 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
BDIS: Bayesian Dense Inverse Searching Method for Real-Time Stereo Surgical Image Matching
May 06, 2022
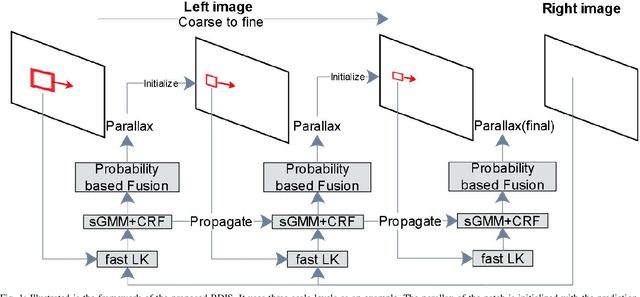
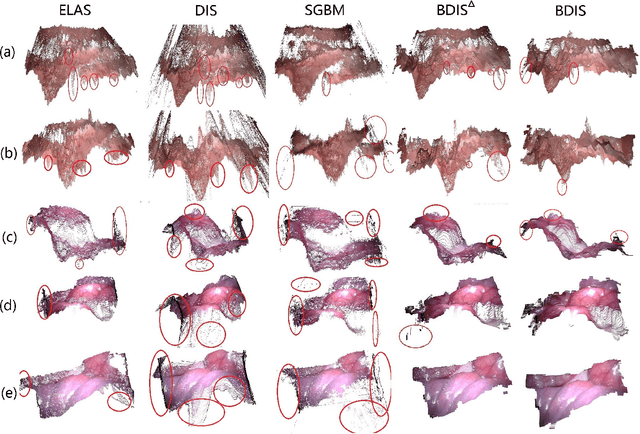
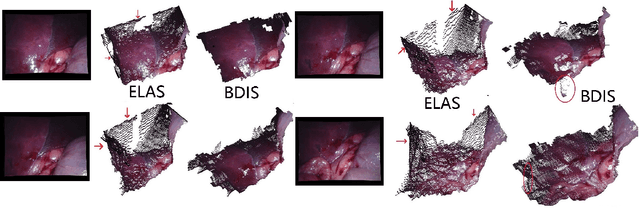
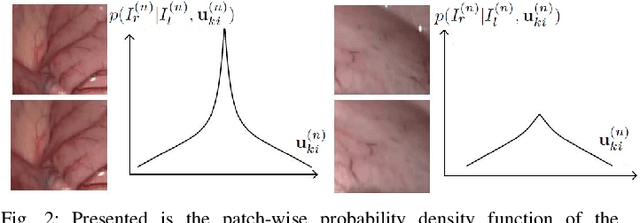
In stereoscope-based Minimally Invasive Surgeries (MIS), dense stereo matching plays an indispensable role in 3D shape recovery, AR, VR, and navigation tasks. Although numerous Deep Neural Network (DNN) approaches are proposed, the conventional prior-free approaches are still popular in the industry because of the lack of open-source annotated data set and the limitation of the task-specific pre-trained DNNs. Among the prior-free stereo matching algorithms, there is no successful real-time algorithm in none GPU environment for MIS. This paper proposes the first CPU-level real-time prior-free stereo matching algorithm for general MIS tasks. We achieve an average 17 Hz on 640*480 images with a single-core CPU (i5-9400) for surgical images. Meanwhile, it achieves slightly better accuracy than the popular ELAS. The patch-based fast disparity searching algorithm is adopted for the rectified stereo images. A coarse-to-fine Bayesian probability and a spatial Gaussian mixed model were proposed to evaluate the patch probability at different scales. An optional probability density function estimation algorithm was adopted to quantify the prediction variance. Extensive experiments demonstrated the proposed method's capability to handle ambiguities introduced by the textureless surfaces and the photometric inconsistency from the non-Lambertian reflectance and dark illumination. The estimated probability managed to balance the confidences of the patches for stereo images at different scales. It has similar or higher accuracy and fewer outliers than the baseline ELAS in MIS, while it is 4-5 times faster. The code and the synthetic data sets are available at https://github.com/JingweiSong/BDIS-v2.
Active Localization using Bernstein Distribution Functions
Oct 06, 2022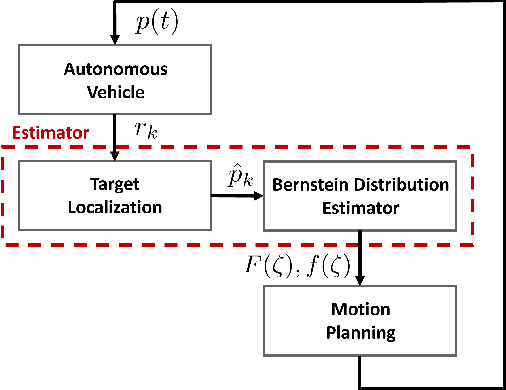
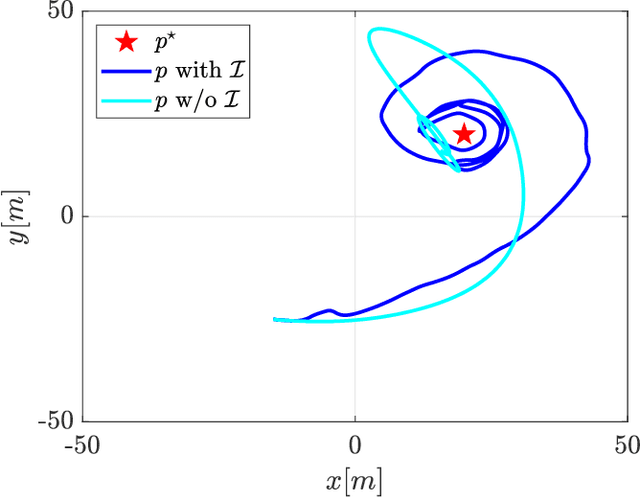
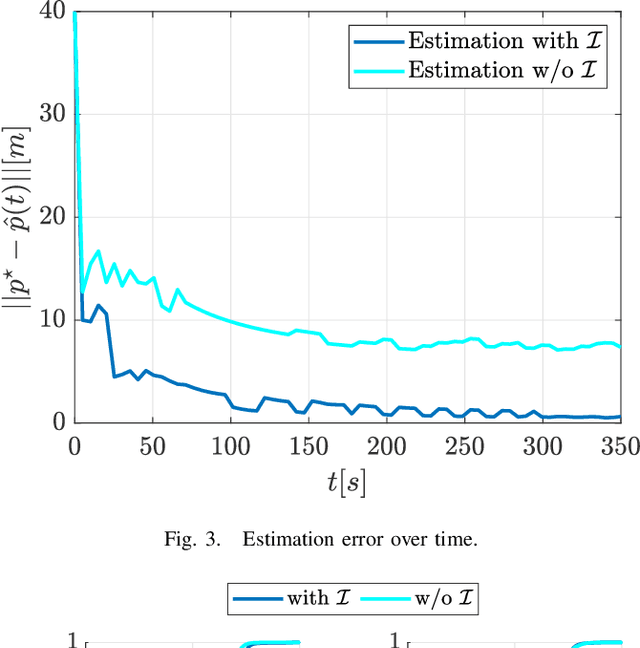
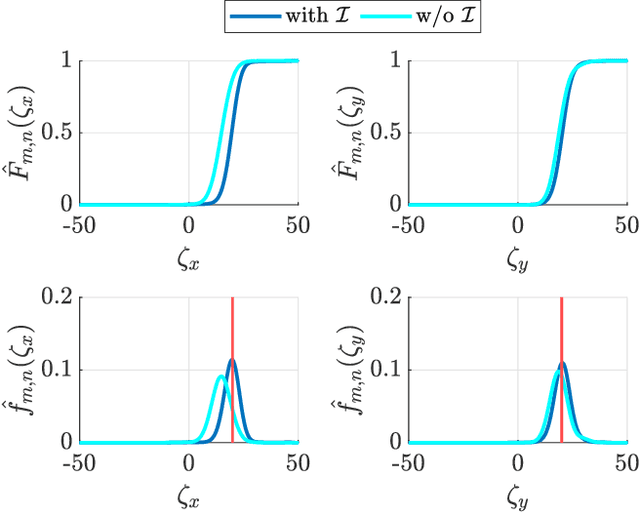
In this work, we present a framework that enables a vehicle to autonomously localize a target based on noisy range measurements computed from RSSI data. To achieve the mission objectives, we develop a control scheme composed of two main parts: an estimator and a motion planner. At each time step, new estimates of the target's position are computed and used to generate and update distribution functions using Bernstein polynomials. A metric of the efficiency of the estimator is derived based on the Fisher Information Matrix. Finally, the motion planning problem is formulated to react in real time to new information about the target and improve the estimator's performance.
Efficiently Controlling Multiple Risks with Pareto Testing
Oct 14, 2022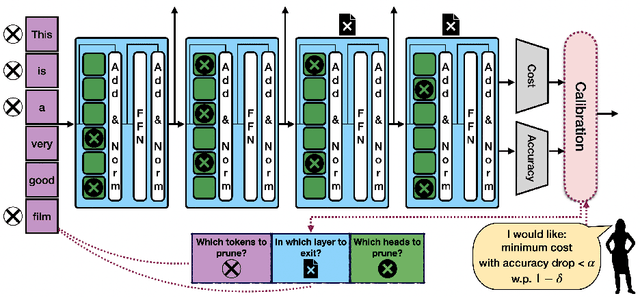
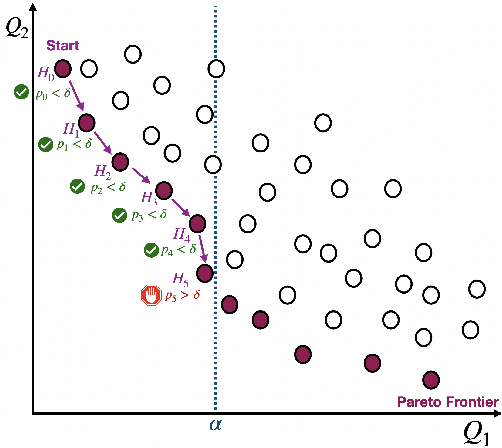
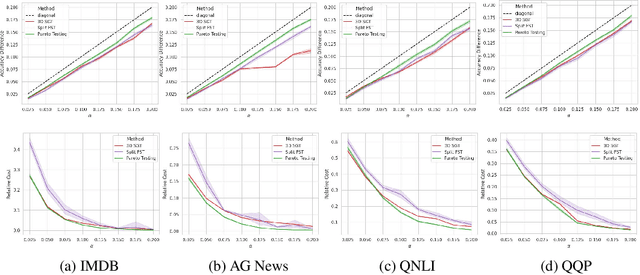
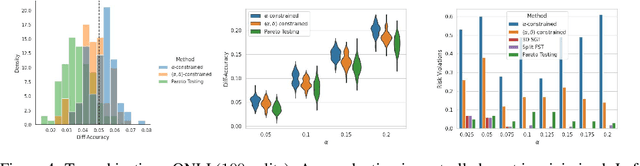
Machine learning applications frequently come with multiple diverse objectives and constraints that can change over time. Accordingly, trained models can be tuned with sets of hyper-parameters that affect their predictive behavior (e.g., their run-time efficiency versus error rate). As the number of constraints and hyper-parameter dimensions grow, naively selected settings may lead to sub-optimal and/or unreliable results. We develop an efficient method for calibrating models such that their predictions provably satisfy multiple explicit and simultaneous statistical guarantees (e.g., upper-bounded error rates), while also optimizing any number of additional, unconstrained objectives (e.g., total run-time cost). Building on recent results in distribution-free, finite-sample risk control for general losses, we propose Pareto Testing: a two-stage process which combines multi-objective optimization with multiple hypothesis testing. The optimization stage constructs a set of promising combinations on the Pareto frontier. We then apply statistical testing to this frontier only to identify configurations that have (i) high utility with respect to our objectives, and (ii) guaranteed risk levels with respect to our constraints, with specifiable high probability. We demonstrate the effectiveness of our approach to reliably accelerate the execution of large-scale Transformer models in natural language processing (NLP) applications. In particular, we show how Pareto Testing can be used to dynamically configure multiple inter-dependent model attributes -- including the number of layers computed before exiting, number of attention heads pruned, or number of text tokens considered -- to simultaneously control and optimize various accuracy and cost metrics.
An Advantage Using Feature Selection with a Quantum Annealer
Nov 17, 2022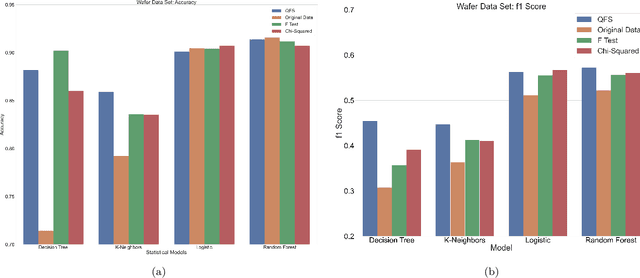
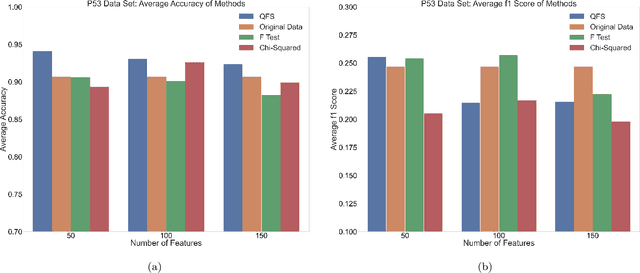
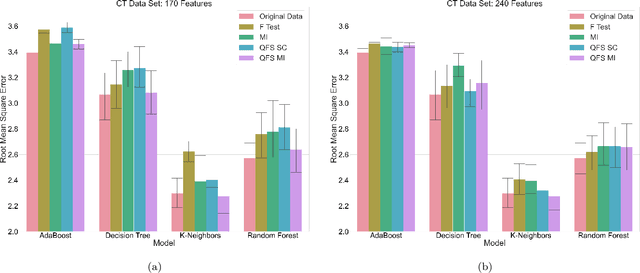
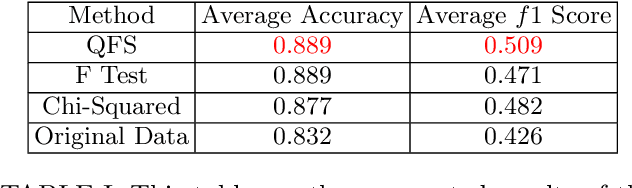
Feature selection is a technique in statistical prediction modeling that identifies features in a record with a strong statistical connection to the target variable. Excluding features with a weak statistical connection to the target variable in training not only drops the dimension of the data, which decreases the time complexity of the algorithm, it also decreases noise within the data which assists in avoiding overfitting. In all, feature selection assists in training a robust statistical model that performs well and is stable. Given the lack of scalability in classical computation, current techniques only consider the predictive power of the feature and not redundancy between the features themselves. Recent advancements in feature selection that leverages quantum annealing (QA) gives a scalable technique that aims to maximize the predictive power of the features while minimizing redundancy. As a consequence, it is expected that this algorithm would assist in the bias/variance trade-off yielding better features for training a statistical model. This paper tests this intuition against classical methods by utilizing open-source data sets and evaluate the efficacy of each trained statistical model well-known prediction algorithms. The numerical results display an advantage utilizing the features selected from the algorithm that leveraged QA.
Perturbation-Recovery Method for Recommendation
Nov 17, 2022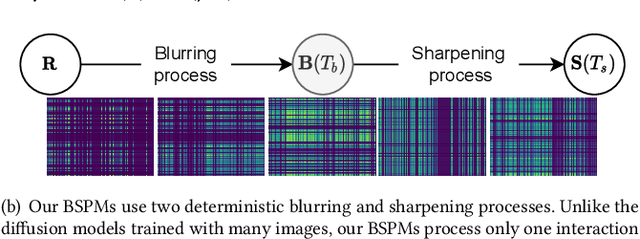


Collaborative filtering is one of the most influential recommender system types. Various methods have been proposed for collaborative filtering, ranging from matrix factorization to graph convolutional methods. Being inspired by recent successes of GF-CF and diffusion models, we present a novel concept of blurring-sharpening process model (BSPM). Diffusion models and BSPMs share the same processing philosophy in that new information is discovered (e.g., a new image is generated in the case of diffusion models) while original information is first perturbed and then recovered to its original form. However, diffusion models and our BSPMs deal with different types of information, and their optimal perturbation and recovery processes have a fundamental discrepancy. Therefore, our BSPMs have different forms from diffusion models. In addition, our concept not only theoretically subsumes many existing collaborative filtering models but also outperforms them in terms of Recall and NDCG in the three benchmark datasets, Gowalla, Yelp2018, and Amazon-book. Our model marks the best accuracy in them. In addition, the processing time of our method is one of the shortest cases ever in collaborative filtering. Our proposed concept has much potential in the future to be enhanced by designing better blurring (i.e., perturbation) and sharpening (i.e., recovery) processes than what we use in this paper.
Performance, Transparency and Time. Feature selection to speed up the diagnosis of Parkinson's disease
Jun 08, 2022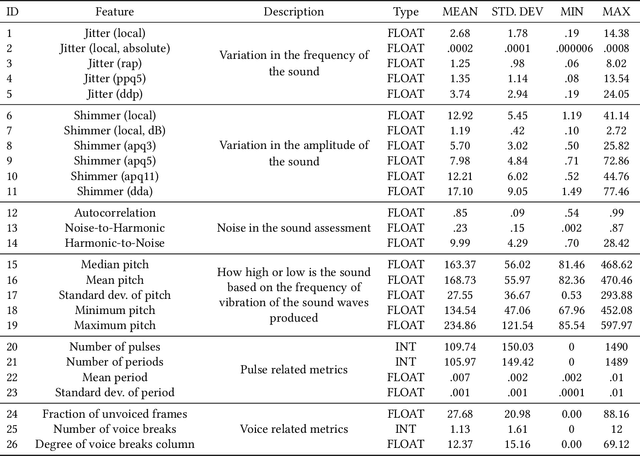
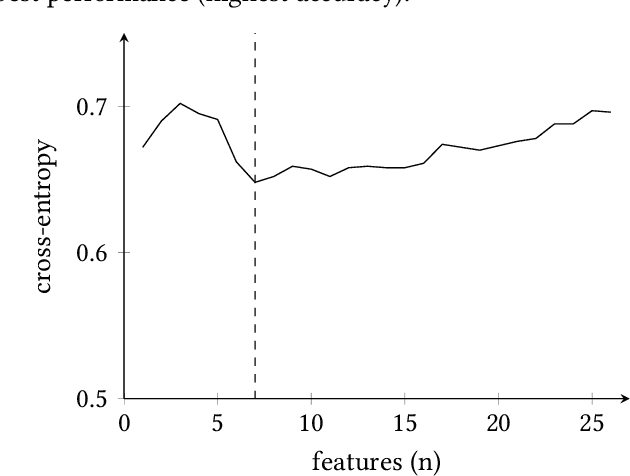
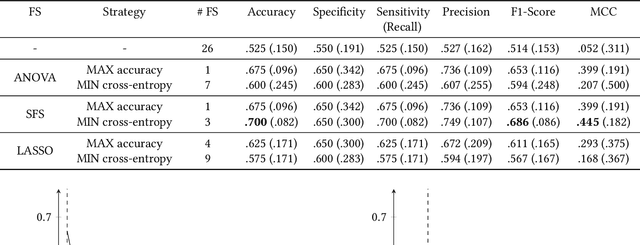
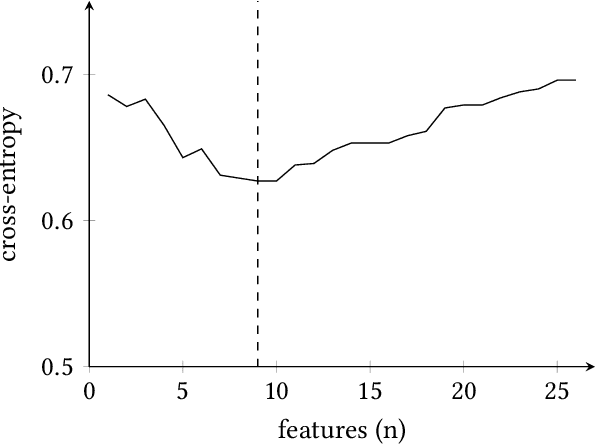
Accurate and early prediction of a disease allows to plan and improve a patient's quality of future life. During pandemic situations, the medical decision becomes a speed challenge in which physicians have to act fast to diagnose and predict the risk of the severity of the disease, moreover this is also of high priority for neurodegenerative diseases like Parkinson's disease. Machine Learning (ML) models with Features Selection (FS) techniques can be applied to help physicians to quickly diagnose a disease. FS optimally subset features that improve a model performance and help reduce the number of needed tests for a patient and hence speeding up the diagnosis. This study shows the result of three Feature Selection (FS) techniques pre-applied to a classifier algorithm, Logistic Regression, on non-invasive test results data. The three FS are Analysis of Variance (ANOVA) as filter based method, Least Absolute Shrinkage and Selection Operator (LASSO) as embedded method and Sequential Feature Selection (SFS) as wrapper method. The outcome shows that FS technique can help to build an efficient and effective classifier, hence improving the performance of the classifier while reducing the computation time.
Resolving the Approximability of Offline and Online Non-monotone DR-Submodular Maximization over General Convex Sets
Oct 12, 2022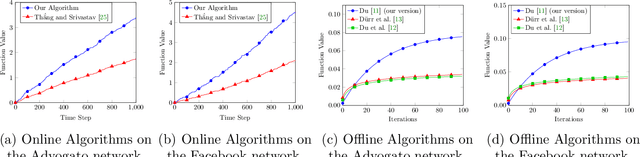
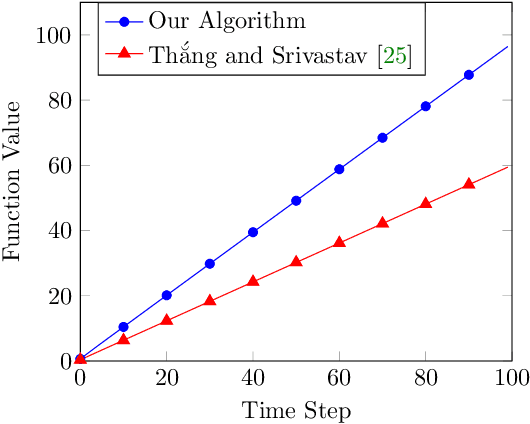
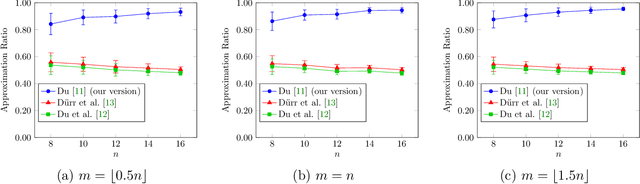
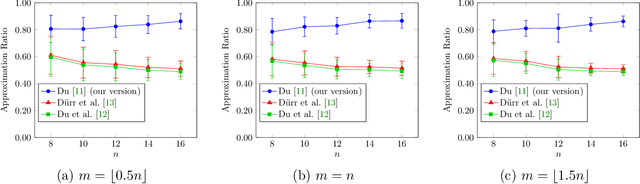
In recent years, maximization of DR-submodular continuous functions became an important research field, with many real-worlds applications in the domains of machine learning, communication systems, operation research and economics. Most of the works in this field study maximization subject to down-closed convex set constraints due to an inapproximability result by Vondr\'ak (2013). However, Durr et al. (2021) showed that one can bypass this inapproximability by proving approximation ratios that are functions of $m$, the minimum $\ell_{\infty}$-norm of any feasible vector. Given this observation, it is possible to get results for maximizing a DR-submodular function subject to general convex set constraints, which has led to multiple works on this problem. The most recent of which is a polynomial time $\tfrac{1}{4}(1 - m)$-approximation offline algorithm due to Du (2022). However, only a sub-exponential time $\tfrac{1}{3\sqrt{3}}(1 - m)$-approximation algorithm is known for the corresponding online problem. In this work, we present a polynomial time online algorithm matching the $\tfrac{1}{4}(1 - m)$-approximation of the state-of-the-art offline algorithm. We also present an inapproximability result showing that our online algorithm and Du's (2022) offline algorithm are both optimal in a strong sense. Finally, we study the empirical performance of our algorithm and the algorithm of Du (which was only theoretically studied previously), and show that they consistently outperform previously suggested algorithms on revenue maximization, location summarization and quadratic programming applications.
Background-Mixed Augmentation for Weakly Supervised Change Detection
Nov 21, 2022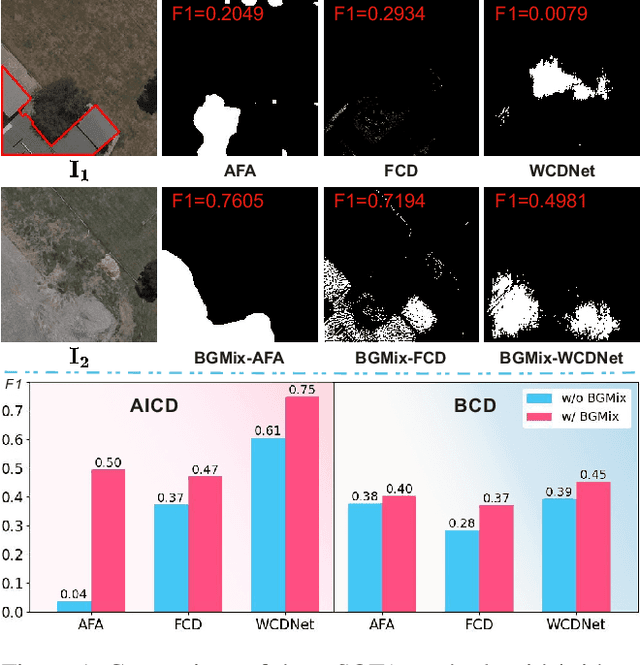
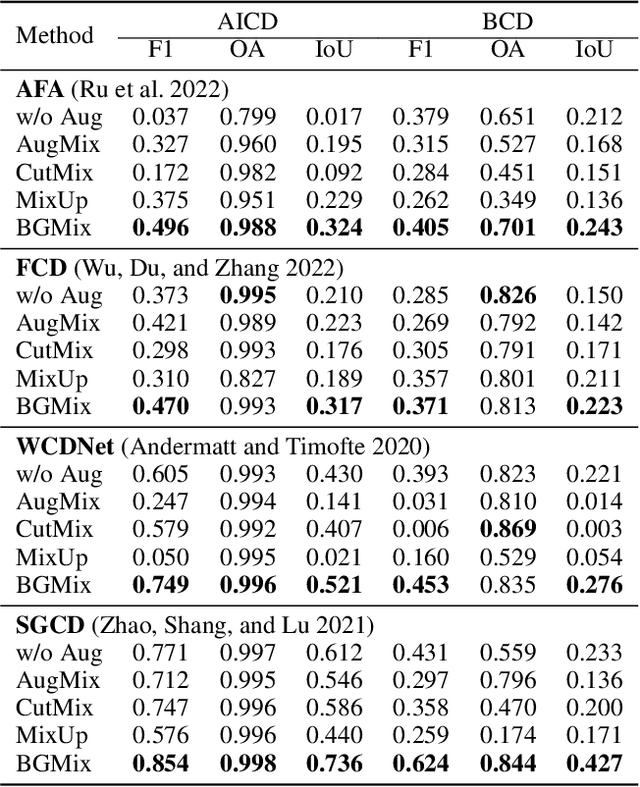

Change detection (CD) is to decouple object changes (i.e., object missing or appearing) from background changes (i.e., environment variations) like light and season variations in two images captured in the same scene over a long time span, presenting critical applications in disaster management, urban development, etc. In particular, the endless patterns of background changes require detectors to have a high generalization against unseen environment variations, making this task significantly challenging. Recent deep learning-based methods develop novel network architectures or optimization strategies with paired-training examples, which do not handle the generalization issue explicitly and require huge manual pixel-level annotation efforts. In this work, for the first attempt in the CD community, we study the generalization issue of CD from the perspective of data augmentation and develop a novel weakly supervised training algorithm that only needs image-level labels. Different from general augmentation techniques for classification, we propose the background-mixed augmentation that is specifically designed for change detection by augmenting examples under the guidance of a set of background changing images and letting deep CD models see diverse environment variations. Moreover, we propose the augmented & real data consistency loss that encourages the generalization increase significantly. Our method as a general framework can enhance a wide range of existing deep learning-based detectors. We conduct extensive experiments in two public datasets and enhance four state-of-the-art methods, demonstrating the advantages of
Self-supervised Trajectory Representation Learning with Temporal Regularities and Travel Semantics
Nov 21, 2022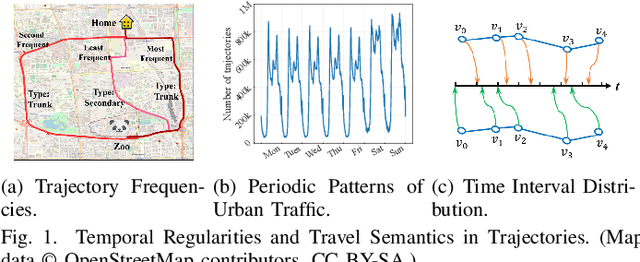
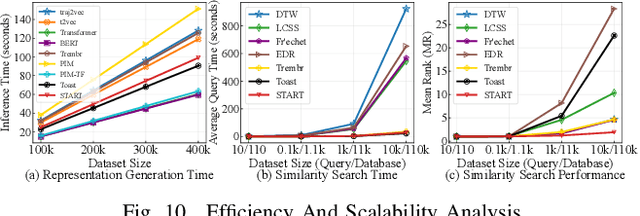
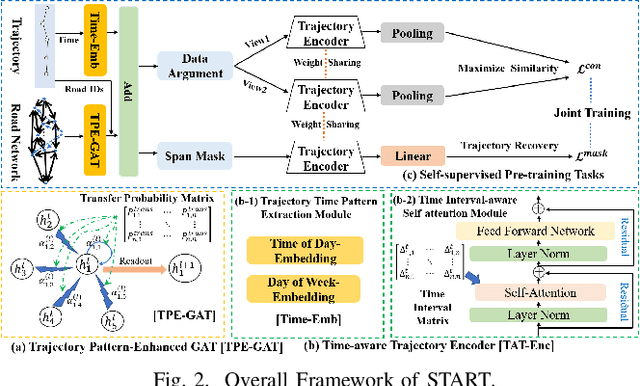
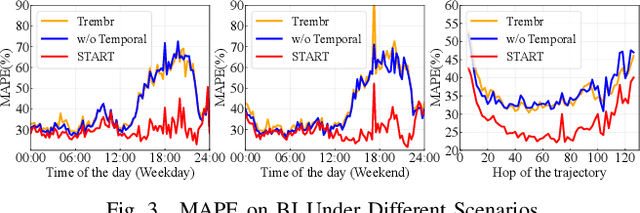
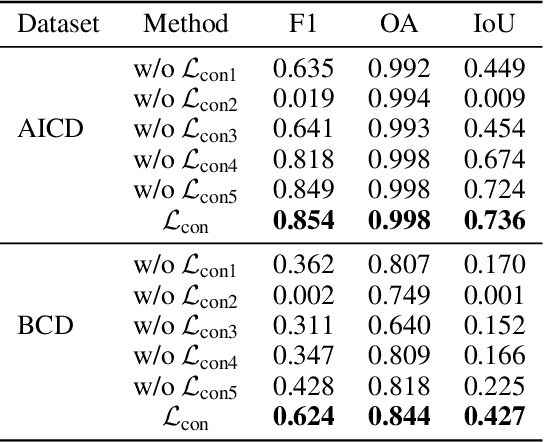
Trajectory Representation Learning (TRL) is a powerful tool for spatial-temporal data analysis and management. TRL aims to convert complicated raw trajectories into low-dimensional representation vectors, which can be applied to various downstream tasks, such as trajectory classification, clustering, and similarity computation. Existing TRL works usually treat trajectories as ordinary sequence data, while some important spatial-temporal characteristics, such as temporal regularities and travel semantics, are not fully exploited. To fill this gap, we propose a novel Self-supervised trajectory representation learning framework with TemporAl Regularities and Travel semantics, namely START. The proposed method consists of two stages. The first stage is a Trajectory Pattern-Enhanced Graph Attention Network (TPE-GAT), which converts the road network features and travel semantics into representation vectors of road segments. The second stage is a Time-Aware Trajectory Encoder (TAT-Enc), which encodes representation vectors of road segments in the same trajectory as a trajectory representation vector, meanwhile incorporating temporal regularities with the trajectory representation. Moreover, we also design two self-supervised tasks, i.e., span-masked trajectory recovery and trajectory contrastive learning, to introduce spatial-temporal characteristics of trajectories into the training process of our START framework. The effectiveness of the proposed method is verified by extensive experiments on two large-scale real-world datasets for three downstream tasks. The experiments also demonstrate that our method can be transferred across different cities to adapt heterogeneous trajectory datasets.
Artificial ASMR: A Cyber-Psychological Study
Oct 27, 2022
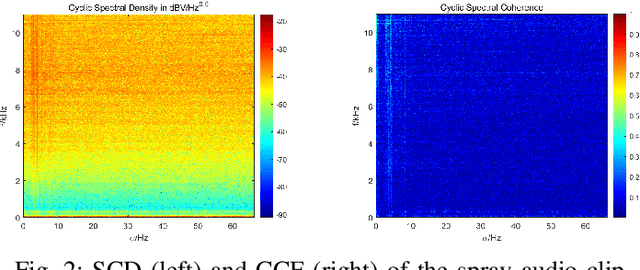
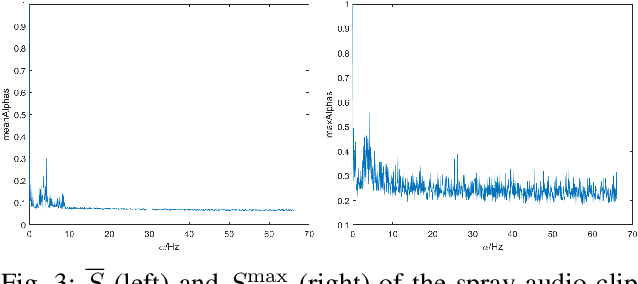
The popularity of Autonomous Sensory Meridian Response (ASMR) has skyrockteted over the past decade, but scientific studies on it are still few and immature. With our attention caught by the common acoustic patterns in ASMR audios, we investigate the correlation between the time-frequency and cyclic features of audio signals and their effectiveness in triggering ASMR effects. A cyber-psychological approach that combines signal processing, artificial intelligence, and experimental psychology is taken, with which we are able to identify ASMR-related acoustic features, and therewith synthesize random artificial ASMR audios.