 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Over-the-Air Computation for Distributed Systems: Something Old and Something New
Nov 01, 2022
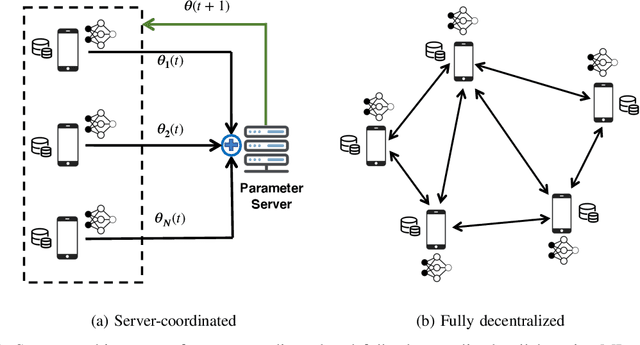
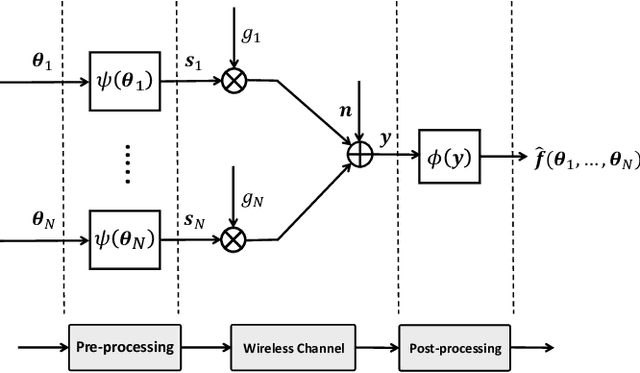
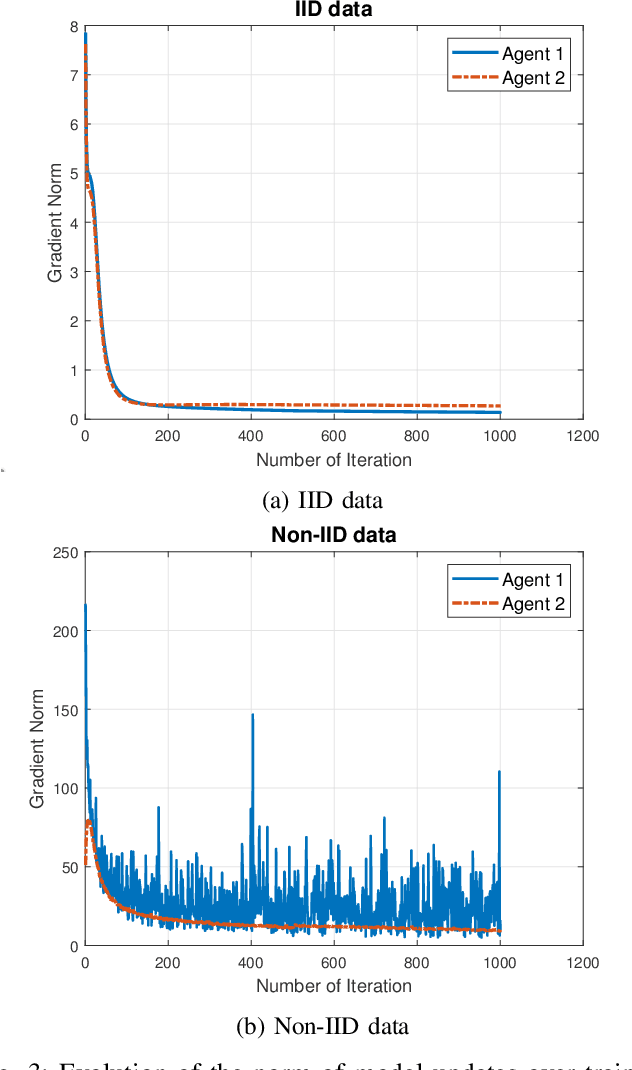

Facing the upcoming era of Internet-of-Things and connected intelligence, efficient information processing, computation and communication design becomes a key challenge in large-scale intelligent systems. Recently, Over-the-Air (OtA) computation has been proposed for data aggregation and distributed function computation over a large set of network nodes. Theoretical foundations for this concept exist for a long time, but it was mainly investigated within the context of wireless sensor networks. There are still many open questions when applying OtA computation in different types of distributed systems where modern wireless communication technology is applied. In this article, we provide a comprehensive overview of the OtA computation principle and its applications in distributed learning, control, and inference systems, for both server-coordinated and fully decentralized architectures. Particularly, we highlight the importance of the statistical heterogeneity of data and wireless channels, the temporal evolution of model updates, and the choice of performance metrics, for the communication design in OtA federated learning (FL) systems. Several key challenges in privacy, security and robustness aspects of OtA FL are also identified for further investigation.
Non-line-of-sight imaging with arbitrary illumination and detection pattern
Nov 01, 2022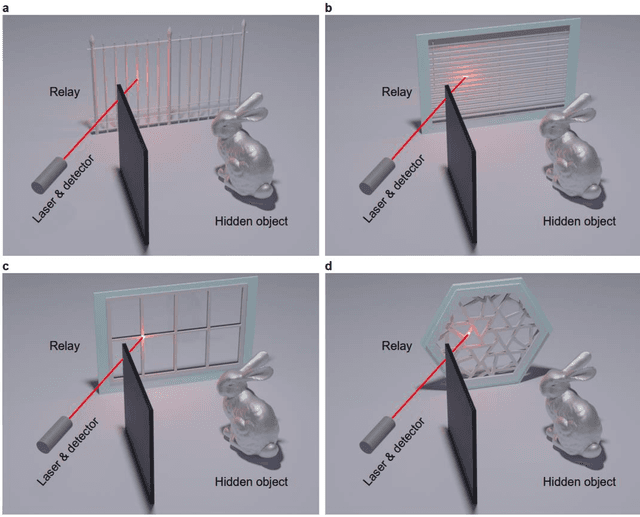
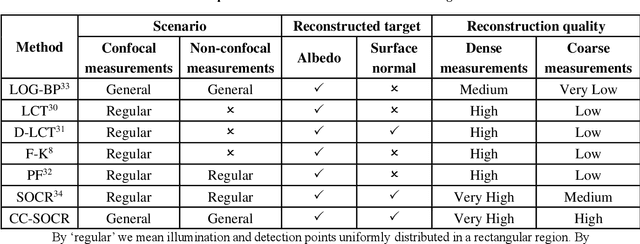
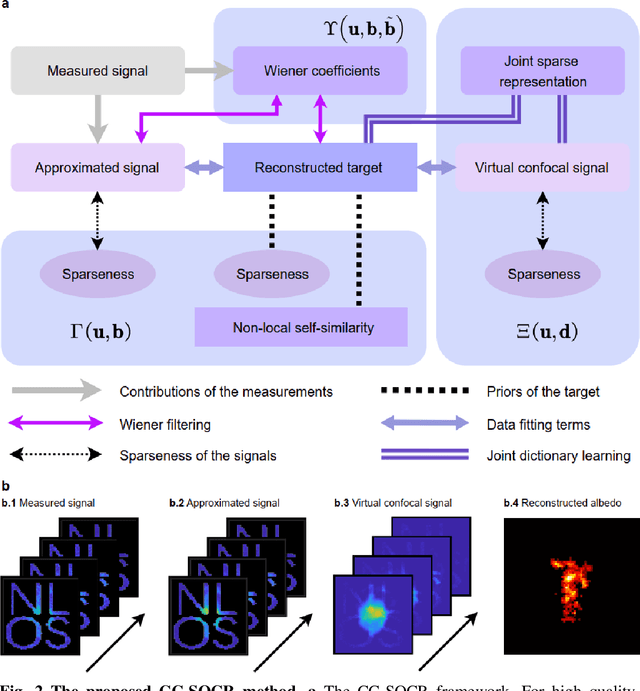
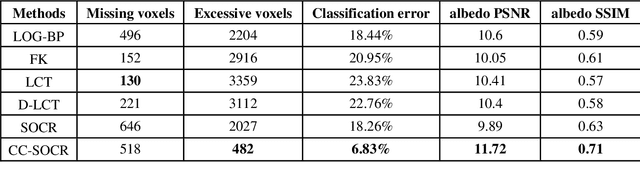
Non-line-of-sight (NLOS) imaging aims at reconstructing targets obscured from the direct line of sight. Existing NLOS imaging algorithms require dense measurements at rectangular grid points in a large area of the relay surface, which severely hinders their availability to variable relay scenarios in practical applications such as robotic vision, autonomous driving, rescue operations and remote sensing. In this work, we propose a Bayesian framework for NLOS imaging with no specific requirements on the spatial pattern of illumination and detection points. By introducing virtual confocal signals, we design a confocal complemented signal-object collaborative regularization (CC-SOCR) algorithm for high quality reconstructions. Our approach is capable of reconstructing both albedo and surface normal of the hidden objects with fine details under the most general relay setting. Moreover, with a regular relay surface, coarse rather than dense measurements are enough for our approach such that the acquisition time can be reduced significantly. As demonstrated in multiple experiments, the new framework substantially enhances the applicability of NLOS imaging.
DeepVARwT: Deep Learning for a VAR Model with Trend
Sep 21, 2022
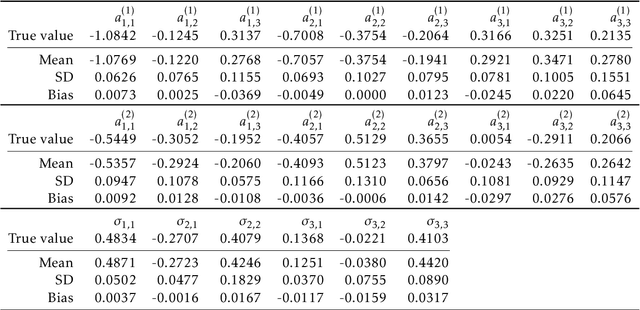
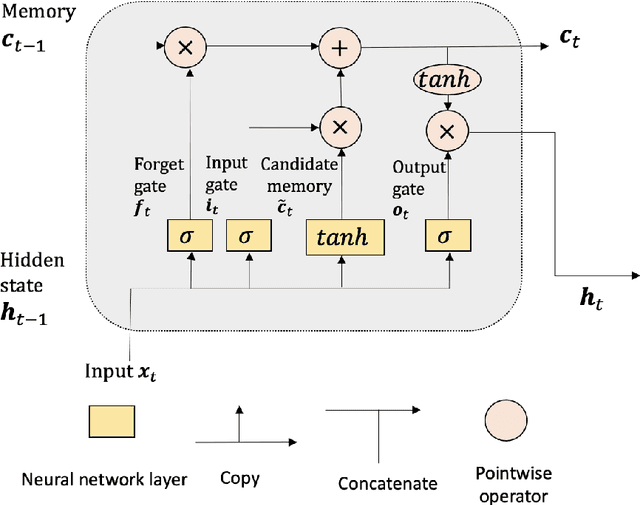

The vector autoregressive (VAR) model has been used to describe the dependence within and across multiple time series. This is a model for stationary time series which can be extended to allow the presence of a deterministic trend in each series. Detrending the data either parametrically or nonparametrically before fitting the VAR model gives rise to more errors in the latter part. In this study, we propose a new approach called DeepVARwT that employs deep learning methodology for maximum likelihood estimation of the trend and the dependence structure at the same time. A Long Short-Term Memory (LSTM) network is used for this purpose. To ensure the stability of the model, we enforce the causality condition on the autoregressive coefficients using the transformation of Ansley & Kohn (1986). We provide a simulation study and an application to real data. In the simulation study, we use realistic trend functions generated from real data and compare the estimates with true function/parameter values. In the real data application, we compare the prediction performance of this model with state-of-the-art models in the literature.
Artificial Intelligence Enables Real-Time and Intuitive Control of Prostheses via Nerve Interface
Mar 16, 2022
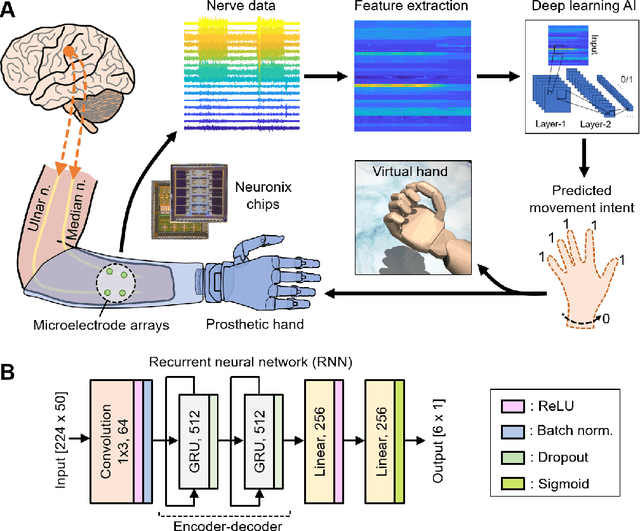
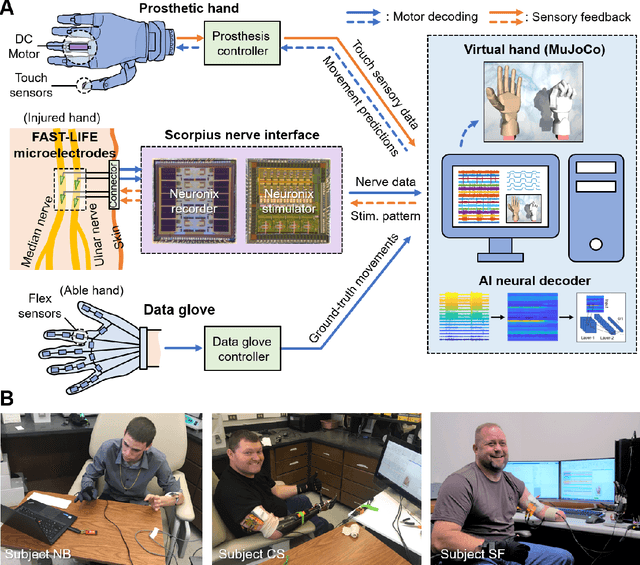
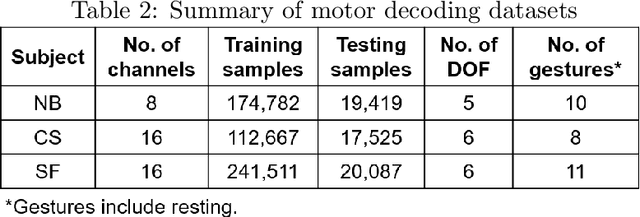
Objective: The next generation prosthetic hand that moves and feels like a real hand requires a robust neural interconnection between the human minds and machines. Methods: Here we present a neuroprosthetic system to demonstrate that principle by employing an artificial intelligence (AI) agent to translate the amputee's movement intent through a peripheral nerve interface. The AI agent is designed based on the recurrent neural network (RNN) and could simultaneously decode six degree-of-freedom (DOF) from multichannel nerve data in real-time. The decoder's performance is characterized in motor decoding experiments with three human amputees. Results: First, we show the AI agent enables amputees to intuitively control a prosthetic hand with individual finger and wrist movements up to 97-98% accuracy. Second, we demonstrate the AI agent's real-time performance by measuring the reaction time and information throughput in a hand gesture matching task. Third, we investigate the AI agent's long-term uses and show the decoder's robust predictive performance over a 16-month implant duration. Conclusion & significance: Our study demonstrates the potential of AI-enabled nerve technology, underling the next generation of dexterous and intuitive prosthetic hands.
Self-Adaptive Driving in Nonstationary Environments through Conjectural Online Lookahead Adaptation
Oct 06, 2022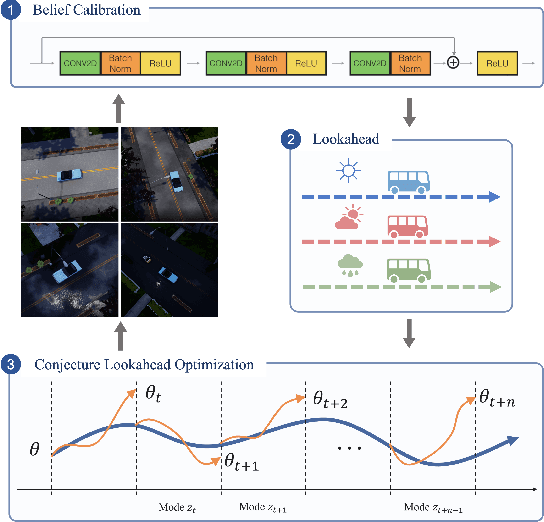
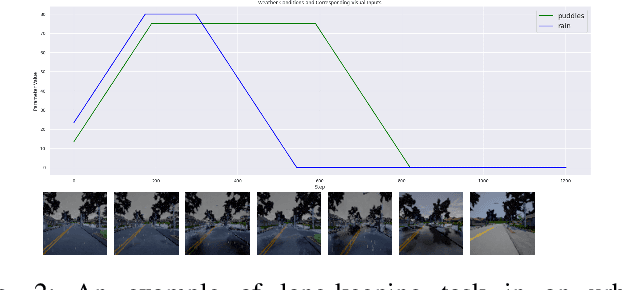
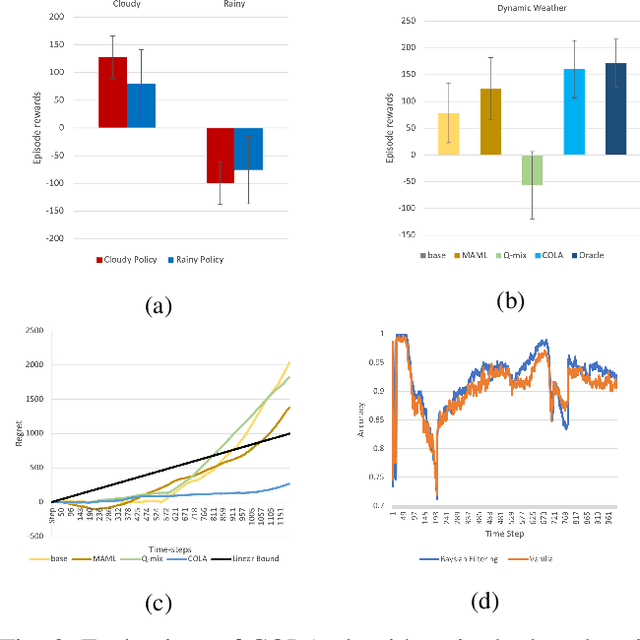
Powered by deep representation learning, reinforcement learning (RL) provides an end-to-end learning framework capable of solving self-driving (SD) tasks without manual designs. However, time-varying nonstationary environments cause proficient but specialized RL policies to fail at execution time. For example, an RL-based SD policy trained under sunny days does not generalize well to rainy weather. Even though meta learning enables the RL agent to adapt to new tasks/environments, its offline operation fails to equip the agent with online adaptation ability when facing nonstationary environments. This work proposes an online meta reinforcement learning algorithm based on the \emph{conjectural online lookahead adaptation} (COLA). COLA determines the online adaptation at every step by maximizing the agent's conjecture of the future performance in a lookahead horizon. Experimental results demonstrate that under dynamically changing weather and lighting conditions, the COLA-based self-adaptive driving outperforms the baseline policies in terms of online adaptability. A demo video, source code, and appendixes are available at {\tt https://github.com/Panshark/COLA}
Domain-Specific Word Embeddings with Structure Prediction
Oct 06, 2022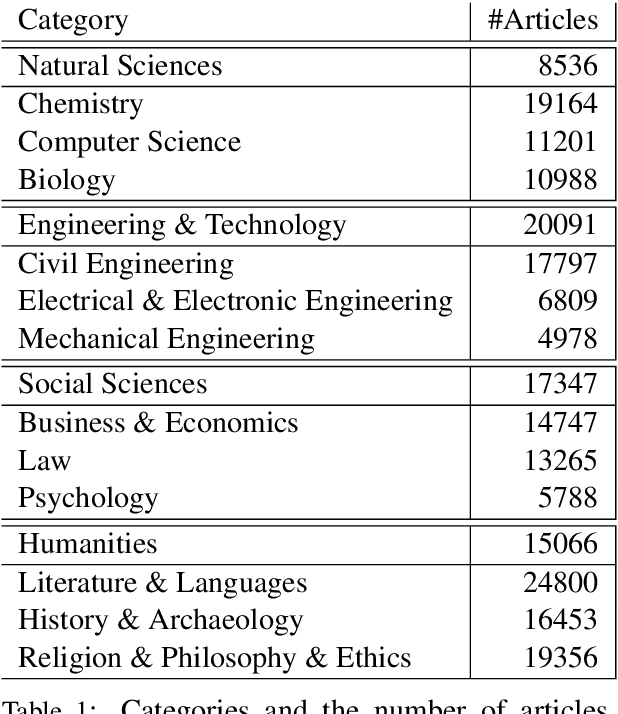
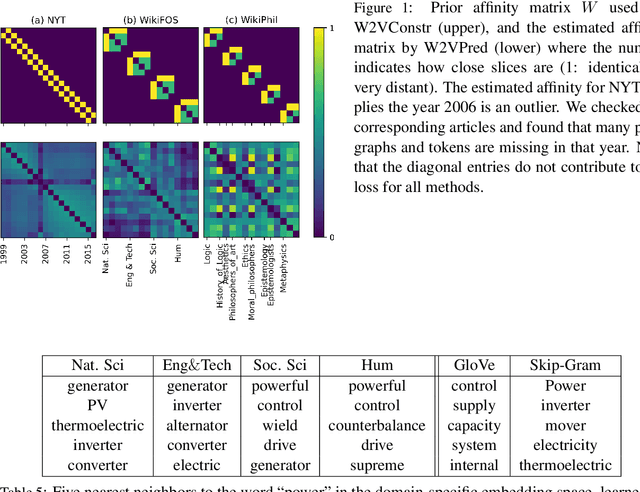
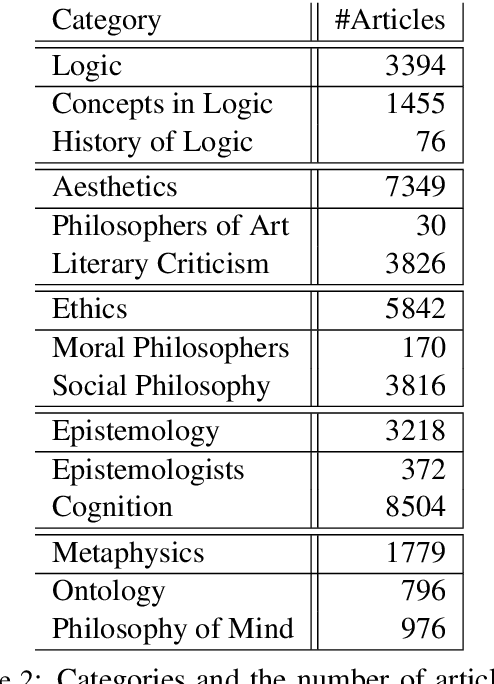
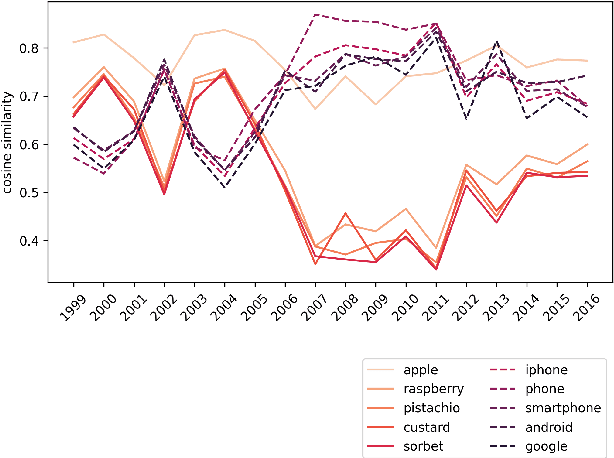
Complementary to finding good general word embeddings, an important question for representation learning is to find dynamic word embeddings, e.g., across time or domain. Current methods do not offer a way to use or predict information on structure between sub-corpora, time or domain and dynamic embeddings can only be compared after post-alignment. We propose novel word embedding methods that provide general word representations for the whole corpus, domain-specific representations for each sub-corpus, sub-corpus structure, and embedding alignment simultaneously. We present an empirical evaluation on New York Times articles and two English Wikipedia datasets with articles on science and philosophy. Our method, called Word2Vec with Structure Prediction (W2VPred), provides better performance than baselines in terms of the general analogy tests, domain-specific analogy tests, and multiple specific word embedding evaluations as well as structure prediction performance when no structure is given a priori. As a use case in the field of Digital Humanities we demonstrate how to raise novel research questions for high literature from the German Text Archive.
A Greek Parliament Proceedings Dataset for Computational Linguistics and Political Analysis
Oct 23, 2022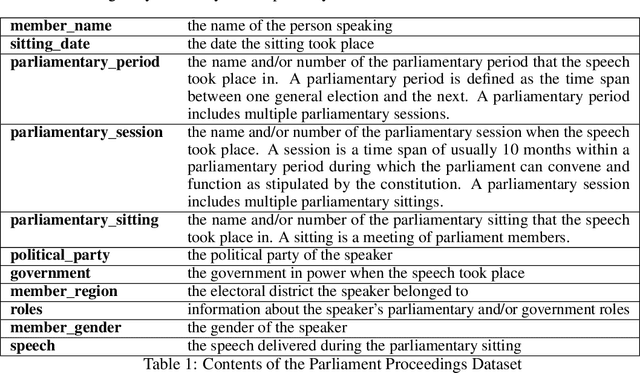
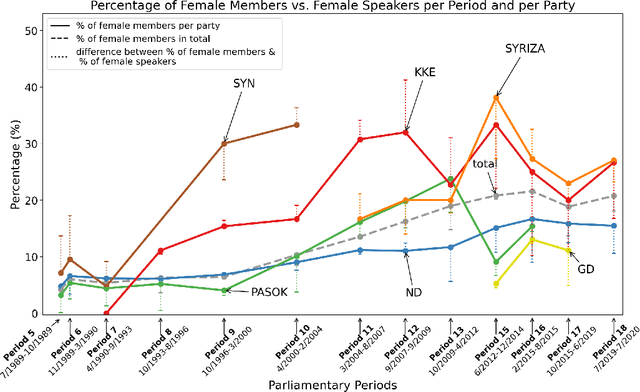
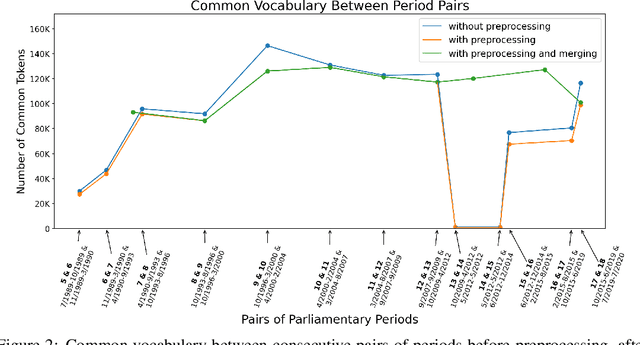

Large, diachronic datasets of political discourse are hard to come across, especially for resource-lean languages such as Greek. In this paper, we introduce a curated dataset of the Greek Parliament Proceedings that extends chronologically from 1989 up to 2020. It consists of more than 1 million speeches with extensive metadata, extracted from 5,355 parliamentary record files. We explain how it was constructed and the challenges that we had to overcome. The dataset can be used for both computational linguistics and political analysis-ideally, combining the two. We present such an application, showing (i) how the dataset can be used to study the change of word usage through time, (ii) between significant historical events and political parties, (iii) by evaluating and employing algorithms for detecting semantic shifts.
Space-Time Block Coded Reconfigurable Intelligent Surface-Based Received Spatial Modulation
Mar 28, 2022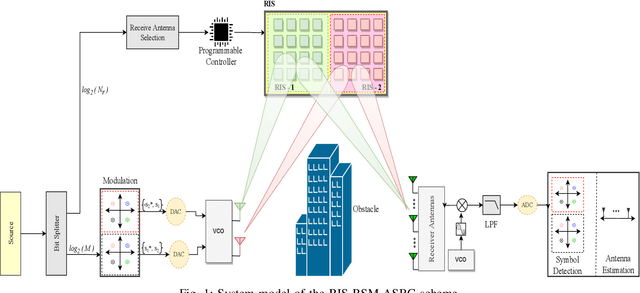
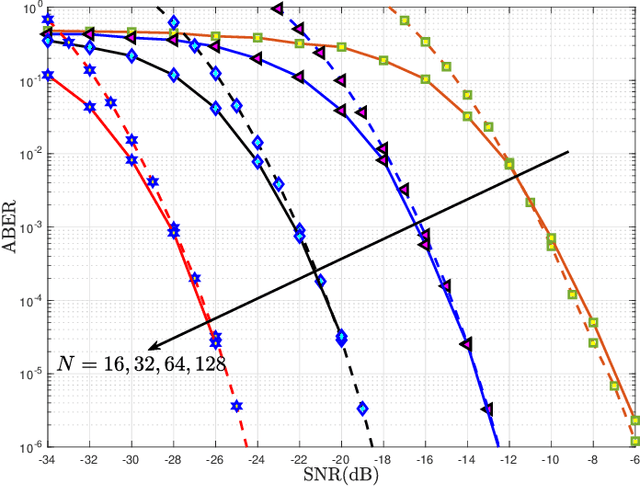
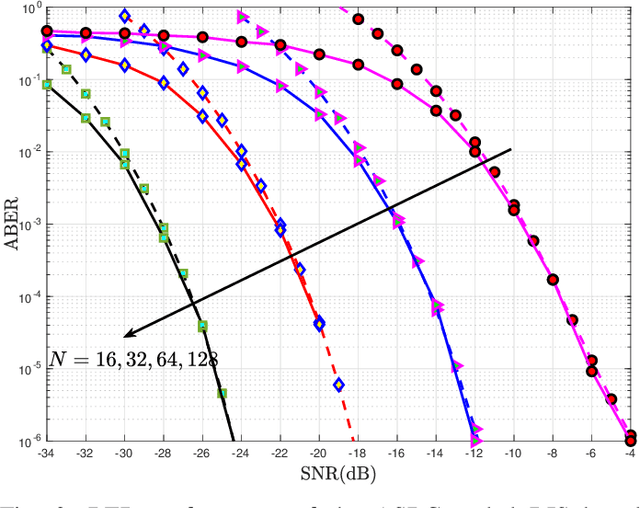
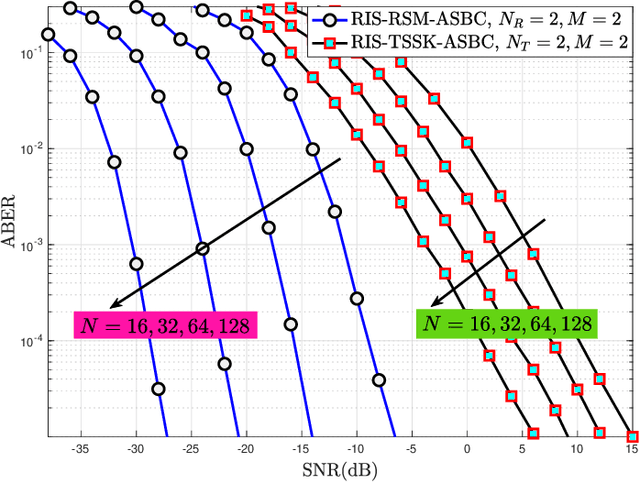
Reconfigurable intelligent surface (RIS) structures reflect the incident signals by adjusting phase adaptively according to the channel condition where doing transmission in order to increase signal quality at the receiver. Besides, the spatial modulation (SM) technique is a possible candidate for future energy-efficient wireless communications due to providing better throughput, low-cost implementation and good error performance. Also, Alamouti's space-time block coding (ASBC) is an important space and time coding technique in terms of diversity gain and simplified ML detection. In this paper, we proposed the RIS assisted received spatial modulation (RSM) scheme with ASBC, namely RIS-RSM-ASBC. The termed RIS is portioned by two parts in the proposed system model. Each one is utilized as an access point (AP) to transmit its Alamouti coded information while reflecting passive signals to the selected received antenna. The optimal maximum likelihood (ML) detector is designed for the proposed RIS-RSM-ASBC scheme. Extensive computer simulations are conducted to corroborate theoretical derivations. Results show that RIS-RSM-ASBC system is highly reliable and provides data rate enhancement in contrast to conventional RIS assisted transmit SM (RIS-TSM), RIS assisted transmit quadrature SM (RIS-TQSM), RIS assisted received SM (RIS-RSM), RIS assisted transmit space shift keying with ASBC (RIS-TSSK-ASBC) and RIS-TSSK-VBLAST schemes.
Beyond Learning from Next Item: Sequential Recommendation via Personalized Interest Sustainability
Sep 14, 2022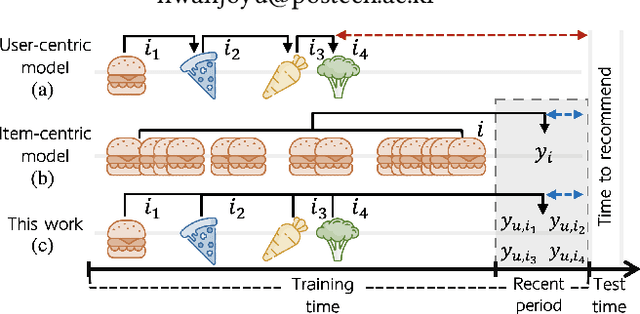
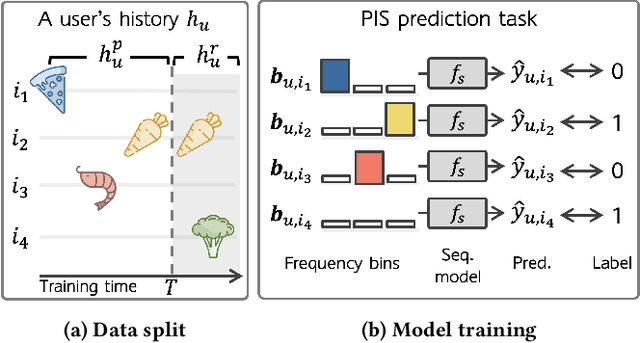
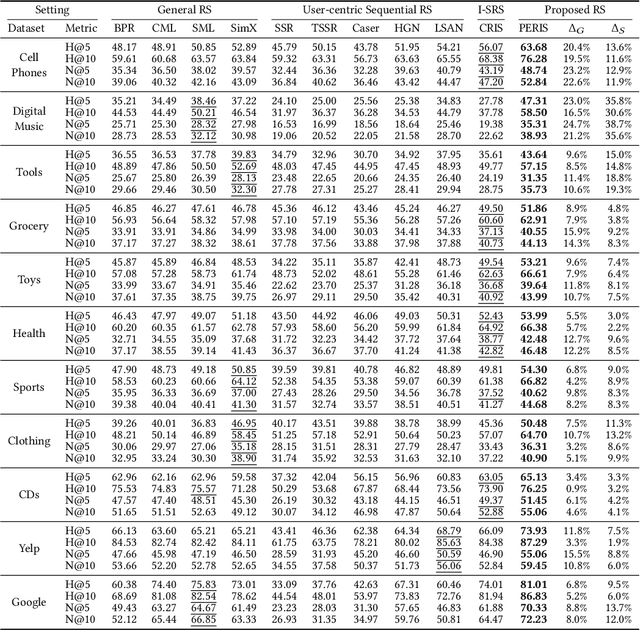
Sequential recommender systems have shown effective suggestions by capturing users' interest drift. There have been two groups of existing sequential models: user- and item-centric models. The user-centric models capture personalized interest drift based on each user's sequential consumption history, but do not explicitly consider whether users' interest in items sustains beyond the training time, i.e., interest sustainability. On the other hand, the item-centric models consider whether users' general interest sustains after the training time, but it is not personalized. In this work, we propose a recommender system taking advantages of the models in both categories. Our proposed model captures personalized interest sustainability, indicating whether each user's interest in items will sustain beyond the training time or not. We first formulate a task that requires to predict which items each user will consume in the recent period of the training time based on users' consumption history. We then propose simple yet effective schemes to augment users' sparse consumption history. Extensive experiments show that the proposed model outperforms 10 baseline models on 11 real-world datasets. The codes are available at https://github.com/dmhyun/PERIS.
Multi-Objective Model Selection for Time Series Forecasting
Feb 17, 2022Research on time series forecasting has predominantly focused on developing methods that improve accuracy. However, other criteria such as training time or latency are critical in many real-world applications. We therefore address the question of how to choose an appropriate forecasting model for a given dataset among the plethora of available forecasting methods when accuracy is only one of many criteria. For this, our contributions are two-fold. First, we present a comprehensive benchmark, evaluating 7 classical and 6 deep learning forecasting methods on 44 heterogeneous, publicly available datasets. The benchmark code is open-sourced along with evaluations and forecasts for all methods. These evaluations enable us to answer open questions such as the amount of data required for deep learning models to outperform classical ones. Second, we leverage the benchmark evaluations to learn good defaults that consider multiple objectives such as accuracy and latency. By learning a mapping from forecasting models to performance metrics, we show that our method PARETOSELECT is able to accurately select models from the Pareto front -- alleviating the need to train or evaluate many forecasting models for model selection. To the best of our knowledge, PARETOSELECT constitutes the first method to learn default models in a multi-objective setting.