 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Does an ensemble of GANs lead to better performance when training segmentation networks with synthetic images?
Nov 08, 2022
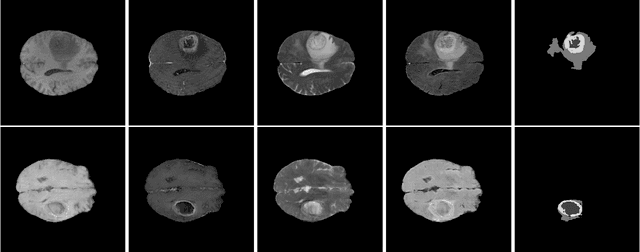
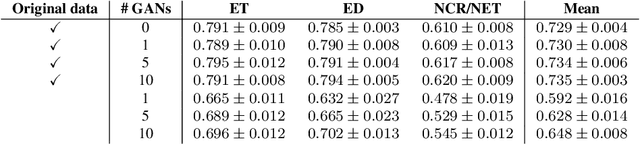
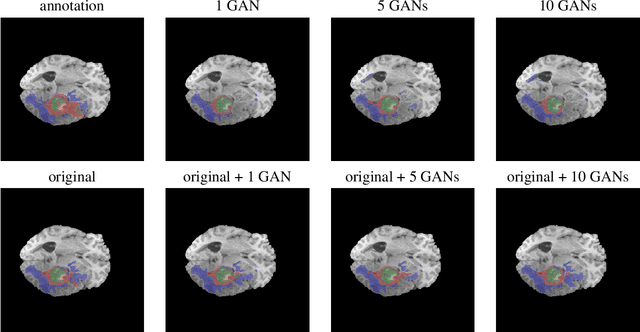
Large annotated datasets are required to train segmentation networks. In medical imaging, it is often difficult, time consuming and expensive to create such datasets, and it may also be difficult to share these datasets with other researchers. Different AI models can today generate very realistic synthetic images, which can potentially be openly shared as they do not belong to specific persons. However, recent work has shown that using synthetic images for training deep networks often leads to worse performance compared to using real images. Here we demonstrate that using synthetic images and annotations from an ensemble of 10 GANs, instead of from a single GAN, increases the Dice score on real test images with 4.7 % to 14.0 % on specific classes.
pyRDDLGym: From RDDL to Gym Environments
Nov 14, 2022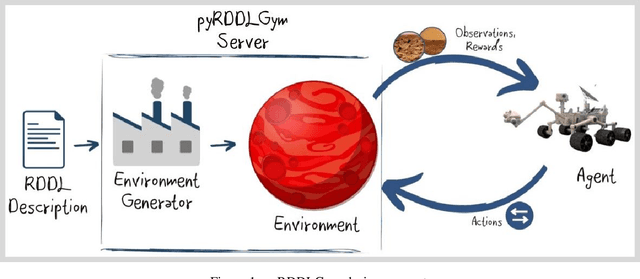
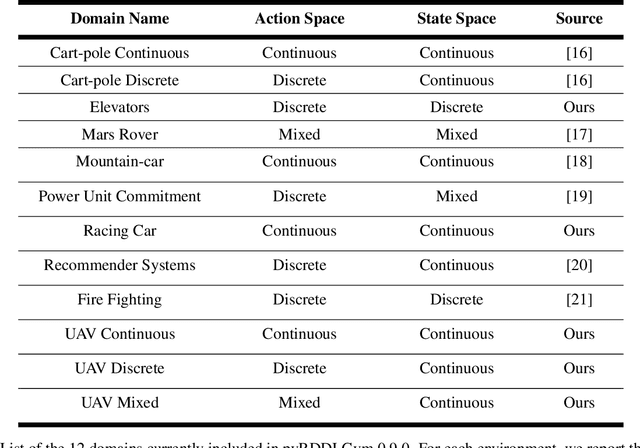


We present pyRDDLGym, a Python framework for auto-generation of OpenAI Gym environments from RDDL declerative description. The discrete time step evolution of variables in RDDL is described by conditional probability functions, which fits naturally into the Gym step scheme. Furthermore, since RDDL is a lifted description, the modification and scaling up of environments to support multiple entities and different configurations becomes trivial rather than a tedious process prone to errors. We hope that pyRDDLGym will serve as a new wind in the reinforcement learning community by enabling easy and rapid development of benchmarks due to the unique expressive power of RDDL. By providing explicit access to the model in the RDDL description, pyRDDLGym can also facilitate research on hybrid approaches for learning from interaction while leveraging model knowledge. We present the design and built-in examples of pyRDDLGym, and the additions made to the RDDL language that were incorporated into the framework.
Hypothesis Transfer in Bandits by Weighted Models
Nov 14, 2022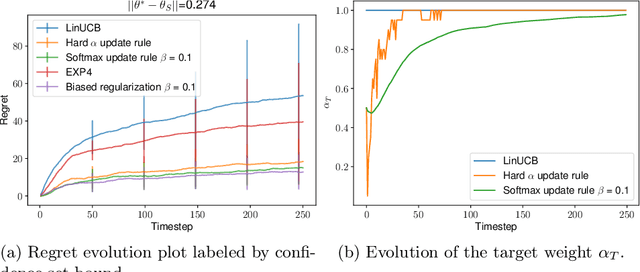
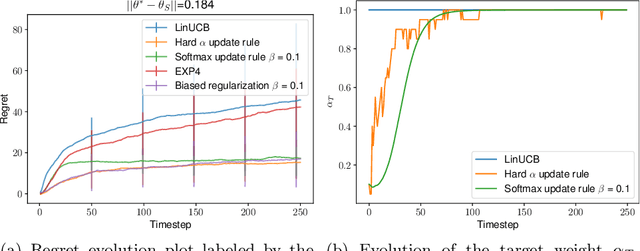
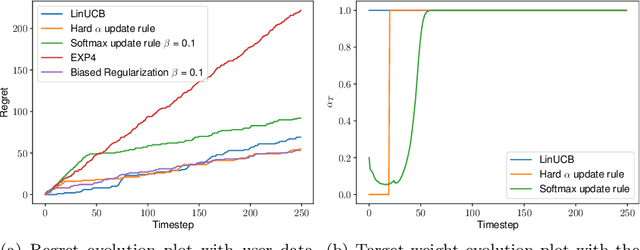
We consider the problem of contextual multi-armed bandits in the setting of hypothesis transfer learning. That is, we assume having access to a previously learned model on an unobserved set of contexts, and we leverage it in order to accelerate exploration on a new bandit problem. Our transfer strategy is based on a re-weighting scheme for which we show a reduction in the regret over the classic Linear UCB when transfer is desired, while recovering the classic regret rate when the two tasks are unrelated. We further extend this method to an arbitrary amount of source models, where the algorithm decides which model is preferred at each time step. Additionally we discuss an approach where a dynamic convex combination of source models is given in terms of a biased regularization term in the classic LinUCB algorithm. The algorithms and the theoretical analysis of our proposed methods substantiated by empirical evaluations on simulated and real-world data.
SNIPER Training: Variable Sparsity Rate Training For Text-To-Speech
Nov 14, 2022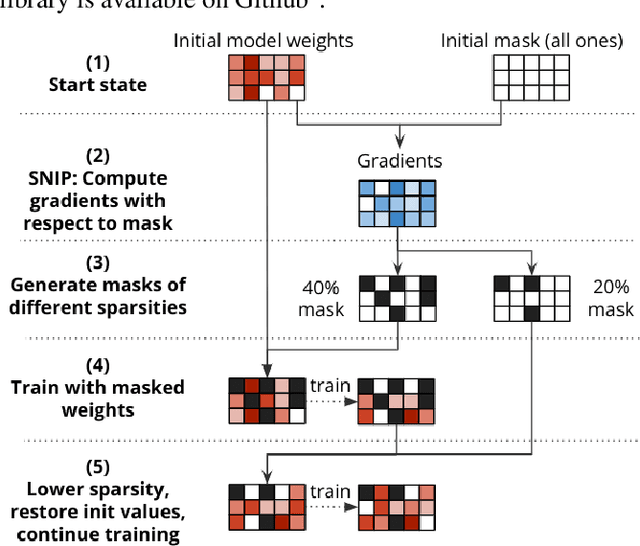
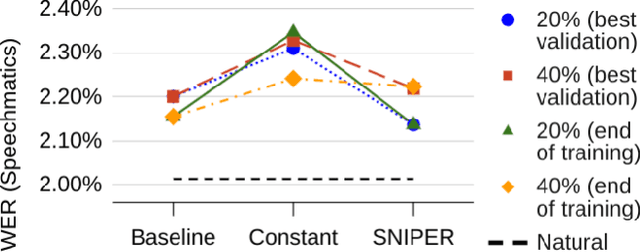
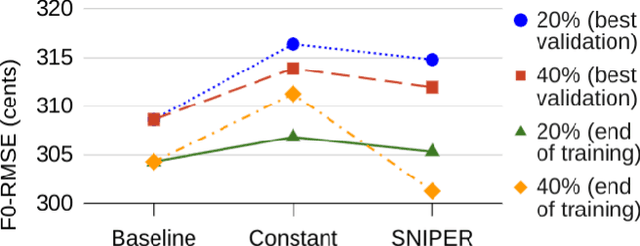
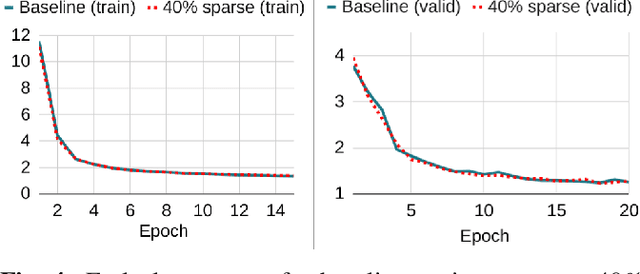
Text-to-speech (TTS) models have achieved remarkable naturalness in recent years, yet like most deep neural models, they have more parameters than necessary. Sparse TTS models can improve on dense models via pruning and extra retraining, or converge faster than dense models with some performance loss. Inspired by these results, we propose training TTS models using a decaying sparsity rate, i.e. a high initial sparsity to accelerate training first, followed by a progressive rate reduction to obtain better eventual performance. This decremental approach differs from current methods of incrementing sparsity to a desired target, which costs significantly more time than dense training. We call our method SNIPER training: Single-shot Initialization Pruning Evolving-Rate training. Our experiments on FastSpeech2 show that although we were only able to obtain better losses in the first few epochs before being overtaken by the baseline, the final SNIPER-trained models beat constant-sparsity models and pip dense models in performance.
Interactively Learning to Summarise Timelines by Reinforcement Learning
Nov 14, 2022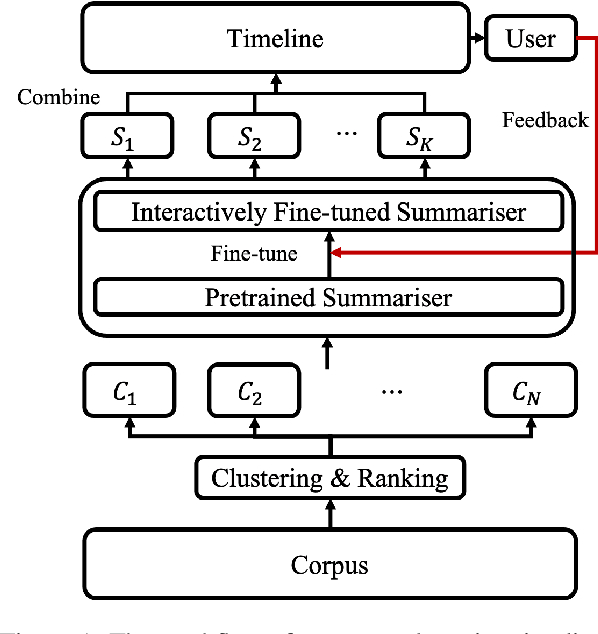
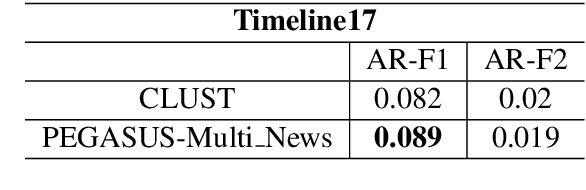
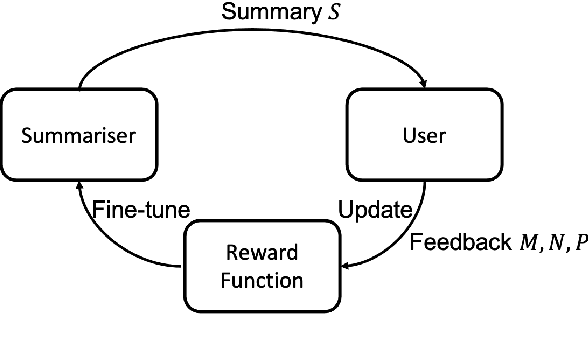
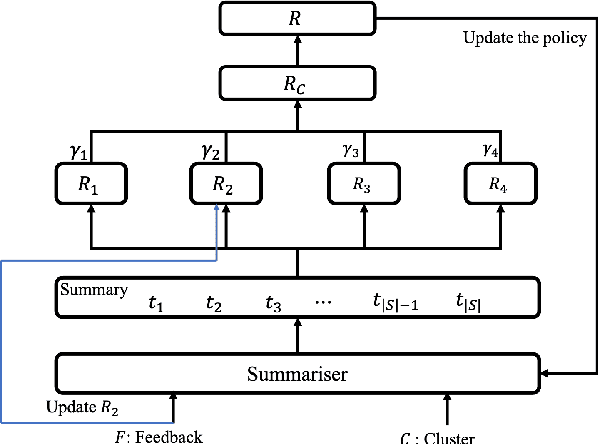
Timeline summarisation (TLS) aims to create a time-ordered summary list concisely describing a series of events with corresponding dates. This differs from general summarisation tasks because it requires the method to capture temporal information besides the main idea of the input documents. This paper proposes a TLS system which can interactively learn from the user's feedback via reinforcement learning and generate timelines satisfying the user's interests. We define a compound reward function that can update automatically according to the received feedback through interaction with the user. The system utilises the reward function to fine-tune an abstractive summarisation model via reinforcement learning to guarantee topical coherence, factual consistency and linguistic fluency of the generated summaries. The proposed system avoids the need of preference feedback from individual users. The experiments show that our system outperforms the baseline on the benchmark TLS dataset and can generate accurate and timeline precises that better satisfy real users.
The Potential of Neural Speech Synthesis-based Data Augmentation for Personalized Speech Enhancement
Nov 14, 2022
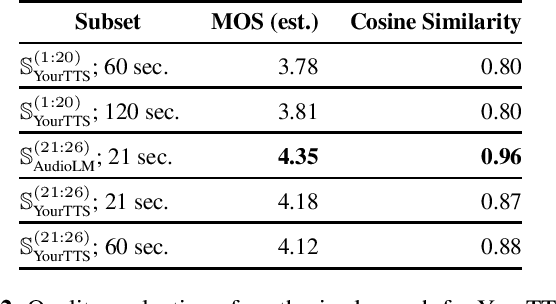
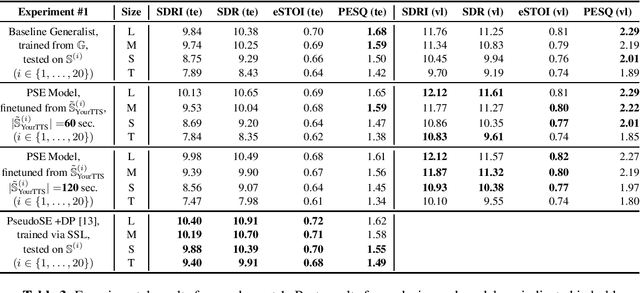
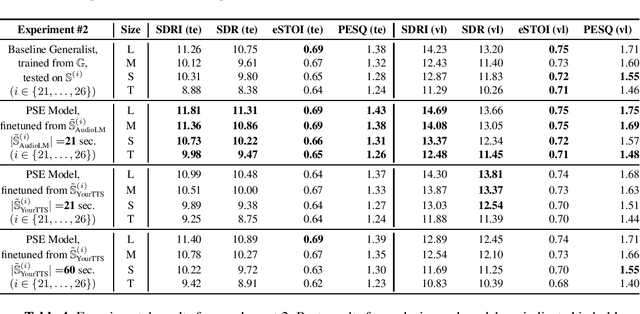
With the advances in deep learning, speech enhancement systems benefited from large neural network architectures and achieved state-of-the-art quality. However, speaker-agnostic methods are not always desirable, both in terms of quality and their complexity, when they are to be used in a resource-constrained environment. One promising way is personalized speech enhancement (PSE), which is a smaller and easier speech enhancement problem for small models to solve, because it focuses on a particular test-time user. To achieve the personalization goal, while dealing with the typical lack of personal data, we investigate the effect of data augmentation based on neural speech synthesis (NSS). In the proposed method, we show that the quality of the NSS system's synthetic data matters, and if they are good enough the augmented dataset can be used to improve the PSE system that outperforms the speaker-agnostic baseline. The proposed PSE systems show significant complexity reduction while preserving the enhancement quality.
DroneNet: Crowd Density Estimation using Self-ONNs for Drones
Nov 14, 2022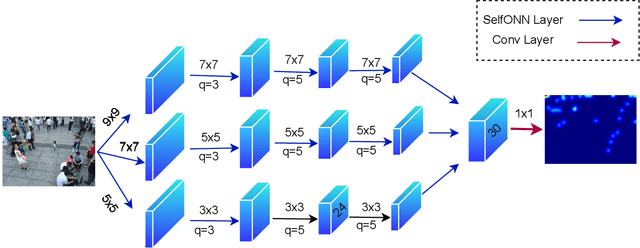
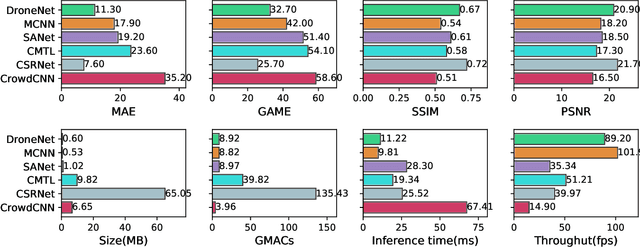

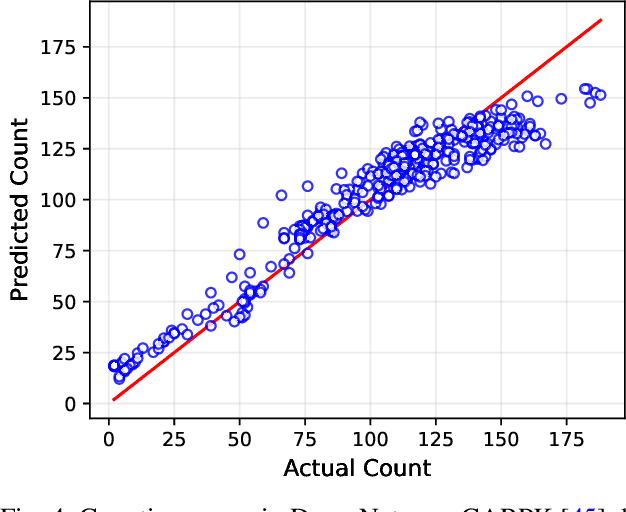
Video surveillance using drones is both convenient and efficient due to the ease of deployment and unobstructed movement of drones in many scenarios. An interesting application of drone-based video surveillance is to estimate crowd densities (both pedestrians and vehicles) in public places. Deep learning using convolution neural networks (CNNs) is employed for automatic crowd counting and density estimation using images and videos. However, the performance and accuracy of such models typically depend upon the model architecture i.e., deeper CNN models improve accuracy at the cost of increased inference time. In this paper, we propose a novel crowd density estimation model for drones (DroneNet) using Self-organized Operational Neural Networks (Self-ONN). Self-ONN provides efficient learning capabilities with lower computational complexity as compared to CNN-based models. We tested our algorithm on two drone-view public datasets. Our evaluation shows that the proposed DroneNet shows superior performance on an equivalent CNN-based model.
Non-stationary Risk-sensitive Reinforcement Learning: Near-optimal Dynamic Regret, Adaptive Detection, and Separation Design
Nov 19, 2022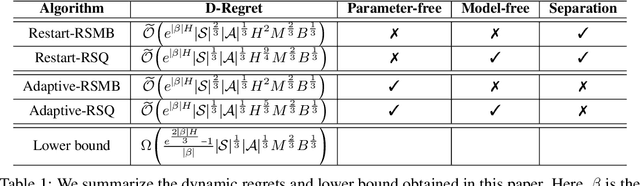
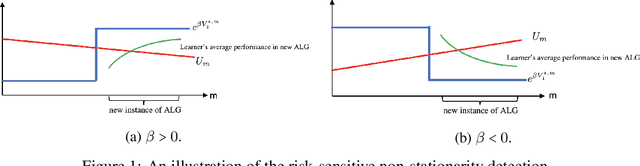
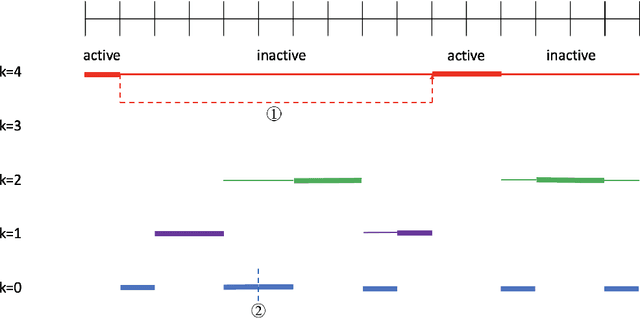
We study risk-sensitive reinforcement learning (RL) based on an entropic risk measure in episodic non-stationary Markov decision processes (MDPs). Both the reward functions and the state transition kernels are unknown and allowed to vary arbitrarily over time with a budget on their cumulative variations. When this variation budget is known a prior, we propose two restart-based algorithms, namely Restart-RSMB and Restart-RSQ, and establish their dynamic regrets. Based on these results, we further present a meta-algorithm that does not require any prior knowledge of the variation budget and can adaptively detect the non-stationarity on the exponential value functions. A dynamic regret lower bound is then established for non-stationary risk-sensitive RL to certify the near-optimality of the proposed algorithms. Our results also show that the risk control and the handling of the non-stationarity can be separately designed in the algorithm if the variation budget is known a prior, while the non-stationary detection mechanism in the adaptive algorithm depends on the risk parameter. This work offers the first non-asymptotic theoretical analyses for the non-stationary risk-sensitive RL in the literature.
BENK: The Beran Estimator with Neural Kernels for Estimating the Heterogeneous Treatment Effect
Nov 19, 2022
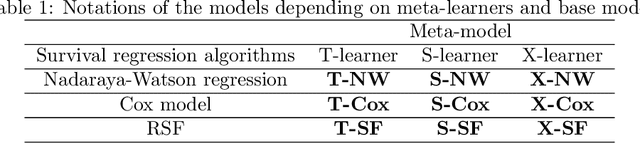
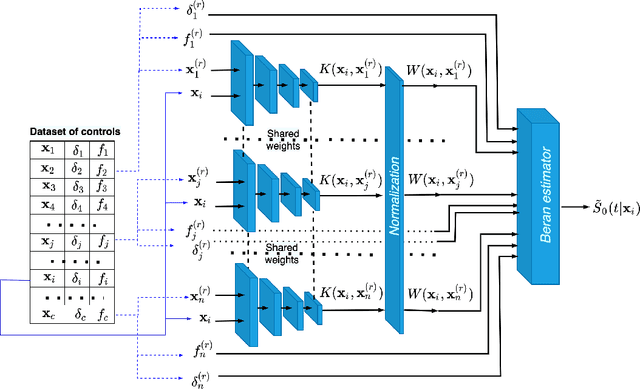
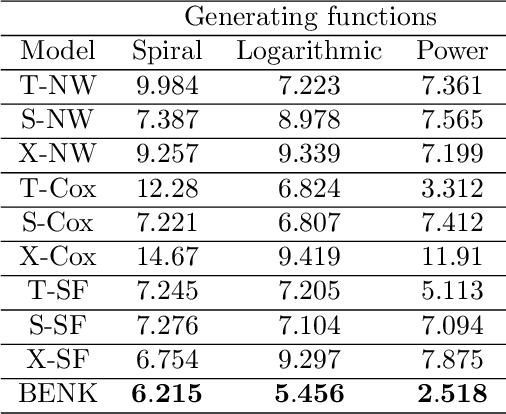
A method for estimating the conditional average treatment effect under condition of censored time-to-event data called BENK (the Beran Estimator with Neural Kernels) is proposed. The main idea behind the method is to apply the Beran estimator for estimating the survival functions of controls and treatments. Instead of typical kernel functions in the Beran estimator, it is proposed to implement kernels in the form of neural networks of a specific form called the neural kernels. The conditional average treatment effect is estimated by using the survival functions as outcomes of the control and treatment neural networks which consists of a set of neural kernels with shared parameters. The neural kernels are more flexible and can accurately model a complex location structure of feature vectors. Various numerical simulation experiments illustrate BENK and compare it with the well-known T-learner, S-learner and X-learner for several types of the control and treatment outcome functions based on the Cox models, the random survival forest and the Nadaraya-Watson regression with Gaussian kernels. The code of proposed algorithms implementing BENK is available in https://github.com/Stasychbr/BENK.
Delay-aware Backpressure Routing Using Graph Neural Networks
Nov 19, 2022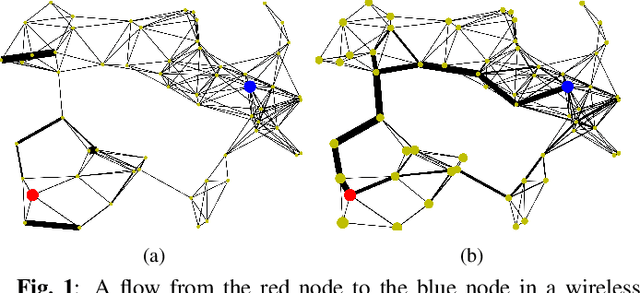
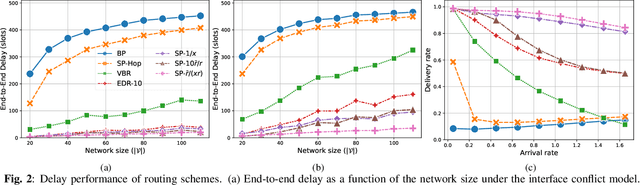
We propose a throughput-optimal biased backpressure (BP) algorithm for routing, where the bias is learned through a graph neural network that seeks to minimize end-to-end delay. Classical BP routing provides a simple yet powerful distributed solution for resource allocation in wireless multi-hop networks but has poor delay performance. A low-cost approach to improve this delay performance is to favor shorter paths by incorporating pre-defined biases in the BP computation, such as a bias based on the shortest path (hop) distance to the destination. In this work, we improve upon the widely-used metric of hop distance (and its variants) for the shortest path bias by introducing a bias based on the link duty cycle, which we predict using a graph convolutional neural network. Numerical results show that our approach can improve the delay performance compared to classical BP and existing BP alternatives based on pre-defined bias while being adaptive to interference density. In terms of complexity, our distributed implementation only introduces a one-time overhead (linear in the number of devices in the network) compared to classical BP, and a constant overhead compared to the lowest-complexity existing bias-based BP algorithms.