 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Streaming, fast and accurate on-device Inverse Text Normalization for Automatic Speech Recognition
Nov 07, 2022
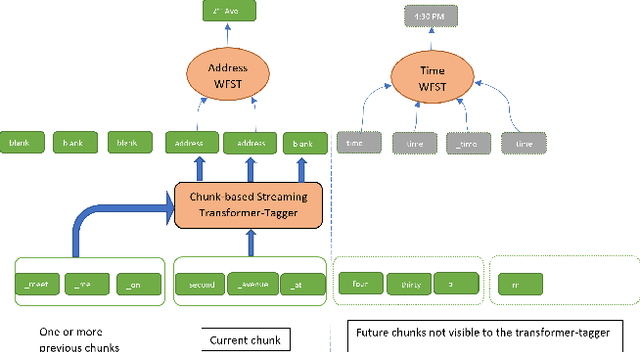
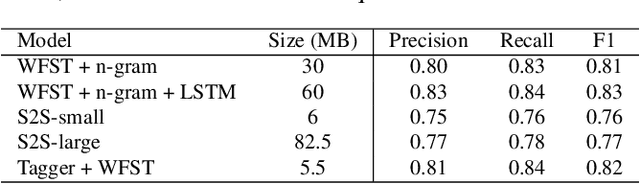
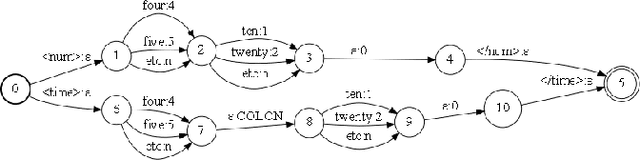
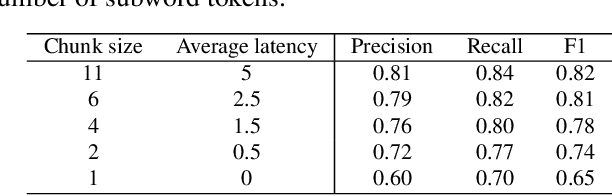
Automatic Speech Recognition (ASR) systems typically yield output in lexical form. However, humans prefer a written form output. To bridge this gap, ASR systems usually employ Inverse Text Normalization (ITN). In previous works, Weighted Finite State Transducers (WFST) have been employed to do ITN. WFSTs are nicely suited to this task but their size and run-time costs can make deployment on embedded applications challenging. In this paper, we describe the development of an on-device ITN system that is streaming, lightweight & accurate. At the core of our system is a streaming transformer tagger, that tags lexical tokens from ASR. The tag informs which ITN category might be applied, if at all. Following that, we apply an ITN-category-specific WFST, only on the tagged text, to reliably perform the ITN conversion. We show that the proposed ITN solution performs equivalent to strong baselines, while being significantly smaller in size and retaining customization capabilities.
Improving abstractive summarization with energy-based re-ranking
Nov 07, 2022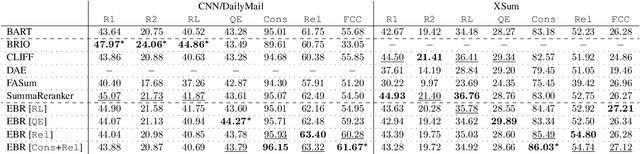
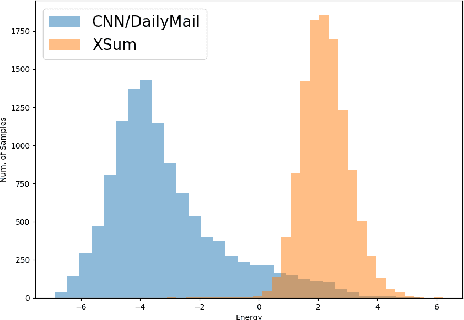
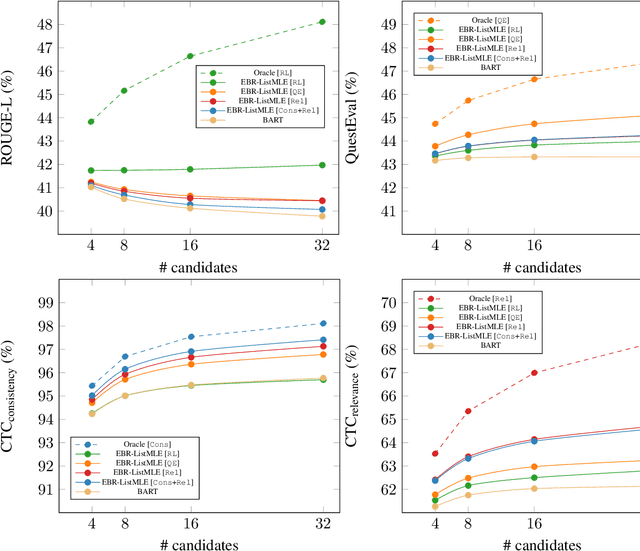

Current abstractive summarization systems present important weaknesses which prevent their deployment in real-world applications, such as the omission of relevant information and the generation of factual inconsistencies (also known as hallucinations). At the same time, automatic evaluation metrics such as CTC scores have been recently proposed that exhibit a higher correlation with human judgments than traditional lexical-overlap metrics such as ROUGE. In this work, we intend to close the loop by leveraging the recent advances in summarization metrics to create quality-aware abstractive summarizers. Namely, we propose an energy-based model that learns to re-rank summaries according to one or a combination of these metrics. We experiment using several metrics to train our energy-based re-ranker and show that it consistently improves the scores achieved by the predicted summaries. Nonetheless, human evaluation results show that the re-ranking approach should be used with care for highly abstractive summaries, as the available metrics are not yet sufficiently reliable for this purpose.
Ultrafast Image Retrieval from a Holographic Memory Disc for High-Speed Operation of a Shift, Scale, and Rotation Invariant Target Recognition System
Nov 07, 2022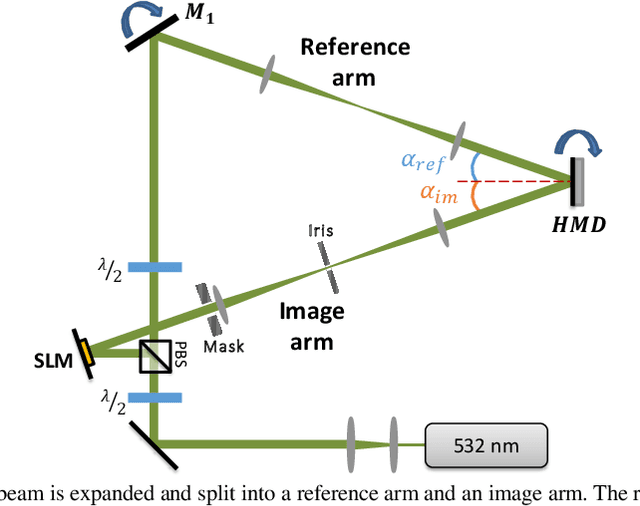

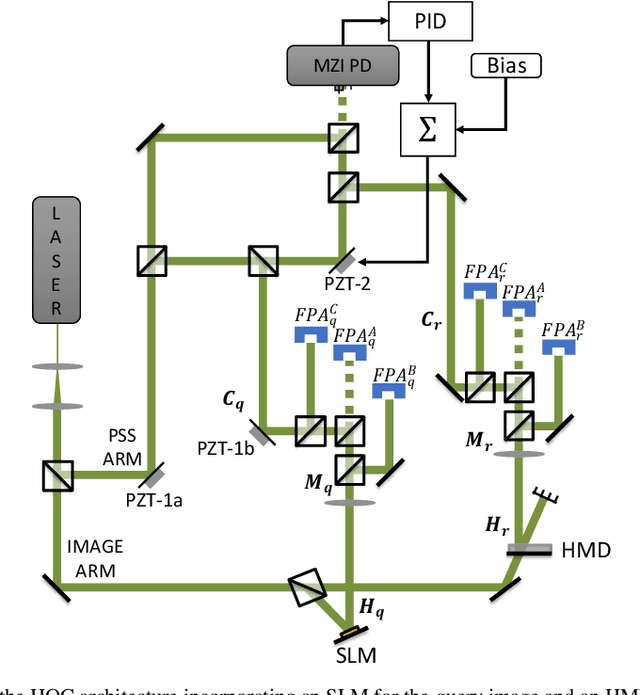

The hybrid opto-electronic correlator (HOC) architecture has been shown to be able to detect matches in a shift, scale, and rotation invariant (SSRI) manner by incorporating a polar Mellin transform (PMT) pre-processing step. Here we demonstrate the design and use of a thick holographic memory disc (HMD) for high-speed SSRI correlation employing an HOC. The HMD was written to have 1,320 stored images, including both unprocessed images and their PMTs. We further propose and demonstrate a novel approach whereby the HOC inputs are spatially shifted to produce correlation signals without requiring stabilization of optical phases, yielding results that are in good agreement with the theory. Use of this approach vastly simplifies the design and operation of the HOC, while improving its stability significantly. Finally, a real-time opto-electronic PMT pre-processor utilizing an FPGA is proposed and prototyped, allowing for the automatic conversion of images into their PMTs without additional processing delay.
* Conference
NSNet: A General Neural Probabilistic Framework for Satisfiability Problems
Nov 07, 2022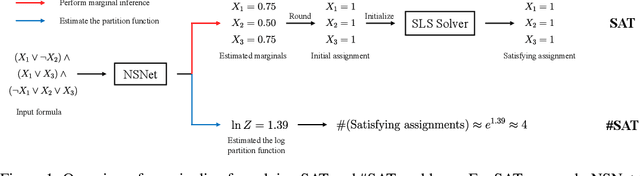
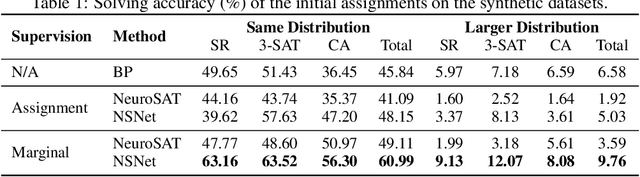
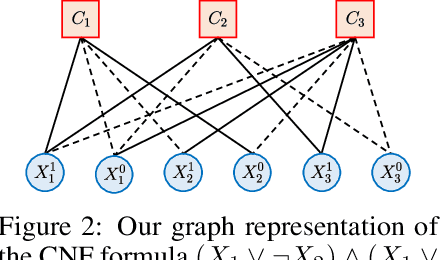
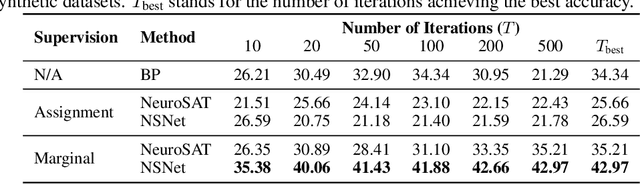
We present the Neural Satisfiability Network (NSNet), a general neural framework that models satisfiability problems as probabilistic inference and meanwhile exhibits proper explainability. Inspired by the Belief Propagation (BP), NSNet uses a novel graph neural network (GNN) to parameterize BP in the latent space, where its hidden representations maintain the same probabilistic interpretation as BP. NSNet can be flexibly configured to solve both SAT and #SAT problems by applying different learning objectives. For SAT, instead of directly predicting a satisfying assignment, NSNet performs marginal inference among all satisfying solutions, which we empirically find is more feasible for neural networks to learn. With the estimated marginals, a satisfying assignment can be efficiently generated by rounding and executing a stochastic local search. For #SAT, NSNet performs approximate model counting by learning the Bethe approximation of the partition function. Our evaluations show that NSNet achieves competitive results in terms of inference accuracy and time efficiency on multiple SAT and #SAT datasets.
Denoising Diffusion Probabilistic Models for Styled Walking Synthesis
Sep 29, 2022

Generating realistic motions for digital humans is time-consuming for many graphics applications. Data-driven motion synthesis approaches have seen solid progress in recent years through deep generative models. These results offer high-quality motions but typically suffer in motion style diversity. For the first time, we propose a framework using the denoising diffusion probabilistic model (DDPM) to synthesize styled human motions, integrating two tasks into one pipeline with increased style diversity compared with traditional motion synthesis methods. Experimental results show that our system can generate high-quality and diverse walking motions.
Sparse-Group Log-Sum Penalized Graphical Model Learning For Time Series
Apr 29, 2022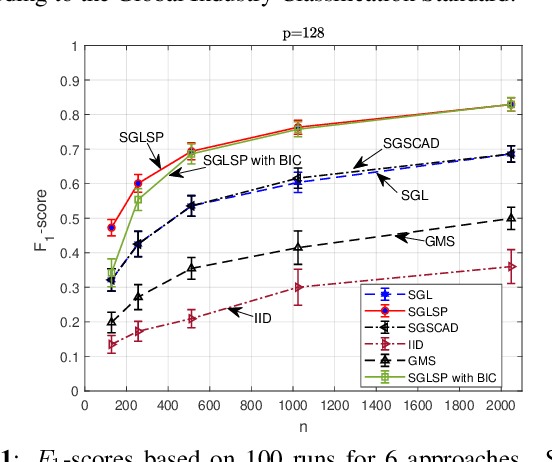
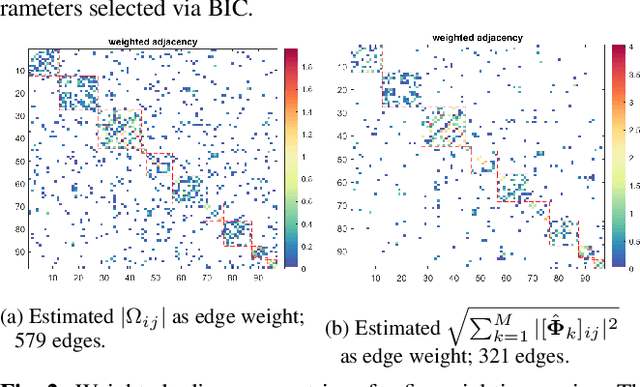
We consider the problem of inferring the conditional independence graph (CIG) of a high-dimensional stationary multivariate Gaussian time series. A sparse-group lasso based frequency-domain formulation of the problem has been considered in the literature where the objective is to estimate the sparse inverse power spectral density (PSD) of the data. The CIG is then inferred from the estimated inverse PSD. In this paper we investigate use of a sparse-group log-sum penalty (LSP) instead of sparse-group lasso penalty. An alternating direction method of multipliers (ADMM) approach for iterative optimization of the non-convex problem is presented. We provide sufficient conditions for local convergence in the Frobenius norm of the inverse PSD estimators to the true value. This results also yields a rate of convergence. We illustrate our approach using numerical examples utilizing both synthetic and real data.
TLP: A Deep Learning-based Cost Model for Tensor Program Tuning
Nov 22, 2022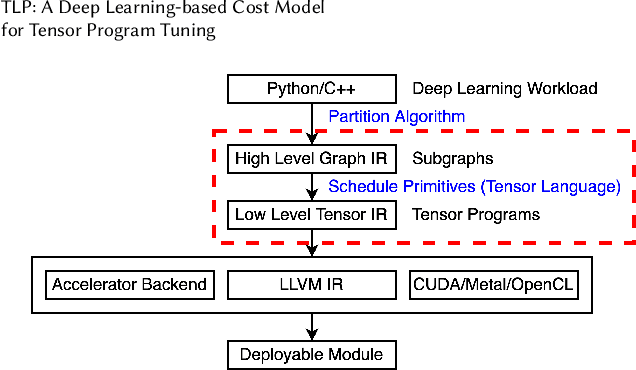


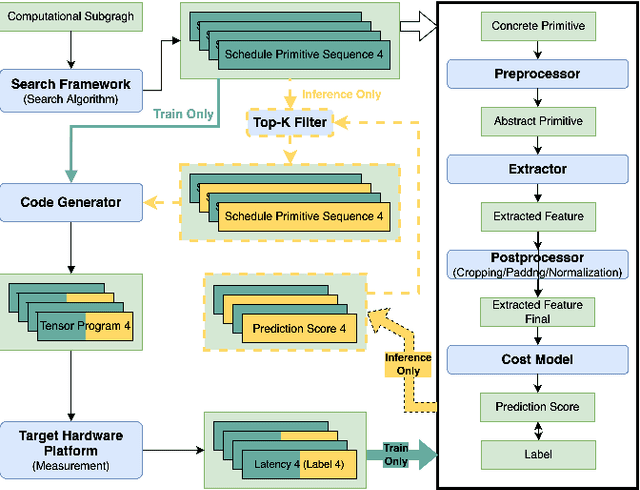
Tensor program tuning is a non-convex objective optimization problem, to which search-based approaches have proven to be effective. At the core of the search-based approaches lies the design of the cost model. Though deep learning-based cost models perform significantly better than other methods, they still fall short and suffer from the following problems. First, their feature extraction heavily relies on expert-level domain knowledge in hardware architectures. Even so, the extracted features are often unsatisfactory and require separate considerations for CPUs and GPUs. Second, a cost model trained on one hardware platform usually performs poorly on another, a problem we call cross-hardware unavailability. In order to address these problems, we propose TLP and MTLTLP. TLP is a deep learning-based cost model that facilitates tensor program tuning. Instead of extracting features from the tensor program itself, TLP extracts features from the schedule primitives. We treat schedule primitives as tensor languages. TLP is thus a Tensor Language Processing task. In this way, the task of predicting the tensor program latency through the cost model is transformed into a natural language processing (NLP) regression task. MTL-TLP combines Multi-Task Learning and TLP to cope with the cross-hardware unavailability problem. We incorporate these techniques into the Ansor framework and conduct detailed experiments. Results show that TLP can speed up the average search time by 9.1X and 3.0X on CPU and GPU workloads, respectively, compared to the state-of-the-art implementation. MTL-TLP can achieve a speed-up of 4.7X and 2.9X on CPU and GPU workloads, respectively, using only 7% of the target hardware data.
Big Earth Data and Machine Learning for Sustainable and Resilient Agriculture
Nov 22, 2022Big streams of Earth images from satellites or other platforms (e.g., drones and mobile phones) are becoming increasingly available at low or no cost and with enhanced spatial and temporal resolution. This thesis recognizes the unprecedented opportunities offered by the high quality and open access Earth observation data of our times and introduces novel machine learning and big data methods to properly exploit them towards developing applications for sustainable and resilient agriculture. The thesis addresses three distinct thematic areas, i.e., the monitoring of the Common Agricultural Policy (CAP), the monitoring of food security and applications for smart and resilient agriculture. The methodological innovations of the developments related to the three thematic areas address the following issues: i) the processing of big Earth Observation (EO) data, ii) the scarcity of annotated data for machine learning model training and iii) the gap between machine learning outputs and actionable advice. This thesis demonstrated how big data technologies such as data cubes, distributed learning, linked open data and semantic enrichment can be used to exploit the data deluge and extract knowledge to address real user needs. Furthermore, this thesis argues for the importance of semi-supervised and unsupervised machine learning models that circumvent the ever-present challenge of scarce annotations and thus allow for model generalization in space and time. Specifically, it is shown how merely few ground truth data are needed to generate high quality crop type maps and crop phenology estimations. Finally, this thesis argues there is considerable distance in value between model inferences and decision making in real-world scenarios and thereby showcases the power of causal and interpretable machine learning in bridging this gap.
A Bioinspired Bidirectional Stiffening Soft Actuator for Multimodal, Compliant, and Robust Grasping
Nov 22, 2022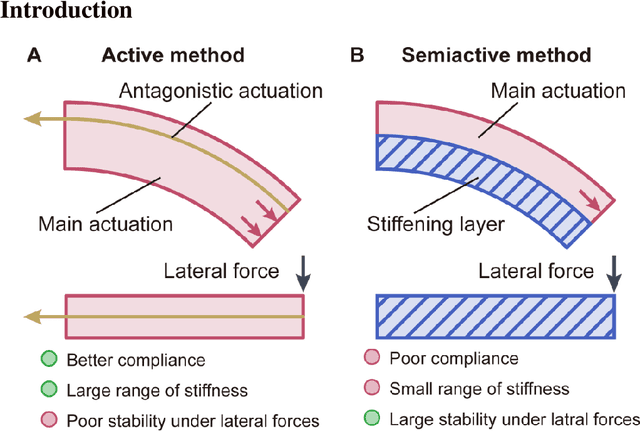
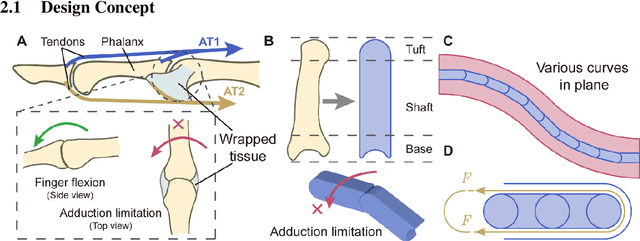
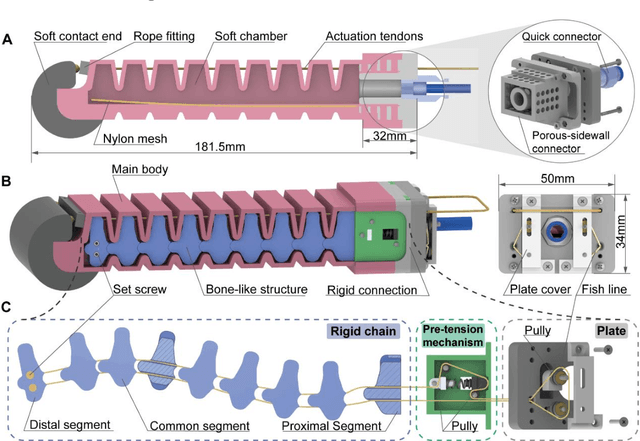
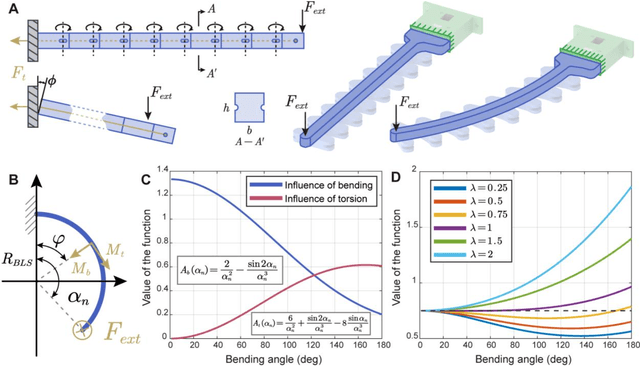
The stiffness modulation mechanism for soft robotics has gained considerable attention to improve deformability, controllability, and stability. However, for the existing stiffness soft actuator, high lateral stiffness and a wide range of bending stiffness are hard to be provided at the same time. This paper presents a bioinspired bidirectional stiffening soft actuator (BISA) combining the air-tendon hybrid actuation (ATA) and a bone-like structure (BLS). The ATA is the main actuation of the BISA, and the bending stiffness can be modulated with a maximum stiffness of about 0.7 N/mm and a maximum magnification of 3 times when the bending angle is 45 deg. Inspired by the morphological structure of the phalanx, the lateral stiffness can be modulated by changing the pulling force of the BLS. The lateral stiffness can be modulated by changing the pulling force to it. The actuator with BLSs can improve the lateral stiffness about 3.9 times compared to the one without BLSs. The maximum lateral stiffness can reach 0.46 N/mm. And the lateral stiffness can be modulated decoupling about 1.3 times (e.g., from 0.35 N/mm to 0.46 when the bending angle is 45 deg). The test results show the influence of the rigid structures on bending is small with about 1.5 mm maximum position errors of the distal point of actuator bending in different pulling forces. The advantages brought by the proposed method enable a soft four-finger gripper to operate in three modes: normal grasping, inverse grasping, and horizontal lifting. The performance of this gripper is further characterized and versatile grasping on various objects is conducted, proving the robust performance and potential application of the proposed design method.
BASM: A Bottom-up Adaptive Spatiotemporal Model for Online Food Ordering Service
Nov 22, 2022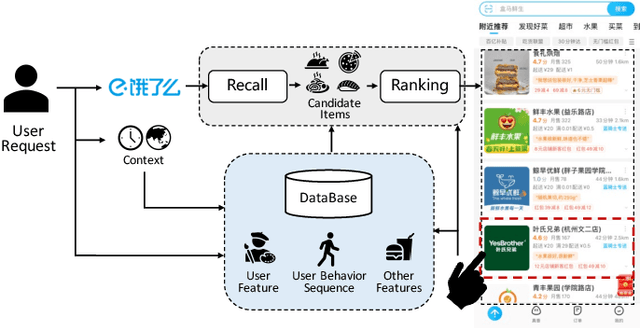
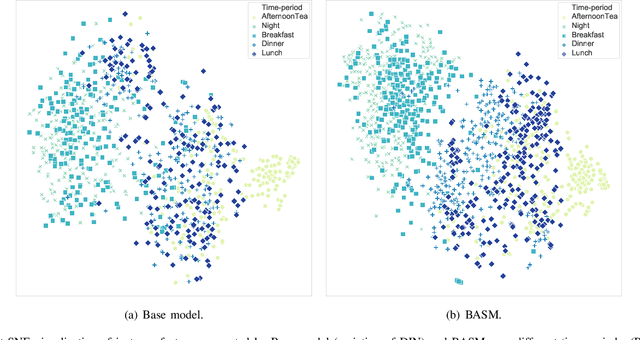
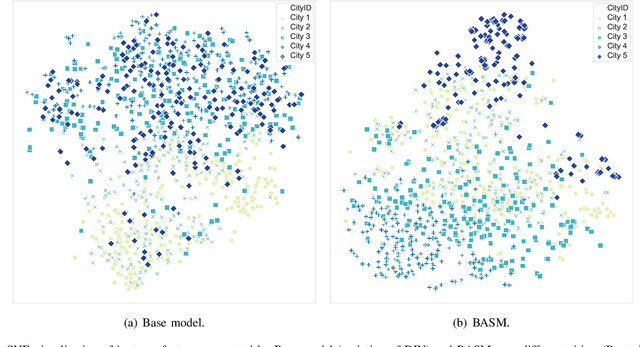
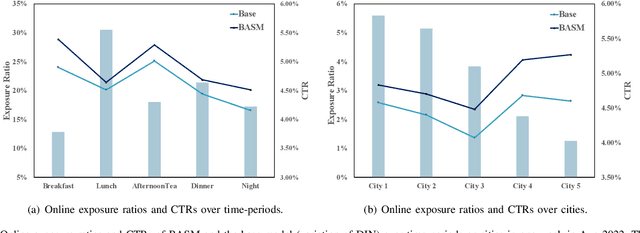
Online Food Ordering Service (OFOS) is a popular location-based service that helps people to order what you want. Compared with traditional e-commerce recommendation systems, users' interests may be diverse under different spatiotemporal contexts, leading to various spatiotemporal data distribution, which limits the fitting capacity of the model. However, numerous current works simply mix all samples to train a set of model parameters, which makes it difficult to capture the diversity in different spatiotemporal contexts. Therefore, we address this challenge by proposing a Bottom-up Adaptive Spatiotemporal Model(BASM) to adaptively fit the spatiotemporal data distribution, which further improve the fitting capability of the model. Specifically, a spatiotemporal-aware embedding layer performs weight adaptation on field granularity in feature embedding, to achieve the purpose of dynamically perceiving spatiotemporal contexts. Meanwhile, we propose a spatiotemporal semantic transformation layer to explicitly convert the concatenated input of the raw semantic to spatiotemporal semantic, which can further enhance the semantic representation under different spatiotemporal contexts. Furthermore, we introduce a novel spatiotemporal adaptive bias tower to capture diverse spatiotemporal bias, reducing the difficulty to model spatiotemporal distinction. To further verify the effectiveness of BASM, we also novelly propose two new metrics, Time-period-wise AUC (TAUC) and City-wise AUC (CAUC). Extensive offline evaluations on public and industrial datasets are conducted to demonstrate the effectiveness of our proposed modle. The online A/B experiment also further illustrates the practicability of the model online service. This proposed method has now been implemented on the Ele.me, a major online food ordering platform in China, serving more than 100 million online users.