 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robotic Assembly Control Reconfiguration Based on Transfer Reinforcement Learning for Objects with Different Geometric Features
Nov 04, 2022
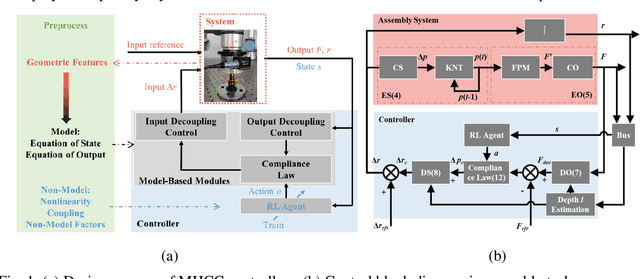
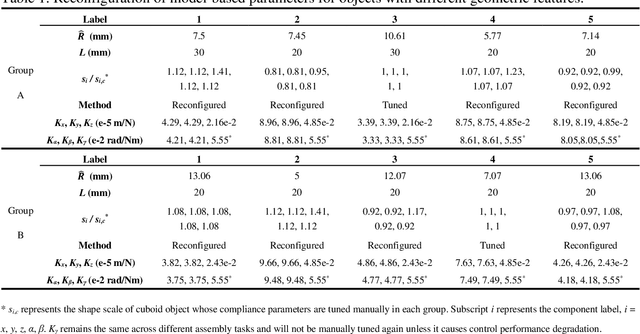
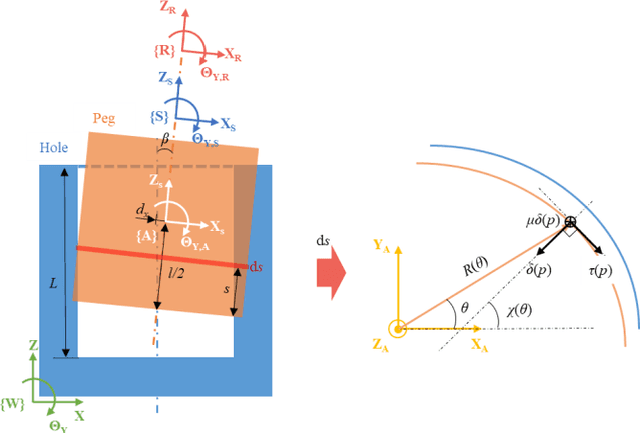
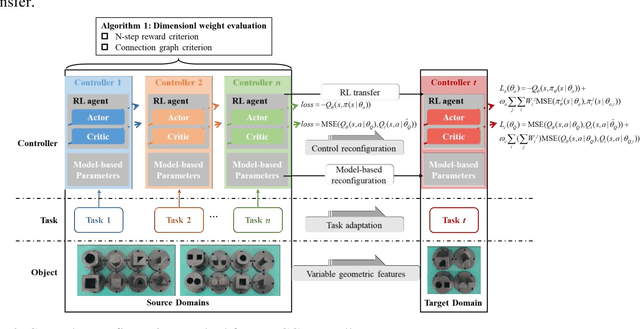
Robotic force-based compliance control is a preferred approach to achieve high-precision assembly tasks. When the geometric features of assembly objects are asymmetric or irregular, reinforcement learning (RL) agents are gradually incorporated into the compliance controller to adapt to complex force-pose mapping which is hard to model analytically. Since force-pose mapping is strongly dependent on geometric features, a compliance controller is only optimal for current geometric features. To reduce the learning cost of assembly objects with different geometric features, this paper is devoted to answering how to reconfigure existing controllers for new assembly objects with different geometric features. In this paper, model-based parameters are first reconfigured based on the proposed Equivalent Theory of Compliance Law (ETCL). Then the RL agent is transferred based on the proposed Weighted Dimensional Policy Distillation (WDPD) method. The experiment results demonstrate that the control reconfiguration method costs less time and achieves better control performance, which confirms the validity of proposed methods.
Sampling Rate Offset Estimation and Compensation for Distributed Adaptive Node-Specific Signal Estimation in Wireless Acoustic Sensor Networks
Nov 04, 2022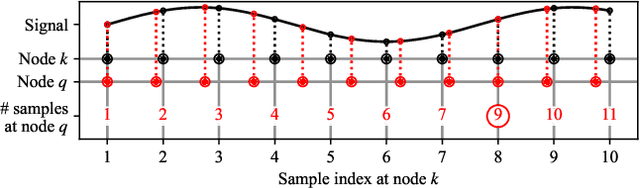
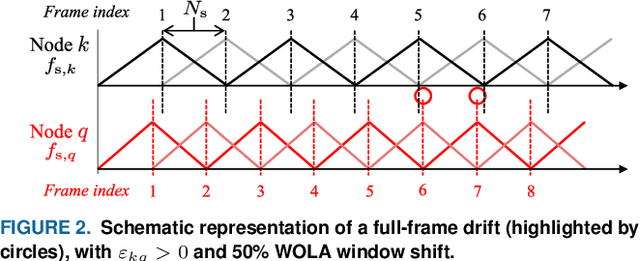
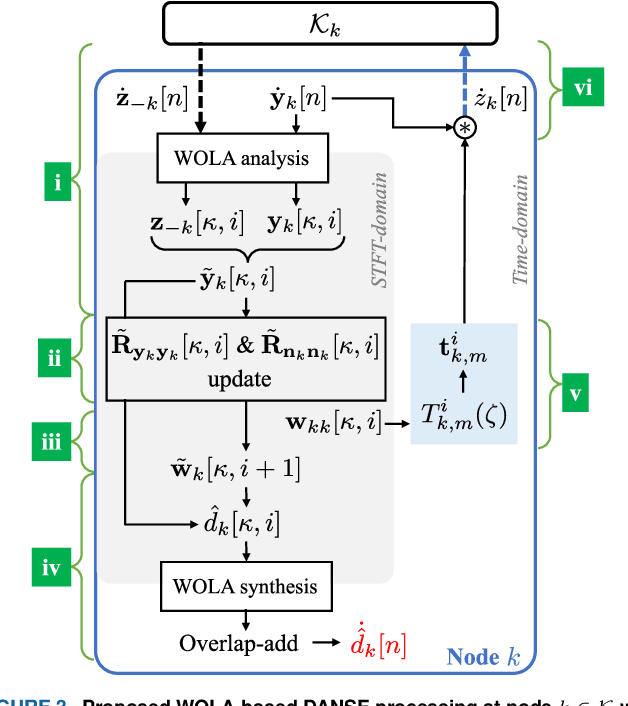
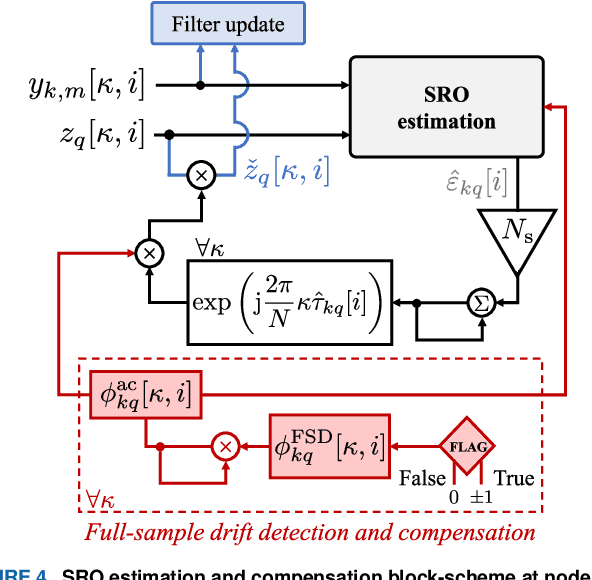
Sampling rate offsets (SROs) between devices in a heterogeneous wireless acoustic sensor network (WASN) can hinder the ability of distributed adaptive algorithms to perform as intended when they rely on coherent signal processing. In this paper, we present an SRO estimation and compensation method to allow the deployment of the distributed adaptive node-specific signal estimation (DANSE) algorithm in WASNs composed of asynchronous devices. The signals available at each node are first utilised in a coherence-drift-based method to blindly estimate SROs which are then compensated for via phase shifts in the frequency domain. A modification of the weighted overlap-add (WOLA) implementation of DANSE is introduced to account for SRO-induced full-sample drifts, permitting per-sample signal transmission via an approximation of the WOLA process as a time-domain convolution. The performance of the proposed algorithm is evaluated in the context of distributed noise reduction for the estimation of a target speech signal in an asynchronous WASN.
$D^2$SLAM: Decentralized and Distributed Collaborative Visual-inertial SLAM System for Aerial Swarm
Nov 04, 2022

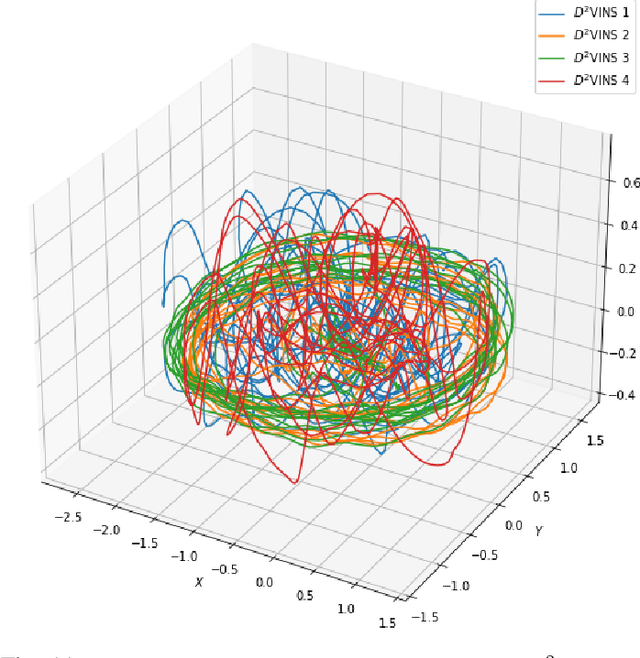
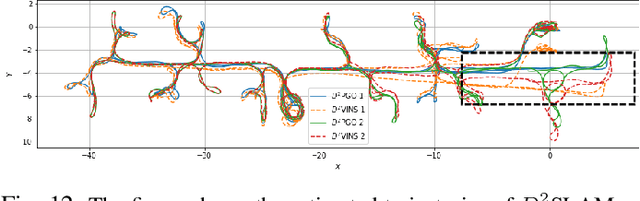
In recent years, aerial swarm technology has developed rapidly. In order to accomplish a fully autonomous aerial swarm, a key technology is decentralized and distributed collaborative SLAM (CSLAM) for aerial swarms, which estimates the relative pose and the consistent global trajectories. In this paper, we propose $D^2$SLAM: a decentralized and distributed ($D^2$) collaborative SLAM algorithm. This algorithm has high local accuracy and global consistency, and the distributed architecture allows it to scale up. $D^2$SLAM covers swarm state estimation in two scenarios: near-field state estimation for high real-time accuracy at close range and far-field state estimation for globally consistent trajectories estimation at the long-range between UAVs. Distributed optimization algorithms are adopted as the backend to achieve the $D^2$ goal. $D^2$SLAM is robust to transient loss of communication, network delays, and other factors. Thanks to the flexible architecture, $D^2$SLAM has the potential of applying in various scenarios.
Interpretable estimation of the risk of heart failure hospitalization from a 30-second electrocardiogram
Nov 04, 2022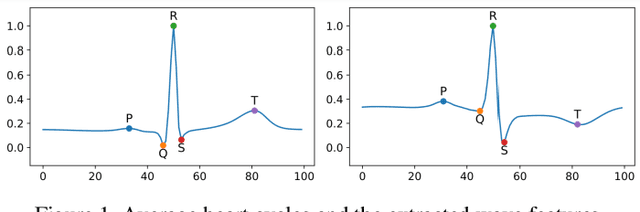
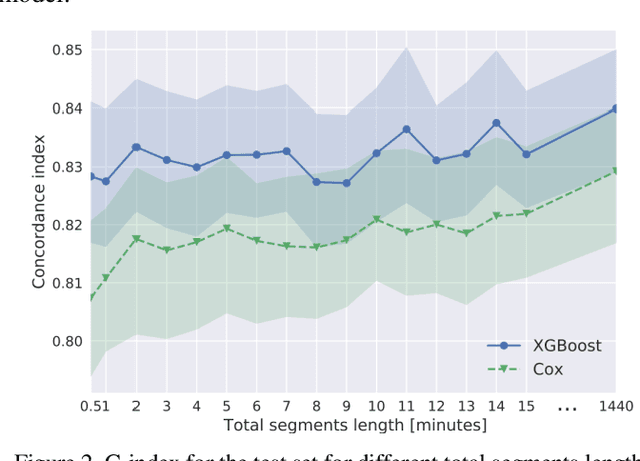
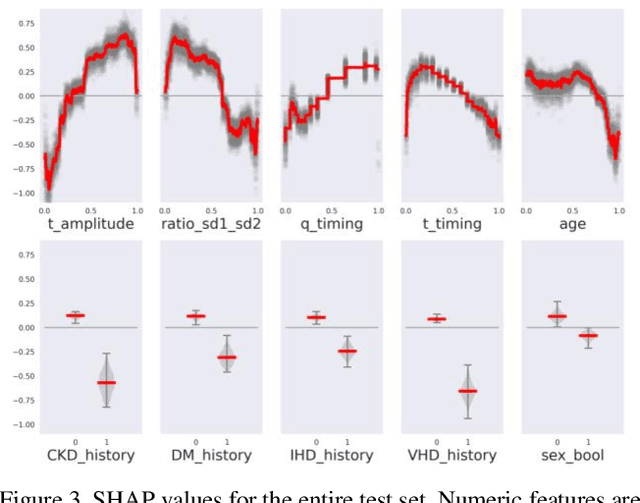
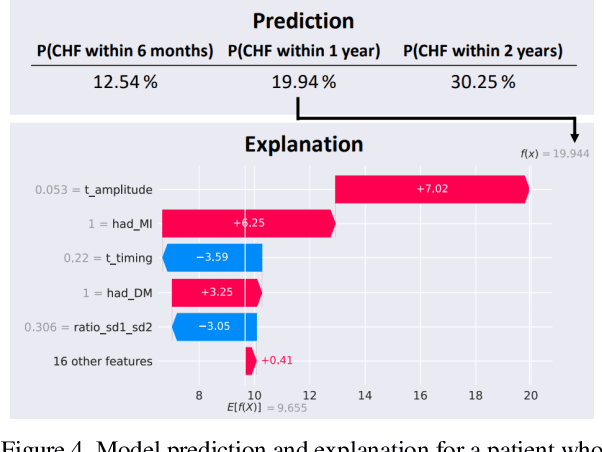
Survival modeling in healthcare relies on explainable statistical models; yet, their underlying assumptions are often simplistic and, thus, unrealistic. Machine learning models can estimate more complex relationships and lead to more accurate predictions, but are non-interpretable. This study shows it is possible to estimate hospitalization for congestive heart failure by a 30 seconds single-lead electrocardiogram signal. Using a machine learning approach not only results in greater predictive power but also provides clinically meaningful interpretations. We train an eXtreme Gradient Boosting accelerated failure time model and exploit SHapley Additive exPlanations values to explain the effect of each feature on predictions. Our model achieved a concordance index of 0.828 and an area under the curve of 0.853 at one year and 0.858 at two years on a held-out test set of 6,573 patients. These results show that a rapid test based on an electrocardiogram could be crucial in targeting and treating high-risk individuals.
Self-Supervised Learning for Speech Enhancement through Synthesis
Nov 04, 2022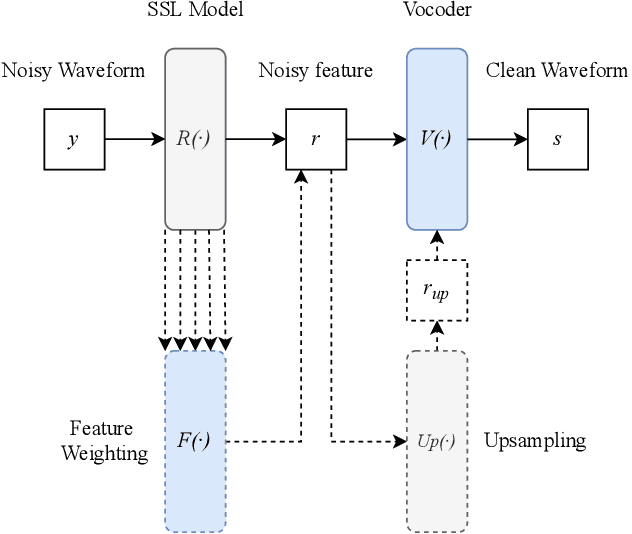
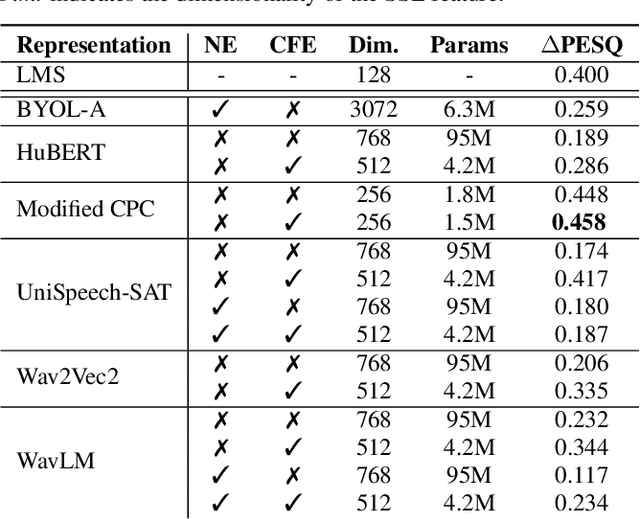
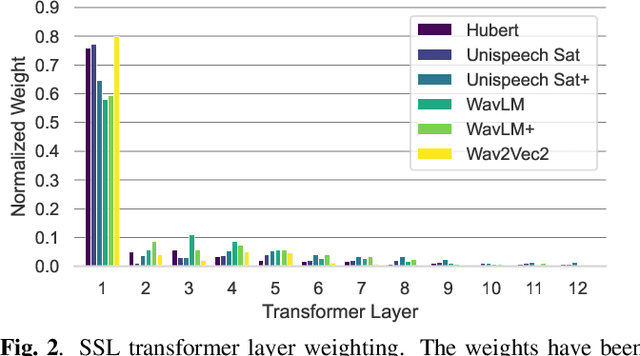
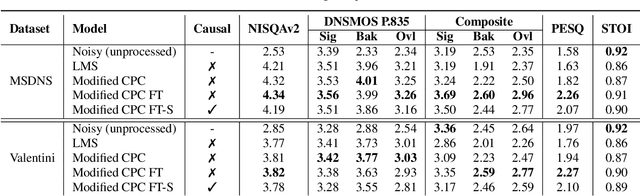
Modern speech enhancement (SE) networks typically implement noise suppression through time-frequency masking, latent representation masking, or discriminative signal prediction. In contrast, some recent works explore SE via generative speech synthesis, where the system's output is synthesized by a neural vocoder after an inherently lossy feature-denoising step. In this paper, we propose a denoising vocoder (DeVo) approach, where a vocoder accepts noisy representations and learns to directly synthesize clean speech. We leverage rich representations from self-supervised learning (SSL) speech models to discover relevant features. We conduct a candidate search across 15 potential SSL front-ends and subsequently train our vocoder adversarially with the best SSL configuration. Additionally, we demonstrate a causal version capable of running on streaming audio with 10ms latency and minimal performance degradation. Finally, we conduct both objective evaluations and subjective listening studies to show our system improves objective metrics and outperforms an existing state-of-the-art SE model subjectively.
Elimination of Non-Novel Segments at Multi-Scale for Few-Shot Segmentation
Nov 04, 2022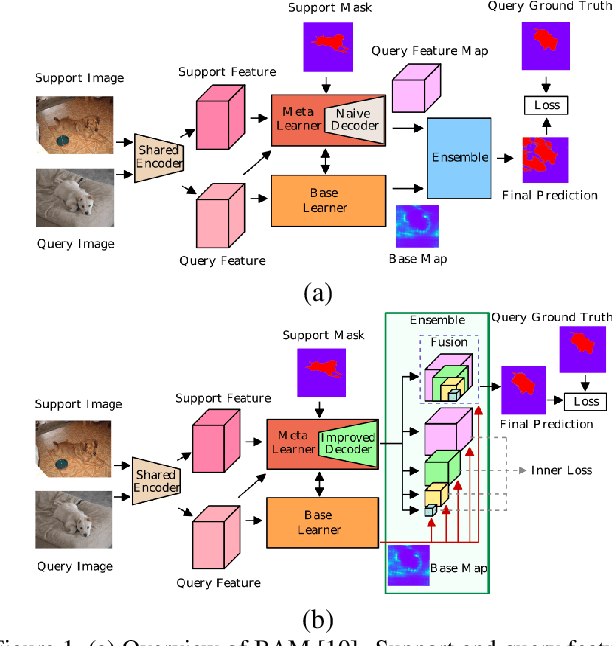
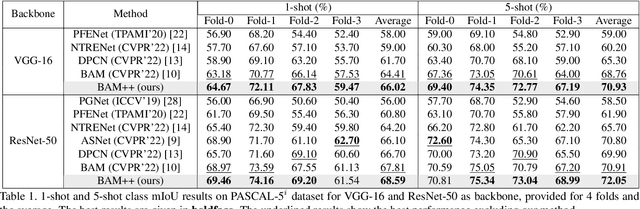
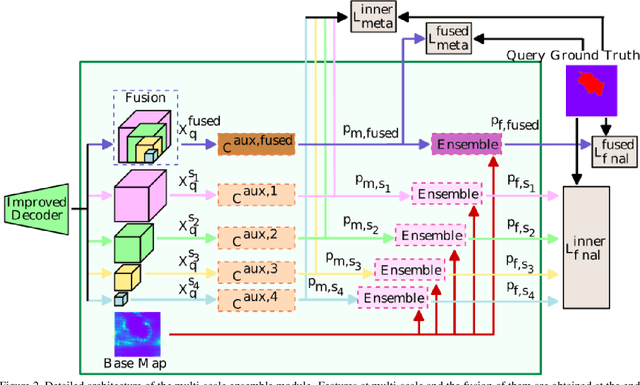

Few-shot segmentation aims to devise a generalizing model that segments query images from unseen classes during training with the guidance of a few support images whose class tally with the class of the query. There exist two domain-specific problems mentioned in the previous works, namely spatial inconsistency and bias towards seen classes. Taking the former problem into account, our method compares the support feature map with the query feature map at multi scales to become scale-agnostic. As a solution to the latter problem, a supervised model, called as base learner, is trained on available classes to accurately identify pixels belonging to seen classes. Hence, subsequent meta learner has a chance to discard areas belonging to seen classes with the help of an ensemble learning model that coordinates meta learner with the base learner. We simultaneously address these two vital problems for the first time and achieve state-of-the-art performances on both PASCAL-5i and COCO-20i datasets.
Few-shot Generation of Personalized Neural Surrogates for Cardiac Simulation via Bayesian Meta-Learning
Oct 06, 2022Clinical adoption of personalized virtual heart simulations faces challenges in model personalization and expensive computation. While an ideal solution is an efficient neural surrogate that at the same time is personalized to an individual subject, the state-of-the-art is either concerned with personalizing an expensive simulation model, or learning an efficient yet generic surrogate. This paper presents a completely new concept to achieve personalized neural surrogates in a single coherent framework of meta-learning (metaPNS). Instead of learning a single neural surrogate, we pursue the process of learning a personalized neural surrogate using a small amount of context data from a subject, in a novel formulation of few-shot generative modeling underpinned by: 1) a set-conditioned neural surrogate for cardiac simulation that, conditioned on subject-specific context data, learns to generate query simulations not included in the context set, and 2) a meta-model of amortized variational inference that learns to condition the neural surrogate via simple feed-forward embedding of context data. As test time, metaPNS delivers a personalized neural surrogate by fast feed-forward embedding of a small and flexible number of data available from an individual, achieving -- for the first time -- personalization and surrogate construction for expensive simulations in one end-to-end learning framework. Synthetic and real-data experiments demonstrated that metaPNS was able to improve personalization and predictive accuracy in comparison to conventionally-optimized cardiac simulation models, at a fraction of computation.
Online model error correction with neural networks in the incremental 4D-Var framework
Oct 25, 2022
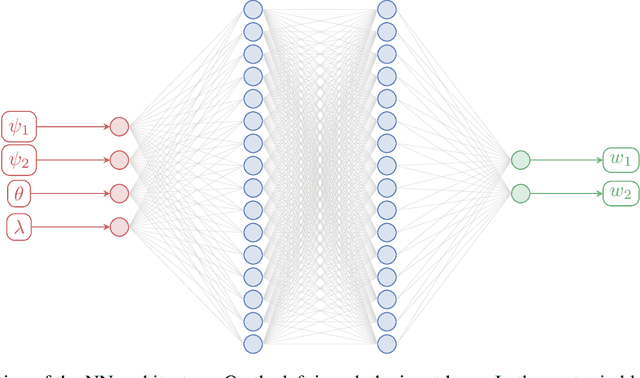
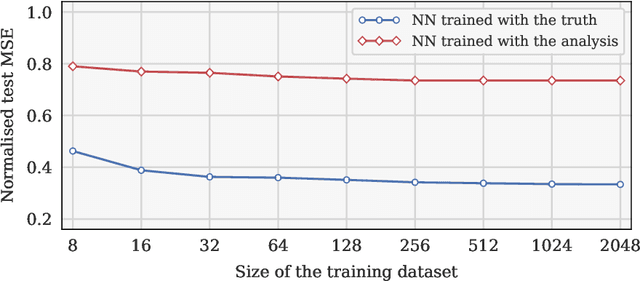

Recent studies have demonstrated that it is possible to combine machine learning with data assimilation to reconstruct the dynamics of a physical model partially and imperfectly observed. Data assimilation is used to estimate the system state from the observations, while machine learning computes a surrogate model of the dynamical system based on those estimated states. The surrogate model can be defined as an hybrid combination where a physical model based on prior knowledge is enhanced with a statistical model estimated by a neural network. The training of the neural network is typically done offline, once a large enough dataset of model state estimates is available. By contrast, with online approaches the surrogate model is improved each time a new system state estimate is computed. Online approaches naturally fit the sequential framework encountered in geosciences where new observations become available with time. In a recent methodology paper, we have developed a new weak-constraint 4D-Var formulation which can be used to train a neural network for online model error correction. In the present article, we develop a simplified version of that method, in the incremental 4D-Var framework adopted by most operational weather centres. The simplified method is implemented in the ECMWF Object-Oriented Prediction System, with the help of a newly developed Fortran neural network library, and tested with a two-layer two-dimensional quasi geostrophic model. The results confirm that online learning is effective and yields a more accurate model error correction than offline learning. Finally, the simplified method is compatible with future applications to state-of-the-art models such as the ECMWF Integrated Forecasting System.
CoV-TI-Net: Transferred Initialization with Modified End Layer for COVID-19 Diagnosis
Sep 20, 2022
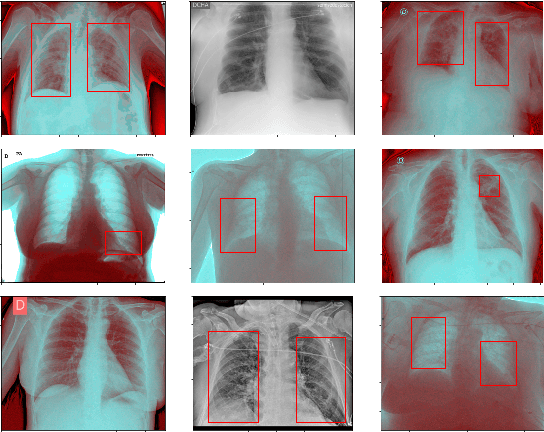
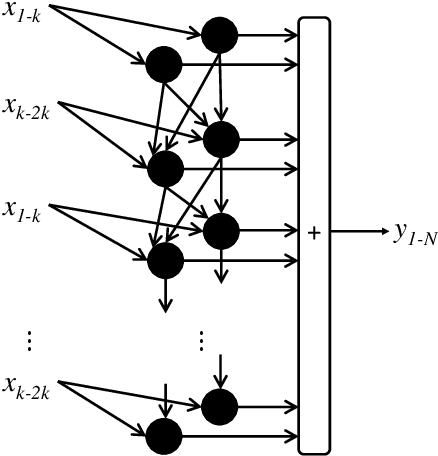
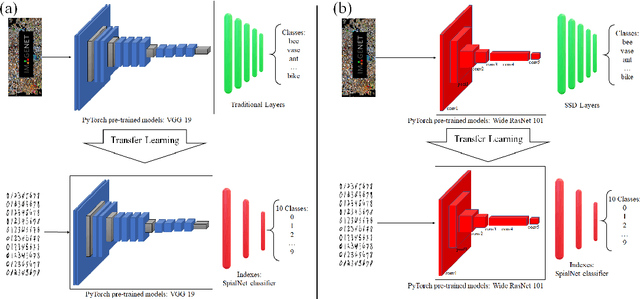
This paper proposes transferred initialization with modified fully connected layers for COVID-19 diagnosis. Convolutional neural networks (CNN) achieved a remarkable result in image classification. However, training a high-performing model is a very complicated and time-consuming process because of the complexity of image recognition applications. On the other hand, transfer learning is a relatively new learning method that has been employed in many sectors to achieve good performance with fewer computations. In this research, the PyTorch pre-trained models (VGG19\_bn and WideResNet -101) are applied in the MNIST dataset for the first time as initialization and with modified fully connected layers. The employed PyTorch pre-trained models were previously trained in ImageNet. The proposed model is developed and verified in the Kaggle notebook, and it reached the outstanding accuracy of 99.77% without taking a huge computational time during the training process of the network. We also applied the same methodology to the SIIM-FISABIO-RSNA COVID-19 Detection dataset and achieved 80.01% accuracy. In contrast, the previous methods need a huge compactional time during the training process to reach a high-performing model. Codes are available at the following link: github.com/dipuk0506/SpinalNet
Multivariate Wasserstein Functional Connectivity for Autism Screening
Sep 23, 2022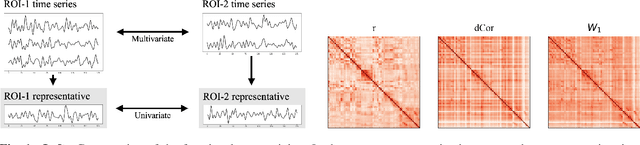
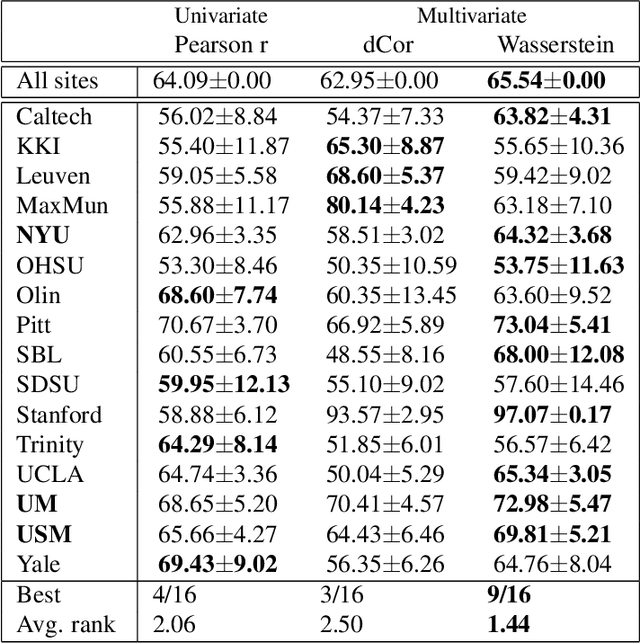
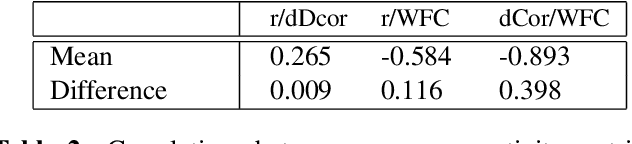
Most approaches to the estimation of brain functional connectivity from the functional magnetic resonance imaging (fMRI) data rely on computing some measure of statistical dependence, or more generally, a distance between univariate representative time series of regions of interest (ROIs) consisting of multiple voxels. However, summarizing a ROI's multiple time series with its mean or the first principal component (1PC) may result to the loss of information as, for example, 1PC explains only a small fraction of variance of the multivariate signal of the neuronal activity. We propose to compare ROIs directly, without the use of representative time series, defining a new measure of multivariate connectivity between ROIs, not necessarily consisting of the same number of voxels, based on the Wasserstein distance. We assess the proposed Wasserstein functional connectivity measure on the autism screening task, demonstrating its superiority over commonly used univariate and multivariate functional connectivity measures.