 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient HLA imputation from sequential SNPs data by Transformer
Nov 11, 2022
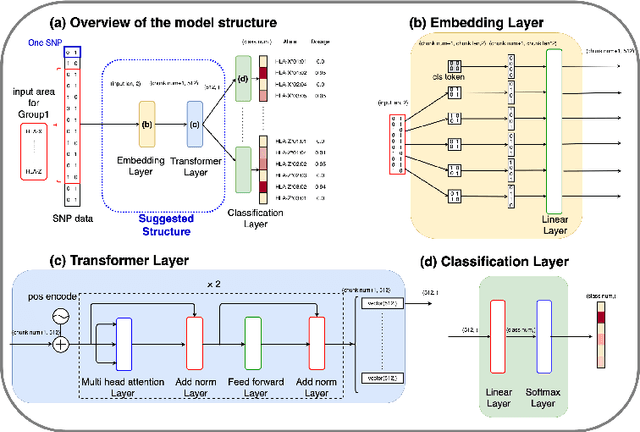
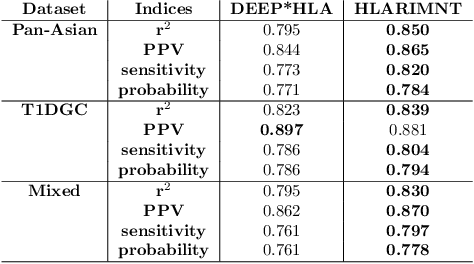
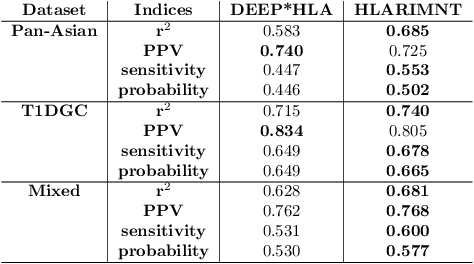
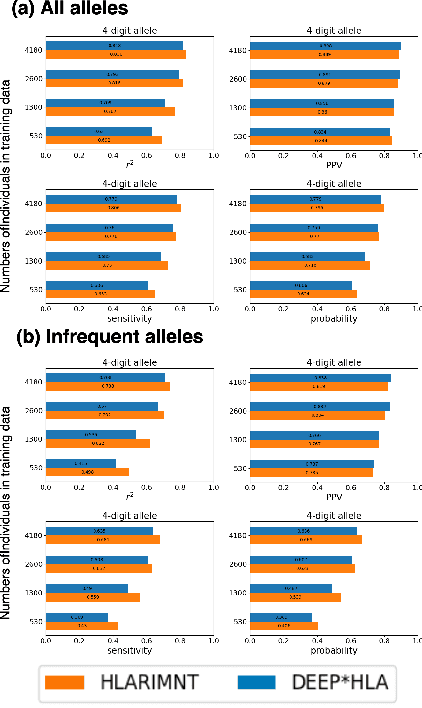
Human leukocyte antigen (HLA) genes are associated with a variety of diseases, however direct typing of HLA is time and cost consuming. Thus various imputation methods using sequential SNPs data have been proposed based on statistical or deep learning models, e.g. CNN-based model, named DEEP*HLA. However, imputation efficiency is not sufficient for in frequent alleles and a large size of reference panel is required. Here, we developed a Transformer-based model to impute HLA alleles, named "HLA Reliable IMputatioN by Transformer (HLARIMNT)" to take advantage of sequential nature of SNPs data. We validated the performance of HLARIMNT using two different reference panels; Pan-Asian reference panel (n = 530) and Type 1 Diabetes Genetics Consortium (T1DGC) reference panel (n = 5,225), as well as the mixture of those two panels (n = 1,060). HLARIMNT achieved higher accuracy than DEEP*HLA by several indices, especially for infrequent alleles. We also varied the size of data used for training, and HLARIMNT imputed more accurately among any size of training data. These results suggest that Transformer-based model may impute efficiently not only HLA types but also any other gene types from sequential SNPs data.
Over-the-Air Consensus for Distributed Vehicle Platooning Control (Extended version)
Nov 11, 2022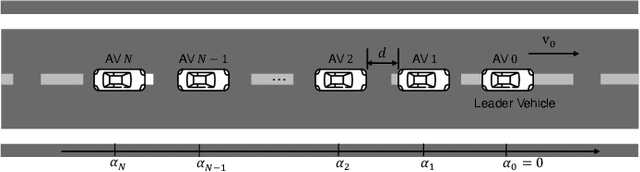
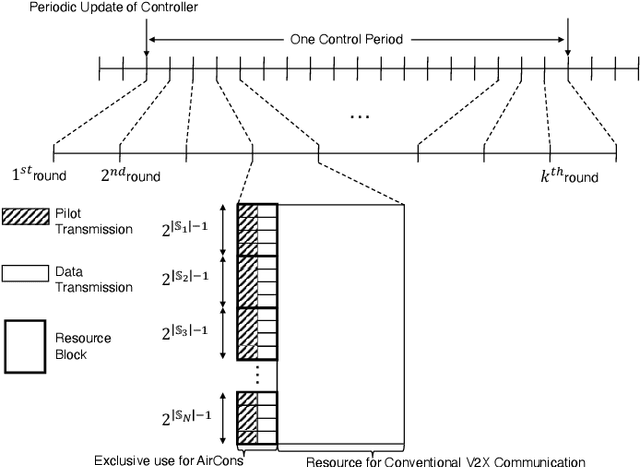
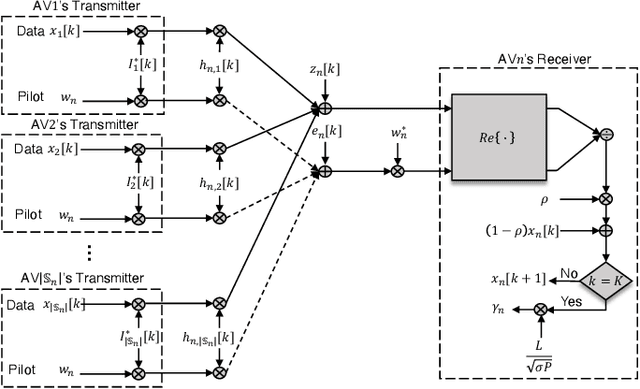
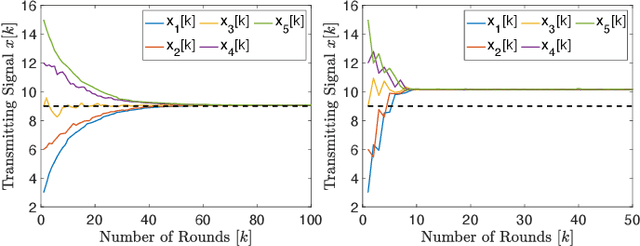
A distributed control of vehicle platooning is referred to as distributed consensus (DC) since many autonomous vehicles (AVs) reach a consensus to move as one body with the same velocity and inter-distance. For DC control to be stable, other AVs' real-time position information should be inputted to each AV's controller via vehicle-to-vehicle (V2V) communications. On the other hand, too many V2V links should be simultaneously established and frequently retrained, causing frequent packet loss and longer communication latency. We propose a novel DC algorithm called over-the-air consensus (AirCons), a joint communication-and-control design with two key features to overcome the above limitations. First, exploiting a wireless signal's superposition and broadcasting properties renders all AVs' signals to converge to a specific value proportional to participating AVs' average position without individual V2V channel information. Second, the estimated average position is used to control each AV's dynamics instead of each AV's individual position. Through analytic and numerical studies, the effectiveness of the proposed AirCons designed on the state-of-the-art New Radio architecture is verified by showing a $14.22\%$ control gain compared to the benchmark without the average position.
Palm Vein Recognition via Multi-task Loss Function and Attention Layer
Nov 11, 2022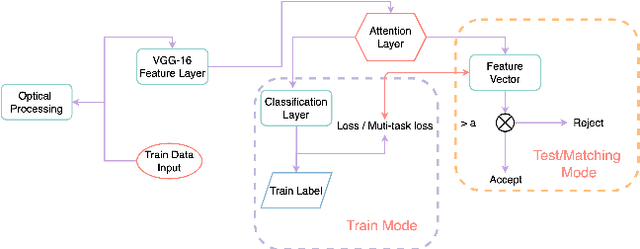
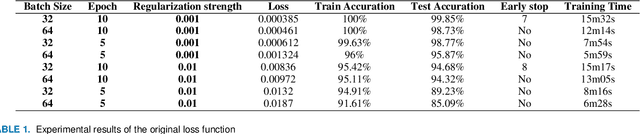
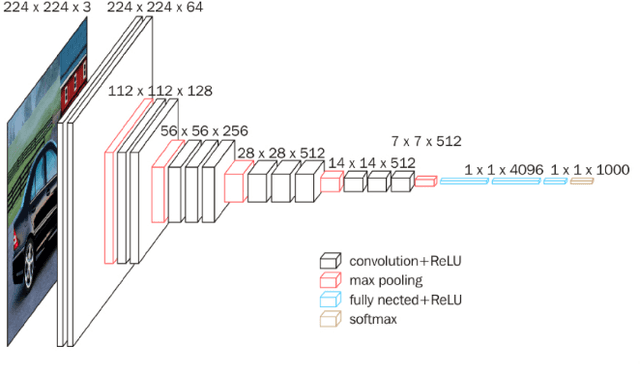

With the improvement of arithmetic power and algorithm accuracy of personal devices, biological features are increasingly widely used in personal identification, and palm vein recognition has rich extractable features and has been widely studied in recent years. However, traditional recognition methods are poorly robust and susceptible to environmental influences such as reflections and noise. In this paper, a convolutional neural network based on VGG-16 transfer learning fused attention mechanism is used as the feature extraction network on the infrared palm vein dataset. The palm vein classification task is first trained using palmprint classification methods, followed by matching using a similarity function, in which we propose the multi-task loss function to improve the accuracy of the matching task. In order to verify the robustness of the model, some experiments were carried out on datasets from different sources. Then, we used K-means clustering to determine the adaptive matching threshold and finally achieved an accuracy rate of 98.89% on prediction set. At the same time, the matching is with high efficiency which takes an average of 0.13 seconds per palm vein pair, and that means our method can be adopted in practice.
Using U-Net Network for Efficient Brain Tumor Segmentation in MRI Images
Nov 03, 2022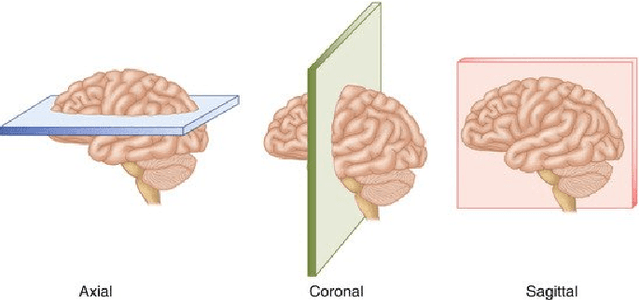
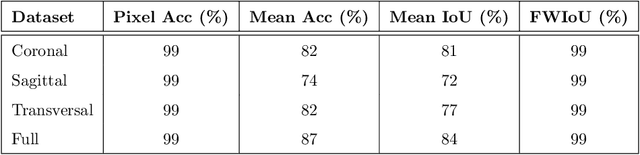
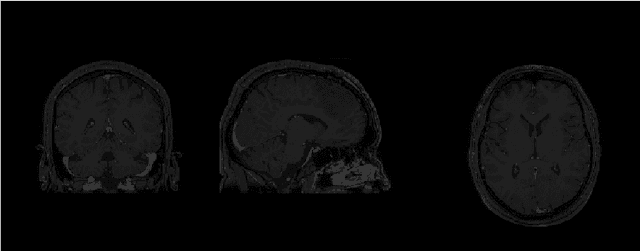
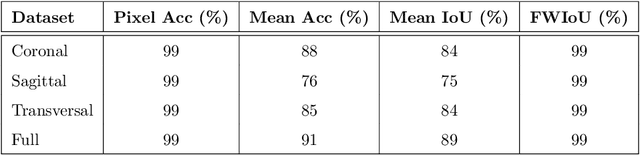
Magnetic Resonance Imaging (MRI) is the most commonly used non-intrusive technique for medical image acquisition. Brain tumor segmentation is the process of algorithmically identifying tumors in brain MRI scans. While many approaches have been proposed in the literature for brain tumor segmentation, this paper proposes a lightweight implementation of U-Net. Apart from providing real-time segmentation of MRI scans, the proposed architecture does not need large amount of data to train the proposed lightweight U-Net. Moreover, no additional data augmentation step is required. The lightweight U-Net shows very promising results on BITE dataset and it achieves a mean intersection-over-union (IoU) of 89% while outperforming the standard benchmark algorithms. Additionally, this work demonstrates an effective use of the three perspective planes, instead of the original three-dimensional volumetric images, for simplified brain tumor segmentation.
Estimating the Carbon Footprint of BLOOM, a 176B Parameter Language Model
Nov 03, 2022


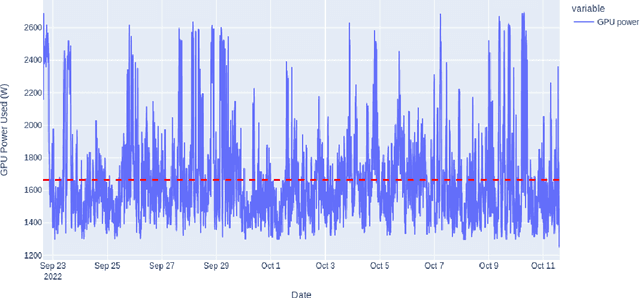
Progress in machine learning (ML) comes with a cost to the environment, given that training ML models requires significant computational resources, energy and materials. In the present article, we aim to quantify the carbon footprint of BLOOM, a 176-billion parameter language model, across its life cycle. We estimate that BLOOM's final training emitted approximately 24.7 tonnes of~\carboneq~if we consider only the dynamic power consumption, and 50.5 tonnes if we account for all processes ranging from equipment manufacturing to energy-based operational consumption. We also study the energy requirements and carbon emissions of its deployment for inference via an API endpoint receiving user queries in real-time. We conclude with a discussion regarding the difficulty of precisely estimating the carbon footprint of ML models and future research directions that can contribute towards improving carbon emissions reporting.
When to Laugh and How Hard? A Multimodal Approach to Detecting Humor and its Intensity
Nov 03, 2022


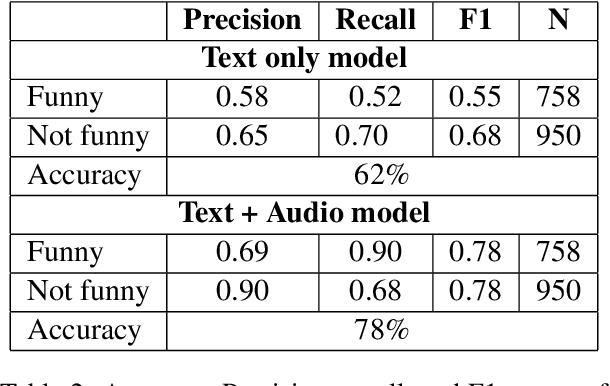
Prerecorded laughter accompanying dialog in comedy TV shows encourages the audience to laugh by clearly marking humorous moments in the show. We present an approach for automatically detecting humor in the Friends TV show using multimodal data. Our model is capable of recognizing whether an utterance is humorous or not and assess the intensity of it. We use the prerecorded laughter in the show as annotation as it marks humor and the length of the audience's laughter tells us how funny a given joke is. We evaluate the model on episodes the model has not been exposed to during the training phase. Our results show that the model is capable of correctly detecting whether an utterance is humorous 78% of the time and how long the audience's laughter reaction should last with a mean absolute error of 600 milliseconds.
Benchmarking local motion planners for navigation of mobile manipulators
Nov 03, 2022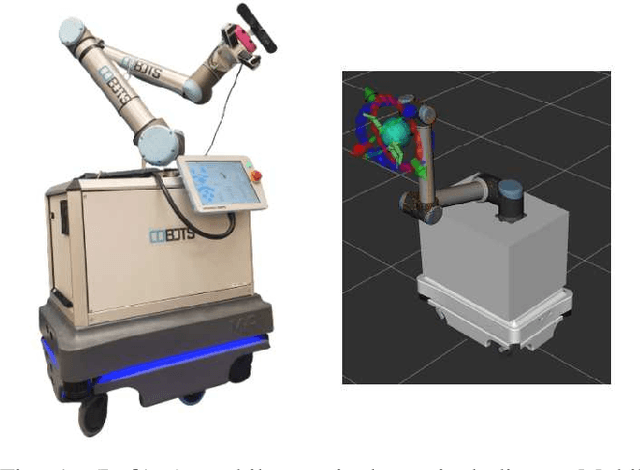

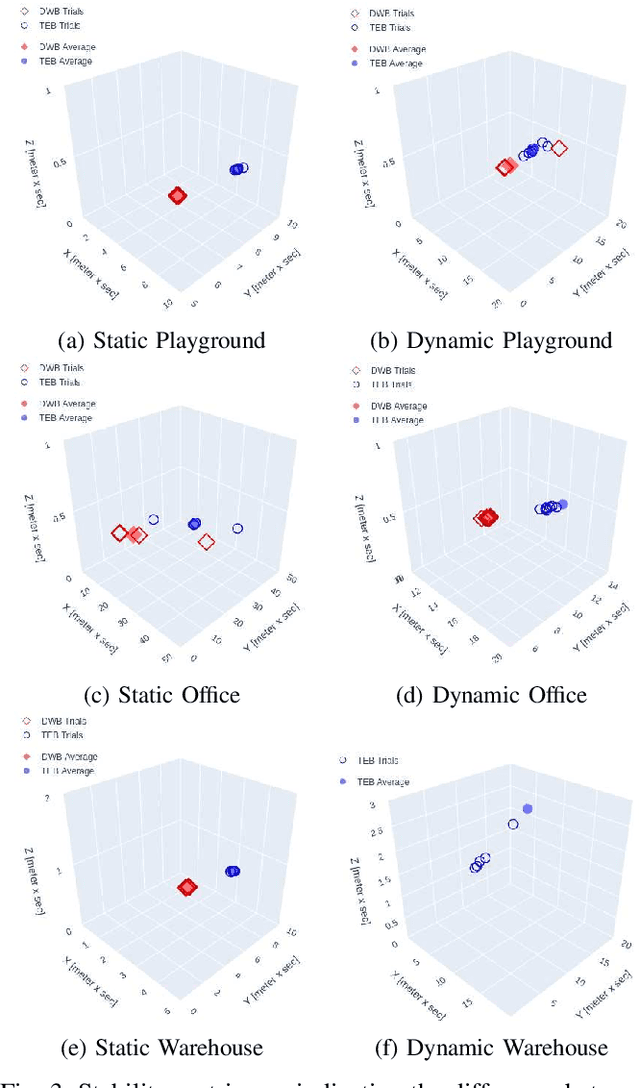
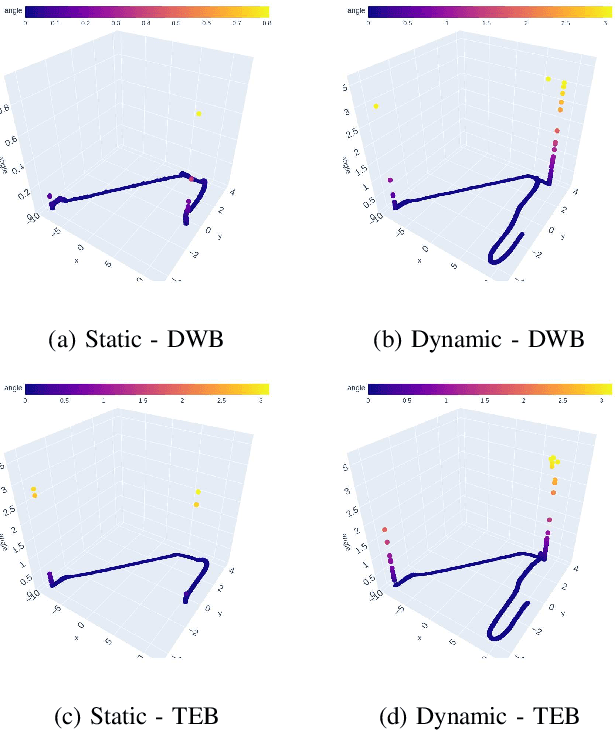
There are various trajectory planners for mobile manipulators. It is often challenging to compare their performance under similar circumstances due to differences in hardware, dissimilarity of tasks and objectives, as well as uncertainties in measurements and operating environments. In this paper, we propose a simulation framework to evaluate the performance of the local trajectory planners to generate smooth, and dynamically and kinematically feasible trajectories for mobile manipulators in the same environment. We focus on local planners as they are key components that provide smooth trajectories while carrying a load, react to dynamic obstacles, and avoid collisions. We evaluate two prominent local trajectory planners, Dynamic-Window Approach (DWA) and Time Elastic Band (TEB) using the metrics that we introduce. Moreover, our software solution is applicable to any other local planners used in the Robot Operating System (ROS) framework, without additional programming effort.
Maintaining AUC and $H$-measure over time
Dec 12, 2021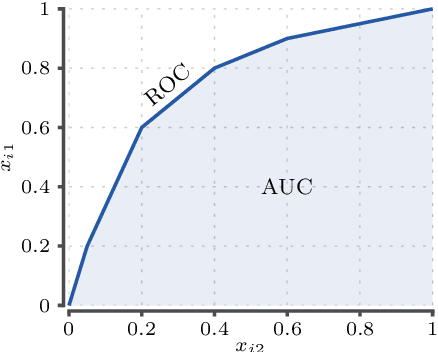

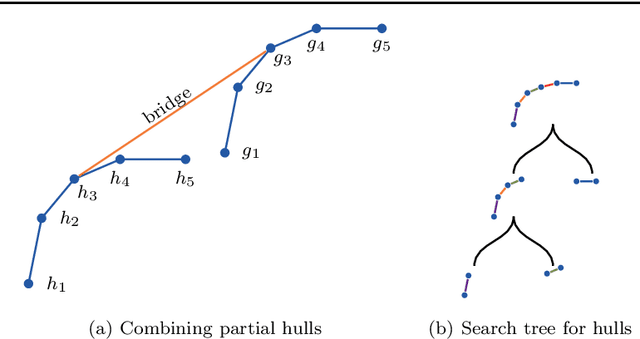
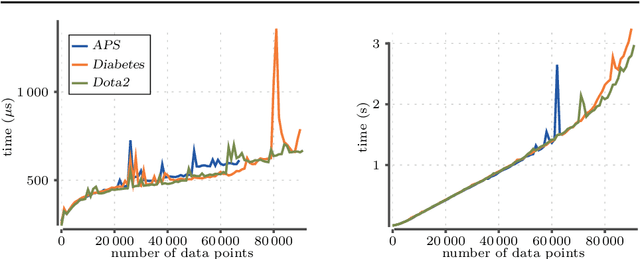
Measuring the performance of a classifier is a vital task in machine learning. The running time of an algorithm that computes the measure plays a very small role in an offline setting, for example, when the classifier is being developed by a researcher. However, the running time becomes more crucial if our goal is to monitor the performance of a classifier over time. In this paper we study three algorithms for maintaining two measures. The first algorithm maintains area under the ROC curve (AUC) under addition and deletion of data points in $O(\log n)$ time. This is done by maintaining the data points sorted in a self-balanced search tree. In addition, we augment the search tree that allows us to query the ROC coordinates of a data point in $O(\log n)$ time. In doing so we are able to maintain AUC in $O(\log n)$ time. Our next two algorithms involve in maintaining $H$-measure, an alternative measure based on the ROC curve. Computing the measure is a two-step process: first we need to compute a convex hull of the ROC curve, followed by a sum over the convex hull. We demonstrate that we can maintain the convex hull using a minor modification of the classic convex hull maintenance algorithm. We then show that under certain conditions, we can compute the $H$-measure exactly in $O(\log^2 n)$ time, and if the conditions are not met, then we can estimate the $H$-measure in $O((\log n + \epsilon^{-1})\log n)$ time. We show empirically that our methods are significantly faster than the baselines.
Solving 3D Inverse Problems using Pre-trained 2D Diffusion Models
Nov 19, 2022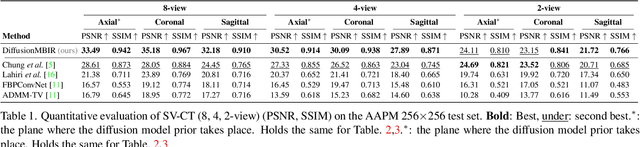
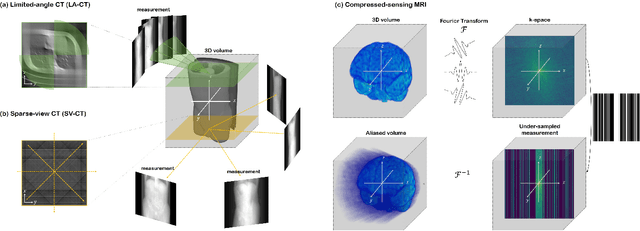
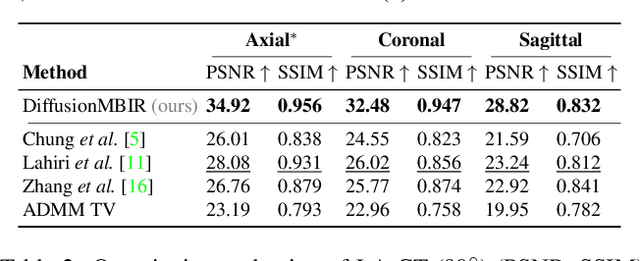
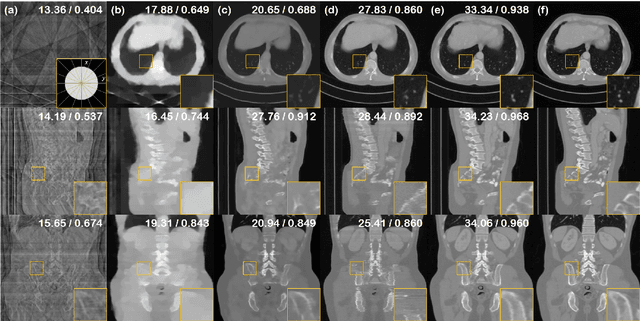
Diffusion models have emerged as the new state-of-the-art generative model with high quality samples, with intriguing properties such as mode coverage and high flexibility. They have also been shown to be effective inverse problem solvers, acting as the prior of the distribution, while the information of the forward model can be granted at the sampling stage. Nonetheless, as the generative process remains in the same high dimensional (i.e. identical to data dimension) space, the models have not been extended to 3D inverse problems due to the extremely high memory and computational cost. In this paper, we combine the ideas from the conventional model-based iterative reconstruction with the modern diffusion models, which leads to a highly effective method for solving 3D medical image reconstruction tasks such as sparse-view tomography, limited angle tomography, compressed sensing MRI from pre-trained 2D diffusion models. In essence, we propose to augment the 2D diffusion prior with a model-based prior in the remaining direction at test time, such that one can achieve coherent reconstructions across all dimensions. Our method can be run in a single commodity GPU, and establishes the new state-of-the-art, showing that the proposed method can perform reconstructions of high fidelity and accuracy even in the most extreme cases (e.g. 2-view 3D tomography). We further reveal that the generalization capacity of the proposed method is surprisingly high, and can be used to reconstruct volumes that are entirely different from the training dataset.
On the Multidimensional Augmentation of Fingerprint Data for Indoor Localization in A Large-Scale Building Complex Based on Multi-Output Gaussian Process
Nov 19, 2022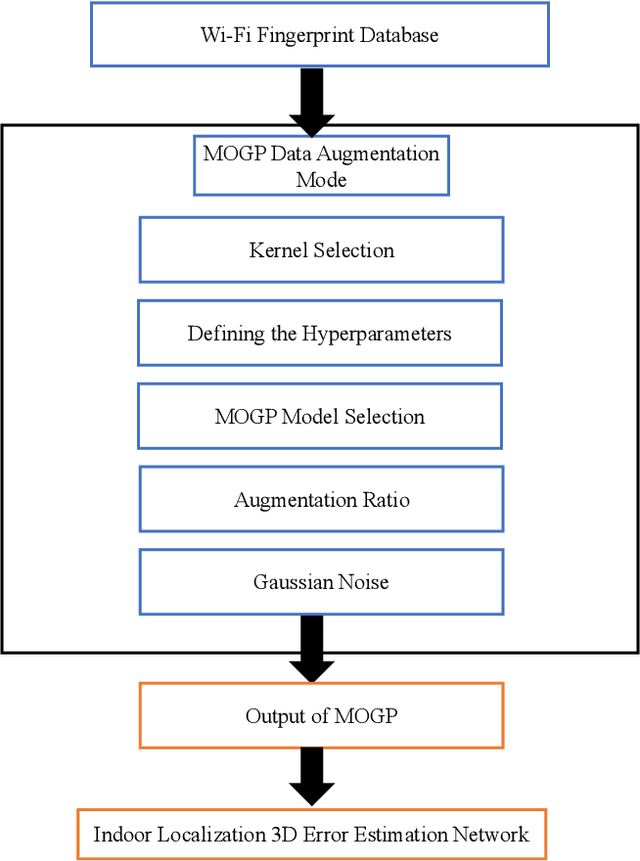
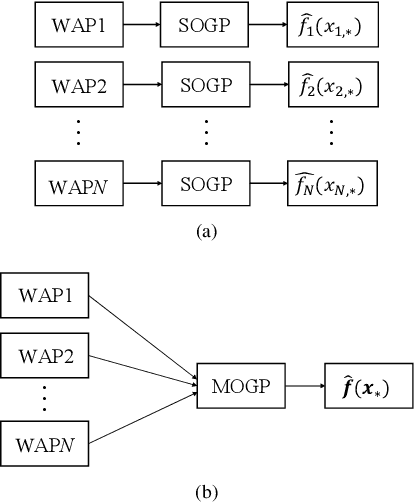
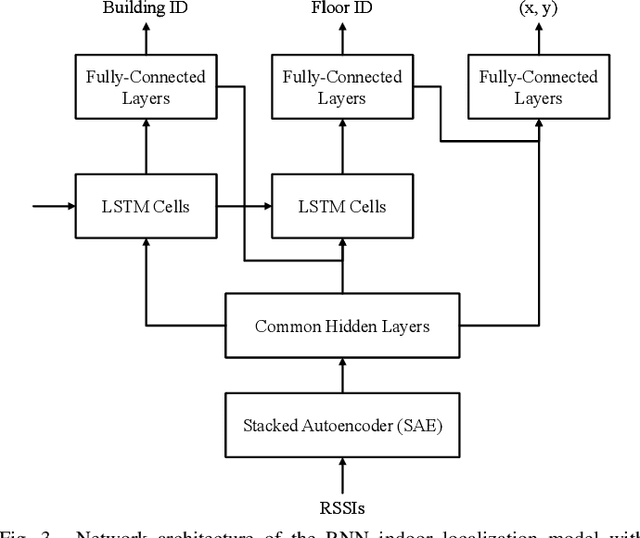
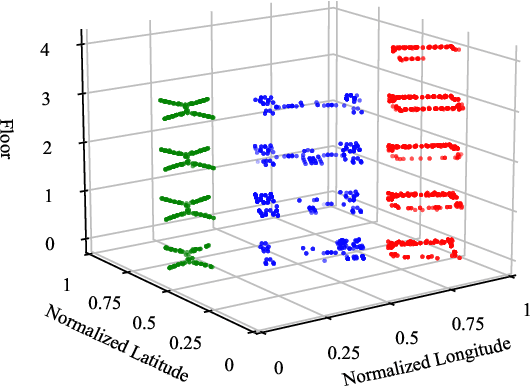
Wi-Fi fingerprinting becomes a dominant solution for large-scale indoor localization due to its major advantage of not requiring new infrastructure and dedicated devices. The number and the distribution of Reference Points (RPs) for the measurement of localization fingerprints like RSSI during the offline phase, however, greatly affects the localization accuracy; for instance, the UJIIndoorLoc is known to have the issue of uneven spatial distribution of RPs over buildings and floors. Data augmentation has been proposed as a feasible solution to not only improve the smaller number and the uneven distribution of RPs in the existing fingerprint databases but also reduce the labor and time costs of constructing new fingerprint databases. In this paper, we propose the multidimensional augmentation of fingerprint data for indoor localization in a large-scale building complex based on Multi-Output Gaussian Process (MOGP) and systematically investigate the impact of augmentation ratio as well as MOGP kernel functions and models with their hyperparameters on the performance of indoor localization using the UJIIndoorLoc database and the state-of-the-art neural network indoor localization model based on a hierarchical RNN. The investigation based on experimental results suggests that we can generate synthetic RSSI fingerprint data up to ten times the original data -- i.e., the augmentation ratio of 10 -- through the proposed multidimensional MOGP-based data augmentation without significantly affecting the indoor localization performance compared to that of the original data alone, which extends the spatial coverage of the combined RPs and thereby could improve the localization performance at the locations that are not part of the test dataset.