 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sinusoidal Frequency Estimation by Gradient Descent
Oct 26, 2022
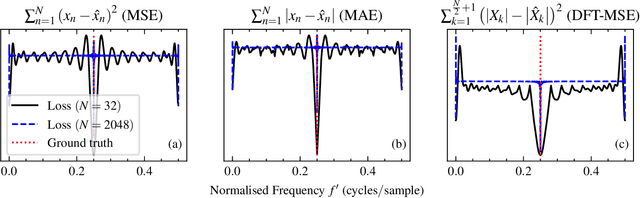
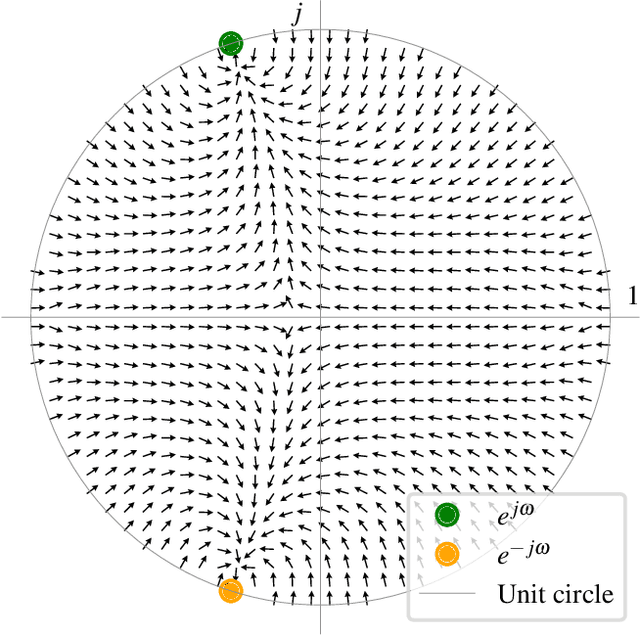
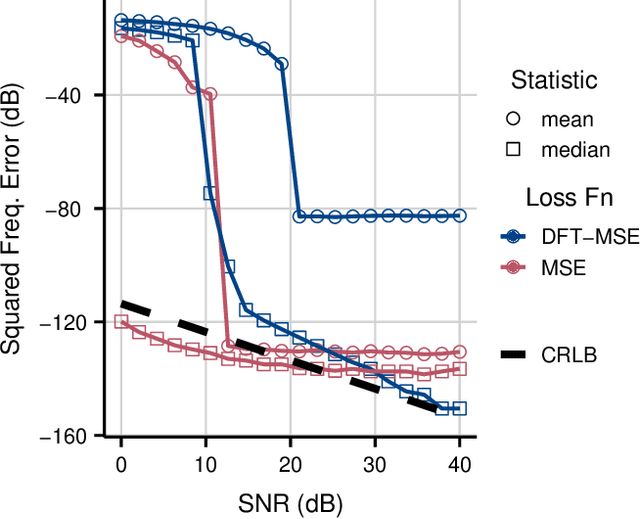
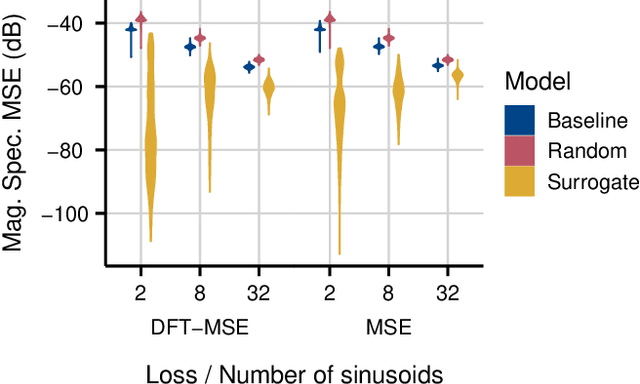
Sinusoidal parameter estimation is a fundamental task in applications from spectral analysis to time-series forecasting. Estimating the sinusoidal frequency parameter by gradient descent is, however, often impossible as the error function is non-convex and densely populated with local minima. The growing family of differentiable signal processing methods has therefore been unable to tune the frequency of oscillatory components, preventing their use in a broad range of applications. This work presents a technique for joint sinusoidal frequency and amplitude estimation using the Wirtinger derivatives of a complex exponential surrogate and any first order gradient-based optimizer, enabling end to-end training of neural network controllers for unconstrained sinusoidal models.
Pi theorem formulation of flood mapping
Nov 16, 2022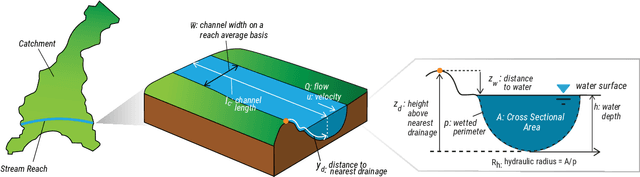
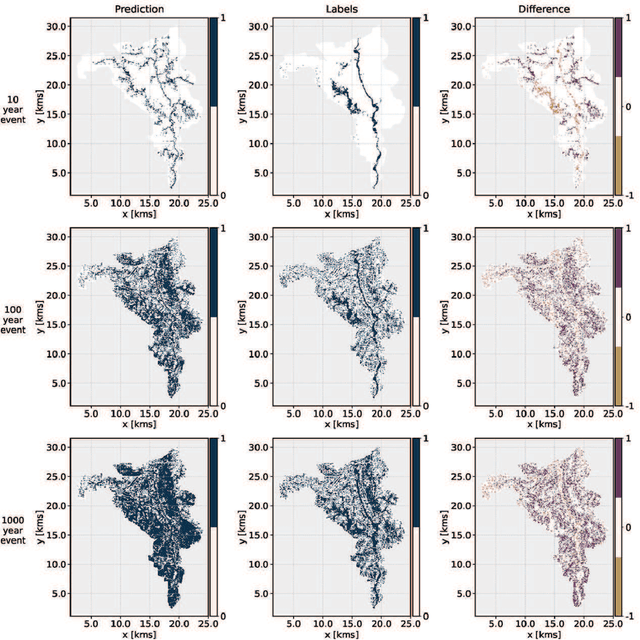
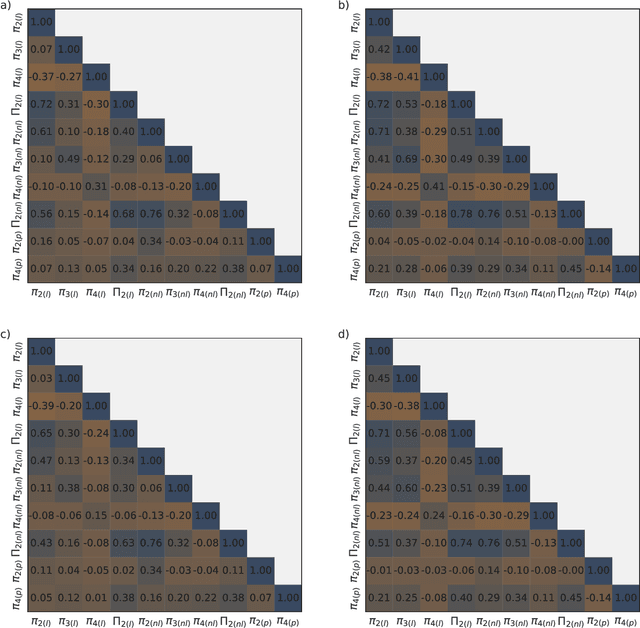
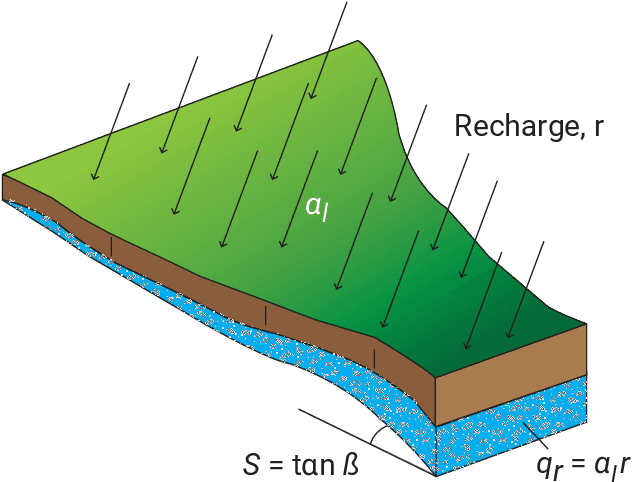
While physical phenomena are stated in terms of physical laws that are homogeneous in all dimensions, the mechanisms and patterns of the physical phenomena are independent of the form of the units describing the physical process. Accordingly, across different conditions, the similarity of a process may be captured through a dimensionless reformulation of the physical problem with Buckingham $\Pi$ theorem. Here, we apply Buckingham $\Pi$ theorem for creating dimensionless indices for capturing the similarity of the flood process, and in turn, these indices allow machine learning to map the likelihood of pluvial (flash) flooding over a landscape. In particular, we use these dimensionless predictors with a logistic regression machine learning (ML) model for a probabilistic determination of flood risk. The logistic regression derived flood maps compare well to 2D hydraulic model results that are the basis of the Federal Emergency Management Agency (FEMA) maps. As a result, the indices and logistic regression also provide the potential to expand existing FEMA maps to new (unmapped) areas and a wider spectrum of flood flows and precipitation events. Our results demonstrate that the new dimensionless indices capture the similarity of the flood process across different topographies and climate regions. Consequently, these dimensionless indices may expand observations of flooding (e.g., satellite) to the risk of flooding in new areas, as well as provide a basis for the rapid, real-time estimation of flood risk on a worldwide scale.
Features for the 0-1 knapsack problem based on inclusionwise maximal solutions
Nov 16, 2022
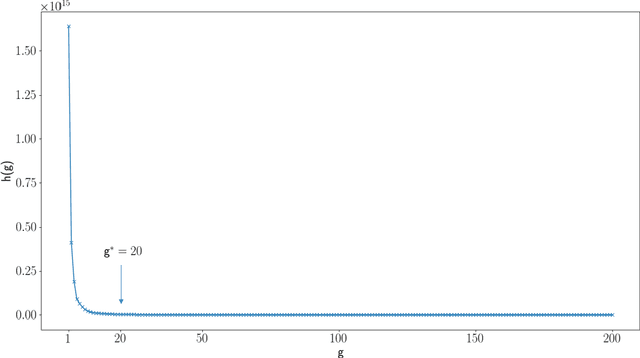
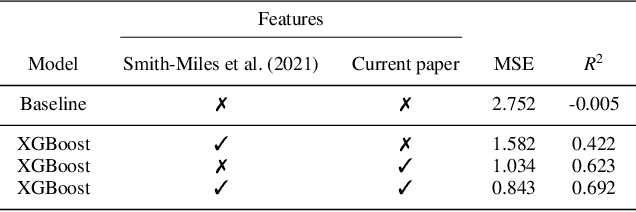
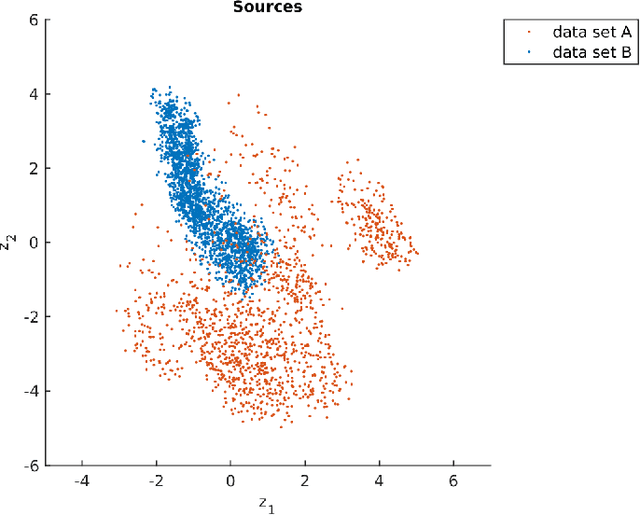
Decades of research on the 0-1 knapsack problem led to very efficient algorithms that are able to quickly solve large problem instances to optimality. This prompted researchers to also investigate whether relatively small problem instances exist that are hard for existing solvers and investigate which features characterize their hardness. Previously the authors proposed a new class of hard 0-1 knapsack problem instances and demonstrated that the properties of so-called inclusionwise maximal solutions (IMSs) can be important hardness indicators for this class. In the current paper, we formulate several new computationally challenging problems related to the IMSs of arbitrary 0-1 knapsack problem instances. Based on generalizations of previous work and new structural results about IMSs, we formulate polynomial and pseudopolynomial time algorithms for solving these problems. From this we derive a set of 14 computationally expensive features, which we calculate for two large datasets on a supercomputer in approximately 540 CPU-hours. We show that the proposed features contain important information related to the empirical hardness of a problem instance that was missing in earlier features from the literature by training machine learning models that can accurately predict the empirical hardness of a wide variety of 0-1 knapsack problem instances. Using the instance space analysis methodology, we also show that hard 0-1 knapsack problem instances are clustered together around a relatively dense region of the instance space and several features behave differently in the easy and hard parts of the instance space.
Data efficient surrogate modeling for engineering design: Ensemble-free batch mode deep active learning for regression
Nov 16, 2022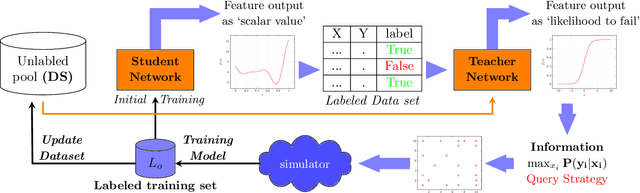

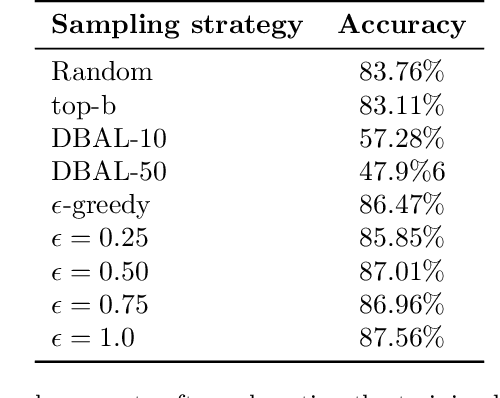
In a computer-aided engineering design optimization problem that involves notoriously complex and time-consuming simulator, the prevalent approach is to replace these simulations with a data-driven surrogate that approximates the simulator's behavior at a much cheaper cost. The main challenge in creating an inexpensive data-driven surrogate is the generation of a sheer number of data using these computationally expensive numerical simulations. In such cases, Active Learning (AL) methods have been used that attempt to learn an input--output behavior while labeling the fewest samples possible. The current trend in AL for a regression problem is dominated by the Bayesian framework that needs training an ensemble of learning models that makes surrogate training computationally tedious if the underlying learning model is Deep Neural Networks (DNNs). However, DNNs have an excellent capability to learn highly nonlinear and complex relationships even for a very high dimensional problem. To leverage the excellent learning capability of deep networks along with avoiding the computational complexity of the Bayesian paradigm, in this work we propose a simple and scalable approach for active learning that works in a student-teacher manner to train a surrogate model. By using this proposed approach, we are able to achieve the same level of surrogate accuracy as the other baselines like DBAL and Monte Carlo sampling with up to 40 % fewer samples. We empirically evaluated this method on multiple use cases including three different engineering design domains:finite element analysis, computational fluid dynamics, and propeller design.
The PerspectiveLiberator -- an upmixing 6DoF rendering plugin for single-perspective Ambisonic room impulse responses
Oct 10, 2022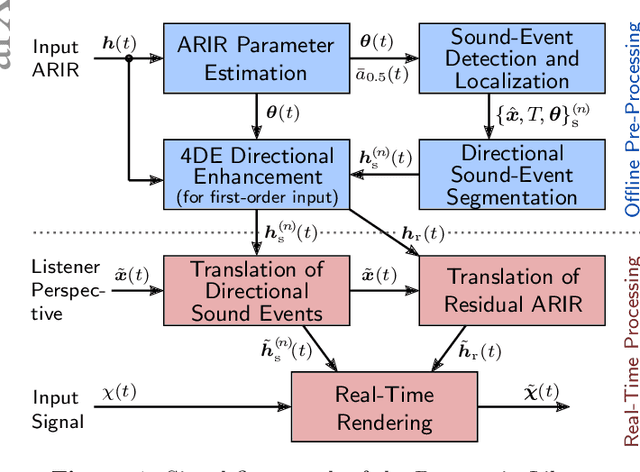
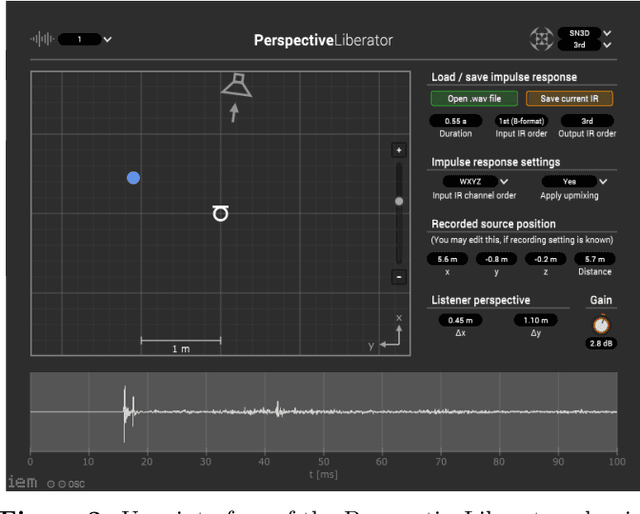
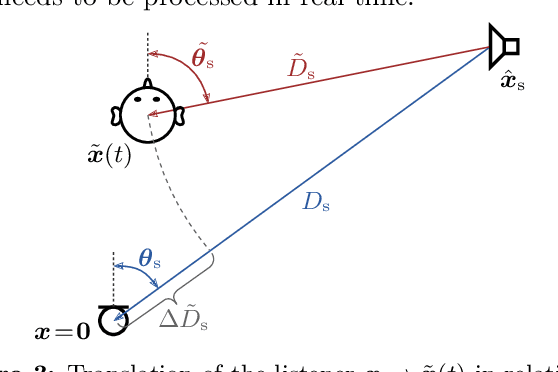
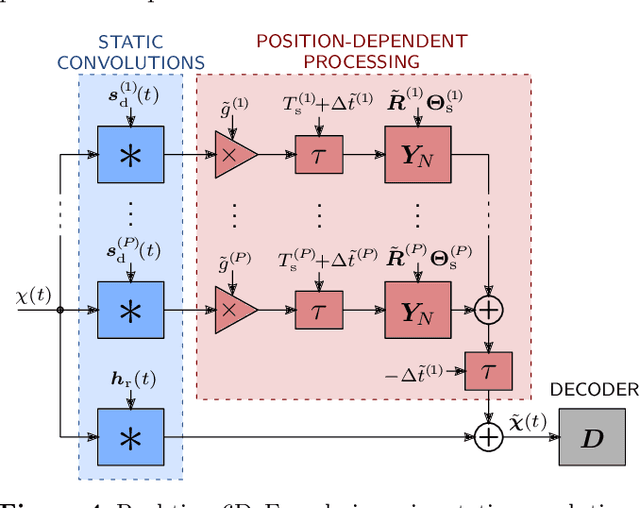
Nowadays, virtual reality interfaces allow the user to change perspectives in six degrees of freedom (6DoF) virtually, and consistently with the visual part, the acoustic perspective needs to be updated interactively. Single-perspective rendering with dynamic head rotation already works quite reliably with upmixed first-order Ambisonic room impulse responses (ASDM, SIRR, etc.). This contribution presents a plugin to free the virtual perspective from the measured one by real-time perspective extrapolation: The PerspectiveLiberator. The plugin permits selecting between two different algorithms for directional resolution enhancement (ASDM, 4DE). And for its main task of convolution-based 6DoF rendering, the plugin detects and localizes prominent directional sound events in the early Ambisonic room impulse response and re-encodes them with direction, time of arrival, and level adapted to the variable perspective of the virtual listener. The diffuse residual is enhanced in directional resolution but remains unaffected by translatory movement to preserve as much of the original room impression as possible.
* 4 pages, submitted to conference: DAGA 2021, Vienna, Austria, 2021
Impact of spiking neurons leakages and network recurrences on event-based spatio-temporal pattern recognition
Nov 14, 2022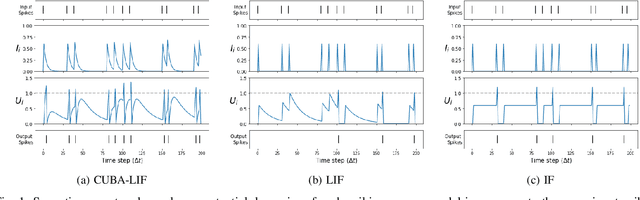
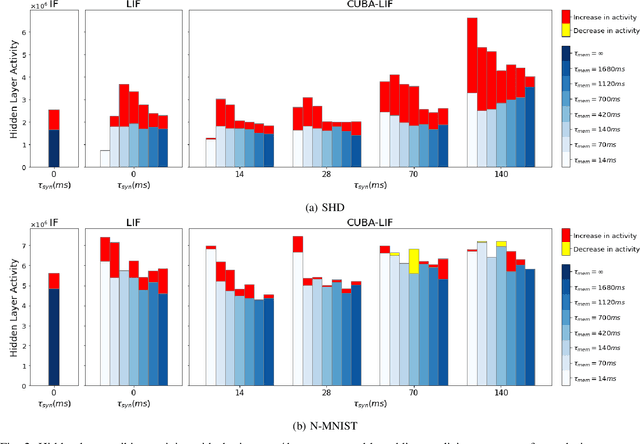
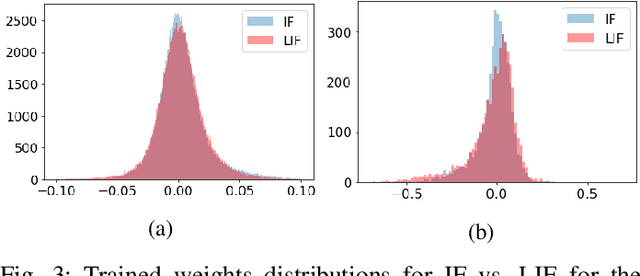

Spiking neural networks coupled with neuromorphic hardware and event-based sensors are getting increased interest for low-latency and low-power inference at the edge. However, multiple spiking neuron models have been proposed in the literature with different levels of biological plausibility and different computational features and complexities. Consequently, there is a need to define the right level of abstraction from biology in order to get the best performance in accurate, efficient and fast inference in neuromorphic hardware. In this context, we explore the impact of synaptic and membrane leakages in spiking neurons. We confront three neural models with different computational complexities using feedforward and recurrent topologies for event-based visual and auditory pattern recognition. Our results show that, in terms of accuracy, leakages are important when there are both temporal information in the data and explicit recurrence in the network. In addition, leakages do not necessarily increase the sparsity of spikes flowing in the network. We also investigate the impact of heterogeneity in the time constant of leakages, and the results show a slight improvement in accuracy when using data with a rich temporal structure. These results advance our understanding of the computational role of the neural leakages and network recurrences, and provide valuable insights for the design of compact and energy-efficient neuromorphic hardware for embedded systems.
Legged Locomotion in Challenging Terrains using Egocentric Vision
Nov 14, 2022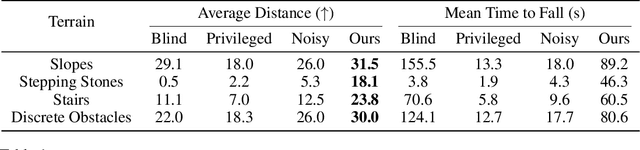

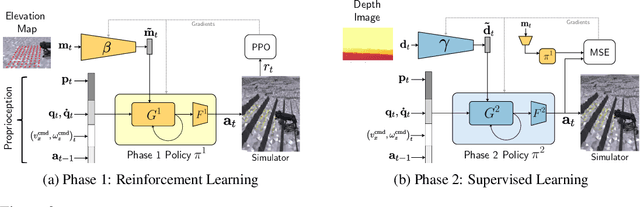
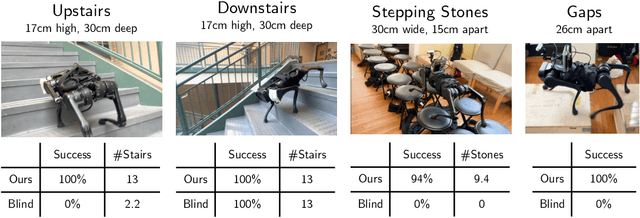
Animals are capable of precise and agile locomotion using vision. Replicating this ability has been a long-standing goal in robotics. The traditional approach has been to decompose this problem into elevation mapping and foothold planning phases. The elevation mapping, however, is susceptible to failure and large noise artifacts, requires specialized hardware, and is biologically implausible. In this paper, we present the first end-to-end locomotion system capable of traversing stairs, curbs, stepping stones, and gaps. We show this result on a medium-sized quadruped robot using a single front-facing depth camera. The small size of the robot necessitates discovering specialized gait patterns not seen elsewhere. The egocentric camera requires the policy to remember past information to estimate the terrain under its hind feet. We train our policy in simulation. Training has two phases - first, we train a policy using reinforcement learning with a cheap-to-compute variant of depth image and then in phase 2 distill it into the final policy that uses depth using supervised learning. The resulting policy transfers to the real world and is able to run in real-time on the limited compute of the robot. It can traverse a large variety of terrain while being robust to perturbations like pushes, slippery surfaces, and rocky terrain. Videos are at https://vision-locomotion.github.io
Analytical Estimation of Beamforming Speed-of-Sound Using Transmission Geometry
Nov 21, 2022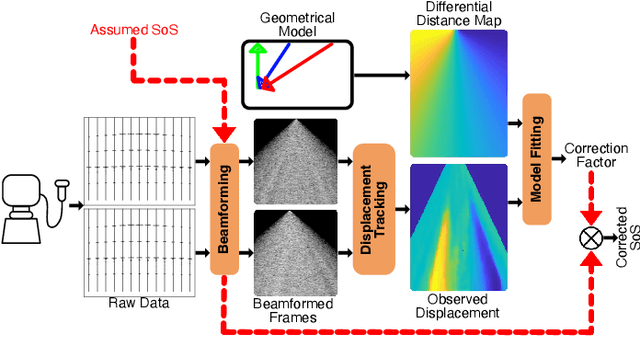
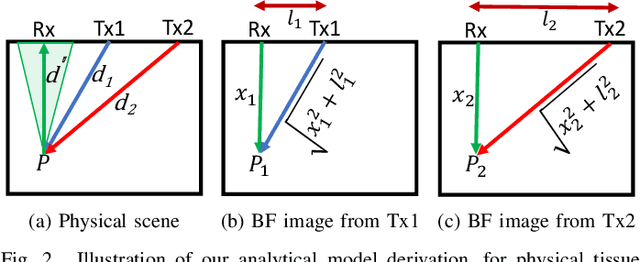
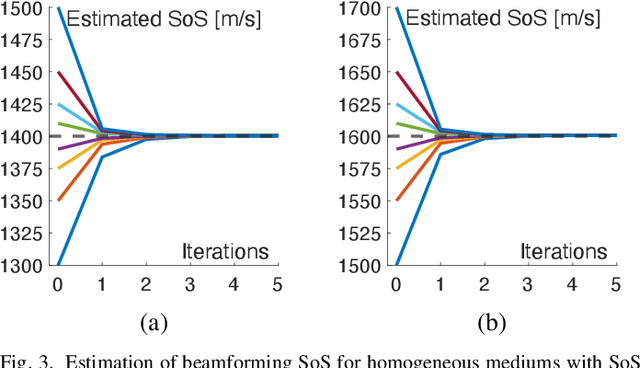
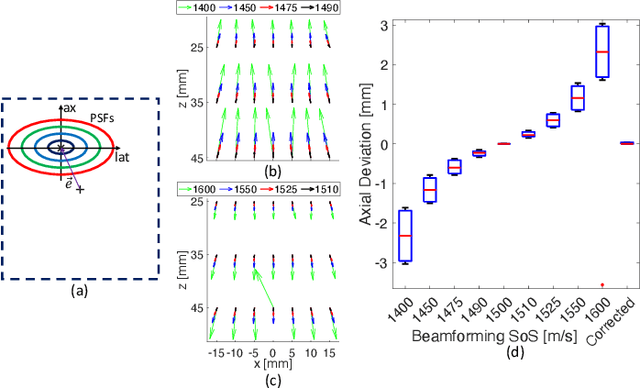
Most ultrasound imaging techniques necessitate the fundamental step of converting temporal signals received from transducer elements into a spatial echogenecity map. This beamforming (BF) step requires the knowledge of speed-of-sound (SoS) value in the imaged medium. An incorrect assumption of BF SoS leads to aberration artifacts, not only deteriorating the quality and resolution of conventional brightness mode (B-mode) images, hence limiting their clinical usability, but also impairing other ultrasound modalities such as elastography and spatial SoS reconstructions, which rely on faithfully beamformed images as their input. In this work, we propose an analytical method for estimating BF SoS. We show that pixel-wise relative shifts between frames beamformed with an assumed SoS is a function of geometric disparities of the transmission paths and the error in such SoS assumption. Using this relation, we devise an analytical model, the closed form solution of which yields the difference between the assumed and the true SoS in the medium. Based on this, we correct the BF SoS, which can also be applied iteratively. Both in simulations and experiments, lateral B-mode resolution is shown to be improved by $\approx$25% compared to that with an initial SoS assumption error of 3.3% (50 m/s), while localization artifacts from beamforming are also corrected. After 5 iterations, our method achieves BF SoS errors of under 0.6 m/s in simulations and under 1 m/s in experimental phantom data. Residual time-delay errors in beamforming 32 numerical phantoms are shown to reduce down to 0.07 $\mu$s, with average improvements of up to 21 folds compared to initial inaccurate assumptions. We additionally show the utility of the proposed method in imaging local SoS maps, where using our correction method reduces reconstruction root-mean-square errors substantially, down to their lower-bound with actual BF SoS.
Reward-Mixing MDPs with a Few Latent Contexts are Learnable
Oct 05, 2022We consider episodic reinforcement learning in reward-mixing Markov decision processes (RMMDPs): at the beginning of every episode nature randomly picks a latent reward model among $M$ candidates and an agent interacts with the MDP throughout the episode for $H$ time steps. Our goal is to learn a near-optimal policy that nearly maximizes the $H$ time-step cumulative rewards in such a model. Previous work established an upper bound for RMMDPs for $M=2$. In this work, we resolve several open questions remained for the RMMDP model. For an arbitrary $M\ge2$, we provide a sample-efficient algorithm--$\texttt{EM}^2$--that outputs an $\epsilon$-optimal policy using $\tilde{O} \left(\epsilon^{-2} \cdot S^d A^d \cdot \texttt{poly}(H, Z)^d \right)$ episodes, where $S, A$ are the number of states and actions respectively, $H$ is the time-horizon, $Z$ is the support size of reward distributions and $d=\min(2M-1,H)$. Our technique is a higher-order extension of the method-of-moments based approach, nevertheless, the design and analysis of the \algname algorithm requires several new ideas beyond existing techniques. We also provide a lower bound of $(SA)^{\Omega(\sqrt{M})} / \epsilon^{2}$ for a general instance of RMMDP, supporting that super-polynomial sample complexity in $M$ is necessary.
Continuous-Time Analog Filters for Audio Edge Intelligence: Review and Analysis on Design Techniques
Jun 06, 2022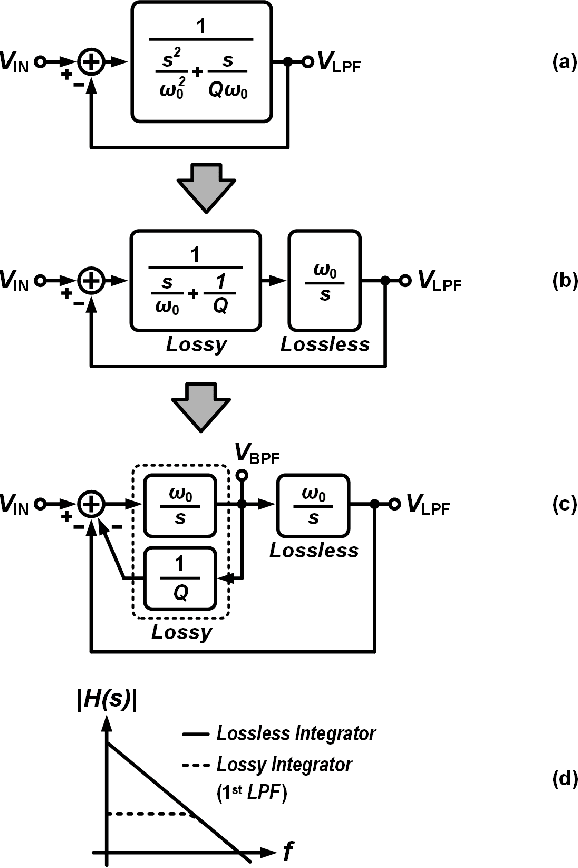
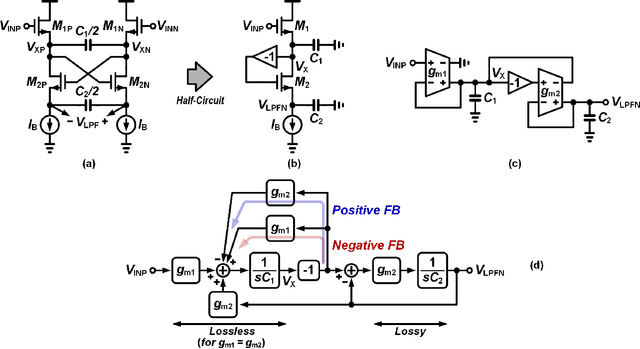
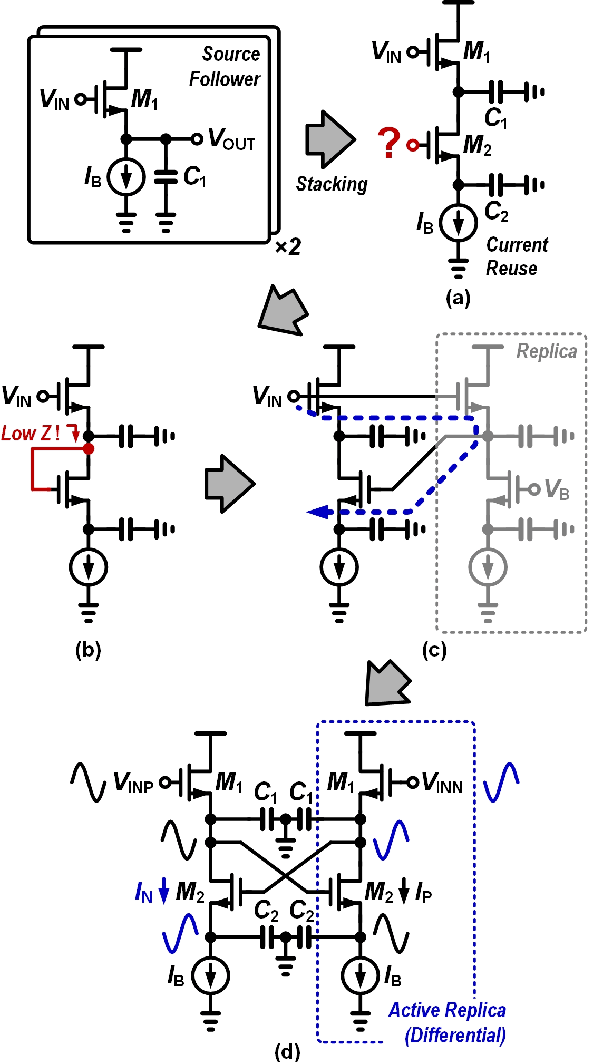
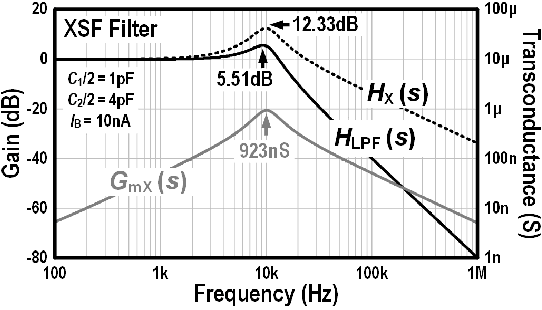
Silicon cochlea designs capture the functionality of the biological cochlea. Their use has been explored for cochlea prosthesis applications and more recently in edge audio devices which are required to support always-on operation. As their stringent power constraints pose several design challenges, IC designers are forced to look for solutions that use low standby power. One promising bio-inspired approach is to combine the continuous-time analog filter channels of the silicon cochlea with a small memory footprint deep neural network that is trained on edge tasks such as keyword spotting, thereby allowing all blocks to be embedded in an IC. This paper reviews the analog filter circuits used as feature extractors for current edge audio devices, starting with the original biquad filter circuits proposed for the silicon cochlea. Our analysis starts from the interpretation of a basic biquad filter as a two-integrator-loop topology and reviews the progression in the design of second-order low-pass and band-pass filters ranging from OTA-based to source-follower-based architectures. We also derive and analyze the small-signal transfer function and discuss performance aspects of these filters. The analysis of these different filter configurations can be applied to other application domains such as biomedical devices which employ a front-end bandpass filter.