 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Detecting Invalid Map Merges in Lifelong SLAM
Nov 07, 2022
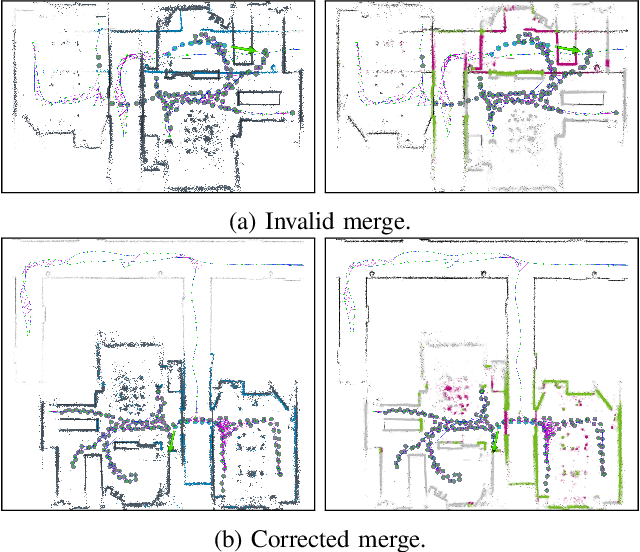
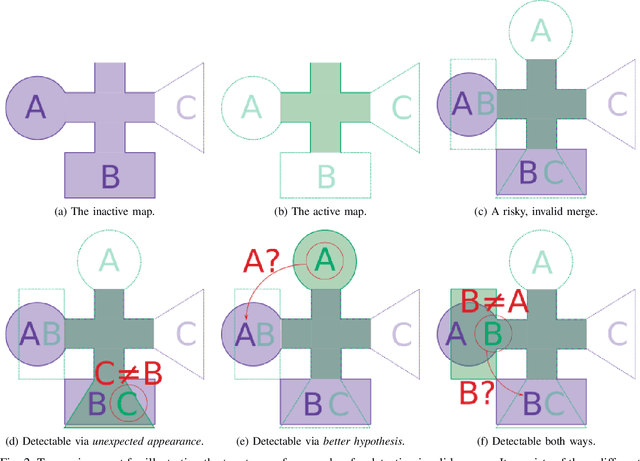
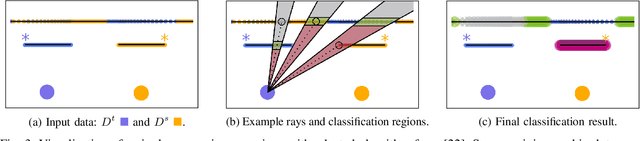

For Lifelong SLAM, one has to deal with temporary localization failures, e.g., induced by kidnapping. We achieve this by starting a new map and merging it with the previous map as soon as relocalization succeeds. Since relocalization methods are fallible, it can happen that such a merge is invalid, e.g., due to perceptual aliasing. To address this issue, we propose methods to detect and undo invalid merges. These methods compare incoming scans with scans that were previously merged into the current map and consider how well they agree with each other. Evaluation of our methods takes place using a dataset that consists of multiple flat and office environments, as well as the public MIT Stata Center dataset. We show that methods based on a change detection algorithm and on comparison of gridmaps perform well in both environments and can be run in real-time with a reasonable computational cost.
Video based Object 6D Pose Estimation using Transformers
Nov 07, 2022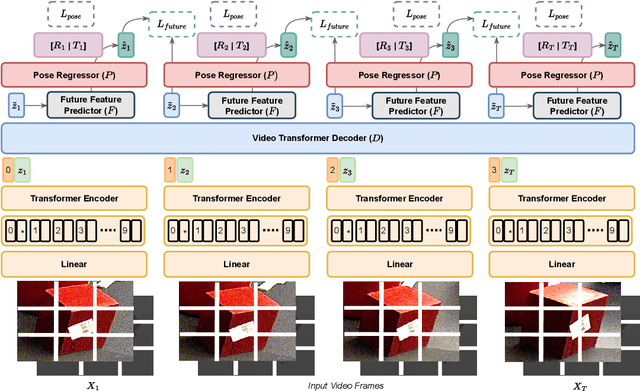

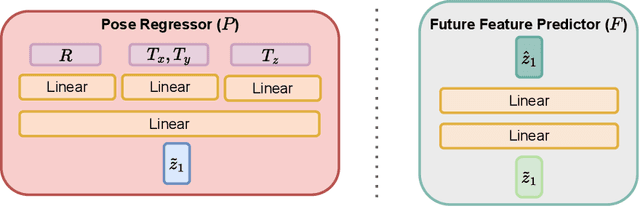
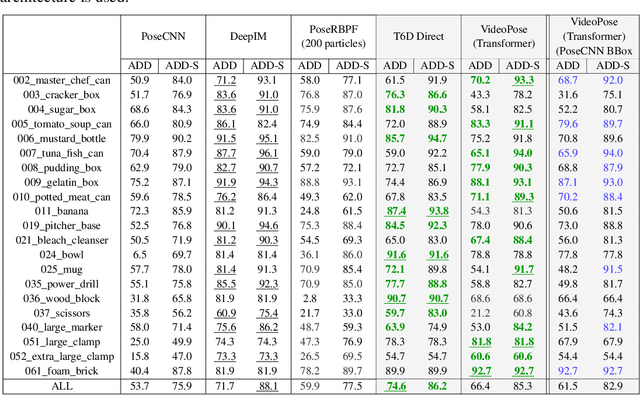
We introduce a Transformer based 6D Object Pose Estimation framework VideoPose, comprising an end-to-end attention based modelling architecture, that attends to previous frames in order to estimate accurate 6D Object Poses in videos. Our approach leverages the temporal information from a video sequence for pose refinement, along with being computationally efficient and robust. Compared to existing methods, our architecture is able to capture and reason from long-range dependencies efficiently, thus iteratively refining over video sequences. Experimental evaluation on the YCB-Video dataset shows that our approach is on par with the state-of-the-art Transformer methods, and performs significantly better relative to CNN based approaches. Further, with a speed of 33 fps, it is also more efficient and therefore applicable to a variety of applications that require real-time object pose estimation. Training code and pretrained models are available at https://github.com/ApoorvaBeedu/VideoPose
Uncertainty Quantification for Atlas-Level Cell Type Transfer
Nov 07, 2022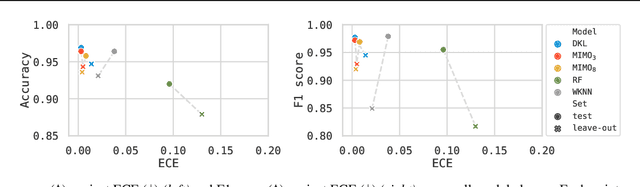
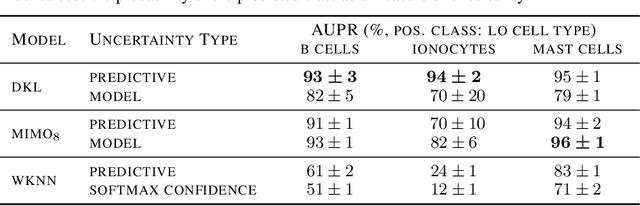
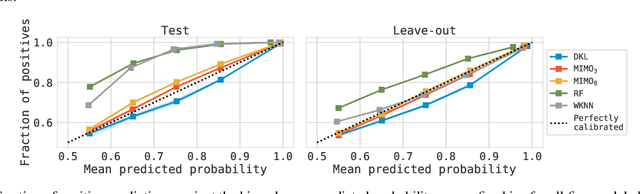

Single-cell reference atlases are large-scale, cell-level maps that capture cellular heterogeneity within an organ using single cell genomics. Given their size and cellular diversity, these atlases serve as high-quality training data for the transfer of cell type labels to new datasets. Such label transfer, however, must be robust to domain shifts in gene expression due to measurement technique, lab specifics and more general batch effects. This requires methods that provide uncertainty estimates on the cell type predictions to ensure correct interpretation. Here, for the first time, we introduce uncertainty quantification methods for cell type classification on single-cell reference atlases. We benchmark four model classes and show that currently used models lack calibration, robustness, and actionable uncertainty scores. Furthermore, we demonstrate how models that quantify uncertainty are better suited to detect unseen cell types in the setting of atlas-level cell type transfer.
Improving Robustness of Retrieval Augmented Translation via Shuffling of Suggestions
Oct 11, 2022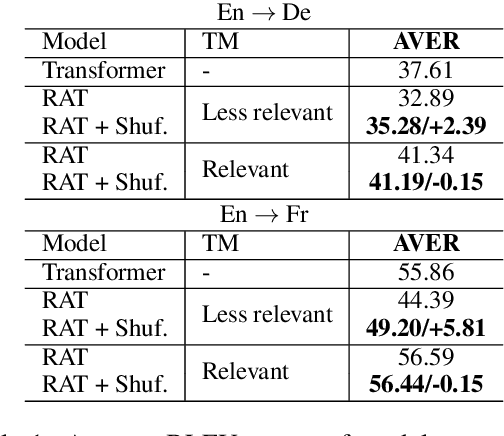
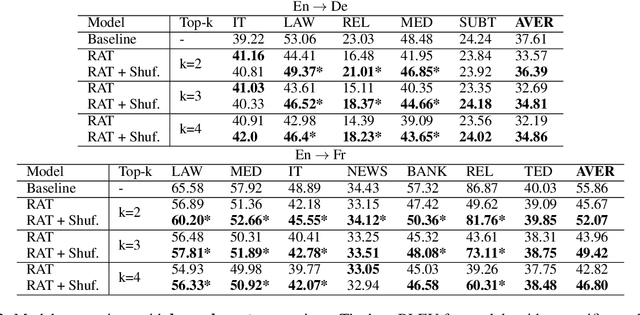
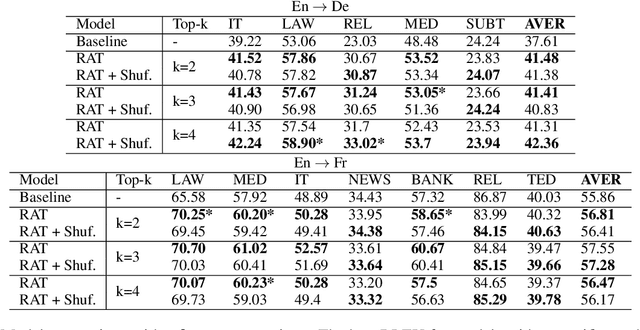

Several recent studies have reported dramatic performance improvements in neural machine translation (NMT) by augmenting translation at inference time with fuzzy-matches retrieved from a translation memory (TM). However, these studies all operate under the assumption that the TMs available at test time are highly relevant to the testset. We demonstrate that for existing retrieval augmented translation methods, using a TM with a domain mismatch to the test set can result in substantially worse performance compared to not using a TM at all. We propose a simple method to expose fuzzy-match NMT systems during training and show that it results in a system that is much more tolerant (regaining up to 5.8 BLEU) to inference with TMs with domain mismatch. Also, the model is still competitive to the baseline when fed with suggestions from relevant TMs.
Evolution TANN and the discovery of the internal variables and evolution equations in solid mechanics
Sep 27, 2022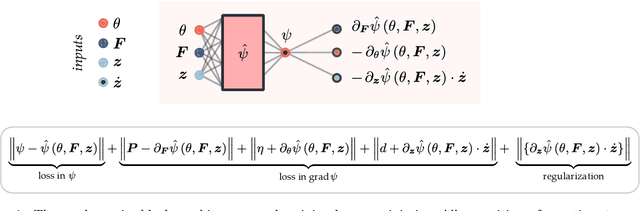
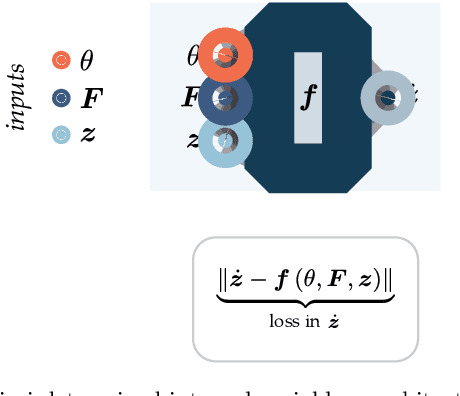
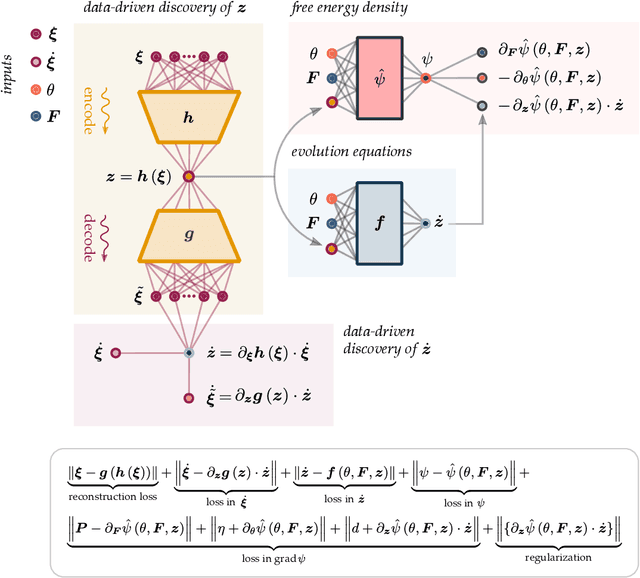
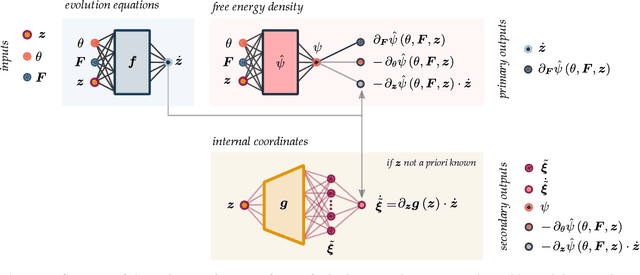
Data-driven and deep learning approaches have demonstrated to have the potential of replacing classical constitutive models for complex materials, displaying path-dependency and possessing multiple inherent scales. Yet, the necessity of structuring constitutive models with an incremental formulation has given rise to data-driven approaches where physical quantities, e.g. deformation, blend with artificial, non-physical ones, such as the increments in deformation and time. Neural networks and the consequent constitutive models depend, thus, on the particular incremental formulation, fail in identifying material representations locally in time, and suffer from poor generalization. Here, we propose a new approach which allows, for the first time, to decouple the material representation from the incremental formulation. Inspired by the Thermodynamics-based Artificial Neural Networks (TANN) and the theory of the internal variables, the evolution TANN (eTANN) are continuous-time, thus independent of the aforementioned artificial quantities. Key feature of the proposed approach is the discovery of the evolution equations of the internal variables in the form of ordinary differential equations, rather than in an incremental discrete-time form. In this work, we focus attention to juxtapose and show how the various general notions of solid mechanics are implemented in eTANN. The laws of thermodynamics are hardwired in the structure of the network and allow predictions which are always consistent. We propose a methodology that allows to discover, from data and first principles, admissible sets of internal variables from the microscopic fields in complex materials. The capabilities as well as the scalability of the proposed approach are demonstrated through several applications involving a broad spectrum of complex material behaviors, from plasticity to damage and viscosity.
Efficient Domain Coverage for Vehicles with Second Order Dynamics via Multi-Agent Reinforcement Learning
Nov 11, 2022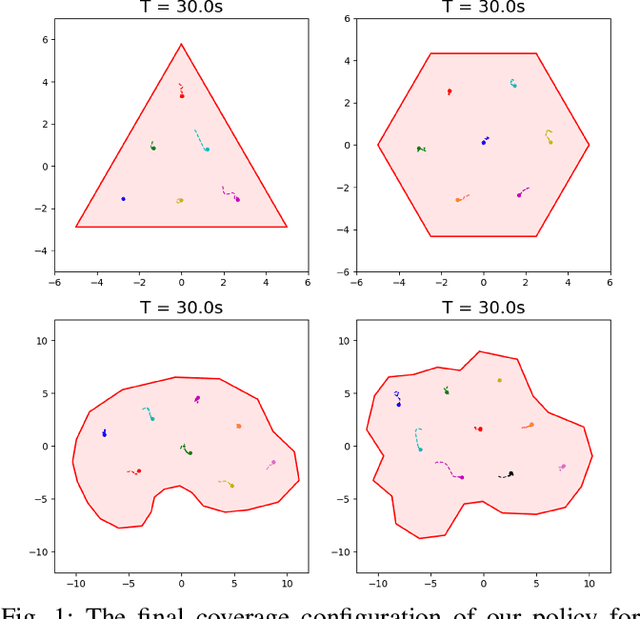
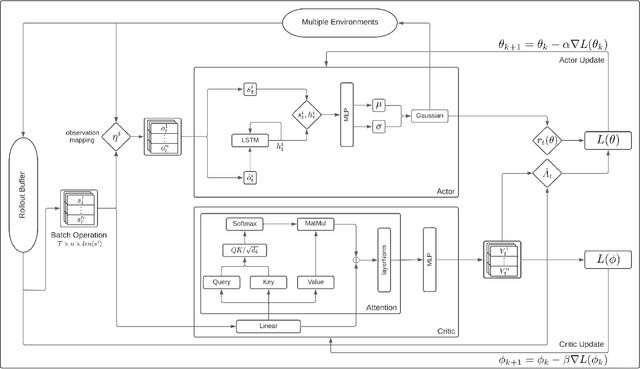
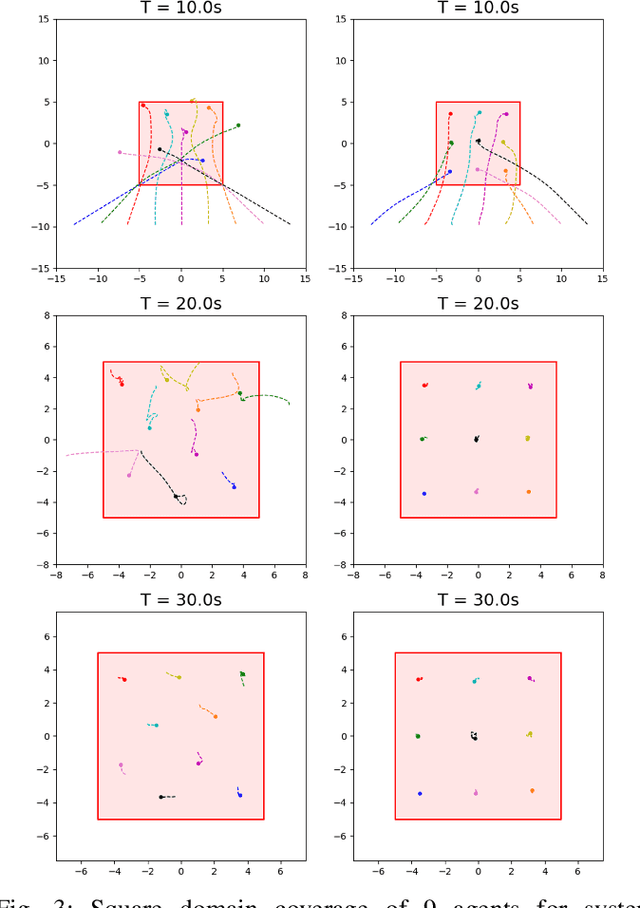
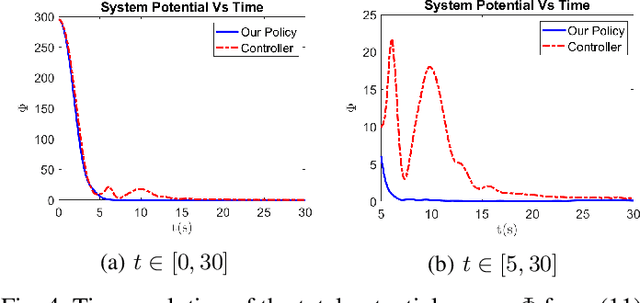
Collaborative autonomous multi-agent systems covering a specified area have many potential applications, such as UAV search and rescue, forest fire fighting, and real-time high-resolution monitoring. Traditional approaches for such coverage problems involve designing a model-based control policy based on sensor data. However, designing model-based controllers is challenging, and the state-of-the-art classical control policy still exhibits a large degree of suboptimality. In this paper, we present a reinforcement learning (RL) approach for the multi-agent coverage problem involving agents with second-order dynamics. Our approach is based on the Multi-Agent Proximal Policy Optimization Algorithm (MAPPO). To improve the stability of the learning-based policy and efficiency of exploration, we utilize an imitation loss based on the state-of-the-art classical control policy. Our trained policy significantly outperforms the state-of-the-art. Our proposed network architecture includes incorporation of self attention, which allows a single-shot domain transfer of the trained policy to a large variety of domain shapes and number of agents. We demonstrate our proposed method in a variety of simulated experiments.
GET-DIPP: Graph-Embedded Transformer for Differentiable Integrated Prediction and Planning
Nov 11, 2022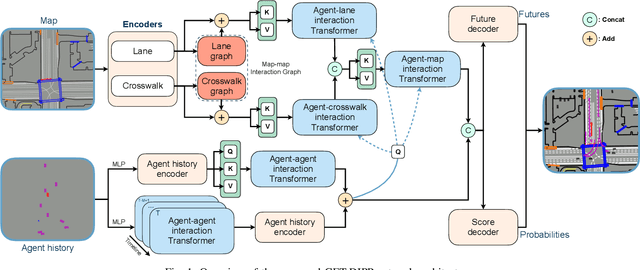
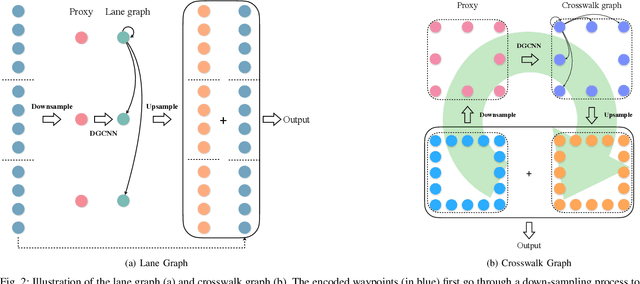
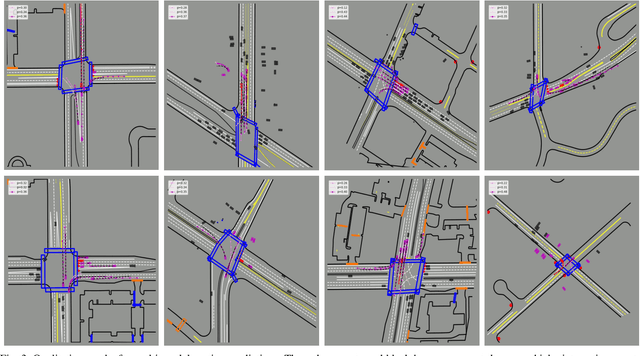
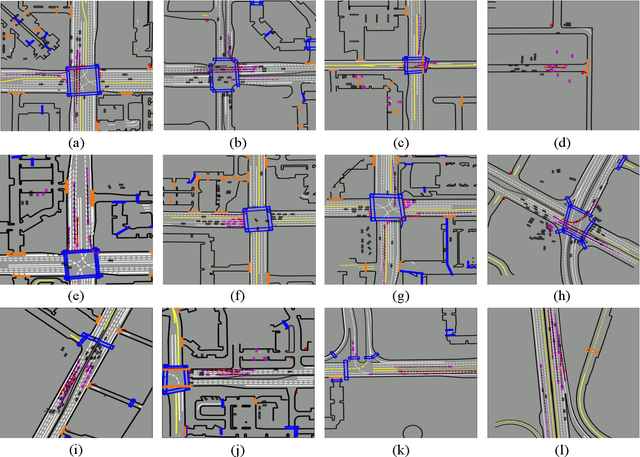
Accurately predicting interactive road agents' future trajectories and planning a socially compliant and human-like trajectory accordingly are important for autonomous vehicles. In this paper, we propose a planning-centric prediction neural network, which takes surrounding agents' historical states and map context information as input, and outputs the joint multi-modal prediction trajectories for surrounding agents, as well as a sequence of control commands for the ego vehicle by imitation learning. An agent-agent interaction module along the time axis is proposed in our network architecture to better comprehend the relationship among all the other intelligent agents on the road. To incorporate the map's topological information, a Dynamic Graph Convolutional Neural Network (DGCNN) is employed to process the road network topology. Besides, the whole architecture can serve as a backbone for the Differentiable Integrated motion Prediction with Planning (DIPP) method by providing accurate prediction results and initial planning commands. Experiments are conducted on real-world datasets to demonstrate the improvements made by our proposed method in both planning and prediction accuracy compared to the previous state-of-the-art methods.
Investigating Enhancements to Contrastive Predictive Coding for Human Activity Recognition
Nov 11, 2022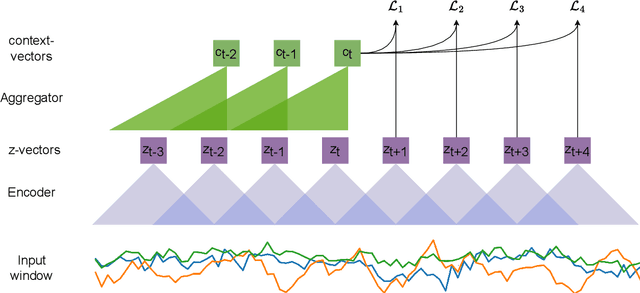
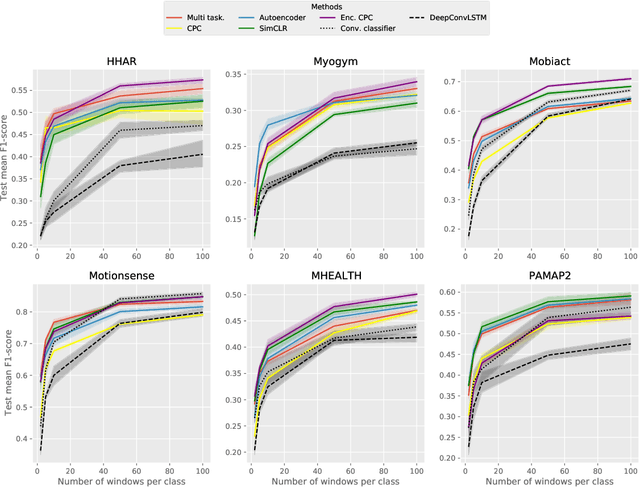
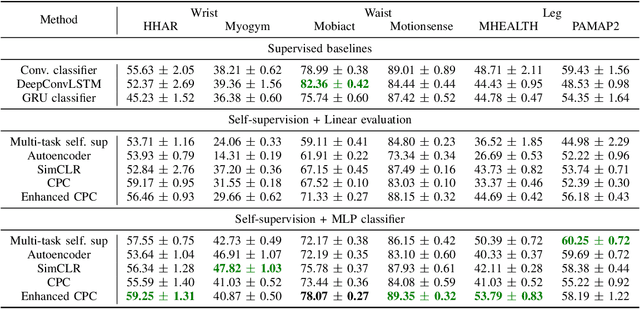

The dichotomy between the challenging nature of obtaining annotations for activities, and the more straightforward nature of data collection from wearables, has resulted in significant interest in the development of techniques that utilize large quantities of unlabeled data for learning representations. Contrastive Predictive Coding (CPC) is one such method, learning effective representations by leveraging properties of time-series data to setup a contrastive future timestep prediction task. In this work, we propose enhancements to CPC, by systematically investigating the encoder architecture, the aggregator network, and the future timestep prediction, resulting in a fully convolutional architecture, thereby improving parallelizability. Across sensor positions and activities, our method shows substantial improvements on four of six target datasets, demonstrating its ability to empower a wide range of application scenarios. Further, in the presence of very limited labeled data, our technique significantly outperforms both supervised and self-supervised baselines, positively impacting situations where collecting only a few seconds of labeled data may be possible. This is promising, as CPC does not require specialized data transformations or reconstructions for learning effective representations.
FinBERT-LSTM: Deep Learning based stock price prediction using News Sentiment Analysis
Nov 11, 2022
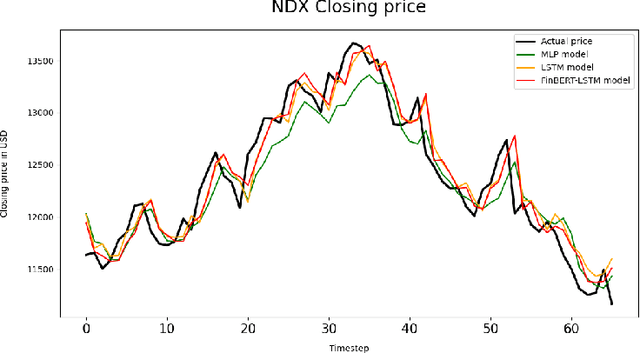
Economy is severely dependent on the stock market. An uptrend usually corresponds to prosperity while a downtrend correlates to recession. Predicting the stock market has thus been a centre of research and experiment for a long time. Being able to predict short term movements in the market enables investors to reap greater returns on their investments. Stock prices are extremely volatile and sensitive to financial market. In this paper we use Deep Learning networks to predict stock prices, assimilating financial, business and technology news articles which present information about the market. First, we create a simple Multilayer Perceptron (MLP) network and then expand into more complex Recurrent Neural Network (RNN) like Long Short Term Memory (LSTM), and finally propose FinBERT-LSTM model, which integrates news article sentiments to predict stock price with greater accuracy by analysing short-term market information. We then train the model on NASDAQ-100 index stock data and New York Times news articles to evaluate the performance of MLP, LSTM, FinBERT-LSTM models using mean absolute error (MAE), mean absolute percentage error (MAPE) and accuracy metrics.
High Speed Convoy in Unstructured Indoor Environments
Nov 11, 2022
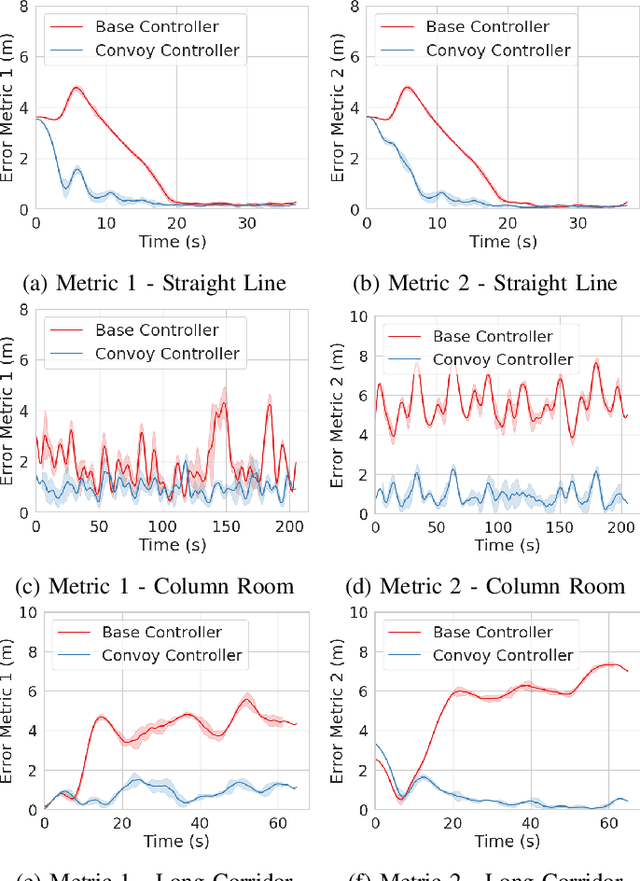
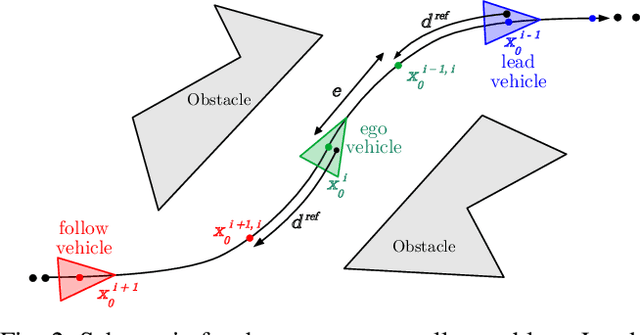
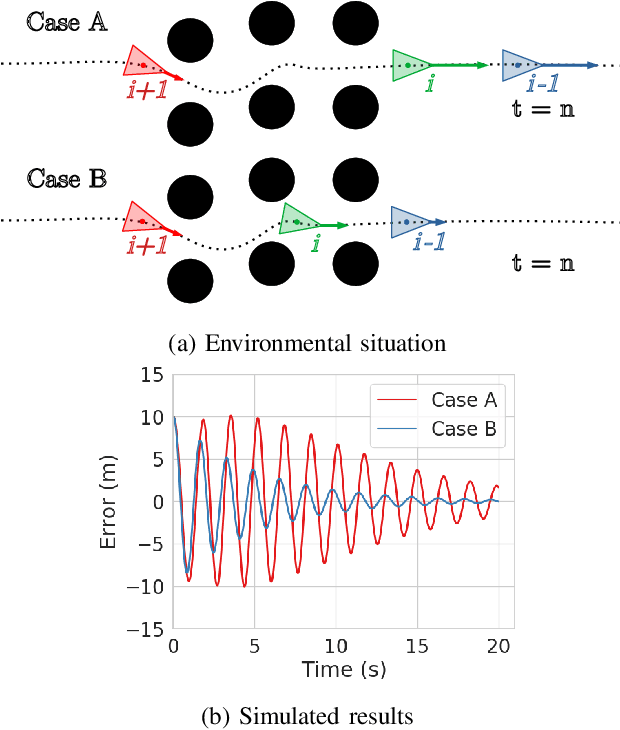
Practical operations of coordinated fleets of mobile robots in different environments reveal benefits of maintaining small distances between robots as they move at higher speeds. This is counter-intuitive in that as speed increases, increased distances would give robots a larger time to respond to sudden motion variations in surrounding robots. However, there is a desire to have lower inter-robot distances in examples like autonomous trucks on highways to optimize energy by vehicle drafting or smaller robots in cluttered environments to maintain communication, etc. This work introduces a model based control framework that directly takes non-linear system dynamics into account. Each robot is able to follow closer at high speeds because it makes predictions on the state information from its adjacent robots and biases it's response by anticipating adjacent robots' motion. In contrast to existing controllers, our non-linear model based predictive decentralized controller is able to achieve lower inter-robot distances at higher speeds. We demonstrate the success of our approach through simulated and hardware results on mobile ground robots.