 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Pedestrian Spatio-Temporal Information Fusion For Video Anomaly Detection
Nov 18, 2022
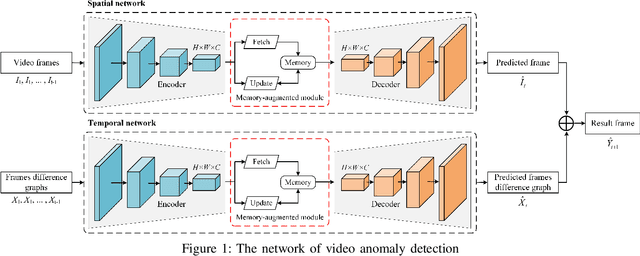
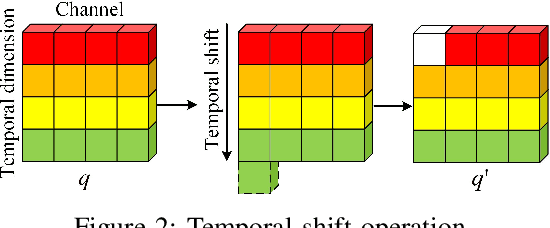
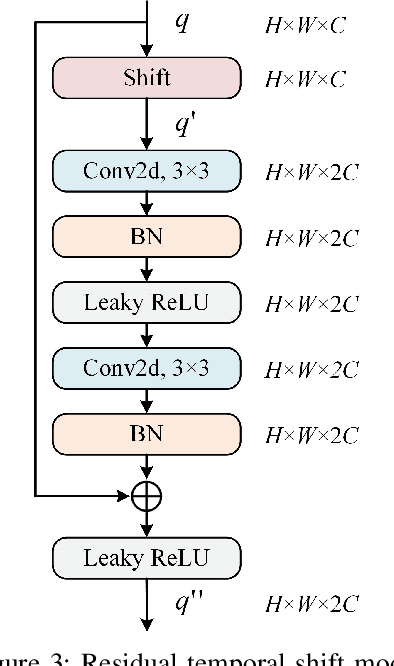
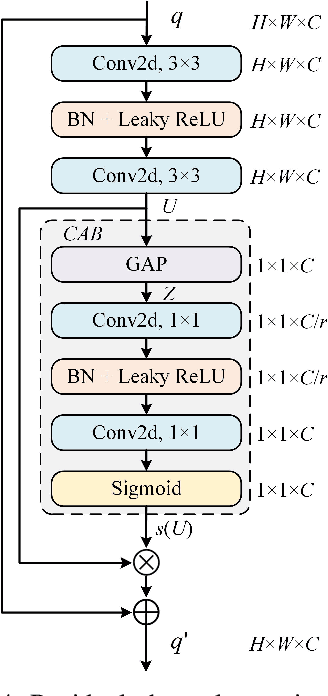
Aiming at the problem that the current video anomaly detection cannot fully use the temporal information and ignore the diversity of normal behavior, an anomaly detection method is proposed to integrate the spatiotemporal information of pedestrians. Based on the convolutional autoencoder, the input frame is compressed and restored through the encoder and decoder. Anomaly detection is realized according to the difference between the output frame and the true value. In order to strengthen the characteristic information connection between continuous video frames, the residual temporal shift module and the residual channel attention module are introduced to improve the modeling ability of the network on temporal information and channel information, respectively. Due to the excessive generalization of convolutional neural networks, in the memory enhancement modules, the hopping connections of each codec layer are added to limit autoencoders' ability to represent abnormal frames too vigorously and improve the anomaly detection accuracy of the network. In addition, the objective function is modified by a feature discretization loss, which effectively distinguishes different normal behavior patterns. The experimental results on the CUHK Avenue and ShanghaiTech datasets show that the proposed method is superior to the current mainstream video anomaly detection methods while meeting the real-time requirements.
CNeRV: Content-adaptive Neural Representation for Visual Data
Nov 18, 2022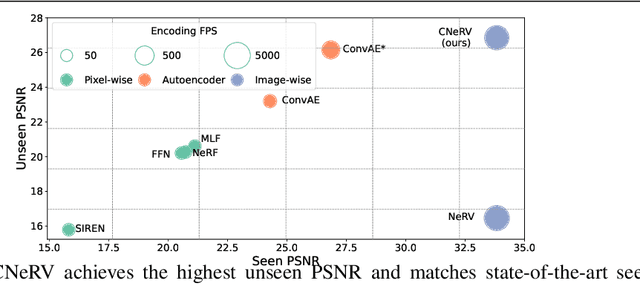
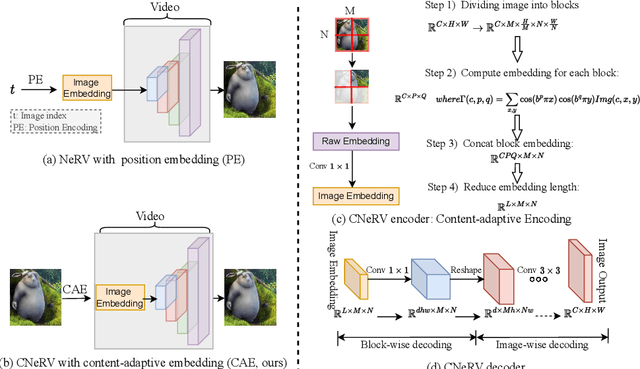

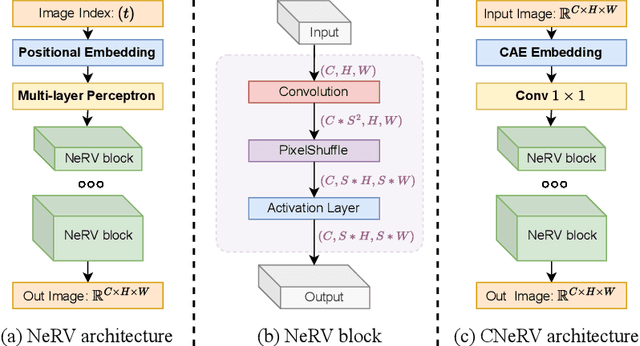
Compression and reconstruction of visual data have been widely studied in the computer vision community, even before the popularization of deep learning. More recently, some have used deep learning to improve or refine existing pipelines, while others have proposed end-to-end approaches, including autoencoders and implicit neural representations, such as SIREN and NeRV. In this work, we propose Neural Visual Representation with Content-adaptive Embedding (CNeRV), which combines the generalizability of autoencoders with the simplicity and compactness of implicit representation. We introduce a novel content-adaptive embedding that is unified, concise, and internally (within-video) generalizable, that compliments a powerful decoder with a single-layer encoder. We match the performance of NeRV, a state-of-the-art implicit neural representation, on the reconstruction task for frames seen during training while far surpassing for frames that are skipped during training (unseen images). To achieve similar reconstruction quality on unseen images, NeRV needs 120x more time to overfit per-frame due to its lack of internal generalization. With the same latent code length and similar model size, CNeRV outperforms autoencoders on reconstruction of both seen and unseen images. We also show promising results for visual data compression. More details can be found in the project pagehttps://haochen-rye.github.io/CNeRV/
Clustering based opcode graph generation for malware variant detection
Nov 18, 2022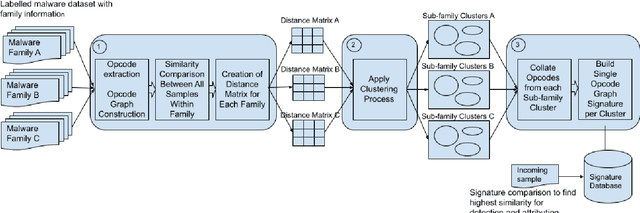
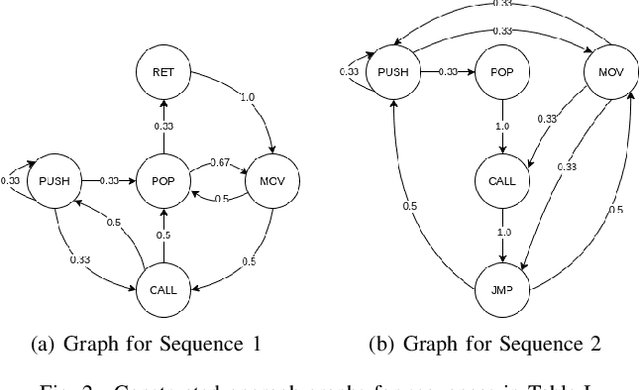
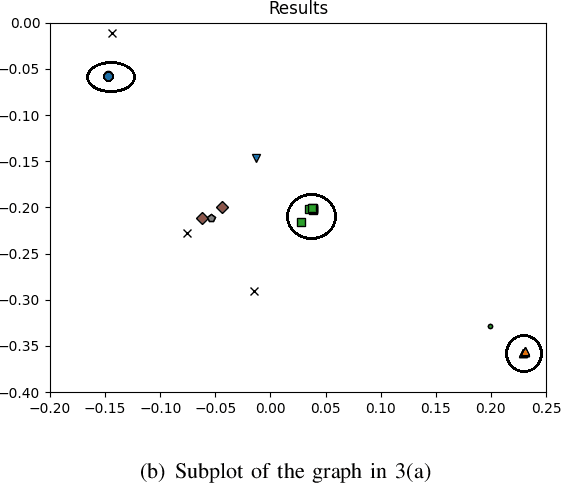
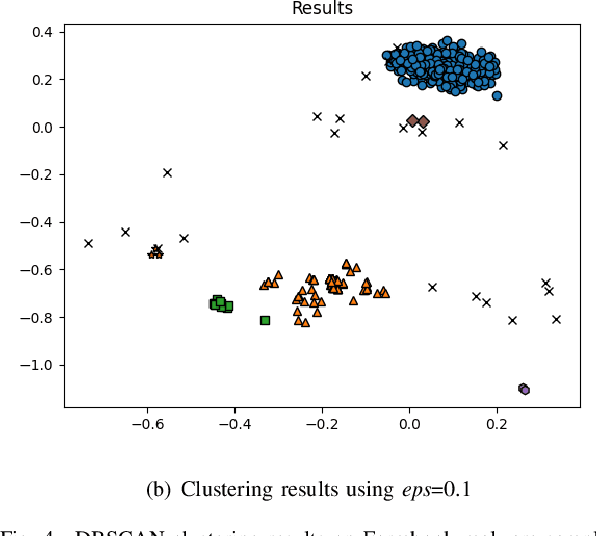
Malwares are the key means leveraged by threat actors in the cyber space for their attacks. There is a large array of commercial solutions in the market and significant scientific research to tackle the challenge of the detection and defense against malwares. At the same time, attackers also advance their capabilities in creating polymorphic and metamorphic malwares to make it increasingly challenging for existing solutions. To tackle this issue, we propose a methodology to perform malware detection and family attribution. The proposed methodology first performs the extraction of opcodes from malwares in each family and constructs their respective opcode graphs. We explore the use of clustering algorithms on the opcode graphs to detect clusters of malwares within the same malware family. Such clusters can be seen as belonging to different sub-family groups. Opcode graph signatures are built from each detected cluster. Hence, for each malware family, a group of signatures is generated to represent the family. These signatures are used to classify an unknown sample as benign or belonging to one the malware families. We evaluate our methodology by performing experiments on a dataset consisting of both benign files and malware samples belonging to a number of different malware families and comparing the results to existing approach.
* Keywords: malware detection and attribution, malware family, clustering, opcode graph, machine learning; https://ieeexplore.ieee.org/document/9647814
Uncertainty-aware Vision-based Metric Cross-view Geolocalization
Nov 22, 2022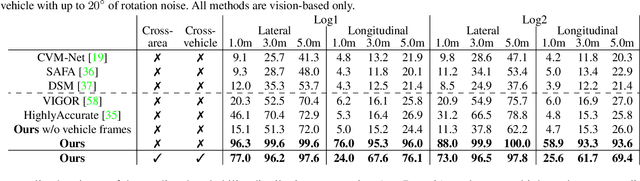
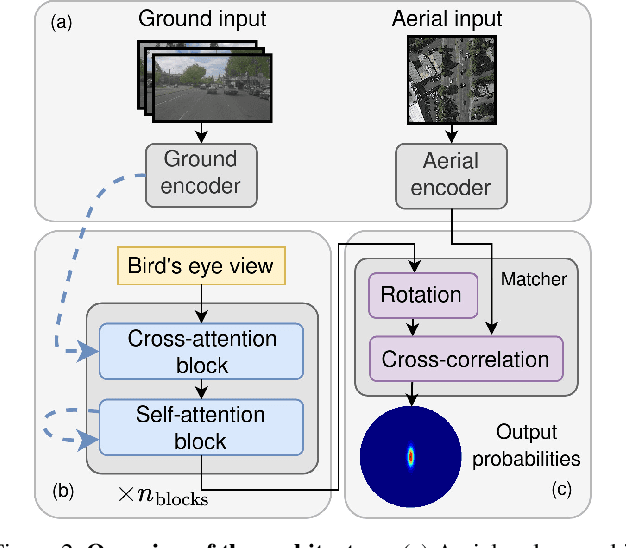
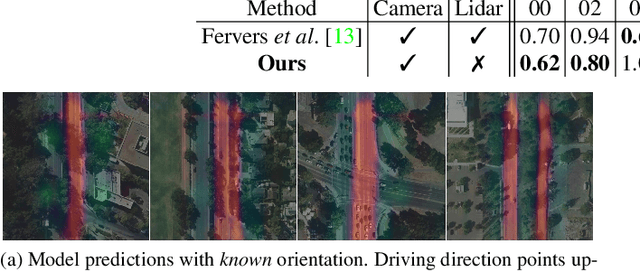
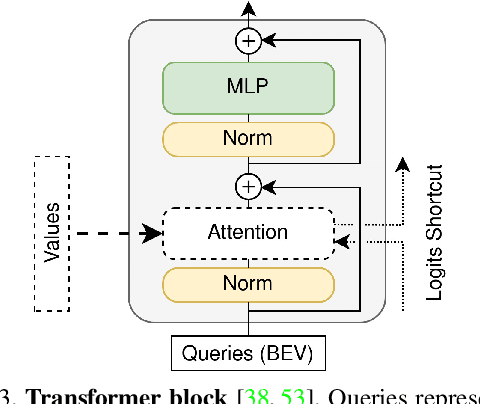
This paper proposes a novel method for vision-based metric cross-view geolocalization (CVGL) that matches the camera images captured from a ground-based vehicle with an aerial image to determine the vehicle's geo-pose. Since aerial images are globally available at low cost, they represent a potential compromise between two established paradigms of autonomous driving, i.e. using expensive high-definition prior maps or relying entirely on the sensor data captured at runtime. We present an end-to-end differentiable model that uses the ground and aerial images to predict a probability distribution over possible vehicle poses. We combine multiple vehicle datasets with aerial images from orthophoto providers on which we demonstrate the feasibility of our method. Since the ground truth poses are often inaccurate w.r.t. the aerial images, we implement a pseudo-label approach to produce more accurate ground truth poses and make them publicly available. While previous works require training data from the target region to achieve reasonable localization accuracy (i.e. same-area evaluation), our approach overcomes this limitation and outperforms previous results even in the strictly more challenging cross-area case. We improve the previous state-of-the-art by a large margin even without ground or aerial data from the test region, which highlights the model's potential for global-scale application. We further integrate the uncertainty-aware predictions in a tracking framework to determine the vehicle's trajectory over time resulting in a mean position error on KITTI-360 of 0.78m.
Predicting adverse outcomes following catheter ablation treatment for atrial fibrillation
Nov 22, 2022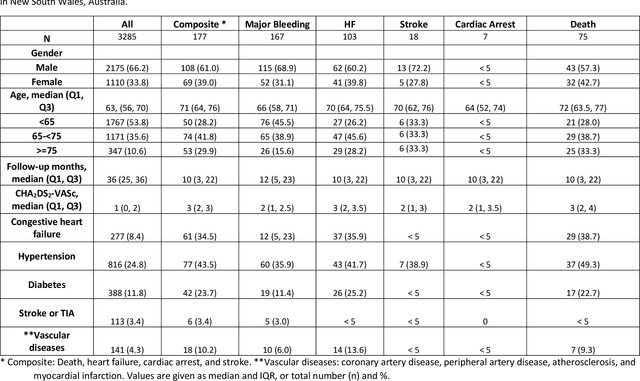
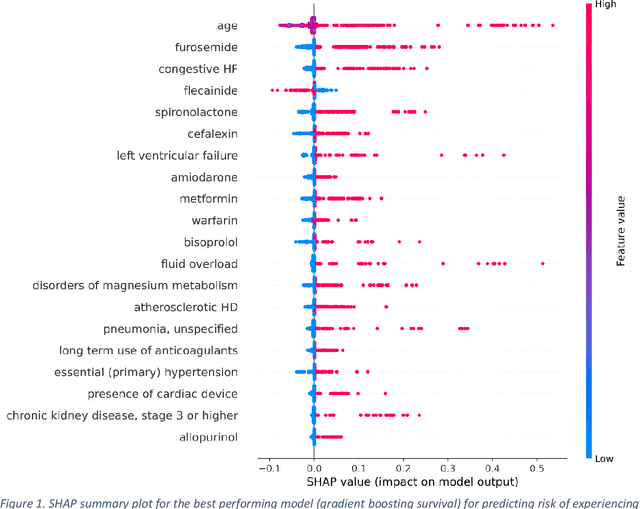
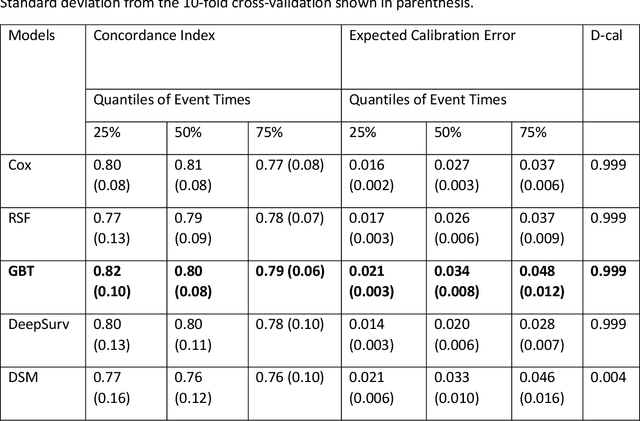
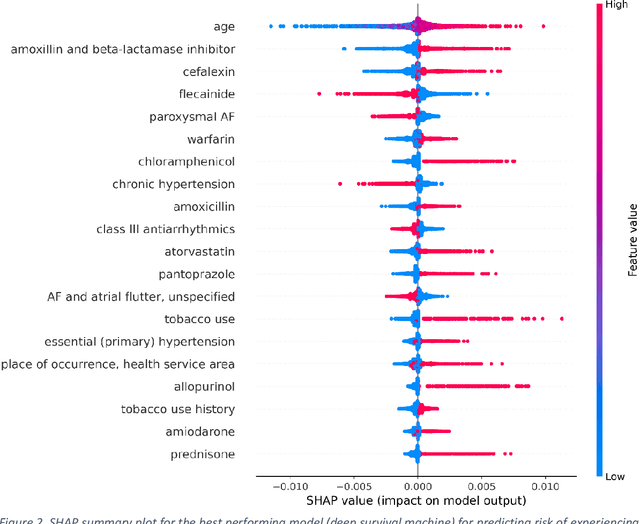
Objective: To develop prognostic survival models for predicting adverse outcomes after catheter ablation treatment for non-valvular atrial fibrillation (AF). Methods: We used a linked dataset including hospital administrative data, prescription medicine claims, emergency department presentations, and death registrations of patients in New South Wales, Australia. The cohort included patients who received catheter ablation for AF. Traditional and deep survival models were trained to predict major bleeding events and a composite of heart failure, stroke, cardiac arrest, and death. Results: Out of a total of 3285 patients in the cohort, 177 (5.3%) experienced the composite outcomeheart failure, stroke, cardiac arrest, deathand 167 (5.1%) experienced major bleeding events after catheter ablation treatment. Models predicting the composite outcome had high risk discrimination accuracy, with the best model having a concordance index > 0.79 at the evaluated time horizons. Models for predicting major bleeding events had poor risk discrimination performance, with all models having a concordance index < 0.66. The most impactful features for the models predicting higher risk were comorbidities indicative of poor health, older age, and therapies commonly used in sicker patients to treat heart failure and AF. Conclusions: Diagnosis and medication history did not contain sufficient information for precise risk prediction of experiencing major bleeding events. The models for predicting the composite outcome have the potential to enable clinicians to identify and manage high-risk patients following catheter ablation proactively. Future research is needed to validate the usefulness of these models in clinical practice.
GDPR Compliant Collection of Therapist-Patient-Dialogues
Nov 22, 2022According to the Global Burden of Disease list provided by the World Health Organization (WHO), mental disorders are among the most debilitating disorders.To improve the diagnosis and the therapy effectiveness in recent years, researchers have tried to identify individual biomarkers. Gathering neurobiological data however, is costly and time-consuming. Another potential source of information, which is already part of the clinical routine, are therapist-patient dialogues. While there are some pioneering works investigating the role of language as predictors for various therapeutic parameters, for example patient-therapist alliance, there are no large-scale studies. A major obstacle to conduct these studies is the availability of sizeable datasets, which are needed to train machine learning models. While these conversations are part of the daily routine of clinicians, gathering them is usually hindered by various ethical (purpose of data usage), legal (data privacy) and technical (data formatting) limitations. Some of these limitations are particular to the domain of therapy dialogues, like the increased difficulty in anonymisation, or the transcription of the recordings. In this paper, we elaborate on the challenges we faced in starting our collection of therapist-patient dialogues in a psychiatry clinic under the General Data Privacy Regulation of the European Union with the goal to use the data for Natural Language Processing (NLP) research. We give an overview of each step in our procedure and point out the potential pitfalls to motivate further research in this field.
AdaptDHM: Adaptive Distribution Hierarchical Model for Multi-Domain CTR Prediction
Nov 22, 2022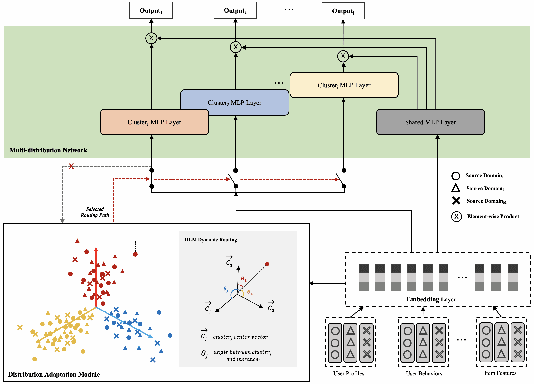
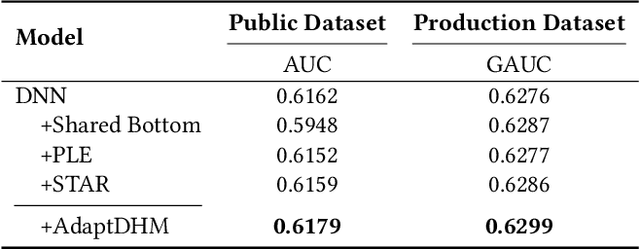
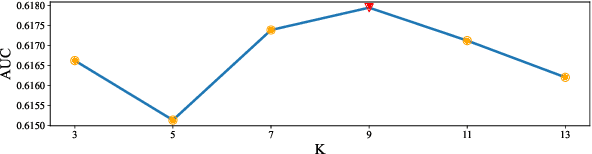
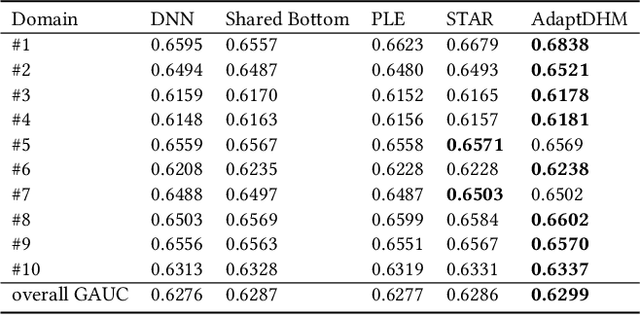
Large-scale commercial platforms usually involve numerous business domains for diverse business strategies and expect their recommendation systems to provide click-through rate (CTR) predictions for multiple domains simultaneously. Existing promising and widely-used multi-domain models discover domain relationships by explicitly constructing domain-specific networks, but the computation and memory boost significantly with the increase of domains. To reduce computational complexity, manually grouping domains with particular business strategies is common in industrial applications. However, this pre-defined data partitioning way heavily relies on prior knowledge, and it may neglect the underlying data distribution of each domain, hence limiting the model's representation capability. Regarding the above issues, we propose an elegant and flexible multi-distribution modeling paradigm, named Adaptive Distribution Hierarchical Model (AdaptDHM), which is an end-to-end optimization hierarchical structure consisting of a clustering process and classification process. Specifically, we design a distribution adaptation module with a customized dynamic routing mechanism. Instead of introducing prior knowledge for pre-defined data allocation, this routing algorithm adaptively provides a distribution coefficient for each sample to determine which cluster it belongs to. Each cluster corresponds to a particular distribution so that the model can sufficiently capture the commonalities and distinctions between these distinct clusters. Extensive experiments on both public and large-scale Alibaba industrial datasets verify the effectiveness and efficiency of AdaptDHM: Our model achieves impressive prediction accuracy and its time cost during the training stage is more than 50% less than that of other models.
A Unified Model for Tracking and Image-Video Detection Has More Power
Nov 20, 2022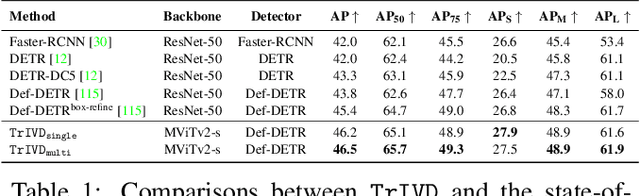
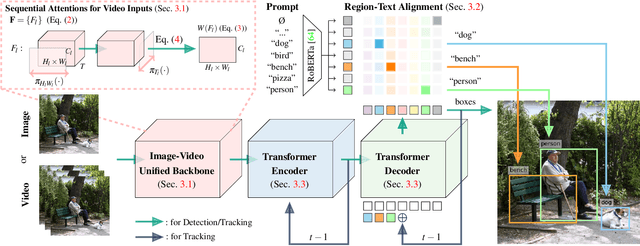


Objection detection (OD) has been one of the most fundamental tasks in computer vision. Recent developments in deep learning have pushed the performance of image OD to new heights by learning-based, data-driven approaches. On the other hand, video OD remains less explored, mostly due to much more expensive data annotation needs. At the same time, multi-object tracking (MOT) which requires reasoning about track identities and spatio-temporal trajectories, shares similar spirits with video OD. However, most MOT datasets are class-specific (e.g., person-annotated only), which constrains a model's flexibility to perform tracking on other objects. We propose TrIVD (Tracking and Image-Video Detection), the first framework that unifies image OD, video OD, and MOT within one end-to-end model. To handle the discrepancies and semantic overlaps across datasets, TrIVD formulates detection/tracking as grounding and reasons about object categories via visual-text alignments. The unified formulation enables cross-dataset, multi-task training, and thus equips TrIVD with the ability to leverage frame-level features, video-level spatio-temporal relations, as well as track identity associations. With such joint training, we can now extend the knowledge from OD data, that comes with much richer object category annotations, to MOT and achieve zero-shot tracking capability. Experiments demonstrate that TrIVD achieves state-of-the-art performances across all image/video OD and MOT tasks.
Real-time Object Detection for Streaming Perception
Mar 29, 2022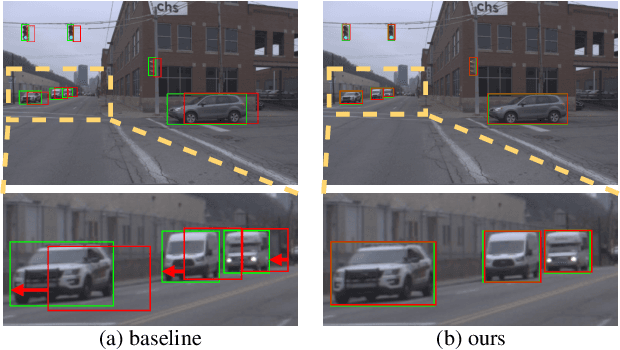

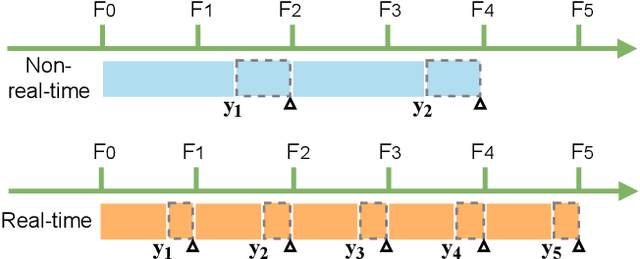
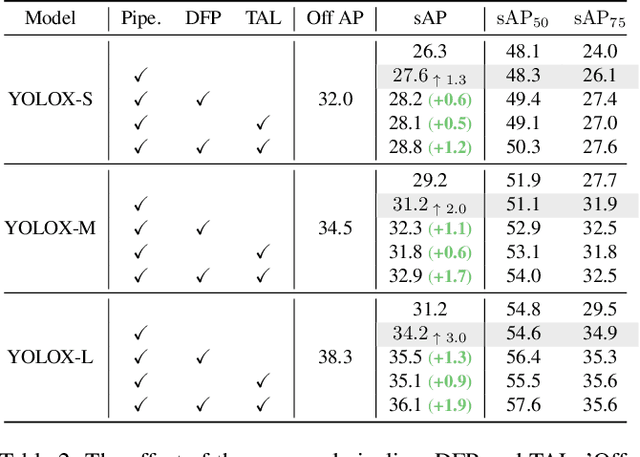
Autonomous driving requires the model to perceive the environment and (re)act within a low latency for safety. While past works ignore the inevitable changes in the environment after processing, streaming perception is proposed to jointly evaluate the latency and accuracy into a single metric for video online perception. In this paper, instead of searching trade-offs between accuracy and speed like previous works, we point out that endowing real-time models with the ability to predict the future is the key to dealing with this problem. We build a simple and effective framework for streaming perception. It equips a novel DualFlow Perception module (DFP), which includes dynamic and static flows to capture the moving trend and basic detection feature for streaming prediction. Further, we introduce a Trend-Aware Loss (TAL) combined with a trend factor to generate adaptive weights for objects with different moving speeds. Our simple method achieves competitive performance on Argoverse-HD dataset and improves the AP by 4.9% compared to the strong baseline, validating its effectiveness. Our code will be made available at https://github.com/yancie-yjr/StreamYOLO.
Fuzzy Cognitive Maps and Hidden Markov Models: Comparative Analysis of Efficiency within the Confines of the Time Series Classification Task
Apr 28, 2022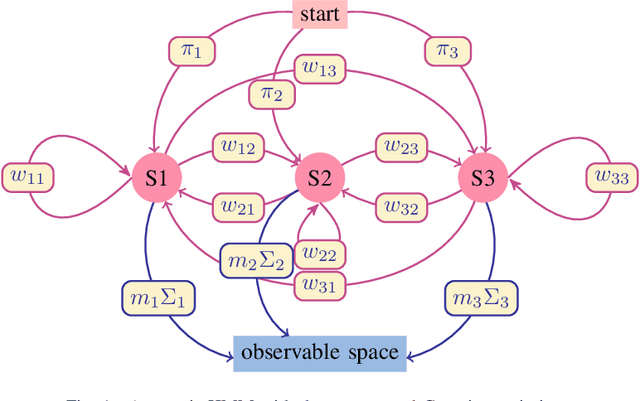
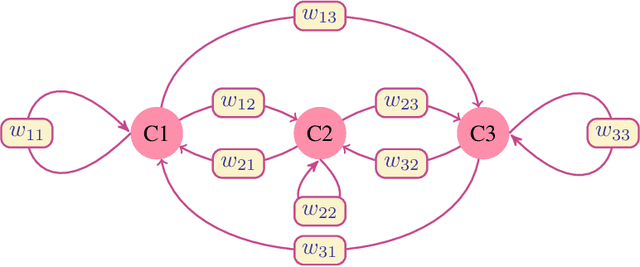
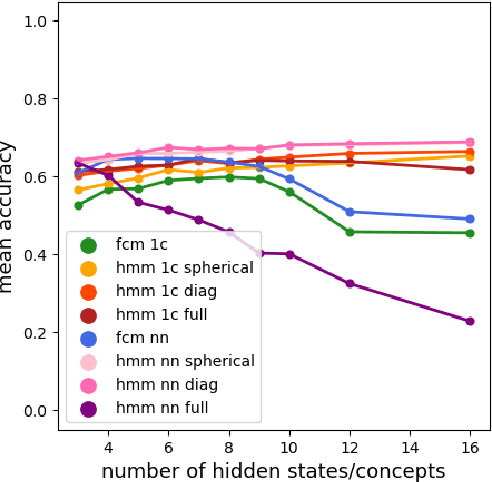
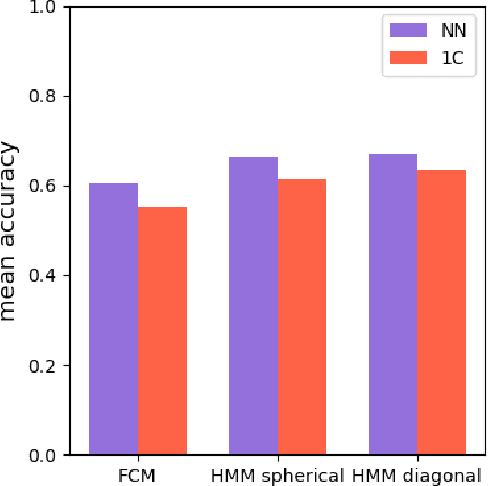
Time series classification is one of the very popular machine learning tasks. In this paper, we explore the application of Hidden Markov Model (HMM) for time series classification. We distinguish between two modes of HMM application. The first, in which a single model is built for each class. The second, in which one HMM is built for each time series. We then transfer both approaches for classifier construction to the domain of Fuzzy Cognitive Maps. The identified four models, HMM NN (HMM, one per series), HMM 1C (HMM, one per class), FCM NN, and FCM 1C are then studied in a series of experiments. We compare the performance of different models and investigate the impact of their hyperparameters on the time series classification accuracy. The empirical evaluation shows a clear advantage of the one-model-per-series approach. The results show that the choice between HMM and FCM should be dataset-dependent.