 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sparse Instance Activation for Real-Time Instance Segmentation
Mar 24, 2022
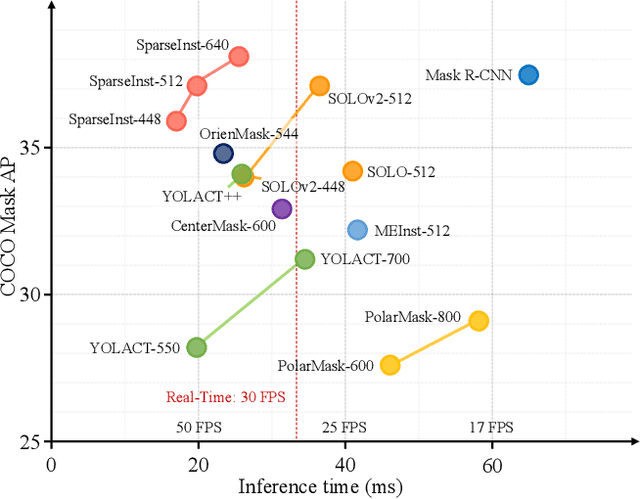
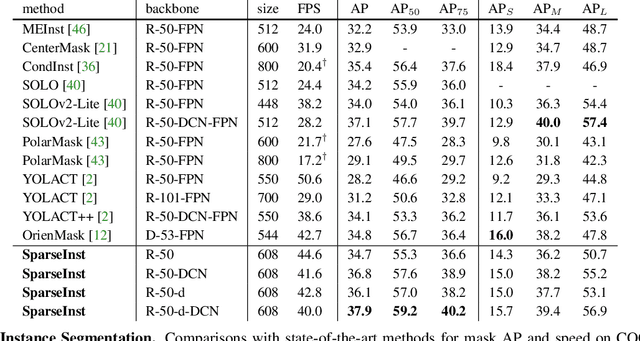
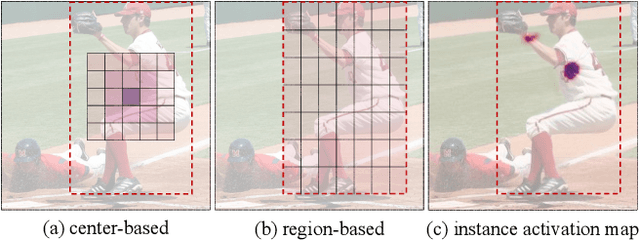
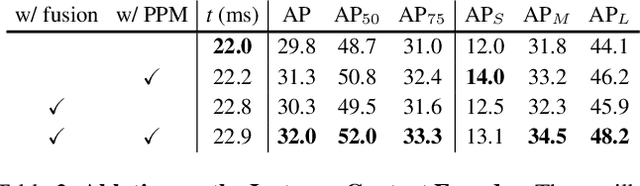
In this paper, we propose a conceptually novel, efficient, and fully convolutional framework for real-time instance segmentation. Previously, most instance segmentation methods heavily rely on object detection and perform mask prediction based on bounding boxes or dense centers. In contrast, we propose a sparse set of instance activation maps, as a new object representation, to highlight informative regions for each foreground object. Then instance-level features are obtained by aggregating features according to the highlighted regions for recognition and segmentation. Moreover, based on bipartite matching, the instance activation maps can predict objects in a one-to-one style, thus avoiding non-maximum suppression (NMS) in post-processing. Owing to the simple yet effective designs with instance activation maps, SparseInst has extremely fast inference speed and achieves 40 FPS and 37.9 AP on the COCO benchmark, which significantly outperforms the counterparts in terms of speed and accuracy. Code and models are available at https://github.com/hustvl/SparseInst.
Effective Early Stopping of Point Cloud Neural Networks
Sep 30, 2022Early stopping techniques can be utilized to decrease the time cost, however currently the ultimate goal of early stopping techniques is closely related to the accuracy upgrade or the ability of the neural network to generalize better on unseen data without being large or complex in structure and not directly with its efficiency. Time efficiency is a critical factor in neural networks, especially when dealing with the segmentation of 3D point cloud data, not only because a neural network itself is computationally expensive, but also because point clouds are large and noisy data, making learning processes even more costly. In this paper, we propose a new early stopping technique based on fundamental mathematics aiming to upgrade the trade-off between the learning efficiency and accuracy of neural networks dealing with 3D point clouds. Our results show that by employing our early stopping technique in four distinct and highly utilized neural networks in segmenting 3D point clouds, the training time efficiency of the models is greatly improved, with efficiency gain values reaching up to 94\%, while the models achieving in just a few epochs approximately similar segmentation accuracy metric values like the ones that are obtained in the training of the neural networks in 200 epochs. Also, our proposal outperforms four conventional early stopping approaches in segmentation accuracy, implying a promising innovative early stopping technique in point cloud segmentation.
APT: Adaptive Perceptual quality based camera Tuning using reinforcement learning
Nov 15, 2022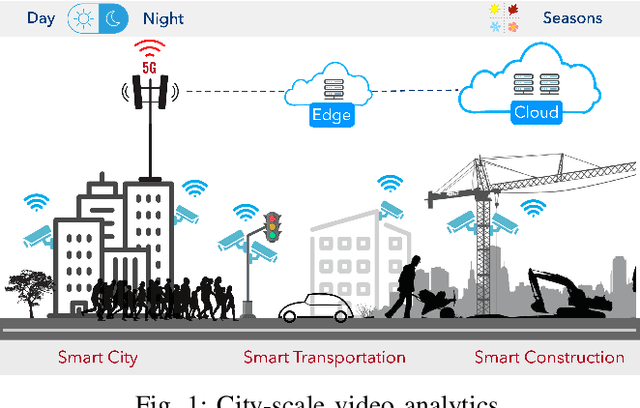
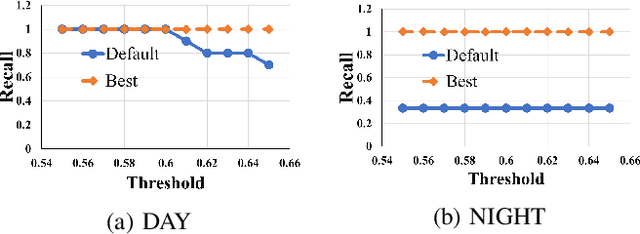
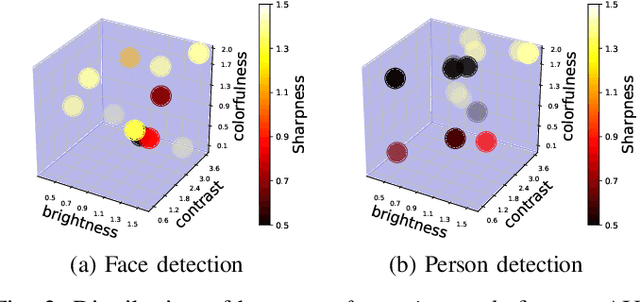
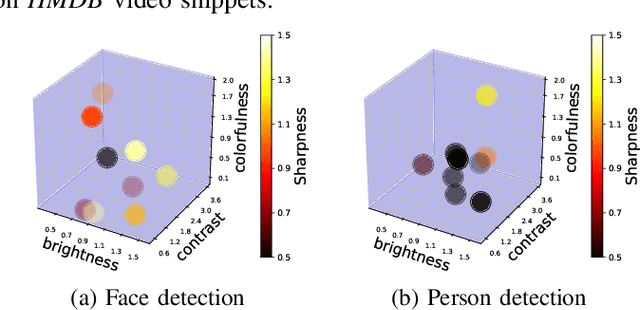
Cameras are increasingly being deployed in cities, enterprises and roads world-wide to enable many applications in public safety, intelligent transportation, retail, healthcare and manufacturing. Often, after initial deployment of the cameras, the environmental conditions and the scenes around these cameras change, and our experiments show that these changes can adversely impact the accuracy of insights from video analytics. This is because the camera parameter settings, though optimal at deployment time, are not the best settings for good-quality video capture as the environmental conditions and scenes around a camera change during operation. Capturing poor-quality video adversely affects the accuracy of analytics. To mitigate the loss in accuracy of insights, we propose a novel, reinforcement-learning based system APT that dynamically, and remotely (over 5G networks), tunes the camera parameters, to ensure a high-quality video capture, which mitigates any loss in accuracy of video analytics. As a result, such tuning restores the accuracy of insights when environmental conditions or scene content change. APT uses reinforcement learning, with no-reference perceptual quality estimation as the reward function. We conducted extensive real-world experiments, where we simultaneously deployed two cameras side-by-side overlooking an enterprise parking lot (one camera only has manufacturer-suggested default setting, while the other camera is dynamically tuned by APT during operation). Our experiments demonstrated that due to dynamic tuning by APT, the analytics insights are consistently better at all times of the day: the accuracy of object detection video analytics application was improved on average by ~ 42%. Since our reward function is independent of any analytics task, APT can be readily used for different video analytics tasks.
A Real Time 1280x720 Object Detection Chip With 585MB/s Memory Traffic
May 02, 2022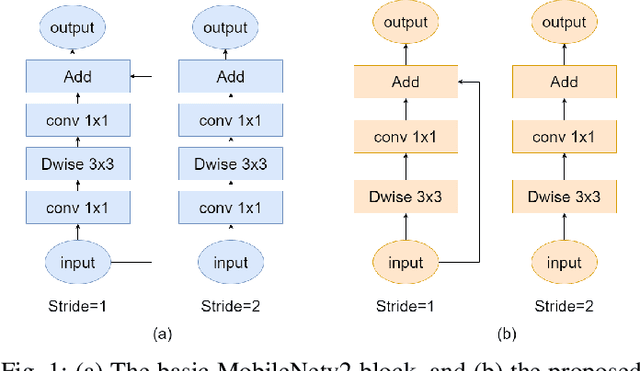
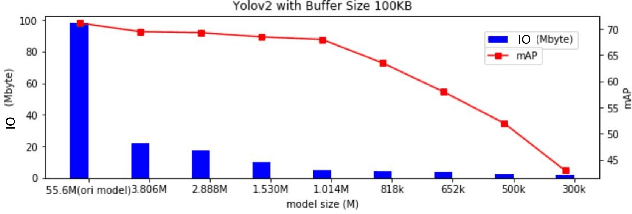
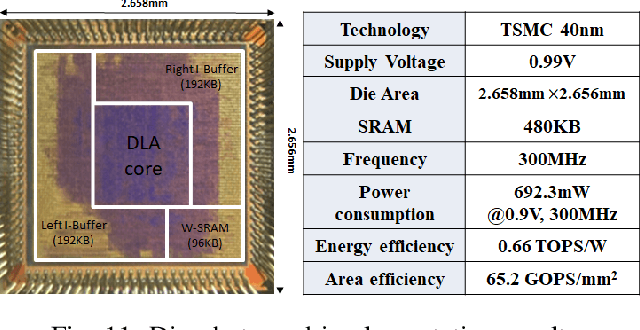
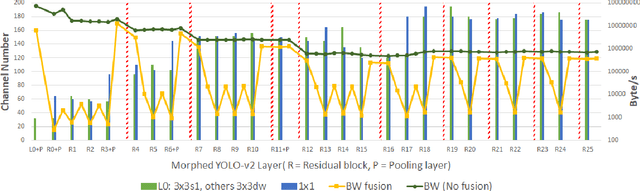
Memory bandwidth has become the real-time bottleneck of current deep learning accelerators (DLA), particularly for high definition (HD) object detection. Under resource constraints, this paper proposes a low memory traffic DLA chip with joint hardware and software optimization. To maximize hardware utilization under memory bandwidth, we morph and fuse the object detection model into a group fusion-ready model to reduce intermediate data access. This reduces the YOLOv2's feature memory traffic from 2.9 GB/s to 0.15 GB/s. To support group fusion, our previous DLA based hardware employes a unified buffer with write-masking for simple layer-by-layer processing in a fusion group. When compared to our previous DLA with the same PE numbers, the chip implemented in a TSMC 40nm process supports 1280x720@30FPS object detection and consumes 7.9X less external DRAM access energy, from 2607 mJ to 327.6 mJ.
HAQJSK: Hierarchical-Aligned Quantum Jensen-Shannon Kernels for Graph Classification
Nov 05, 2022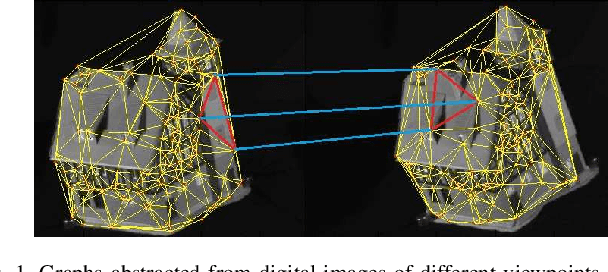
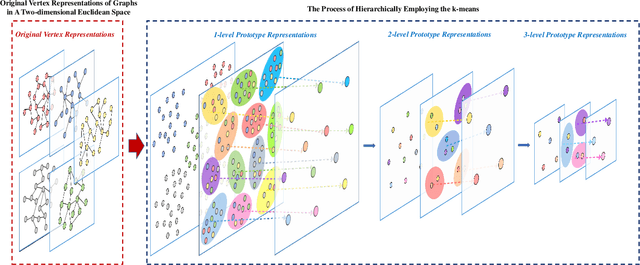
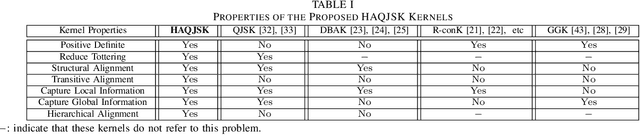
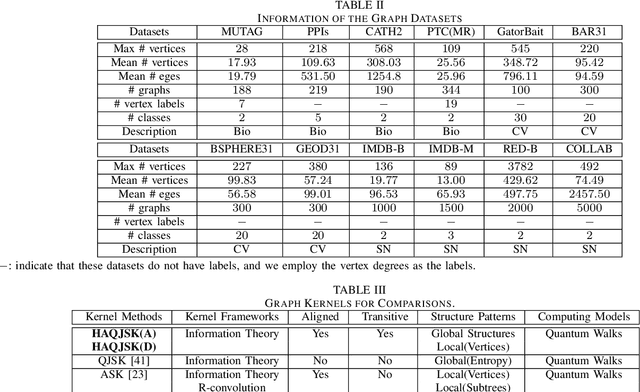
In this work, we propose a family of novel quantum kernels, namely the Hierarchical Aligned Quantum Jensen-Shannon Kernels (HAQJSK), for un-attributed graphs. Different from most existing classical graph kernels, the proposed HAQJSK kernels can incorporate hierarchical aligned structure information between graphs and transform graphs of random sizes into fixed-sized aligned graph structures, i.e., the Hierarchical Transitive Aligned Adjacency Matrix of vertices and the Hierarchical Transitive Aligned Density Matrix of the Continuous-Time Quantum Walk (CTQW). For a pair of graphs to hand, the resulting HAQJSK kernels are defined by measuring the Quantum Jensen-Shannon Divergence (QJSD) between their transitive aligned graph structures. We show that the proposed HAQJSK kernels not only reflect richer intrinsic global graph characteristics in terms of the CTQW, but also address the drawback of neglecting structural correspondence information arising in most existing R-convolution kernels. Furthermore, unlike the previous Quantum Jensen-Shannon Kernels associated with the QJSD and the CTQW, the proposed HAQJSK kernels can simultaneously guarantee the properties of permutation invariant and positive definiteness, explaining the theoretical advantages of the HAQJSK kernels. Experiments indicate the effectiveness of the proposed kernels.
An optimal open-loop strategy for handling a flexible beam with a robot manipulator
Oct 02, 2022
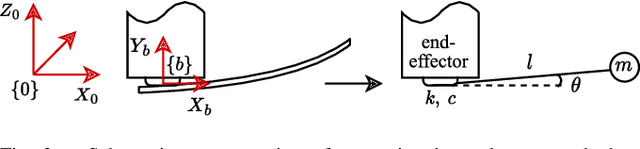
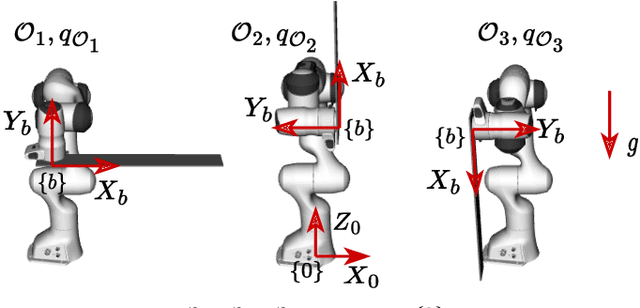
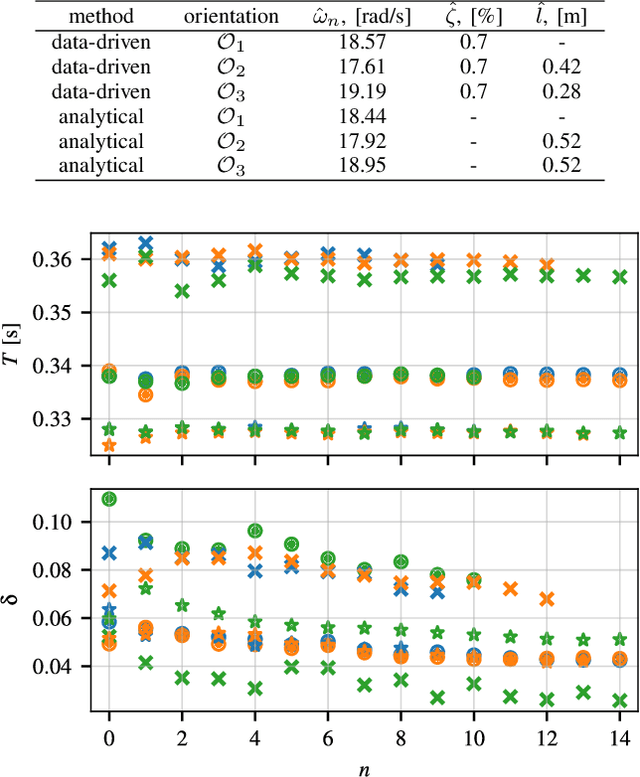
Fast and safe manipulation of flexible objects with a robot manipulator necessitates measures to cope with vibrations. Existing approaches either increase the task execution time or require complex models and/or additional instrumentation to measure vibrations. This paper develops a model-based method that overcomes these limitations. It relies on a simple pendulum-like model for modeling the beam, open-loop optimal control for suppressing vibrations, and does not require any exteroceptive sensors. We experimentally show that the proposed method drastically reduces residual vibrations -- at least 90% -- and outperforms the commonly used input shaping (IS) for the same execution time. Besides, our method can also execute the task faster than IS with a minor reduction in vibration suppression performance. The proposed method facilitates the development of new solutions to a wide range of tasks that involve dynamic manipulation of flexible objects.
Continuous longitudinal fetus brain atlas construction via implicit neural representation
Sep 14, 2022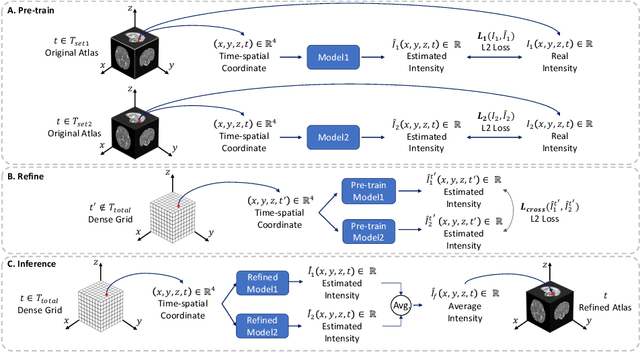
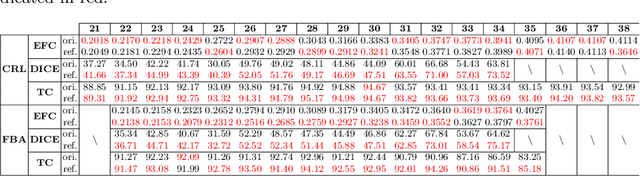
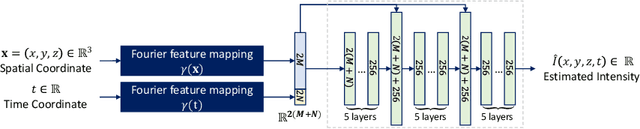
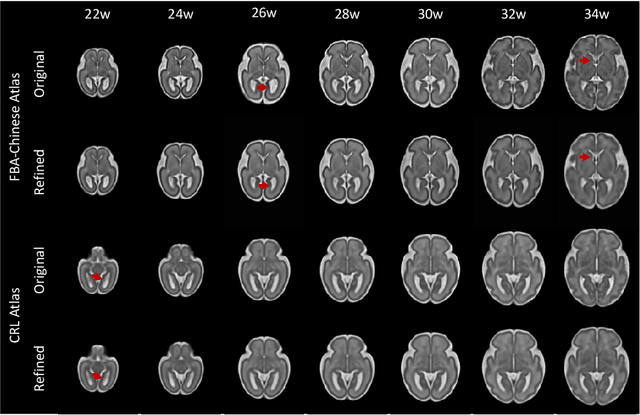
Longitudinal fetal brain atlas is a powerful tool for understanding and characterizing the complex process of fetus brain development. Existing fetus brain atlases are typically constructed by averaged brain images on discrete time points independently over time. Due to the differences in onto-genetic trends among samples at different time points, the resulting atlases suffer from temporal inconsistency, which may lead to estimating error of the brain developmental characteristic parameters along the timeline. To this end, we proposed a multi-stage deep-learning framework to tackle the time inconsistency issue as a 4D (3D brain volume + 1D age) image data denoising task. Using implicit neural representation, we construct a continuous and noise-free longitudinal fetus brain atlas as a function of the 4D spatial-temporal coordinate. Experimental results on two public fetal brain atlases (CRL and FBA-Chinese atlases) show that the proposed method can significantly improve the atlas temporal consistency while maintaining good fetus brain structure representation. In addition, the continuous longitudinal fetus brain atlases can also be extensively applied to generate finer 4D atlases in both spatial and temporal resolution.
Time-Aware Neighbor Sampling for Temporal Graph Networks
Dec 18, 2021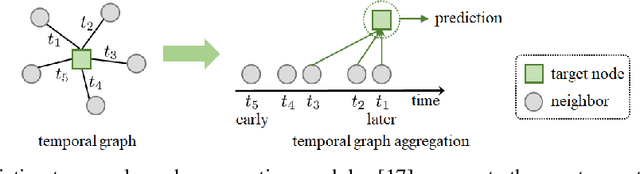


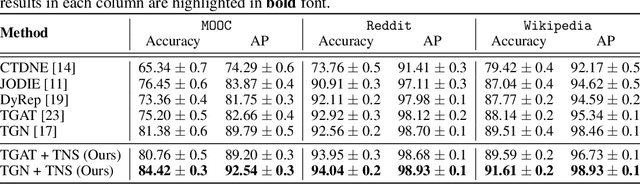
We present a new neighbor sampling method on temporal graphs. In a temporal graph, predicting different nodes' time-varying properties can require the receptive neighborhood of various temporal scales. In this work, we propose the TNS (Time-aware Neighbor Sampling) method: TNS learns from temporal information to provide an adaptive receptive neighborhood for every node at any time. Learning how to sample neighbors is non-trivial, since the neighbor indices in time order are discrete and not differentiable. To address this challenge, we transform neighbor indices from discrete values to continuous ones by interpolating the neighbors' messages. TNS can be flexibly incorporated into popular temporal graph networks to improve their effectiveness without increasing their time complexity. TNS can be trained in an end-to-end manner. It needs no extra supervision and is automatically and implicitly guided to sample the neighbors that are most beneficial for prediction. Empirical results on multiple standard datasets show that TNS yields significant gains on edge prediction and node classification.
Time Masking for Temporal Language Models
Oct 22, 2021

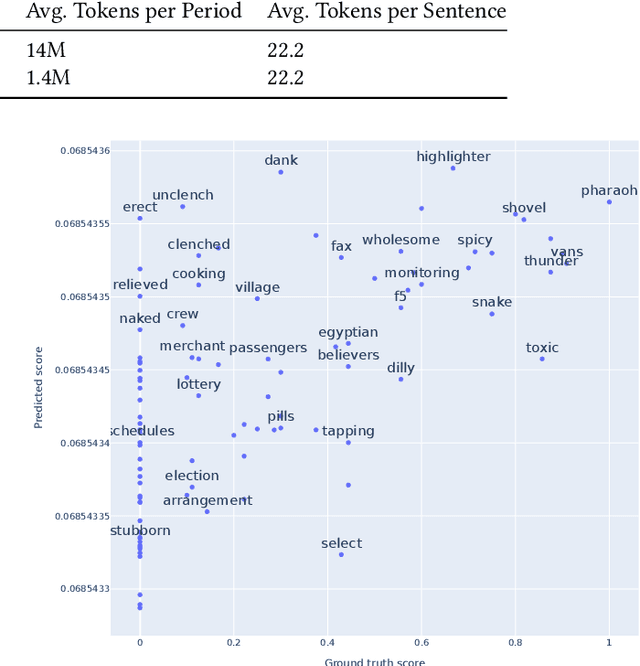
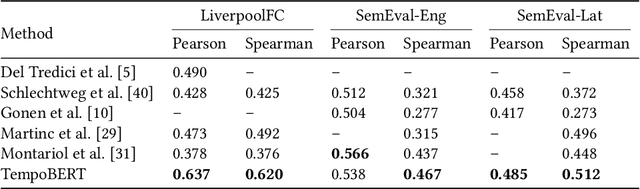
Our world is constantly evolving, and so is the content on the web. Consequently, our languages, often said to mirror the world, are dynamic in nature. However, most current contextual language models are static and cannot adapt to changes over time. In this work, we propose a temporal contextual language model called TempoBERT, which uses time as an additional context of texts. Our technique is based on modifying texts with temporal information and performing time masking - specific masking for the supplementary time information. We leverage our approach for the tasks of semantic change detection and sentence time prediction, experimenting on diverse datasets in terms of time, size, genre, and language. Our extensive evaluation shows that both tasks benefit from exploiting time masking.
Detecting Disengagement in Virtual Learning as an Anomaly
Nov 13, 2022
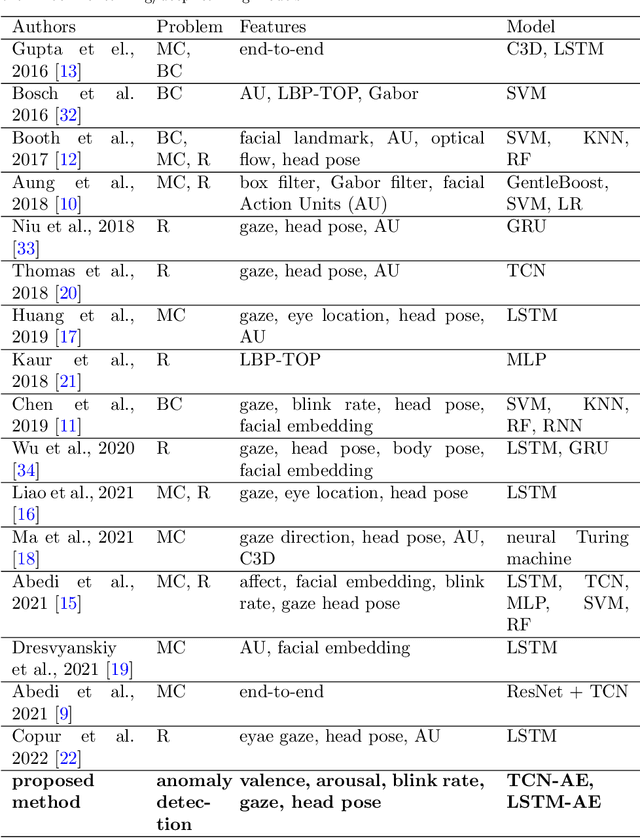
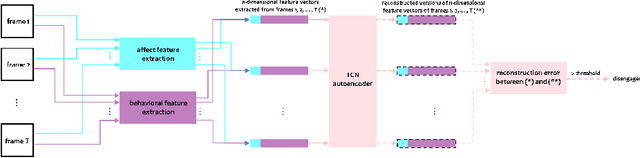

Student engagement is an important factor in meeting the goals of virtual learning programs. Automatic measurement of student engagement provides helpful information for instructors to meet learning program objectives and individualize program delivery. Many existing approaches solve video-based engagement measurement using the traditional frameworks of binary classification (classifying video snippets into engaged or disengaged classes), multi-class classification (classifying video snippets into multiple classes corresponding to different levels of engagement), or regression (estimating a continuous value corresponding to the level of engagement). However, we observe that while the engagement behaviour is mostly well-defined (e.g., focused, not distracted), disengagement can be expressed in various ways. In addition, in some cases, the data for disengaged classes may not be sufficient to train generalizable binary or multi-class classifiers. To handle this situation, in this paper, for the first time, we formulate detecting disengagement in virtual learning as an anomaly detection problem. We design various autoencoders, including temporal convolutional network autoencoder, long-short-term memory autoencoder, and feedforward autoencoder using different behavioral and affect features for video-based student disengagement detection. The result of our experiments on two publicly available student engagement datasets, DAiSEE and EmotiW, shows the superiority of the proposed approach for disengagement detection as an anomaly compared to binary classifiers for classifying videos into engaged versus disengaged classes (with an average improvement of 9% on the area under the curve of the receiver operating characteristic curve and 22% on the area under the curve of the precision-recall curve).