 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Gaussian Mean Testing Made Simple
Oct 25, 2022
We study the following fundamental hypothesis testing problem, which we term Gaussian mean testing. Given i.i.d. samples from a distribution $p$ on $\mathbb{R}^d$, the task is to distinguish, with high probability, between the following cases: (i) $p$ is the standard Gaussian distribution, $\mathcal{N}(0,I_d)$, and (ii) $p$ is a Gaussian $\mathcal{N}(\mu,\Sigma)$ for some unknown covariance $\Sigma$ and mean $\mu \in \mathbb{R}^d$ satisfying $\|\mu\|_2 \geq \epsilon$. Recent work gave an algorithm for this testing problem with the optimal sample complexity of $\Theta(\sqrt{d}/\epsilon^2)$. Both the previous algorithm and its analysis are quite complicated. Here we give an extremely simple algorithm for Gaussian mean testing with a one-page analysis. Our algorithm is sample optimal and runs in sample linear time.
An approach to the Gaussian RBF kernels via Fock spaces
Oct 25, 2022We use methods from the Fock space and Segal-Bargmann theories to prove several results on the Gaussian RBF kernel in complex analysis. The latter is one of the most used kernels in modern machine learning kernel methods, and in support vector machines (SVMs) classification algorithms. Complex analysis techniques allow us to consider several notions linked to the RBF kernels like the feature space and the feature map, using the so-called Segal-Bargmann transform. We show also how the RBF kernels can be related to some of the most used operators in quantum mechanics and time frequency analysis, specifically, we prove the connections of such kernels with creation, annihilation, Fourier, translation, modulation and Weyl operators. For the Weyl operators, we also study a semigroup property in this case.
Time Masking for Temporal Language Models
Oct 14, 2021

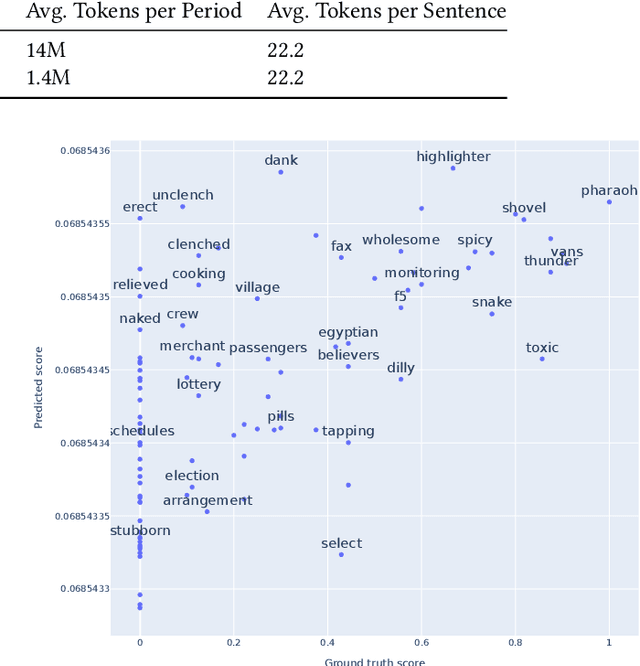
Our world is constantly evolving, and so is the content on the web. Consequently, our languages, often said to mirror the world, are dynamic in nature. However, most current contextual language models are static and cannot adapt to changes over time. In this work, we propose a temporal contextual language model called TempoBERT, which uses time as an additional context of texts. Our technique is based on modifying texts with temporal information and performing time masking - specific masking for the supplementary time information. We leverage our approach for the tasks of semantic change detection and sentence time prediction, experimenting on diverse datasets in terms of time, size, genre, and language. Our extensive evaluation shows that both tasks benefit from exploiting time masking.
Design Process is a Reinforcement Learning Problem
Nov 06, 2022

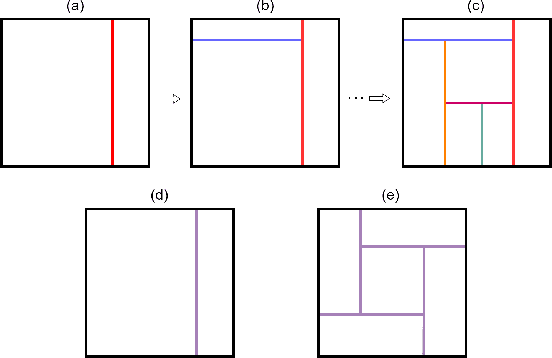
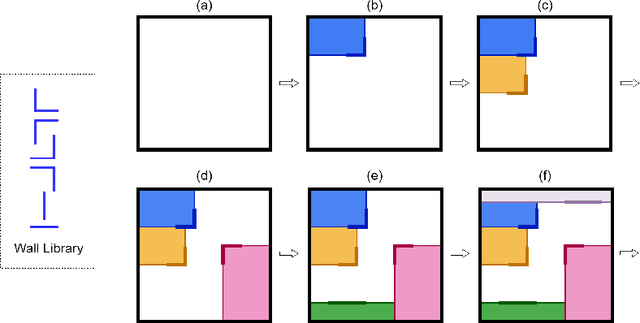
While reinforcement learning has been used widely in research during the past few years, it found fewer real-world applications than supervised learning due to some weaknesses that the RL algorithms suffer from, such as performance degradation in transitioning from the simulator to the real world. Here, we argue the design process is a reinforcement learning problem and can potentially be a proper application for RL algorithms as it is an offline process and conventionally is done in CAD software - a sort of simulator. This creates opportunities for using RL methods and, at the same time, raises challenges. While the design processes are so diverse, here we focus on the space layout planning (SLP), frame it as an RL problem under the Markov Decision Process, and use PPO to address the layout design problem. To do so, we developed an environment named RLDesigner, to simulate the SLP. The RLDesigner is an OpenAI Gym compatible environment that can be easily customized to define a diverse range of design scenarios. We publicly share the environment to encourage both RL and architecture communities to use it for testing different RL algorithms or in their design practice. The codes are available in the following GitHub repository https://github.com/ RezaKakooee/rldesigner/tree/Second_Paper
ProtoX: Explaining a Reinforcement Learning Agent via Prototyping
Nov 06, 2022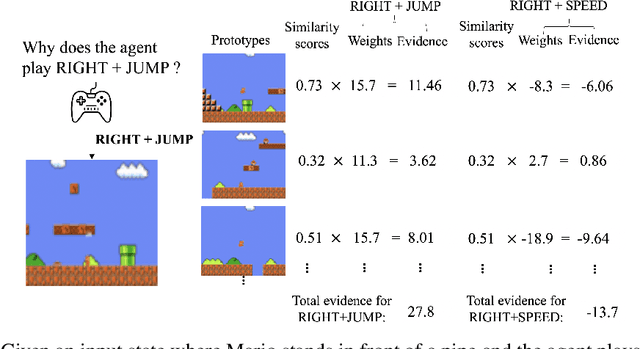
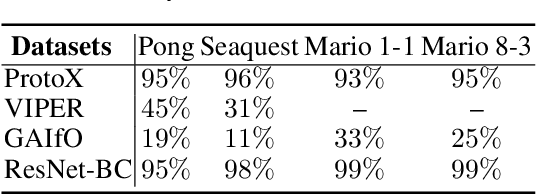
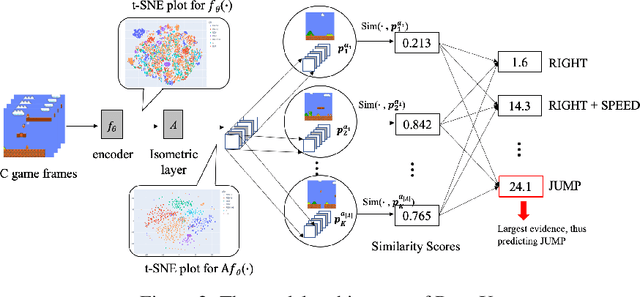

While deep reinforcement learning has proven to be successful in solving control tasks, the "black-box" nature of an agent has received increasing concerns. We propose a prototype-based post-hoc policy explainer, ProtoX, that explains a blackbox agent by prototyping the agent's behaviors into scenarios, each represented by a prototypical state. When learning prototypes, ProtoX considers both visual similarity and scenario similarity. The latter is unique to the reinforcement learning context, since it explains why the same action is taken in visually different states. To teach ProtoX about visual similarity, we pre-train an encoder using contrastive learning via self-supervised learning to recognize states as similar if they occur close together in time and receive the same action from the black-box agent. We then add an isometry layer to allow ProtoX to adapt scenario similarity to the downstream task. ProtoX is trained via imitation learning using behavior cloning, and thus requires no access to the environment or agent. In addition to explanation fidelity, we design different prototype shaping terms in the objective function to encourage better interpretability. We conduct various experiments to test ProtoX. Results show that ProtoX achieved high fidelity to the original black-box agent while providing meaningful and understandable explanations.
Evaluating Digital Tools for Sustainable Agriculture using Causal Inference
Nov 06, 2022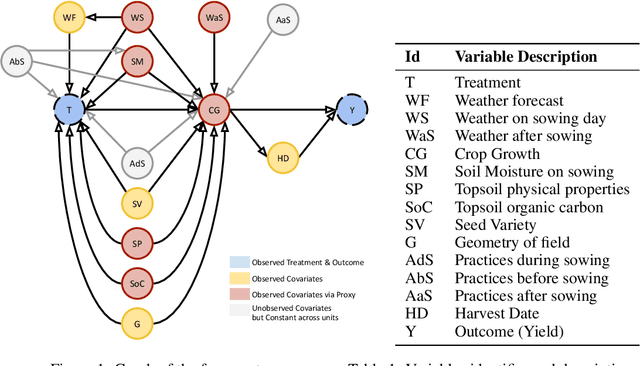
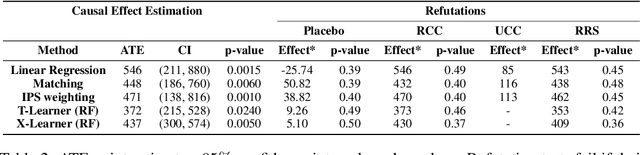

In contrast to the rapid digitalization of several industries, agriculture suffers from low adoption of climate-smart farming tools. Even though AI-driven digital agriculture can offer high-performing predictive functionalities, it lacks tangible quantitative evidence on its benefits to the farmers. Field experiments can derive such evidence, but are often costly and time consuming. To this end, we propose an observational causal inference framework for the empirical evaluation of the impact of digital tools on target farm performance indicators. This way, we can increase farmers' trust by enhancing the transparency of the digital agriculture market, and in turn accelerate the adoption of technologies that aim to increase productivity and secure a sustainable and resilient agriculture against a changing climate. As a case study, we perform an empirical evaluation of a recommendation system for optimal cotton sowing, which was used by a farmers' cooperative during the growing season of 2021. We leverage agricultural knowledge to develop a causal graph of the farm system, we use the back-door criterion to identify the impact of recommendations on the yield and subsequently estimate it using several methods on observational data. The results show that a field sown according to our recommendations enjoyed a significant increase in yield (12% to 17%).
AU-Aware Vision Transformers for Biased Facial Expression Recognition
Nov 12, 2022
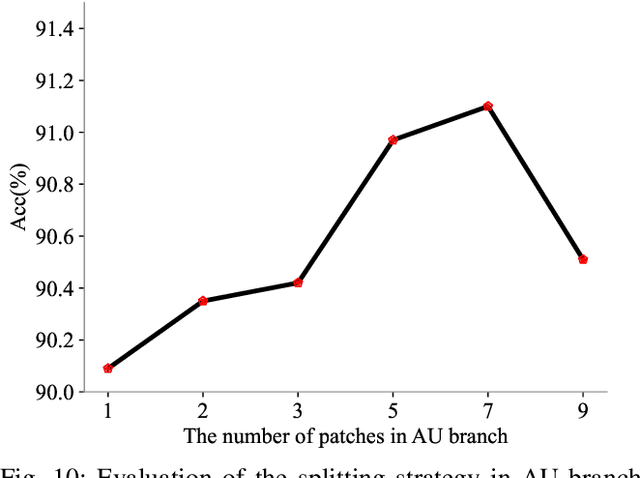

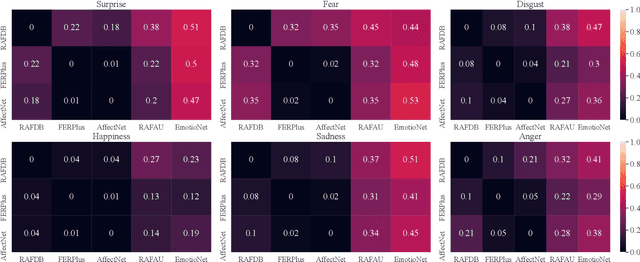
Studies have proven that domain bias and label bias exist in different Facial Expression Recognition (FER) datasets, making it hard to improve the performance of a specific dataset by adding other datasets. For the FER bias issue, recent researches mainly focus on the cross-domain issue with advanced domain adaption algorithms. This paper addresses another problem: how to boost FER performance by leveraging cross-domain datasets. Unlike the coarse and biased expression label, the facial Action Unit (AU) is fine-grained and objective suggested by psychological studies. Motivated by this, we resort to the AU information of different FER datasets for performance boosting and make contributions as follows. First, we experimentally show that the naive joint training of multiple FER datasets is harmful to the FER performance of individual datasets. We further introduce expression-specific mean images and AU cosine distances to measure FER dataset bias. This novel measurement shows consistent conclusions with experimental degradation of joint training. Second, we propose a simple yet conceptually-new framework, AU-aware Vision Transformer (AU-ViT). It improves the performance of individual datasets by jointly training auxiliary datasets with AU or pseudo-AU labels. We also find that the AU-ViT is robust to real-world occlusions. Moreover, for the first time, we prove that a carefully-initialized ViT achieves comparable performance to advanced deep convolutional networks. Our AU-ViT achieves state-of-the-art performance on three popular datasets, namely 91.10% on RAF-DB, 65.59% on AffectNet, and 90.15% on FERPlus. The code and models will be released soon.
On Estimating the Autoregressive Coefficients of Time-Varying Fading Channels
Mar 31, 2022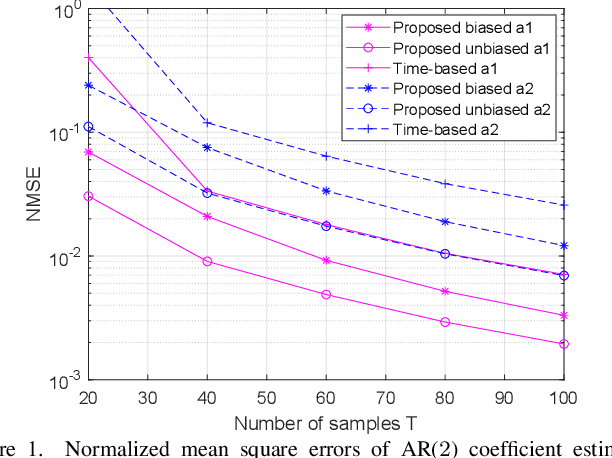
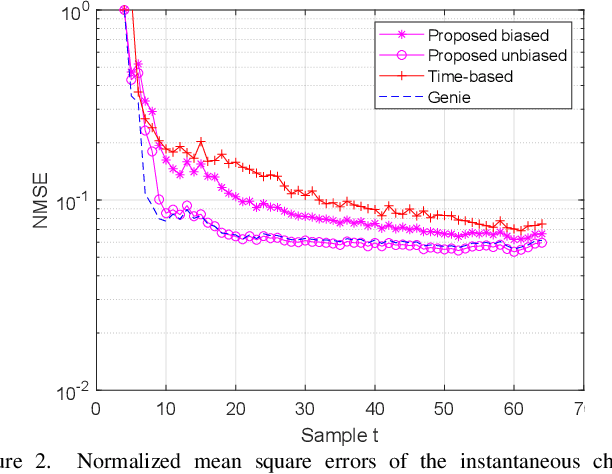
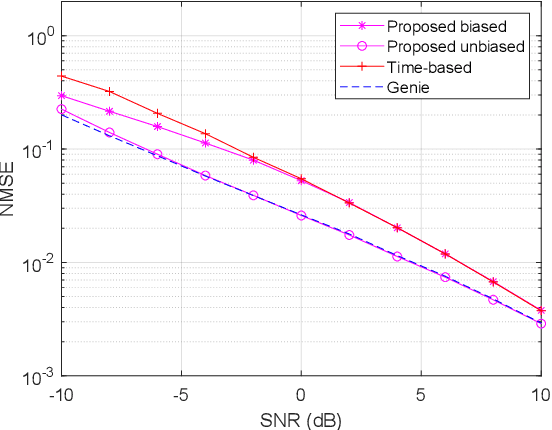
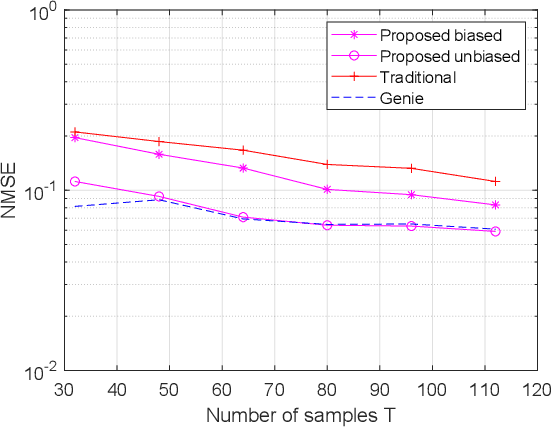
As several previous works have pointed out, the evolution of the wireless channels in multiple input multiple output systems can be advantageously modeled as an autoregressive process. Therefore, estimating the coefficients, and, in particular, the state transition matrix of this autoregressive process is a key to accurate channel estimation, tracking, and prediction in fast fading environments. In this paper we assume a time varying spatially uncorrelated channel, which is approximately the case with proper antenna spacing at the base station in rich scattering environments. We propose a method for autoregressive parameter estimation for the single input multiple output (SIMO) channel. We show an almost sure convergence of the estimated coefficients to the true autoregressive coefficients in large dimensions. We apply the proposed method to SIMO channel tracking.
* 5 pages 4 figures, 18 references
A Greek Parliament Proceedings Dataset for Computational Linguistics and Political Analysis
Oct 23, 2022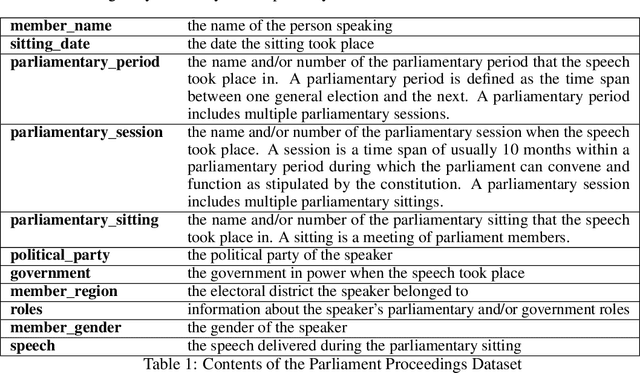
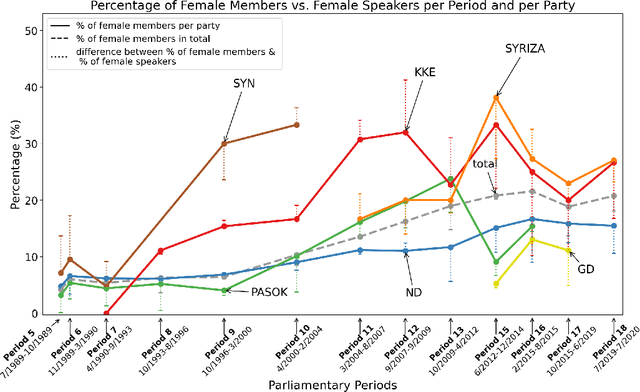
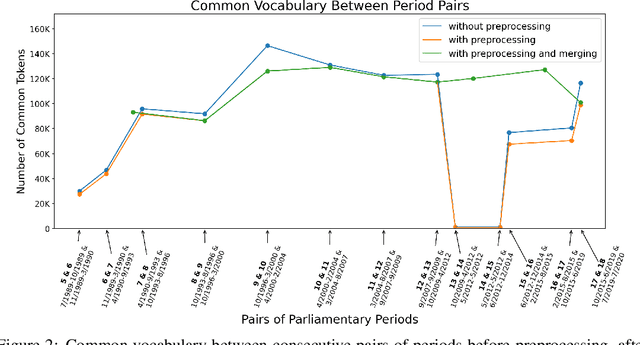

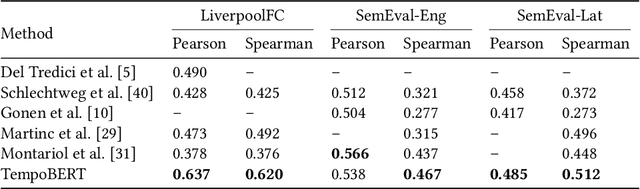
Large, diachronic datasets of political discourse are hard to come across, especially for resource-lean languages such as Greek. In this paper, we introduce a curated dataset of the Greek Parliament Proceedings that extends chronologically from 1989 up to 2020. It consists of more than 1 million speeches with extensive metadata, extracted from 5,355 parliamentary record files. We explain how it was constructed and the challenges that we had to overcome. The dataset can be used for both computational linguistics and political analysis-ideally, combining the two. We present such an application, showing (i) how the dataset can be used to study the change of word usage through time, (ii) between significant historical events and political parties, (iii) by evaluating and employing algorithms for detecting semantic shifts.
Safety-Critical Adaptation in Self-Adaptive Systems
Sep 30, 2022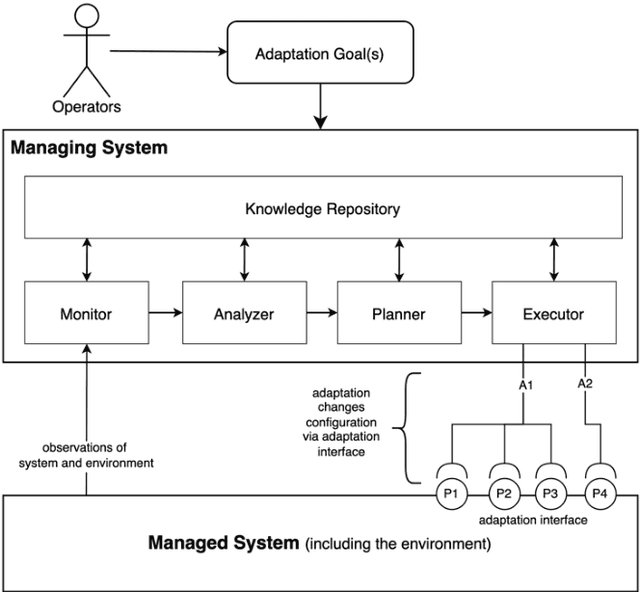
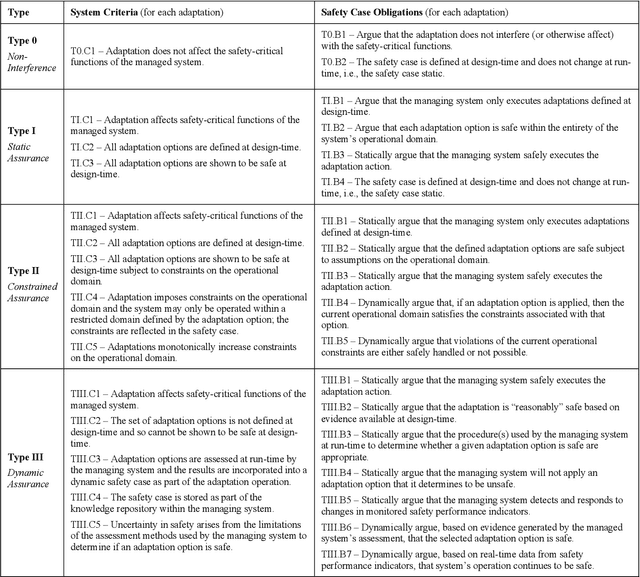
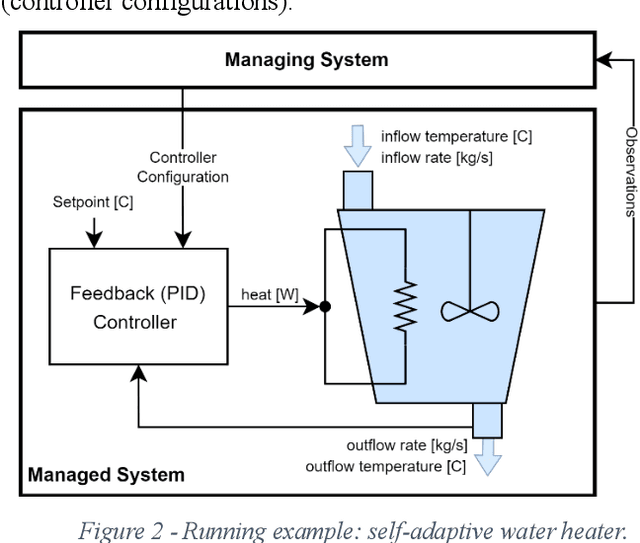
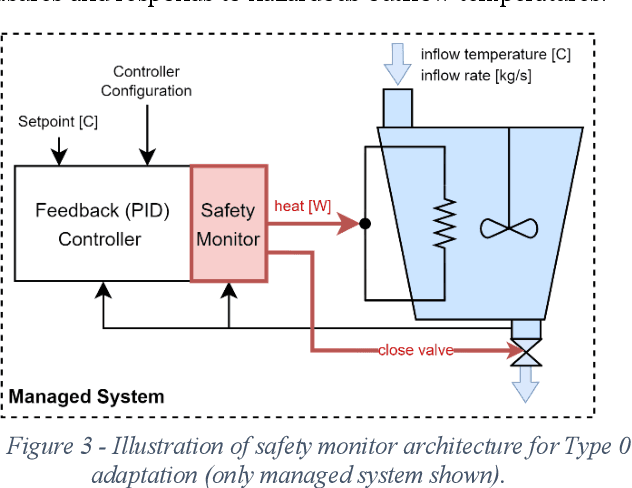
Modern systems are designed to operate in increasingly variable and uncertain environments. Not only are these environments complex, in the sense that they contain a tremendous number of variables, but they also change over time. Systems must be able to adjust their behaviour at run-time to manage these uncertainties. These self-adaptive systems have been studied extensively. This paper proposes a definition of a safety-critical self-adaptive system and then describes a taxonomy for classifying adaptations into different types based on their impact on the system's safety and the system's safety case. The taxonomy expresses criteria for classification and then describes specific criteria that the safety case for a self-adaptive system must satisfy, depending on the type of adaptations performed. Each type in the taxonomy is illustrated using the example of a safety-critical self-adaptive water heating system.