 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Denoising Time Cycle Modeling for Recommendation
Feb 05, 2024
Recently, modeling temporal patterns of user-item interactions have attracted much attention in recommender systems. We argue that existing methods ignore the variety of temporal patterns of user behaviors. We define the subset of user behaviors that are irrelevant to the target item as noises, which limits the performance of target-related time cycle modeling and affect the recommendation performance. In this paper, we propose Denoising Time Cycle Modeling (DiCycle), a novel approach to denoise user behaviors and select the subset of user behaviors that are highly related to the target item. DiCycle is able to explicitly model diverse time cycle patterns for recommendation. Extensive experiments are conducted on both public benchmarks and a real-world dataset, demonstrating the superior performance of DiCycle over the state-of-the-art recommendation methods.
Deep Reinforcement Learning: A Convex Optimization Approach
Feb 29, 2024In this paper, we consider reinforcement learning of nonlinear systems with continuous state and action spaces. We present an episodic learning algorithm, where we for each episode use convex optimization to find a two-layer neural network approximation of the optimal $Q$-function. The convex optimization approach guarantees that the weights calculated at each episode are optimal, with respect to the given sampled states and actions of the current episode. For stable nonlinear systems, we show that the algorithm converges and that the converging parameters of the trained neural network can be made arbitrarily close to the optimal neural network parameters. In particular, if the regularization parameter is $\rho$ and the time horizon is $T$, then the parameters of the trained neural network converge to $w$, where the distance between $w$ from the optimal parameters $w^\star$ is bounded by $\mathcal{O}(\rho T^{-1})$. That is, when the number of episodes goes to infinity, there exists a constant $C$ such that \[\|w-w^\star\| \le C\cdot\frac{\rho}{T}.\] In particular, our algorithm converges arbitrarily close to the optimal neural network parameters as the time horizon increases or as the regularization parameter decreases.
Test-Time Backdoor Attacks on Multimodal Large Language Models
Feb 13, 2024Backdoor attacks are commonly executed by contaminating training data, such that a trigger can activate predetermined harmful effects during the test phase. In this work, we present AnyDoor, a test-time backdoor attack against multimodal large language models (MLLMs), which involves injecting the backdoor into the textual modality using adversarial test images (sharing the same universal perturbation), without requiring access to or modification of the training data. AnyDoor employs similar techniques used in universal adversarial attacks, but distinguishes itself by its ability to decouple the timing of setup and activation of harmful effects. In our experiments, we validate the effectiveness of AnyDoor against popular MLLMs such as LLaVA-1.5, MiniGPT-4, InstructBLIP, and BLIP-2, as well as provide comprehensive ablation studies. Notably, because the backdoor is injected by a universal perturbation, AnyDoor can dynamically change its backdoor trigger prompts/harmful effects, exposing a new challenge for defending against backdoor attacks. Our project page is available at https://sail-sg.github.io/AnyDoor/.
On the Role of Information Structure in Reinforcement Learning for Partially-Observable Sequential Teams and Games
Mar 01, 2024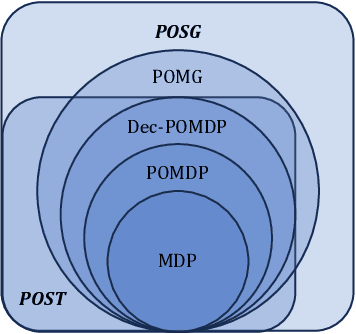
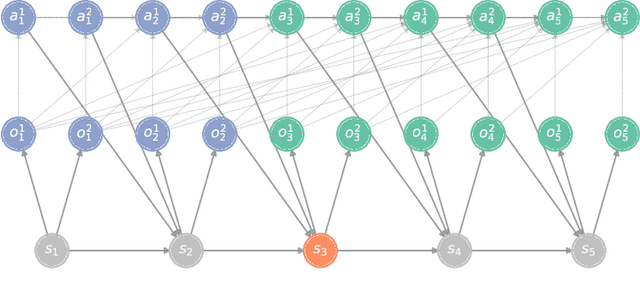
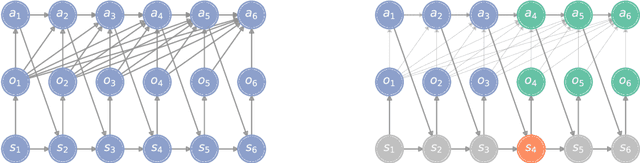
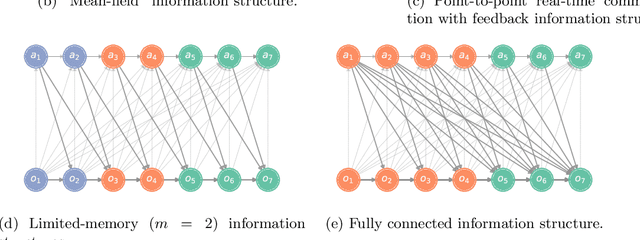
In a sequential decision-making problem, the information structure is the description of how events in the system occurring at different points in time affect each other. Classical models of reinforcement learning (e.g., MDPs, POMDPs, Dec-POMDPs, and POMGs) assume a very simple and highly regular information structure, while more general models like predictive state representations do not explicitly model the information structure. By contrast, real-world sequential decision-making problems typically involve a complex and time-varying interdependence of system variables, requiring a rich and flexible representation of information structure. In this paper, we argue for the perspective that explicit representation of information structures is an important component of analyzing and solving reinforcement learning problems. We propose novel reinforcement learning models with an explicit representation of information structure, capturing classical models as special cases. We show that this leads to a richer analysis of sequential decision-making problems and enables more tailored algorithm design. In particular, we characterize the "complexity" of the observable dynamics of any sequential decision-making problem through a graph-theoretic analysis of the DAG representation of its information structure. The central quantity in this analysis is the minimal set of variables that $d$-separates the past observations from future observations. Furthermore, through constructing a generalization of predictive state representations, we propose tailored reinforcement learning algorithms and prove that the sample complexity is in part determined by the information structure. This recovers known tractability results and gives a novel perspective on reinforcement learning in general sequential decision-making problems, providing a systematic way of identifying new tractable classes of problems.
Teaching MLP More Graph Information: A Three-stage Multitask Knowledge Distillation Framework
Mar 02, 2024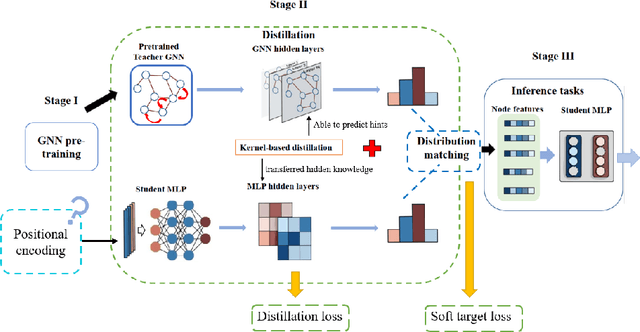
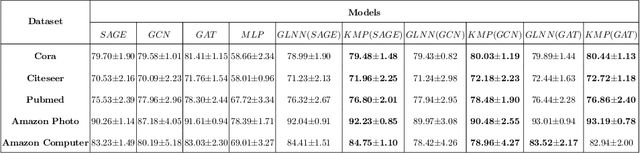
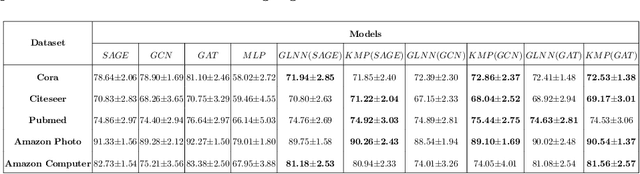
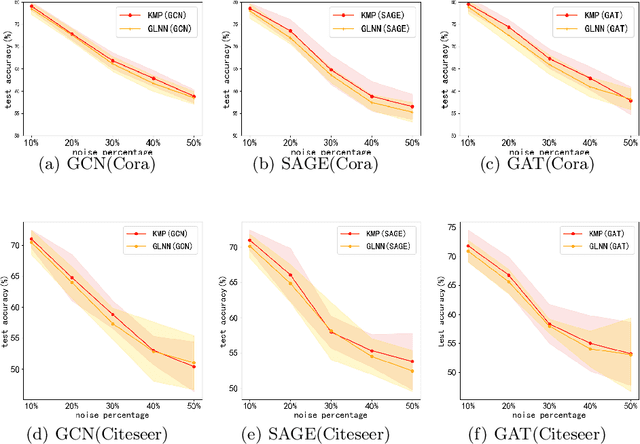
We study the challenging problem for inference tasks on large-scale graph datasets of Graph Neural Networks: huge time and memory consumption, and try to overcome it by reducing reliance on graph structure. Even though distilling graph knowledge to student MLP is an excellent idea, it faces two major problems of positional information loss and low generalization. To solve the problems, we propose a new three-stage multitask distillation framework. In detail, we use Positional Encoding to capture positional information. Also, we introduce Neural Heat Kernels responsible for graph data processing in GNN and utilize hidden layer outputs matching for better performance of student MLP's hidden layers. To the best of our knowledge, it is the first work to include hidden layer distillation for student MLP on graphs and to combine graph Positional Encoding with MLP. We test its performance and robustness with several settings and draw the conclusion that our work can outperform well with good stability.
A Hybrid Model for Traffic Incident Detection based on Generative Adversarial Networks and Transformer Model
Mar 02, 2024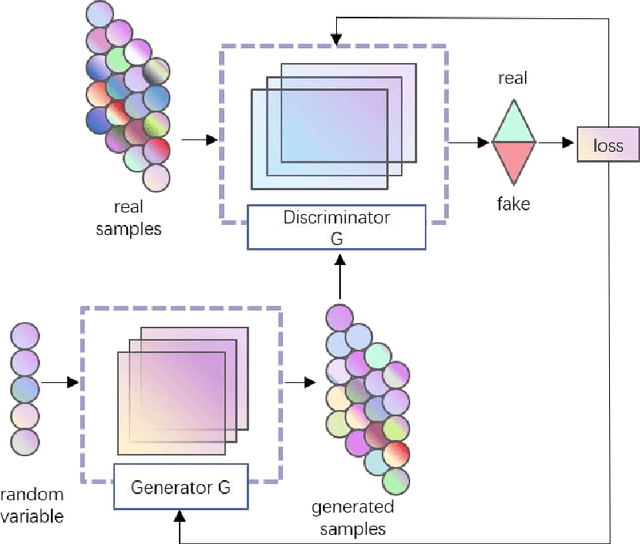

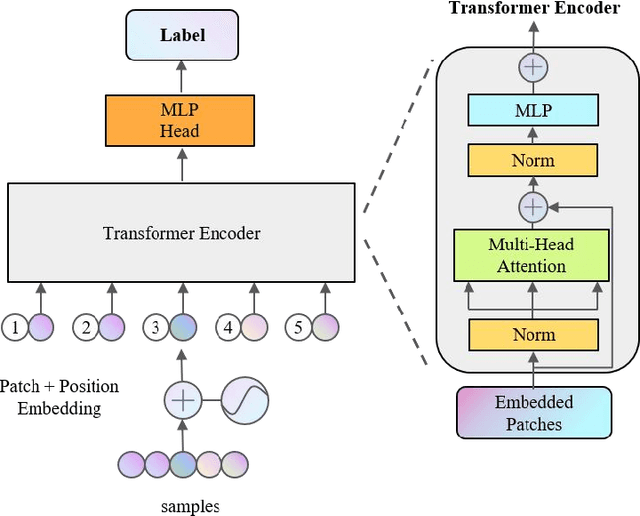
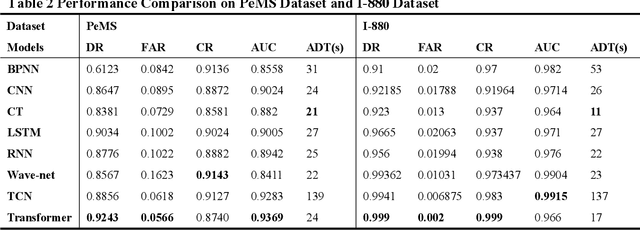
In addition to enhancing traffic safety and facilitating prompt emergency response, traffic incident detection plays an indispensable role in intelligent transportation systems by providing real-time traffic status information. This enables the realization of intelligent traffic control and management. Previous research has identified that apart from employing advanced algorithmic models, the effectiveness of detection is also significantly influenced by challenges related to acquiring large datasets and addressing dataset imbalances. A hybrid model combining transformer and generative adversarial networks (GANs) is proposed to address these challenges. Experiments are conducted on four real datasets to validate the superiority of the transformer in traffic incident detection. Additionally, GANs are utilized to expand the dataset and achieve a balanced ratio of 1:4, 2:3, and 1:1. The proposed model is evaluated against the baseline model. The results demonstrate that the proposed model enhances the dataset size, balances the dataset, and improves the performance of traffic incident detection in various aspects.
Transformers for Supervised Online Continual Learning
Mar 03, 2024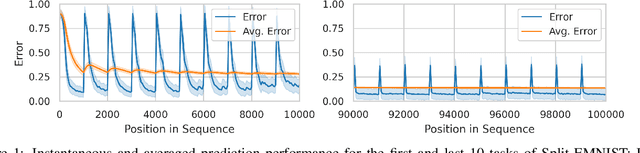
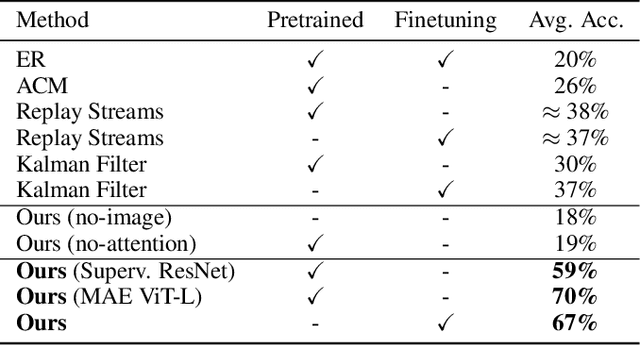
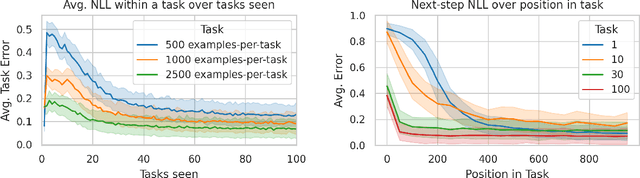
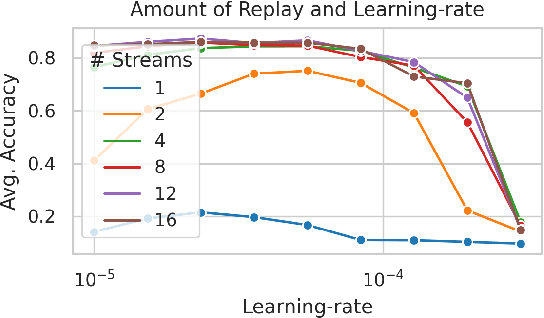
Transformers have become the dominant architecture for sequence modeling tasks such as natural language processing or audio processing, and they are now even considered for tasks that are not naturally sequential such as image classification. Their ability to attend to and to process a set of tokens as context enables them to develop in-context few-shot learning abilities. However, their potential for online continual learning remains relatively unexplored. In online continual learning, a model must adapt to a non-stationary stream of data, minimizing the cumulative nextstep prediction loss. We focus on the supervised online continual learning setting, where we learn a predictor $x_t \rightarrow y_t$ for a sequence of examples $(x_t, y_t)$. Inspired by the in-context learning capabilities of transformers and their connection to meta-learning, we propose a method that leverages these strengths for online continual learning. Our approach explicitly conditions a transformer on recent observations, while at the same time online training it with stochastic gradient descent, following the procedure introduced with Transformer-XL. We incorporate replay to maintain the benefits of multi-epoch training while adhering to the sequential protocol. We hypothesize that this combination enables fast adaptation through in-context learning and sustained longterm improvement via parametric learning. Our method demonstrates significant improvements over previous state-of-the-art results on CLOC, a challenging large-scale real-world benchmark for image geo-localization.
Bellman Conformal Inference: Calibrating Prediction Intervals For Time Series
Feb 09, 2024We introduce Bellman Conformal Inference (BCI), a framework that wraps around any time series forecasting models and provides approximately calibrated prediction intervals. Unlike existing methods, BCI is able to leverage multi-step ahead forecasts and explicitly optimize the average interval lengths by solving a one-dimensional stochastic control problem (SCP) at each time step. In particular, we use the dynamic programming algorithm to find the optimal policy for the SCP. We prove that BCI achieves long-term coverage under arbitrary distribution shifts and temporal dependence, even with poor multi-step ahead forecasts. We find empirically that BCI avoids uninformative intervals that have infinite lengths and generates substantially shorter prediction intervals in multiple applications when compared with existing methods.
VastGaussian: Vast 3D Gaussians for Large Scene Reconstruction
Feb 27, 2024Existing NeRF-based methods for large scene reconstruction often have limitations in visual quality and rendering speed. While the recent 3D Gaussian Splatting works well on small-scale and object-centric scenes, scaling it up to large scenes poses challenges due to limited video memory, long optimization time, and noticeable appearance variations. To address these challenges, we present VastGaussian, the first method for high-quality reconstruction and real-time rendering on large scenes based on 3D Gaussian Splatting. We propose a progressive partitioning strategy to divide a large scene into multiple cells, where the training cameras and point cloud are properly distributed with an airspace-aware visibility criterion. These cells are merged into a complete scene after parallel optimization. We also introduce decoupled appearance modeling into the optimization process to reduce appearance variations in the rendered images. Our approach outperforms existing NeRF-based methods and achieves state-of-the-art results on multiple large scene datasets, enabling fast optimization and high-fidelity real-time rendering.
Mesoscale Traffic Forecasting for Real-Time Bottleneck and Shockwave Prediction
Feb 08, 2024Accurate real-time traffic state forecasting plays a pivotal role in traffic control research. In particular, the CIRCLES consortium project necessitates predictive techniques to mitigate the impact of data source delays. After the success of the MegaVanderTest experiment, this paper aims at overcoming the current system limitations and develop a more suited approach to improve the real-time traffic state estimation for the next iterations of the experiment. In this paper, we introduce the SA-LSTM, a deep forecasting method integrating Self-Attention (SA) on the spatial dimension with Long Short-Term Memory (LSTM) yielding state-of-the-art results in real-time mesoscale traffic forecasting. We extend this approach to multi-step forecasting with the n-step SA-LSTM, which outperforms traditional multi-step forecasting methods in the trade-off between short-term and long-term predictions, all while operating in real-time.