 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
HighlightNet: Highlighting Low-Light Potential Features for Real-Time UAV Tracking
Aug 14, 2022
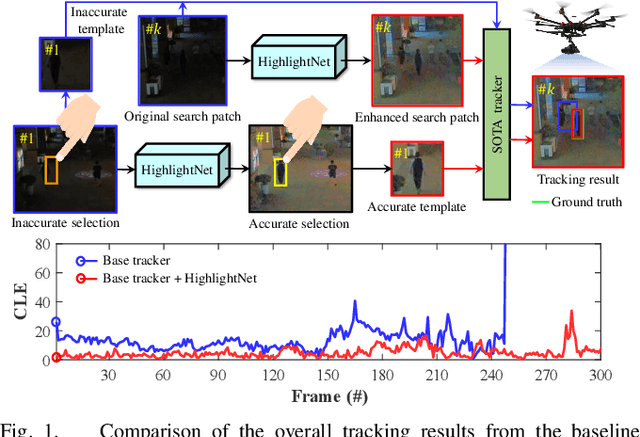
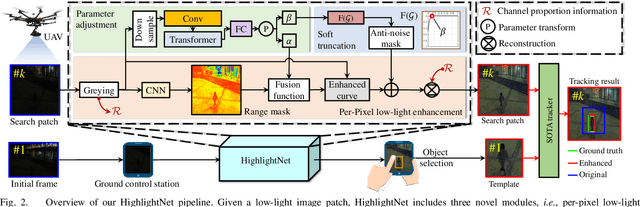


Low-light environments have posed a formidable challenge for robust unmanned aerial vehicle (UAV) tracking even with state-of-the-art (SOTA) trackers since the potential image features are hard to extract under adverse light conditions. Besides, due to the low visibility, accurate online selection of the object also becomes extremely difficult for human monitors to initialize UAV tracking in ground control stations. To solve these problems, this work proposes a novel enhancer, i.e., HighlightNet, to light up potential objects for both human operators and UAV trackers. By employing Transformer, HighlightNet can adjust enhancement parameters according to global features and is thus adaptive for the illumination variation. Pixel-level range mask is introduced to make HighlightNet more focused on the enhancement of the tracking object and regions without light sources. Furthermore, a soft truncation mechanism is built to prevent background noise from being mistaken for crucial features. Evaluations on image enhancement benchmarks demonstrate HighlightNet has advantages in facilitating human perception. Experiments on the public UAVDark135 benchmark show that HightlightNet is more suitable for UAV tracking tasks than other SOTA low-light enhancers. In addition, real-world tests on a typical UAV platform verify HightlightNet's practicability and efficiency in nighttime aerial tracking-related applications. The code and demo videos are available at https://github.com/vision4robotics/HighlightNet.
Building Normalizing Flows with Stochastic Interpolants
Sep 30, 2022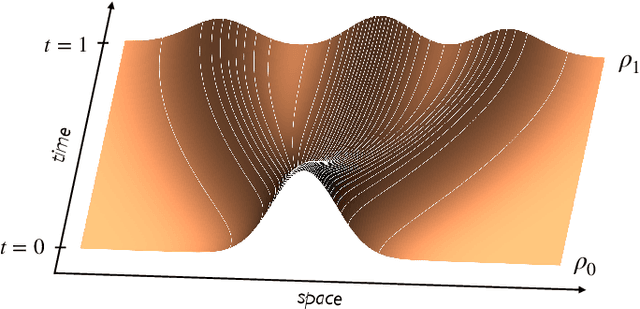


A simple generative model based on a continuous-time normalizing flow between any pair of base and target distributions is proposed. The velocity field of this flow is inferred from the probability current of a time-dependent distribution that interpolates between the base and the target in finite time. Unlike conventional normalizing flow inference methods based the maximum likelihood principle, which require costly backpropagation through ODE solvers, our interpolant approach leads to a simple quadratic loss for the velocity itself which is expressed in terms of expectations that are readily amenable to empirical estimation. The flow can be used to generate samples from either the base or target, and can be used to estimate the likelihood at any time along the interpolant. The approach is contextualized in its relation to diffusions. In particular, in situations where the base is a Gaussian distribution, we show that the velocity of our normalizing flow can also be used to construct a diffusion model to sample the target as well as estimating its score. This allows one to map methods based on stochastic differential equations to those of ordinary differential equations, simplifying the mechanics of the model, but capturing equivalent dynamics. Benchmarking on density estimation tasks illustrates that the learned flow can match and surpass maximum likelihood continuous flows at a fraction of the conventional ODE training costs.
An Empirical Bayes Analysis of Vehicle Trajectory Models
Nov 03, 2022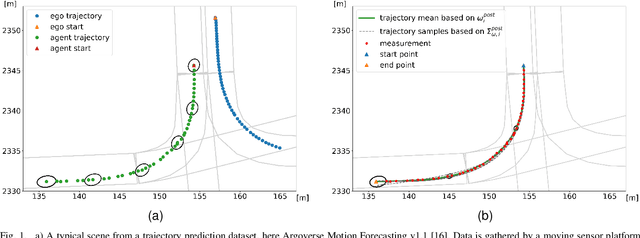
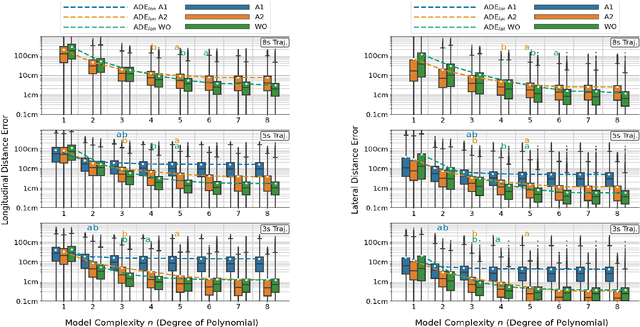
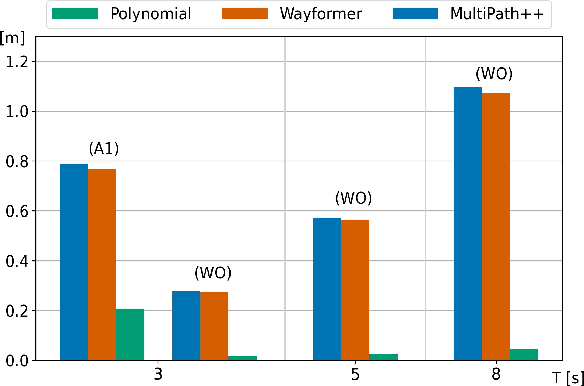
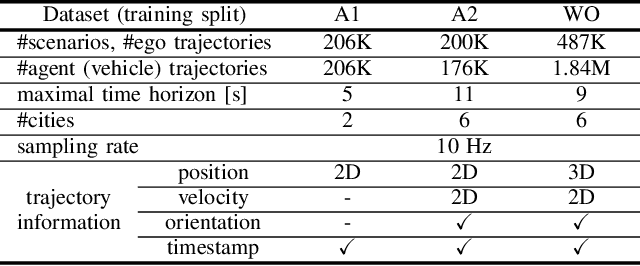
We present an in-depth empirical analysis of the trade-off between model complexity and representation error in modelling vehicle trajectories. Analyzing several large public datasets, we show that simple linear models do represent realworld trajectories with high fidelity over relevant time scales at very moderate model complexity. This finding allows the formulation of trajectory tracking and prediction as a Bayesian filtering problem. Using an Empirical Bayes approach, we estimate prior distributions over model parameters from the data that inform the motion models necessary in the trajectory tracking problem and that can help regularize prediction models. We argue for the use of linear models in trajectory prediction tasks as their representation error is much smaller than the typical epistemic uncertainty in this task.
SL3D: Self-supervised-Self-labeled 3D Recognition
Nov 03, 2022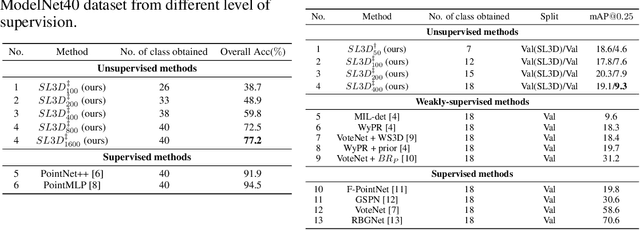
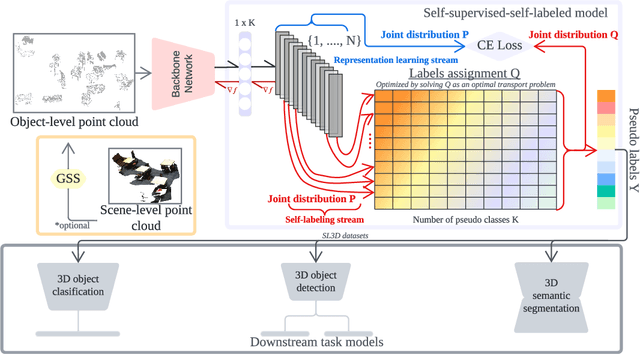
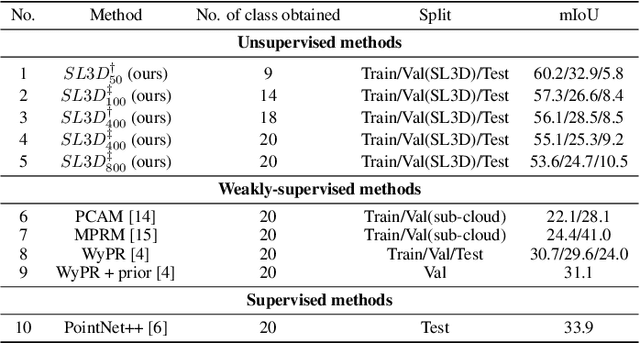
There are a lot of promising results in 3D recognition, including classification, object detection, and semantic segmentation. However, many of these results rely on manually collecting densely annotated real-world 3D data, which is highly time-consuming and expensive to obtain, limiting the scalability of 3D recognition tasks. Thus in this paper, we study unsupervised 3D recognition and propose a Self-supervised-Self-Labeled 3D Recognition (SL3D) framework. SL3D simultaneously solves two coupled objectives, i.e., clustering and learning feature representation to generate pseudo labeled data for unsupervised 3D recognition. SL3D is a generic framework and can be applied to solve different 3D recognition tasks, including classification, object detection, and semantic segmentation. Extensive experiments demonstrate its effectiveness. Code is available at https://github.com/fcendra/sl3d.
Data Fusion for Multipath-Based SLAM: Combing Information from Multiple Propagation Paths
Nov 24, 2022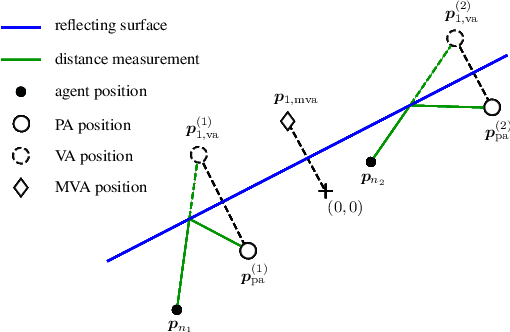
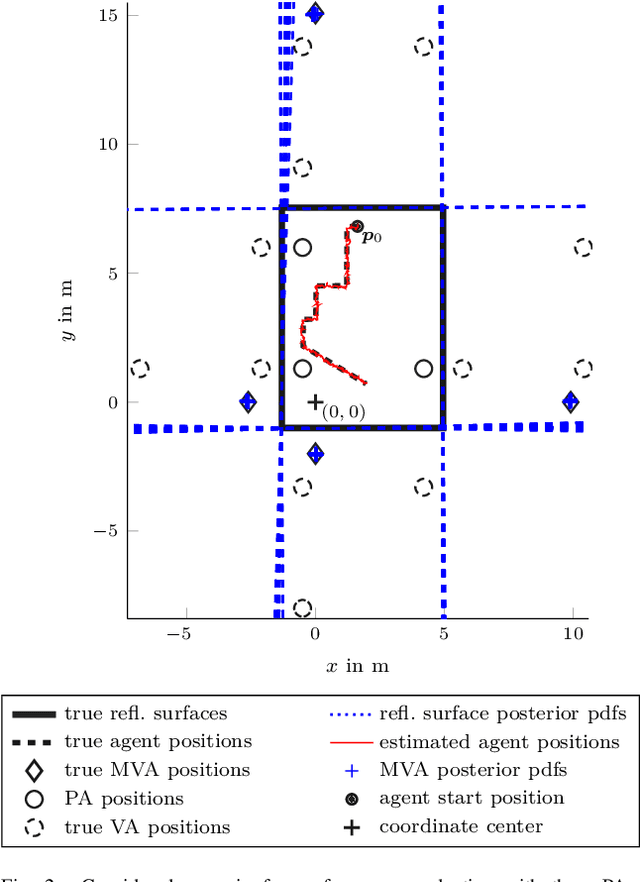
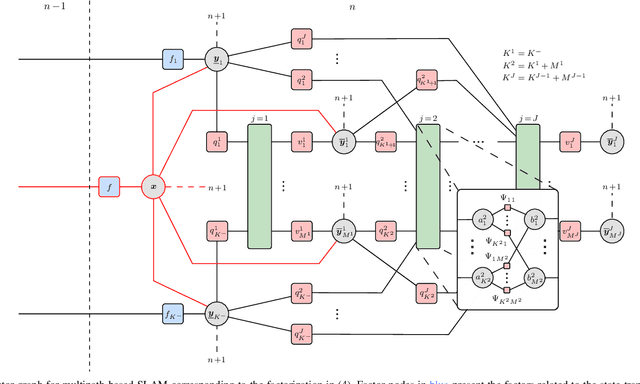
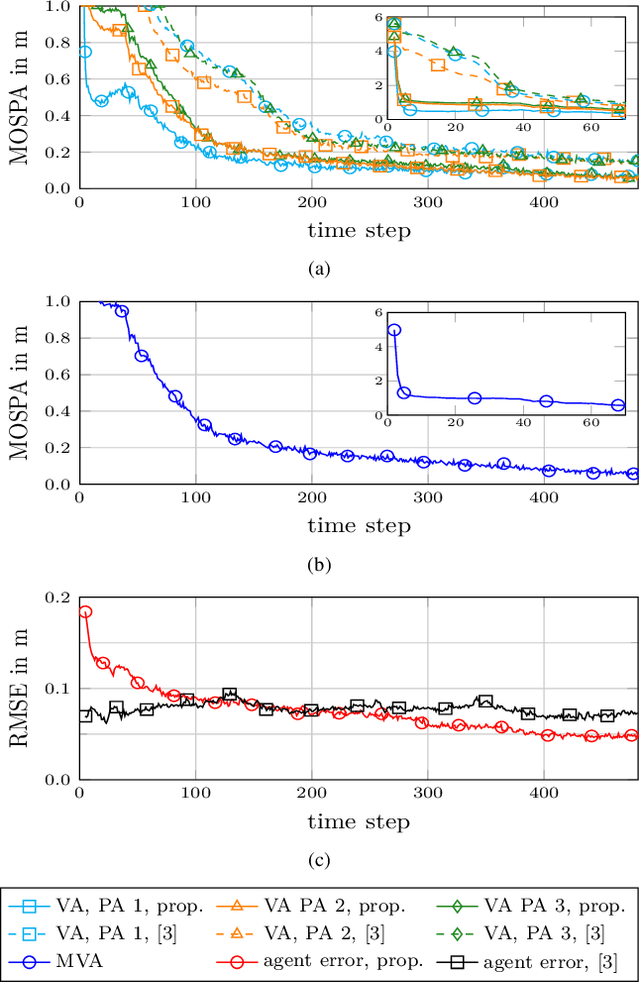
Multipath-based simultaneous localization and mapping (SLAM) is an emerging paradigm for accurate indoor localization with limited resources. The goal of multipath-based SLAM is to detect and localize radio reflective surfaces to support the estimation of time-varying positions of mobile agents. Radio reflective surfaces are typically represented by so-called virtual anchors (VAs), which are mirror images of base stations at the surfaces. In existing multipath-based SLAM methods, a VA is introduced for each propagation path, even if the goal is to map the reflective surfaces. The fact that not every reflective surface but every propagation path is modeled by a VA, complicates a consistent combination "fusion" of statistical information across multiple paths and base stations and thus limits the accuracy and mapping speed of existing multipath-based SLAM methods. In this paper, we introduce an improved statistical model and estimation method that enables data fusion for multipath-based SLAM by representing each surface by a single master virtual anchor (MVA). We further develop a particle-based sum-product algorithm (SPA) that performs probabilistic data association to compute marginal posterior distributions of MVA and agent positions efficiently. A key aspect of the proposed estimation method based on MVAs is to check the availability of single-bounce and double-bounce propagation paths at a specific agent position by means of ray-launching. The availability check is directly integrated into the statistical model by providing detection probabilities for probabilistic data association. Our numerical simulation results demonstrate significant improvements in estimation accuracy and mapping speed compared to state-of-the-art multipath-based SLAM methods.
DBA: Efficient Transformer with Dynamic Bilinear Low-Rank Attention
Nov 24, 2022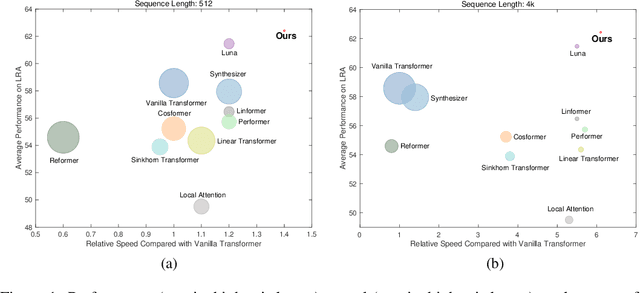
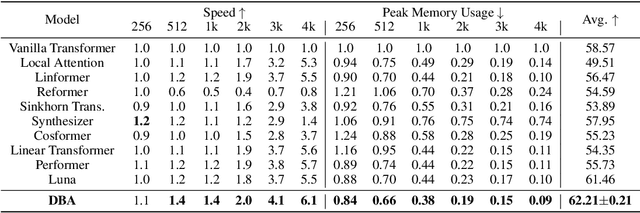
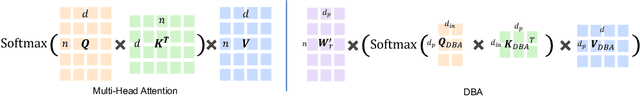
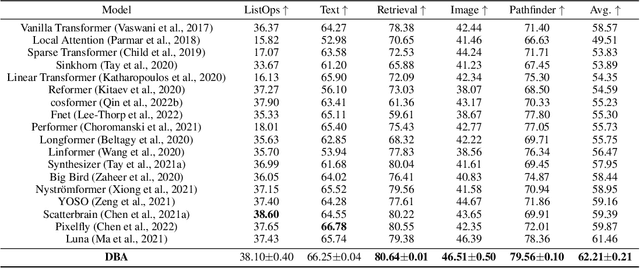
Many studies have been conducted to improve the efficiency of Transformer from quadric to linear. Among them, the low-rank-based methods aim to learn the projection matrices to compress the sequence length. However, the projection matrices are fixed once they have been learned, which compress sequence length with dedicated coefficients for tokens in the same position. Adopting such input-invariant projections ignores the fact that the most informative part of a sequence varies from sequence to sequence, thus failing to preserve the most useful information that lies in varied positions. In addition, previous efficient Transformers only focus on the influence of sequence length while neglecting the effect of hidden state dimension. To address the aforementioned problems, we present an efficient yet effective attention mechanism, namely the Dynamic Bilinear Low-Rank Attention (DBA), which compresses the sequence length by input-sensitive dynamic projection matrices and achieves linear time and space complexity by jointly optimizing the sequence length and hidden state dimension while maintaining state-of-the-art performance. Specifically, we first theoretically demonstrate that the sequence length can be compressed non-destructively from a novel perspective of information theory, with compression matrices dynamically determined by the input sequence. Furthermore, we show that the hidden state dimension can be approximated by extending the Johnson-Lindenstrauss lemma, optimizing the attention in bilinear form. Theoretical analysis shows that DBA is proficient in capturing high-order relations in cross-attention problems. Experiments over tasks with diverse sequence length conditions show that DBA achieves state-of-the-art performance compared with various strong baselines while maintaining less memory consumption with higher speed.
Self-Adaptive Forecasting for Improved Deep Learning on Non-Stationary Time-Series
Feb 04, 2022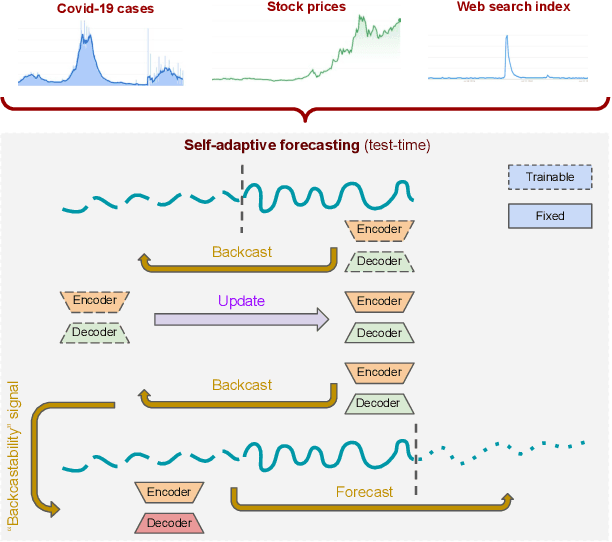

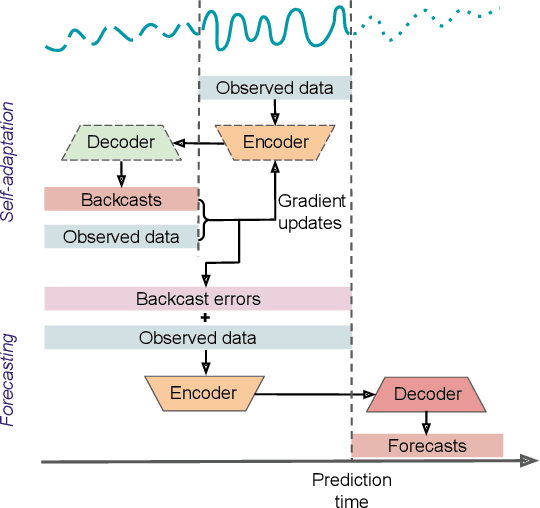
Real-world time-series datasets often violate the assumptions of standard supervised learning for forecasting -- their distributions evolve over time, rendering the conventional training and model selection procedures suboptimal. In this paper, we propose a novel method, Self-Adaptive Forecasting (SAF), to modify the training of time-series forecasting models to improve their performance on forecasting tasks with such non-stationary time-series data. SAF integrates a self-adaptation stage prior to forecasting based on `backcasting', i.e. predicting masked inputs backward in time. This is a form of test-time training that creates a self-supervised learning problem on test samples before performing the prediction task. In this way, our method enables efficient adaptation of encoded representations to evolving distributions, leading to superior generalization. SAF can be integrated with any canonical encoder-decoder based time-series architecture such as recurrent neural networks or attention-based architectures. On synthetic and real-world datasets in domains where time-series data are known to be notoriously non-stationary, such as healthcare and finance, we demonstrate a significant benefit of SAF in improving forecasting accuracy.
Enhancing Cancer Prediction in Challenging Screen-Detected Incident Lung Nodules Using Time-Series Deep Learning
Mar 30, 2022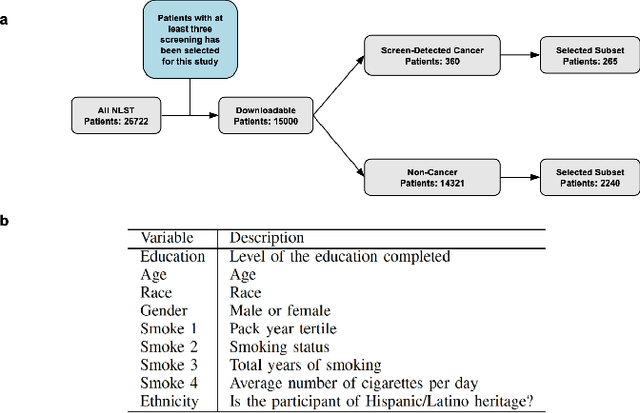
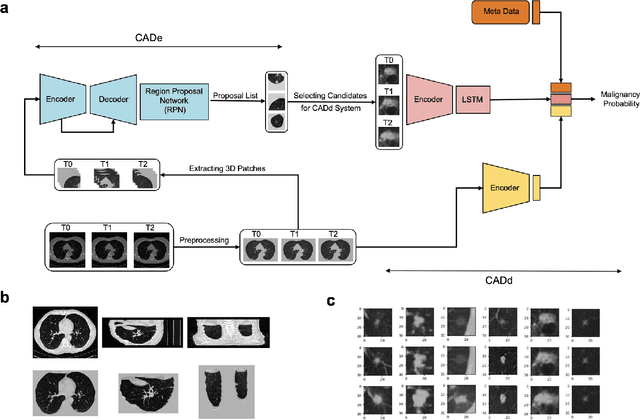
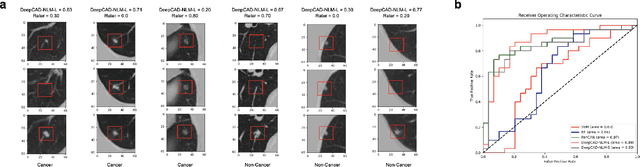

Lung cancer is the leading cause of cancer-related mortality worldwide. Lung cancer screening (LCS) using annual low-dose computed tomography (CT) scanning has been proven to significantly reduce lung cancer mortality by detecting cancerous lung nodules at an earlier stage. Improving risk stratification of malignancy risk in lung nodules can be enhanced using machine/deep learning algorithms. However most existing algorithms: a) have primarily assessed single time-point CT data alone thereby failing to utilize the inherent advantages contained within longitudinal imaging datasets; b) have not integrated into computer models pertinent clinical data that might inform risk prediction; c) have not assessed algorithm performance on the spectrum of nodules that are most challenging for radiologists to interpret and where assistance from analytic tools would be most beneficial. Here we show the performance of our time-series deep learning model (DeepCAD-NLM-L) which integrates multi-model information across three longitudinal data domains: nodule-specific, lung-specific, and clinical demographic data. We compared our time-series deep learning model to a) radiologist performance on CTs from the National Lung Screening Trial enriched with the most challenging nodules for diagnosis; b) a nodule management algorithm from a North London LCS study (SUMMIT). Our model demonstrated comparable and complementary performance to radiologists when interpreting challenging lung nodules and showed improved performance (AUC=88\%) against models utilizing single time-point data only. The results emphasise the importance of time-series, multi-modal analysis when interpreting malignancy risk in LCS.
A Graph-Based Approach to Generate Energy-Optimal Robot Trajectories in Polynomial Environments
Nov 09, 2022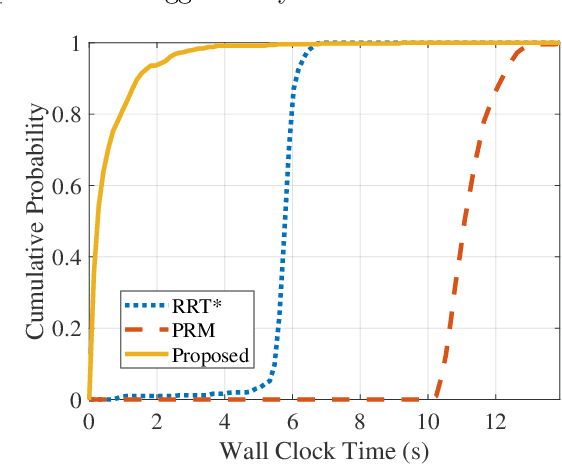
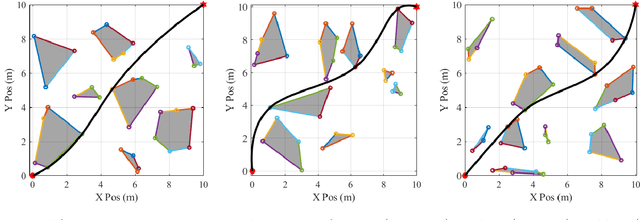
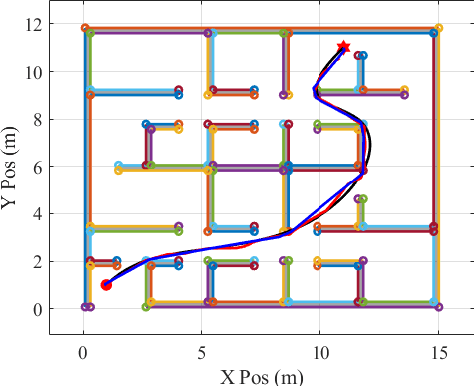
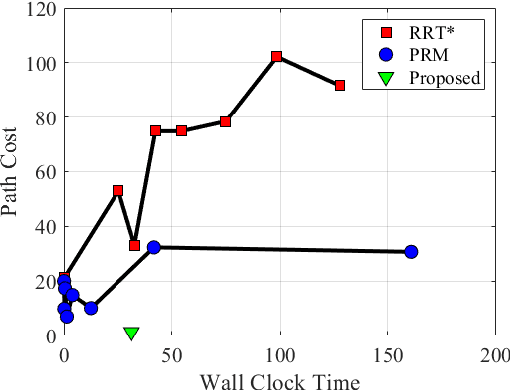
As robotic systems continue to address emerging issues in areas such as logistics, mobility, manufacturing, and disaster response, it is increasingly important to rapidly generate safe and energy-efficient trajectories. In this article, we present a new approach to plan energy-optimal trajectories through cluttered environments containing polygonal obstacles. In particular, we develop a method to quickly generate optimal trajectories for a double-integrator system, and we show that optimal path planning reduces to an integer program. To find an efficient solution, we present a distance-informed prefix search to efficiently generate optimal trajectories for a large class of environments. We demonstrate that our approach, while matching the performance of RRT* and Probabilistic Road Maps in terms of path length, outperforms both in terms of energy cost and computational time by up to an order of magnitude. We also demonstrate that our approach yields implementable trajectories in an experiment with a Crazyflie quadrotor.
Efficient Joint Detection and Multiple Object Tracking with Spatially Aware Transformer
Nov 09, 2022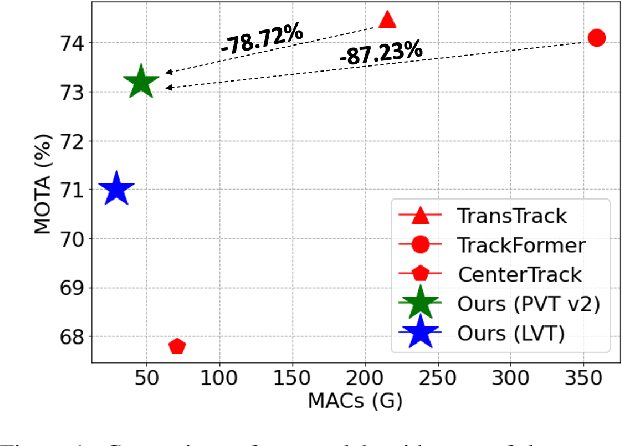
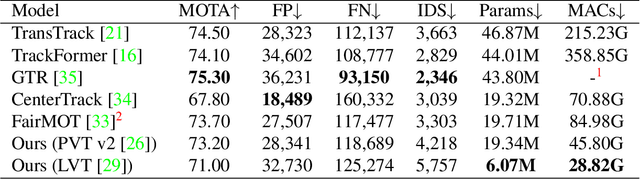
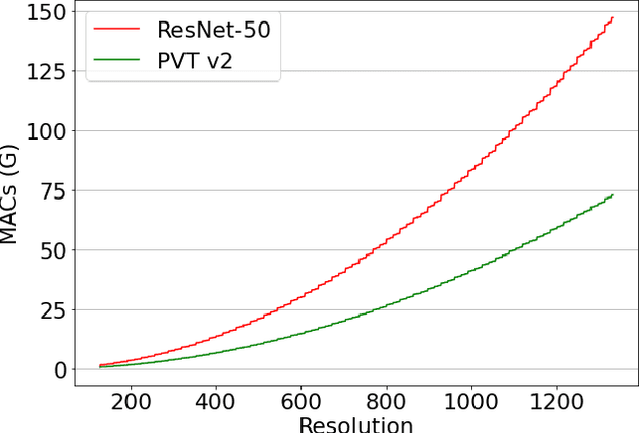
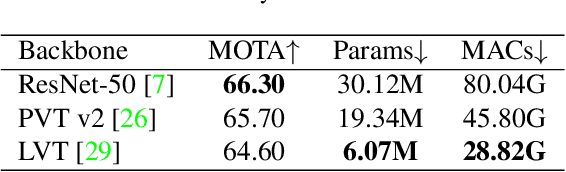
We propose a light-weight and highly efficient Joint Detection and Tracking pipeline for the task of Multi-Object Tracking using a fully-transformer architecture. It is a modified version of TransTrack, which overcomes the computational bottleneck associated with its design, and at the same time, achieves state-of-the-art MOTA score of 73.20%. The model design is driven by a transformer based backbone instead of CNN, which is highly scalable with the input resolution. We also propose a drop-in replacement for Feed Forward Network of transformer encoder layer, by using Butterfly Transform Operation to perform channel fusion and depth-wise convolution to learn spatial context within the feature maps, otherwise missing within the attention maps of the transformer. As a result of our modifications, we reduce the overall model size of TransTrack by 58.73% and the complexity by 78.72%. Therefore, we expect our design to provide novel perspectives for architecture optimization in future research related to multi-object tracking.