 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time Object Detection for Streaming Perception
Mar 29, 2022
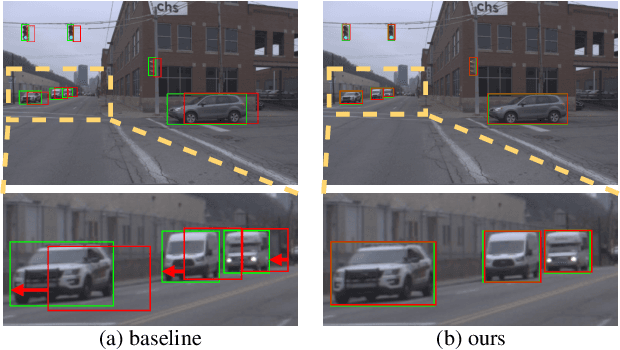

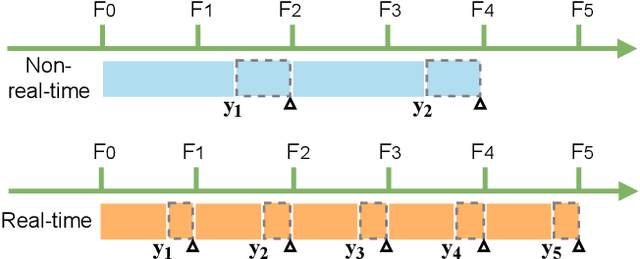
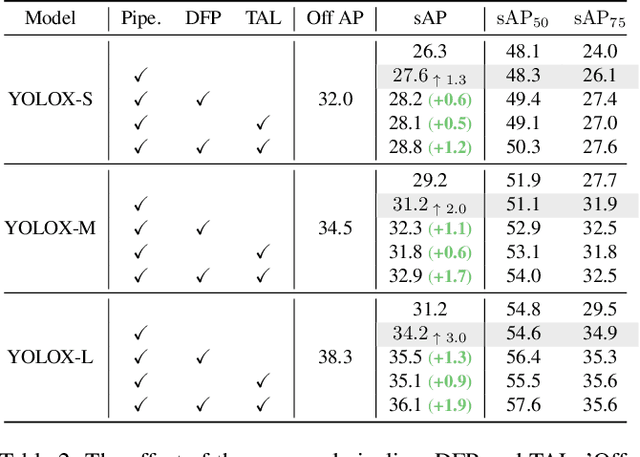
Autonomous driving requires the model to perceive the environment and (re)act within a low latency for safety. While past works ignore the inevitable changes in the environment after processing, streaming perception is proposed to jointly evaluate the latency and accuracy into a single metric for video online perception. In this paper, instead of searching trade-offs between accuracy and speed like previous works, we point out that endowing real-time models with the ability to predict the future is the key to dealing with this problem. We build a simple and effective framework for streaming perception. It equips a novel DualFlow Perception module (DFP), which includes dynamic and static flows to capture the moving trend and basic detection feature for streaming prediction. Further, we introduce a Trend-Aware Loss (TAL) combined with a trend factor to generate adaptive weights for objects with different moving speeds. Our simple method achieves competitive performance on Argoverse-HD dataset and improves the AP by 4.9% compared to the strong baseline, validating its effectiveness. Our code will be made available at https://github.com/yancie-yjr/StreamYOLO.
Evolution TANN and the discovery of the internal variables and evolution equations in solid mechanics
Sep 27, 2022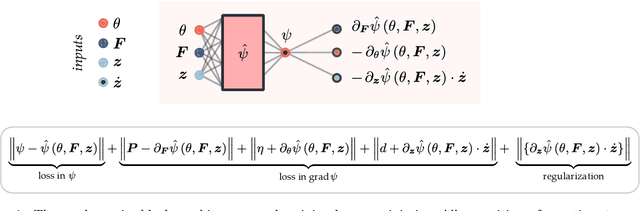
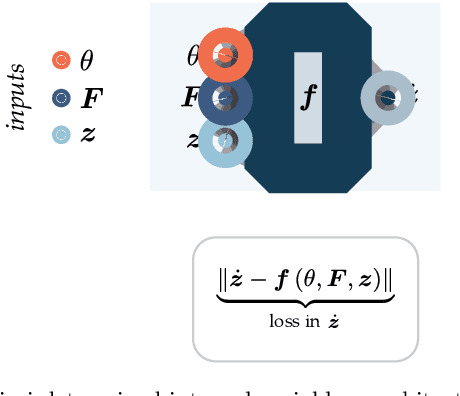
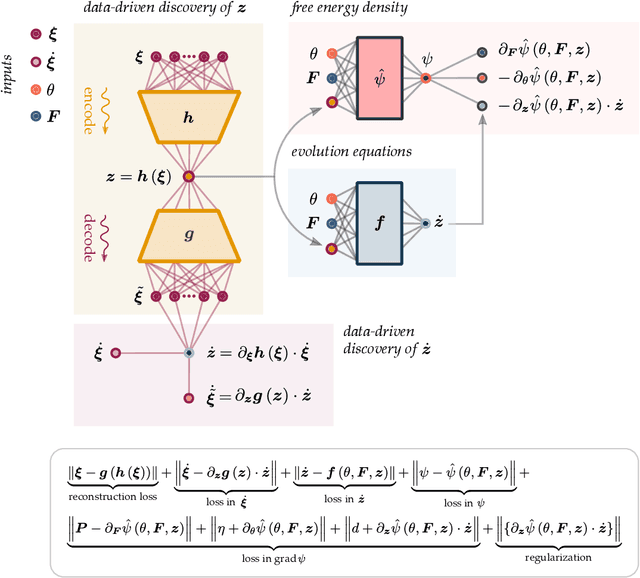
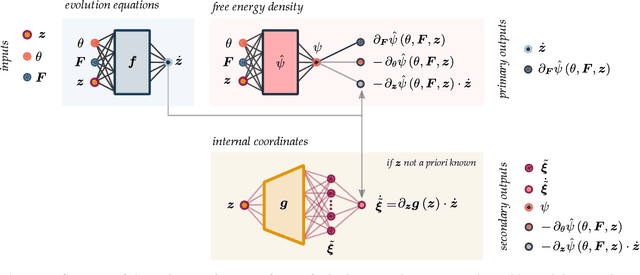
Data-driven and deep learning approaches have demonstrated to have the potential of replacing classical constitutive models for complex materials, displaying path-dependency and possessing multiple inherent scales. Yet, the necessity of structuring constitutive models with an incremental formulation has given rise to data-driven approaches where physical quantities, e.g. deformation, blend with artificial, non-physical ones, such as the increments in deformation and time. Neural networks and the consequent constitutive models depend, thus, on the particular incremental formulation, fail in identifying material representations locally in time, and suffer from poor generalization. Here, we propose a new approach which allows, for the first time, to decouple the material representation from the incremental formulation. Inspired by the Thermodynamics-based Artificial Neural Networks (TANN) and the theory of the internal variables, the evolution TANN (eTANN) are continuous-time, thus independent of the aforementioned artificial quantities. Key feature of the proposed approach is the discovery of the evolution equations of the internal variables in the form of ordinary differential equations, rather than in an incremental discrete-time form. In this work, we focus attention to juxtapose and show how the various general notions of solid mechanics are implemented in eTANN. The laws of thermodynamics are hardwired in the structure of the network and allow predictions which are always consistent. We propose a methodology that allows to discover, from data and first principles, admissible sets of internal variables from the microscopic fields in complex materials. The capabilities as well as the scalability of the proposed approach are demonstrated through several applications involving a broad spectrum of complex material behaviors, from plasticity to damage and viscosity.
CL-CrossVQA: A Continual Learning Benchmark for Cross-Domain Visual Question Answering
Nov 19, 2022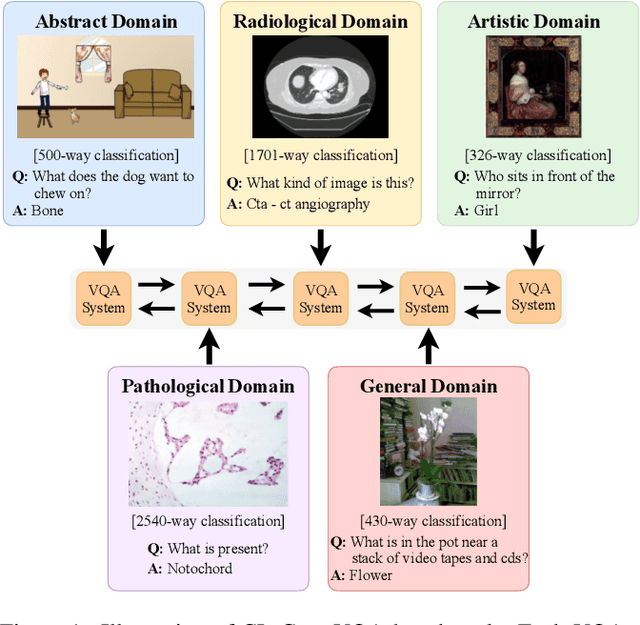


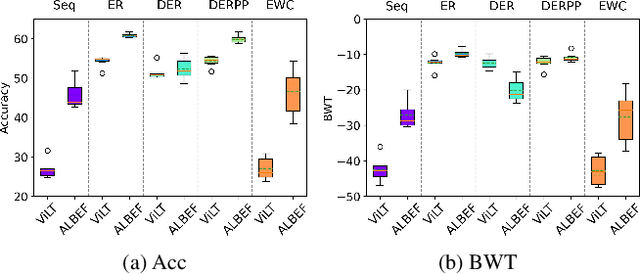
Visual Question Answering (VQA) is a multi-discipline research task. To produce the right answer, it requires an understanding of the visual content of images, the natural language questions, as well as commonsense reasoning over the information contained in the image and world knowledge. Recently, large-scale Vision-and-Language Pre-trained Models (VLPMs) have been the mainstream approach to VQA tasks due to their superior performance. The standard practice is to fine-tune large-scale VLPMs pre-trained on huge general-domain datasets using the domain-specific VQA datasets. However, in reality, the application domain can change over time, necessitating VLPMs to continually learn and adapt to new domains without forgetting previously acquired knowledge. Most existing continual learning (CL) research concentrates on unimodal tasks, whereas a more practical application scenario, i.e, CL on cross-domain VQA, has not been studied. Motivated by this, we introduce CL-CrossVQA, a rigorous Continual Learning benchmark for Cross-domain Visual Question Answering, through which we conduct extensive experiments on 4 VLPMs, 4 CL approaches, and 5 VQA datasets from different domains. In addition, by probing the forgetting phenomenon of the intermediate layers, we provide insights into how model architecture affects CL performance, why CL approaches can help mitigate forgetting in VLPMs to some extent, and how to design CL approaches suitable for VLPMs in this challenging continual learning environment. To facilitate future work on CL for cross-domain VQA, we will release our datasets and code.
Non-Coherent Over-the-Air Decentralized Stochastic Gradient Descent
Nov 19, 2022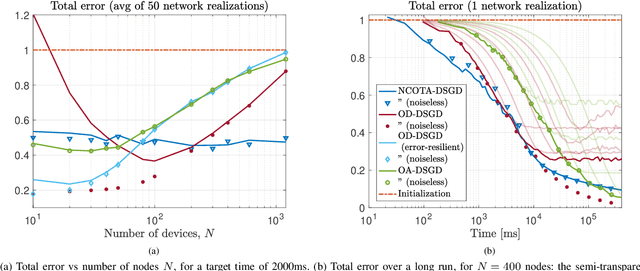
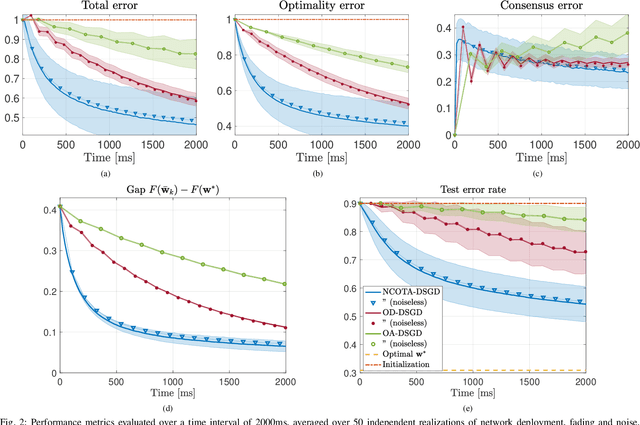
This paper proposes a Decentralized Stochastic Gradient Descent (DSGD) algorithm to solve distributed machine-learning tasks over wirelessly-connected systems, without the coordination of a base station. It combines local stochastic gradient descent steps with a Non-Coherent Over-The-Air (NCOTA) consensus scheme at the receivers, that enables concurrent transmissions by leveraging the waveform superposition properties of the wireless channels. With NCOTA, local optimization signals are mapped to a mixture of orthogonal preamble sequences and transmitted concurrently over the wireless channel under half-duplex constraints. Consensus is estimated by non-coherently combining the received signals with the preamble sequences and mitigating the impact of noise and fading via a consensus stepsize. NCOTA-DSGD operates without channel state information (typically used in over-the-air computation schemes for channel inversion) and leverages the channel pathloss to mix signals, without explicit knowledge of the mixing weights (typically known in consensus-based optimization). It is shown that, with a suitable tuning of decreasing consensus and learning stepsizes, the error (measured as Euclidean distance) between the local and globally optimum models vanishes with rate $\mathcal O(k^{-1/4})$ after $k$ iterations. NCOTA-DSGD is evaluated numerically by solving an image classification task on the MNIST dataset, cast as a regularized cross-entropy loss minimization. Numerical results depict faster convergence vis-\`a-vis running time than implementations of the classical DSGD algorithm over digital and analog orthogonal channels, when the number of learning devices is large, under stringent delay constraints.
Unifying Label-inputted Graph Neural Networks with Deep Equilibrium Models
Nov 19, 2022

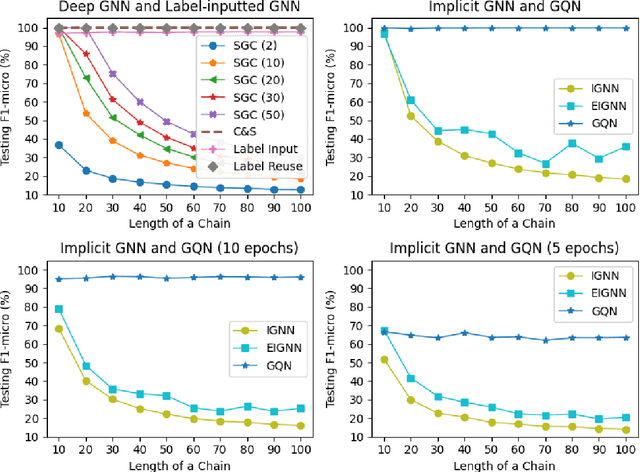
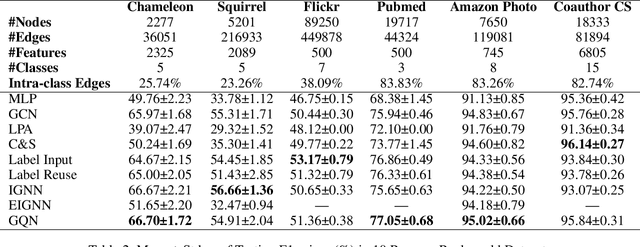
For node classification, Graph Neural Networks (GNN) assign predefined labels to graph nodes according to node features propagated along the graph structure. Apart from the traditional end-to-end manner inherited from deep learning, many subsequent works input assigned labels into GNNs to improve their classification performance. Such label-inputted GNNs (LGNN) combine the advantages of learnable feature propagation and long-range label propagation, producing state-of-the-art performance on various benchmarks. However, the theoretical foundations of LGNNs are not well-established, and the combination is with seam because the long-range propagation is memory-consuming for optimization. To this end, this work interprets LGNNs with the theory of Implicit GNN (IGNN), which outputs a fixed state point of iterating its network infinite times and optimizes the infinite-range propagation with constant memory consumption. Besides, previous contributions to LGNNs inspire us to overcome the heavy computation in training IGNN by iterating the network only once but starting from historical states, which are randomly masked in forward-pass to implicitly guarantee the existence and uniqueness of the fixed point. Our improvements to IGNNs are network agnostic: for the first time, they are extended with complex networks and applied to large-scale graphs. Experiments on two synthetic and six real-world datasets verify the advantages of our method in terms of long-range dependencies capturing, label transitions modelling, accuracy, scalability, efficiency, and well-posedness.
Category-Adaptive Label Discovery and Noise Rejection for Multi-label Image Recognition with Partial Positive Labels
Nov 15, 2022
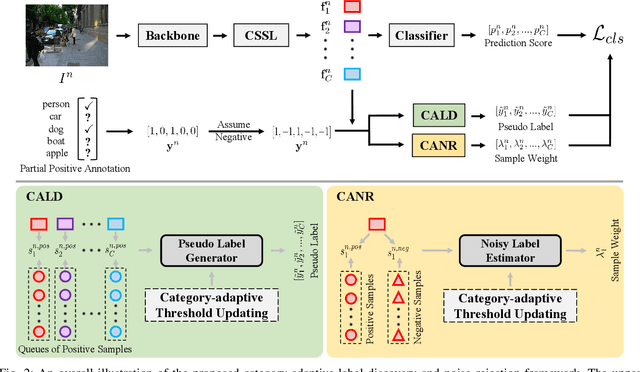
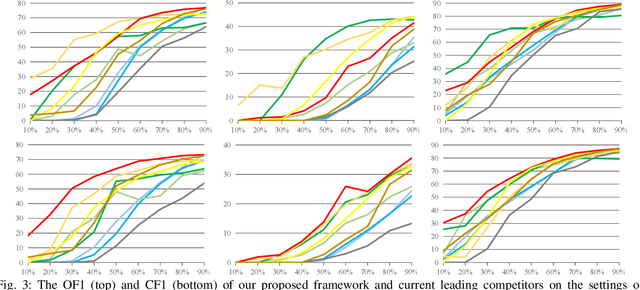
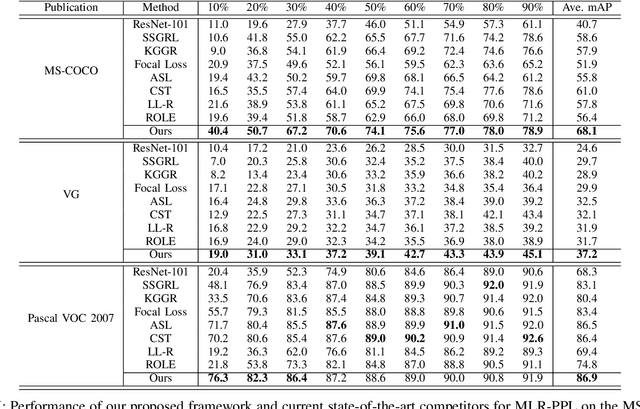
As a promising solution of reducing annotation cost, training multi-label models with partial positive labels (MLR-PPL), in which merely few positive labels are known while other are missing, attracts increasing attention. Due to the absence of any negative labels, previous works regard unknown labels as negative and adopt traditional MLR algorithms. To reject noisy labels, recent works regard large loss samples as noise but ignore the semantic correlation different multi-label images. In this work, we propose to explore semantic correlation among different images to facilitate the MLR-PPL task. Specifically, we design a unified framework, Category-Adaptive Label Discovery and Noise Rejection, that discovers unknown labels and rejects noisy labels for each category in an adaptive manner. The framework consists of two complementary modules: (1) Category-Adaptive Label Discovery module first measures the semantic similarity between positive samples and then complement unknown labels with high similarities; (2) Category-Adaptive Noise Rejection module first computes the sample weights based on semantic similarities from different samples and then discards noisy labels with low weights. Besides, we propose a novel category-adaptive threshold updating that adaptively adjusts the threshold, to avoid the time-consuming manual tuning process. Extensive experiments demonstrate that our proposed method consistently outperforms current leading algorithms.
Deep scene-scale material estimation from multi-view indoor captures
Nov 15, 2022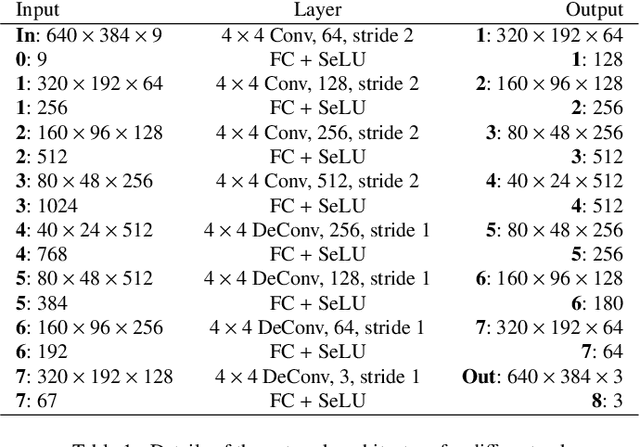

The movie and video game industries have adopted photogrammetry as a way to create digital 3D assets from multiple photographs of a real-world scene. But photogrammetry algorithms typically output an RGB texture atlas of the scene that only serves as visual guidance for skilled artists to create material maps suitable for physically-based rendering. We present a learning-based approach that automatically produces digital assets ready for physically-based rendering, by estimating approximate material maps from multi-view captures of indoor scenes that are used with retopologized geometry. We base our approach on a material estimation Convolutional Neural Network (CNN) that we execute on each input image. We leverage the view-dependent visual cues provided by the multiple observations of the scene by gathering, for each pixel of a given image, the color of the corresponding point in other images. This image-space CNN provides us with an ensemble of predictions, which we merge in texture space as the last step of our approach. Our results demonstrate that the recovered assets can be directly used for physically-based rendering and editing of real indoor scenes from any viewpoint and novel lighting. Our method generates approximate material maps in a fraction of time compared to the closest previous solutions.
* 17 pages
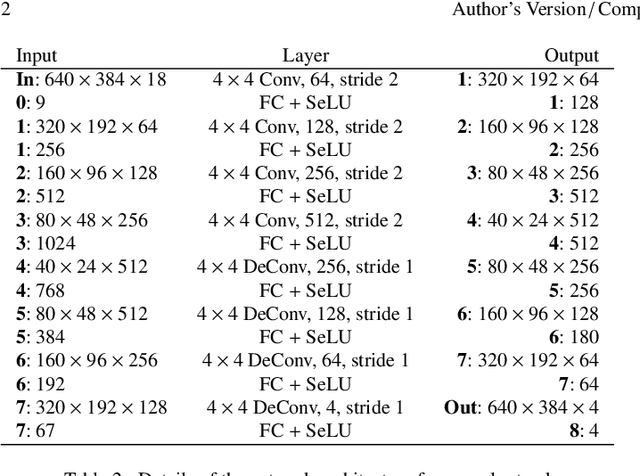
AgileAvatar: Stylized 3D Avatar Creation via Cascaded Domain Bridging
Nov 15, 2022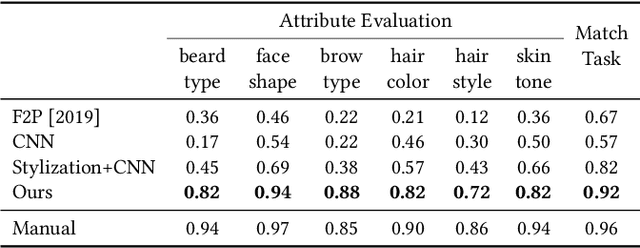
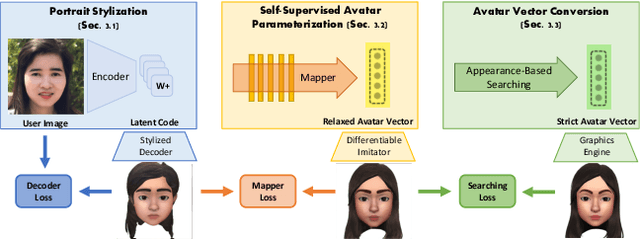


Stylized 3D avatars have become increasingly prominent in our modern life. Creating these avatars manually usually involves laborious selection and adjustment of continuous and discrete parameters and is time-consuming for average users. Self-supervised approaches to automatically create 3D avatars from user selfies promise high quality with little annotation cost but fall short in application to stylized avatars due to a large style domain gap. We propose a novel self-supervised learning framework to create high-quality stylized 3D avatars with a mix of continuous and discrete parameters. Our cascaded domain bridging framework first leverages a modified portrait stylization approach to translate input selfies into stylized avatar renderings as the targets for desired 3D avatars. Next, we find the best parameters of the avatars to match the stylized avatar renderings through a differentiable imitator we train to mimic the avatar graphics engine. To ensure we can effectively optimize the discrete parameters, we adopt a cascaded relaxation-and-search pipeline. We use a human preference study to evaluate how well our method preserves user identity compared to previous work as well as manual creation. Our results achieve much higher preference scores than previous work and close to those of manual creation. We also provide an ablation study to justify the design choices in our pipeline.
Improved techniques for deterministic l2 robustness
Nov 15, 2022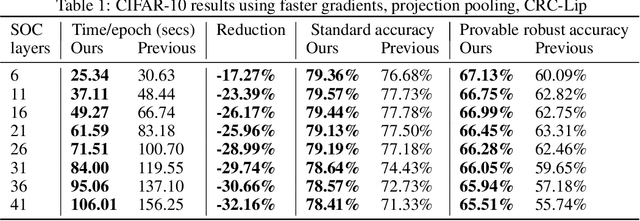


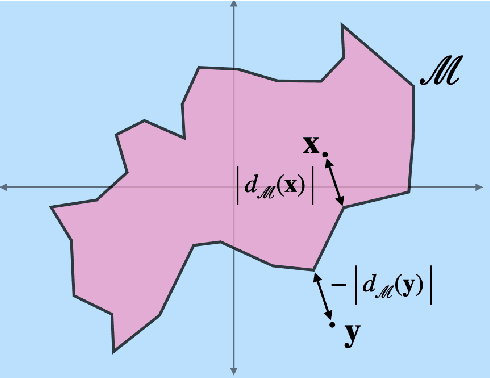
Training convolutional neural networks (CNNs) with a strict 1-Lipschitz constraint under the $l_{2}$ norm is useful for adversarial robustness, interpretable gradients and stable training. 1-Lipschitz CNNs are usually designed by enforcing each layer to have an orthogonal Jacobian matrix (for all inputs) to prevent the gradients from vanishing during backpropagation. However, their performance often significantly lags behind that of heuristic methods to enforce Lipschitz constraints where the resulting CNN is not \textit{provably} 1-Lipschitz. In this work, we reduce this gap by introducing (a) a procedure to certify robustness of 1-Lipschitz CNNs by replacing the last linear layer with a 1-hidden layer MLP that significantly improves their performance for both standard and provably robust accuracy, (b) a method to significantly reduce the training time per epoch for Skew Orthogonal Convolution (SOC) layers (>30\% reduction for deeper networks) and (c) a class of pooling layers using the mathematical property that the $l_{2}$ distance of an input to a manifold is 1-Lipschitz. Using these methods, we significantly advance the state-of-the-art for standard and provable robust accuracies on CIFAR-10 (gains of +1.79\% and +3.82\%) and similarly on CIFAR-100 (+3.78\% and +4.75\%) across all networks. Code is available at \url{https://github.com/singlasahil14/improved_l2_robustness}.
Predicting Eye Gaze Location on Websites
Nov 15, 2022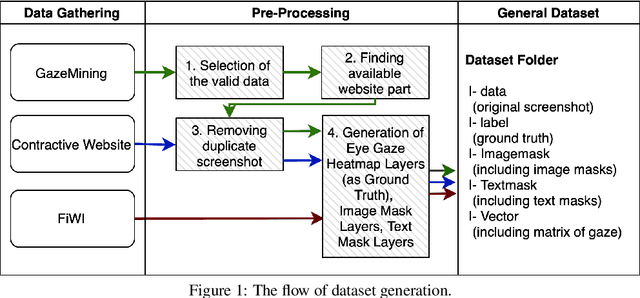
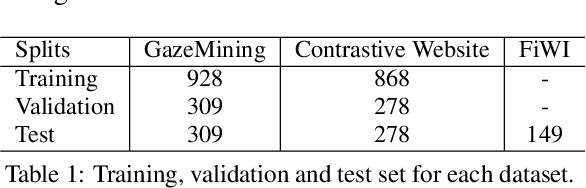
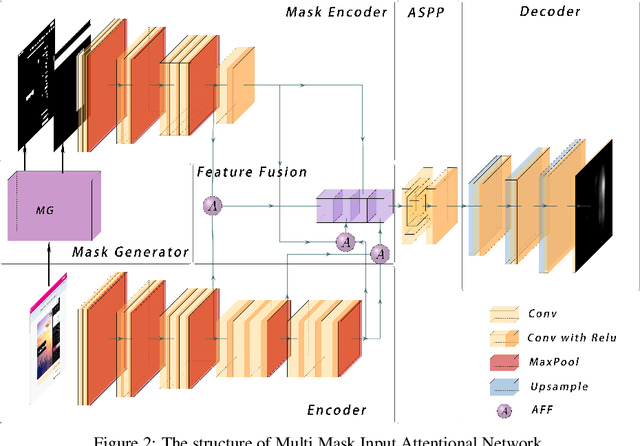
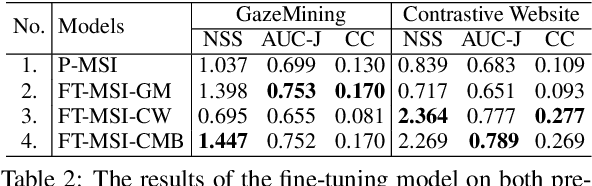
World-wide-web, with the website and webpage as the main interface, facilitates the dissemination of important information. Hence it is crucial to optimize them for better user interaction, which is primarily done by analyzing users' behavior, especially users' eye-gaze locations. However, gathering these data is still considered to be labor and time intensive. In this work, we enable the development of automatic eye-gaze estimations given a website screenshots as the input. This is done by the curation of a unified dataset that consists of website screenshots, eye-gaze heatmap and website's layout information in the form of image and text masks. Our pre-processed dataset allows us to propose an effective deep learning-based model that leverages both image and text spatial location, which is combined through attention mechanism for effective eye-gaze prediction. In our experiment, we show the benefit of careful fine-tuning using our unified dataset to improve the accuracy of eye-gaze predictions. We further observe the capability of our model to focus on the targeted areas (images and text) to achieve high accuracy. Finally, the comparison with other alternatives shows the state-of-the-art result of our model establishing the benchmark for the eye-gaze prediction task.