 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Impedance Variation Detection at MISO Receivers
Nov 07, 2022
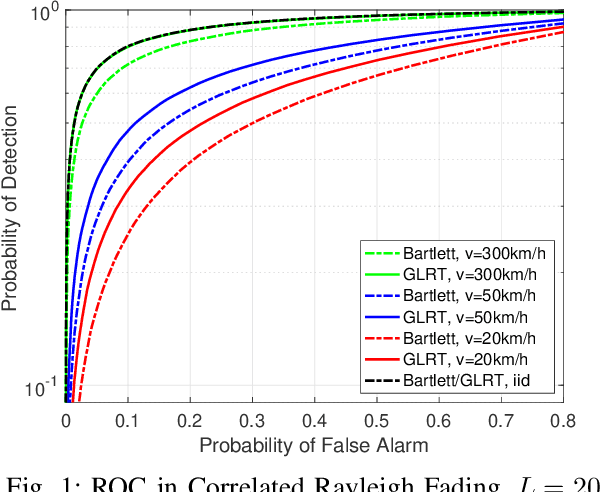
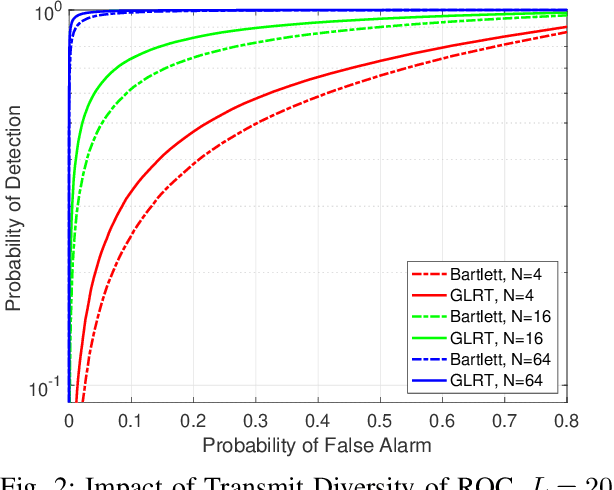
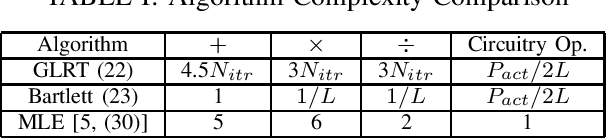
Techniques have been proposed to estimate unknown antenna impedance due to time-varying near-field loading conditions at multiple-input single-output (MISO) receivers. However, it remains unclear when a change occurs and impedance estimation becomes necessary. In this letter, we address this problem by formulating it as a hypothesis test. Our contributions include deriving a generalized likelihood-ratio test (GLRT) detector to decide if the antenna impedance has changed over two groups of packets. This GLRT formulation leads to a novel optimization problem, but we propose a binary search based algorithm to solve it efficiently. Our derived GLRT detector enjoys a better detection and false alarm trade-off when compared with a well-known, reference detector in simulations. As one result, more transmit diversity significantly improves detection accuracy at a given false alarm rate, especially in slow fading channels.
ConchShell: A Generative Adversarial Networks that Turns Pictures into Piano Music
Oct 11, 2022

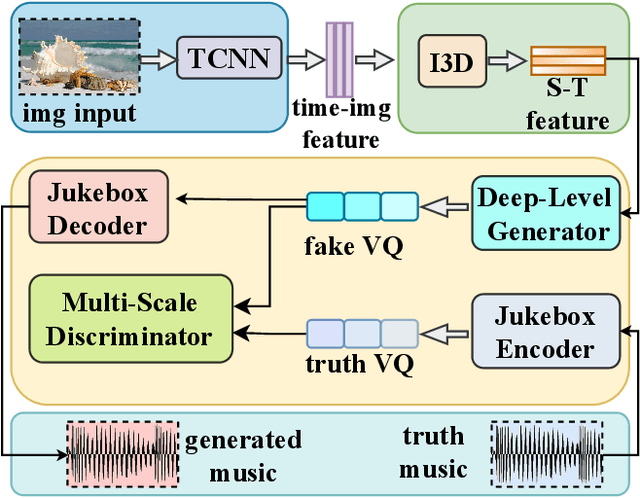
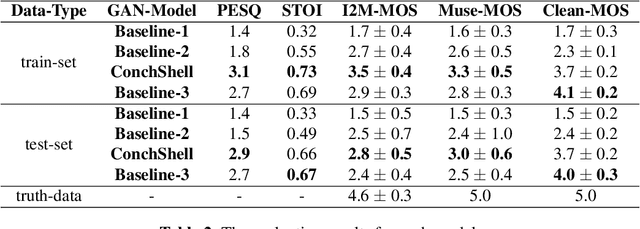
We present ConchShell, a multi-modal generative adversarial framework that takes pictures as input to the network and generates piano music samples that match the picture context. Inspired by I3D, we introduce a novel image feature representation method: time-convolutional neural network (TCNN), which is used to forge features for images in the temporal dimension. Although our image data consists of only six categories, our proposed framework will be innovative and commercially meaningful. The project will provide technical ideas for work such as 3D game voice overs, short-video soundtracks, and real-time generation of metaverse background music.We have also released a new dataset, the Beach-Ocean-Piano Dataset (BOPD) 1, which contains more than 3,000 images and more than 1,500 piano pieces. This dataset will support multimodal image-to-music research.
DeepParliament: A Legal domain Benchmark & Dataset for Parliament Bills Prediction
Nov 15, 2022
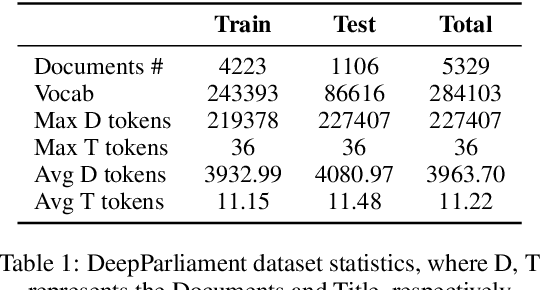
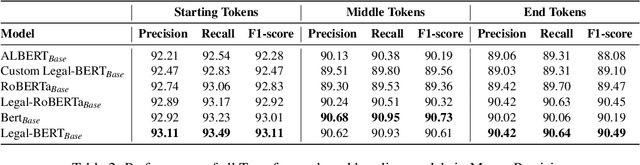
This paper introduces DeepParliament, a legal domain Benchmark Dataset that gathers bill documents and metadata and performs various bill status classification tasks. The proposed dataset text covers a broad range of bills from 1986 to the present and contains richer information on parliament bill content. Data collection, detailed statistics and analyses are provided in the paper. Moreover, we experimented with different types of models ranging from RNN to pretrained and reported the results. We are proposing two new benchmarks: Binary and Multi-Class Bill Status classification. Models developed for bill documents and relevant supportive tasks may assist Members of Parliament (MPs), presidents, and other legal practitioners. It will help review or prioritise bills, thus speeding up the billing process, improving the quality of decisions and reducing the time consumption in both houses. Considering that the foundation of the country's democracy is Parliament and state legislatures, we anticipate that our research will be an essential addition to the Legal NLP community. This work will be the first to present a Parliament bill prediction task. In order to improve the accessibility of legal AI resources and promote reproducibility, we have made our code and dataset publicly accessible at github.com/monk1337/DeepParliament
Collaborative and AI-aided Exam Question Generation using Wikidata in Education
Nov 15, 2022
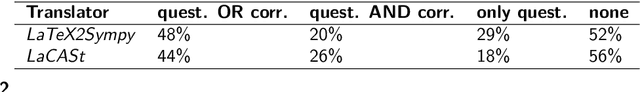

Since the COVID-19 outbreak, the use of digital learning or education platforms has significantly increased. Teachers now digitally distribute homework and provide exercise questions. In both cases, teachers need to continuously develop novel and individual questions. This process can be very time-consuming and should be facilitated and accelerated both through exchange with other teachers and by using Artificial Intelligence (AI) capabilities. To address this need, we propose a multilingual Wikimedia framework that allows for collaborative worldwide teacher knowledge engineering and subsequent AI-aided question generation, test, and correction. As a proof of concept, we present >>PhysWikiQuiz<<, a physics question generation and test engine. Our system (hosted by Wikimedia at https://physwikiquiz.wmflabs.org) retrieves physics knowledge from the open community-curated database Wikidata. It can generate questions in different variations and verify answer values and units using a Computer Algebra System (CAS). We evaluate the performance on a public benchmark dataset at each stage of the system workflow. For an average formula with three variables, the system can generate and correct up to 300 questions for individual students based on a single formula concept name as input by the teacher.
Particle Filter based Massive MIMO Channel Estimation
Nov 02, 2022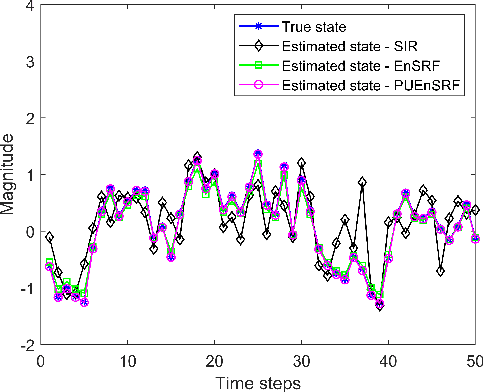
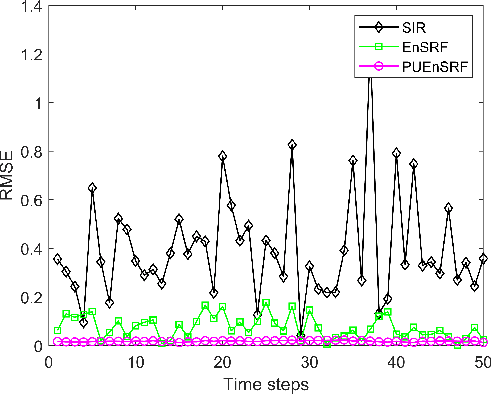
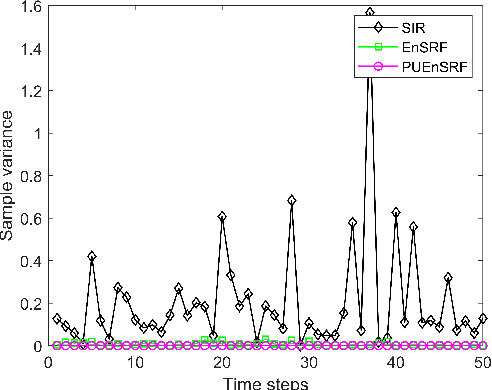
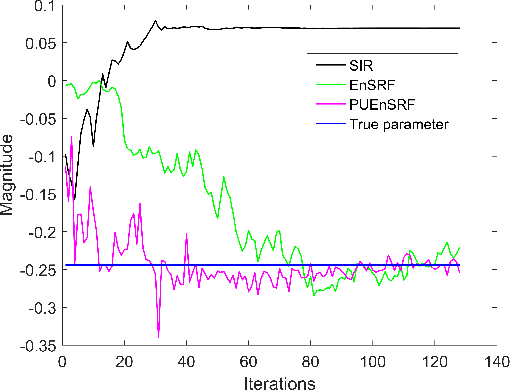
Massive multiple-input multiple-output (MIMO) communication systems have drawn significant interest recently in next-generation wireless communications. The use of a large number of antennas in massive MIMO makes the estimation of channel state information very challenging. Accurate channel state information is essential in capitalizing the advantages of the massive MIMO technology. This paper proposes the application of the Ensemble Square Root Filter (EnSRF) and a variant of EnSRF, namely a Particle wise Update version of the Ensemble Square Root Filter (PUEnSRF) to estimate the time-selective frequency-flat fading channel coefficients in the massive MIMO scenario. Simulation results clearly indicate the remarkably superior accuracy and filter convergence of PUEnSRF estimates as compared to the conventional particle filters.
Evaluating k-NN in the Classification of Data Streams with Concept Drift
Oct 06, 2022
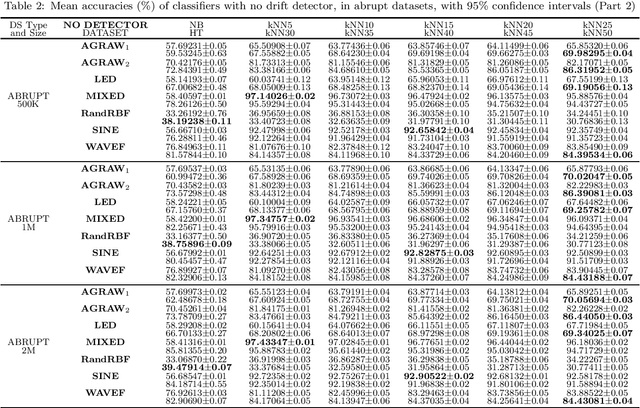
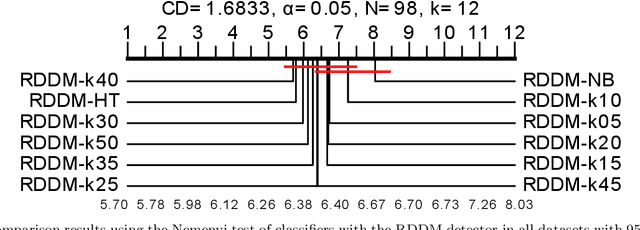
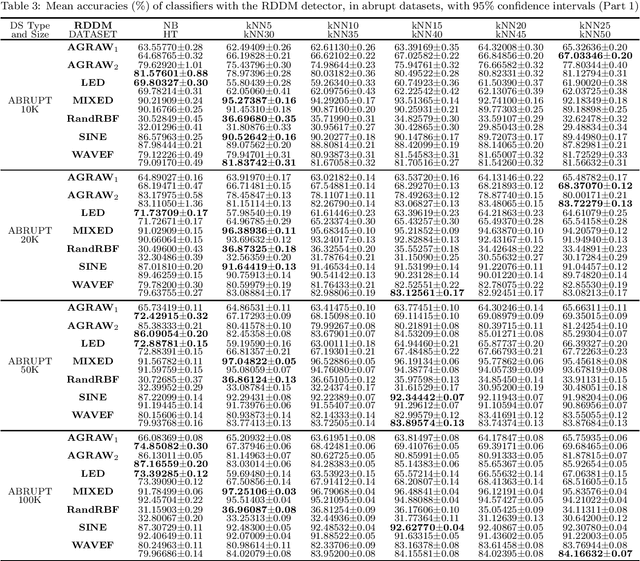
Data streams are often defined as large amounts of data flowing continuously at high speed. Moreover, these data are likely subject to changes in data distribution, known as concept drift. Given all the reasons mentioned above, learning from streams is often online and under restrictions of memory consumption and run-time. Although many classification algorithms exist, most of the works published in the area use Naive Bayes (NB) and Hoeffding Trees (HT) as base learners in their experiments. This article proposes an in-depth evaluation of k-Nearest Neighbors (k-NN) as a candidate for classifying data streams subjected to concept drift. It also analyses the complexity in time and the two main parameters of k-NN, i.e., the number of nearest neighbors used for predictions (k), and window size (w). We compare different parameter values for k-NN and contrast it to NB and HT both with and without a drift detector (RDDM) in many datasets. We formulated and answered 10 research questions which led to the conclusion that k-NN is a worthy candidate for data stream classification, especially when the run-time constraint is not too restrictive.
Efficient shallow learning as an alternative to deep learning
Nov 23, 2022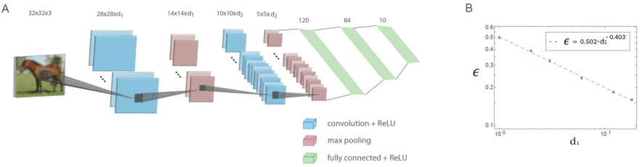
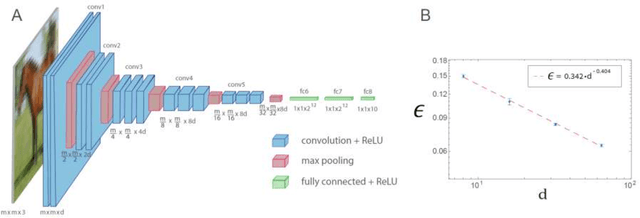
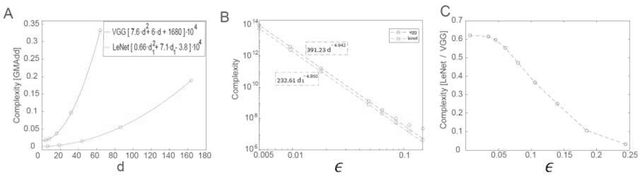
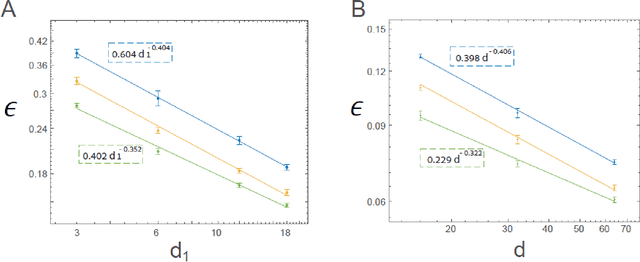
The realization of complex classification tasks requires training of deep learning (DL) architectures consisting of tens or even hundreds of convolutional and fully connected hidden layers, which is far from the reality of the human brain. According to the DL rationale, the first convolutional layer reveals localized patterns in the input and large-scale patterns in the following layers, until it reliably characterizes a class of inputs. Here, we demonstrate that with a fixed ratio between the depths of the first and second convolutional layers, the error rates of the generalized shallow LeNet architecture, consisting of only five layers, decay as a power law with the number of filters in the first convolutional layer. The extrapolation of this power law indicates that the generalized LeNet can achieve small error rates that were previously obtained for the CIFAR-10 database using DL architectures. A power law with a similar exponent also characterizes the generalized VGG-16 architecture. However, this results in a significantly increased number of operations required to achieve a given error rate with respect to LeNet. This power law phenomenon governs various generalized LeNet and VGG-16 architectures, hinting at its universal behavior and suggesting a quantitative hierarchical time-space complexity among machine learning architectures. Additionally, the conservation law along the convolutional layers, which is the square-root of their size times their depth, is found to asymptotically minimize error rates. The efficient shallow learning that is demonstrated in this study calls for further quantitative examination using various databases and architectures and its accelerated implementation using future dedicated hardware developments.
CMT: Interpretable Model for Rapid Recognition Pneumonia from Chest X-Ray Images by Fusing Low Complexity Multilevel Attention Mechanism
Oct 29, 2022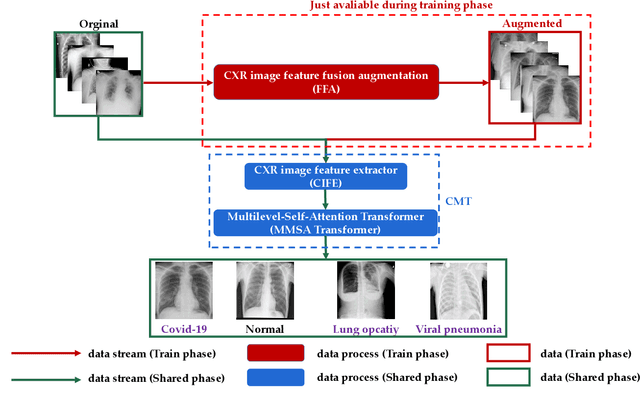
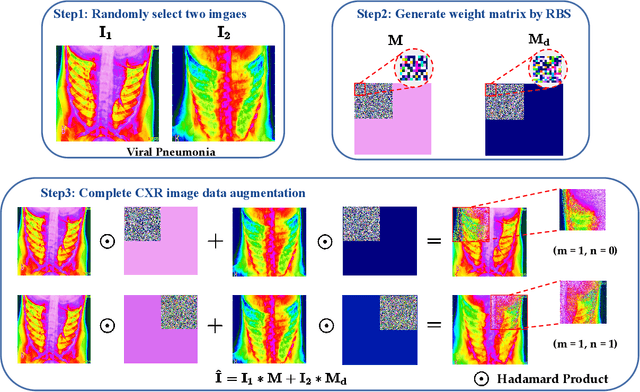
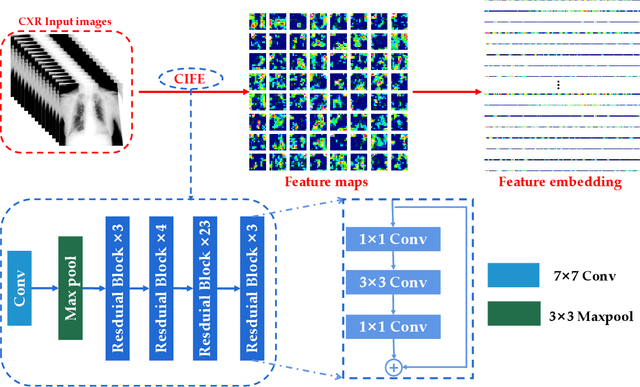
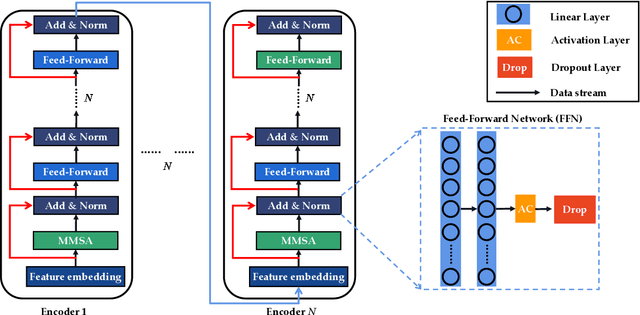
Chest imaging plays an essential role in diagnosing and predicting patients with COVID-19 with evidence of worsening respiratory status. Many deep learning-based diagnostic models for pneumonia have been developed to enable computer-aided diagnosis. However, the long training and inference time make them inflexible. In addition, the lack of interpretability reduces their credibility in clinical medical practice. This paper presents CMT, a model with interpretability and rapid recognition of pneumonia, especially COVID-19 positive. Multiple convolutional layers in CMT are first used to extract features in CXR images, and then Transformer is applied to calculate the possibility of each symptom. To improve the model's generalization performance and to address the problem of sparse medical image data, we propose Feature Fusion Augmentation (FFA), a plug-and-play method for image augmentation. It fuses the features of the two images to varying degrees to produce a new image that does not deviate from the original distribution. Furthermore, to reduce the computational complexity and accelerate the convergence, we propose Multilevel Multi-Head Self-Attention (MMSA), which computes attention on different levels to establish the relationship between global and local features. It significantly improves the model performance while substantially reducing its training and inference time. Experimental results on the largest COVID-19 dataset show the proposed CMT has state-of-the-art performance. The effectiveness of FFA and MMSA is demonstrated in the ablation experiments. In addition, the weights and feature activation maps of the model inference process are visualized to show the CMT's interpretability.
Boosting Monocular 3D Object Detection with Object-Centric Auxiliary Depth Supervision
Oct 29, 2022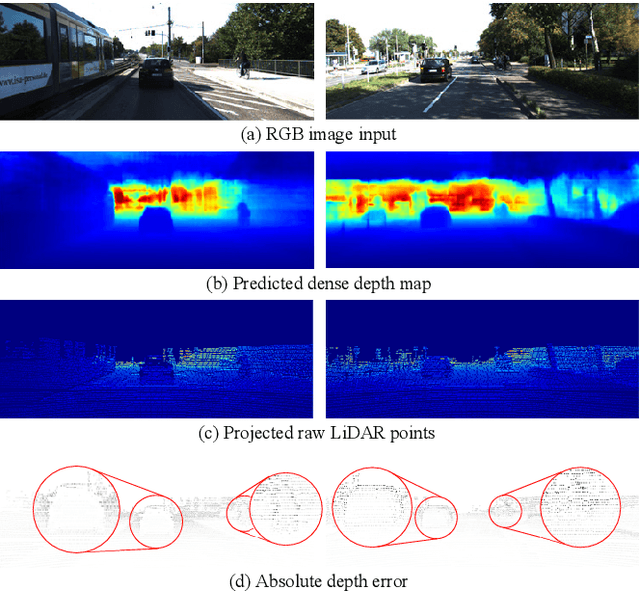
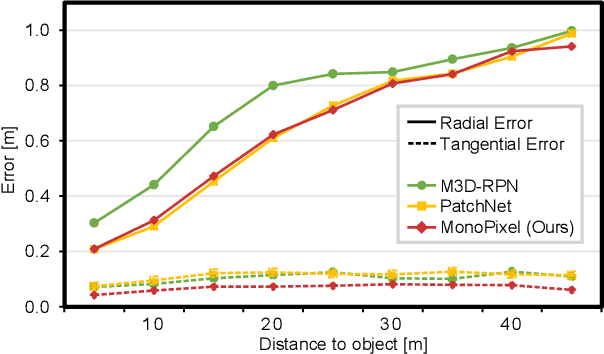
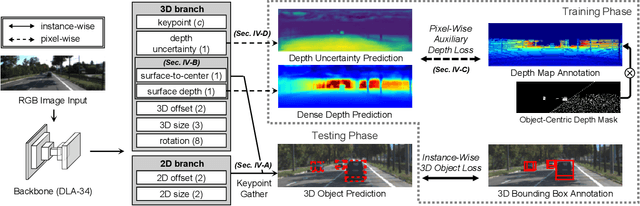
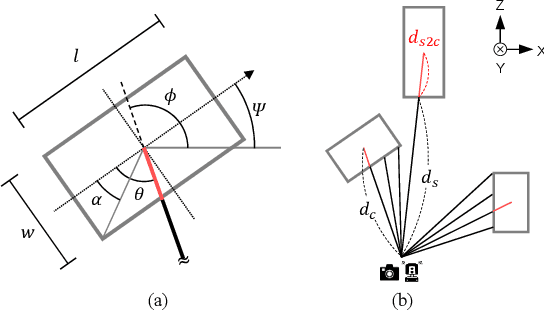
Recent advances in monocular 3D detection leverage a depth estimation network explicitly as an intermediate stage of the 3D detection network. Depth map approaches yield more accurate depth to objects than other methods thanks to the depth estimation network trained on a large-scale dataset. However, depth map approaches can be limited by the accuracy of the depth map, and sequentially using two separated networks for depth estimation and 3D detection significantly increases computation cost and inference time. In this work, we propose a method to boost the RGB image-based 3D detector by jointly training the detection network with a depth prediction loss analogous to the depth estimation task. In this way, our 3D detection network can be supervised by more depth supervision from raw LiDAR points, which does not require any human annotation cost, to estimate accurate depth without explicitly predicting the depth map. Our novel object-centric depth prediction loss focuses on depth around foreground objects, which is important for 3D object detection, to leverage pixel-wise depth supervision in an object-centric manner. Our depth regression model is further trained to predict the uncertainty of depth to represent the 3D confidence of objects. To effectively train the 3D detector with raw LiDAR points and to enable end-to-end training, we revisit the regression target of 3D objects and design a network architecture. Extensive experiments on KITTI and nuScenes benchmarks show that our method can significantly boost the monocular image-based 3D detector to outperform depth map approaches while maintaining the real-time inference speed.
2D and 3D CT Radiomic Features Performance Comparison in Characterization of Gastric Cancer: A Multi-center Study
Oct 29, 2022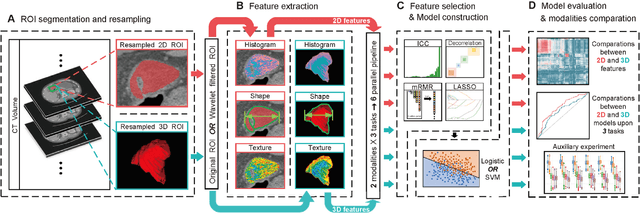
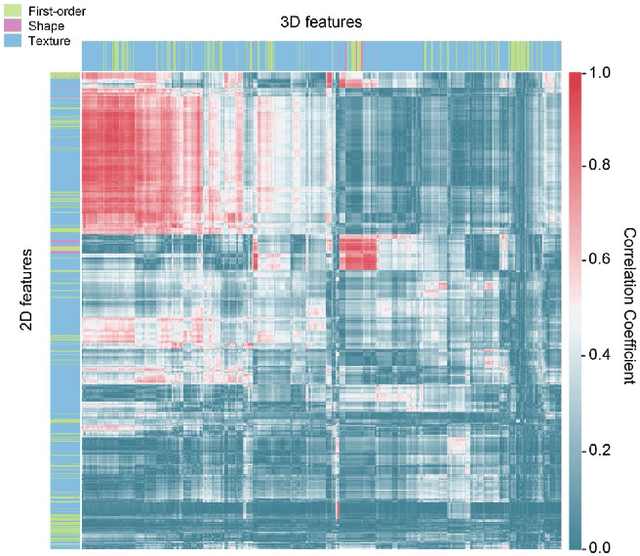
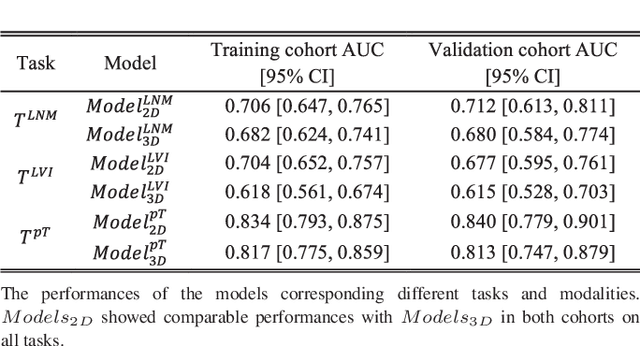
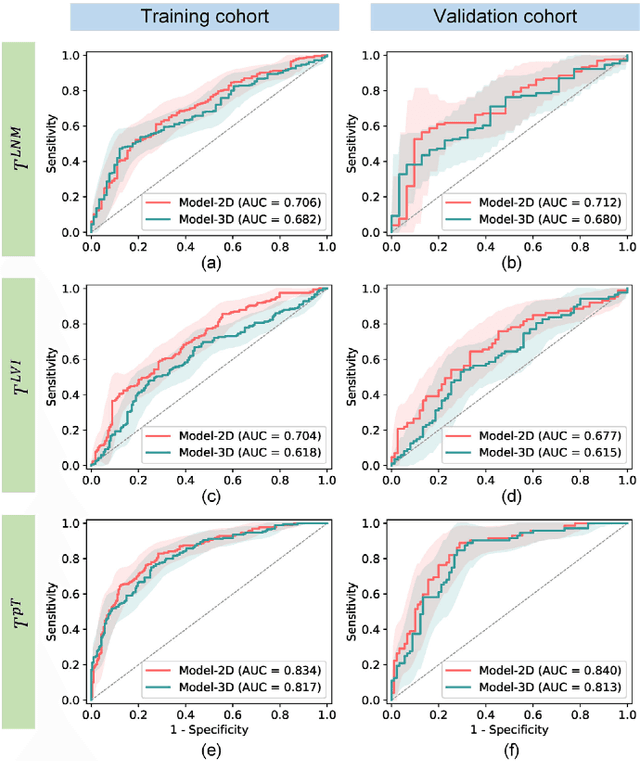
Objective: Radiomics, an emerging tool for medical image analysis, is potential towards precisely characterizing gastric cancer (GC). Whether using one-slice 2D annotation or whole-volume 3D annotation remains a long-time debate, especially for heterogeneous GC. We comprehensively compared 2D and 3D radiomic features' representation and discrimination capacity regarding GC, via three tasks. Methods: Four-center 539 GC patients were retrospectively enrolled and divided into the training and validation cohorts. From 2D or 3D regions of interest (ROIs) annotated by radiologists, radiomic features were extracted respectively. Feature selection and model construction procedures were customed for each combination of two modalities (2D or 3D) and three tasks. Subsequently, six machine learning models (Model_2D^LNM, Model_3D^LNM; Model_2D^LVI, Model_3D^LVI; Model_2D^pT, Model_3D^pT) were derived and evaluated to reflect modalities' performances in characterizing GC. Furthermore, we performed an auxiliary experiment to assess modalities' performances when resampling spacing is different. Results: Regarding three tasks, the yielded areas under the curve (AUCs) were: Model_2D^LNM's 0.712 (95% confidence interval, 0.613-0.811), Model_3D^LNM's 0.680 (0.584-0.775); Model_2D^LVI's 0.677 (0.595-0.761), Model_3D^LVI's 0.615 (0.528-0.703); Model_2D^pT's 0.840 (0.779-0.901), Model_3D^pT's 0.813 (0.747-0.879). Moreover, the auxiliary experiment indicated that Models_2D are statistically more advantageous than Models3D with different resampling spacings. Conclusion: Models constructed with 2D radiomic features revealed comparable performances with those constructed with 3D features in characterizing GC. Significance: Our work indicated that time-saving 2D annotation would be the better choice in GC, and provided a related reference to further radiomics-based researches.
* Published in IEEE Journal of Biomedical and Health Informatics