 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CapillaryX: A Software Design Pattern for Analyzing Medical Images in Real-time using Deep Learning
Apr 13, 2022
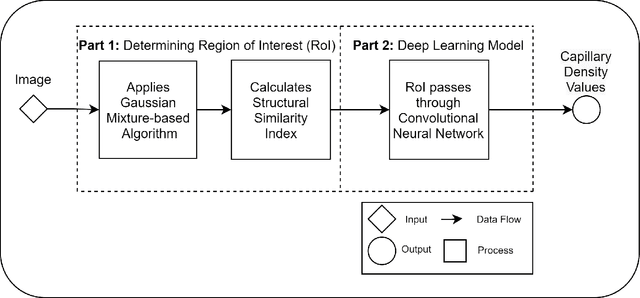
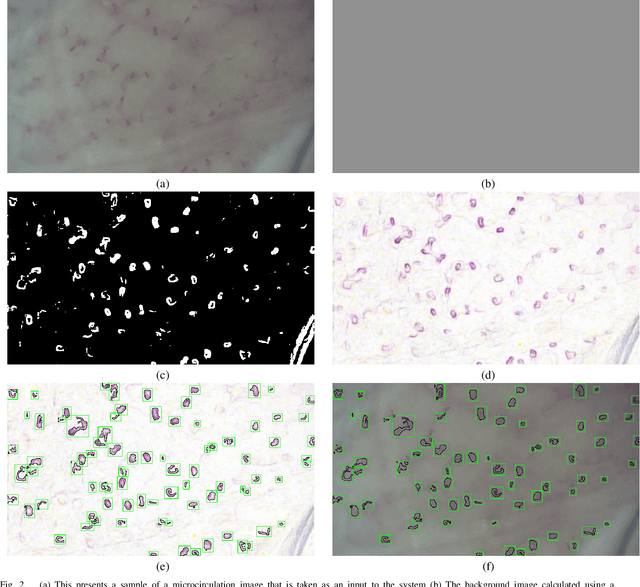
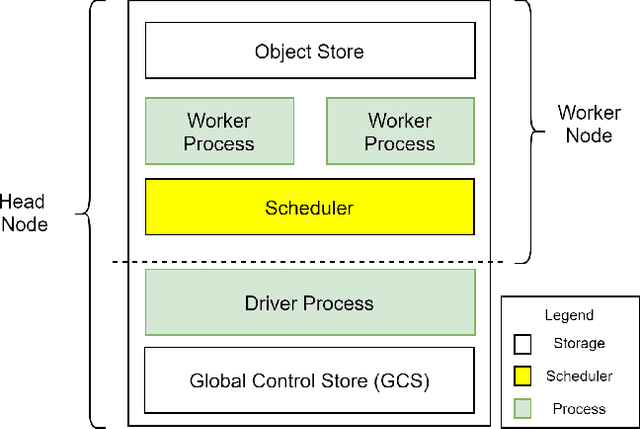
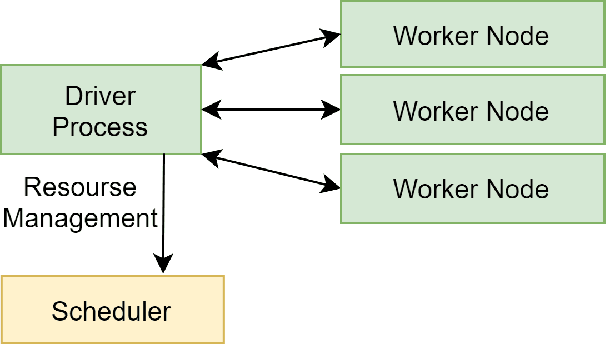
Recent advances in digital imaging, e.g., increased number of pixels captured, have meant that the volume of data to be processed and analyzed from these images has also increased. Deep learning algorithms are state-of-the-art for analyzing such images, given their high accuracy when trained with a large data volume of data. Nevertheless, such analysis requires considerable computational power, making such algorithms time- and resource-demanding. Such high demands can be met by using third-party cloud service providers. However, analyzing medical images using such services raises several legal and privacy challenges and does not necessarily provide real-time results. This paper provides a computing architecture that locally and in parallel can analyze medical images in real-time using deep learning thus avoiding the legal and privacy challenges stemming from uploading data to a third-party cloud provider. To make local image processing efficient on modern multi-core processors, we utilize parallel execution to offset the resource-intensive demands of deep neural networks. We focus on a specific medical-industrial case study, namely the quantifying of blood vessels in microcirculation images for which we have developed a working system. It is currently used in an industrial, clinical research setting as part of an e-health application. Our results show that our system is approximately 78% faster than its serial system counterpart and 12% faster than a master-slave parallel system architecture.
Dynamic-Pix2Pix: Noise Injected cGAN for Modeling Input and Target Domain Joint Distributions with Limited Training Data
Nov 15, 2022

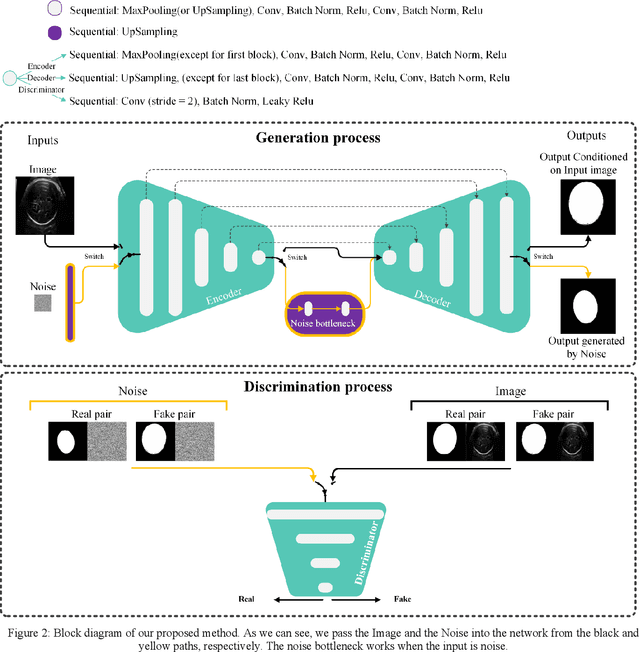
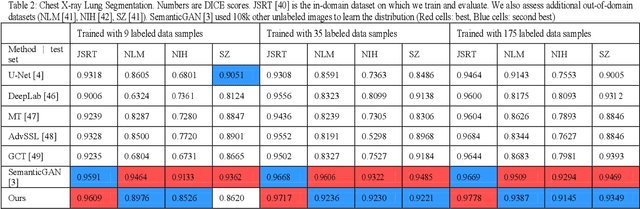
Learning to translate images from a source to a target domain with applications such as converting simple line drawing to oil painting has attracted significant attention. The quality of translated images is directly related to two crucial issues. First, the consistency of the output distribution with that of the target is essential. Second, the generated output should have a high correlation with the input. Conditional Generative Adversarial Networks, cGANs, are the most common models for translating images. The performance of a cGAN drops when we use a limited training dataset. In this work, we increase the Pix2Pix (a form of cGAN) target distribution modeling ability with the help of dynamic neural network theory. Our model has two learning cycles. The model learns the correlation between input and ground truth in the first cycle. Then, the model's architecture is refined in the second cycle to learn the target distribution from noise input. These processes are executed in each iteration of the training procedure. Helping the cGAN learn the target distribution from noise input results in a better model generalization during the test time and allows the model to fit almost perfectly to the target domain distribution. As a result, our model surpasses the Pix2Pix model in segmenting HC18 and Montgomery's chest x-ray images. Both qualitative and Dice scores show the superiority of our model. Although our proposed method does not use thousand of additional data for pretraining, it produces comparable results for the in and out-domain generalization compared to the state-of-the-art methods.
Efficient shallow learning as an alternative to deep learning
Nov 15, 2022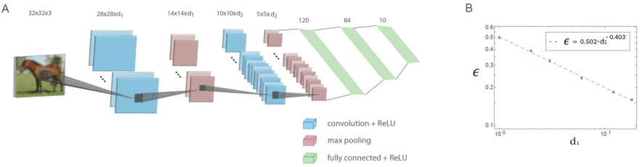
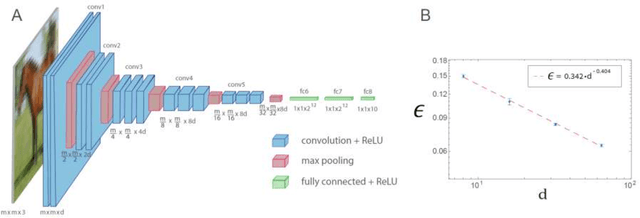
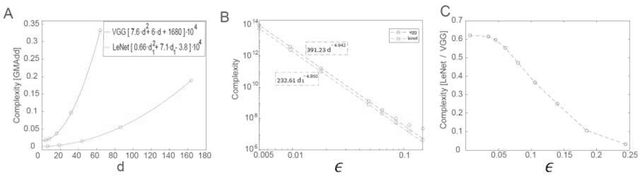
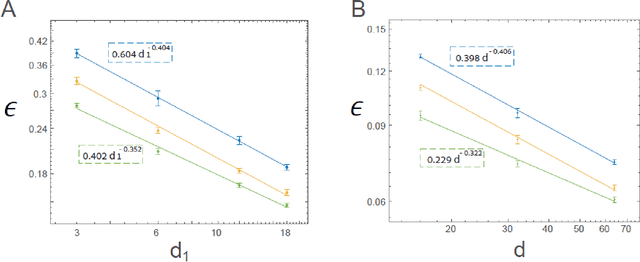
The realization of complex classification tasks requires training of deep learning (DL) architectures consisting of tens or even hundreds of convolutional and fully connected hidden layers, which is far from the reality of the human brain. According to the DL rationale, the first convolutional layer reveals localized patterns in the input and large-scale patterns in the following layers, until it reliably characterizes a class of inputs. Here, we demonstrate that with a fixed ratio between the depths of the first and second convolutional layers, the error rates of the generalized shallow LeNet architecture, consisting of only five layers, decay as a power law with the number of filters in the first convolutional layer. The extrapolation of this power law indicates that the generalized LeNet can achieve small error rates that were previously obtained for the CIFAR-10 database using DL architectures. A power law with a similar exponent also characterizes the generalized VGG-16 architecture. However, this results in a significantly increased number of operations required to achieve a given error rate with respect to LeNet. This power law phenomenon governs various generalized LeNet and VGG-16 architectures, hinting at its universal behavior and suggesting a quantitative hierarchical time-space complexity among machine learning architectures. Additionally, the conservation law along the convolutional layers, which is the square-root of their size times their depth, is found to asymptotically minimize error rates. The efficient shallow learning that is demonstrated in this study calls for further quantitative examination using various databases and architectures and its accelerated implementation using future dedicated hardware developments.
Machine Learning enabled models for YouTube Ranking Mechanism and Views Prediction
Nov 15, 2022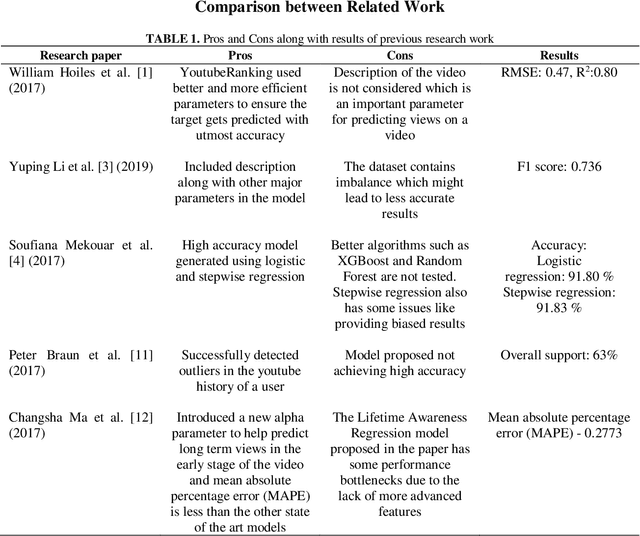
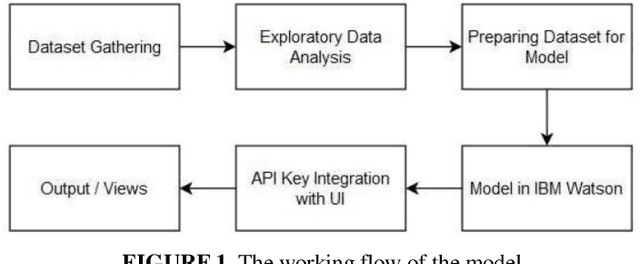

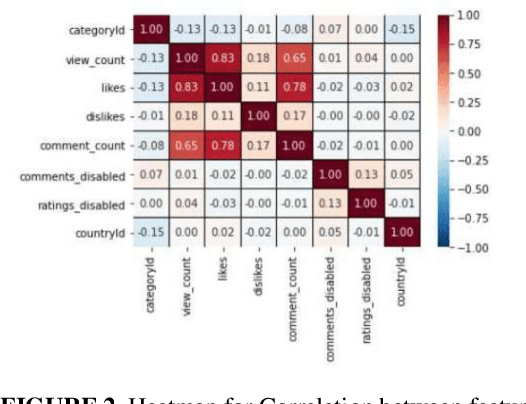
With the continuous increase of internet usage in todays time, everyone is influenced by this source of the power of technology. Due to this, the rise of applications and games Is unstoppable. A major percentage of our population uses these applications for multiple purposes. These range from education, communication, news, entertainment, and many more. Out of this, the application that is making sure that the world stays in touch with each other and with current affairs is social media. Social media applications have seen a boom in the last 10 years with the introduction of smartphones and the internet being available at affordable prices. Applications like Twitch and Youtube are some of the best platforms for producing content and expressing their talent as well. It is the goal of every content creator to post the best and most reliable content so that they can gain recognition. It is important to know the methods of achieving popularity easily, which is what this paper proposes to bring to the spotlight. There should be certain parameters based on which the reach of content could be multiplied by a good factor. The proposed research work aims to identify and estimate the reach, popularity, and views of a YouTube video by using certain features using machine learning and AI techniques. A ranking system would also be used keeping the trending videos in consideration. This would eventually help the content creator know how authentic their content is and healthy competition to make better content before uploading the video on the platform will be ensured.
Air Pollution Hotspot Detection and Source Feature Analysis using Cross-domain Urban Data
Nov 15, 2022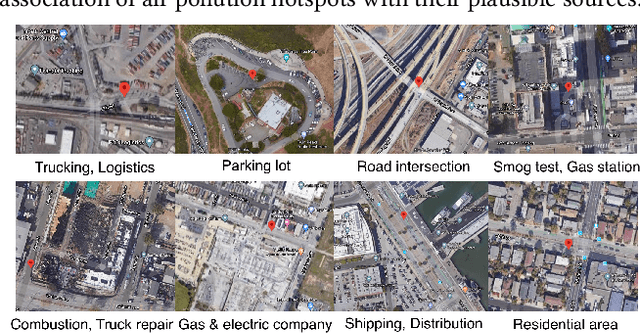
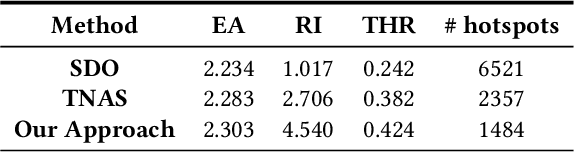
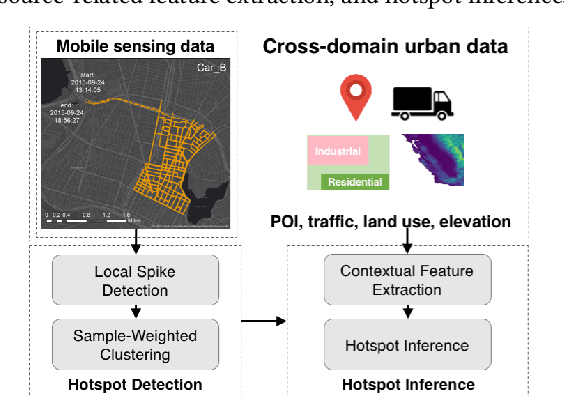
Air pollution is a major global environmental health threat, in particular for people who live or work near pollution sources. Areas adjacent to pollution sources often have high ambient pollution concentrations, and those areas are commonly referred to as air pollution hotspots. Detecting and characterizing pollution hotspots are of great importance for air quality management, but are challenging due to the high spatial and temporal variability of air pollutants. In this work, we explore the use of mobile sensing data (i.e., air quality sensors installed on vehicles) to detect pollution hotspots. One major challenge with mobile sensing data is uneven sampling, i.e., data collection can vary by both space and time. To address this challenge, we propose a two-step approach to detect hotspots from mobile sensing data, which includes local spike detection and sample-weighted clustering. Essentially, this approach tackles the uneven sampling issue by weighting samples based on their spatial frequency and temporal hit rate, so as to identify robust and persistent hotspots. To contextualize the hotspots and discover potential pollution source characteristics, we explore a variety of cross-domain urban data and extract features from them. As a soft-validation of the extracted features, we build hotspot inference models for cities with and without mobile sensing data. Evaluation results using real-world mobile sensing air quality data as well as cross-domain urban data demonstrate the effectiveness of our approach in detecting and inferring pollution hotspots. Furthermore, the empirical analysis of hotspots and source features yields useful insights regarding neighborhood pollution sources.
* 10 pages
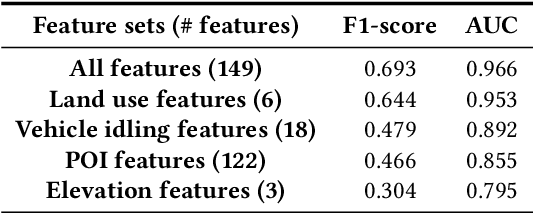
Hierarchical Inference of the Lensing Convergence from Photometric Catalogs with Bayesian Graph Neural Networks
Nov 15, 2022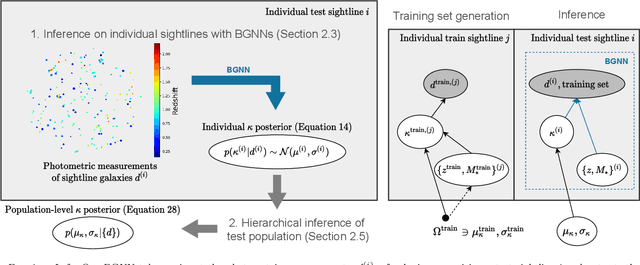
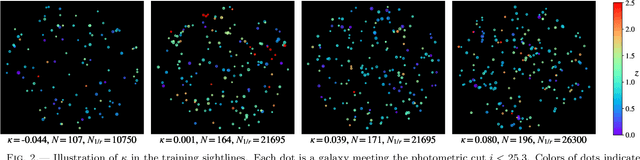
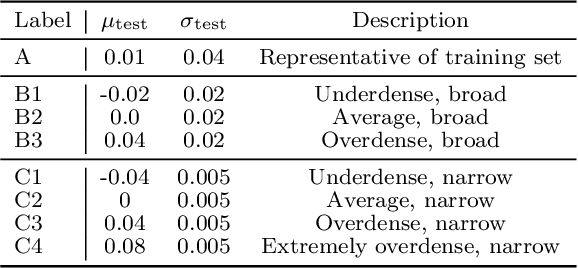
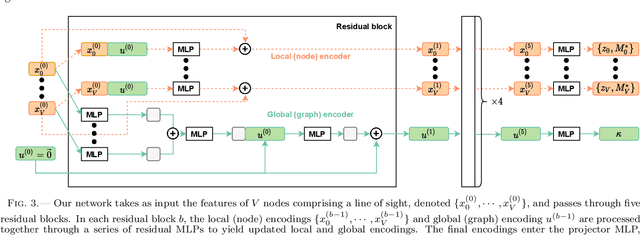
We present a Bayesian graph neural network (BGNN) that can estimate the weak lensing convergence ($\kappa$) from photometric measurements of galaxies along a given line of sight. The method is of particular interest in strong gravitational time delay cosmography (TDC), where characterizing the "external convergence" ($\kappa_{\rm ext}$) from the lens environment and line of sight is necessary for precise inference of the Hubble constant ($H_0$). Starting from a large-scale simulation with a $\kappa$ resolution of $\sim$1$'$, we introduce fluctuations on galaxy-galaxy lensing scales of $\sim$1$''$ and extract random sightlines to train our BGNN. We then evaluate the model on test sets with varying degrees of overlap with the training distribution. For each test set of 1,000 sightlines, the BGNN infers the individual $\kappa$ posteriors, which we combine in a hierarchical Bayesian model to yield constraints on the hyperparameters governing the population. For a test field well sampled by the training set, the BGNN recovers the population mean of $\kappa$ precisely and without bias, resulting in a contribution to the $H_0$ error budget well under 1\%. In the tails of the training set with sparse samples, the BGNN, which can ingest all available information about each sightline, extracts more $\kappa$ signal compared to a simplified version of the traditional method based on matching galaxy number counts, which is limited by sample variance. Our hierarchical inference pipeline using BGNNs promises to improve the $\kappa_{\rm ext}$ characterization for precision TDC. The implementation of our pipeline is available as a public Python package, Node to Joy.
Reverberation as Supervision for Speech Separation
Nov 15, 2022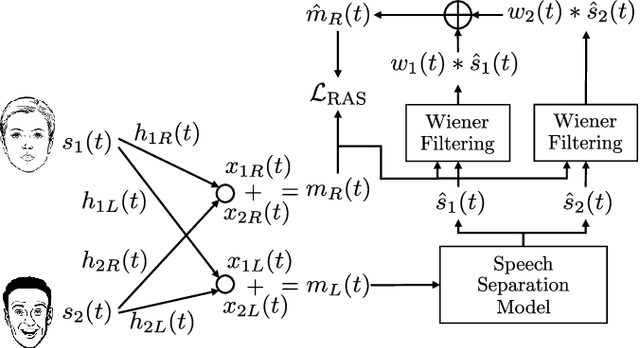

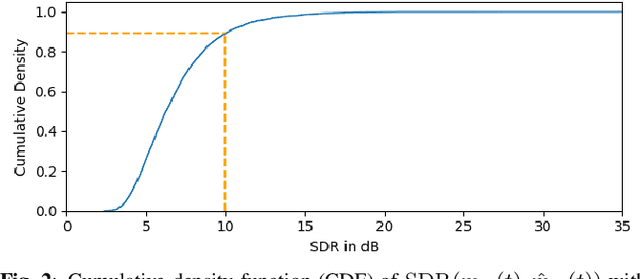
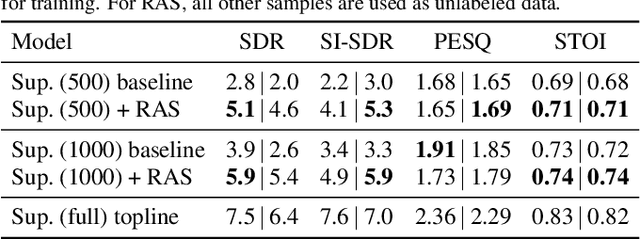
This paper proposes reverberation as supervision (RAS), a novel unsupervised loss function for single-channel reverberant speech separation. Prior methods for unsupervised separation required the synthesis of mixtures of mixtures or assumed the existence of a teacher model, making them difficult to consider as potential methods explaining the emergence of separation abilities in an animal's auditory system. We assume the availability of two-channel mixtures at training time, and train a neural network to separate the sources given one of the channels as input such that the other channel may be predicted from the separated sources. As the relationship between the room impulse responses (RIRs) of each channel depends on the locations of the sources, which are unknown to the network, the network cannot rely on learning that relationship. Instead, our proposed loss function fits each of the separated sources to the mixture in the target channel via Wiener filtering, and compares the resulting mixture to the ground-truth one. We show that minimizing the scale-invariant signal-to-distortion ratio (SI-SDR) of the predicted right-channel mixture with respect to the ground truth implicitly guides the network towards separating the left-channel sources. On a semi-supervised reverberant speech separation task based on the WHAMR! dataset, using training data where just 5% (resp., 10%) of the mixtures are labeled with associated isolated sources, we achieve 70% (resp., 78%) of the SI-SDR improvement obtained when training with supervision on the full training set, while a model trained only on the labeled data obtains 43% (resp., 45%).
Global, and Local Optimization Beamforming for Acoustic Broadband Sources
Nov 09, 2022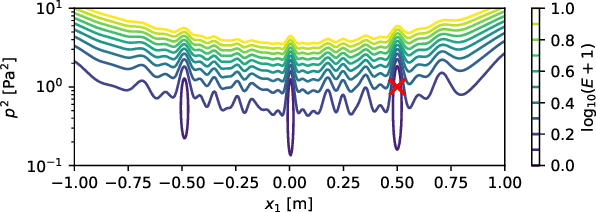
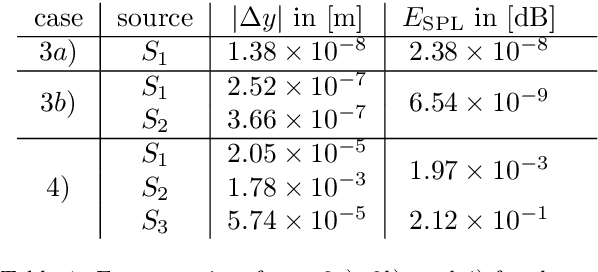
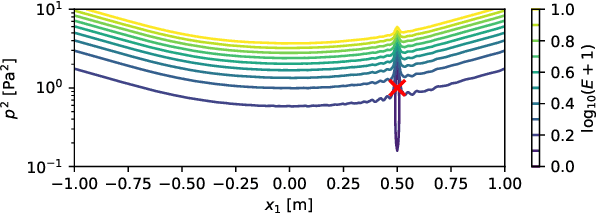
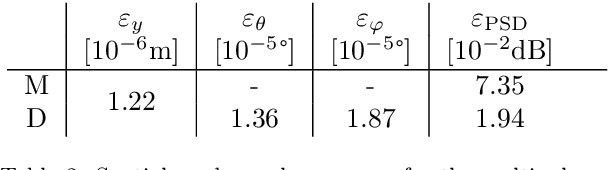
This paper presents an extension to global optimization beamforming for acoustic broadband sources. Given, that properties such as the source location, spatial shape, multipole rotation, or flow properties can be parameterized over the frequency, a CSM-fitting can be performed for all frequencies at the same time. A numerical analysis shows that the non-linear error function for the standard global optimization problem is similar to a Point Spread Function and contains local minima, but can be improved with the proposed broadband optimization. Not only increases the broadband optimization process the ratio of equations to unknown variables, but it also smooths out the cost function. It also simplifies the process of identifying sources and reconstructing their spectra from the results. The paper shows that the method is superior on synthetic monopoles compared to standard global optimization and CLEAN-SC. For real-world data the results of broadband global optimization, standard global optimization, and CLEAN-SC are similar. However, the proposed method does not require the identification and integration of Regions Of Interest. It is shown, that by using reasonable initial values the global optimization problem reduces to a local optimization problem with similar results. Further, it is shown that the proposed method is able to identify multipoles with different pole amplitudes and unknown pole rotations.
An Exponentially-Tight Approximate Factorization of the Joint PDF of Statistical Dependent Measurements in Wireless Sensor Networks
Nov 09, 2022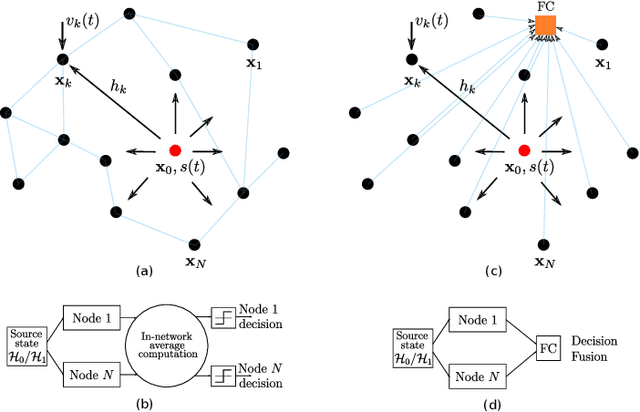
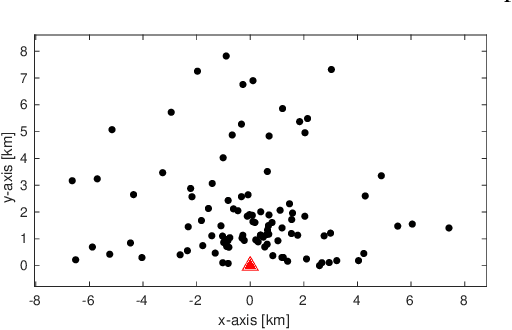
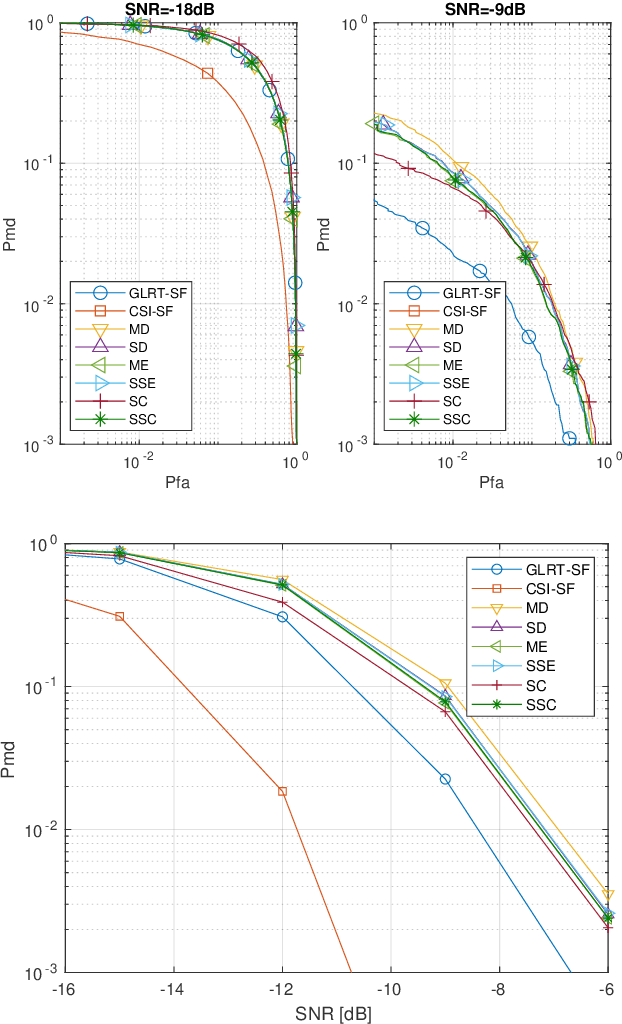
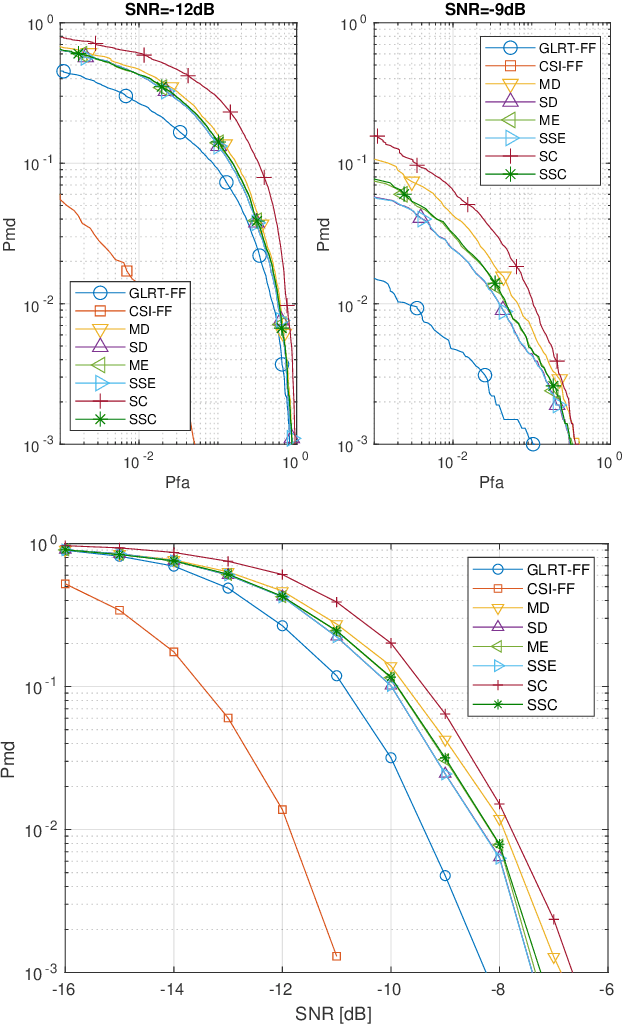
We consider the distributed detection problem of a temporally correlated random radio source signal using a wireless sensor network capable of measuring the energy of the received signals. It is well-known that optimal tests in the Neyman-Pearson setting are based on likelihood ratio tests (LRT), which, in this set-up, evaluate the quotient between the probability density functions (PDF) of the measurements when the source signal is present and absent. When the source is present, the computation of the joint PDF of the energy measurements at the nodes is a challenging problem. This is due to the statistical dependence introduced to the received signals by the radio source propagated through fading channels. We deal with this problem using the characteristic function of the (intractable) joint PDF, and proposing an approximation to it. We derive bounds for the approximation error in two wireless propagation scenarios, slow and fast fading, and show that the proposed approximation is exponentially tight with the number of nodes when the time-bandwidth product is sufficiently high. The approximation is used as a substitute of the exact joint PDF for building an approximate LRT, which performs better than other well-known detectors, as verified by Monte Carlo simulations.
DC-Check: A Data-Centric AI checklist to guide the development of reliable machine learning systems
Nov 09, 2022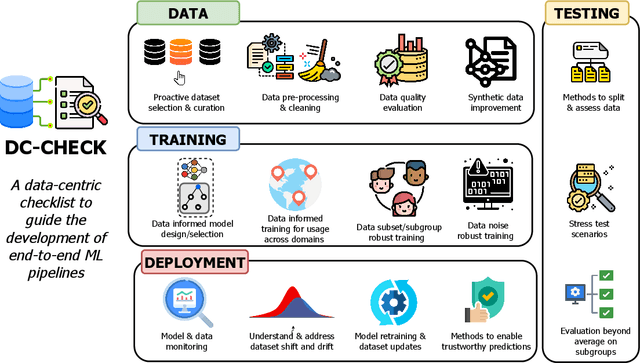
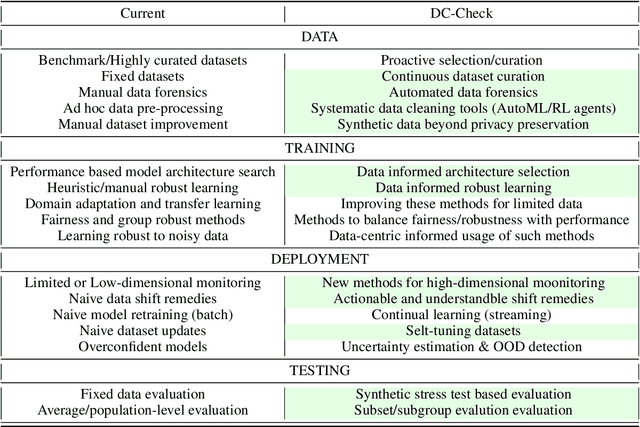
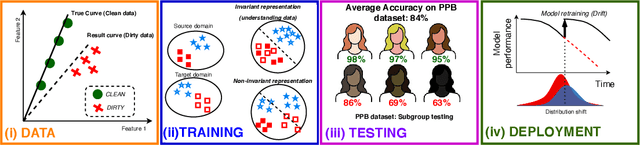
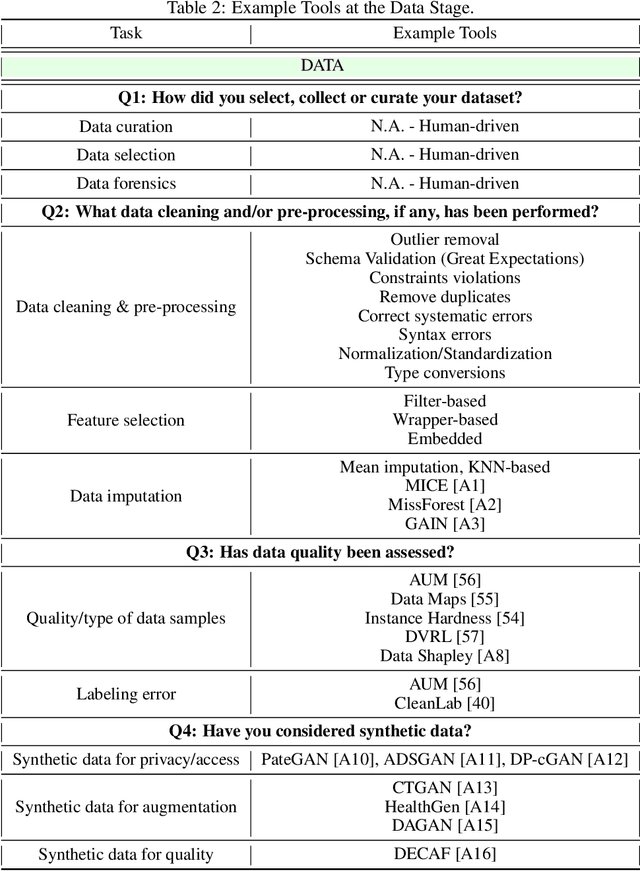
While there have been a number of remarkable breakthroughs in machine learning (ML), much of the focus has been placed on model development. However, to truly realize the potential of machine learning in real-world settings, additional aspects must be considered across the ML pipeline. Data-centric AI is emerging as a unifying paradigm that could enable such reliable end-to-end pipelines. However, this remains a nascent area with no standardized framework to guide practitioners to the necessary data-centric considerations or to communicate the design of data-centric driven ML systems. To address this gap, we propose DC-Check, an actionable checklist-style framework to elicit data-centric considerations at different stages of the ML pipeline: Data, Training, Testing, and Deployment. This data-centric lens on development aims to promote thoughtfulness and transparency prior to system development. Additionally, we highlight specific data-centric AI challenges and research opportunities. DC-Check is aimed at both practitioners and researchers to guide day-to-day development. As such, to easily engage with and use DC-Check and associated resources, we provide a DC-Check companion website (https://www.vanderschaar-lab.com/dc-check/). The website will also serve as an updated resource as methods and tooling evolve over time.