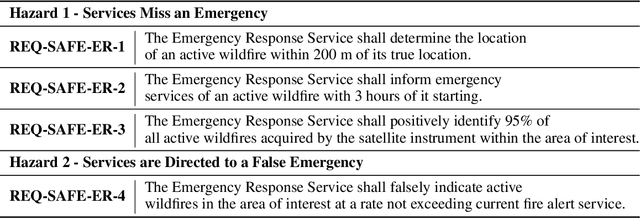
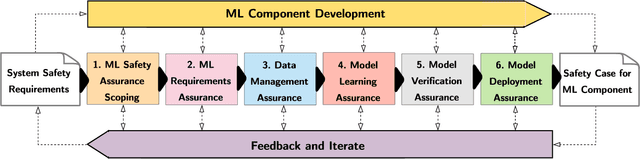

Wildfires are a common problem in many areas of the world with often catastrophic consequences. A number of systems have been created to provide early warnings of wildfires, including those that use satellite data to detect fires. The increased availability of small satellites, such as CubeSats, allows the wildfire detection response time to be reduced by deploying constellations of multiple satellites over regions of interest. By using machine learned components on-board the satellites, constraints which limit the amount of data that can be processed and sent back to ground stations can be overcome. There are hazards associated with wildfire alert systems, such as failing to detect the presence of a wildfire, or detecting a wildfire in the incorrect location. It is therefore necessary to be able to create a safety assurance case for the wildfire alert ML component that demonstrates it is sufficiently safe for use. This paper describes in detail how a safety assurance case for an ML wildfire alert system is created. This represents the first fully developed safety case for an ML component containing explicit argument and evidence as to the safety of the machine learning.
Partial Differential Equations Meet Deep Neural Networks: A Survey
Nov 18, 2022
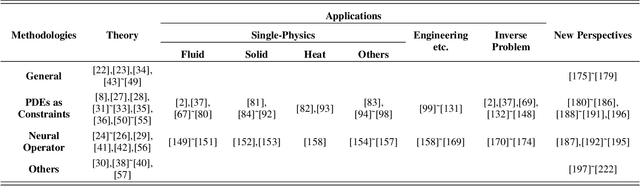
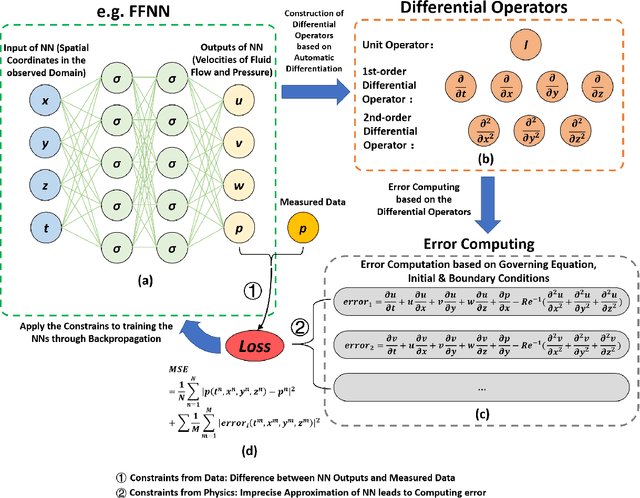

Many problems in science and engineering can be represented by a set of partial differential equations (PDEs) through mathematical modeling. Mechanism-based computation following PDEs has long been an essential paradigm for studying topics such as computational fluid dynamics, multiphysics simulation, molecular dynamics, or even dynamical systems. It is a vibrant multi-disciplinary field of increasing importance and with extraordinary potential. At the same time, solving PDEs efficiently has been a long-standing challenge. Generally, except for a few differential equations for which analytical solutions are directly available, many more equations must rely on numerical approaches such as the finite difference method, finite element method, finite volume method, and boundary element method to be solved approximately. These numerical methods usually divide a continuous problem domain into discrete points and then concentrate on solving the system at each of those points. Though the effectiveness of these traditional numerical methods, the vast number of iterative operations accompanying each step forward significantly reduces the efficiency. Recently, another equally important paradigm, data-based computation represented by deep learning, has emerged as an effective means of solving PDEs. Surprisingly, a comprehensive review for this interesting subfield is still lacking. This survey aims to categorize and review the current progress on Deep Neural Networks (DNNs) for PDEs. We discuss the literature published in this subfield over the past decades and present them in a common taxonomy, followed by an overview and classification of applications of these related methods in scientific research and engineering scenarios. The origin, developing history, character, sort, as well as the future trends in each potential direction of this subfield are also introduced.
Invariant Learning via Diffusion Dreamed Distribution Shifts
Nov 18, 2022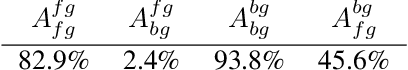



Though the background is an important signal for image classification, over reliance on it can lead to incorrect predictions when spurious correlations between foreground and background are broken at test time. Training on a dataset where these correlations are unbiased would lead to more robust models. In this paper, we propose such a dataset called Diffusion Dreamed Distribution Shifts (D3S). D3S consists of synthetic images generated through StableDiffusion using text prompts and image guides obtained by pasting a sample foreground image onto a background template image. Using this scalable approach we generate 120K images of objects from all 1000 ImageNet classes in 10 diverse backgrounds. Due to the incredible photorealism of the diffusion model, our images are much closer to natural images than previous synthetic datasets. D3S contains a validation set of more than 17K images whose labels are human-verified in an MTurk study. Using the validation set, we evaluate several popular DNN image classifiers and find that the classification performance of models generally suffers on our background diverse images. Next, we leverage the foreground & background labels in D3S to learn a foreground (background) representation that is invariant to changes in background (foreground) by penalizing the mutual information between the foreground (background) features and the background (foreground) labels. Linear classifiers trained on these features to predict foreground (background) from foreground (background) have high accuracies at 82.9% (93.8%), while classifiers that predict these labels from background and foreground have a much lower accuracy of 2.4% and 45.6% respectively. This suggests that our foreground and background features are well disentangled. We further test the efficacy of these representations by training classifiers on a task with strong spurious correlations.
Towards a real-time continuous ultrafast ultrasound beamformer with programmable logic
Aug 06, 2022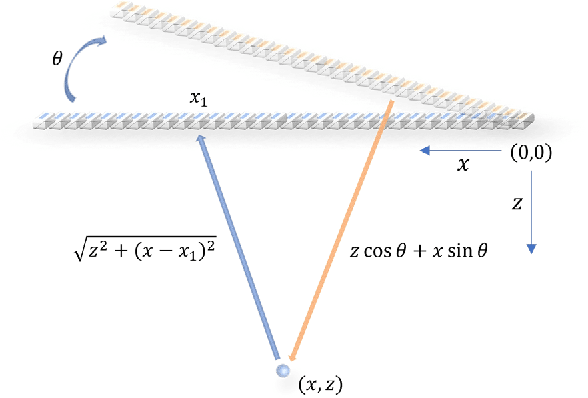
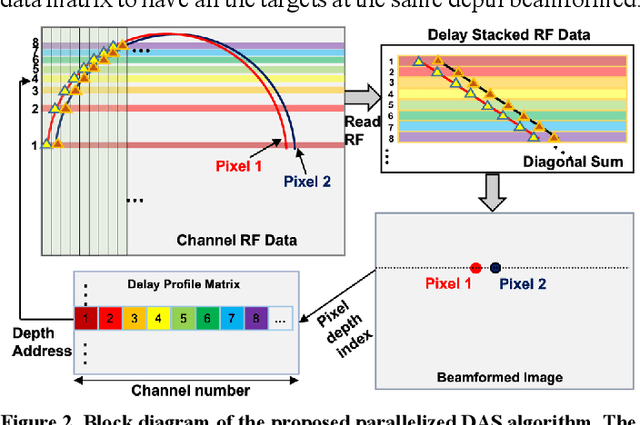
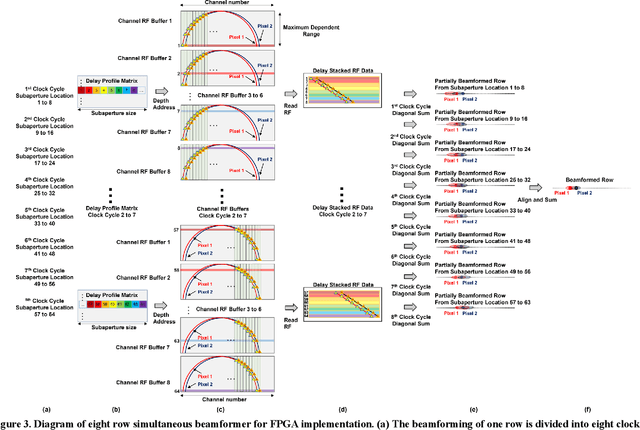
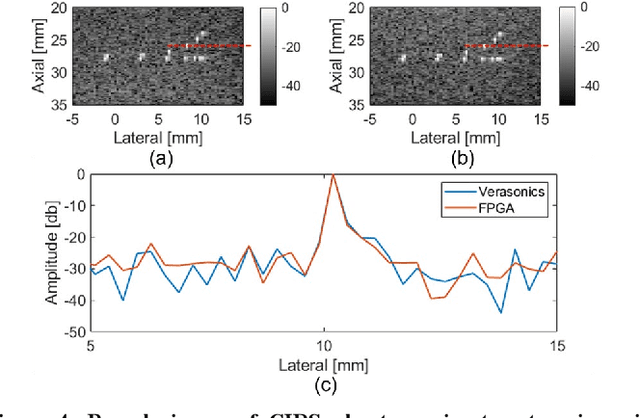
Ultrafast ultrasound imaging is essential for advanced ultrasound imaging techniques such as ultrasound localization microscopy (ULM) and functional ultrasound (fUS). Current ultrafast ultrasound imaging is challenged by the ultrahigh data bandwidth associated with the radio frequency (RF) signal, and by the latency of the computationally expensive beamforming process. As such, continuous ultrafast data acquisition and beamforming remain elusive with existing software beamformers based on CPUs or GPUs. To address these challenges, the proposed work introduces a hybrid solution composed of an improved delay and sum (DAS) algorithm with high hardware efficiency and an ultrafast beamformer based on the field programmable gate array (FPGA). Our proposed method presents two unique advantages over conventional FPGA-based beamformers: 1) high scalability that allows fast adaptation to different FPGA platforms; 2) high adaptability to different imaging probes and applications thanks to the absence of hard-coded imaging parameters. With the proposed method, we measured an ultrafast beamforming frame rate of over 3.38 GPixels/second. The performance of the proposed beamformer was compared with the software beamformer on the Verasonics Vantage system for both phantom imaging and in vivo imaging of a mouse brain. Multiple imaging schemes including B-mode, power Doppler and ULM were evaluated with the proposed solution.
Ice Core Dating using Probabilistic Programming
Oct 29, 2022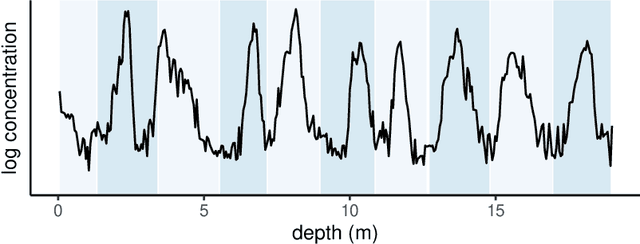
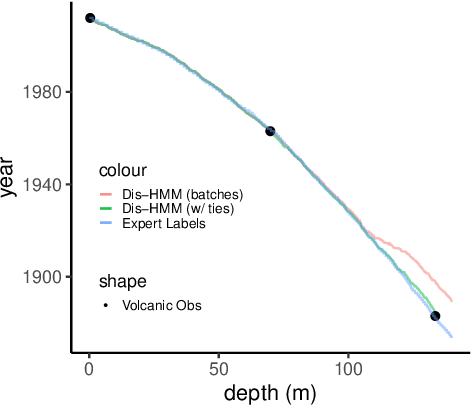
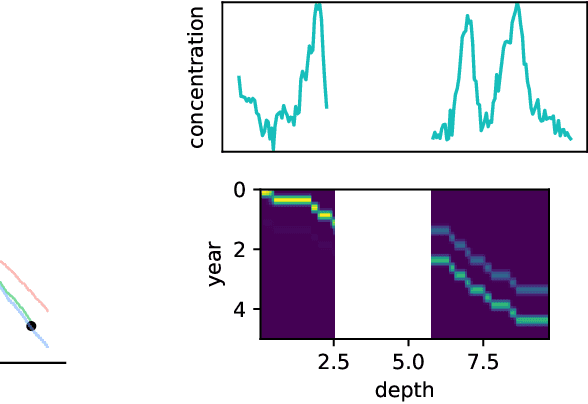
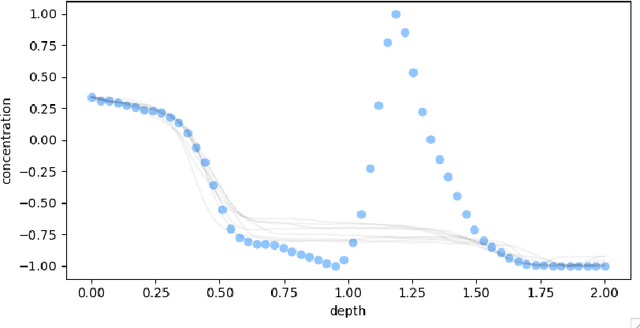
Ice cores record crucial information about past climate. However, before ice core data can have scientific value, the chronology must be inferred by estimating the age as a function of depth. Under certain conditions, chemicals locked in the ice display quasi-periodic cycles that delineate annual layers. Manually counting these noisy seasonal patterns to infer the chronology can be an imperfect and time-consuming process, and does not capture uncertainty in a principled fashion. In addition, several ice cores may be collected from a region, introducing an aspect of spatial correlation between them. We present an exploration of the use of probabilistic models for automatic dating of ice cores, using probabilistic programming to showcase its use for prototyping, automatic inference and maintainability, and demonstrate common failure modes of these tools.