 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CL2R: Compatible Lifelong Learning Representations
Nov 16, 2022
In this paper, we propose a method to partially mimic natural intelligence for the problem of lifelong learning representations that are compatible. We take the perspective of a learning agent that is interested in recognizing object instances in an open dynamic universe in a way in which any update to its internal feature representation does not render the features in the gallery unusable for visual search. We refer to this learning problem as Compatible Lifelong Learning Representations (CL2R) as it considers compatible representation learning within the lifelong learning paradigm. We identify stationarity as the property that the feature representation is required to hold to achieve compatibility and propose a novel training procedure that encourages local and global stationarity on the learned representation. Due to stationarity, the statistical properties of the learned features do not change over time, making them interoperable with previously learned features. Extensive experiments on standard benchmark datasets show that our CL2R training procedure outperforms alternative baselines and state-of-the-art methods. We also provide novel metrics to specifically evaluate compatible representation learning under catastrophic forgetting in various sequential learning tasks. Code at https://github.com/NiccoBiondi/CompatibleLifelongRepresentation.
Semi-Supervised and Self-Supervised Collaborative Learning for Prostate 3D MR Image Segmentation
Nov 16, 2022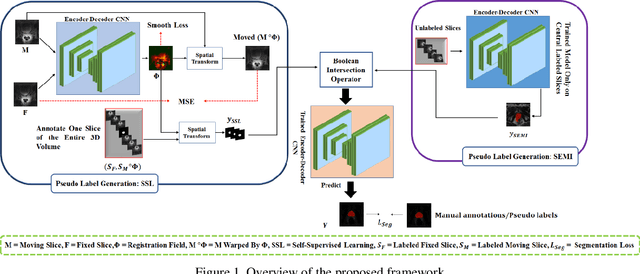
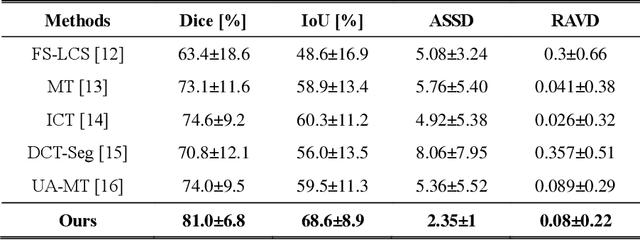
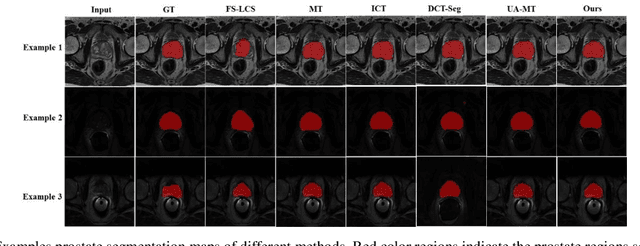
Volumetric magnetic resonance (MR) image segmentation plays an important role in many clinical applications. Deep learning (DL) has recently achieved state-of-the-art or even human-level performance on various image segmentation tasks. Nevertheless, manually annotating volumetric MR images for DL model training is labor-exhaustive and time-consuming. In this work, we aim to train a semi-supervised and self-supervised collaborative learning framework for prostate 3D MR image segmentation while using extremely sparse annotations, for which the ground truth annotations are provided for just the central slice of each volumetric MR image. Specifically, semi-supervised learning and self-supervised learning methods are used to generate two independent sets of pseudo labels. These pseudo labels are then fused by Boolean operation to extract a more confident pseudo label set. The images with either manual or network self-generated labels are then employed to train a segmentation model for target volume extraction. Experimental results on a publicly available prostate MR image dataset demonstrate that, while requiring significantly less annotation effort, our framework generates very encouraging segmentation results. The proposed framework is very useful in clinical applications when training data with dense annotations are difficult to obtain.
Egocentric Hand-object Interaction Detection
Nov 16, 2022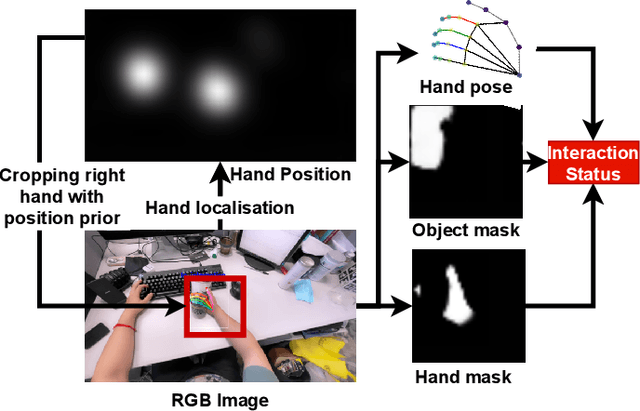


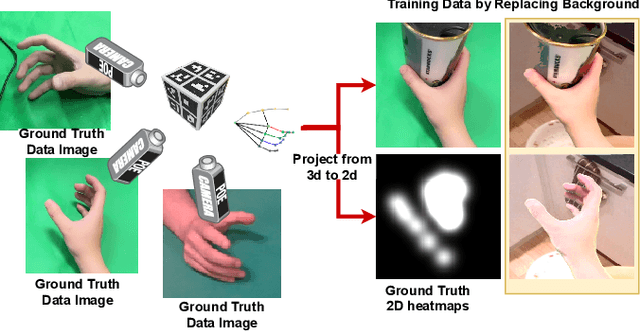
In this paper, we propose a method to jointly determine the status of hand-object interaction. This is crucial for egocentric human activity understanding and interaction. From a computer vision perspective, we believe that determining whether a hand is interacting with an object depends on whether there is an interactive hand pose and whether the hand is touching the object. Thus, we extract the hand pose, hand-object masks to jointly determine the interaction status. In order to solve the problem of hand pose estimation due to in-hand object occlusion, we use a multi-cam system to capture hand pose data from multiple perspectives. We evaluate and compare our method with the most recent work from Shan et al. \cite{Shan20} on selected images from EPIC-KITCHENS \cite{damen2018scaling} dataset and achieve $89\%$ accuracy on HOI (hand-object interaction) detection which is comparative to Shan's ($92\%$). However, for real-time performance, our method can run over $\textbf{30}$ FPS which is much more efficient than Shan's ($\textbf{1}\sim\textbf{2}$ FPS). A demo can be found from https://www.youtube.com/watch?v=XVj3zBuynmQ
Parameter-Efficient Tuning on Layer Normalization for Pre-trained Language Models
Nov 16, 2022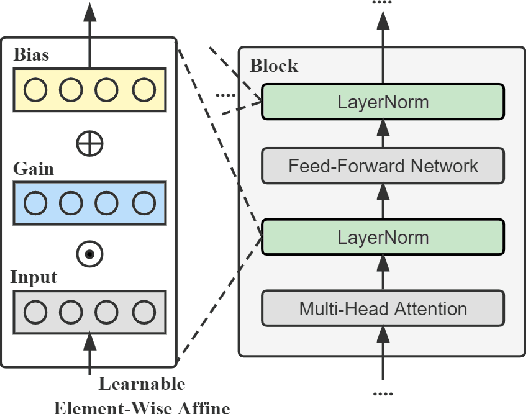
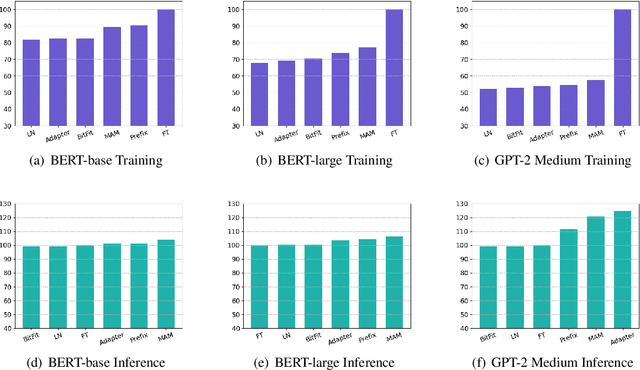
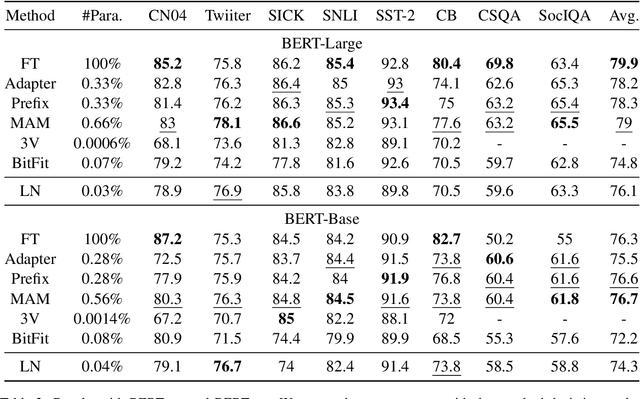
Conventional fine-tuning encounters increasing difficulties given the size of current Pre-trained Language Models, which makes parameter-efficient tuning become the focal point of frontier research. Previous methods in this field add tunable adapters into MHA or/and FFN of Transformer blocks to enable PLMs achieve transferability. However, as an important part of Transformer architecture, the power of layer normalization for parameter-efficent tuning is ignored. In this paper, we first propose LN-tuning, by tuning the gain and bias term of Layer Normalization module with only 0.03\% parameters, which is of high time-efficency and significantly superior to baselines which are less than 0.1\% tunable parameters. Further, we study the unified framework of combining LN-tuning with previous ones and we find that: (1) the unified framework of combining prefix-tuning, the adapter-based method working on MHA, and LN-tuning achieves SOTA performance. (2) unified framework which tunes MHA and LayerNorm simultaneously can get performance improvement but those which tune FFN and LayerNorm simultaneous will cause performance decrease. Ablation study validates LN-tuning is of no abundant parameters and gives a further understanding of it.
TTS-GAN: A Transformer-based Time-Series Generative Adversarial Network
Feb 06, 2022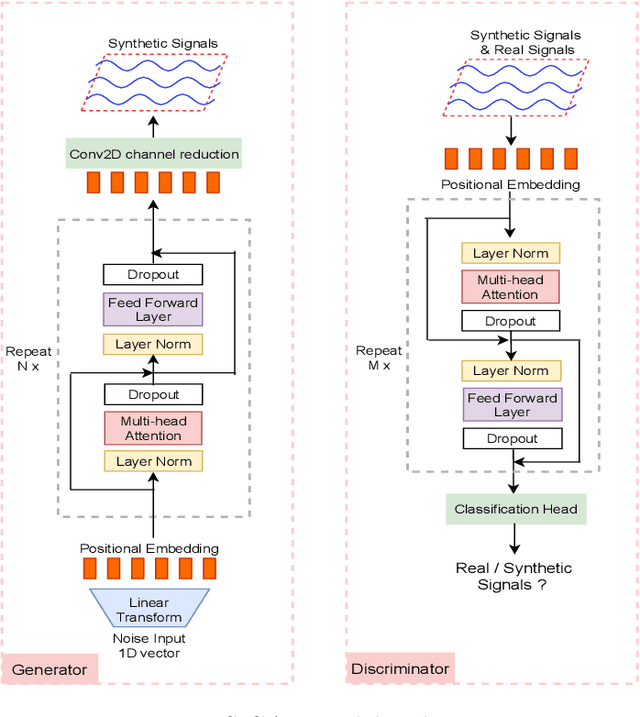
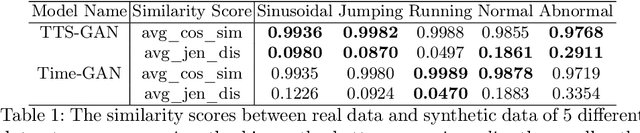
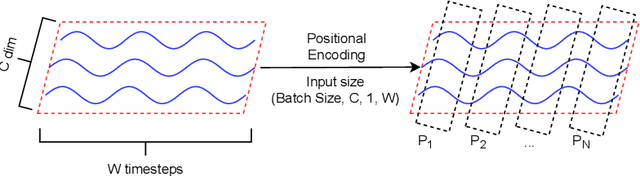
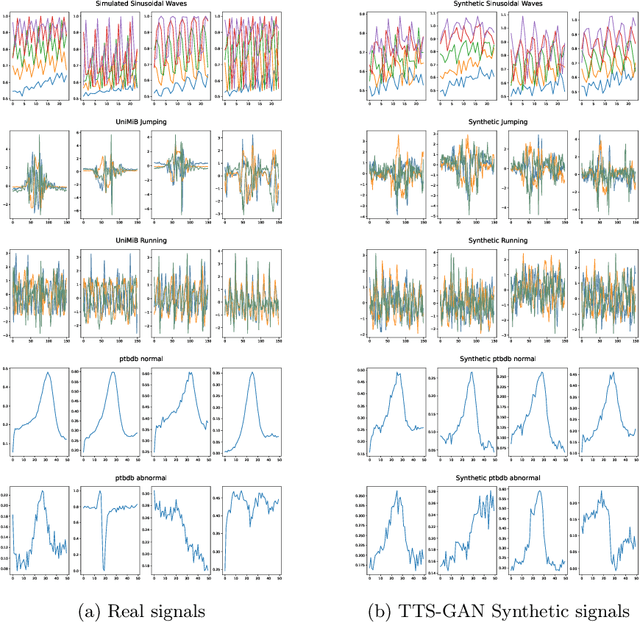
Signal measurements appearing in the form of time series are one of the most common types of data used in medical machine learning applications. However, such datasets are often small, making the training of deep neural network architectures ineffective. For time-series, the suite of data augmentation tricks we can use to expand the size of the dataset is limited by the need to maintain the basic properties of the signal. Data generated by a Generative Adversarial Network (GAN) can be utilized as another data augmentation tool. RNN-based GANs suffer from the fact that they cannot effectively model long sequences of data points with irregular temporal relations. To tackle these problems, we introduce TTS-GAN, a transformer-based GAN which can successfully generate realistic synthetic time-series data sequences of arbitrary length, similar to the real ones. Both the generator and discriminator networks of the GAN model are built using a pure transformer encoder architecture. We use visualizations and dimensionality reduction techniques to demonstrate the similarity of real and generated time-series data. We also compare the quality of our generated data with the best existing alternative, which is an RNN-based time-series GAN.
DynImp: Dynamic Imputation for Wearable Sensing Data Through Sensory and Temporal Relatedness
Sep 26, 2022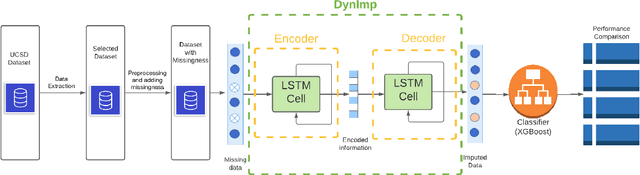

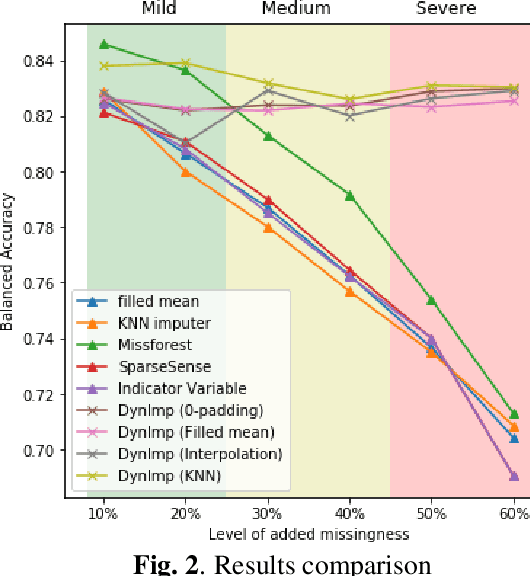
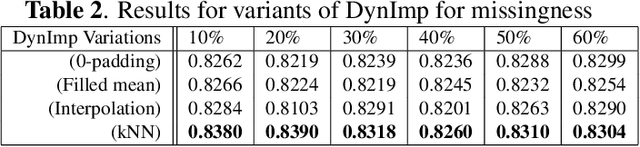
In wearable sensing applications, data is inevitable to be irregularly sampled or partially missing, which pose challenges for any downstream application. An unique aspect of wearable data is that it is time-series data and each channel can be correlated to another one, such as x, y, z axis of accelerometer. We argue that traditional methods have rarely made use of both times-series dynamics of the data as well as the relatedness of the features from different sensors. We propose a model, termed as DynImp, to handle different time point's missingness with nearest neighbors along feature axis and then feeding the data into a LSTM-based denoising autoencoder which can reconstruct missingness along the time axis. We experiment the model on the extreme missingness scenario ($>50\%$ missing rate) which has not been widely tested in wearable data. Our experiments on activity recognition show that the method can exploit the multi-modality features from related sensors and also learn from history time-series dynamics to reconstruct the data under extreme missingness.
Rapid and robust endoscopic content area estimation: A lean GPU-based pipeline and curated benchmark dataset
Oct 26, 2022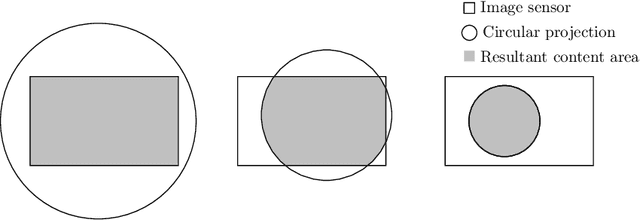
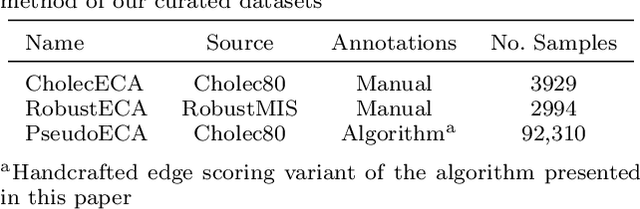
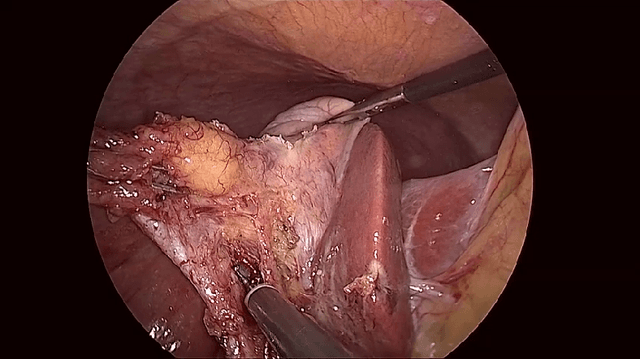
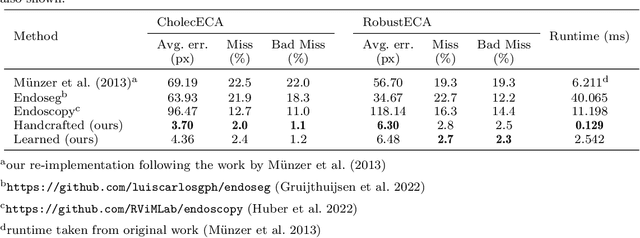
Endoscopic content area refers to the informative area enclosed by the dark, non-informative, border regions present in most endoscopic footage. The estimation of the content area is a common task in endoscopic image processing and computer vision pipelines. Despite the apparent simplicity of the problem, several factors make reliable real-time estimation surprisingly challenging. The lack of rigorous investigation into the topic combined with the lack of a common benchmark dataset for this task has been a long-lasting issue in the field. In this paper, we propose two variants of a lean GPU-based computational pipeline combining edge detection and circle fitting. The two variants differ by relying on handcrafted features, and learned features respectively to extract content area edge point candidates. We also present a first-of-its-kind dataset of manually annotated and pseudo-labelled content areas across a range of surgical indications. To encourage further developments, the curated dataset, and an implementation of both algorithms, has been made public (https://doi.org/10.7303/syn32148000, https://github.com/charliebudd/torch-content-area). We compare our proposed algorithm with a state-of-the-art U-Net-based approach and demonstrate significant improvement in terms of both accuracy (Hausdorff distance: 6.3 px versus 118.1 px) and computational time (Average runtime per frame: 0.13 ms versus 11.2 ms).
Continuum Robot State Estimation Using Gaussian Process Regression on $SE(3)$
Oct 26, 2022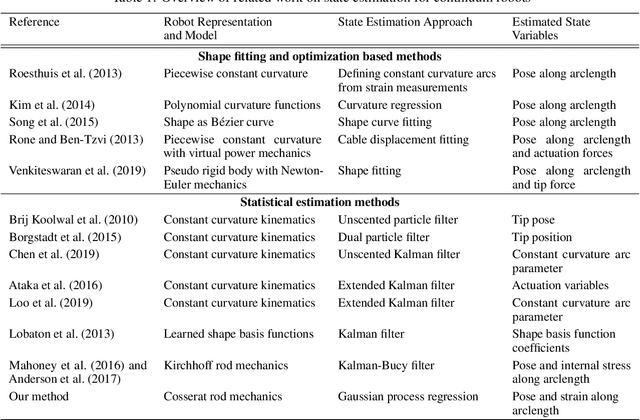
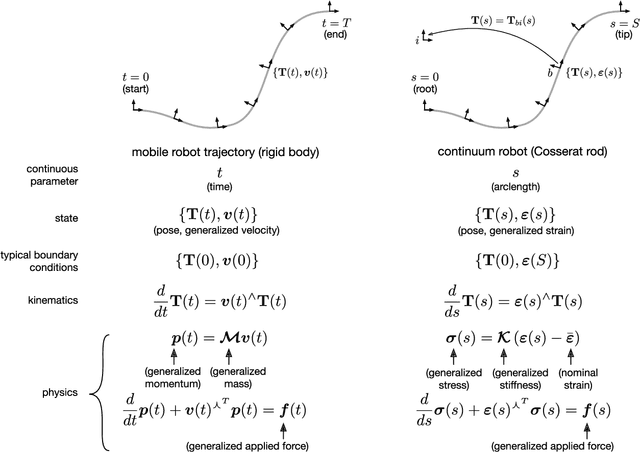
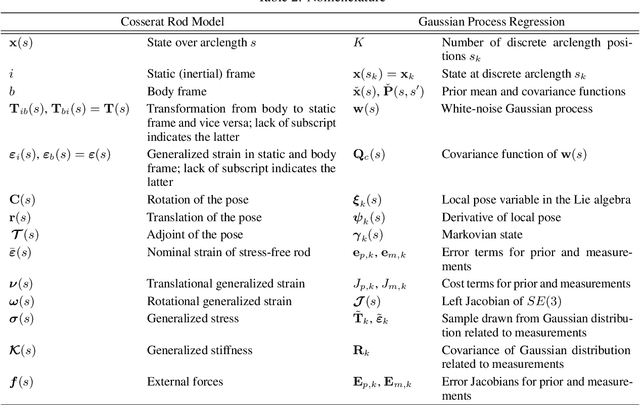
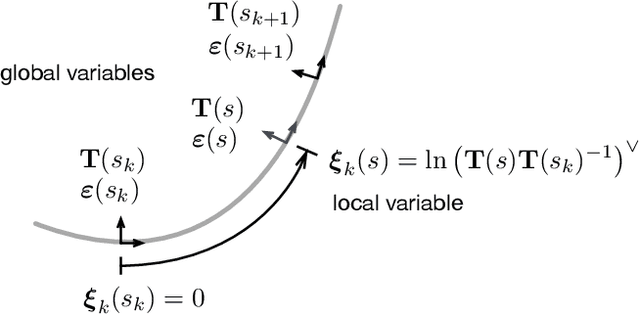
Continuum robots have the potential to enable new applications in medicine, inspection, and countless other areas due to their unique shape, compliance, and size. Excellent progess has been made in the mechanical design and dynamic modelling of continuum robots, to the point that there are some canonical designs, although new concepts continue to be explored. In this paper, we turn to the problem of state estimation for continuum robots that can been modelled with the common Cosserat rod model. Sensing for continuum robots might comprise external camera observations, embedded tracking coils or strain gauges. We repurpose a Gaussian process (GP) regression approach to state estimation, initially developed for continuous-time trajectory estimation in $SE(3)$. In our case, the continuous variable is not time but arclength and we show how to estimate the continuous shape (and strain) of the robot (along with associated uncertainties) given discrete, noisy measurements of both pose and strain along the length. We demonstrate our approach quantitatively through simulations as well as through experiments. Our evaluations show that accurate and continuous estimates of a continuum robot's shape can be achieved, resulting in average end-effector errors between the estimated and ground truth shape as low as 3.5mm and 0.016$^\circ$ in simulation or 3.3mm and 0.035$^\circ$ for unloaded configurations and 6.2mm and 0.041$^\circ$ for loaded ones during experiments, when using discrete pose measurements.
LinkFormer: Automatic Contextualised Link Recovery of Software Artifacts in both Project-based and Transfer Learning Settings
Nov 01, 2022
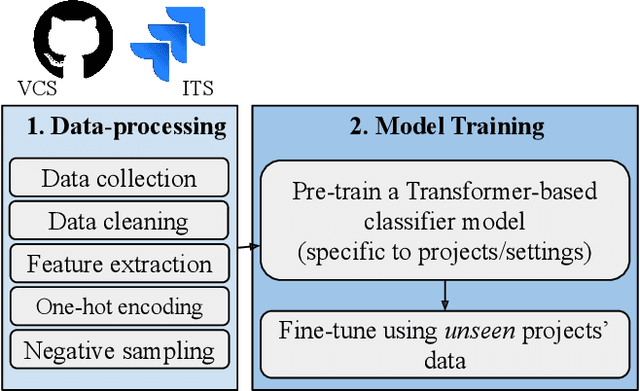
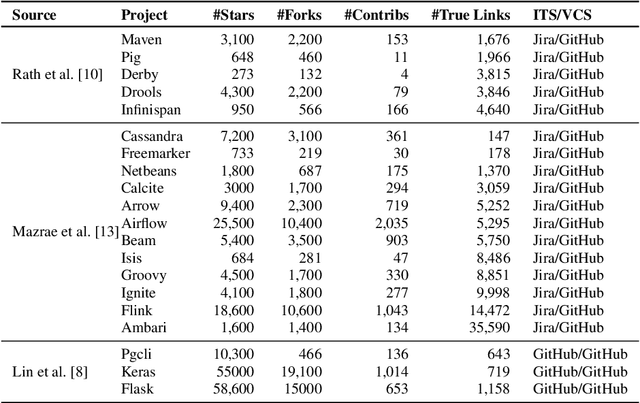
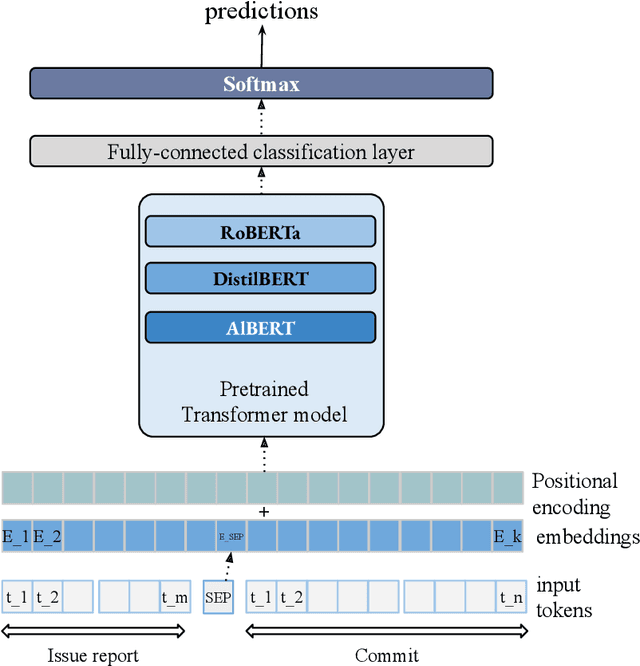
Software artifacts often interact with each other throughout the software development cycle. Associating related artifacts is a common practice for effective documentation and maintenance of software projects. Conventionally, to register the link between an issue report and its associated commit, developers manually include the issue identifier in the message of the relevant commit. Research has shown that developers tend to forget to connect said artifacts manually, resulting in a loss of links. Hence, several link recovery techniques were proposed to discover and revive such links automatically. However, the literature mainly focuses on improving the prediction accuracy on a randomly-split test set, while neglecting other important aspects of this problem, including the effect of time and generalizability of the predictive models. In this paper, we propose LinkFormer to address this problem from three aspects; 1) Accuracy: To better utilize contextual information for prediction, we employ the Transformer architecture and fine-tune multiple pre-trained models on textual and metadata of issues and commits. 2) Data leakage: To empirically assess the impact of time through the splitting policy, we train and test our proposed model along with several existing approaches on both randomly- and temporally split data. 3) Generalizability: To provide a generic model that can perform well across different projects, we further fine-tune LinkFormer in two transfer learning settings. We empirically show that researchers should preserve the temporal flow of data when training learning-based models to resemble the real-world setting. In addition, LinkFormer significantly outperforms the state-of-the-art by large margins. LinkFormer is also capable of extending the knowledge it learned to unseen projects with little to no historical data.
Cross-domain Transfer of defect features in technical domains based on partial target data
Nov 24, 2022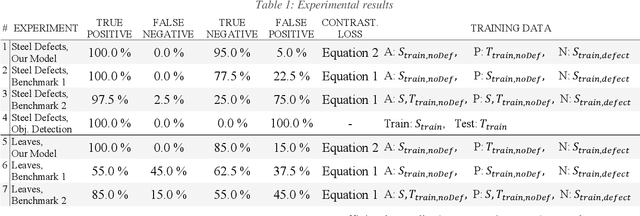


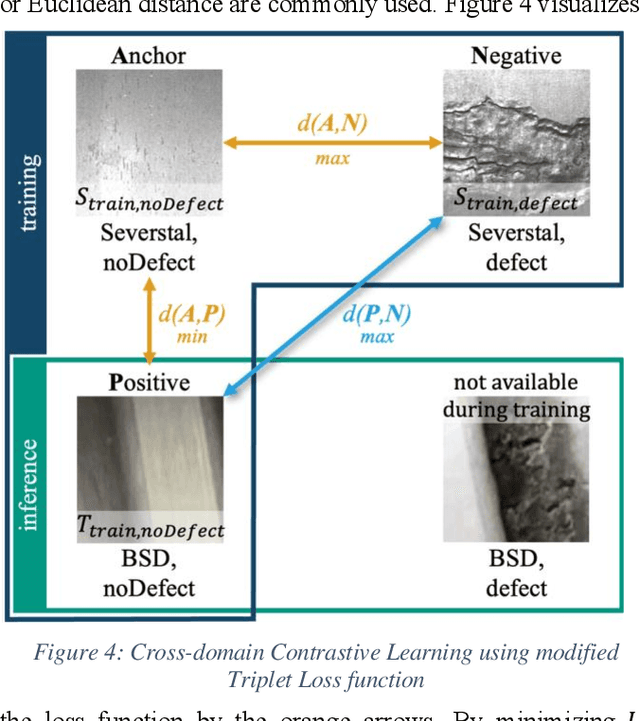
A common challenge in real world classification scenarios with sequentially appending target domain data is insufficient training datasets during the training phase. Therefore, conventional deep learning and transfer learning classifiers are not applicable especially when individual classes are not represented or are severely underrepresented at the outset. In many technical domains, however, it is only the defect or worn reject classes that are insufficiently represented, while the non-defect class is often available from the beginning. The proposed classification approach addresses such conditions and is based on a CNN encoder. Following a contrastive learning approach, it is trained with a modified triplet loss function using two datasets: Besides the non-defective target domain class 1st dataset, a state-of-the-art labeled source domain dataset that contains highly related classes e.g., a related manufacturing error or wear defect but originates from a highly different domain e.g., different product, material, or appearance = 2nd dataset is utilized. The approach learns the classification features from the source domain dataset while at the same time learning the differences between the source and the target domain in a single training step, aiming to transfer the relevant features to the target domain. The classifier becomes sensitive to the classification features and by architecture robust against the highly domain-specific context. The approach is benchmarked in a technical and a non-technical domain and shows convincing classification results. In particular, it is shown that the domain generalization capabilities and classification results are improved by the proposed architecture, allowing for larger domain shifts between source and target domains.