 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Frustratingly Easy Sentiment Analysis of Text Streams: Generating High-Quality Emotion Arcs Using Emotion Lexicons
Oct 13, 2022
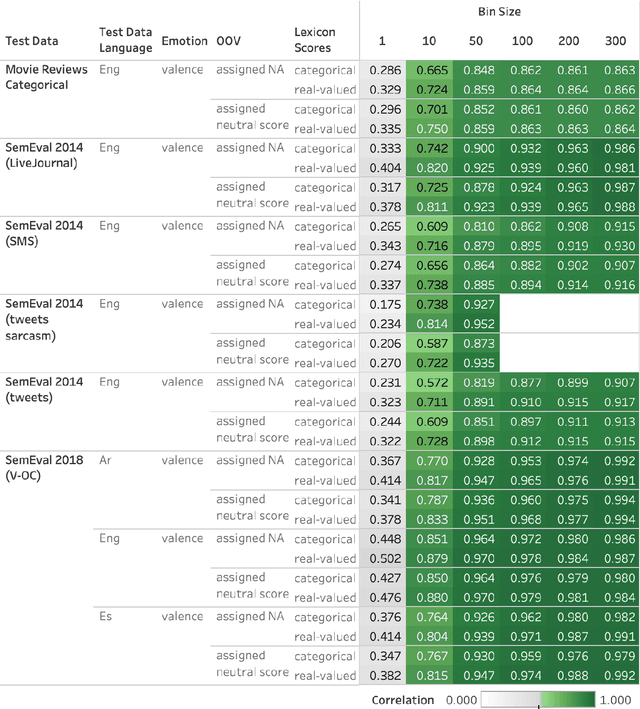

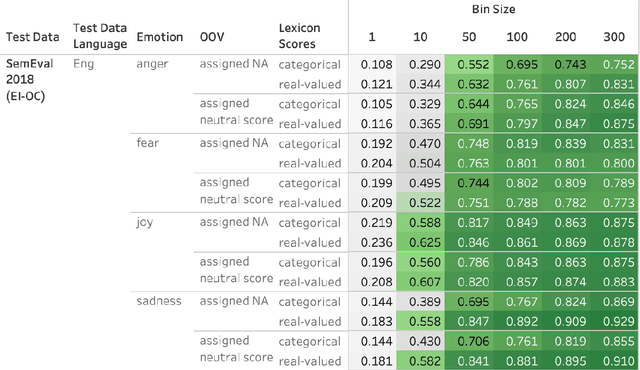
Automatically generated emotion arcs -- that capture how an individual or a population feels over time -- are widely used in industry and research. However, there is little work on evaluating the generated arcs. This is in part due to the difficulty of establishing the true (gold) emotion arc. Our work, for the first time, systematically and quantitatively evaluates automatically generated emotion arcs. We also compare two common ways of generating emotion arcs: Machine-Learning (ML) models and Lexicon-Only (LexO) methods. Using a number of diverse datasets, we systematically study the relationship between the quality of an emotion lexicon and the quality of the emotion arc that can be generated with it. We also study the relationship between the quality of an instance-level emotion detection system (say from an ML model) and the quality of emotion arcs that can be generated with it. We show that despite being markedly poor at instance level, LexO methods are highly accurate at generating emotion arcs by aggregating information from hundreds of instances. This has wide-spread implications for commercial development, as well as research in psychology, public health, digital humanities, etc. that values simple interpretable methods and disprefers the need for domain-specific training data, programming expertise, and high-carbon-footprint models.
Design and Evaluation of a Generic Visual SLAM Framework for Multi-Camera Systems
Oct 13, 2022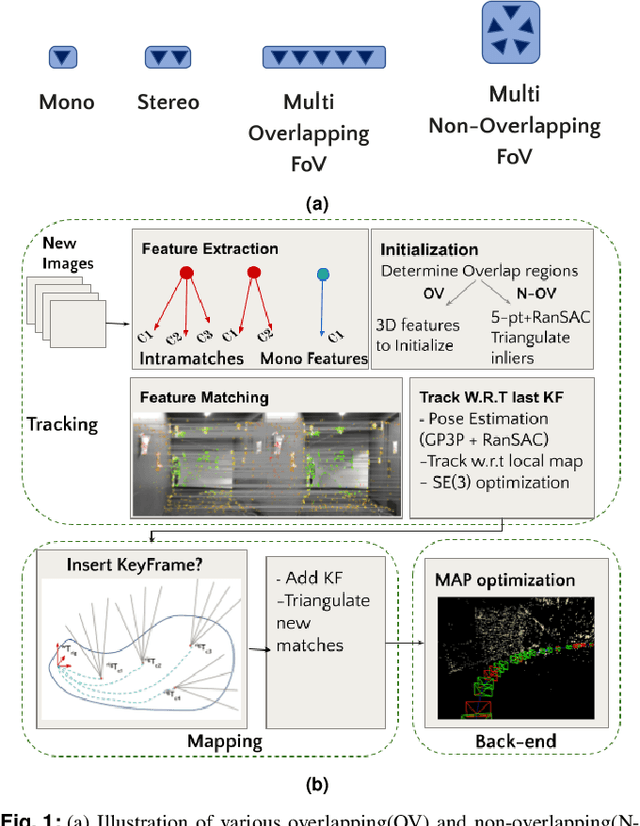

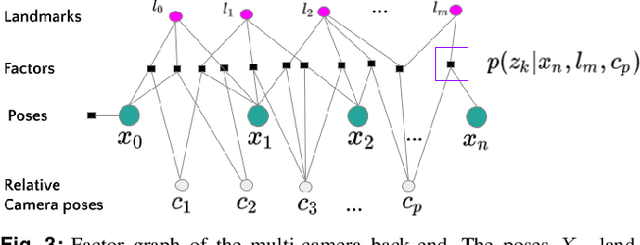

Multi-camera systems have been shown to improve the accuracy and robustness of SLAM estimates, yet state-of-the-art SLAM systems predominantly support monocular or stereo setups. This paper presents a generic sparse visual SLAM framework capable of running on any number of cameras and in any arrangement. Our SLAM system uses the generalized camera model, which allows us to represent an arbitrary multi-camera system as a single imaging device. Additionally, it takes advantage of the overlapping fields of view (FoV) by extracting cross-matched features across cameras in the rig. This limits the linear rise in the number of features with the number of cameras and keeps the computational load in check while enabling an accurate representation of the scene. We evaluate our method in terms of accuracy, robustness, and run time on indoor and outdoor datasets that include challenging real-world scenarios such as narrow corridors, featureless spaces, and dynamic objects. We show that our system can adapt to different camera configurations and allows real-time execution for typical robotic applications. Finally, we benchmark the impact of the critical design parameters - the number of cameras and the overlap between their FoV that define the camera configuration for SLAM. All our software and datasets are freely available for further research.
DiffusER: Discrete Diffusion via Edit-based Reconstruction
Oct 30, 2022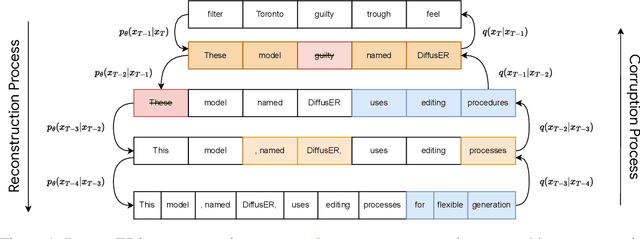

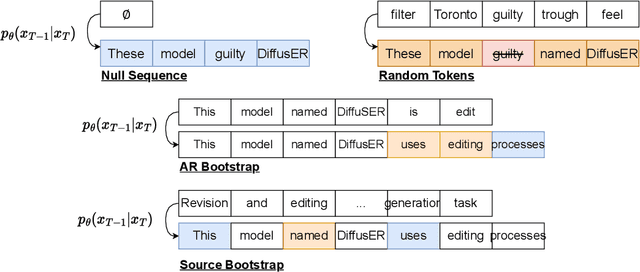
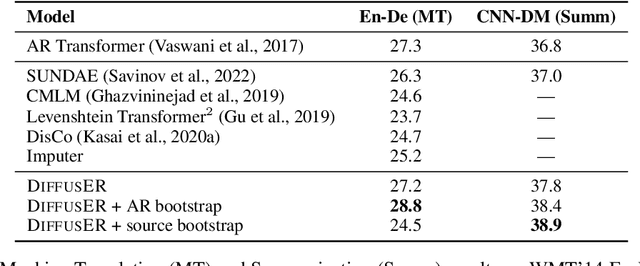
In text generation, models that generate text from scratch one token at a time are currently the dominant paradigm. Despite being performant, these models lack the ability to revise existing text, which limits their usability in many practical scenarios. We look to address this, with DiffusER (Diffusion via Edit-based Reconstruction), a new edit-based generative model for text based on denoising diffusion models -- a class of models that use a Markov chain of denoising steps to incrementally generate data. DiffusER is not only a strong generative model in general, rivalling autoregressive models on several tasks spanning machine translation, summarization, and style transfer; it can also perform other varieties of generation that standard autoregressive models are not well-suited for. For instance, we demonstrate that DiffusER makes it possible for a user to condition generation on a prototype, or an incomplete sequence, and continue revising based on previous edit steps.
Deep Appearance Prefiltering
Nov 08, 2022


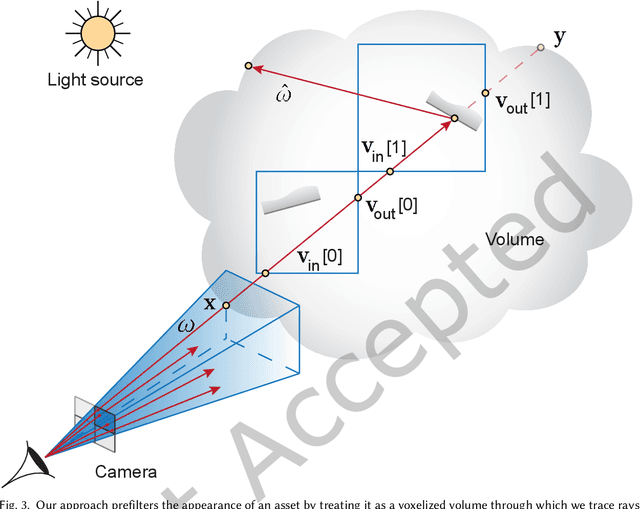
Physically based rendering of complex scenes can be prohibitively costly with a potentially unbounded and uneven distribution of complexity across the rendered image. The goal of an ideal level of detail (LoD) method is to make rendering costs independent of the 3D scene complexity, while preserving the appearance of the scene. However, current prefiltering LoD methods are limited in the appearances they can support due to their reliance of approximate models and other heuristics. We propose the first comprehensive multi-scale LoD framework for prefiltering 3D environments with complex geometry and materials (e.g., the Disney BRDF), while maintaining the appearance with respect to the ray-traced reference. Using a multi-scale hierarchy of the scene, we perform a data-driven prefiltering step to obtain an appearance phase function and directional coverage mask at each scale. At the heart of our approach is a novel neural representation that encodes this information into a compact latent form that is easy to decode inside a physically based renderer. Once a scene is baked out, our method requires no original geometry, materials, or textures at render time. We demonstrate that our approach compares favorably to state-of-the-art prefiltering methods and achieves considerable savings in memory for complex scenes.
Multiple Signal Classification Based Joint Communication and Sensing System
Nov 08, 2022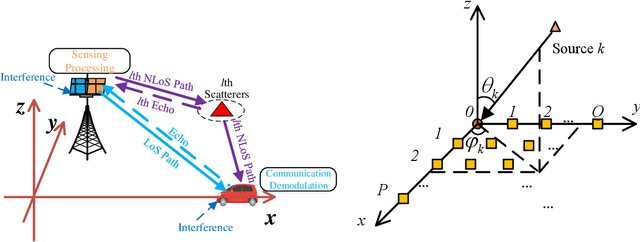
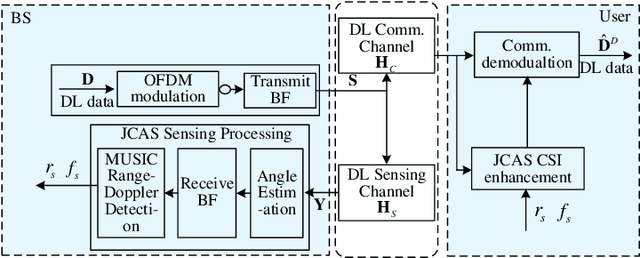
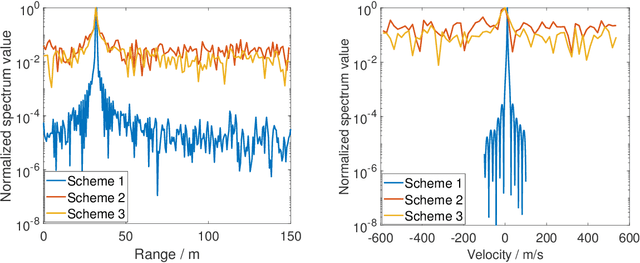
Joint communication and sensing (JCS) has become a promising technology for mobile networks because of its higher spectrum and energy efficiency. Up to now, the prevalent fast Fourier transform (FFT)-based sensing method for mobile JCS networks is on-grid based, and the grid interval determines the resolution. Because the mobile network usually has limited consecutive OFDM symbols in a downlink (DL) time slot, the sensing accuracy is restricted by the limited resolution, especially for velocity estimation. In this paper, we propose a multiple signal classification (MUSIC)-based JCS system that can achieve higher sensing accuracy for the angle of arrival, range, and velocity estimation, compared with the traditional FFT-based JCS method. We further propose a JCS channel state information (CSI) enhancement method by leveraging the JCS sensing results. Finally, we derive a theoretical lower bound for sensing mean square error (MSE) by using perturbation analysis. Simulation results show that in terms of the sensing MSE performance, the proposed MUSIC-based JCS outperforms the FFT-based one by more than 20 dB. Moreover, the bit error rate (BER) of communication demodulation using the proposed JCS CSI enhancement method is significantly reduced compared with communication using the originally estimated CSI.
Downlink and Uplink Cooperative Joint Communication and Sensing
Nov 08, 2022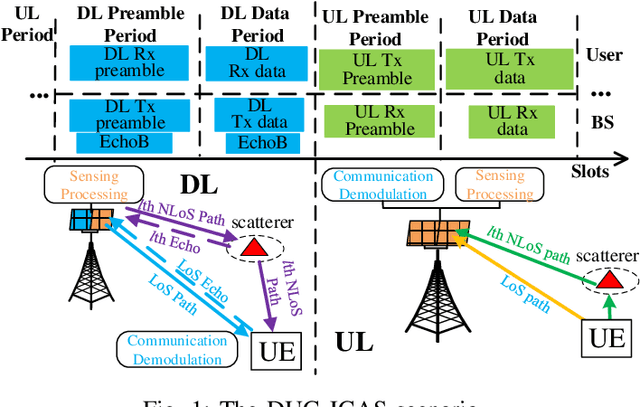
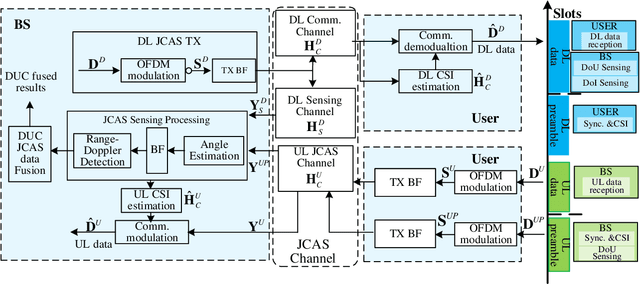
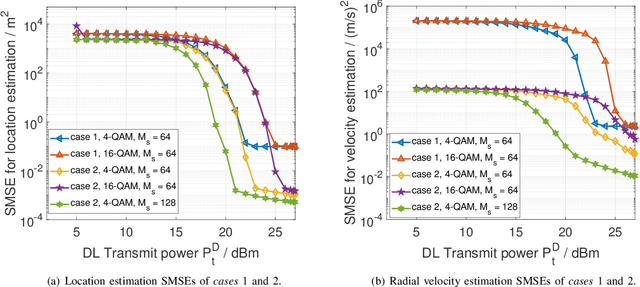
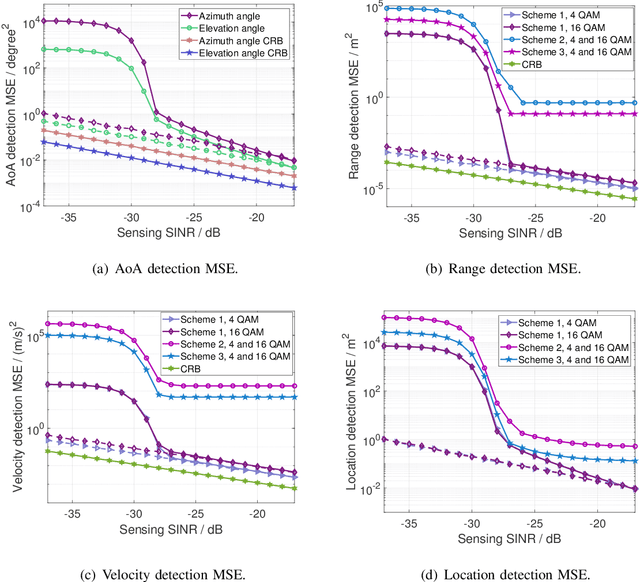
Downlink (DL) and uplink (UL) joint communication and sensing (JCAS) technologies have been individually studied for realizing sensing using DL and UL communication signals, respectively. Since the spatial environment and JCAS channels in the consecutive DL and UL JCAS time slots are generally unchanged, DL and UL JCAS may be jointly designed to achieve better sensing performance. In this paper, we propose a novel DL and UL cooperative (DUC) JCAS scheme, including a unified multiple signal classification (MUSIC)-based JCAS sensing scheme for both DL and UL JCAS and a DUC JCAS fusion method. The unified MUSIC JCAS sensing scheme can accurately estimate AoA, range, and Doppler based on a unified MUSIC-based sensing module. The DUC JCAS fusion method can distinguish between the sensing results of the communication user and other dumb targets. Moreover, by exploiting the channel reciprocity, it can also improve the sensing and channel state information (CSI) estimation accuracy. Extensive simulation results validate the proposed DUC JCAS scheme. It is shown that the minimum location and velocity estimation mean square errors of the proposed DUC JCAS scheme are about 20 dB lower than those of the state-of-the-art separated DL and UL JCAS schemes.
MD-GAN with multi-particle input: the machine learning of long-time molecular behavior from short-time MD data
Feb 02, 2022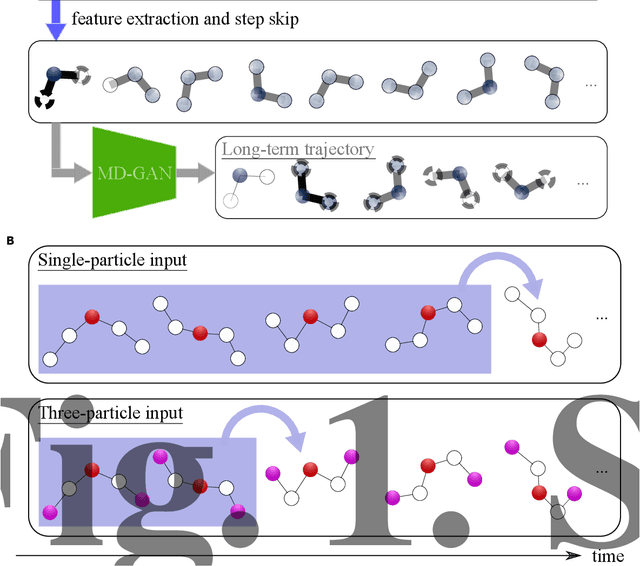
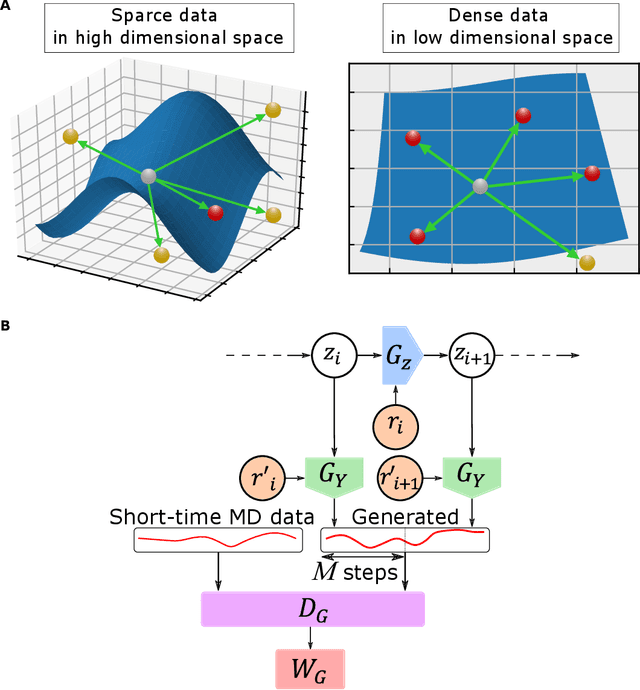
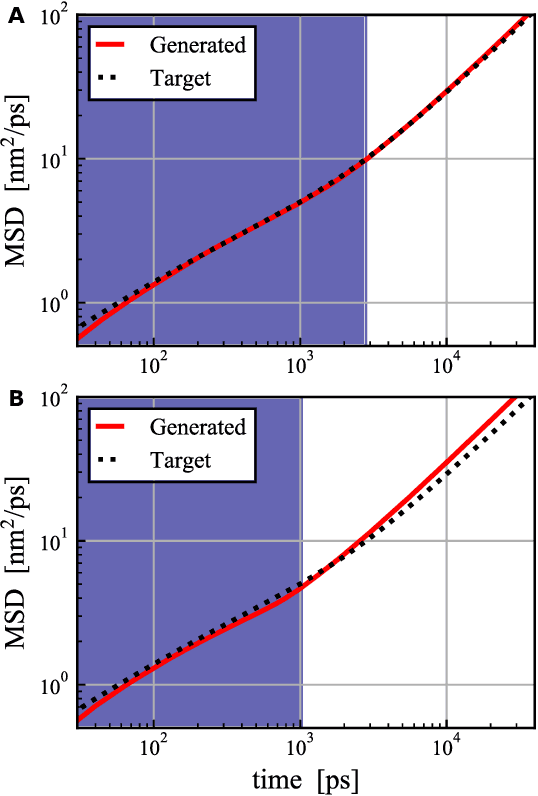
MD-GAN is a machine learning-based method that can evolve part of the system at any time step, accelerating the generation of molecular dynamics data. For the accurate prediction of MD-GAN, sufficient information on the dynamics of a part of the system should be included with the training data. Therefore, the selection of the part of the system is important for efficient learning. In a previous study, only one particle (or vector) of each molecule was extracted as part of the system. Therefore, we investigated the effectiveness of adding information from other particles to the learning process. In the experiment of the polyethylene system, when the dynamics of three particles of each molecule were used, the diffusion was successfully predicted using one-third of the time length of the training data, compared to the single-particle input. Surprisingly, the unobserved transition of diffusion in the training data was also predicted using this method.
Deep Unsupervised Key Frame Extraction for Efficient Video Classification
Nov 12, 2022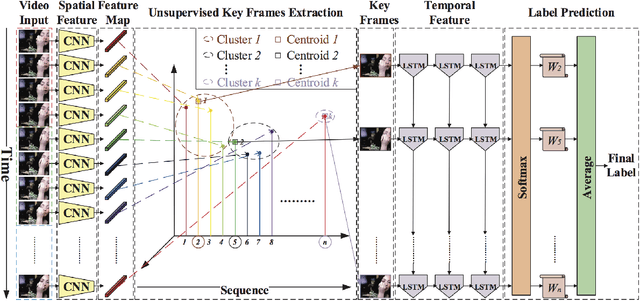
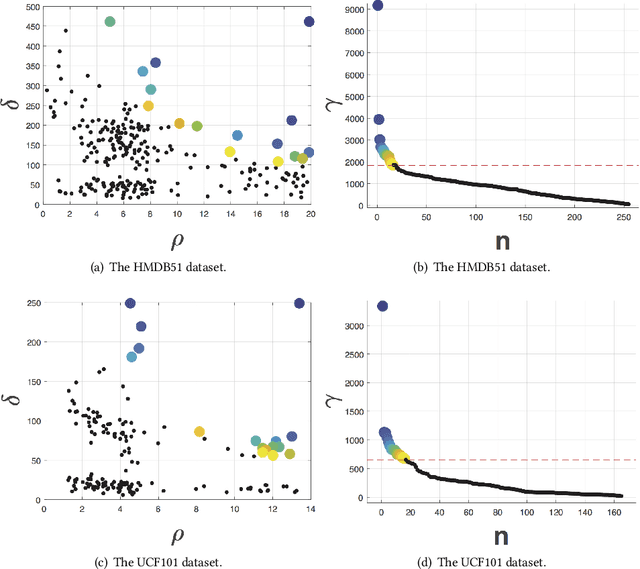
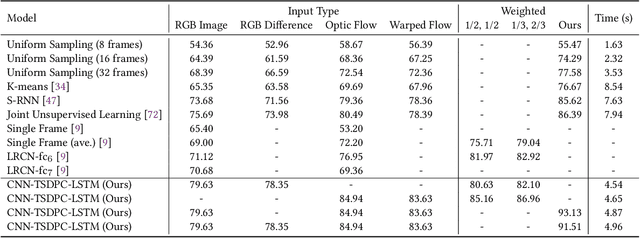
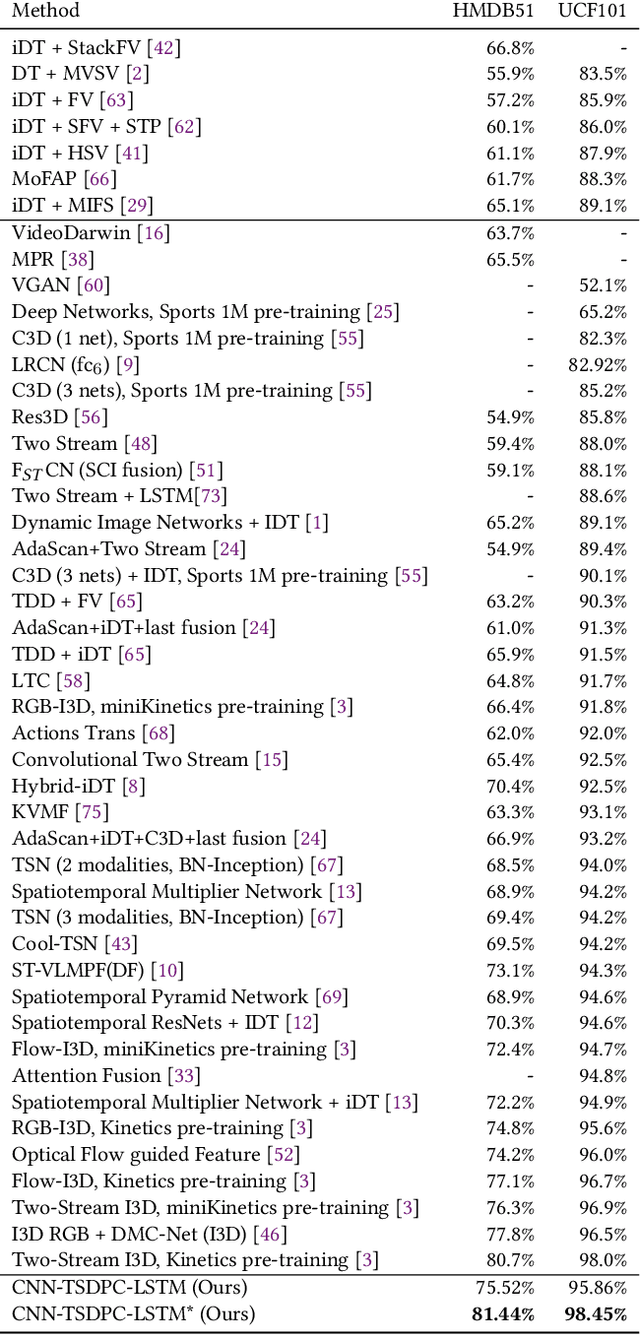
Video processing and analysis have become an urgent task since a huge amount of videos (e.g., Youtube, Hulu) are uploaded online every day. The extraction of representative key frames from videos is very important in video processing and analysis since it greatly reduces computing resources and time. Although great progress has been made recently, large-scale video classification remains an open problem, as the existing methods have not well balanced the performance and efficiency simultaneously. To tackle this problem, this work presents an unsupervised method to retrieve the key frames, which combines Convolutional Neural Network (CNN) and Temporal Segment Density Peaks Clustering (TSDPC). The proposed TSDPC is a generic and powerful framework and it has two advantages compared with previous works, one is that it can calculate the number of key frames automatically. The other is that it can preserve the temporal information of the video. Thus it improves the efficiency of video classification. Furthermore, a Long Short-Term Memory network (LSTM) is added on the top of the CNN to further elevate the performance of classification. Moreover, a weight fusion strategy of different input networks is presented to boost the performance. By optimizing both video classification and key frame extraction simultaneously, we achieve better classification performance and higher efficiency. We evaluate our method on two popular datasets (i.e., HMDB51 and UCF101) and the experimental results consistently demonstrate that our strategy achieves competitive performance and efficiency compared with the state-of-the-art approaches.
Deep Explainable Learning with Graph Based Data Assessing and Rule Reasoning
Nov 10, 2022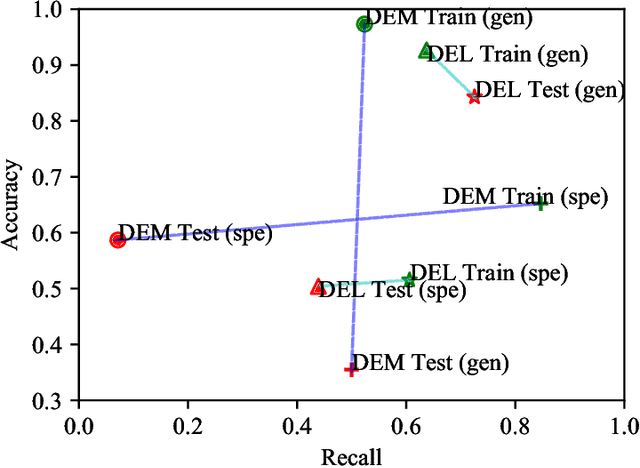
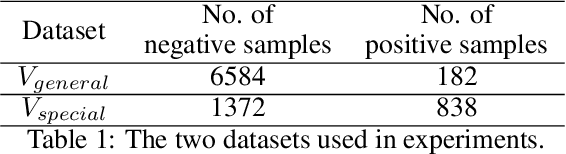
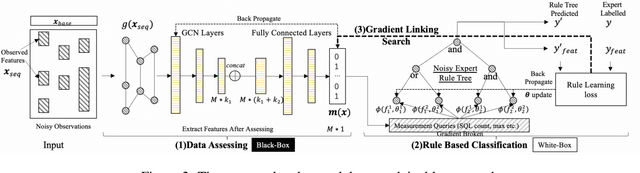
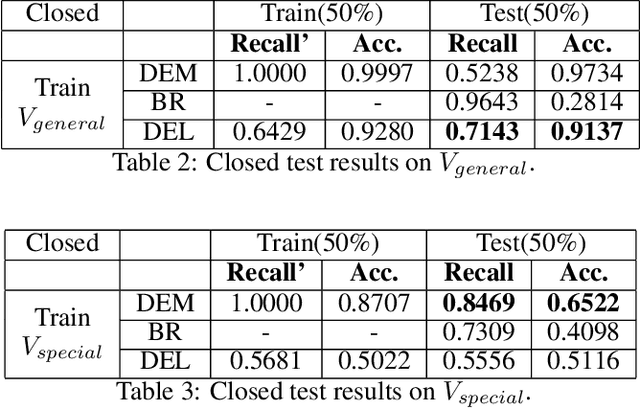
Learning an explainable classifier often results in low accuracy model or ends up with a huge rule set, while learning a deep model is usually more capable of handling noisy data at scale, but with the cost of hard to explain the result and weak at generalization. To mitigate this gap, we propose an end-to-end deep explainable learning approach that combines the advantage of deep model in noise handling and expert rule-based interpretability. Specifically, we propose to learn a deep data assessing model which models the data as a graph to represent the correlations among different observations, whose output will be used to extract key data features. The key features are then fed into a rule network constructed following predefined noisy expert rules with trainable parameters. As these models are correlated, we propose an end-to-end training framework, utilizing the rule classification loss to optimize the rule learning model and data assessing model at the same time. As the rule-based computation is none-differentiable, we propose a gradient linking search module to carry the gradient information from the rule learning model to the data assessing model. The proposed method is tested in an industry production system, showing comparable prediction accuracy, much higher generalization stability and better interpretability when compared with a decent deep ensemble baseline, and shows much better fitting power than pure rule-based approach.
A metaheuristic multi-objective interaction-aware feature selection method
Nov 10, 2022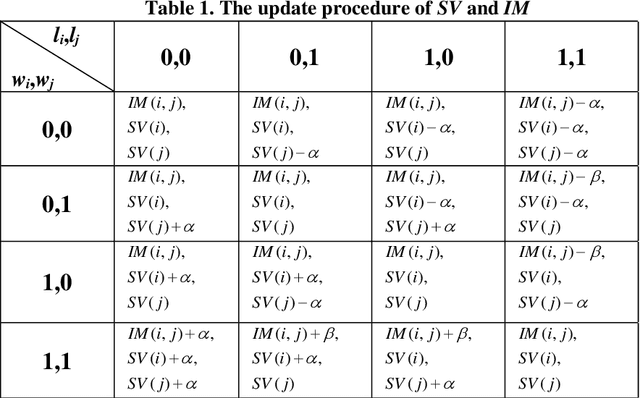
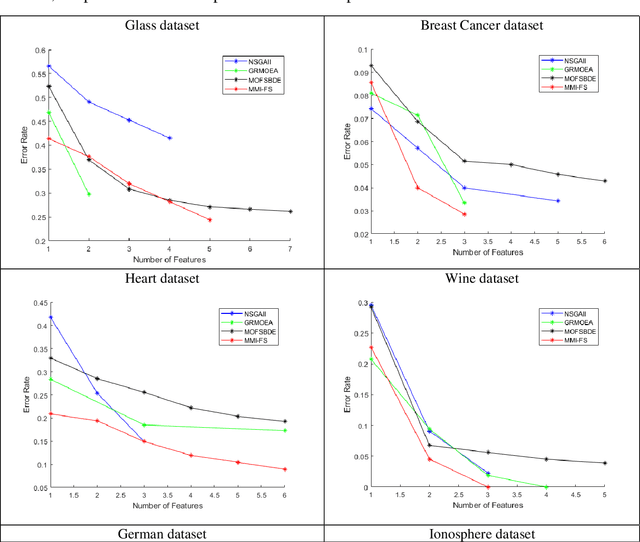
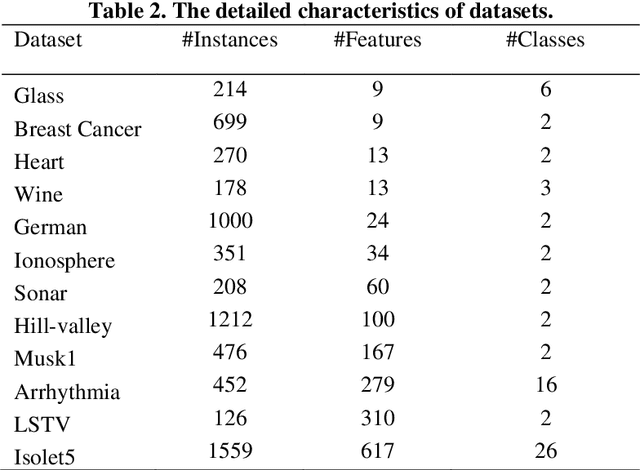
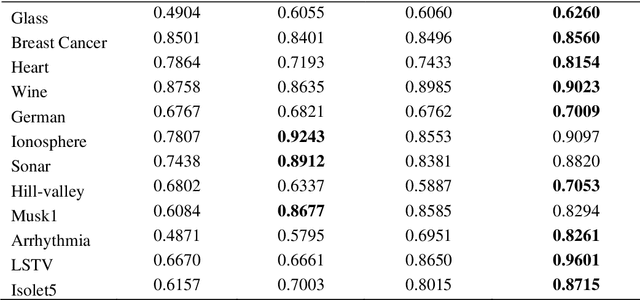
Multi-objective feature selection is one of the most significant issues in the field of pattern recognition. It is challenging because it maximizes the classification performance and, at the same time, minimizes the number of selected features, and the mentioned two objectives are usually conflicting. To achieve a better Pareto optimal solution, metaheuristic optimization methods are widely used in many studies. However, the main drawback is the exploration of a large search space. Another problem with multi-objective feature selection approaches is the interaction between features. Selecting correlated features has negative effect on classification performance. To tackle these problems, we present a novel multi-objective feature selection method that has several advantages. Firstly, it considers the interaction between features using an advanced probability scheme. Secondly, it is based on the Pareto Archived Evolution Strategy (PAES) method that has several advantages such as simplicity and its speed in exploring the solution space. However, we improve the structure of PAES in such a way that generates the offsprings, intelligently. Thus, the proposed method utilizes the introduced probability scheme to produce more promising offsprings. Finally, it is equipped with a novel strategy that guides it to find the optimum number of features through the process of evolution. The experimental results show a significant improvement in finding the optimal Pareto front compared to state-of-the-art methods on different real-world datasets.