 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DyG2Vec: Representation Learning for Dynamic Graphs with Self-Supervision
Oct 30, 2022
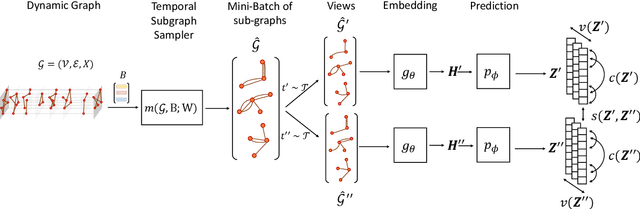
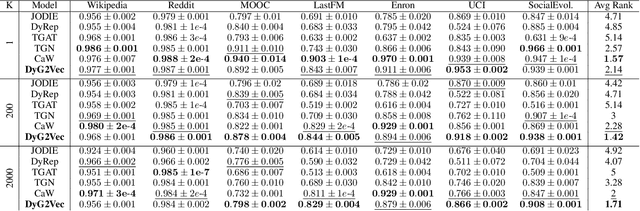
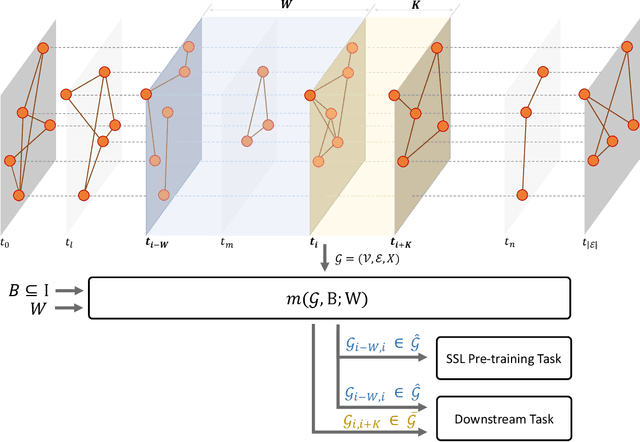
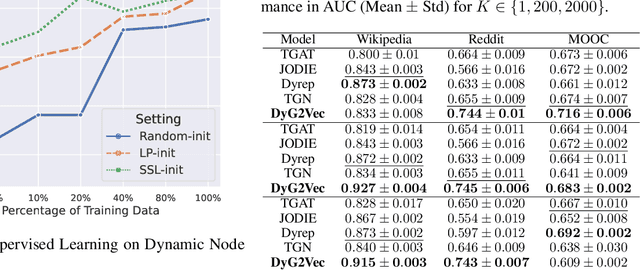
The challenge in learning from dynamic graphs for predictive tasks lies in extracting fine-grained temporal motifs from an ever-evolving graph. Moreover, task labels are often scarce, costly to obtain, and highly imbalanced for large dynamic graphs. Recent advances in self-supervised learning on graphs demonstrate great potential, but focus on static graphs. State-of-the-art (SoTA) models for dynamic graphs are not only incompatible with the self-supervised learning (SSL) paradigm but also fail to forecast interactions beyond the very near future. To address these limitations, we present DyG2Vec, an SSL-compatible, efficient model for representation learning on dynamic graphs. DyG2Vec uses a window-based mechanism to generate task-agnostic node embeddings that can be used to forecast future interactions. DyG2Vec significantly outperforms SoTA baselines on benchmark datasets for downstream tasks while only requiring a fraction of the training/inference time. We adapt two SSL evaluation mechanisms to make them applicable to dynamic graphs and thus show that SSL pre-training helps learn more robust temporal node representations, especially for scenarios with few labels.
Medical Codes Prediction from Clinical Notes: From Human Coders to Machines
Oct 30, 2022Prediction of medical codes from clinical notes is a practical and essential need for every healthcare delivery organization within current medical systems. Automating annotation will save significant time and excessive effort that human coders spend today. However, the biggest challenge is directly identifying appropriate medical codes from several thousands of high-dimensional codes from unstructured free-text clinical notes. This complex medical codes prediction problem from clinical notes has received substantial interest in the NLP community, and several recent studies have shown the state-of-the-art code prediction results of full-fledged deep learning-based methods. This progress raises the fundamental question of how far automated machine learning systems are from human coders' working performance, as well as the important question of how well current explainability methods apply to advanced neural network models such as transformers. This is to predict correct codes and present references in clinical notes that support code prediction, as this level of explainability and accuracy of the prediction outcomes is critical to gaining trust from professional medical coders.
Statistical shape representations for temporal registration of plant components in 3D
Sep 23, 2022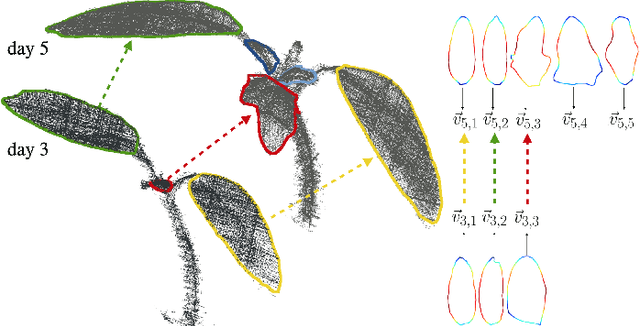
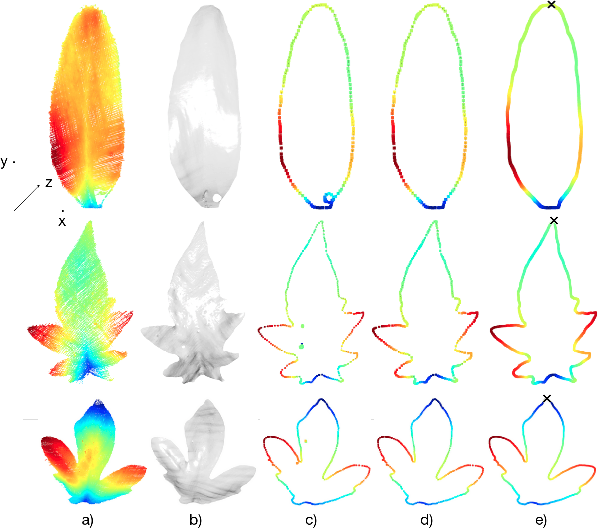
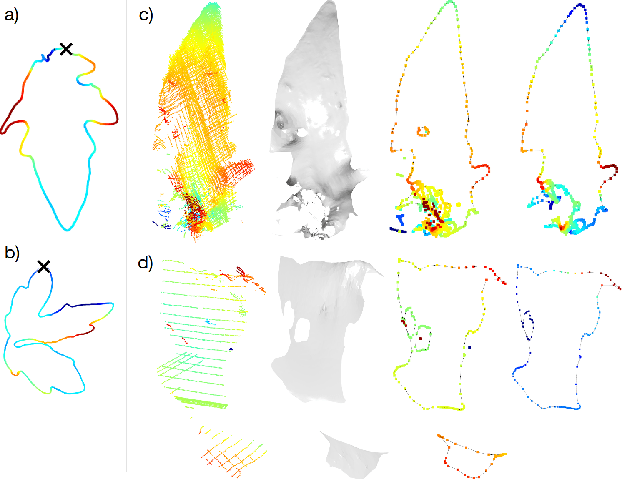
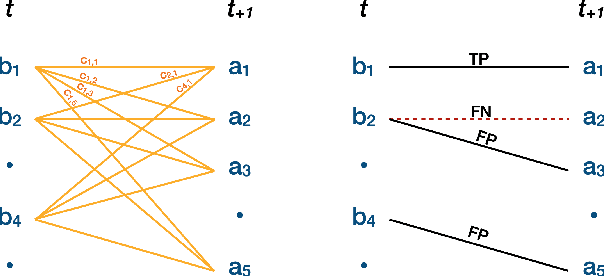
Plants are dynamic organisms. Understanding temporal variations in vegetation is an essential problem for all robots in the wild. However, associating repeated 3D scans of plants across time is challenging. A key step in this process is re-identifying and tracking the same individual plant components over time. Previously, this has been achieved by comparing their global spatial or topological location. In this work, we demonstrate how using shape features improves temporal organ matching. We present a landmark-free shape compression algorithm, which allows for the extraction of 3D shape features of leaves, characterises leaf shape and curvature efficiently in few parameters, and makes the association of individual leaves in feature space possible. The approach combines 3D contour extraction and further compression using Principal Component Analysis (PCA) to produce a shape space encoding, which is entirely learned from data and retains information about edge contours and 3D curvature. Our evaluation on temporal scan sequences of tomato plants shows, that incorporating shape features improves temporal leaf-matching. A combination of shape, location, and rotation information proves most informative for recognition of leaves over time and yields a true positive rate of 75%, a 15% improvement on sate-of-the-art methods. This is essential for robotic crop monitoring, which enables whole-of-lifecycle phenotyping.
Importance Tempering: Group Robustness for Overparameterized Models
Sep 27, 2022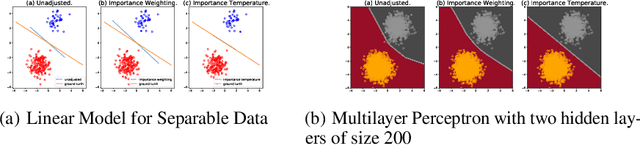
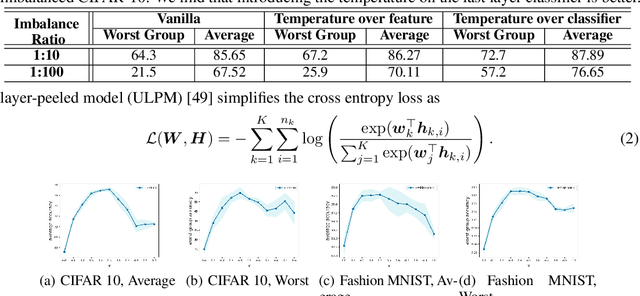
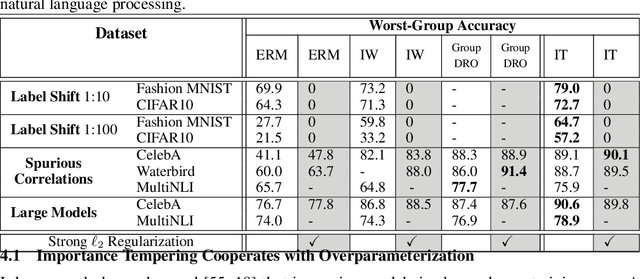

Although overparameterized models have shown their success on many machine learning tasks, the accuracy could drop on the testing distribution that is different from the training one. This accuracy drop still limits applying machine learning in the wild. At the same time, importance weighting, a traditional technique to handle distribution shifts, has been demonstrated to have less or even no effect on overparameterized models both empirically and theoretically. In this paper, we propose importance tempering to improve the decision boundary and achieve consistently better results for overparameterized models. Theoretically, we justify that the selection of group temperature can be different under label shift and spurious correlation setting. At the same time, we also prove that properly selected temperatures can extricate the minority collapse for imbalanced classification. Empirically, we achieve state-of-the-art results on worst group classification tasks using importance tempering.
Deep Dynamic Effective Connectivity Estimation from Multivariate Time Series
Feb 04, 2022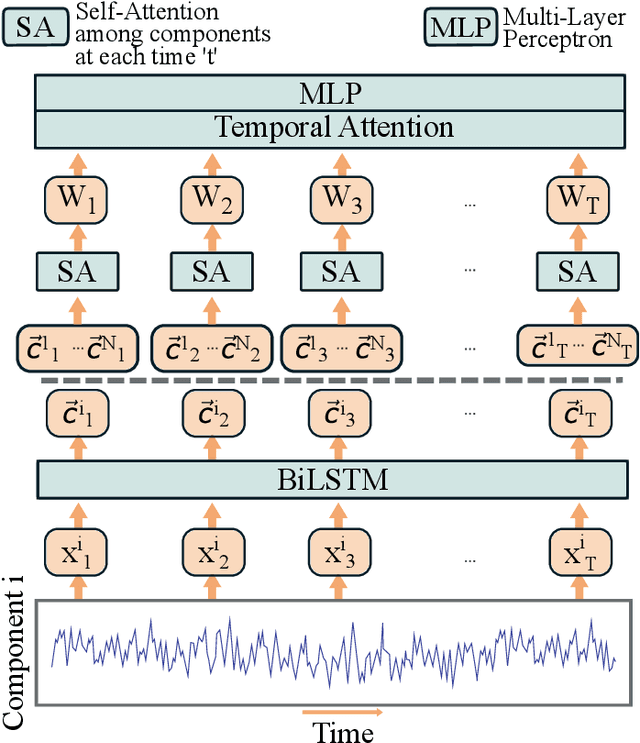
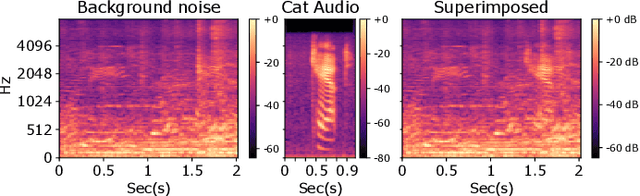
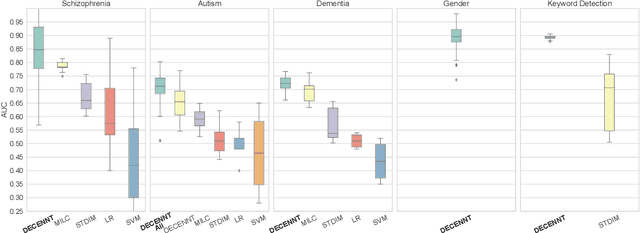
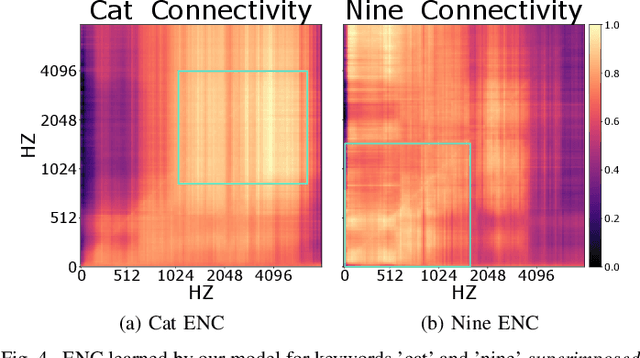
Recently, methods that represent data as a graph, such as graph neural networks (GNNs) have been successfully used to learn data representations and structures to solve classification and link prediction problems. The applications of such methods are vast and diverse, but most of the current work relies on the assumption of a static graph. This assumption does not hold for many highly dynamic systems, where the underlying connectivity structure is non-stationary and is mostly unobserved. Using a static model in these situations may result in sub-optimal performance. In contrast, modeling changes in graph structure with time can provide information about the system whose applications go beyond classification. Most work of this type does not learn effective connectivity and focuses on cross-correlation between nodes to generate undirected graphs. An undirected graph is unable to capture direction of an interaction which is vital in many fields, including neuroscience. To bridge this gap, we developed dynamic effective connectivity estimation via neural network training (DECENNT), a novel model to learn an interpretable directed and dynamic graph induced by the downstream classification/prediction task. DECENNT outperforms state-of-the-art (SOTA) methods on five different tasks and infers interpretable task-specific dynamic graphs. The dynamic graphs inferred from functional neuroimaging data align well with the existing literature and provide additional information. Additionally, the temporal attention module of DECENNT identifies time-intervals crucial for predictive downstream task from multivariate time series data.
Memory-guided Image De-raining Using Time-Lapse Data
Jan 06, 2022


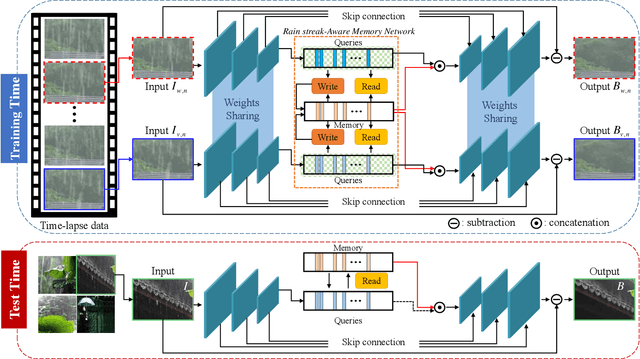
This paper addresses the problem of single image de-raining, that is, the task of recovering clean and rain-free background scenes from a single image obscured by a rainy artifact. Although recent advances adopt real-world time-lapse data to overcome the need for paired rain-clean images, they are limited to fully exploit the time-lapse data. The main cause is that, in terms of network architectures, they could not capture long-term rain streak information in the time-lapse data during training owing to the lack of memory components. To address this problem, we propose a novel network architecture based on a memory network that explicitly helps to capture long-term rain streak information in the time-lapse data. Our network comprises the encoder-decoder networks and a memory network. The features extracted from the encoder are read and updated in the memory network that contains several memory items to store rain streak-aware feature representations. With the read/update operation, the memory network retrieves relevant memory items in terms of the queries, enabling the memory items to represent the various rain streaks included in the time-lapse data. To boost the discriminative power of memory features, we also present a novel background selective whitening (BSW) loss for capturing only rain streak information in the memory network by erasing the background information. Experimental results on standard benchmarks demonstrate the effectiveness and superiority of our approach.
Fast Gaussian Process Predictions on Large Geospatial Fields with Prediction-Point Dependent Basis Functions
Oct 17, 2022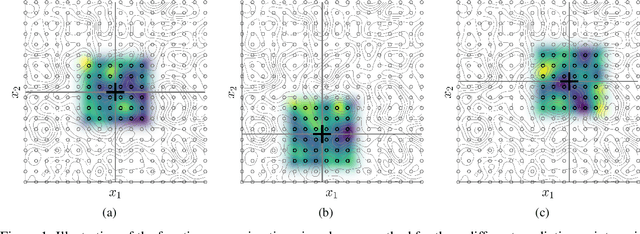
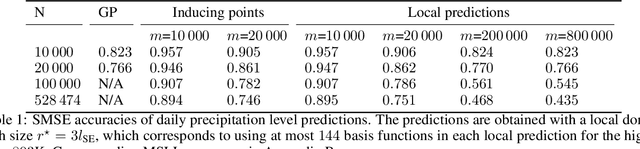
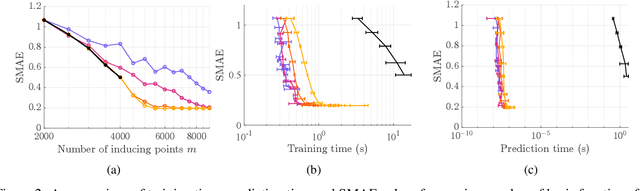
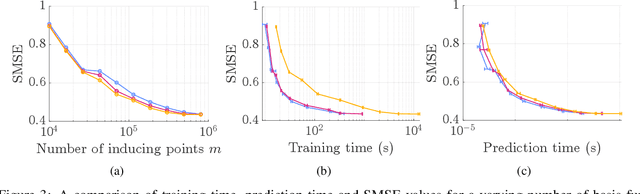
In order to perform GP predictions fast in large geospatial fields with small-scale variations, a computational complexity that is independent of the number of measurements $N$ and the size of the field is crucial. In this setting, GP approximations using $m$ basis functions requires $\mathcal{O}(Nm^2+m^3)$ computations. Using finite-support basis functions reduces the required number of computations to perform a single prediction to $\mathcal{O}(m^3)$, after a one-time training cost of $O(N)$. The prediction cost increases with increasing field size, as the number of required basis functions $m$ grows with the size of the field relative to the size of the spatial variations. To prevent the prediction speed from depending on field size, we propose leveraging the property that a subset of the trained system is a trained subset of the system to use only a local subset of $m'\ll m$ finite-support basis functions centered around each prediction point to perform predictions. Our proposed approximation requires $\mathcal{O}(m'^3)$ operations to perform each prediction after a one-time training cost of $\mathcal{O}(N)$. We show on real-life spatial data that our approach matches the prediction error of state-of-the-art methods and that it performs faster predictions, also compared to state-of-the-art approximations that lower the prediction cost of $\mathcal{O}(m^3)$ to $\mathcal{O}(m\log(m))$ using a conjugate gradient solver. Finally, we demonstrate that our approach can perform fast predictions on a global bathymetry dataset using millions of basis functions and tens of millions of measurements on a laptop computer.
Just ClozE! A Fast and Simple Method for Evaluating the Factual Consistency in Abstractive Summarization
Oct 06, 2022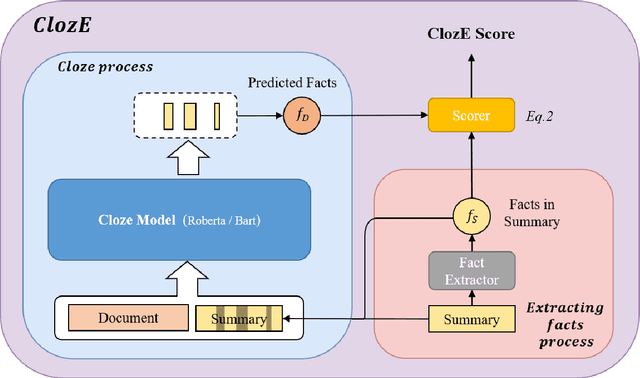
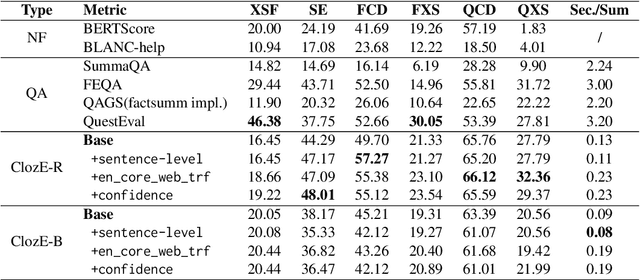
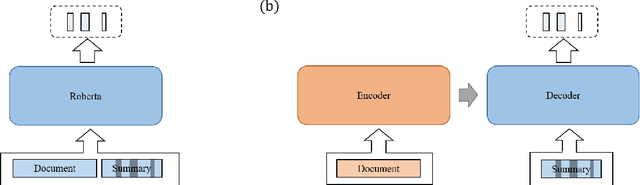

The issue of factual consistency in abstractive summarization has attracted much attention in recent years, and the evaluation of factual consistency between summary and document has become an important and urgent task. Most of the current evaluation metrics are adopted from the question answering (QA). However, the application of QA-based metrics is extremely time-consuming in practice, causing the iteration cycle of abstractive summarization research to be severely prolonged. In this paper, we propose a new method called ClozE to evaluate factual consistency by cloze model, instantiated based on masked language model(MLM), with strong interpretability and substantially higher speed. We demonstrate that ClozE can reduce the evaluation time by nearly 96$\%$ relative to QA-based metrics while retaining their interpretability and performance through experiments on six human-annotated datasets and a meta-evaluation benchmark GO FIGURE \citep{gabriel2020go}. We also implement experiments to further demonstrate more characteristics of ClozE in terms of performance and speed. In addition, we conduct an experimental analysis of the limitations of ClozE, which suggests future research directions. The code and models for ClozE will be released upon the paper acceptance.
HetSyn: Speeding Up Local SGD with Heterogeneous Synchronization
Oct 06, 2022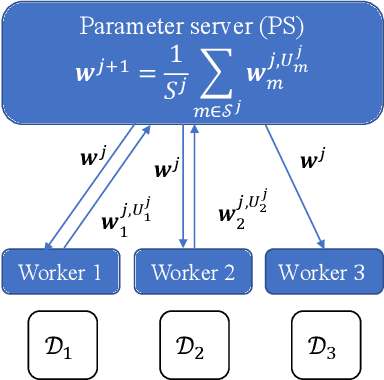
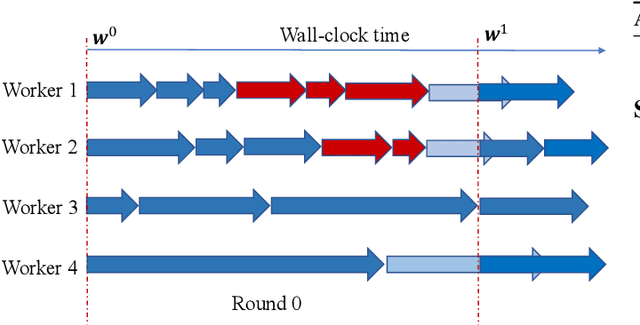
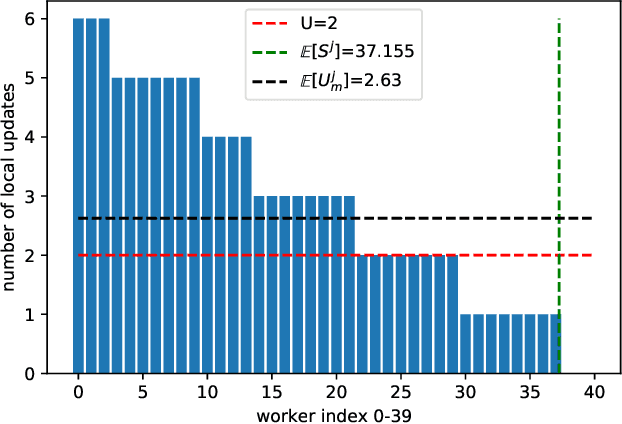
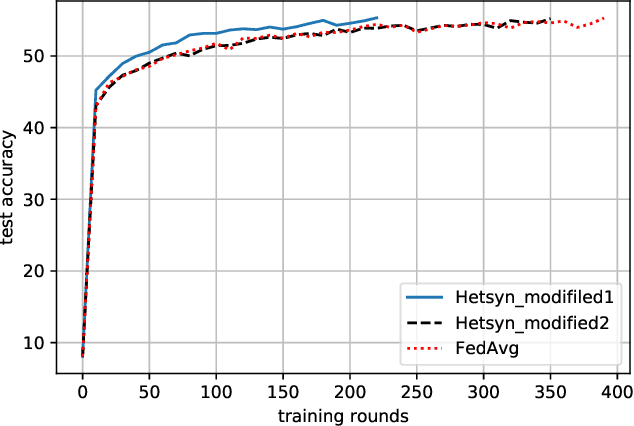
Synchronous local stochastic gradient descent (local SGD) suffers from some workers being idle and random delays due to slow and straggling workers, as it waits for the workers to complete the same amount of local updates. In this paper, to mitigate stragglers and improve communication efficiency, a novel local SGD strategy, named HetSyn, is developed. The key point is to keep all the workers computing continually at each synchronization round, and make full use of any effective (completed) local update of each worker regardless of stragglers. An analysis of the average wall-clock time, average number of local updates and average number of uploading workers per round is provided to gauge the performance of HetSyn. The convergence of HetSyn is also rigorously established even when the objective function is nonconvex. Experimental results show the superiority of the proposed HetSyn against state-of-the-art schemes through utilization of additional effective local updates at each worker, and the influence of system parameters is studied. By allowing heterogeneous synchronization with different numbers of local updates across workers, HetSyn provides substantial improvements both in time and communication efficiency.
Geodesic Graph Neural Network for Efficient Graph Representation Learning
Oct 06, 2022
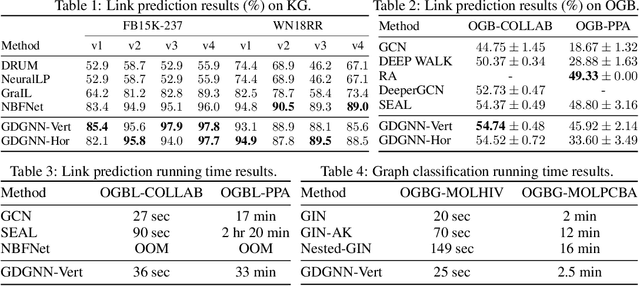
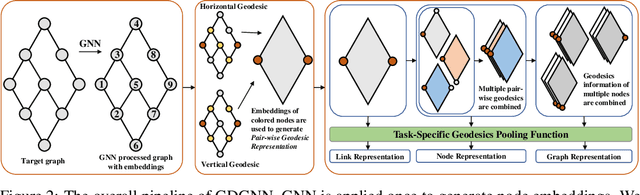
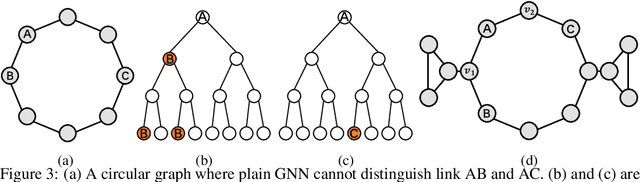
Recently, Graph Neural Networks (GNNs) have been applied to graph learning tasks and achieved state-of-the-art results. However, many competitive methods employ preprocessing on the target nodes, such as subgraph extraction and customized labeling, to capture some information that is hard to be learned by normal GNNs. Such operations are time-consuming and do not scale to large graphs. In this paper, we propose an efficient GNN framework called Geodesic GNN (GDGNN). It injects conditional relationships between nodes into the model without labeling. Specifically, we view the shortest paths between two nodes as the spatial graph context of the neighborhood around them. The GNN embeddings of nodes on the shortest paths are used to generate geodesic representations. Conditioned on the geodesic representations, GDGNN is able to generate node, link, and graph representations that carry much richer structural information than plain GNNs. We theoretically prove that GDGNN is more powerful than plain GNNs, and present experimental results to show that GDGNN achieves highly competitive performance with state-of-the-art GNN models on link prediction and graph classification tasks while taking significantly less time.