 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Streaming Voice Conversion Via Intermediate Bottleneck Features And Non-streaming Teacher Guidance
Oct 27, 2022
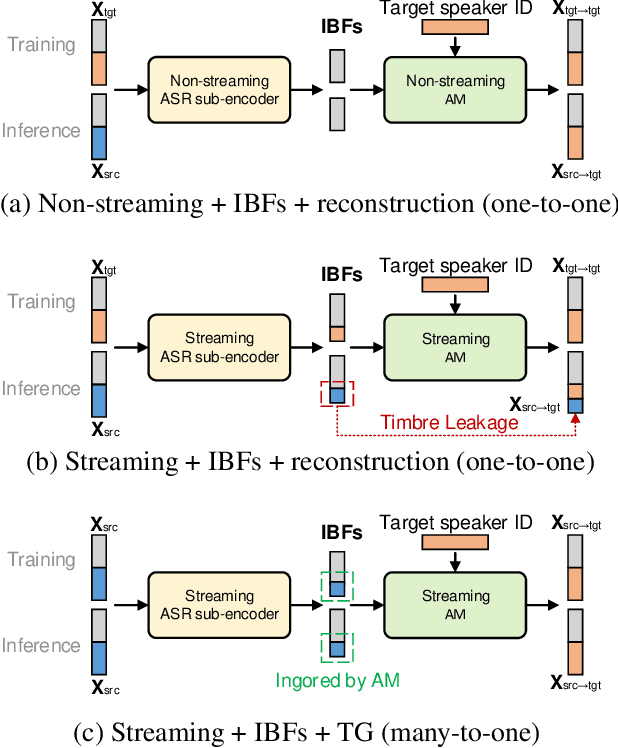
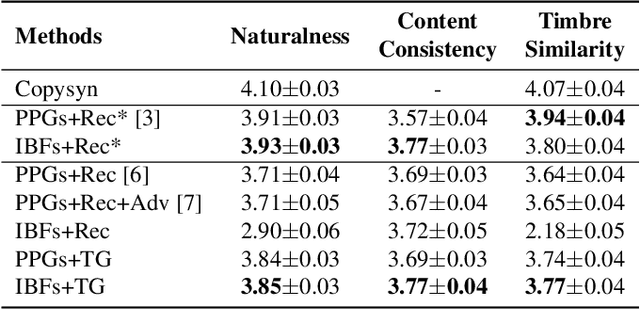
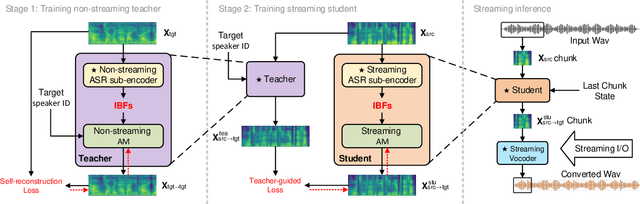
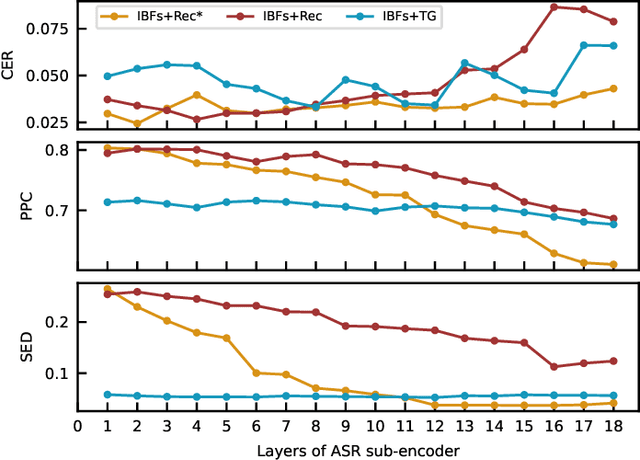
Streaming voice conversion (VC) is the task of converting the voice of one person to another in real-time. Previous streaming VC methods use phonetic posteriorgrams (PPGs) extracted from automatic speech recognition (ASR) systems to represent speaker-independent information. However, PPGs lack the prosody and vocalization information of the source speaker, and streaming PPGs contain undesired leaked timbre of the source speaker. In this paper, we propose to use intermediate bottleneck features (IBFs) to replace PPGs. VC systems trained with IBFs retain more prosody and vocalization information of the source speaker. Furthermore, we propose a non-streaming teacher guidance (TG) framework that addresses the timbre leakage problem. Experiments show that our proposed IBFs and the TG framework achieve a state-of-the-art streaming VC naturalness of 3.85, a content consistency of 3.77, and a timbre similarity of 3.77 under a future receptive field of 160 ms which significantly outperform previous streaming VC systems.
Just ClozE! A Fast and Simple Method for Evaluating the Factual Consistency in Abstractive Summarization
Oct 06, 2022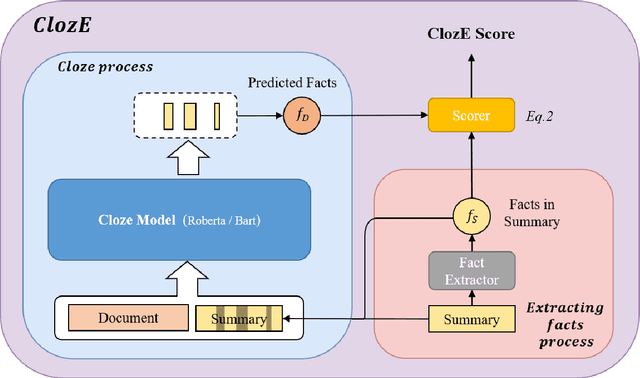
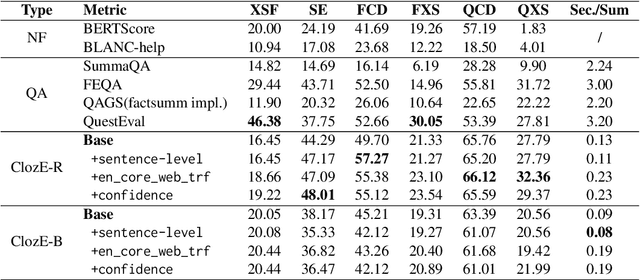
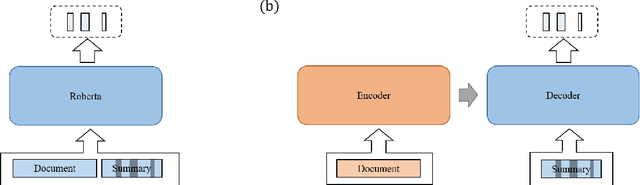

The issue of factual consistency in abstractive summarization has attracted much attention in recent years, and the evaluation of factual consistency between summary and document has become an important and urgent task. Most of the current evaluation metrics are adopted from the question answering (QA). However, the application of QA-based metrics is extremely time-consuming in practice, causing the iteration cycle of abstractive summarization research to be severely prolonged. In this paper, we propose a new method called ClozE to evaluate factual consistency by cloze model, instantiated based on masked language model(MLM), with strong interpretability and substantially higher speed. We demonstrate that ClozE can reduce the evaluation time by nearly 96$\%$ relative to QA-based metrics while retaining their interpretability and performance through experiments on six human-annotated datasets and a meta-evaluation benchmark GO FIGURE \citep{gabriel2020go}. We also implement experiments to further demonstrate more characteristics of ClozE in terms of performance and speed. In addition, we conduct an experimental analysis of the limitations of ClozE, which suggests future research directions. The code and models for ClozE will be released upon the paper acceptance.
HetSyn: Speeding Up Local SGD with Heterogeneous Synchronization
Oct 06, 2022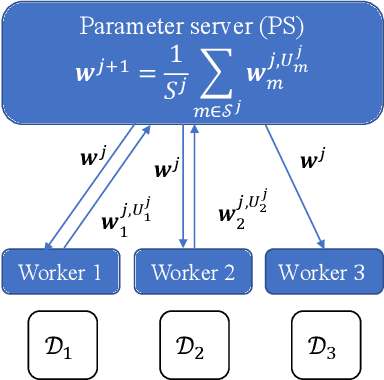
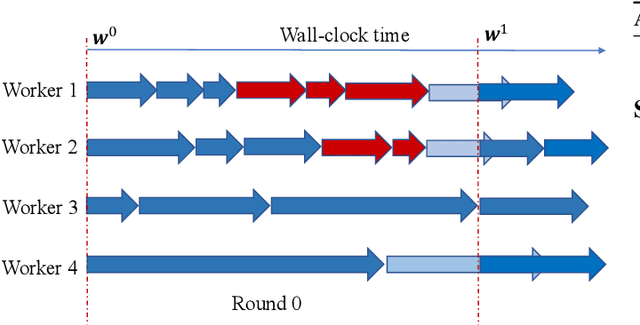
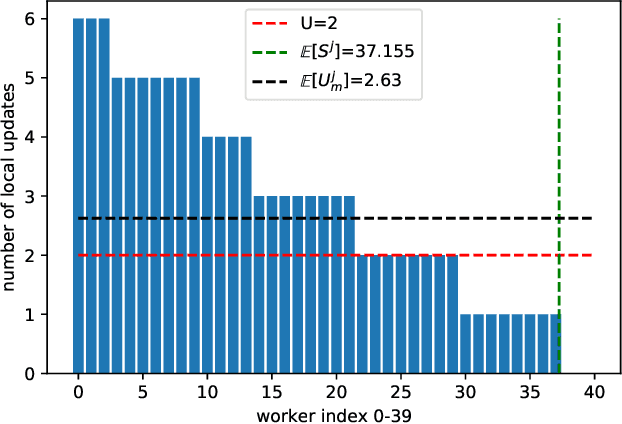
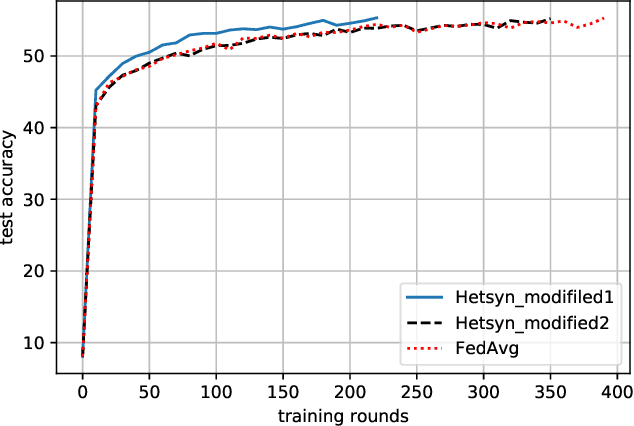
Synchronous local stochastic gradient descent (local SGD) suffers from some workers being idle and random delays due to slow and straggling workers, as it waits for the workers to complete the same amount of local updates. In this paper, to mitigate stragglers and improve communication efficiency, a novel local SGD strategy, named HetSyn, is developed. The key point is to keep all the workers computing continually at each synchronization round, and make full use of any effective (completed) local update of each worker regardless of stragglers. An analysis of the average wall-clock time, average number of local updates and average number of uploading workers per round is provided to gauge the performance of HetSyn. The convergence of HetSyn is also rigorously established even when the objective function is nonconvex. Experimental results show the superiority of the proposed HetSyn against state-of-the-art schemes through utilization of additional effective local updates at each worker, and the influence of system parameters is studied. By allowing heterogeneous synchronization with different numbers of local updates across workers, HetSyn provides substantial improvements both in time and communication efficiency.
Geodesic Graph Neural Network for Efficient Graph Representation Learning
Oct 06, 2022
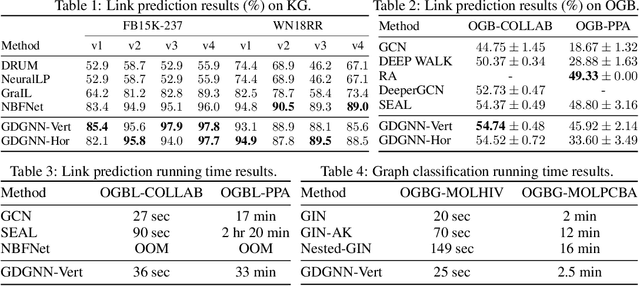
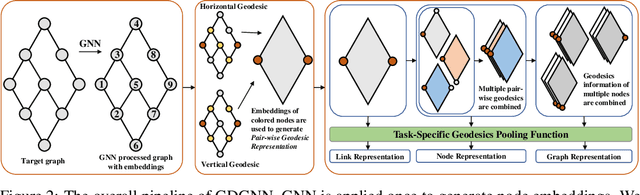
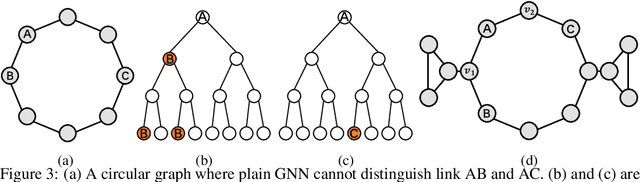
Recently, Graph Neural Networks (GNNs) have been applied to graph learning tasks and achieved state-of-the-art results. However, many competitive methods employ preprocessing on the target nodes, such as subgraph extraction and customized labeling, to capture some information that is hard to be learned by normal GNNs. Such operations are time-consuming and do not scale to large graphs. In this paper, we propose an efficient GNN framework called Geodesic GNN (GDGNN). It injects conditional relationships between nodes into the model without labeling. Specifically, we view the shortest paths between two nodes as the spatial graph context of the neighborhood around them. The GNN embeddings of nodes on the shortest paths are used to generate geodesic representations. Conditioned on the geodesic representations, GDGNN is able to generate node, link, and graph representations that carry much richer structural information than plain GNNs. We theoretically prove that GDGNN is more powerful than plain GNNs, and present experimental results to show that GDGNN achieves highly competitive performance with state-of-the-art GNN models on link prediction and graph classification tasks while taking significantly less time.
Lyapunov Function Consistent Adaptive Network Signal Control with Back Pressure and Reinforcement Learning
Oct 06, 2022
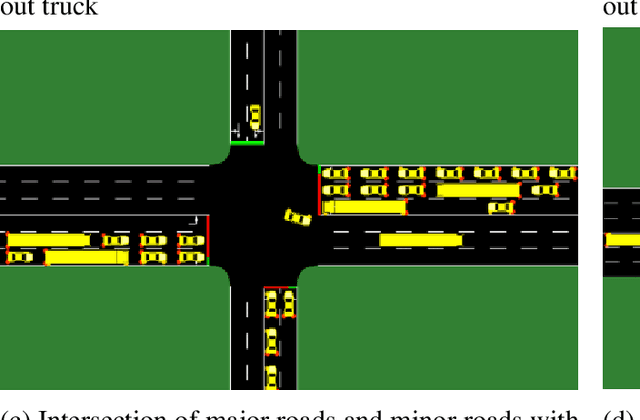

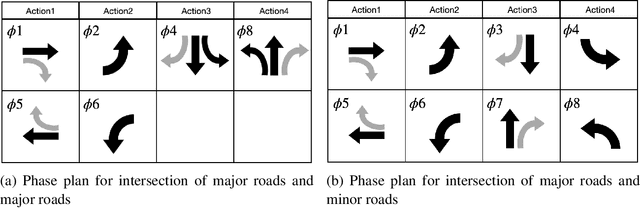
This research studies the network traffic signal control problem. It uses the Lyapunov control function to derive the back pressure method, which is equal to differential queue lengths weighted by intersection lane flows. Lyapunov control theory is a platform that unifies several current theories for intersection signal control. We further use the theorem to derive the flow-based and other pressure-based signal control algorithms. For example, the Dynamic, Optimal, Real-time Algorithm for Signals (DORAS) algorithm may be derived by defining the Lyapunov function as the sum of queue length. The study then utilizes the back pressure as a reward in the reinforcement learning (RL) based network signal control, whose agent is trained with double Deep Q-Network (Double-DQN). The proposed algorithm is compared with several traditional and RL-based methods under passenger traffic flow and mixed flow with freight traffic, respectively. The numerical tests are conducted on a single corridor and on a local grid network under three traffic demand scenarios of low, medium, and heavy traffic, respectively. The numerical simulation demonstrates that the proposed algorithm outperforms the others in terms of the average vehicle waiting time on the network.
A Data Cube of Big Satellite Image Time-Series for Agriculture Monitoring
May 16, 2022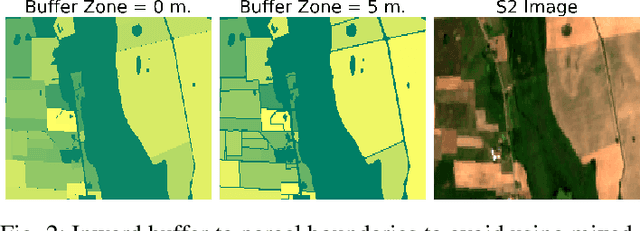

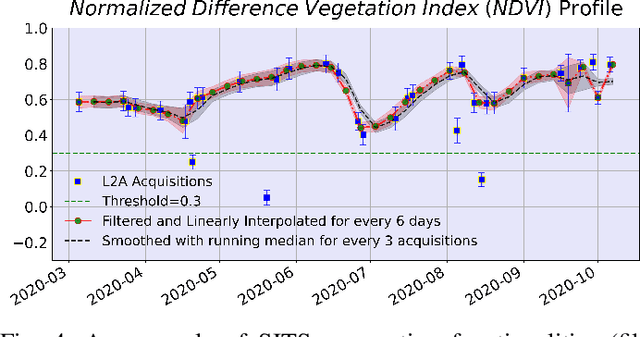
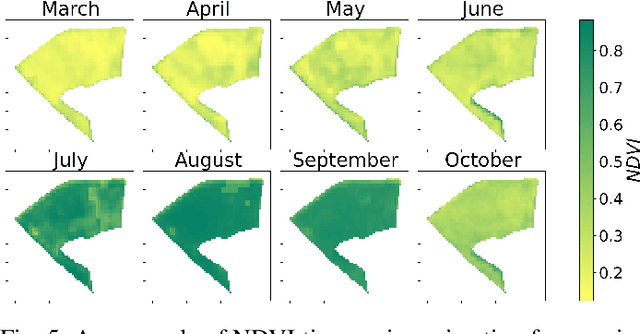
The modernization of the Common Agricultural Policy (CAP) requires the large scale and frequent monitoring of agricultural land. Towards this direction, the free and open satellite data (i.e., Sentinel missions) have been extensively used as the sources for the required high spatial and temporal resolution Earth observations. Nevertheless, monitoring the CAP at large scales constitutes a big data problem and puts a strain on CAP paying agencies that need to adapt fast in terms of infrastructure and know-how. Hence, there is a need for efficient and easy-to-use tools for the acquisition, storage, processing and exploitation of big satellite data. In this work, we present the Agriculture monitoring Data Cube (ADC), which is an automated, modular, end-to-end framework for discovering, pre-processing and indexing optical and Synthetic Aperture Radar (SAR) images into a multidimensional cube. We also offer a set of powerful tools on top of the ADC, including i) the generation of analysis-ready feature spaces of big satellite data to feed downstream machine learning tasks and ii) the support of Satellite Image Time-Series (SITS) analysis via services pertinent to the monitoring of the CAP (e.g., detecting trends and events, monitoring the growth status etc.). The knowledge extracted from the SITS analyses and the machine learning tasks returns to the data cube, building scalable country-specific knowledge bases that can efficiently answer complex and multi-faceted geospatial queries.
Differentially Private Online-to-Batch for Smooth Losses
Oct 12, 2022We develop a new reduction that converts any online convex optimization algorithm suffering $O(\sqrt{T})$ regret into an $\epsilon$-differentially private stochastic convex optimization algorithm with the optimal convergence rate $\tilde O(1/\sqrt{T} + \sqrt{d}/\epsilon T)$ on smooth losses in linear time, forming a direct analogy to the classical non-private "online-to-batch" conversion. By applying our techniques to more advanced adaptive online algorithms, we produce adaptive differentially private counterparts whose convergence rates depend on apriori unknown variances or parameter norms.
HoechstGAN: Virtual Lymphocyte Staining Using Generative Adversarial Networks
Oct 17, 2022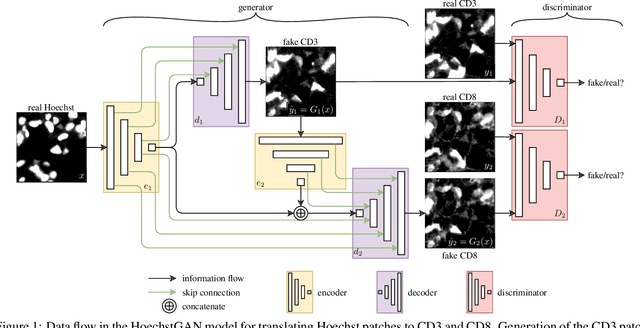


The presence and density of specific types of immune cells are important to understand a patient's immune response to cancer. However, immunofluorescence staining required to identify T cell subtypes is expensive, time-consuming, and rarely performed in clinical settings. We present a framework to virtually stain Hoechst images (which are cheap and widespread) with both CD3 and CD8 to identify T cell subtypes in clear cell renal cell carcinoma using generative adversarial networks. Our proposed method jointly learns both staining tasks, incentivising the network to incorporate mutually beneficial information from each task. We devise a novel metric to quantify the virtual staining quality, and use it to evaluate our method.
On the Achievable SINR in MU-MIMO Systems Operating in Time-Varying Rayleigh Fading
Mar 24, 2022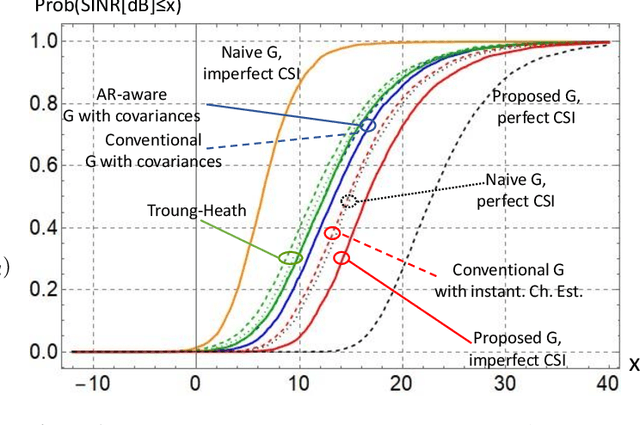
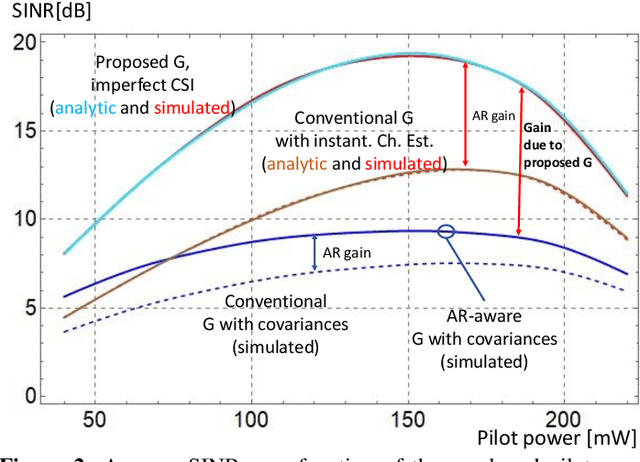
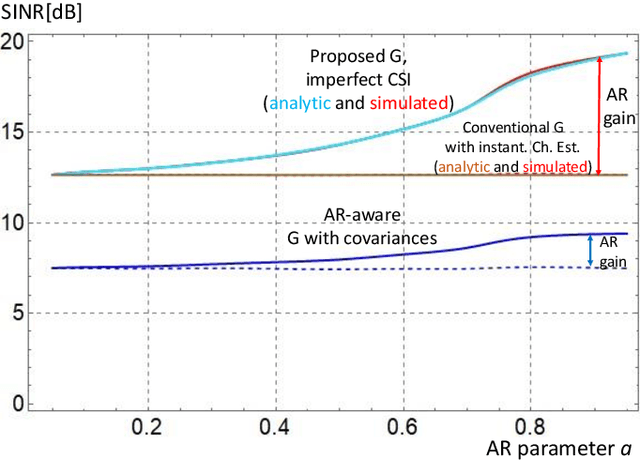
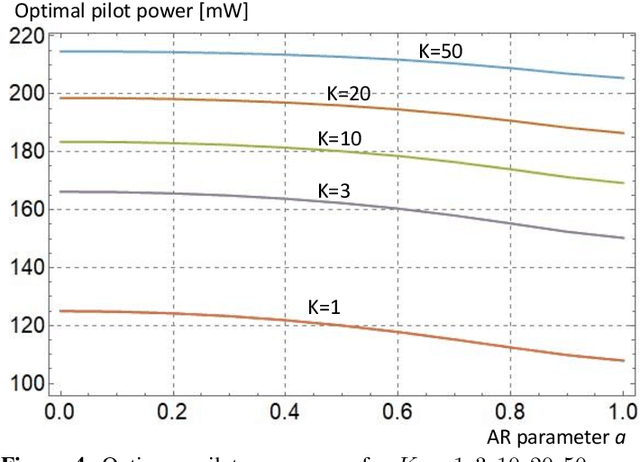
Minimizing the symbol error in the uplink of multi-user multiple input multiple output systems is important, because the symbol error affects the achieved signal-to-interference-plus-noise ratio (SINR) and thereby the spectral efficiency of the system. Despite the vast literature available on minimum mean squared error (MMSE) receivers, previously proposed receivers for block fading channels do not minimize the symbol error in time-varying Rayleigh fading channels. Specifically, we show that the true MMSE receiver structure does not only depend on the statistics of the CSI error, but also on the autocorrelation coefficient of the time-variant channel. It turns out that calculating the average SINR when using the proposed receiver is highly non-trivial. In this paper, we employ a random matrix theoretical approach, which allows us to derive a quasi-closed form for the average SINR, which allows to obtain analytical exact results that give valuable insights into how the SINR depends on the number of antennas, employed pilot and data power and the covariance of the time-varying channel. We benchmark the performance of the proposed receiver against recently proposed receivers and find that the proposed MMSE receiver achieves higher SINR than the previously proposed ones, and this benefit increases with increasing autoregressive coefficient.
* 15 pages, 9 figures, 4 tables
An Algebraic Framework for Stock & Flow Diagrams and Dynamical Systems Using Category Theory
Nov 01, 2022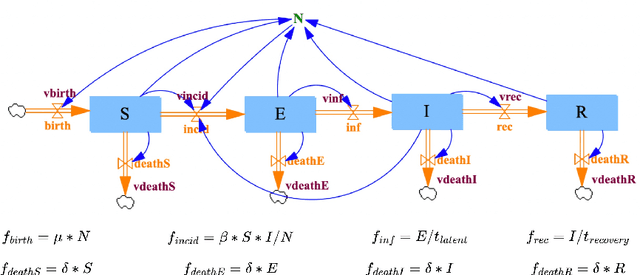
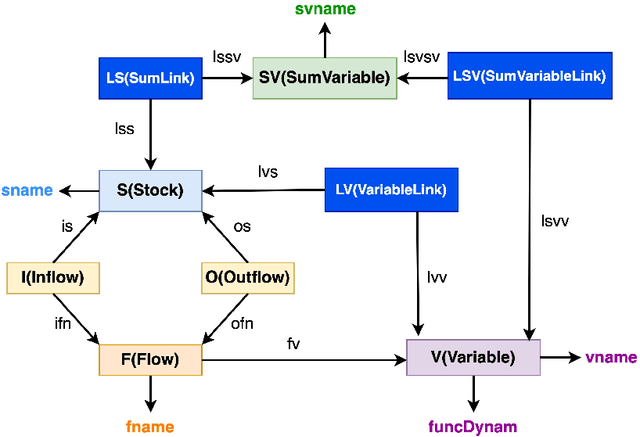
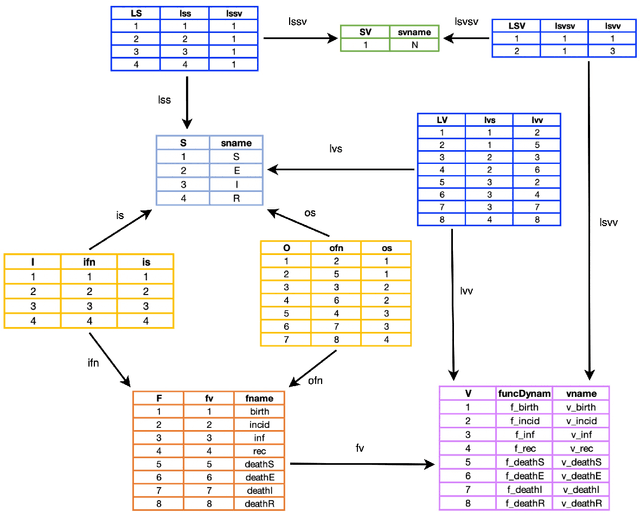
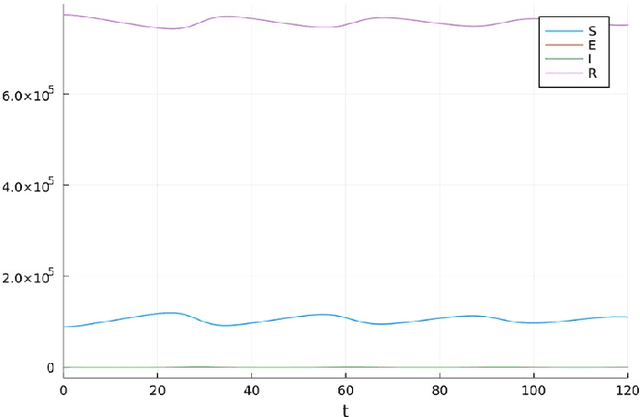
Mathematical modeling of infectious disease at scale is important, but challenging. Some of these difficulties can be alleviated by an approach that takes diagrams seriously as mathematical formalisms in their own right. Stock & flow diagrams are widely used as broadly accessible building blocks for infectious disease modeling. In this chapter, rather than focusing on the underlying mathematics, we informally use communicable disease examples created by the implemented software of StockFlow.jl to explain the basics, characteristics, and benefits of the categorical framework. We first characterize categorical stock & flow diagrams, and note the clear separation between the syntax of stock & flow diagrams and their semantics, demonstrating three examples of semantics already implemented in the software: ODEs, causal loop diagrams, and system structure diagrams. We then establish composition and stratification frameworks and examples for stock & flow diagrams. Applying category theory, these frameworks can build large diagrams from smaller ones in a modular fashion. Finally, we introduce the open-source ModelCollab software for diagram-centric real-time collaborative modeling. Using the graphical user interface, this web-based software allows the user to undertake the types of categorically-rooted operations discussed above, but without any knowledge of their categorical foundations.