 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Monte Carlo Tree Search Algorithms for Risk-Aware and Multi-Objective Reinforcement Learning
Nov 23, 2022

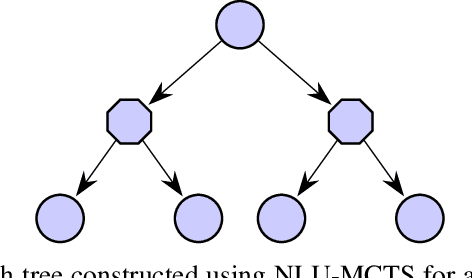
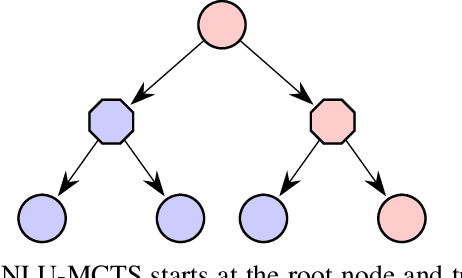
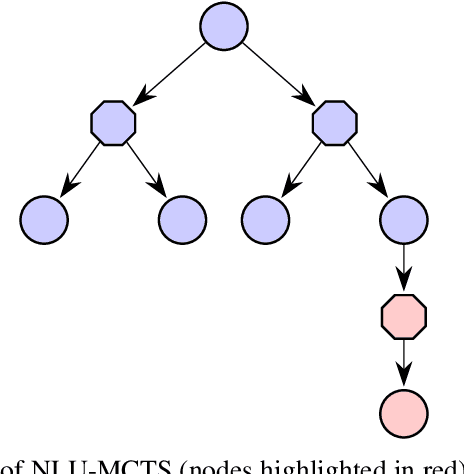
In many risk-aware and multi-objective reinforcement learning settings, the utility of the user is derived from a single execution of a policy. In these settings, making decisions based on the average future returns is not suitable. For example, in a medical setting a patient may only have one opportunity to treat their illness. Making decisions using just the expected future returns -- known in reinforcement learning as the value -- cannot account for the potential range of adverse or positive outcomes a decision may have. Therefore, we should use the distribution over expected future returns differently to represent the critical information that the agent requires at decision time by taking both the future and accrued returns into consideration. In this paper, we propose two novel Monte Carlo tree search algorithms. Firstly, we present a Monte Carlo tree search algorithm that can compute policies for nonlinear utility functions (NLU-MCTS) by optimising the utility of the different possible returns attainable from individual policy executions, resulting in good policies for both risk-aware and multi-objective settings. Secondly, we propose a distributional Monte Carlo tree search algorithm (DMCTS) which extends NLU-MCTS. DMCTS computes an approximate posterior distribution over the utility of the returns, and utilises Thompson sampling during planning to compute policies in risk-aware and multi-objective settings. Both algorithms outperform the state-of-the-art in multi-objective reinforcement learning for the expected utility of the returns.
Comparison of Motion Encoding Frameworks on Human Manipulation Actions
Nov 23, 2022
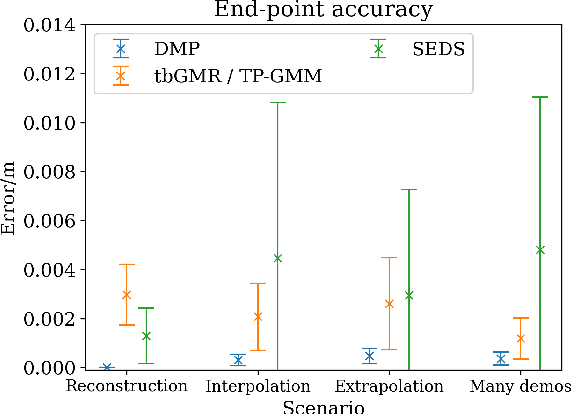
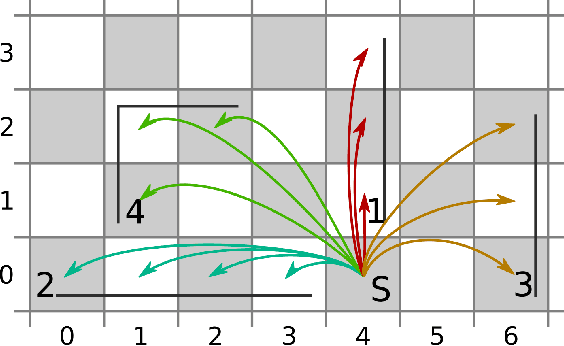
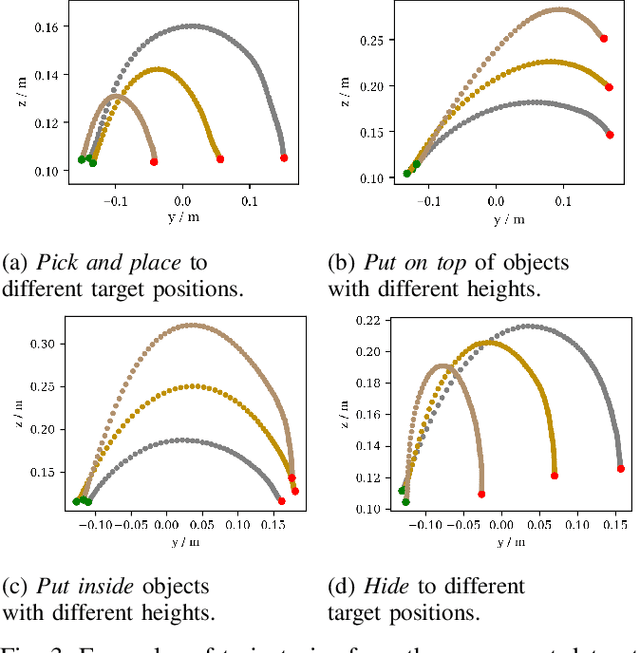
Movement generation, and especially generalisation to unseen situations, plays an important role in robotics. Different types of movement generation methods exist such as spline based methods, dynamical system based methods, and methods based on Gaussian mixture models (GMMs). Using a large, new dataset on human manipulations, in this paper we provide a highly detailed comparison of three most widely used movement encoding and generation frameworks: dynamic movement primitives (DMPs), time based Gaussian mixture regression (tbGMR) and stable estimator of dynamical systems (SEDS). We compare these frameworks with respect to their movement encoding efficiency, reconstruction accuracy, and movement generalisation capabilities. The new dataset consists of nine object manipulation actions performed by 12 humans: pick and place, put on top/take down, put inside/take out, hide/uncover, and push/pull with a total of 7,652 movement examples. Our analysis shows that for movement encoding and reconstruction DMPs are the most efficient framework with respect to the number of parameters and reconstruction accuracy if a sufficient number of kernels is used. In case of movement generalisation to new start- and end-point situations, DMPs and task parameterized GMM (TP-GMM, movement generalisation framework based on tbGMR) lead to similar performance and outperform SEDS. Furthermore we observe that TP-GMM and SEDS suffer from inaccurate convergence to the end-point as compared to DMPs. These different quantitative results will help designing trajectory representations in an improved task-dependent way in future robotic applications.
SS-CXR: Multitask Representation Learning using Self Supervised Pre-training from Chest X-Rays
Nov 23, 2022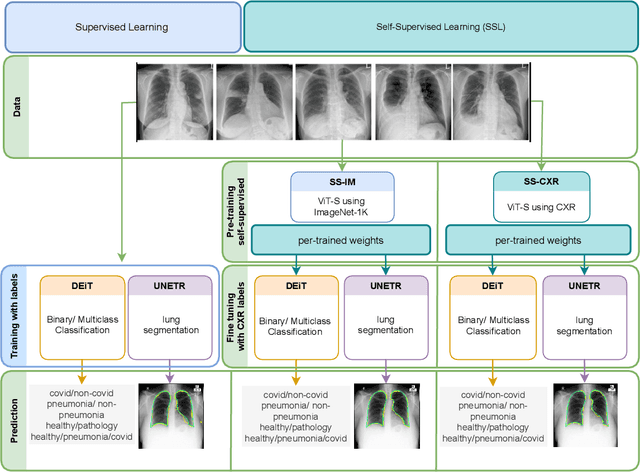

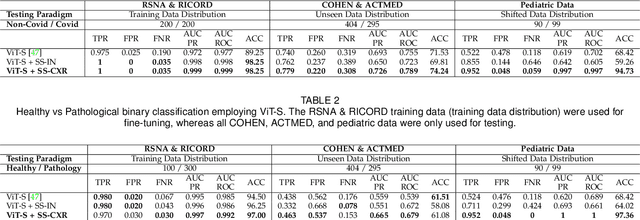

Chest X-rays (CXRs) are a widely used imaging modality for the diagnosis and prognosis of lung disease. The image analysis tasks vary. Examples include pathology detection and lung segmentation. There is a large body of work where machine learning algorithms are developed for specific tasks. A significant recent example is Coronavirus disease (covid-19) detection using CXR data. However, the traditional diagnostic tool design methods based on supervised learning are burdened by the need to provide training data annotation, which should be of good quality for better clinical outcomes. Here, we propose an alternative solution, a new self-supervised paradigm, where a general representation from CXRs is learned using a group-masked self-supervised framework. The pre-trained model is then fine-tuned for domain-specific tasks such as covid-19, pneumonia detection, and general health screening. We show that the same pre-training can be used for the lung segmentation task. Our proposed paradigm shows robust performance in multiple downstream tasks which demonstrates the success of the pre-training. Moreover, the performance of the pre-trained models on data with significant drift during test time proves the learning of a better generic representation. The methods are further validated by covid-19 detection in a unique small-scale pediatric data set. The performance gain in accuracy (~25\%) is significant when compared to a supervised transformer-based method. This adds credence to the strength and reliability of our proposed framework and pre-training strategy.
Are Concept Drift Detectors Reliable Alarming Systems? -- A Comparative Study
Nov 23, 2022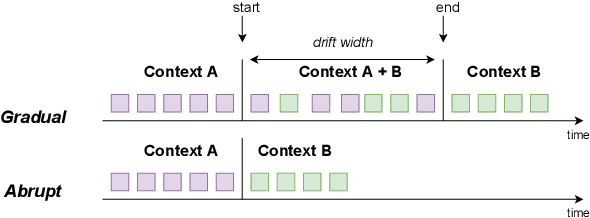
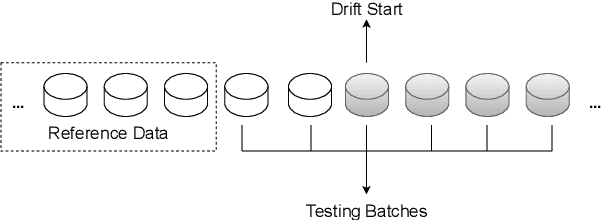
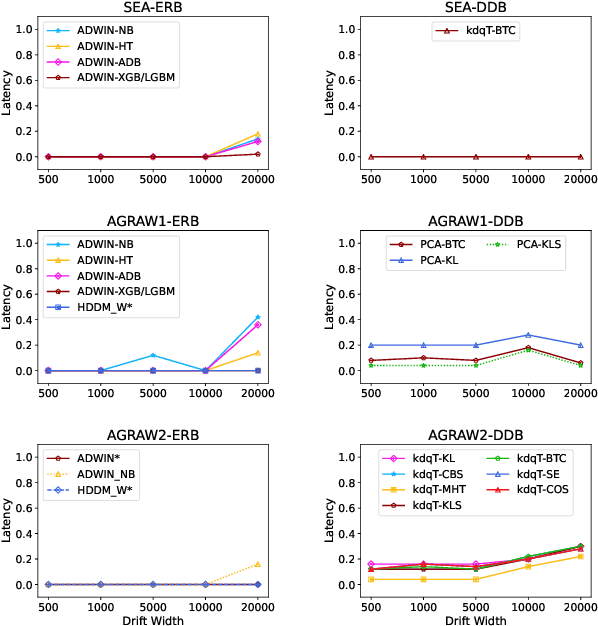
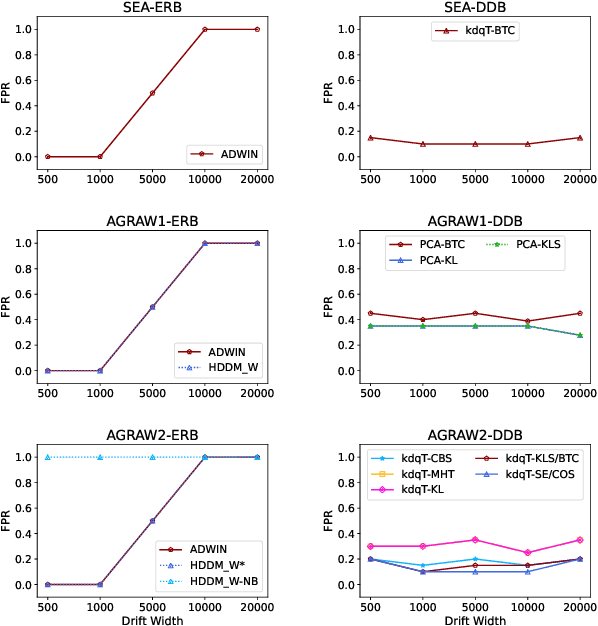
As machine learning models increasingly replace traditional business logic in the production system, their lifecycle management is becoming a significant concern. Once deployed into production, the machine learning models are constantly evaluated on new streaming data. Given the continuous data flow, shifting data, also known as concept drift, is ubiquitous in such settings. Concept drift usually impacts the performance of machine learning models, thus, identifying the moment when concept drift occurs is required. Concept drift is identified through concept drift detectors. In this work, we assess the reliability of concept drift detectors to identify drift in time by exploring how late are they reporting drifts and how many false alarms are they signaling. We compare the performance of the most popular drift detectors belonging to two different concept drift detector groups, error rate-based detectors and data distribution-based detectors. We assess their performance on both synthetic and real-world data. In the case of synthetic data, we investigate the performance of detectors to identify two types of concept drift, abrupt and gradual. Our findings aim to help practitioners understand which drift detector should be employed in different situations and, to achieve this, we share a list of the most important observations made throughout this study, which can serve as guidelines for practical usage. Furthermore, based on our empirical results, we analyze the suitability of each concept drift detection group to be used as alarming system.
Self-Supervised Learning based on Heat Equation
Nov 23, 2022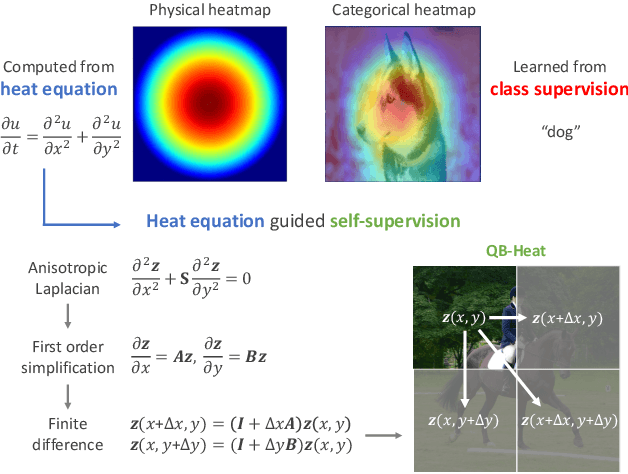

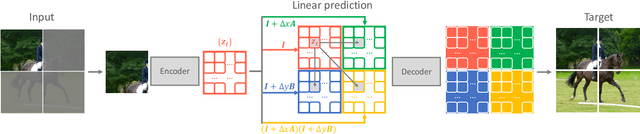
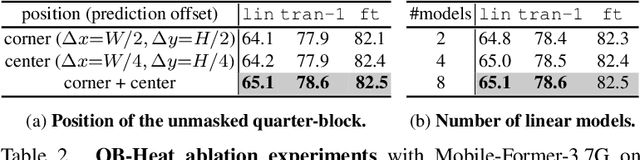
This paper presents a new perspective of self-supervised learning based on extending heat equation into high dimensional feature space. In particular, we remove time dependence by steady-state condition, and extend the remaining 2D Laplacian from x--y isotropic to linear correlated. Furthermore, we simplify it by splitting x and y axes as two first-order linear differential equations. Such simplification explicitly models the spatial invariance along horizontal and vertical directions separately, supporting prediction across image blocks. This introduces a very simple masked image modeling (MIM) method, named QB-Heat. QB-Heat leaves a single block with size of quarter image unmasked and extrapolates other three masked quarters linearly. It brings MIM to CNNs without bells and whistles, and even works well for pre-training light-weight networks that are suitable for both image classification and object detection without fine-tuning. Compared with MoCo-v2 on pre-training a Mobile-Former with 5.8M parameters and 285M FLOPs, QB-Heat is on par in linear probing on ImageNet, but clearly outperforms in non-linear probing that adds a transformer block before linear classifier (65.6% vs. 52.9%). When transferring to object detection with frozen backbone, QB-Heat outperforms MoCo-v2 and supervised pre-training on ImageNet by 7.9 and 4.5 AP respectively. This work provides an insightful hypothesis on the invariance within visual representation over different shapes and textures: the linear relationship between horizontal and vertical derivatives. The code will be publicly released.
Tangent Bundle Filters and Neural Networks: from Manifolds to Cellular Sheaves and Back
Nov 02, 2022
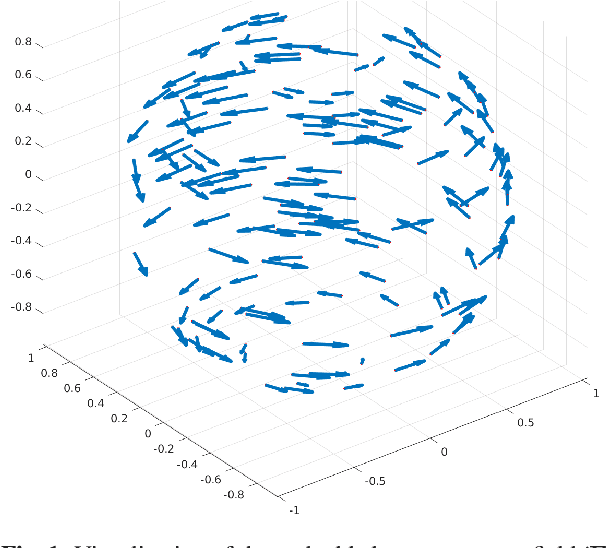
In this work we introduce a convolution operation over the tangent bundle of Riemannian manifolds exploiting the Connection Laplacian operator. We use the convolution to define tangent bundle filters and tangent bundle neural networks (TNNs), novel continuous architectures operating on tangent bundle signals, i.e. vector fields over manifolds. We discretize TNNs both in space and time domains, showing that their discrete counterpart is a principled variant of the recently introduced Sheaf Neural Networks. We formally prove that this discrete architecture converges to the underlying continuous TNN. We numerically evaluate the effectiveness of the proposed architecture on a denoising task of a tangent vector field over the unit 2-sphere.
eXplainable AI for Quantum Machine Learning
Nov 02, 2022

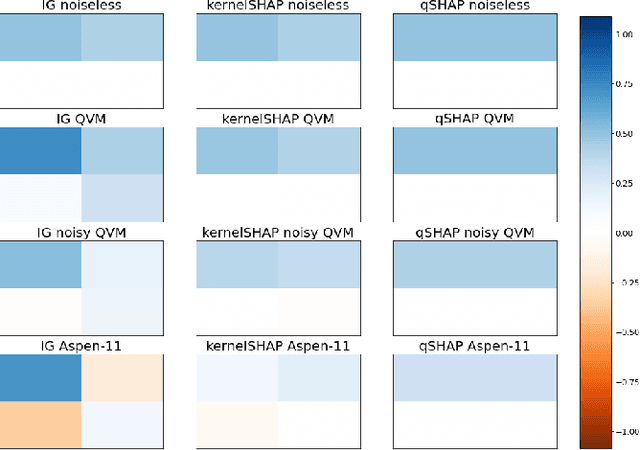

Parametrized Quantum Circuits (PQCs) enable a novel method for machine learning (ML). However, from a computational point of view they present a challenge to existing eXplainable AI (xAI) methods. On the one hand, measurements on quantum circuits introduce probabilistic errors which impact the convergence of these methods. On the other hand, the phase space of a quantum circuit expands exponentially with the number of qubits, complicating efforts to execute xAI methods in polynomial time. In this paper we will discuss the performance of established xAI methods, such as Baseline SHAP and Integrated Gradients. Using the internal mechanics of PQCs we study ways to speed up their computation.
DETRDistill: A Universal Knowledge Distillation Framework for DETR-families
Nov 21, 2022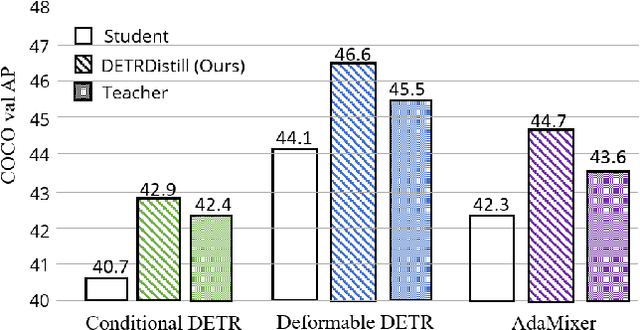
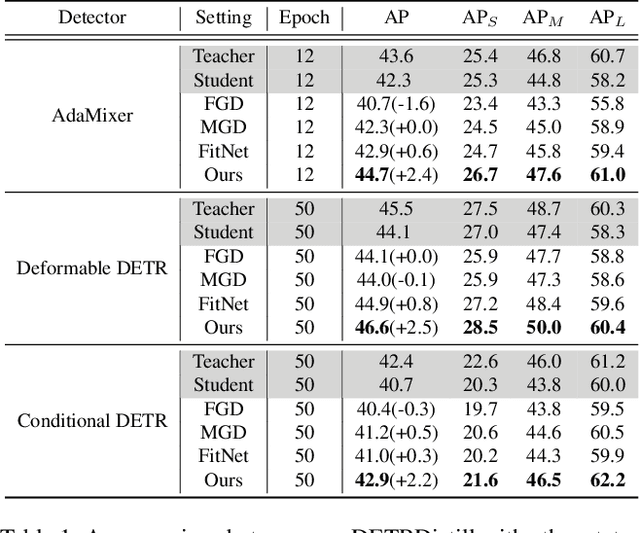

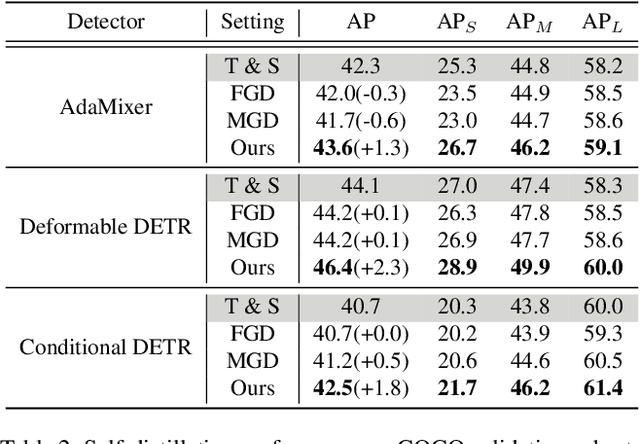
Transformer-based detectors (DETRs) have attracted great attention due to their sparse training paradigm and the removal of post-processing operations, but the huge model can be computationally time-consuming and difficult to be deployed in real-world applications. To tackle this problem, knowledge distillation (KD) can be employed to compress the huge model by constructing a universal teacher-student learning framework. Different from the traditional CNN detectors, where the distillation targets can be naturally aligned through the feature map, DETR regards object detection as a set prediction problem, leading to an unclear relationship between teacher and student during distillation. In this paper, we propose DETRDistill, a novel knowledge distillation dedicated to DETR-families. We first explore a sparse matching paradigm with progressive stage-by-stage instance distillation. Considering the diverse attention mechanisms adopted in different DETRs, we propose attention-agnostic feature distillation module to overcome the ineffectiveness of conventional feature imitation. Finally, to fully leverage the intermediate products from the teacher, we introduce teacher-assisted assignment distillation, which uses the teacher's object queries and assignment results for a group with additional guidance. Extensive experiments demonstrate that our distillation method achieves significant improvement on various competitive DETR approaches, without introducing extra consumption in the inference phase. To the best of our knowledge, this is the first systematic study to explore a general distillation method for DETR-style detectors.
Teaching Structured Vision&Language Concepts to Vision&Language Models
Nov 21, 2022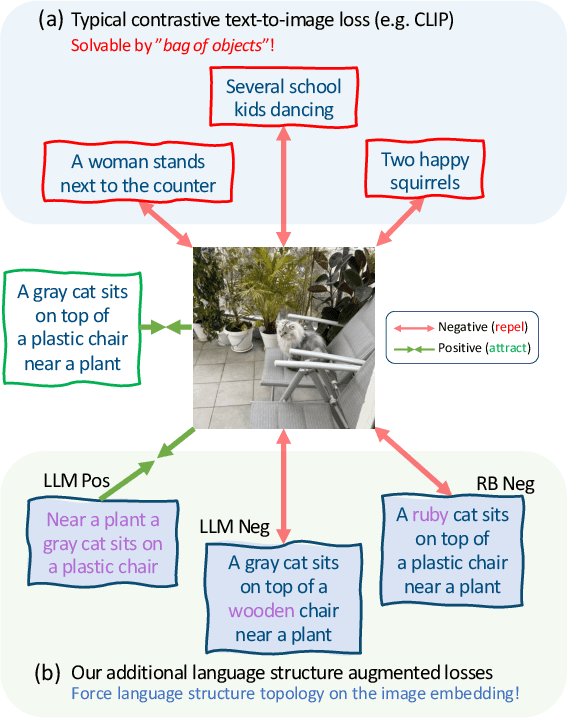
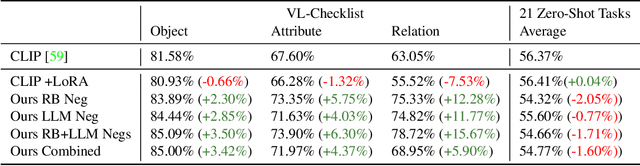
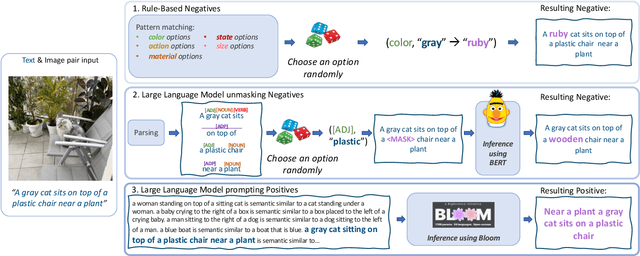

Vision and Language (VL) models have demonstrated remarkable zero-shot performance in a variety of tasks. However, some aspects of complex language understanding still remain a challenge. We introduce the collective notion of Structured Vision&Language Concepts (SVLC) which includes object attributes, relations, and states which are present in the text and visible in the image. Recent studies have shown that even the best VL models struggle with SVLC. A possible way of fixing this issue is by collecting dedicated datasets for teaching each SVLC type, yet this might be expensive and time-consuming. Instead, we propose a more elegant data-driven approach for enhancing VL models' understanding of SVLCs that makes more effective use of existing VL pre-training datasets and does not require any additional data. While automatic understanding of image structure still remains largely unsolved, language structure is much better modeled and understood, allowing for its effective utilization in teaching VL models. In this paper, we propose various techniques based on language structure understanding that can be used to manipulate the textual part of off-the-shelf paired VL datasets. VL models trained with the updated data exhibit a significant improvement of up to 15% in their SVLC understanding with only a mild degradation in their zero-shot capabilities both when training from scratch or fine-tuning a pre-trained model.
Visual Dexterity: In-hand Dexterous Manipulation from Depth
Nov 21, 2022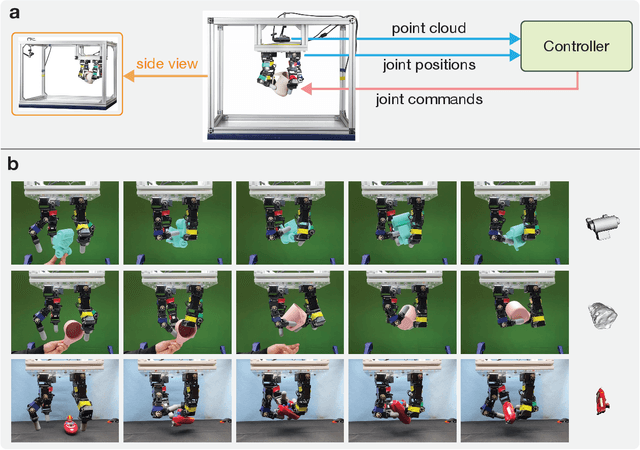
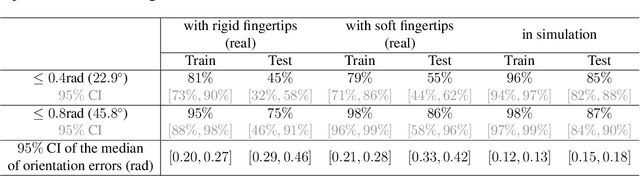

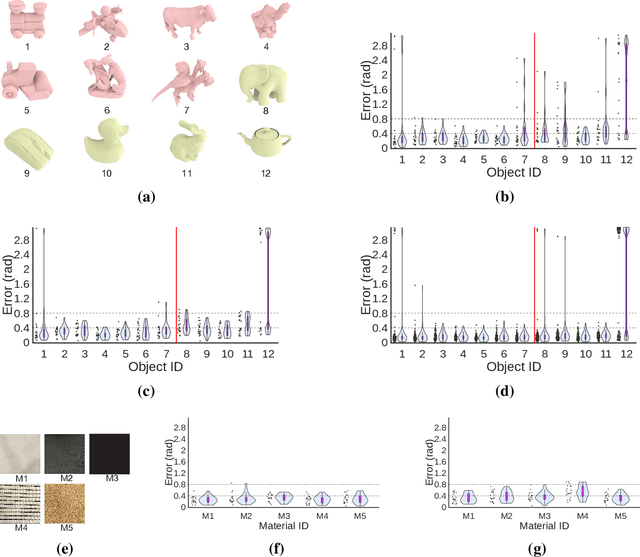
In-hand object reorientation is necessary for performing many dexterous manipulation tasks, such as tool use in unstructured environments that remain beyond the reach of current robots. Prior works built reorientation systems that assume one or many of the following specific circumstances: reorienting only specific objects with simple shapes, limited range of reorientation, slow or quasistatic manipulation, the need for specialized and costly sensor suites, simulation-only results, and other constraints which make the system infeasible for real-world deployment. We overcome these limitations and present a general object reorientation controller that is trained using reinforcement learning in simulation and evaluated in the real world. Our system uses readings from a single commodity depth camera to dynamically reorient complex objects by any amount in real time. The controller generalizes to novel objects not used during training. It is successful in the most challenging test: the ability to reorient objects in the air held by a downward-facing hand that must counteract gravity during reorientation. The results demonstrate that the policy transfer from simulation to the real world can be accomplished even for dynamic and contact-rich tasks. Lastly, our hardware only uses open-source components that cost less than five thousand dollars. Such construction makes it possible to replicate the work and democratize future research in dexterous manipulation. Videos are available at: https://taochenshh.github.io/projects/visual-dexterity.