 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Video Background Music Generation: Dataset, Method and Evaluation
Nov 21, 2022
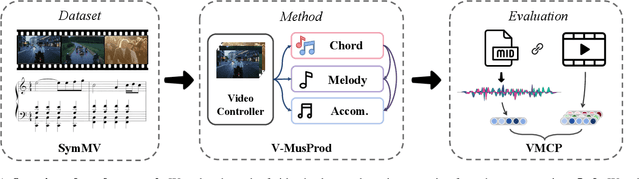
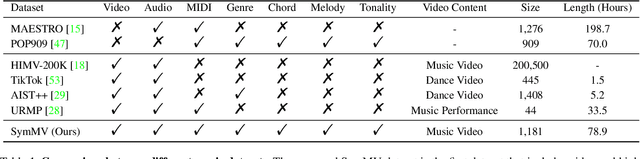

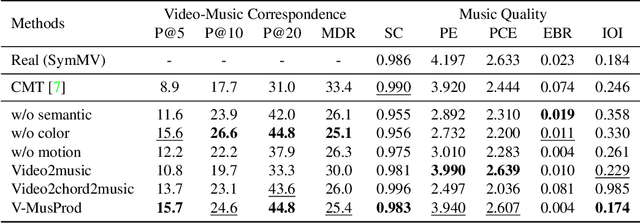
Music is essential when editing videos, but selecting music manually is difficult and time-consuming. Thus, we seek to automatically generate background music tracks given video input. This is a challenging task since it requires plenty of paired videos and music to learn their correspondence. Unfortunately, there exist no such datasets. To close this gap, we introduce a dataset, benchmark model, and evaluation metric for video background music generation. We introduce SymMV, a video and symbolic music dataset, along with chord, rhythm, melody, and accompaniment annotations. To the best of our knowledge, it is the first video-music dataset with high-quality symbolic music and detailed annotations. We also propose a benchmark video background music generation framework named V-MusProd, which utilizes music priors of chords, melody, and accompaniment along with video-music relations of semantic, color, and motion features. To address the lack of objective metrics for video-music correspondence, we propose a retrieval-based metric VMCP built upon a powerful video-music representation learning model. Experiments show that with our dataset, V-MusProd outperforms the state-of-the-art method in both music quality and correspondence with videos. We believe our dataset, benchmark model, and evaluation metric will boost the development of video background music generation.
From Traditional Adaptive Data Caching to Adaptive Context Caching: A Survey
Nov 21, 2022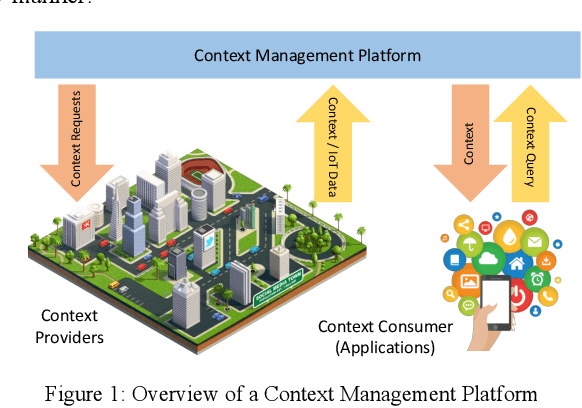
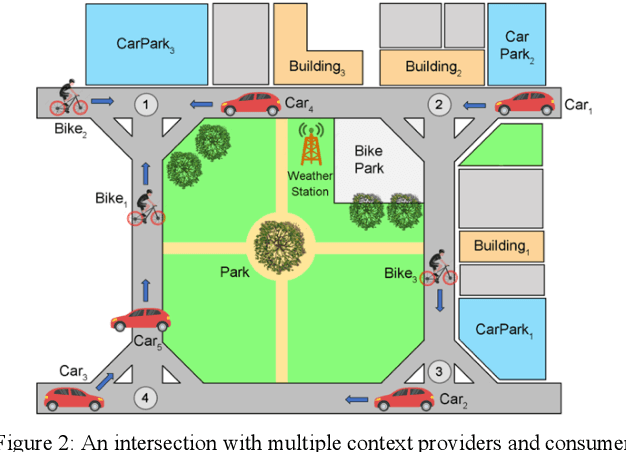
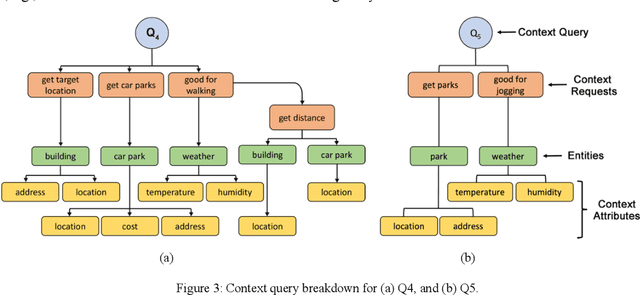
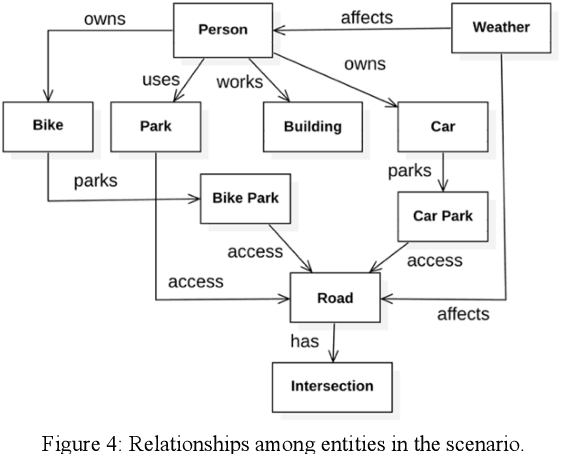
Context data is in demand more than ever with the rapid increase in the development of many context-aware Internet of Things applications. Research in context and context-awareness is being conducted to broaden its applicability in light of many practical and technical challenges. One of the challenges is improving performance when responding to large number of context queries. Context Management Platforms that infer and deliver context to applications measure this problem using Quality of Service (QoS) parameters. Although caching is a proven way to improve QoS, transiency of context and features such as variability, heterogeneity of context queries pose an additional real-time cost management problem. This paper presents a critical survey of state-of-the-art in adaptive data caching with the objective of developing a body of knowledge in cost- and performance-efficient adaptive caching strategies. We comprehensively survey a large number of research publications and evaluate, compare, and contrast different techniques, policies, approaches, and schemes in adaptive caching. Our critical analysis is motivated by the focus on adaptively caching context as a core research problem. A formal definition for adaptive context caching is then proposed, followed by identified features and requirements of a well-designed, objective optimal adaptive context caching strategy.
FPGA Implementation of An Event-driven Saliency-based Selective Attention Model
Nov 25, 2022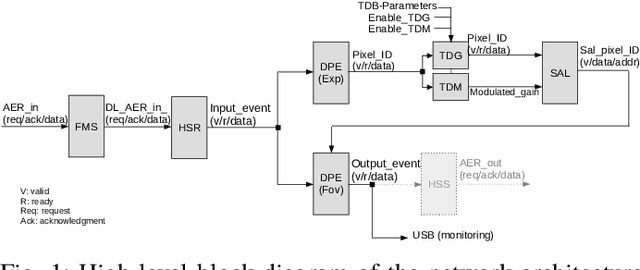
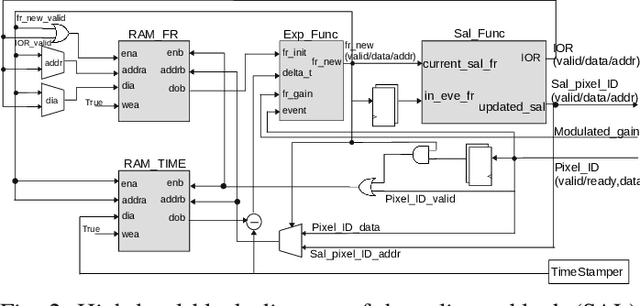
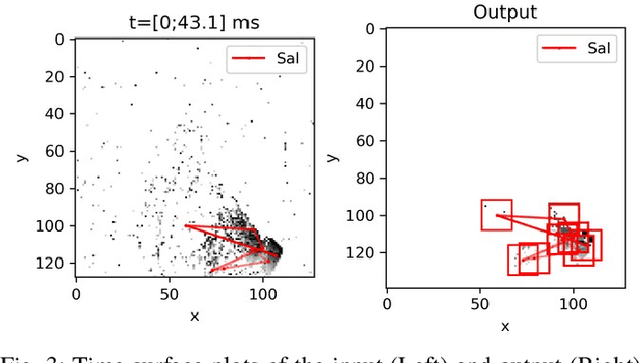
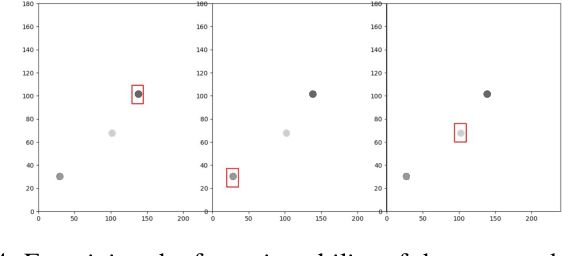
Artificial vision systems of autonomous agents face very difficult challenges, as their vision sensors are required to transmit vast amounts of information to the processing stages, and to process it in real-time. One first approach to reduce data transmission is to use event-based vision sensors, whose pixels produce events only when there are changes in the input. However, even for event-based vision, transmission and processing of visual data can be quite onerous. Currently, these challenges are solved by using high-speed communication links and powerful machine vision processing hardware. But if resources are limited, instead of processing all the sensory information in parallel, an effective strategy is to divide the visual field into several small sub-regions, choose the region of highest saliency, process it, and shift serially the focus of attention to regions of decreasing saliency. This strategy, commonly used also by the visual system of many animals, is typically referred to as ``selective attention''. Here we present a digital architecture implementing a saliency-based selective visual attention model for processing asynchronous event-based sensory information received from a DVS. For ease of prototyping, we use a standard digital design flow and map the architecture on an FPGA. We describe the architecture block diagram highlighting the efficient use of the available hardware resources demonstrated through experimental results exploiting a hardware setup where the FPGA interfaced with the DVS camera.
Learning General Audio Representations with Large-Scale Training of Patchout Audio Transformers
Nov 25, 2022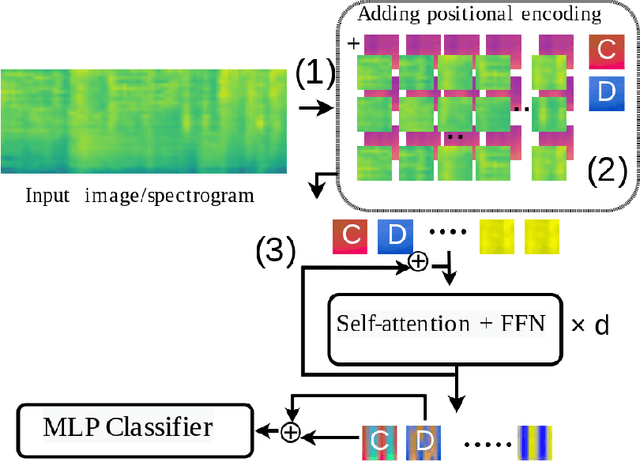
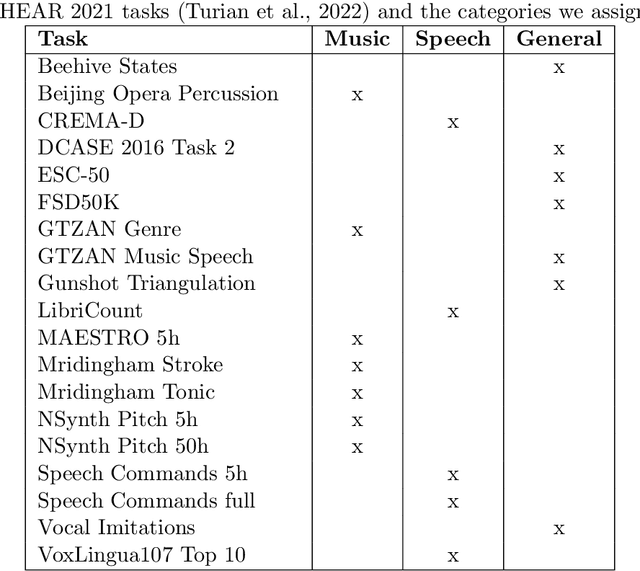
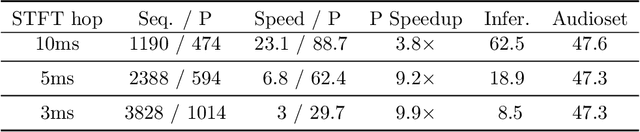
The success of supervised deep learning methods is largely due to their ability to learn relevant features from raw data. Deep Neural Networks (DNNs) trained on large-scale datasets are capable of capturing a diverse set of features, and learning a representation that can generalize onto unseen tasks and datasets that are from the same domain. Hence, these models can be used as powerful feature extractors, in combination with shallower models as classifiers, for smaller tasks and datasets where the amount of training data is insufficient for learning an end-to-end model from scratch. During the past years, Convolutional Neural Networks (CNNs) have largely been the method of choice for audio processing. However, recently attention-based transformer models have demonstrated great potential in supervised settings, outperforming CNNs. In this work, we investigate the use of audio transformers trained on large-scale datasets to learn general-purpose representations. We study how the different setups in these audio transformers affect the quality of their embeddings. We experiment with the models' time resolution, extracted embedding level, and receptive fields in order to see how they affect performance on a variety of tasks and datasets, following the HEAR 2021 NeurIPS challenge evaluation setup. Our results show that representations extracted by audio transformers outperform CNN representations. Furthermore, we will show that transformers trained on Audioset can be extremely effective representation extractors for a wide range of downstream tasks.
SCOOP: Self-Supervised Correspondence and Optimization-Based Scene Flow
Nov 25, 2022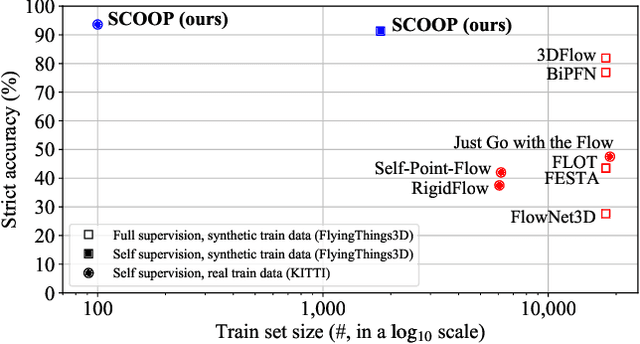
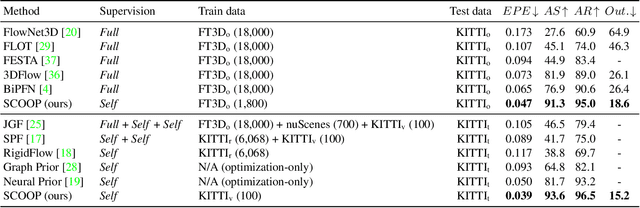


Scene flow estimation is a long-standing problem in computer vision, where the goal is to find the 3D motion of a scene from its consecutive observations. Recently, there have been efforts to compute the scene flow from 3D point clouds. A common approach is to train a regression model that consumes source and target point clouds and outputs the per-point translation vectors. An alternative is to learn point matches between the point clouds concurrently with regressing a refinement of the initial correspondence flow. In both cases, the learning task is very challenging since the flow regression is done in the free 3D space, and a typical solution is to resort to a large annotated synthetic dataset. We introduce SCOOP, a new method for scene flow estimation that can be learned on a small amount of data without employing ground-truth flow supervision. In contrast to previous work, we train a pure correspondence model focused on learning point feature representation and initialize the flow as the difference between a source point and its softly corresponding target point. Then, in the run-time phase, we directly optimize a flow refinement component with a self-supervised objective, which leads to a coherent and accurate flow field between the point clouds. Experiments on widespread datasets demonstrate the performance gains achieved by our method compared to existing leading techniques while using a fraction of the training data. Our code is publicly available at https://github.com/itailang/SCOOP.
Real-time Hyperspectral Imaging in Hardware via Trained Metasurface Encoders
Apr 05, 2022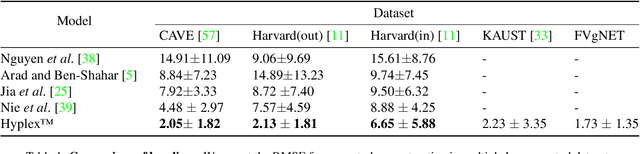

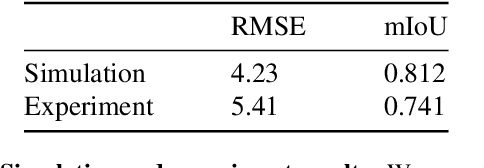
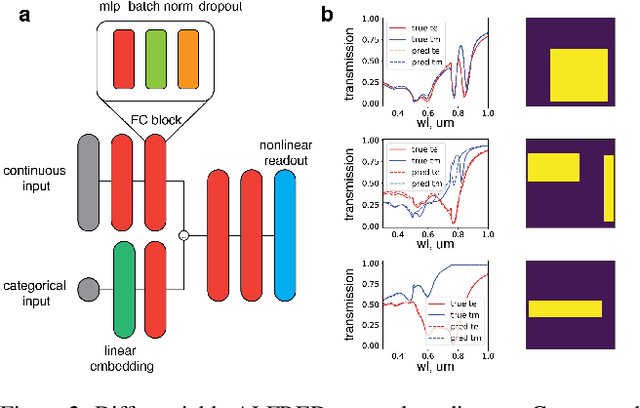
Hyperspectral imaging has attracted significant attention to identify spectral signatures for image classification and automated pattern recognition in computer vision. State-of-the-art implementations of snapshot hyperspectral imaging rely on bulky, non-integrated, and expensive optical elements, including lenses, spectrometers, and filters. These macroscopic components do not allow fast data processing for, e.g real-time and high-resolution videos. This work introduces Hyplex, a new integrated architecture addressing the limitations discussed above. Hyplex is a CMOS-compatible, fast hyperspectral camera that replaces bulk optics with nanoscale metasurfaces inversely designed through artificial intelligence. Hyplex does not require spectrometers but makes use of conventional monochrome cameras, opening up the possibility for real-time and high-resolution hyperspectral imaging at inexpensive costs. Hyplex exploits a model-driven optimization, which connects the physical metasurfaces layer with modern visual computing approaches based on end-to-end training. We design and implement a prototype version of Hyplex and compare its performance against the state-of-the-art for typical imaging tasks such as spectral reconstruction and semantic segmentation. In all benchmarks, Hyplex reports the smallest reconstruction error. We additionally present what is, to the best of our knowledge, the largest publicly available labeled hyperspectral dataset for semantic segmentation.
Gradient Descent and the Power Method: Exploiting their connection to find the leftmost eigen-pair and escape saddle points
Nov 02, 2022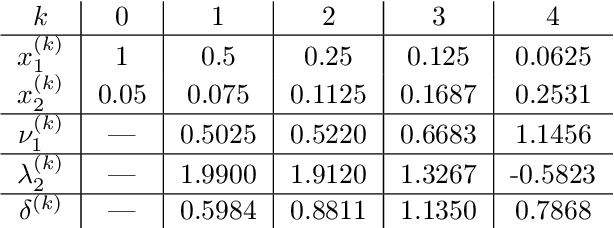
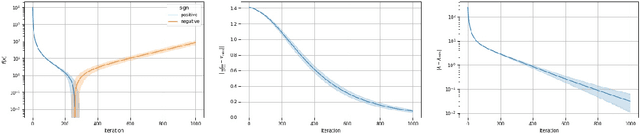
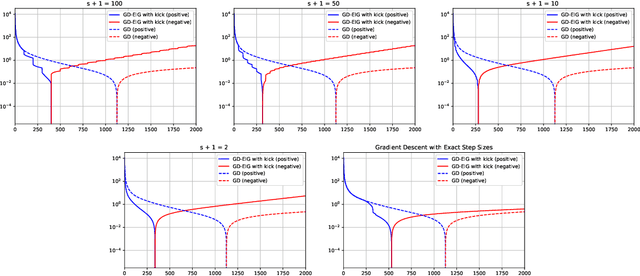
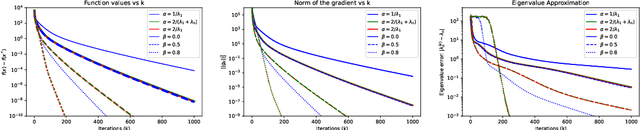
This work shows that applying Gradient Descent (GD) with a fixed step size to minimize a (possibly nonconvex) quadratic function is equivalent to running the Power Method (PM) on the gradients. The connection between GD with a fixed step size and the PM, both with and without fixed momentum, is thus established. Consequently, valuable eigen-information is available via GD. Recent examples show that GD with a fixed step size, applied to locally quadratic nonconvex functions, can take exponential time to escape saddle points (Simon S. Du, Chi Jin, Jason D. Lee, Michael I. Jordan, Aarti Singh, and Barnabas Poczos: "Gradient descent can take exponential time to escape saddle points"; S. Paternain, A. Mokhtari, and A. Ribeiro: "A newton-based method for nonconvex optimization with fast evasion of saddle points"). Here, those examples are revisited and it is shown that eigenvalue information was missing, so that the examples may not provide a complete picture of the potential practical behaviour of GD. Thus, ongoing investigation of the behaviour of GD on nonconvex functions, possibly with an \emph{adaptive} or \emph{variable} step size, is warranted. It is shown that, in the special case of a quadratic in $R^2$, if an eigenvalue is known, then GD with a fixed step size will converge in two iterations, and a complete eigen-decomposition is available. By considering the dynamics of the gradients and iterates, new step size strategies are proposed to improve the practical performance of GD. Several numerical examples are presented, which demonstrate the advantages of exploiting the GD--PM connection.
Word-Level Representation From Bytes For Language Modeling
Nov 23, 2022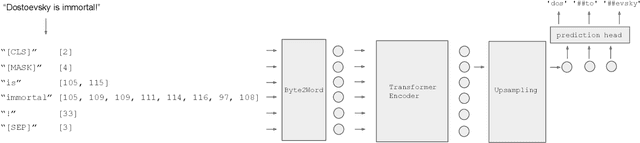
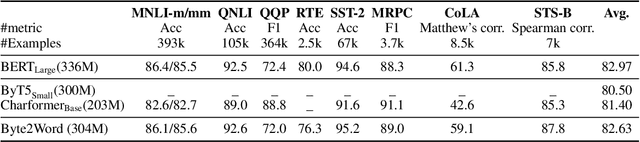

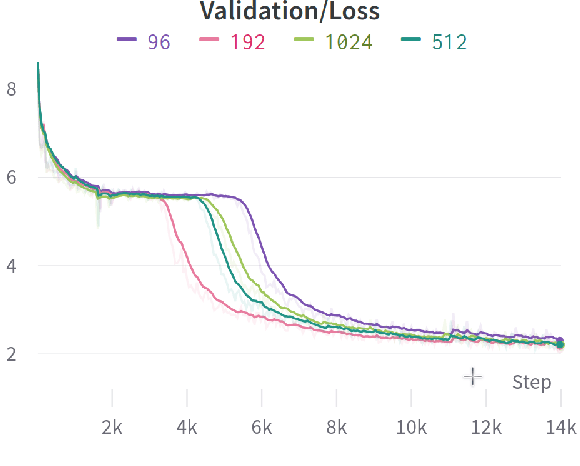
Modern language models mostly take sub-words as input, a design that balances the trade-off between vocabulary size, number of parameters, and performance. However, sub-word tokenization still has disadvantages like not being robust to noise and difficult to generalize to new languages. Also, the current trend of scaling up models reveals that larger models require larger embeddings but that makes parallelization hard. Previous work on image classification proves splitting raw input into a sequence of chucks is a strong, model-agnostic inductive bias. Based on this observation, we rethink the existing character-aware method that takes character-level inputs but makes word-level sequence modeling and prediction. We overhaul this method by introducing a cross-attention network that builds word-level representation directly from bytes, and a sub-word level prediction based on word-level hidden states to avoid the time and space requirement of word-level prediction. With these two improvements combined, we have a token free model with slim input embeddings for downstream tasks. We name our method Byte2Word and perform evaluations on language modeling and text classification. Experiments show that Byte2Word is on par with the strong sub-word baseline BERT but only takes up 10\% of embedding size. We further test our method on synthetic noise and cross-lingual transfer and find it competitive to baseline methods on both settings.
Wheel Impact Test by Deep Learning: Prediction of Location and Magnitude of Maximum Stress
Oct 03, 2022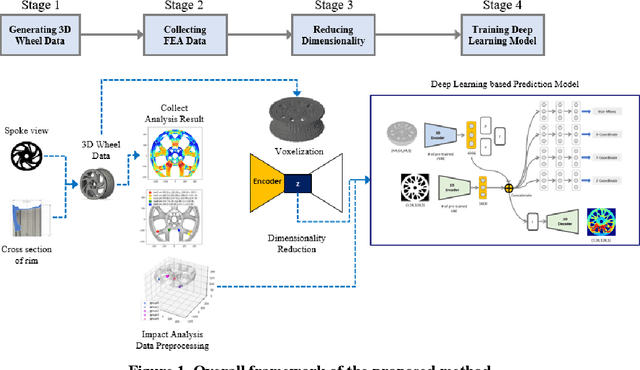
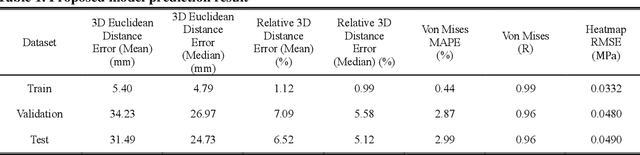
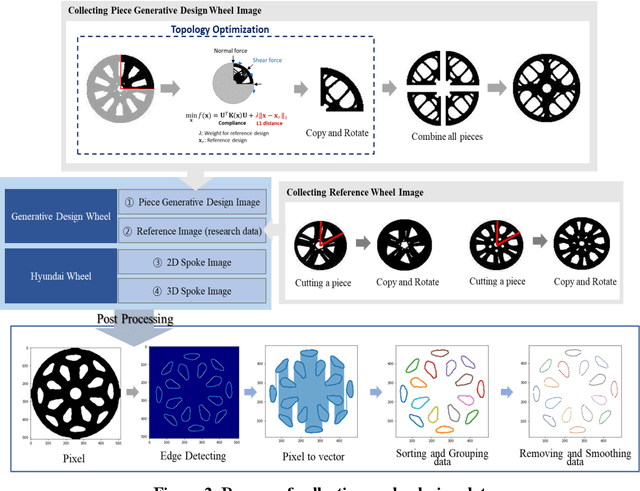
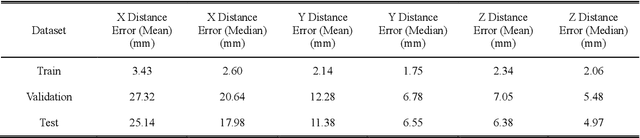
The impact performance of the wheel during wheel development must be ensured through a wheel impact test for vehicle safety. However, manufacturing and testing a real wheel take a significant amount of time and money because developing an optimal wheel design requires numerous iterative processes of modifying the wheel design and verifying the safety performance. Accordingly, the actual wheel impact test has been replaced by computer simulations, such as Finite Element Analysis (FEA), but it still requires high computational costs for modeling and analysis. Moreover, FEA experts are needed. This study presents an aluminum road wheel impact performance prediction model based on deep learning that replaces the computationally expensive and time-consuming 3D FEA. For this purpose, 2D disk-view wheel image data, 3D wheel voxel data, and barrier mass value used for wheel impact test are utilized as the inputs to predict the magnitude of maximum von Mises stress, corresponding location, and the stress distribution of 2D disk-view. The wheel impact performance prediction model can replace the impact test in the early wheel development stage by predicting the impact performance in real time and can be used without domain knowledge. The time required for the wheel development process can be shortened through this mechanism.
Globus Automation Services: Research process automation across the space-time continuum
Aug 19, 2022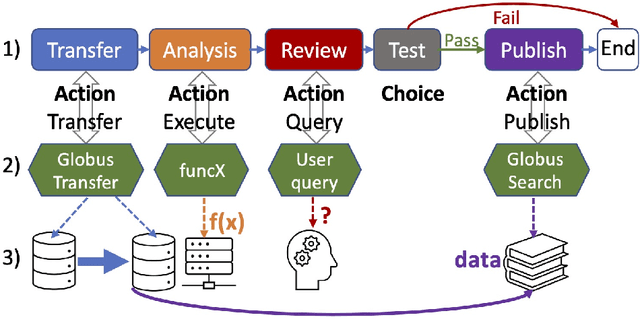
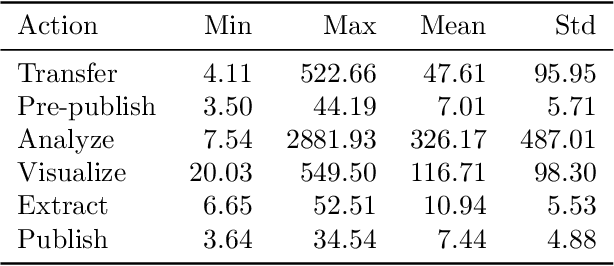
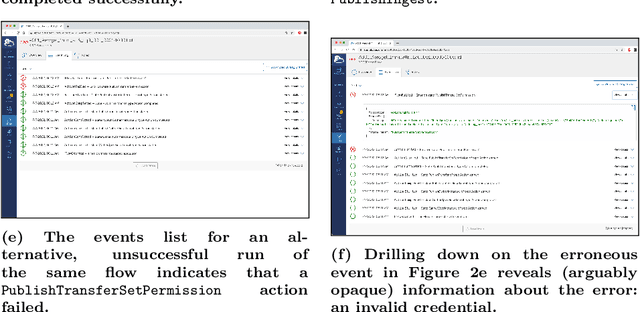
Research process automation--the reliable, efficient, and reproducible execution of linked sets of actions on scientific instruments, computers, data stores, and other resources--has emerged as an essential element of modern science. We report here on new services within the Globus research data management platform that enable the specification of diverse research processes as reusable sets of actions, flows, and the execution of such flows in heterogeneous research environments. To support flows with broad spatial extent (e.g., from scientific instrument to remote data center) and temporal extent (from seconds to weeks), these Globus automation services feature: 1) cloud hosting for reliable execution of even long-lived flows despite sporadic failures; 2) a declarative notation, and extensible asynchronous action provider API, for defining and executing a wide variety of actions and flow specifications involving arbitrary resources; 3) authorization delegation mechanisms for secure invocation of actions. These services permit researchers to outsource and automate the management of a broad range of research tasks to a reliable, scalable, and secure cloud platform. We present use cases for Globus automation services, describe the design and implementation of the services, present microbenchmark studies, and review experiences applying the services in a range of applications