 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ProtoX: Explaining a Reinforcement Learning Agent via Prototyping
Nov 06, 2022
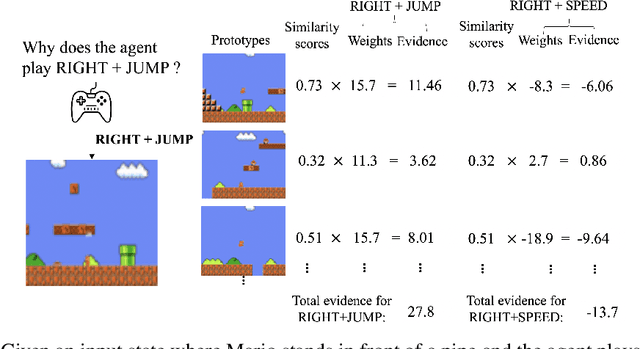
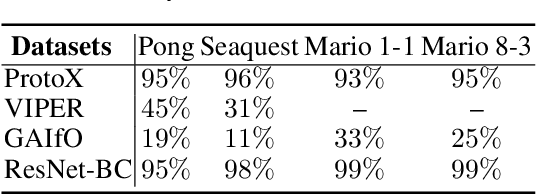
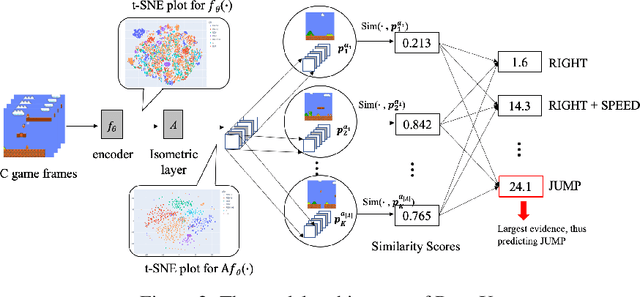

While deep reinforcement learning has proven to be successful in solving control tasks, the "black-box" nature of an agent has received increasing concerns. We propose a prototype-based post-hoc policy explainer, ProtoX, that explains a blackbox agent by prototyping the agent's behaviors into scenarios, each represented by a prototypical state. When learning prototypes, ProtoX considers both visual similarity and scenario similarity. The latter is unique to the reinforcement learning context, since it explains why the same action is taken in visually different states. To teach ProtoX about visual similarity, we pre-train an encoder using contrastive learning via self-supervised learning to recognize states as similar if they occur close together in time and receive the same action from the black-box agent. We then add an isometry layer to allow ProtoX to adapt scenario similarity to the downstream task. ProtoX is trained via imitation learning using behavior cloning, and thus requires no access to the environment or agent. In addition to explanation fidelity, we design different prototype shaping terms in the objective function to encourage better interpretability. We conduct various experiments to test ProtoX. Results show that ProtoX achieved high fidelity to the original black-box agent while providing meaningful and understandable explanations.
Evaluating Digital Tools for Sustainable Agriculture using Causal Inference
Nov 06, 2022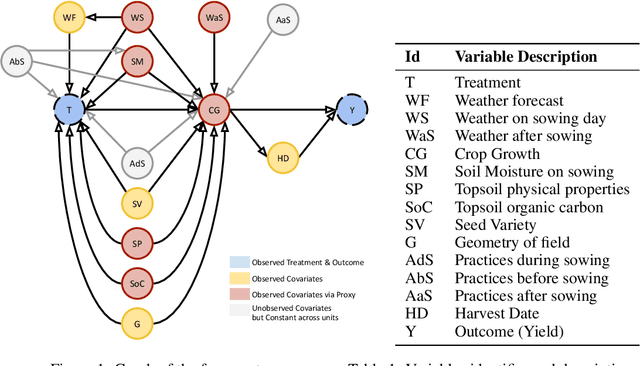
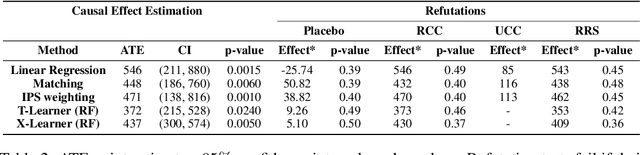

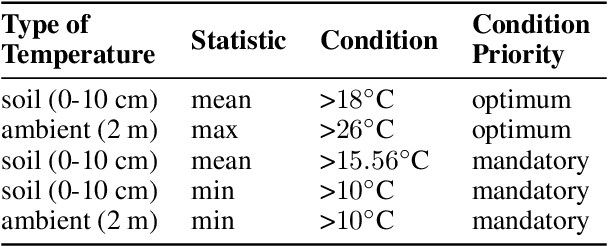
In contrast to the rapid digitalization of several industries, agriculture suffers from low adoption of climate-smart farming tools. Even though AI-driven digital agriculture can offer high-performing predictive functionalities, it lacks tangible quantitative evidence on its benefits to the farmers. Field experiments can derive such evidence, but are often costly and time consuming. To this end, we propose an observational causal inference framework for the empirical evaluation of the impact of digital tools on target farm performance indicators. This way, we can increase farmers' trust by enhancing the transparency of the digital agriculture market, and in turn accelerate the adoption of technologies that aim to increase productivity and secure a sustainable and resilient agriculture against a changing climate. As a case study, we perform an empirical evaluation of a recommendation system for optimal cotton sowing, which was used by a farmers' cooperative during the growing season of 2021. We leverage agricultural knowledge to develop a causal graph of the farm system, we use the back-door criterion to identify the impact of recommendations on the yield and subsequently estimate it using several methods on observational data. The results show that a field sown according to our recommendations enjoyed a significant increase in yield (12% to 17%).
Space-Time Block Coded Reconfigurable Intelligent Surface-Based Received Spatial Modulation
Mar 28, 2022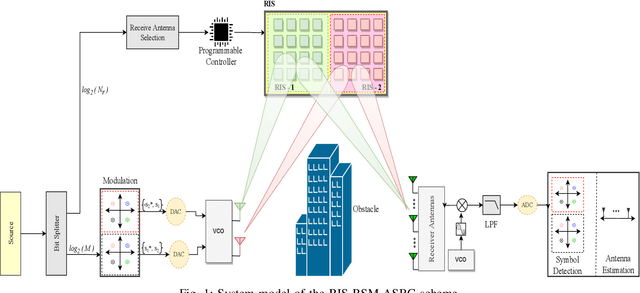
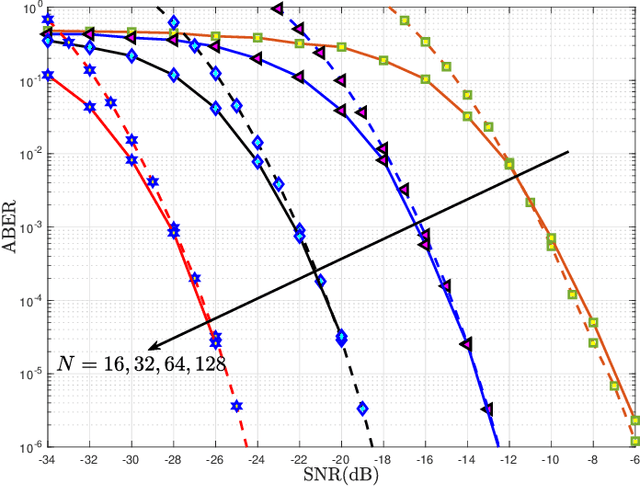
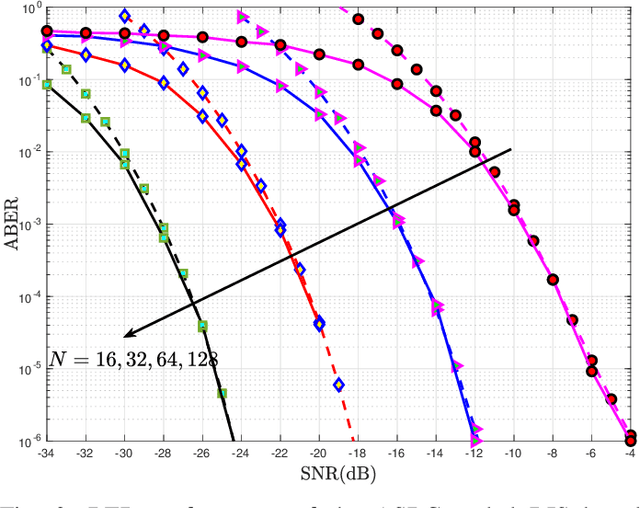
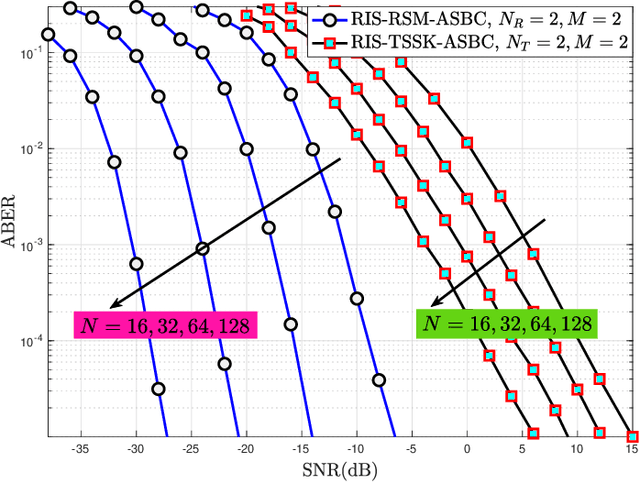
Reconfigurable intelligent surface (RIS) structures reflect the incident signals by adjusting phase adaptively according to the channel condition where doing transmission in order to increase signal quality at the receiver. Besides, the spatial modulation (SM) technique is a possible candidate for future energy-efficient wireless communications due to providing better throughput, low-cost implementation and good error performance. Also, Alamouti's space-time block coding (ASBC) is an important space and time coding technique in terms of diversity gain and simplified ML detection. In this paper, we proposed the RIS assisted received spatial modulation (RSM) scheme with ASBC, namely RIS-RSM-ASBC. The termed RIS is portioned by two parts in the proposed system model. Each one is utilized as an access point (AP) to transmit its Alamouti coded information while reflecting passive signals to the selected received antenna. The optimal maximum likelihood (ML) detector is designed for the proposed RIS-RSM-ASBC scheme. Extensive computer simulations are conducted to corroborate theoretical derivations. Results show that RIS-RSM-ASBC system is highly reliable and provides data rate enhancement in contrast to conventional RIS assisted transmit SM (RIS-TSM), RIS assisted transmit quadrature SM (RIS-TQSM), RIS assisted received SM (RIS-RSM), RIS assisted transmit space shift keying with ASBC (RIS-TSSK-ASBC) and RIS-TSSK-VBLAST schemes.
Multi-Objective Model Selection for Time Series Forecasting
Feb 17, 2022Research on time series forecasting has predominantly focused on developing methods that improve accuracy. However, other criteria such as training time or latency are critical in many real-world applications. We therefore address the question of how to choose an appropriate forecasting model for a given dataset among the plethora of available forecasting methods when accuracy is only one of many criteria. For this, our contributions are two-fold. First, we present a comprehensive benchmark, evaluating 7 classical and 6 deep learning forecasting methods on 44 heterogeneous, publicly available datasets. The benchmark code is open-sourced along with evaluations and forecasts for all methods. These evaluations enable us to answer open questions such as the amount of data required for deep learning models to outperform classical ones. Second, we leverage the benchmark evaluations to learn good defaults that consider multiple objectives such as accuracy and latency. By learning a mapping from forecasting models to performance metrics, we show that our method PARETOSELECT is able to accurately select models from the Pareto front -- alleviating the need to train or evaluate many forecasting models for model selection. To the best of our knowledge, PARETOSELECT constitutes the first method to learn default models in a multi-objective setting.
Towards Global Crop Maps with Transfer Learning
Nov 10, 2022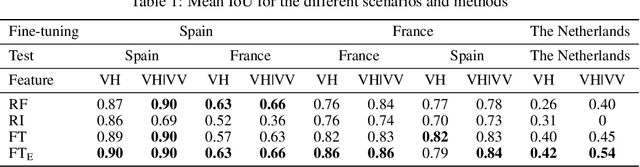
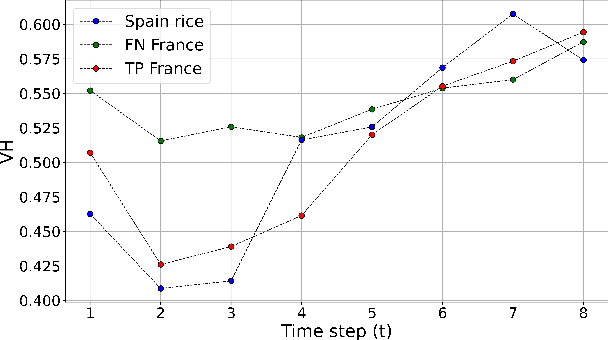
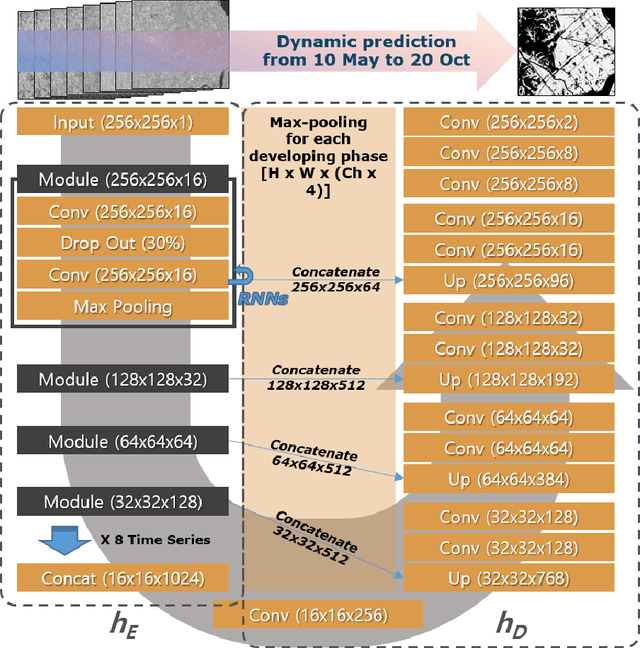
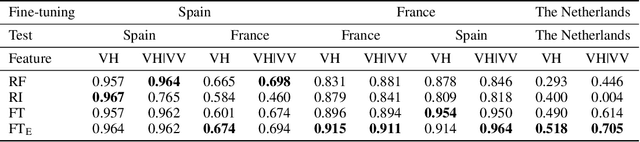
The continuous increase in global population and the impact of climate change on crop production are expected to affect the food sector significantly. In this context, there is need for timely, large-scale and precise mapping of crops for evidence-based decision making. A key enabler towards this direction are new satellite missions that freely offer big remote sensing data of high spatio-temporal resolution and global coverage. During the previous decade and because of this surge of big Earth observations, deep learning methods have dominated the remote sensing and crop mapping literature. Nevertheless, deep learning models require large amounts of annotated data that are scarce and hard-to-acquire. To address this problem, transfer learning methods can be used to exploit available annotations and enable crop mapping for other regions, crop types and years of inspection. In this work, we have developed and trained a deep learning model for paddy rice detection in South Korea using Sentinel-1 VH time-series. We then fine-tune the model for i) paddy rice detection in France and Spain and ii) barley detection in the Netherlands. Additionally, we propose a modification in the pre-trained weights in order to incorporate extra input features (Sentinel-1 VV). Our approach shows excellent performance when transferring in different areas for the same crop type and rather promising results when transferring in a different area and crop type.
Estimation of Doubly-Dispersive Channels in Linearly Precoded Multicarrier Systems Using Smoothness Regularization
Oct 11, 2022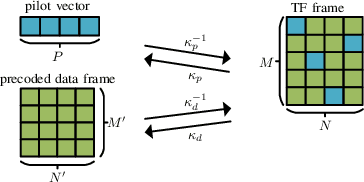
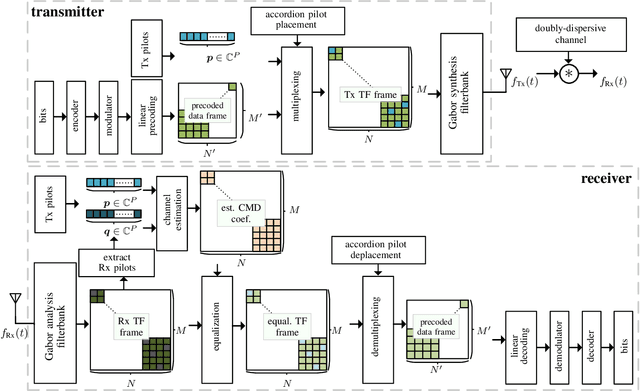
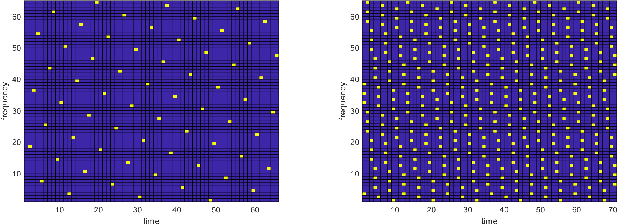
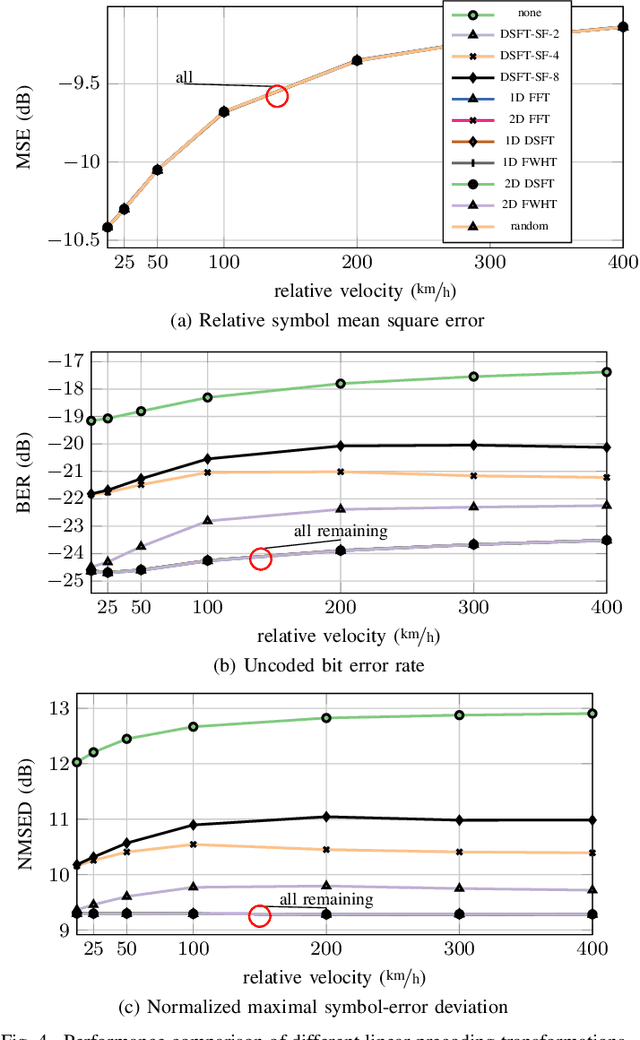
In this paper, we propose a novel channel estimation scheme for pulse-shaped multicarrier systems using smoothness regularization for ultra-reliable low-latency communication (URLLC). It can be applied to any multicarrier system with or without linear precoding to estimate challenging doubly-dispersive channels. A recently proposed modulation scheme using orthogonal precoding is orthogonal time-frequency and space modulation (OTFS). In OTFS, pilot and data symbols are placed in delay-Doppler (DD) domain and are jointly precoded to the time-frequency (TF) domain. On the one hand, such orthogonal precoding increases the achievable channel estimation accuracy and enables high TF diversity at the receiver. On the other hand, it introduces leakage effects which requires extensive leakage suppression when the piloting is jointly precoded with the data. To avoid this, we propose to precode the data symbols only, place pilot symbols without precoding into the TF domain, and estimate the channel coefficients by interpolating smooth functions from the pilot samples. Furthermore, we present a piloting scheme enabling a smooth control of the number and position of the pilot symbols. Our numerical results suggest that the proposed scheme provides accurate channel estimation with reduced signaling overhead compared to standard estimators using Wiener filtering in the discrete DD domain.
DeepVARwT: Deep Learning for a VAR Model with Trend
Sep 21, 2022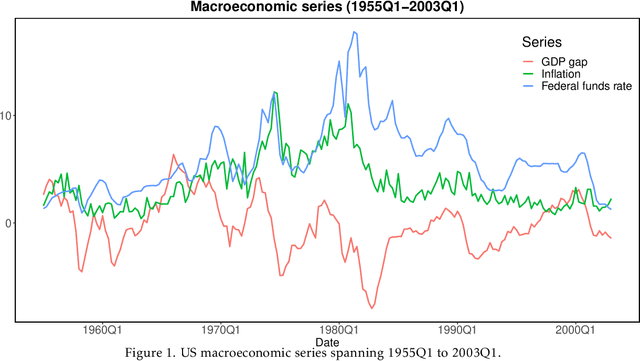
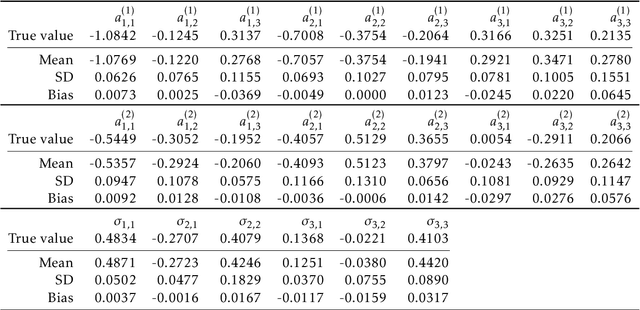
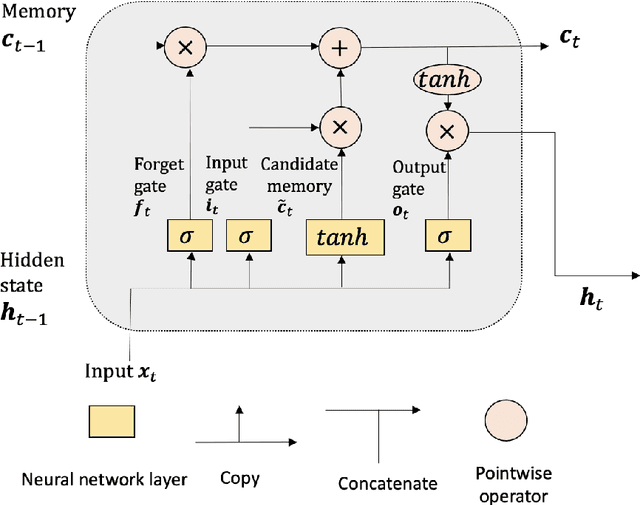

The vector autoregressive (VAR) model has been used to describe the dependence within and across multiple time series. This is a model for stationary time series which can be extended to allow the presence of a deterministic trend in each series. Detrending the data either parametrically or nonparametrically before fitting the VAR model gives rise to more errors in the latter part. In this study, we propose a new approach called DeepVARwT that employs deep learning methodology for maximum likelihood estimation of the trend and the dependence structure at the same time. A Long Short-Term Memory (LSTM) network is used for this purpose. To ensure the stability of the model, we enforce the causality condition on the autoregressive coefficients using the transformation of Ansley & Kohn (1986). We provide a simulation study and an application to real data. In the simulation study, we use realistic trend functions generated from real data and compare the estimates with true function/parameter values. In the real data application, we compare the prediction performance of this model with state-of-the-art models in the literature.
MicroISP: Processing 32MP Photos on Mobile Devices with Deep Learning
Nov 08, 2022
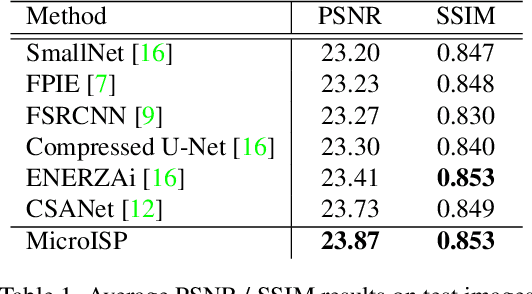

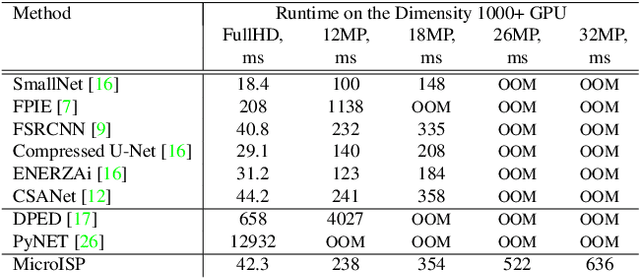
While neural networks-based photo processing solutions can provide a better image quality compared to the traditional ISP systems, their application to mobile devices is still very limited due to their very high computational complexity. In this paper, we present a novel MicroISP model designed specifically for edge devices, taking into account their computational and memory limitations. The proposed solution is capable of processing up to 32MP photos on recent smartphones using the standard mobile ML libraries and requiring less than 1 second to perform the inference, while for FullHD images it achieves real-time performance. The architecture of the model is flexible, allowing to adjust its complexity to devices of different computational power. To evaluate the performance of the model, we collected a novel Fujifilm UltraISP dataset consisting of thousands of paired photos captured with a normal mobile camera sensor and a professional 102MP medium-format FujiFilm GFX100 camera. The experiments demonstrated that, despite its compact size, the MicroISP model is able to provide comparable or better visual results than the traditional mobile ISP systems, while outperforming the previously proposed efficient deep learning based solutions. Finally, this model is also compatible with the latest mobile AI accelerators, achieving good runtime and low power consumption on smartphone NPUs and APUs. The code, dataset and pre-trained models are available on the project website: https://people.ee.ethz.ch/~ihnatova/microisp.html
Reliable Malware Analysis and Detection using Topology Data Analysis
Nov 08, 2022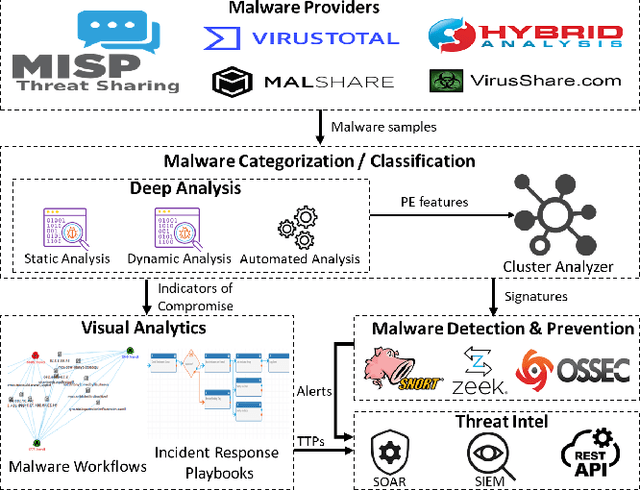
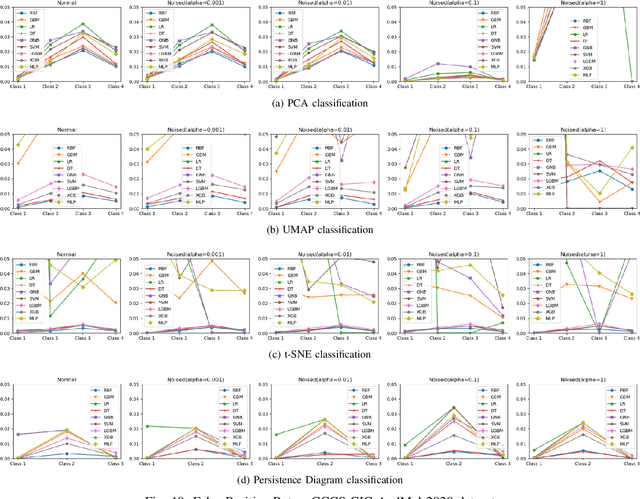
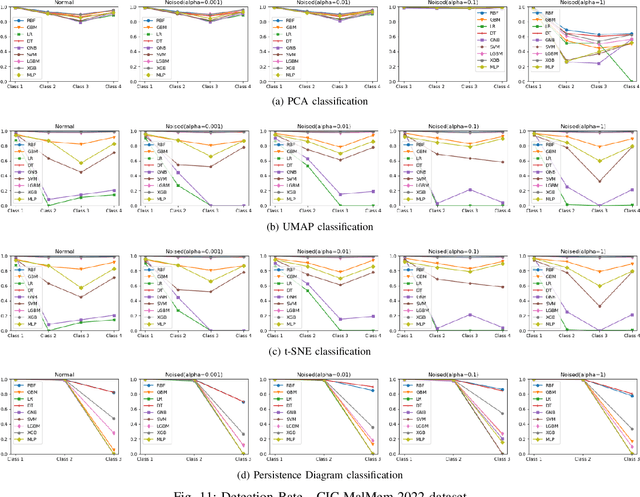
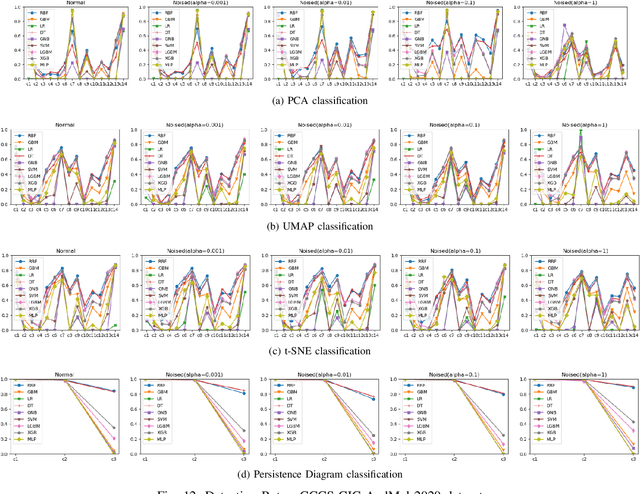
Increasingly, malwares are becoming complex and they are spreading on networks targeting different infrastructures and personal-end devices to collect, modify, and destroy victim information. Malware behaviors are polymorphic, metamorphic, persistent, able to hide to bypass detectors and adapt to new environments, and even leverage machine learning techniques to better damage targets. Thus, it makes them difficult to analyze and detect with traditional endpoint detection and response, intrusion detection and prevention systems. To defend against malwares, recent work has proposed different techniques based on signatures and machine learning. In this paper, we propose to use an algebraic topological approach called topological-based data analysis (TDA) to efficiently analyze and detect complex malware patterns. Next, we compare the different TDA techniques (i.e., persistence homology, tomato, TDA Mapper) and existing techniques (i.e., PCA, UMAP, t-SNE) using different classifiers including random forest, decision tree, xgboost, and lightgbm. We also propose some recommendations to deploy the best-identified models for malware detection at scale. Results show that TDA Mapper (combined with PCA) is better for clustering and for identifying hidden relationships between malware clusters compared to PCA. Persistent diagrams are better to identify overlapping malware clusters with low execution time compared to UMAP and t-SNE. For malware detection, malware analysts can use Random Forest and Decision Tree with t-SNE and Persistent Diagram to achieve better performance and robustness on noised data.
Privacy Meets Explainability: A Comprehensive Impact Benchmark
Nov 08, 2022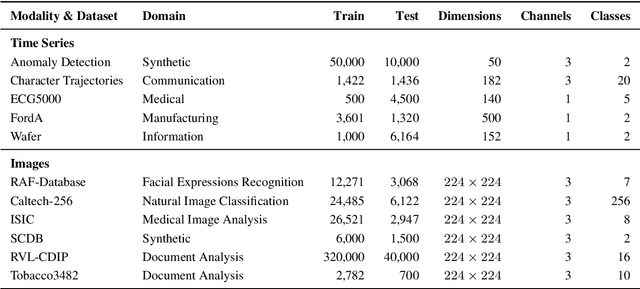
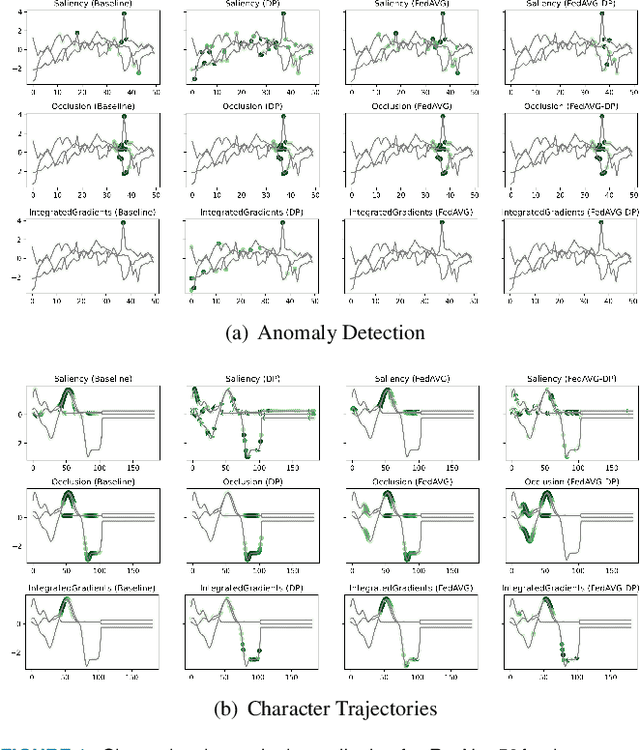
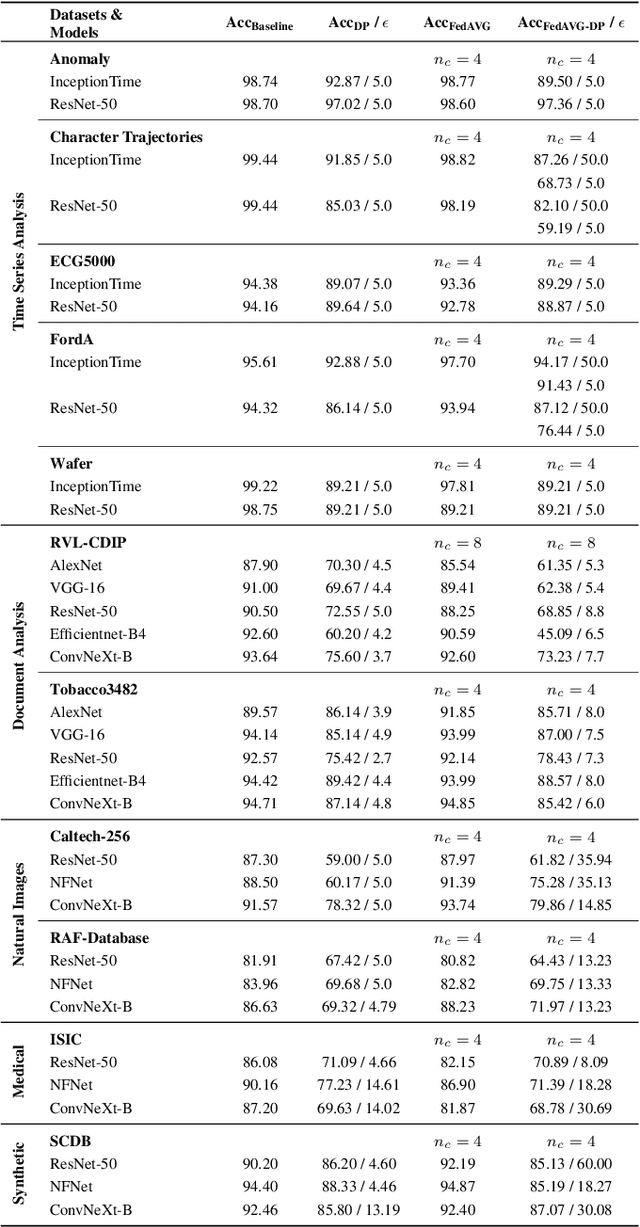

Since the mid-10s, the era of Deep Learning (DL) has continued to this day, bringing forth new superlatives and innovations each year. Nevertheless, the speed with which these innovations translate into real applications lags behind this fast pace. Safety-critical applications, in particular, underlie strict regulatory and ethical requirements which need to be taken care of and are still active areas of debate. eXplainable AI (XAI) and privacy-preserving machine learning (PPML) are both crucial research fields, aiming at mitigating some of the drawbacks of prevailing data-hungry black-box models in DL. Despite brisk research activity in the respective fields, no attention has yet been paid to their interaction. This work is the first to investigate the impact of private learning techniques on generated explanations for DL-based models. In an extensive experimental analysis covering various image and time series datasets from multiple domains, as well as varying privacy techniques, XAI methods, and model architectures, the effects of private training on generated explanations are studied. The findings suggest non-negligible changes in explanations through the introduction of privacy. Apart from reporting individual effects of PPML on XAI, the paper gives clear recommendations for the choice of techniques in real applications. By unveiling the interdependencies of these pivotal technologies, this work is a first step towards overcoming the remaining hurdles for practically applicable AI in safety-critical domains.