 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PickNet: Real-Time Channel Selection for Ad Hoc Microphone Arrays
Jan 24, 2022
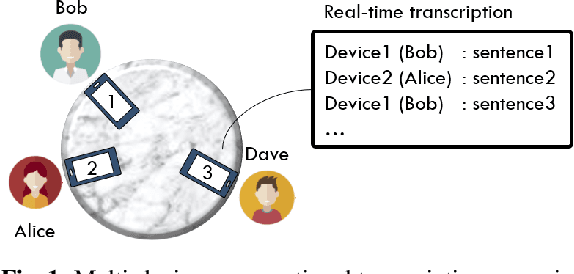
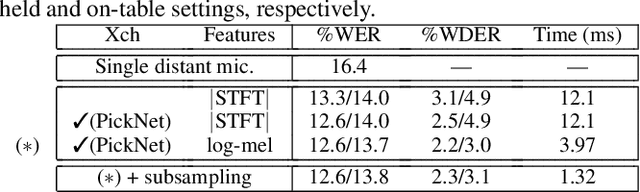
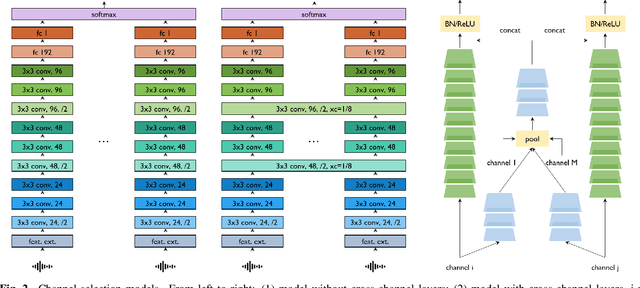
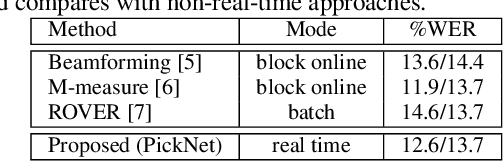
This paper proposes PickNet, a neural network model for real-time channel selection for an ad hoc microphone array consisting of multiple recording devices like cell phones. Assuming at most one person to be vocally active at each time point, PickNet identifies the device that is spatially closest to the active person for each time frame by using a short spectral patch of just hundreds of milliseconds. The model is applied to every time frame, and the short time frame signals from the selected microphones are concatenated across the frames to produce an output signal. As the personal devices are usually held close to their owners, the output signal is expected to have higher signal-to-noise and direct-to-reverberation ratios on average than the input signals. Since PickNet utilizes only limited acoustic context at each time frame, the system using the proposed model works in real time and is robust to changes in acoustic conditions. Speech recognition-based evaluation was carried out by using real conversational recordings obtained with various smartphones. The proposed model yielded significant gains in word error rate with limited computational cost over systems using a block-online beamformer and a single distant microphone.
Treatment-RSPN: Recurrent Sum-Product Networks for Sequential Treatment Regimes
Nov 14, 2022
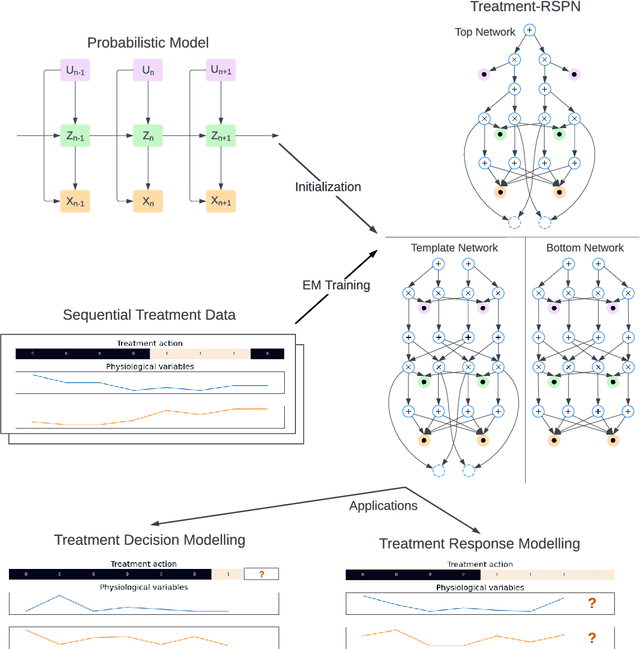
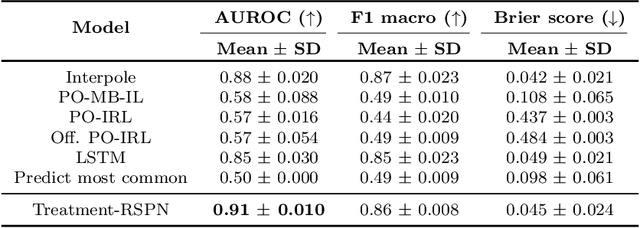
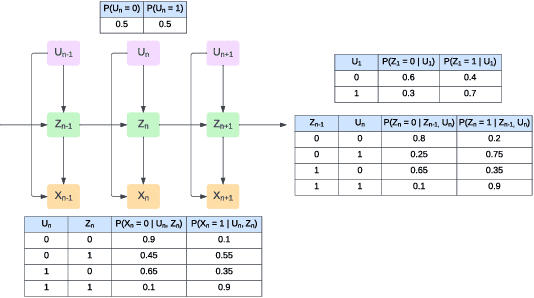
Sum-product networks (SPNs) have recently emerged as a novel deep learning architecture enabling highly efficient probabilistic inference. Since their introduction, SPNs have been applied to a wide range of data modalities and extended to time-sequence data. In this paper, we propose a general framework for modelling sequential treatment decision-making behaviour and treatment response using recurrent sum-product networks (RSPNs). Models developed using our framework benefit from the full range of RSPN capabilities, including the abilities to model the full distribution of the data, to seamlessly handle latent variables, missing values and categorical data, and to efficiently perform marginal and conditional inference. Our methodology is complemented by a novel variant of the expectation-maximization algorithm for RSPNs, enabling efficient training of our models. We evaluate our approach on a synthetic dataset as well as real-world data from the MIMIC-IV intensive care unit medical database. Our evaluation demonstrates that our approach can closely match the ground-truth data generation process on synthetic data and achieve results close to neural and probabilistic baselines while using a tractable and interpretable model.
Marine Microalgae Detection in Microscopy Images: A New Dataset
Nov 14, 2022

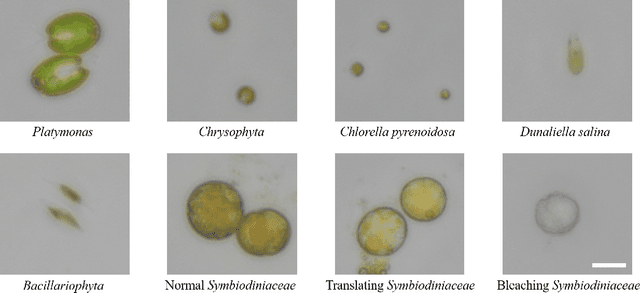
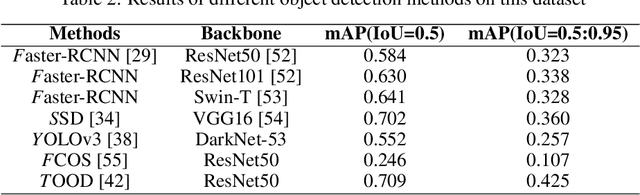
Marine microalgae are widespread in the ocean and play a crucial role in the ecosystem. Automatic identification and location of marine microalgae in microscopy images would help establish marine ecological environment monitoring and water quality evaluation system. A new dataset for marine microalgae detection is proposed in this paper. Six classes of microalgae commonlyfound in the ocean (Bacillariophyta, Chlorella pyrenoidosa, Platymonas, Dunaliella salina, Chrysophyta, Symbiodiniaceae) are microscopically imaged in real-time. Images of Symbiodiniaceae in three physiological states known as normal, bleaching, and translating are also included. We annotated these images with bounding boxes using Labelme software and split them into the training and testing sets. The total number of images in the dataset is 937 and all the objects in these images were annotated. The total number of annotated objects is 4201. The training set contains 537 images and the testing set contains 430 images. Baselines of different object detection algorithms are trained, validated and tested on this dataset. This data set can be got accessed via tianchi.aliyun.com/competition/entrance/532036/information.
MedleyVox: An Evaluation Dataset for Multiple Singing Voices Separation
Nov 14, 2022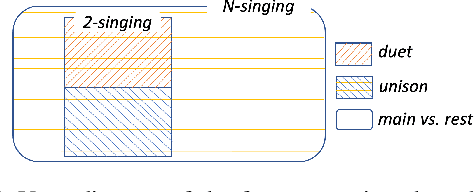
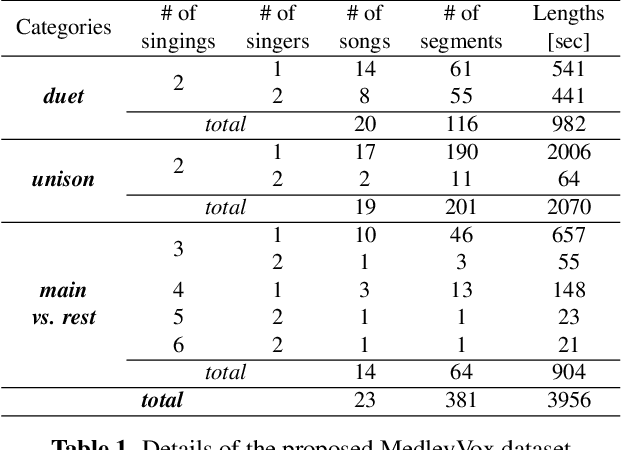
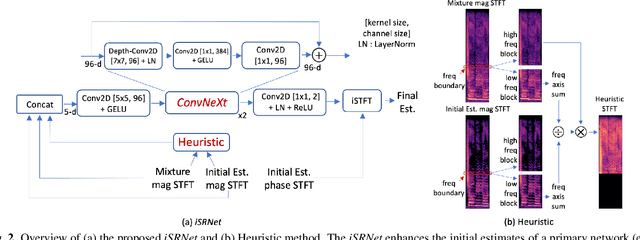
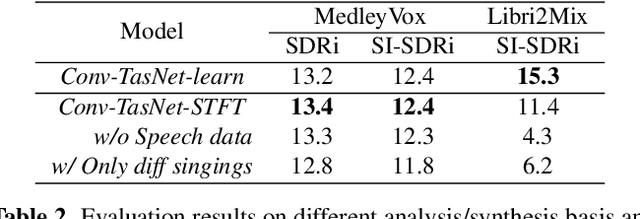
Separation of multiple singing voices into each voice is a rarely studied area in music source separation research. The absence of a benchmark dataset has hindered its progress. In this paper, we present an evaluation dataset and provide baseline studies for multiple singing voices separation. First, we introduce MedleyVox, an evaluation dataset for multiple singing voices separation that corresponds to such categories. We specify the problem definition in this dataset by categorizing the problem into i) duet, ii) unison, iii)main vs. rest, and iv) N-singing separation. Second, we present a strategy for construction of multiple singing mixtures using various single-singing datasets. This can be used to obtain training data. Third, we propose the improved super-resolution network (iSRNet). Jointly trained with the Conv-TasNet and the multi-singing mixture construction strategy, the proposed iSRNet achieved comparable performance to ideal time-frequency masks on duet and unison subsets of MedleyVox. Audio samples, the dataset, and codes are available on our GitHub page (https://github.com/jeonchangbin49/MedleyVox).
Language-free Training for Zero-shot Video Grounding
Oct 24, 2022
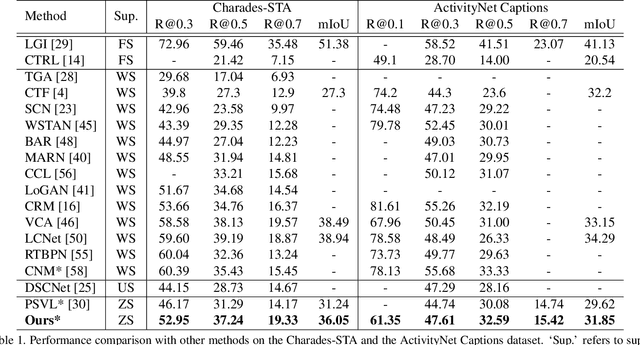
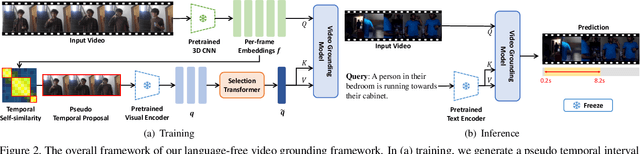
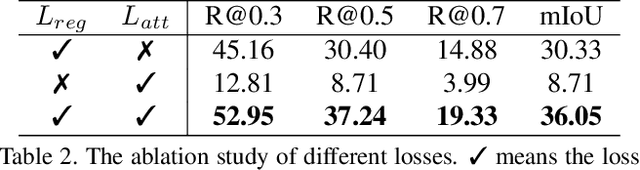
Given an untrimmed video and a language query depicting a specific temporal moment in the video, video grounding aims to localize the time interval by understanding the text and video simultaneously. One of the most challenging issues is an extremely time- and cost-consuming annotation collection, including video captions in a natural language form and their corresponding temporal regions. In this paper, we present a simple yet novel training framework for video grounding in the zero-shot setting, which learns a network with only video data without any annotation. Inspired by the recent language-free paradigm, i.e. training without language data, we train the network without compelling the generation of fake (pseudo) text queries into a natural language form. Specifically, we propose a method for learning a video grounding model by selecting a temporal interval as a hypothetical correct answer and considering the visual feature selected by our method in the interval as a language feature, with the help of the well-aligned visual-language space of CLIP. Extensive experiments demonstrate the prominence of our language-free training framework, outperforming the existing zero-shot video grounding method and even several weakly-supervised approaches with large margins on two standard datasets.
High Fidelity Neural Audio Compression
Oct 24, 2022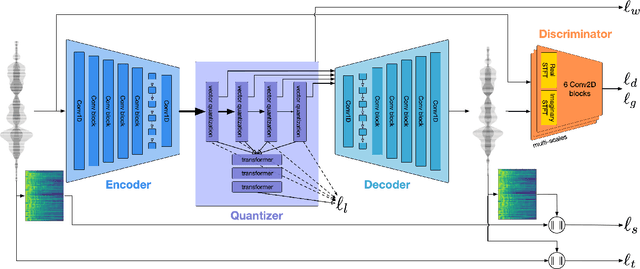
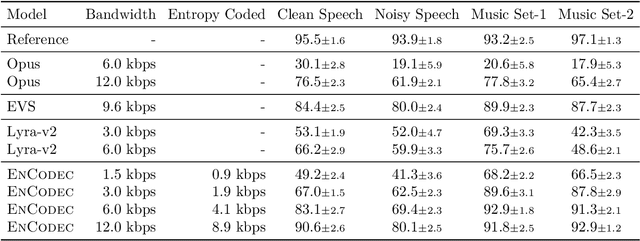
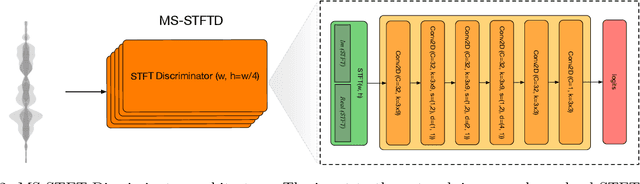
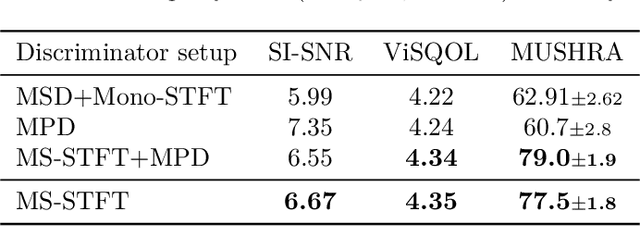
We introduce a state-of-the-art real-time, high-fidelity, audio codec leveraging neural networks. It consists in a streaming encoder-decoder architecture with quantized latent space trained in an end-to-end fashion. We simplify and speed-up the training by using a single multiscale spectrogram adversary that efficiently reduces artifacts and produce high-quality samples. We introduce a novel loss balancer mechanism to stabilize training: the weight of a loss now defines the fraction of the overall gradient it should represent, thus decoupling the choice of this hyper-parameter from the typical scale of the loss. Finally, we study how lightweight Transformer models can be used to further compress the obtained representation by up to 40%, while staying faster than real time. We provide a detailed description of the key design choices of the proposed model including: training objective, architectural changes and a study of various perceptual loss functions. We present an extensive subjective evaluation (MUSHRA tests) together with an ablation study for a range of bandwidths and audio domains, including speech, noisy-reverberant speech, and music. Our approach is superior to the baselines methods across all evaluated settings, considering both 24 kHz monophonic and 48 kHz stereophonic audio. Code and models are available at github.com/facebookresearch/encodec.
Evaluating Long-Term Memory in 3D Mazes
Oct 24, 2022
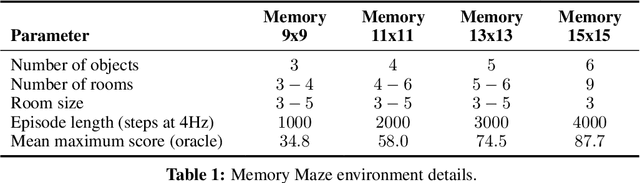
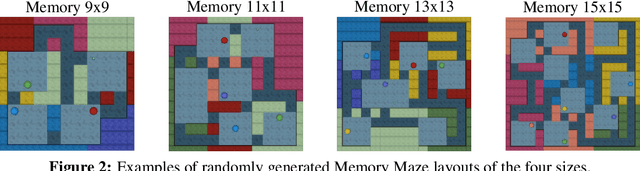
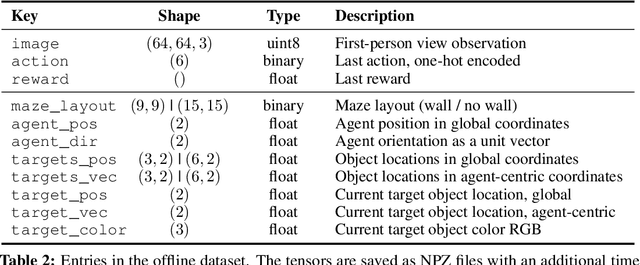
Intelligent agents need to remember salient information to reason in partially-observed environments. For example, agents with a first-person view should remember the positions of relevant objects even if they go out of view. Similarly, to effectively navigate through rooms agents need to remember the floor plan of how rooms are connected. However, most benchmark tasks in reinforcement learning do not test long-term memory in agents, slowing down progress in this important research direction. In this paper, we introduce the Memory Maze, a 3D domain of randomized mazes specifically designed for evaluating long-term memory in agents. Unlike existing benchmarks, Memory Maze measures long-term memory separate from confounding agent abilities and requires the agent to localize itself by integrating information over time. With Memory Maze, we propose an online reinforcement learning benchmark, a diverse offline dataset, and an offline probing evaluation. Recording a human player establishes a strong baseline and verifies the need to build up and retain memories, which is reflected in their gradually increasing rewards within each episode. We find that current algorithms benefit from training with truncated backpropagation through time and succeed on small mazes, but fall short of human performance on the large mazes, leaving room for future algorithmic designs to be evaluated on the Memory Maze.
Re-Analyze Gauss: Bounds for Private Matrix Approximation via Dyson Brownian Motion
Nov 11, 2022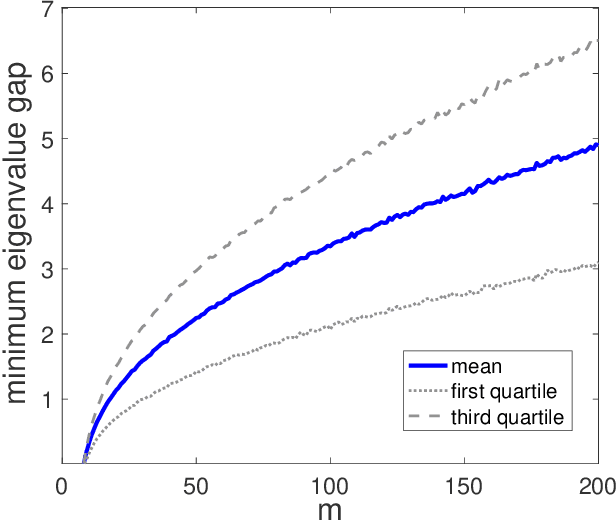
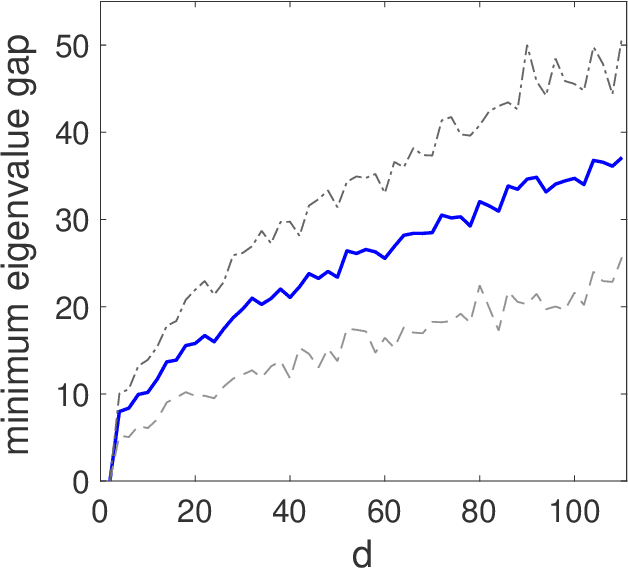
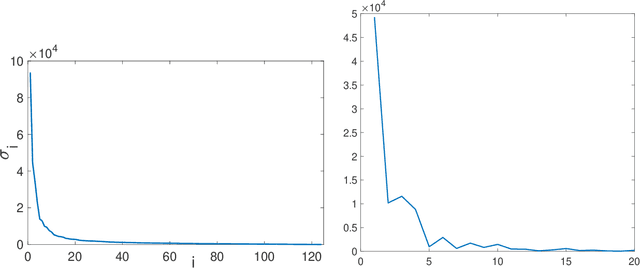
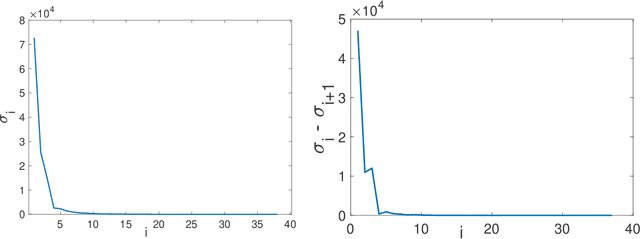
Given a symmetric matrix $M$ and a vector $\lambda$, we present new bounds on the Frobenius-distance utility of the Gaussian mechanism for approximating $M$ by a matrix whose spectrum is $\lambda$, under $(\varepsilon,\delta)$-differential privacy. Our bounds depend on both $\lambda$ and the gaps in the eigenvalues of $M$, and hold whenever the top $k+1$ eigenvalues of $M$ have sufficiently large gaps. When applied to the problems of private rank-$k$ covariance matrix approximation and subspace recovery, our bounds yield improvements over previous bounds. Our bounds are obtained by viewing the addition of Gaussian noise as a continuous-time matrix Brownian motion. This viewpoint allows us to track the evolution of eigenvalues and eigenvectors of the matrix, which are governed by stochastic differential equations discovered by Dyson. These equations allow us to bound the utility as the square-root of a sum-of-squares of perturbations to the eigenvectors, as opposed to a sum of perturbation bounds obtained via Davis-Kahan-type theorems.
A Graph-Based Approach to Generate Energy-Optimal Robot Trajectories in Polygonal Environments
Nov 11, 2022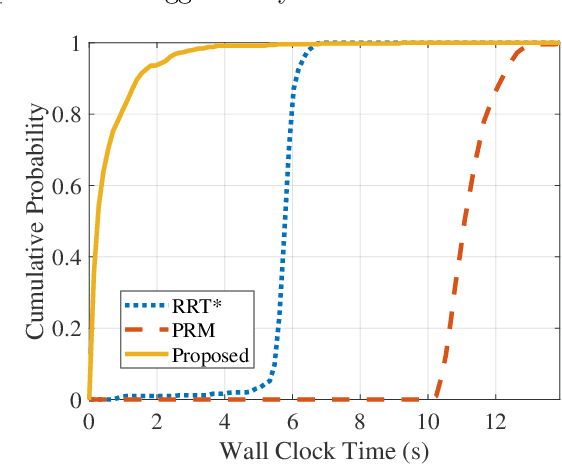
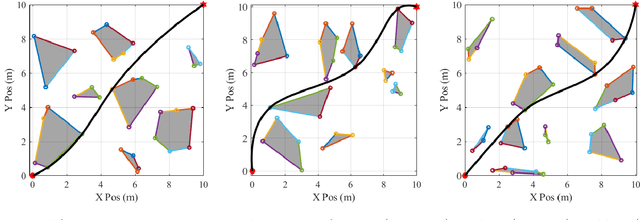
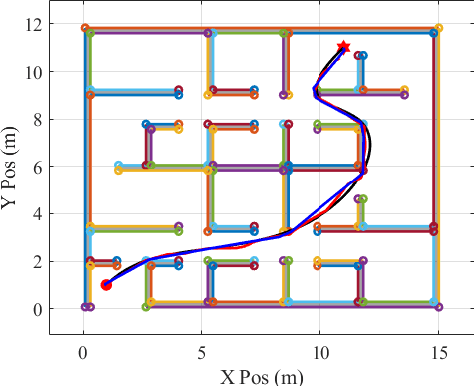
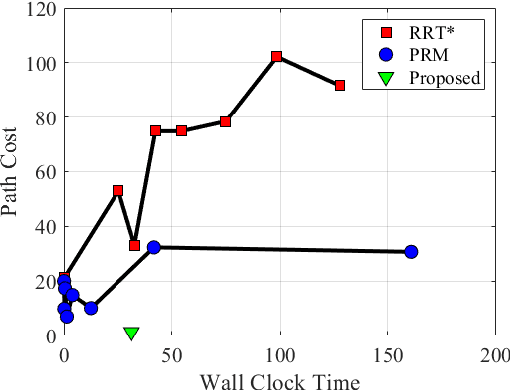
As robotic systems continue to address emerging issues in areas such as logistics, mobility, manufacturing, and disaster response, it is increasingly important to rapidly generate safe and energy-efficient trajectories. In this article, we present a new approach to plan energy-optimal trajectories through cluttered environments containing polygonal obstacles. In particular, we develop a method to quickly generate optimal trajectories for a double-integrator system, and we show that optimal path planning reduces to an integer program. To find an efficient solution, we present a distance-informed prefix search to efficiently generate optimal trajectories for a large class of environments. We demonstrate that our approach, while matching the performance of RRT* and Probabilistic Road Maps in terms of path length, outperforms both in terms of energy cost and computational time by up to an order of magnitude. We also demonstrate that our approach yields implementable trajectories in an experiment with a Crazyflie quadrotor.
Dual Complementary Dynamic Convolution for Image Recognition
Nov 11, 2022As a powerful engine, vanilla convolution has promoted huge breakthroughs in various computer tasks. However, it often suffers from sample and content agnostic problems, which limits the representation capacities of the convolutional neural networks (CNNs). In this paper, we for the first time model the scene features as a combination of the local spatial-adaptive parts owned by the individual and the global shift-invariant parts shared to all individuals, and then propose a novel two-branch dual complementary dynamic convolution (DCDC) operator to flexibly deal with these two types of features. The DCDC operator overcomes the limitations of vanilla convolution and most existing dynamic convolutions who capture only spatial-adaptive features, and thus markedly boosts the representation capacities of CNNs. Experiments show that the DCDC operator based ResNets (DCDC-ResNets) significantly outperform vanilla ResNets and most state-of-the-art dynamic convolutional networks on image classification, as well as downstream tasks including object detection, instance and panoptic segmentation tasks, while with lower FLOPs and parameters.