 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Holistic Evaluation of Language Models
Nov 16, 2022
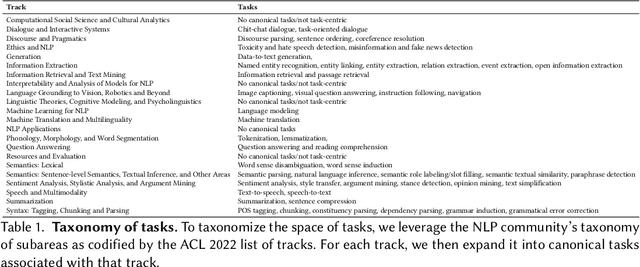



Language models (LMs) are becoming the foundation for almost all major language technologies, but their capabilities, limitations, and risks are not well understood. We present Holistic Evaluation of Language Models (HELM) to improve the transparency of language models. First, we taxonomize the vast space of potential scenarios (i.e. use cases) and metrics (i.e. desiderata) that are of interest for LMs. Then we select a broad subset based on coverage and feasibility, noting what's missing or underrepresented (e.g. question answering for neglected English dialects, metrics for trustworthiness). Second, we adopt a multi-metric approach: We measure 7 metrics (accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency) for each of 16 core scenarios when possible (87.5% of the time). This ensures metrics beyond accuracy don't fall to the wayside, and that trade-offs are clearly exposed. We also perform 7 targeted evaluations, based on 26 targeted scenarios, to analyze specific aspects (e.g. reasoning, disinformation). Third, we conduct a large-scale evaluation of 30 prominent language models (spanning open, limited-access, and closed models) on all 42 scenarios, 21 of which were not previously used in mainstream LM evaluation. Prior to HELM, models on average were evaluated on just 17.9% of the core HELM scenarios, with some prominent models not sharing a single scenario in common. We improve this to 96.0%: now all 30 models have been densely benchmarked on the same core scenarios and metrics under standardized conditions. Our evaluation surfaces 25 top-level findings. For full transparency, we release all raw model prompts and completions publicly for further analysis, as well as a general modular toolkit. We intend for HELM to be a living benchmark for the community, continuously updated with new scenarios, metrics, and models.
Definition and Quantification of Shock/Impact/Transient Vibrations
Nov 16, 2022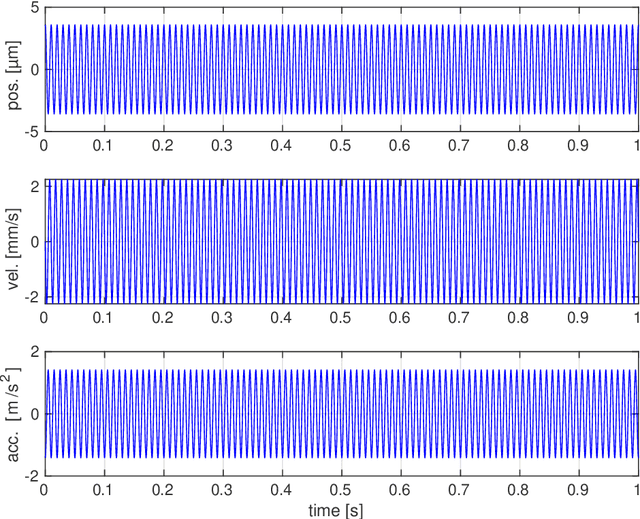
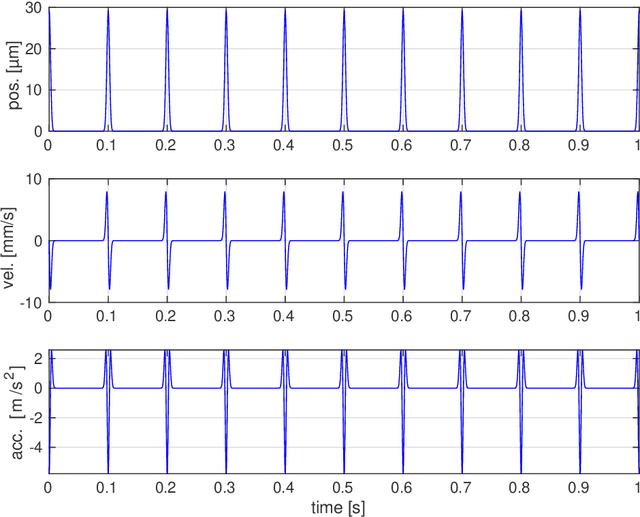
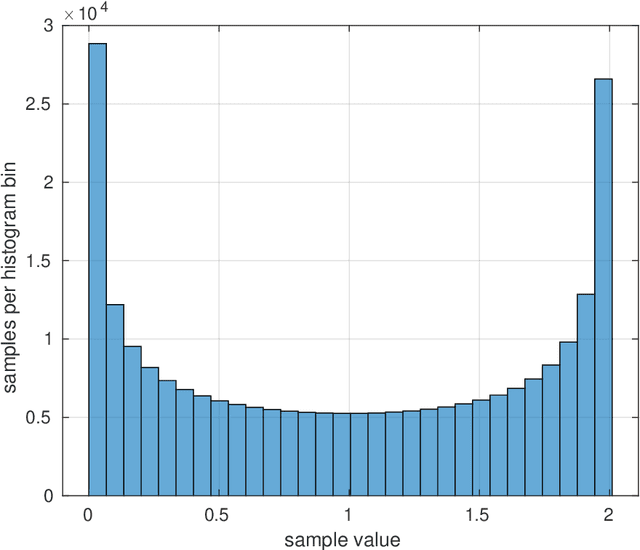
Vibration injury in the hand-arm system from hand-held machines is one of the most common occupational health injuries and causes severe and often chronic nerve and vascular injury to the operator. Machines emitting shock vibrations, e.g., impact wrenches have since long been identified as a special risk factor. In legislative and standard texts the terms shock, impact, and transient vibration are frequently used to underline the special risk associated with these kinds of vibrations. In spite of this, there is no mathematically stringent definition what a shock vibration is or how the amplitude of the shock is defined. This lack of definitions is the subject of this article. This document discusses a number of candidate definitions for a vibration shock index (VSI) that quantifies different vibration signals in terms of how localized they are in the time domain. The VSI is intended to be used to classify and compare different vibration sources. The VSI is independent of the vibration level, i.e., it is unchanged if the vibration signal is rescaled. The traditional root mean square method to determine the vibration level will not produce a value representative for the shocks occurring in a signal with high VSI. Thus, there is a need for a complementing quantification method for the localized signal parts. Possible definitions for such a vibration shock level (VSL) are suggested. A problem formulation is first stated together with a description of the approach used for designing the VSI and the VSL. After this, model signals are defined, which are used to discuss and evaluate the different candidate definitions. Then, a number of candidate definitions are discussed, leading up to a conclusion on which candidate definitions that are promising for experimental evaluation.
Audio-visual speech enhancement with a deep Kalman filter generative model
Nov 02, 2022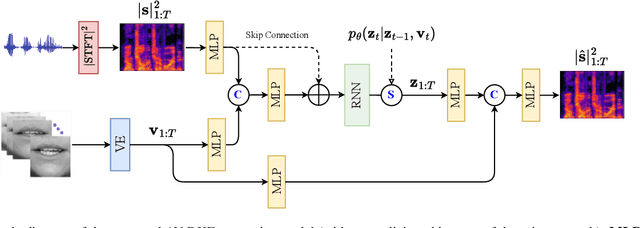
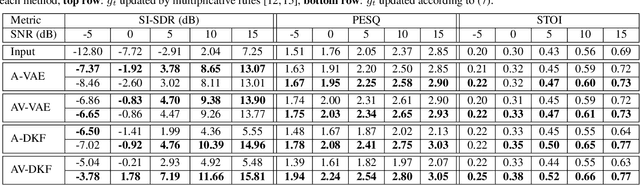
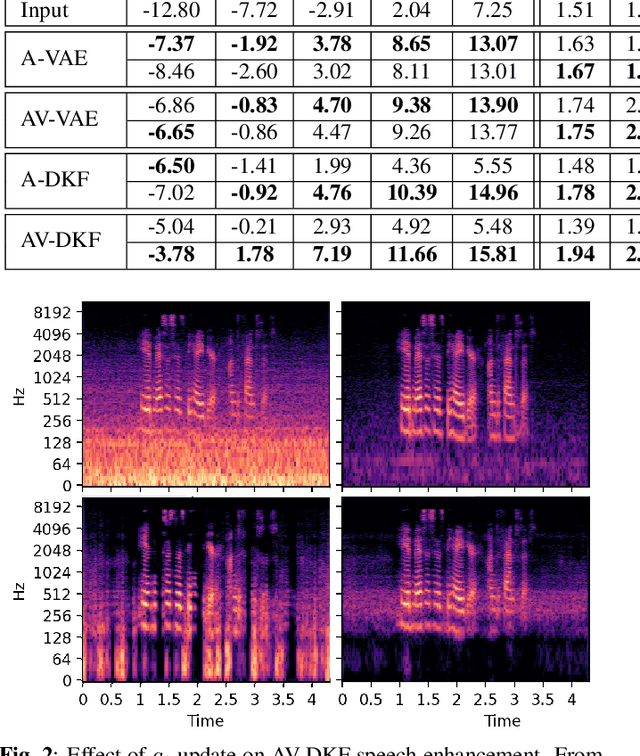
Deep latent variable generative models based on variational autoencoder (VAE) have shown promising performance for audiovisual speech enhancement (AVSE). The underlying idea is to learn a VAEbased audiovisual prior distribution for clean speech data, and then combine it with a statistical noise model to recover a speech signal from a noisy audio recording and video (lip images) of the target speaker. Existing generative models developed for AVSE do not take into account the sequential nature of speech data, which prevents them from fully incorporating the power of visual data. In this paper, we present an audiovisual deep Kalman filter (AV-DKF) generative model which assumes a first-order Markov chain model for the latent variables and effectively fuses audiovisual data. Moreover, we develop an efficient inference methodology to estimate speech signals at test time. We conduct a set of experiments to compare different variants of generative models for speech enhancement. The results demonstrate the superiority of the AV-DKF model compared with both its audio-only version and the non-sequential audio-only and audiovisual VAE-based models.
Neural Fourier Shift for Binaural Speech Rendering
Nov 02, 2022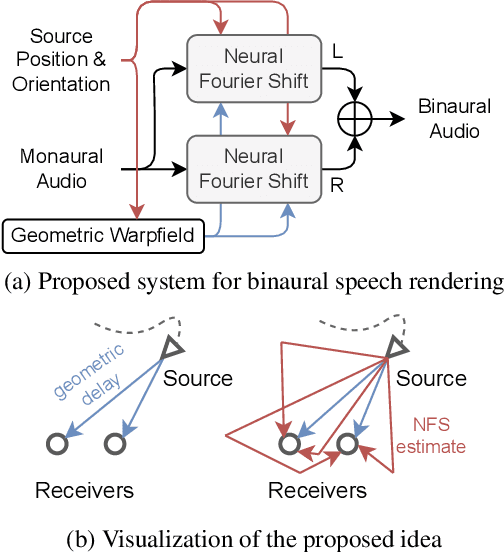
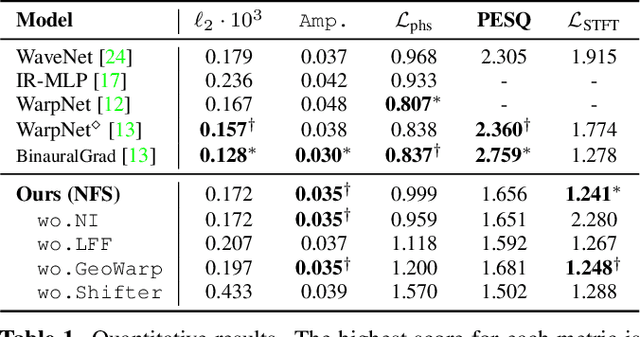
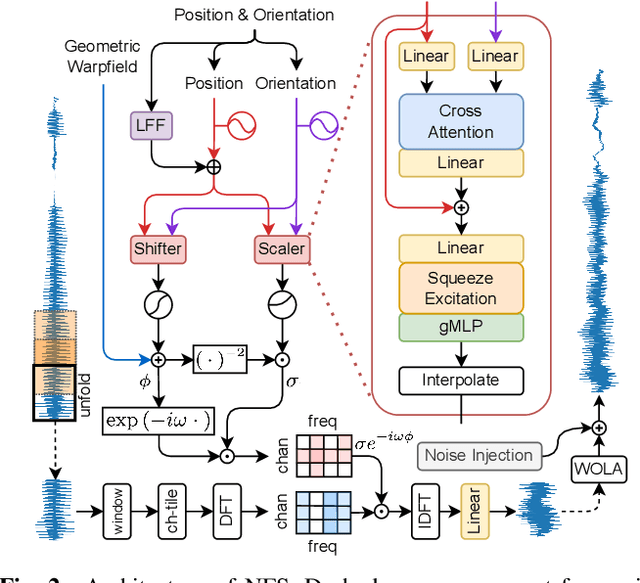

We present a neural network for rendering binaural speech from given monaural audio, position, and orientation of the source. Most of the previous works have focused on synthesizing binaural speeches by conditioning the positions and orientations in the feature space of convolutional neural networks. These synthesis approaches are powerful in estimating the target binaural speeches even for in-the-wild data but are difficult to generalize for rendering the audio from out-of-distribution domains. To alleviate this, we propose Neural Fourier Shift (NFS), a novel network architecture that enables binaural speech rendering in the Fourier space. Specifically, utilizing a geometric time delay based on the distance between the source and the receiver, NFS is trained to predict the delays and scales of various early reflections. NFS is efficient in both memory and computational cost, is interpretable, and operates independently of the source domain by its design. With up to 25 times lighter memory and 6 times fewer calculations, the experimental results show that NFS outperforms the previous studies on the benchmark dataset.
Long-Time Convergence and Propagation of Chaos for Nonlinear MCMC
Feb 11, 2022
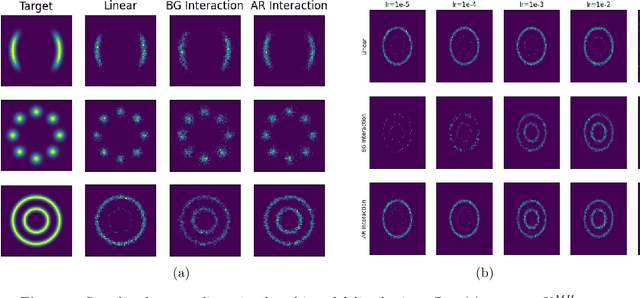
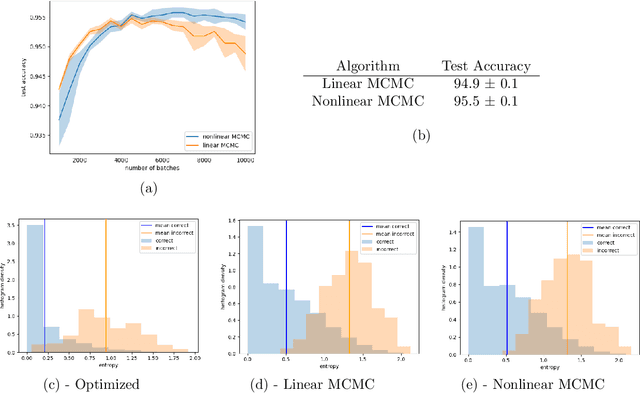
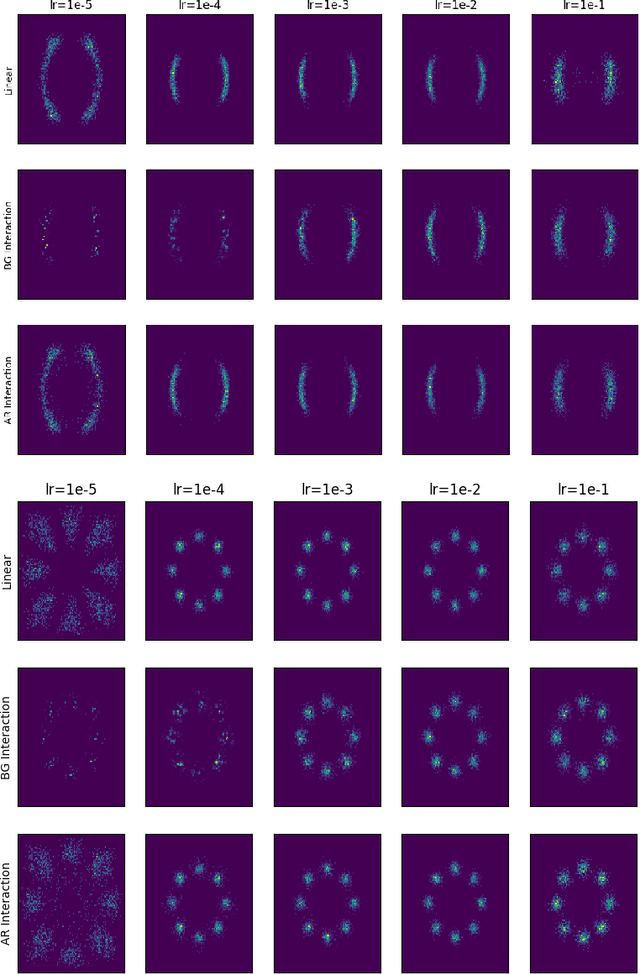
In this paper, we study the long-time convergence and uniform strong propagation of chaos for a class of nonlinear Markov chains for Markov chain Monte Carlo (MCMC). Our technique is quite simple, making use of recent contraction estimates for linear Markov kernels and basic techniques from Markov theory and analysis. Moreover, the same proof strategy applies to both the long-time convergence and propagation of chaos. We also show, via some experiments, that these nonlinear MCMC techniques are viable for use in real-world high-dimensional inference such as Bayesian neural networks.
Uplift and Upsample: Efficient 3D Human Pose Estimation with Uplifting Transformers
Oct 12, 2022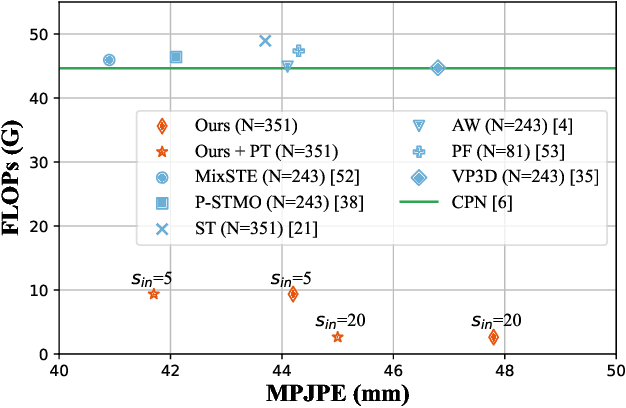
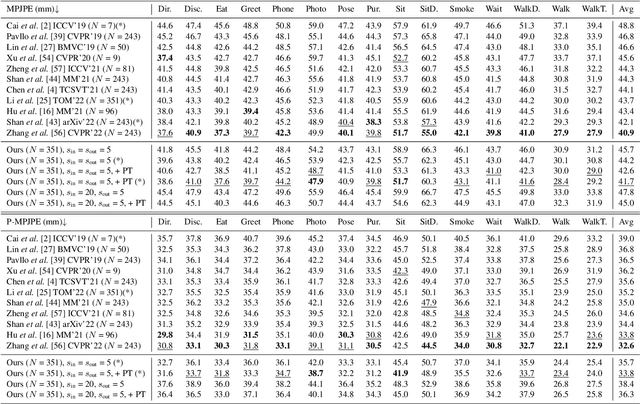
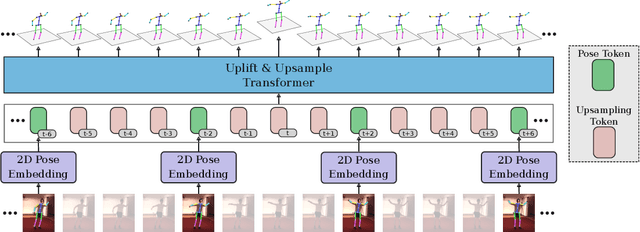
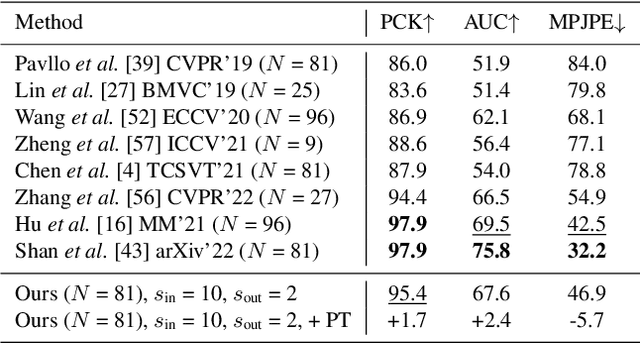
The state-of-the-art for monocular 3D human pose estimation in videos is dominated by the paradigm of 2D-to-3D pose uplifting. While the uplifting methods themselves are rather efficient, the true computational complexity depends on the per-frame 2D pose estimation. In this paper, we present a Transformer-based pose uplifting scheme that can operate on temporally sparse 2D pose sequences but still produce temporally dense 3D pose estimates. We show how masked token modeling can be utilized for temporal upsampling within Transformer blocks. This allows to decouple the sampling rate of input 2D poses and the target frame rate of the video and drastically decreases the total computational complexity. Additionally, we explore the option of pre-training on large motion capture archives, which has been largely neglected so far. We evaluate our method on two popular benchmark datasets: Human3.6M and MPI-INF-3DHP. With an MPJPE of 45.0 mm and 46.9 mm, respectively, our proposed method can compete with the state-of-the-art while reducing inference time by a factor of 12. This enables real-time throughput with variable consumer hardware in stationary and mobile applications. We release our code and models at https://github.com/goldbricklemon/uplift-upsample-3dhpe
ViewBirdiformer: Learning to recover ground-plane crowd trajectories and ego-motion from a single ego-centric view
Oct 12, 2022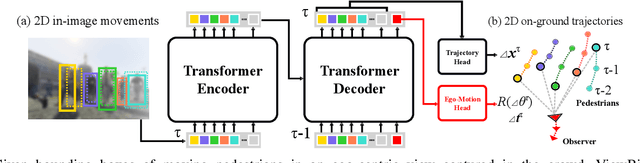
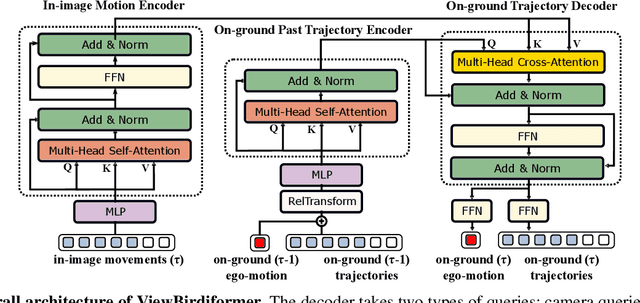
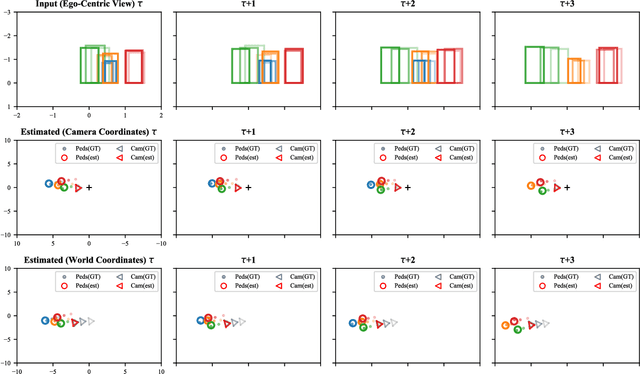
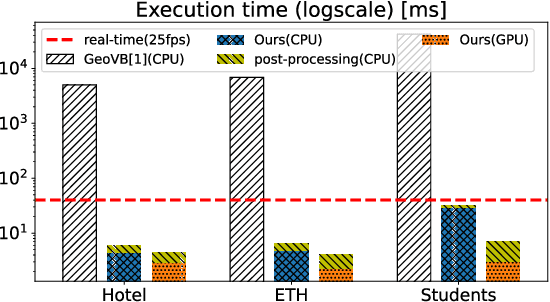
We introduce a novel learning-based method for view birdification, the task of recovering ground-plane trajectories of pedestrians of a crowd and their observer in the same crowd just from the observed ego-centric video. View birdification becomes essential for mobile robot navigation and localization in dense crowds where the static background is hard to see and reliably track. It is challenging mainly for two reasons; i) absolute trajectories of pedestrians are entangled with the movement of the observer which needs to be decoupled from their observed relative movements in the ego-centric video, and ii) a crowd motion model describing the pedestrian movement interactions is specific to the scene yet unknown a priori. For this, we introduce a Transformer-based network referred to as ViewBirdiformer which implicitly models the crowd motion through self-attention and decomposes relative 2D movement observations onto the ground-plane trajectories of the crowd and the camera through cross-attention between views. Most important, ViewBirdiformer achieves view birdification in a single forward pass which opens the door to accurate real-time, always-on situational awareness. Extensive experimental results demonstrate that ViewBirdiformer achieves accuracy similar to or better than state-of-the-art with three orders of magnitude reduction in execution time.
BoundED: Neural Boundary and Edge Detection in 3D Point Clouds via Local Neighborhood Statistics
Oct 24, 2022
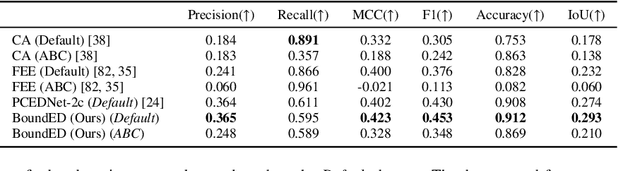
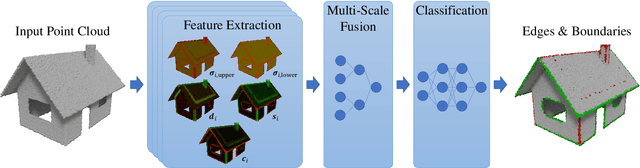
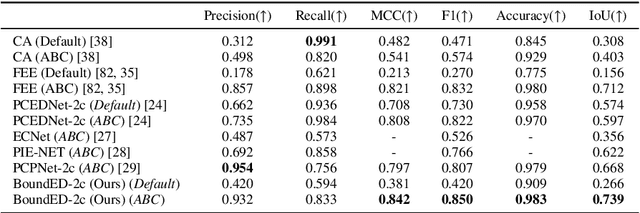
Extracting high-level structural information from 3D point clouds is challenging but essential for tasks like urban planning or autonomous driving requiring an advanced understanding of the scene at hand. Existing approaches are still not able to produce high-quality results consistently while being fast enough to be deployed in scenarios requiring interactivity. We propose to utilize a novel set of features describing the local neighborhood on a per-point basis via first and second order statistics as input for a simple and compact classification network to distinguish between non-edge, sharp-edge, and boundary points in the given data. Leveraging this feature embedding enables our algorithm to outperform the state-of-the-art techniques in terms of quality and processing time.
A Scalable Data-Driven Technique for Joint Evacuation Routing and Scheduling Problems
Sep 12, 2022
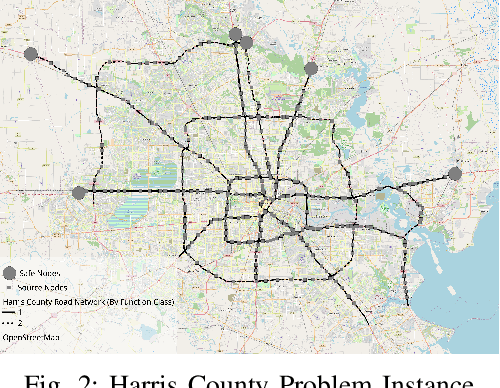
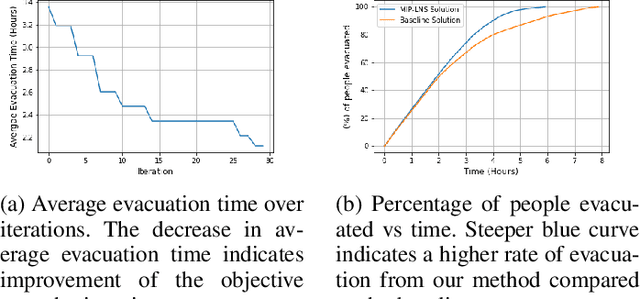
Evacuation planning is a crucial part of disaster management where the goal is to relocate people to safety and minimize casualties. Every evacuation plan has two essential components: routing and scheduling. However, joint optimization of these two components with objectives such as minimizing average evacuation time or evacuation completion time, is a computationally hard problem. To approach it, we present MIP-LNS, a scalable optimization method that combines heuristic search with mathematical optimization and can optimize a variety of objective functions. We use real-world road network and population data from Harris County in Houston, Texas, and apply MIP-LNS to find evacuation routes and schedule for the area. We show that, within a given time limit, our proposed method finds better solutions than existing methods in terms of average evacuation time, evacuation completion time and optimality guarantee of the solutions. We perform agent-based simulations of evacuation in our study area to demonstrate the efficacy and robustness of our solution. We show that our prescribed evacuation plan remains effective even if the evacuees deviate from the suggested schedule upto a certain extent. We also examine how evacuation plans are affected by road failures. Our results show that MIP-LNS can use information regarding estimated deadline of roads to come up with better evacuation plans in terms evacuating more people successfully and conveniently.
Micro and Macro Level Graph Modeling for Graph Variational Auto-Encoders
Oct 30, 2022
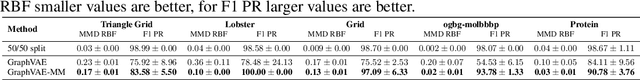
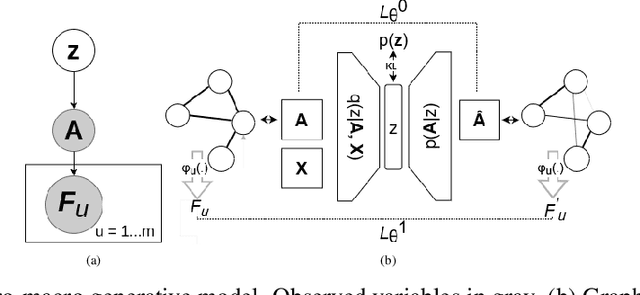
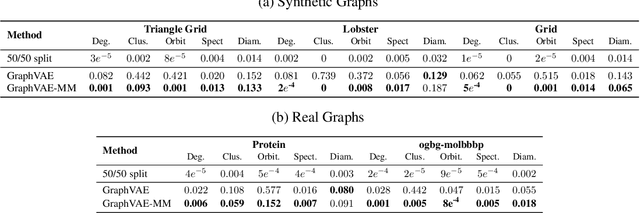
Generative models for graph data are an important research topic in machine learning. Graph data comprise two levels that are typically analyzed separately: node-level properties such as the existence of a link between a pair of nodes, and global aggregate graph-level statistics, such as motif counts. This paper proposes a new multi-level framework that jointly models node-level properties and graph-level statistics, as mutually reinforcing sources of information. We introduce a new micro-macro training objective for graph generation that combines node-level and graph-level losses. We utilize the micro-macro objective to improve graph generation with a GraphVAE, a well-established model based on graph-level latent variables, that provides fast training and generation time for medium-sized graphs. Our experiments show that adding micro-macro modeling to the GraphVAE model improves graph quality scores up to 2 orders of magnitude on five benchmark datasets, while maintaining the GraphVAE generation speed advantage.