 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TTS-GAN: A Transformer-based Time-Series Generative Adversarial Network
Feb 06, 2022
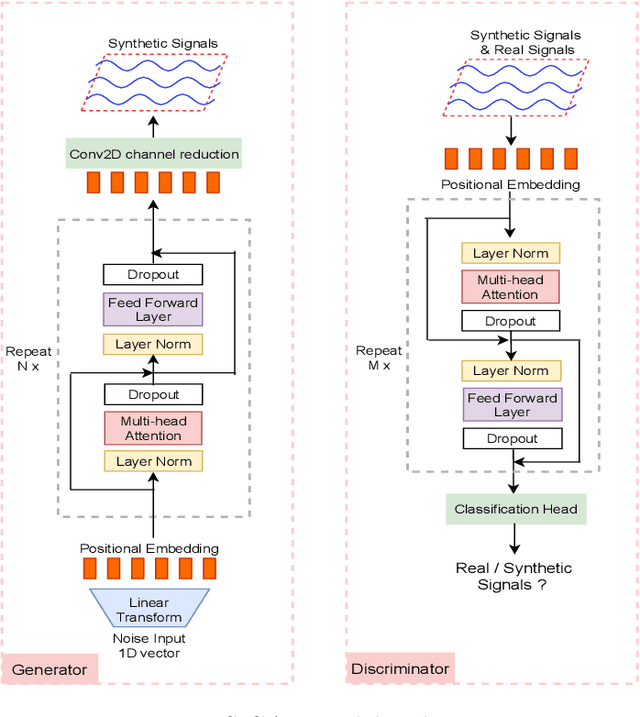
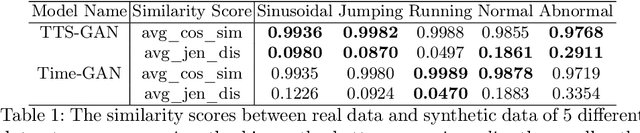
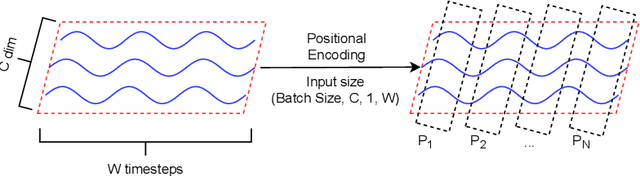
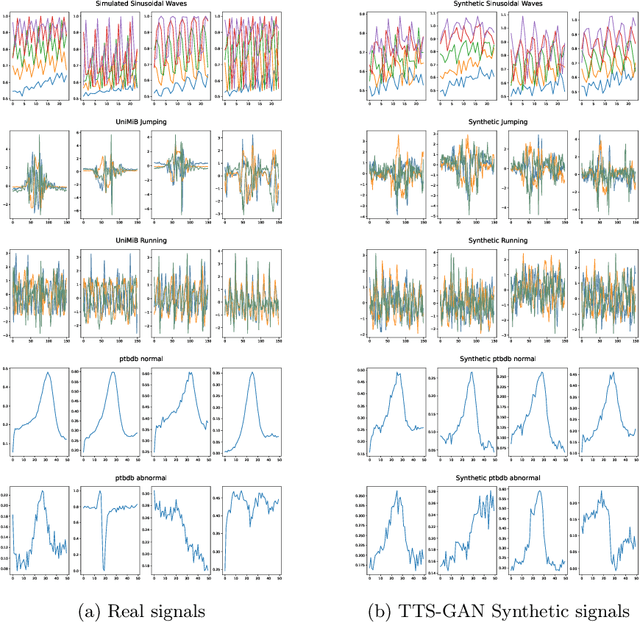
Signal measurements appearing in the form of time series are one of the most common types of data used in medical machine learning applications. However, such datasets are often small, making the training of deep neural network architectures ineffective. For time-series, the suite of data augmentation tricks we can use to expand the size of the dataset is limited by the need to maintain the basic properties of the signal. Data generated by a Generative Adversarial Network (GAN) can be utilized as another data augmentation tool. RNN-based GANs suffer from the fact that they cannot effectively model long sequences of data points with irregular temporal relations. To tackle these problems, we introduce TTS-GAN, a transformer-based GAN which can successfully generate realistic synthetic time-series data sequences of arbitrary length, similar to the real ones. Both the generator and discriminator networks of the GAN model are built using a pure transformer encoder architecture. We use visualizations and dimensionality reduction techniques to demonstrate the similarity of real and generated time-series data. We also compare the quality of our generated data with the best existing alternative, which is an RNN-based time-series GAN.
Synthetic Data Supervised Salient Object Detection
Oct 25, 2022
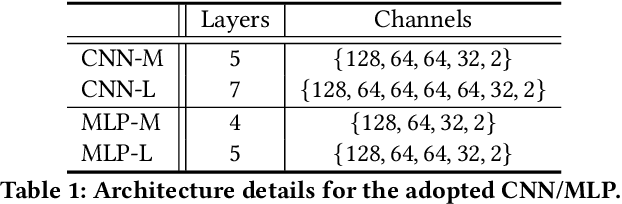
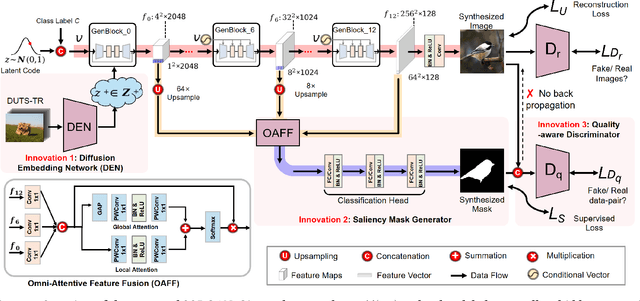
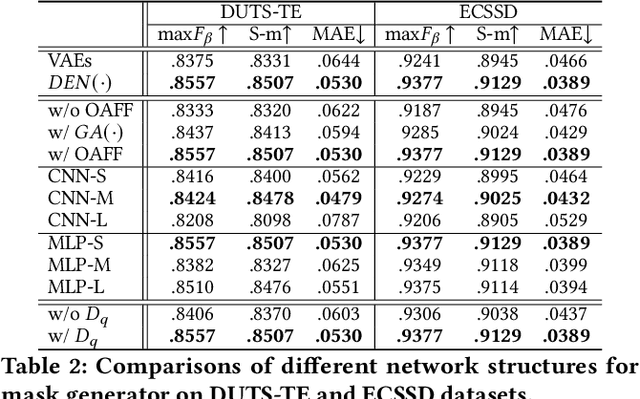
Although deep salient object detection (SOD) has achieved remarkable progress, deep SOD models are extremely data-hungry, requiring large-scale pixel-wise annotations to deliver such promising results. In this paper, we propose a novel yet effective method for SOD, coined SODGAN, which can generate infinite high-quality image-mask pairs requiring only a few labeled data, and these synthesized pairs can replace the human-labeled DUTS-TR to train any off-the-shelf SOD model. Its contribution is three-fold. 1) Our proposed diffusion embedding network can address the manifold mismatch and is tractable for the latent code generation, better matching with the ImageNet latent space. 2) For the first time, our proposed few-shot saliency mask generator can synthesize infinite accurate image synchronized saliency masks with a few labeled data. 3) Our proposed quality-aware discriminator can select highquality synthesized image-mask pairs from noisy synthetic data pool, improving the quality of synthetic data. For the first time, our SODGAN tackles SOD with synthetic data directly generated from the generative model, which opens up a new research paradigm for SOD. Extensive experimental results show that the saliency model trained on synthetic data can achieve $98.4\%$ F-measure of the saliency model trained on the DUTS-TR. Moreover, our approach achieves a new SOTA performance in semi/weakly-supervised methods, and even outperforms several fully-supervised SOTA methods. Code is available at https://github.com/wuzhenyubuaa/SODGAN
* 9 pages, 8 figures
Performance, Transparency and Time. Feature selection to speed up the diagnosis of Parkinson's disease
Jun 08, 2022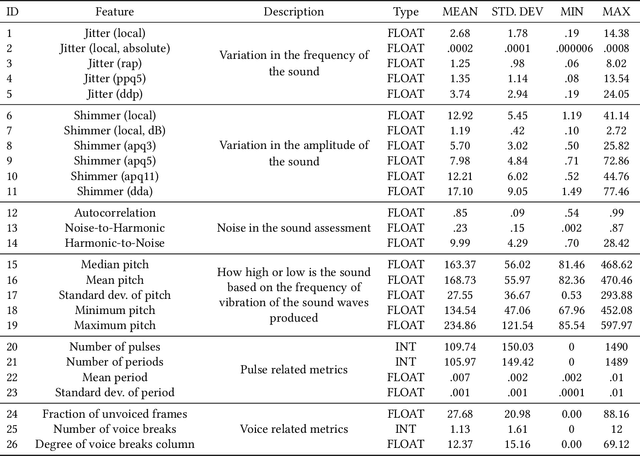
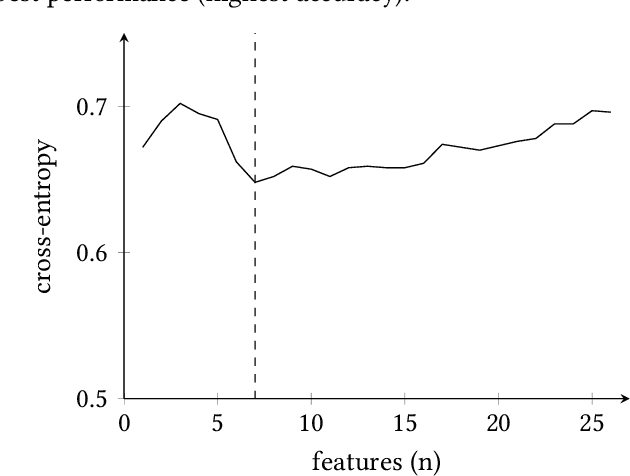
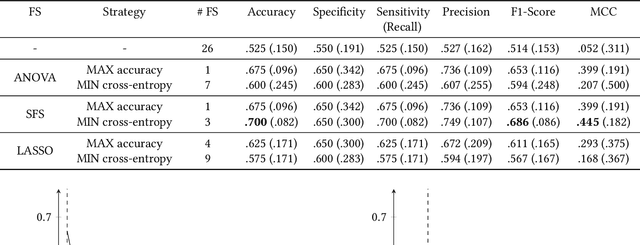
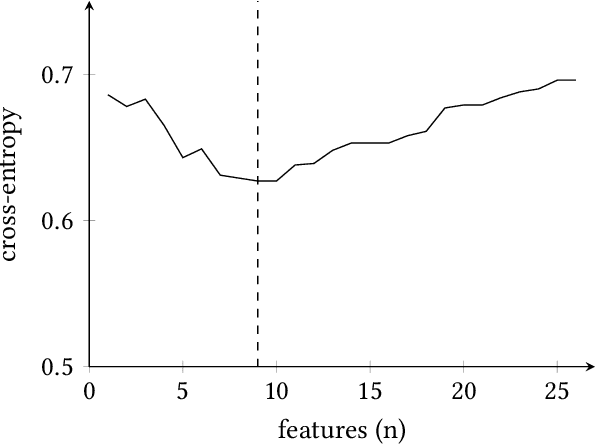
Accurate and early prediction of a disease allows to plan and improve a patient's quality of future life. During pandemic situations, the medical decision becomes a speed challenge in which physicians have to act fast to diagnose and predict the risk of the severity of the disease, moreover this is also of high priority for neurodegenerative diseases like Parkinson's disease. Machine Learning (ML) models with Features Selection (FS) techniques can be applied to help physicians to quickly diagnose a disease. FS optimally subset features that improve a model performance and help reduce the number of needed tests for a patient and hence speeding up the diagnosis. This study shows the result of three Feature Selection (FS) techniques pre-applied to a classifier algorithm, Logistic Regression, on non-invasive test results data. The three FS are Analysis of Variance (ANOVA) as filter based method, Least Absolute Shrinkage and Selection Operator (LASSO) as embedded method and Sequential Feature Selection (SFS) as wrapper method. The outcome shows that FS technique can help to build an efficient and effective classifier, hence improving the performance of the classifier while reducing the computation time.
Neural-network solutions to stochastic reaction networks
Sep 29, 2022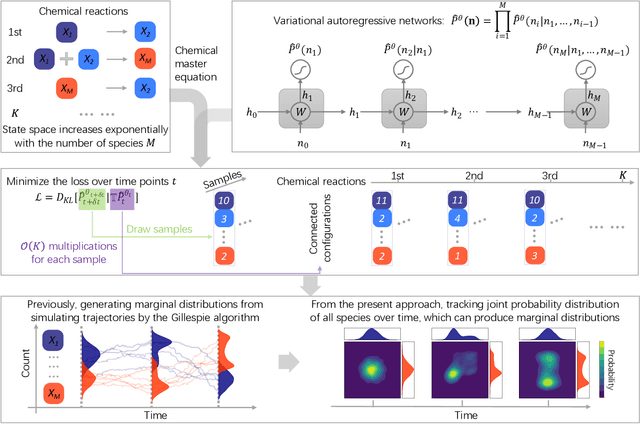
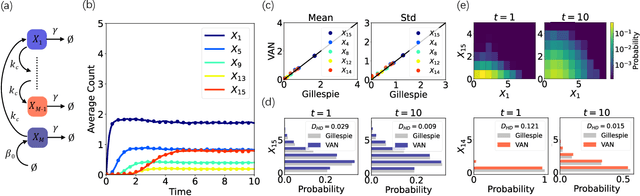
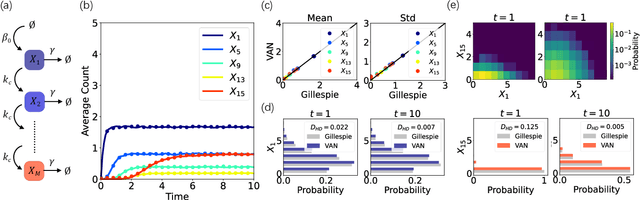
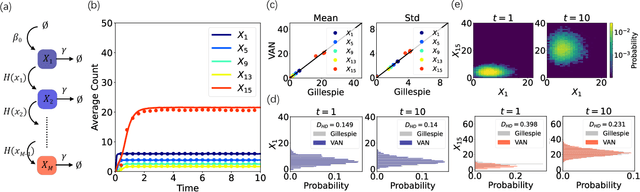
The stochastic reaction network is widely used to model stochastic processes in physics, chemistry and biology. However, the size of the state space increases exponentially with the number of species, making it challenging to investigate the time evolution of the chemical master equation for the reaction network. Here, we propose a machine-learning approach using the variational autoregressive network to solve the chemical master equation. The approach is based on the reinforcement learning framework and does not require any data simulated in prior by another method. Different from simulating single trajectories, the proposed approach tracks the time evolution of the joint probability distribution in the state space of species counts, and supports direct sampling on configurations and computing their normalized joint probabilities. We apply the approach to various systems in physics and biology, and demonstrate that it accurately generates the probability distribution over time in the genetic toggle switch, the early life self-replicator, the epidemic model and the intracellular signaling cascade. The variational autoregressive network exhibits a plasticity in representing the multi-modal distribution by feedback regulations, cooperates with the conservation law, enables time-dependent reaction rates, and is efficient for high-dimensional reaction networks with allowing a flexible upper count limit. The results suggest a general approach to investigate stochastic reaction networks based on modern machine learning.
Time-Incremental Learning from Data Using Temporal Logics
Dec 28, 2021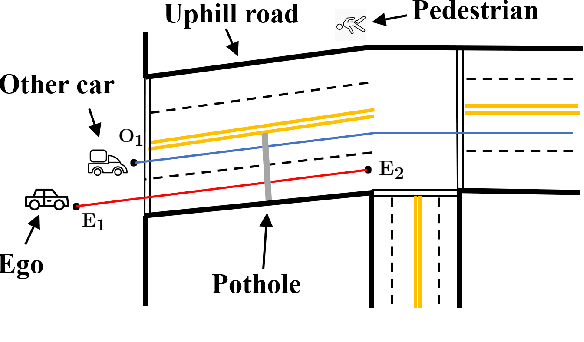
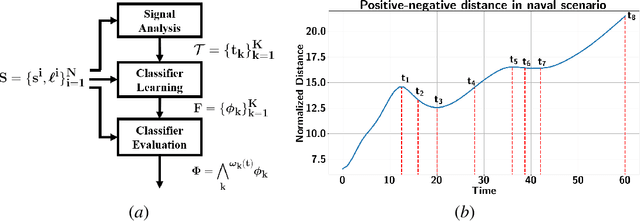
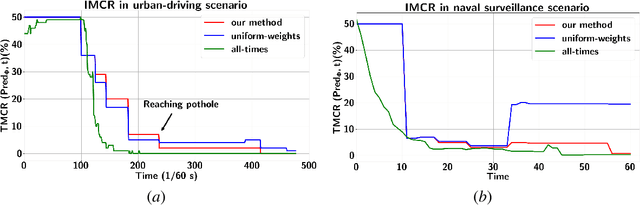
Real-time and human-interpretable decision-making in cyber-physical systems is a significant but challenging task, which usually requires predictions of possible future events from limited data. In this paper, we introduce a time-incremental learning framework: given a dataset of labeled signal traces with a common time horizon, we propose a method to predict the label of a signal that is received incrementally over time, referred to as prefix signal. Prefix signals are the signals that are being observed as they are generated, and their time length is shorter than the common horizon of signals. We present a novel decision-tree based approach to generate a finite number of Signal Temporal Logic (STL) specifications from the given dataset, and construct a predictor based on them. Each STL specification, as a binary classifier of time-series data, captures the temporal properties of the dataset over time. The predictor is constructed by assigning time-variant weights to the STL formulas. The weights are learned by using neural networks, with the goal of minimizing the misclassification rate for the prefix signals defined over the given dataset. The learned predictor is used to predict the label of a prefix signal, by computing the weighted sum of the robustness of the prefix signal with respect to each STL formula. The effectiveness and classification performance of our algorithm are evaluated on an urban-driving and a naval-surveillance case studies.
Mixed Reality Interface for Digital Twin of Plant Factory
Oct 29, 2022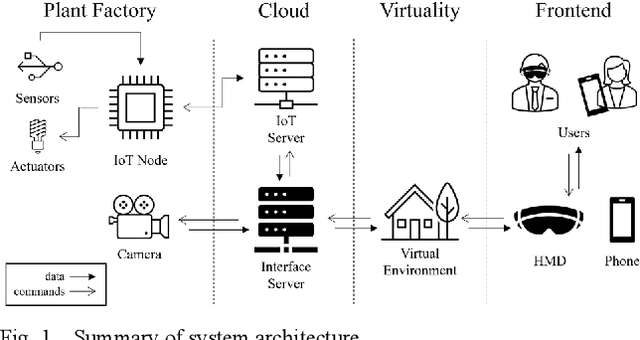



An easier and intuitive interface architecture is necessary for digital twin of plant factory. I suggest an immersive and interactive mixed reality interface for digital twin models of smart farming, for remote work rather than simulation of components. The environment is constructed with UI display and a streaming background scene, which is a real time scene taken from camera device located in the plant factory, processed with deformable neural radiance fields. User can monitor and control the remote plant factory facilities with HMD or 2D display based mixed reality environment. This paper also introduces detailed concept and describes the system architecture to implement suggested mixed reality interface.
Latent Prompt Tuning for Text Summarization
Nov 03, 2022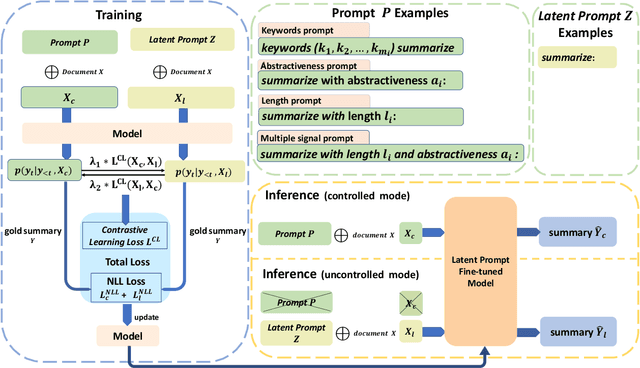
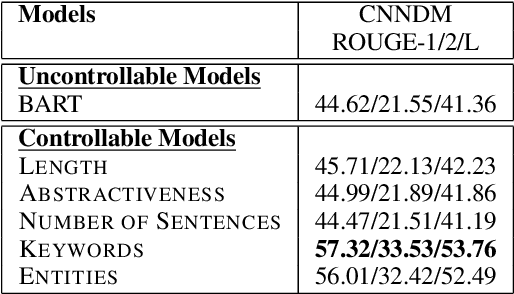
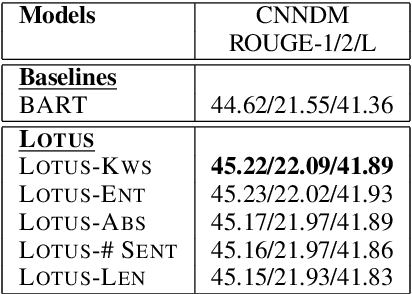
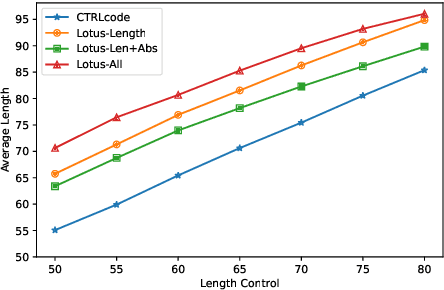
Prompts with different control signals (e.g., length, keywords, etc.) can be used to control text summarization. When control signals are available, they can control the properties of generated summaries and potentially improve summarization quality (since more information are given). Unfortunately, control signals are not already available during inference time. In this paper, we propose Lotus (shorthand for Latent Prompt Tuning for Summarization), which is a single model that can be applied in both controlled and uncontrolled (without control signals) modes. During training, Lotus learns latent prompt representations from prompts with gold control signals using a contrastive learning objective. Experiments show Lotus in uncontrolled mode consistently improves upon strong (uncontrollable) summarization models across four different summarization datasets. We also demonstrate generated summaries can be controlled using prompts with user specified control tokens.
MUSTACHE: Multi-Step-Ahead Predictions for Cache Eviction
Nov 03, 2022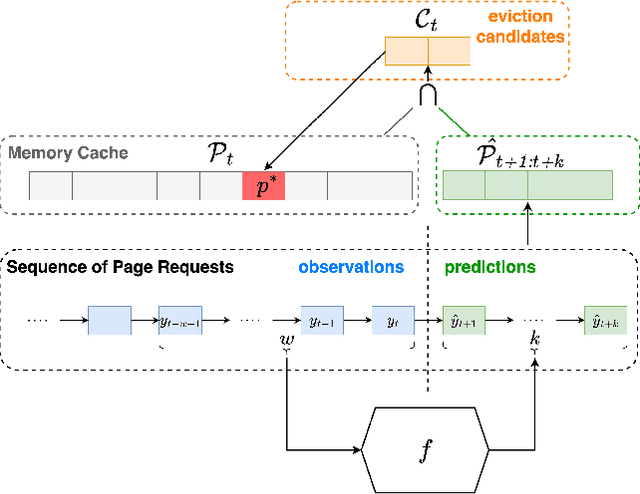

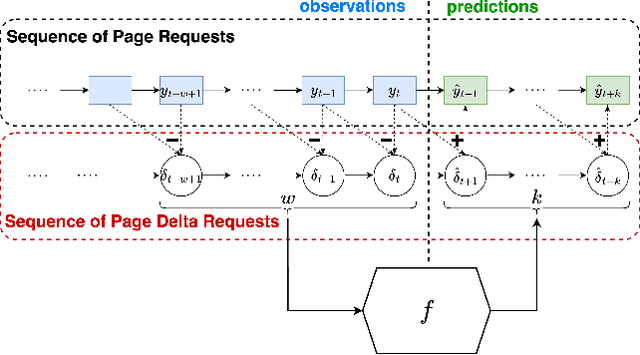

In this work, we propose MUSTACHE, a new page cache replacement algorithm whose logic is learned from observed memory access requests rather than fixed like existing policies. We formulate the page request prediction problem as a categorical time series forecasting task. Then, our method queries the learned page request forecaster to obtain the next $k$ predicted page memory references to better approximate the optimal B\'el\'ady's replacement algorithm. We implement several forecasting techniques using advanced deep learning architectures and integrate the best-performing one into an existing open-source cache simulator. Experiments run on benchmark datasets show that MUSTACHE outperforms the best page replacement heuristic (i.e., exact LRU), improving the cache hit ratio by 1.9% and reducing the number of reads/writes required to handle cache misses by 18.4% and 10.3%.
Galaxy Image Deconvolution for Weak Gravitational Lensing with Physics-informed Deep Learning
Nov 03, 2022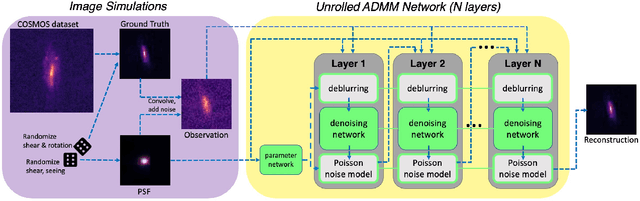
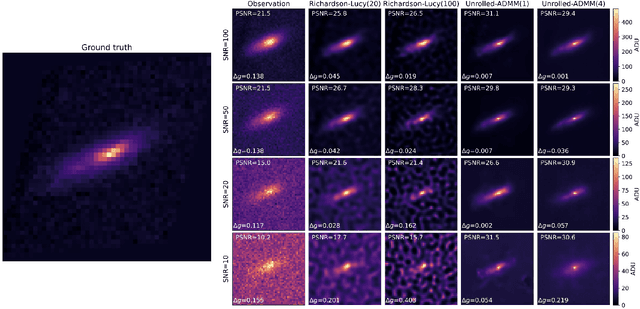
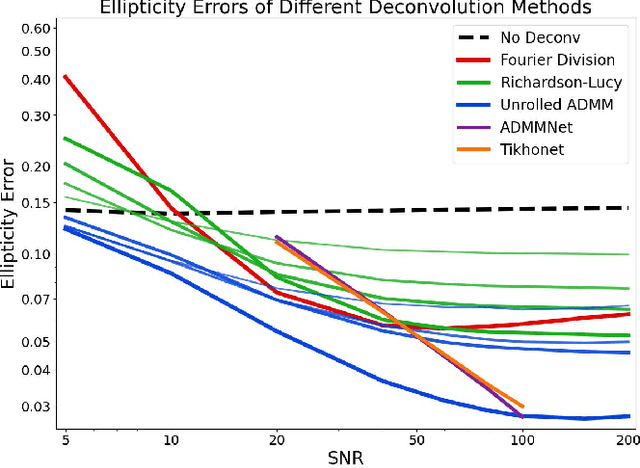
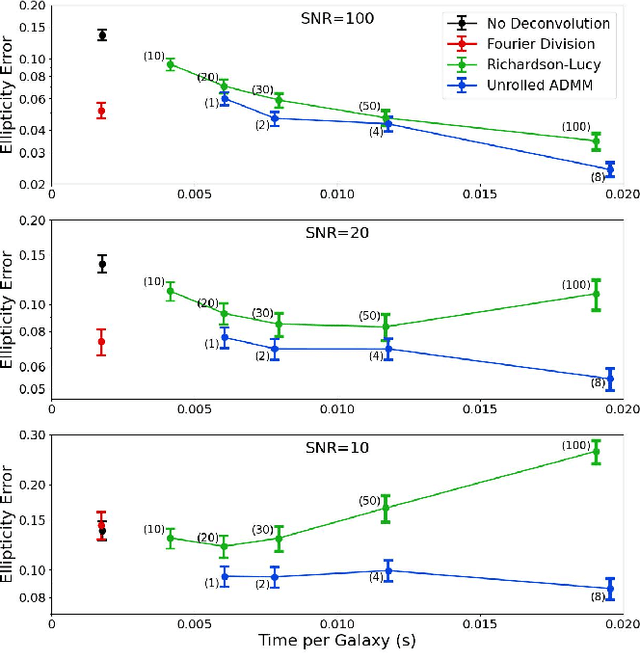
Removing optical and atmospheric blur from galaxy images significantly improves galaxy shape measurements for weak gravitational lensing and galaxy evolution studies. This ill-posed linear inverse problem is usually solved with deconvolution algorithms enhanced by regularisation priors or deep learning. We introduce a so-called "physics-based deep learning" approach to the Point Spread Function (PSF) deconvolution problem in galaxy surveys. We apply algorithm unrolling and the Plug-and-Play technique to the Alternating Direction Method of Multipliers (ADMM) with a Poisson noise model and use a neural network to learn appropriate priors from simulated galaxy images. We characterise the time-performance trade-off of several methods for galaxies of differing brightness levels, showing an improvement of 26% (SNR=20)/48% (SNR=100) compared to standard methods and 14% (SNR=20) compared to modern methods.
Going In Style: Audio Backdoors Through Stylistic Transformations
Nov 06, 2022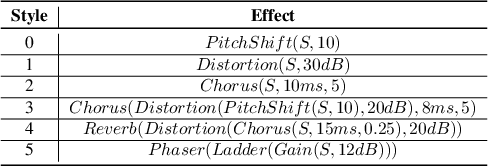
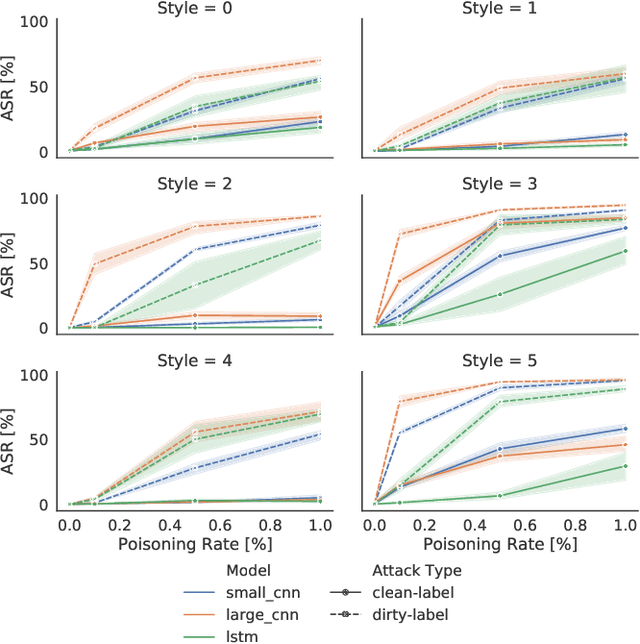
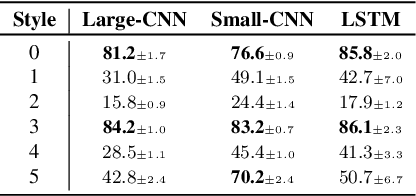
A backdoor attack places triggers in victims' deep learning models to enable a targeted misclassification at testing time. In general, triggers are fixed artifacts attached to samples, making backdoor attacks easy to spot. Only recently, a new trigger generation harder to detect has been proposed: the stylistic triggers that apply stylistic transformations to the input samples (e.g., a specific writing style). Currently, stylistic backdoor literature lacks a proper formalization of the attack, which is established in this paper. Moreover, most studies of stylistic triggers focus on text and images, while there is no understanding of whether they can work in sound. This work fills this gap. We propose JingleBack, the first stylistic backdoor attack based on audio transformations such as chorus and gain. Using 444 models in a speech classification task, we confirm the feasibility of stylistic triggers in audio, achieving 96% attack success.