 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Leveraging Heteroscedastic Uncertainty in Learning Complex Spectral Mapping for Single-channel Speech Enhancement
Nov 16, 2022
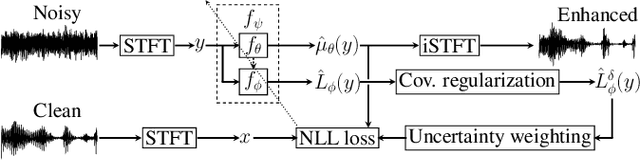
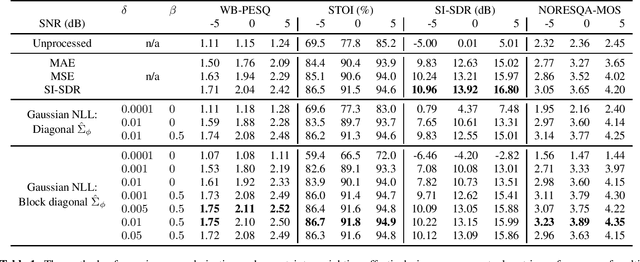
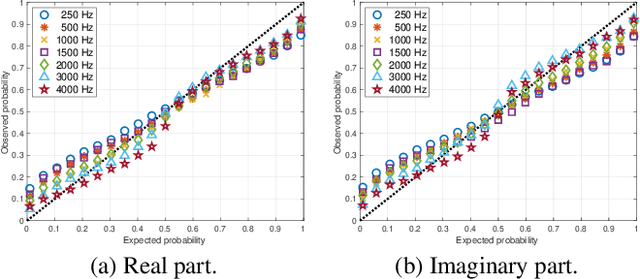
Most speech enhancement (SE) models learn a point estimate, and do not make use of uncertainty estimation in the learning process. In this paper, we show that modeling heteroscedastic uncertainty by minimizing a multivariate Gaussian negative log-likelihood (NLL) improves SE performance at no extra cost. During training, our approach augments a model learning complex spectral mapping with a temporary submodel to predict the covariance of the enhancement error at each time-frequency bin. Due to unrestricted heteroscedastic uncertainty, the covariance introduces an undersampling effect, detrimental to SE performance. To mitigate undersampling, our approach inflates the uncertainty lower bound and weights each loss component with their uncertainty, effectively compensating severely undersampled components with more penalties. Our multivariate setting reveals common covariance assumptions such as scalar and diagonal matrices. By weakening these assumptions, we show that the NLL achieves superior performance compared to popular losses including the mean squared error (MSE), mean absolute error (MAE), and scale-invariant signal-to-distortion ratio (SI-SDR).
Energy Reconstruction in Analysis of Cherenkov Telescopes Images in TAIGA Experiment Using Deep Learning Methods
Nov 16, 2022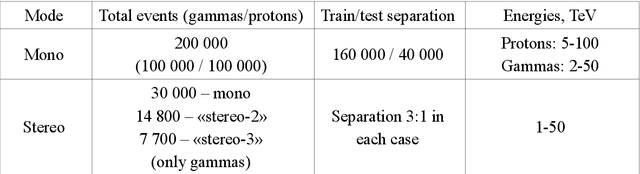
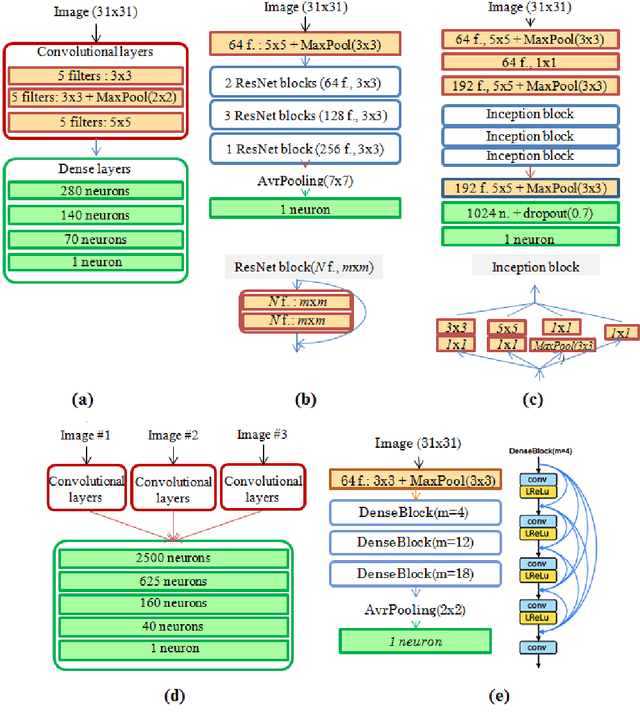
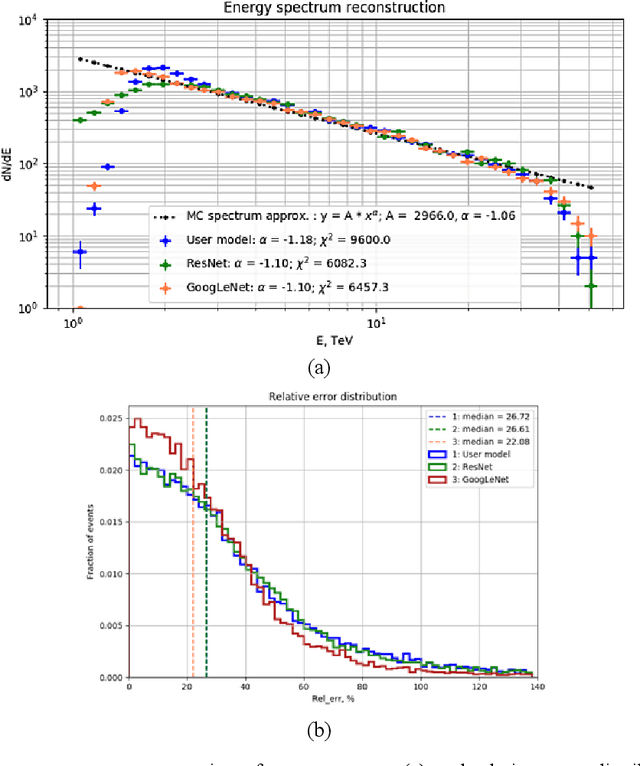
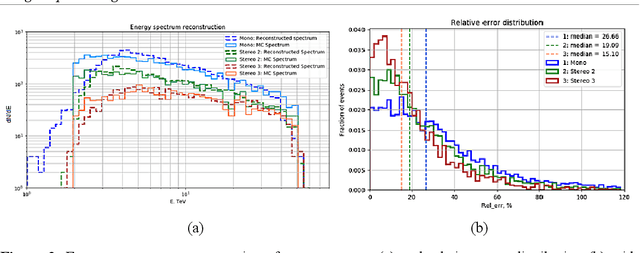
Imaging Atmospheric Cherenkov Telescopes (IACT) of TAIGA astrophysical complex allow to observe high energy gamma radiation helping to study many astrophysical objects and processes. TAIGA-IACT enables us to select gamma quanta from the total cosmic radiation flux and recover their primary parameters, such as energy and direction of arrival. The traditional method of processing the resulting images is an image parameterization - so-called the Hillas parameters method. At the present time Machine Learning methods, in particular Deep Learning methods have become actively used for IACT image processing. This paper presents the analysis of simulated Monte Carlo images by several Deep Learning methods for a single telescope (mono-mode) and multiple IACT telescopes (stereo-mode). The estimation of the quality of energy reconstruction was carried out and their energy spectra were analyzed using several types of neural networks. Using the developed methods the obtained results were also compared with the results obtained by traditional methods based on the Hillas parameters.
Beyond Ensemble Averages: Leveraging Climate Model Ensembles for Subseasonal Forecasting
Nov 29, 2022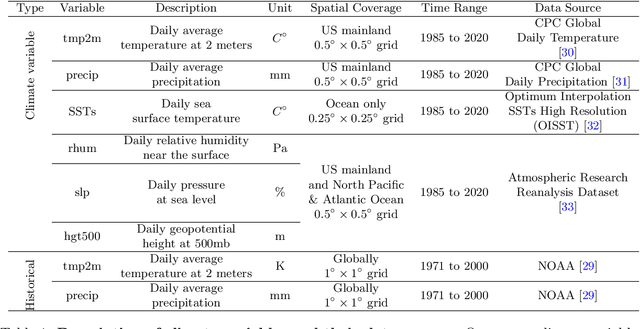
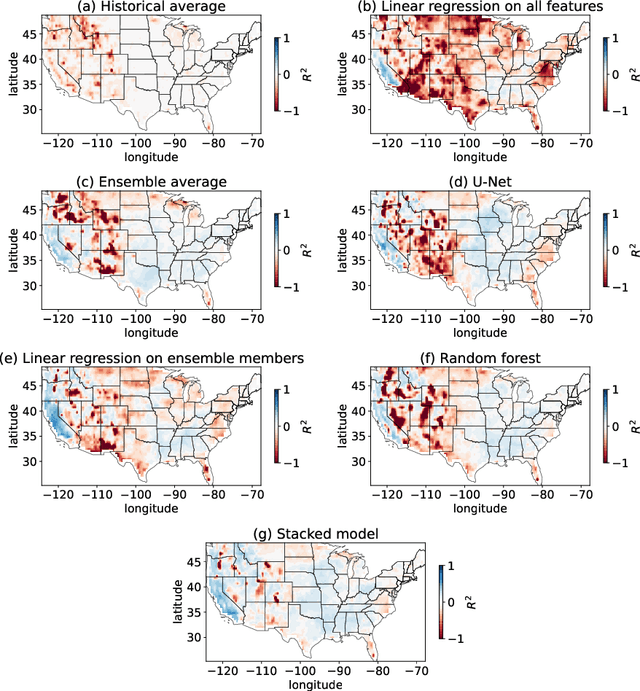

Producing high-quality forecasts of key climate variables such as temperature and precipitation on subseasonal time scales has long been a gap in operational forecasting. Recent studies have shown promising results using machine learning (ML) models to advance subseasonal forecasting (SSF), but several open questions remain. First, several past approaches use the average of an ensemble of physics-based forecasts as an input feature of these models. However, ensemble forecasts contain information that can aid prediction beyond only the ensemble mean. Second, past methods have focused on average performance, whereas forecasts of extreme events are far more important for planning and mitigation purposes. Third, climate forecasts correspond to a spatially-varying collection of forecasts, and different methods account for spatial variability in the response differently. Trade-offs between different approaches may be mitigated with model stacking. This paper describes the application of a variety of ML methods used to predict monthly average precipitation and two meter temperature using physics-based predictions (ensemble forecasts) and observational data such as relative humidity, pressure at sea level, or geopotential height, two weeks in advance for the whole continental United States. Regression, quantile regression, and tercile classification tasks using linear models, random forests, convolutional neural networks, and stacked models are considered. The proposed models outperform common baselines such as historical averages (or quantiles) and ensemble averages (or quantiles). This paper further includes an investigation of feature importance, trade-offs between using the full ensemble or only the ensemble average, and different modes of accounting for spatial variability.
Will My Robot Achieve My Goals? Predicting the Probability that an MDP Policy Reaches a User-Specified Behavior Target
Nov 29, 2022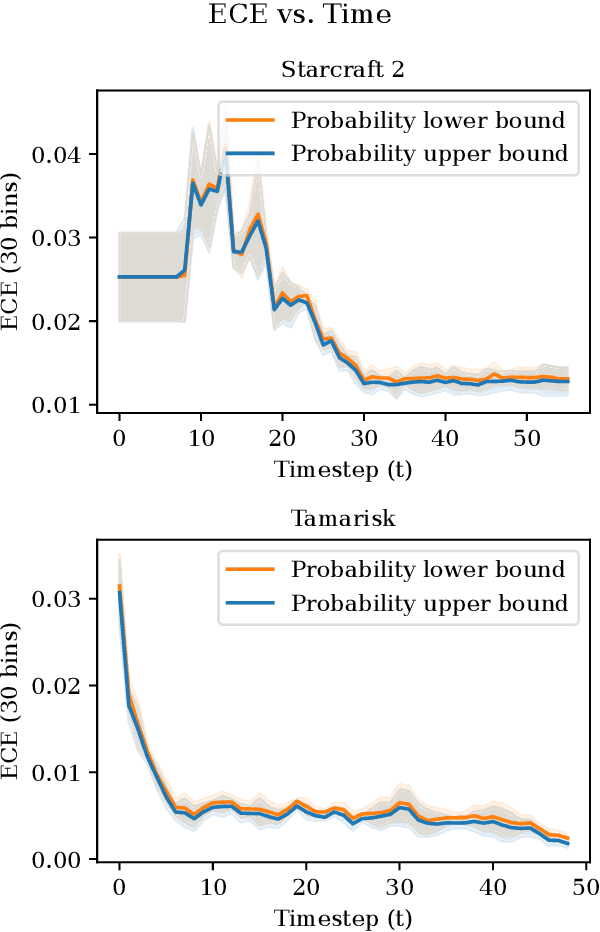
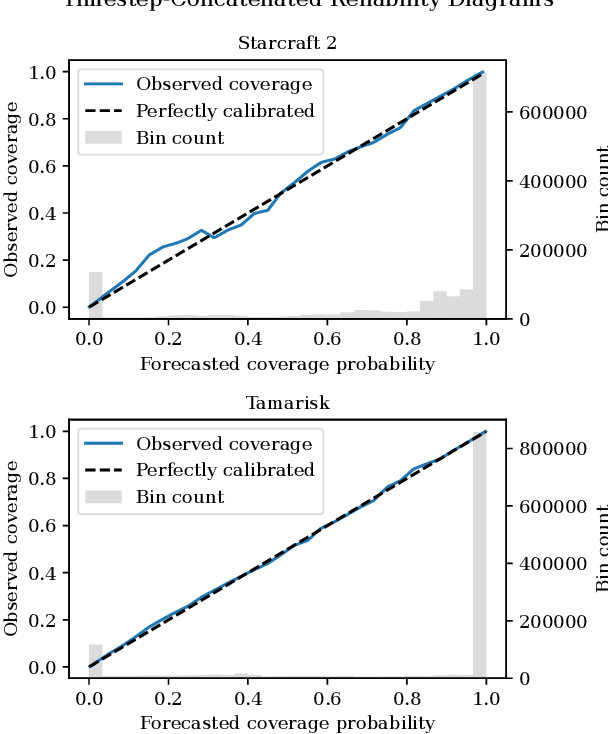
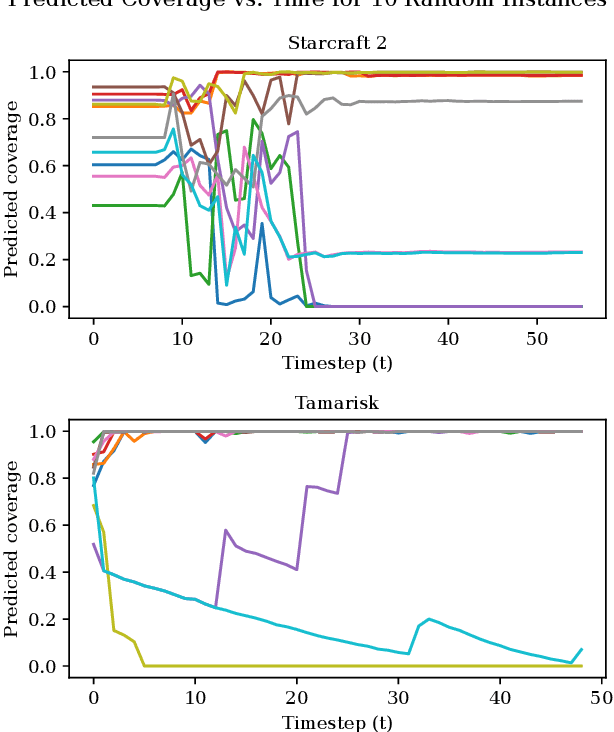
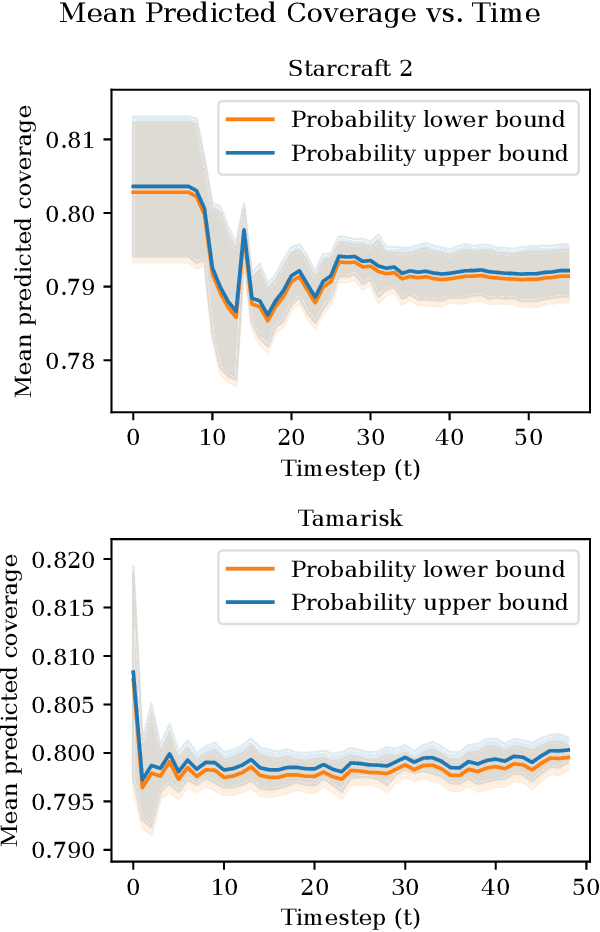
As an autonomous system performs a task, it should maintain a calibrated estimate of the probability that it will achieve the user's goal. If that probability falls below some desired level, it should alert the user so that appropriate interventions can be made. This paper considers settings where the user's goal is specified as a target interval for a real-valued performance summary, such as the cumulative reward, measured at a fixed horizon $H$. At each time $t \in \{0, \ldots, H-1\}$, our method produces a calibrated estimate of the probability that the final cumulative reward will fall within a user-specified target interval $[y^-,y^+].$ Using this estimate, the autonomous system can raise an alarm if the probability drops below a specified threshold. We compute the probability estimates by inverting conformal prediction. Our starting point is the Conformalized Quantile Regression (CQR) method of Romano et al., which applies split-conformal prediction to the results of quantile regression. CQR is not invertible, but by using the conditional cumulative distribution function (CDF) as the non-conformity measure, we show how to obtain an invertible modification that we call \textbf{P}robability-space \textbf{C}onformalized \textbf{Q}uantile \textbf{R}egression (PCQR). Like CQR, PCQR produces well-calibrated conditional prediction intervals with finite-sample marginal guarantees. By inverting PCQR, we obtain marginal guarantees for the probability that the cumulative reward of an autonomous system will fall within an arbitrary user-specified target intervals. Experiments on two domains confirm that these probabilities are well-calibrated.
Two Is Better Than One: Dual Embeddings for Complementary Product Recommendations
Nov 29, 2022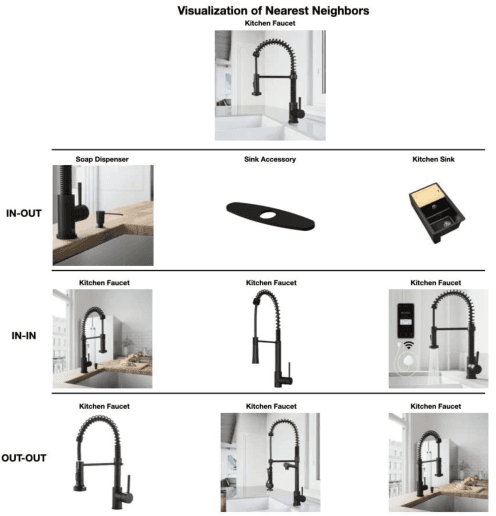
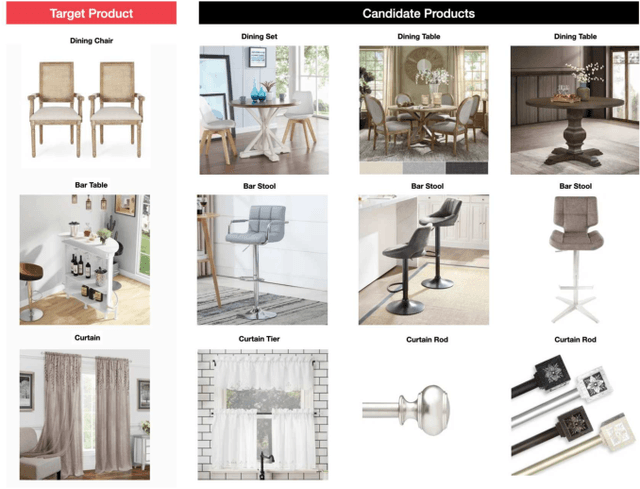

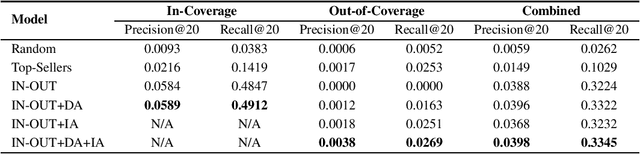
Embedding based product recommendations have gained popularity in recent years due to its ability to easily integrate to large-scale systems and allowing nearest neighbor searches in real-time. The bulk of studies in this area has predominantly been focused on similar item recommendations. Research on complementary item recommendations, on the other hand, still remains considerably under-explored. We define similar items as items that are interchangeable in terms of their utility and complementary items as items that serve different purposes, yet are compatible when used with one another. In this paper, we apply a novel approach to finding complementary items by leveraging dual embedding representations for products. We demonstrate that the notion of relatedness discovered in NLP for skip-gram negative sampling (SGNS) models translates effectively to the concept of complementarity when training item representations using co-purchase data. Since sparsity of purchase data is a major challenge in real-world scenarios, we further augment the model using synthetic samples to extend coverage. This allows the model to provide complementary recommendations for items that do not share co-purchase data by leveraging other abundantly available data modalities such as images, text, clicks etc. We establish the effectiveness of our approach in improving both coverage and quality of recommendations on real world data for a major online retail company. We further show the importance of task specific hyperparameter tuning in training SGNS. Our model is effective yet simple to implement, making it a great candidate for generating complementary item recommendations at any e-commerce website.
N-Gram in Swin Transformers for Efficient Lightweight Image Super-Resolution
Nov 21, 2022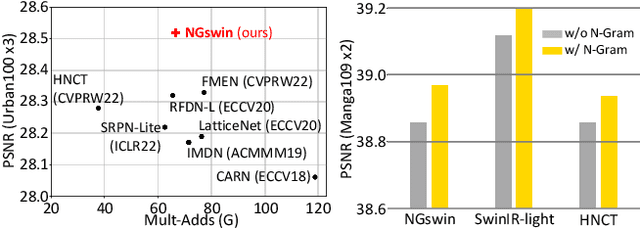
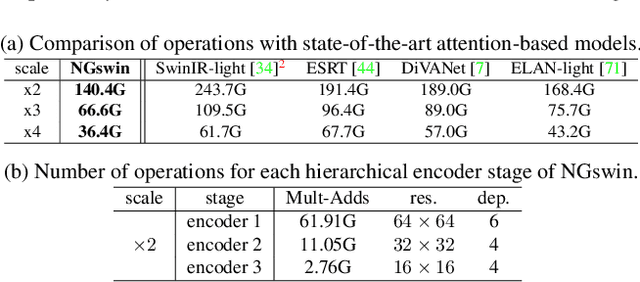
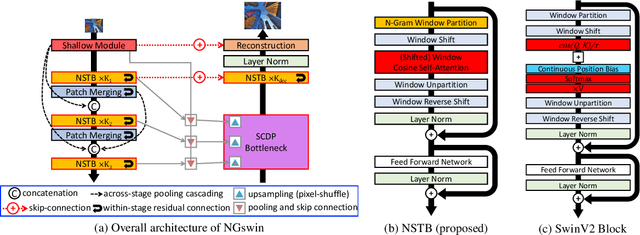
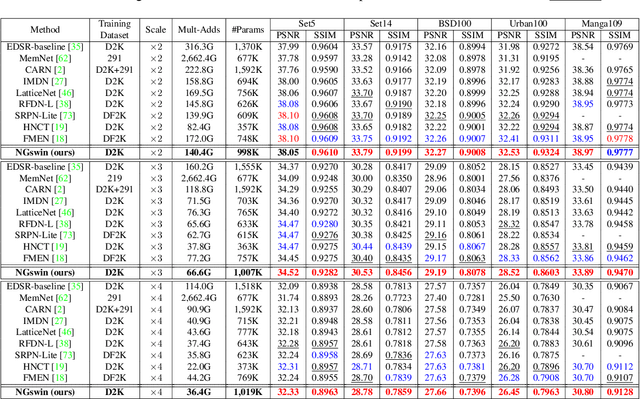
While some studies have proven that Swin Transformer (SwinT) with window self-attention (WSA) is suitable for single image super-resolution (SR), SwinT ignores the broad regions for reconstructing high-resolution images due to window and shift size. In addition, many deep learning SR methods suffer from intensive computations. To address these problems, we introduce the N-Gram context to the image domain for the first time in history. We define N-Gram as neighboring local windows in SwinT, which differs from text analysis that views N-Gram as consecutive characters or words. N-Grams interact with each other by sliding-WSA, expanding the regions seen to restore degraded pixels. Using the N-Gram context, we propose NGswin, an efficient SR network with SCDP bottleneck taking all outputs of the hierarchical encoder. Experimental results show that NGswin achieves competitive performance while keeping an efficient structure, compared with previous leading methods. Moreover, we also improve other SwinT-based SR methods with the N-Gram context, thereby building an enhanced model: SwinIR-NG. Our improved SwinIR-NG outperforms the current best lightweight SR approaches and establishes state-of-the-art results. Codes will be available soon.
Crowdsensing-based Road Damage Detection Challenge (CRDDC-2022)
Nov 21, 2022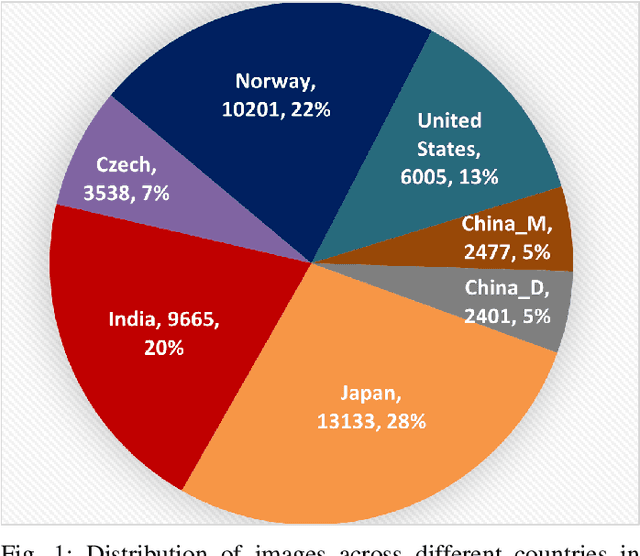
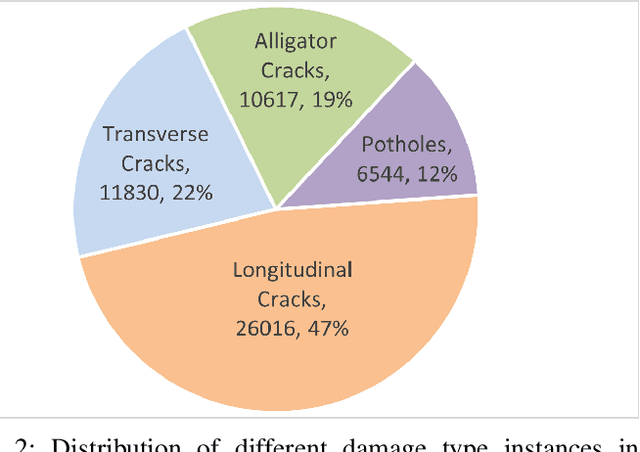

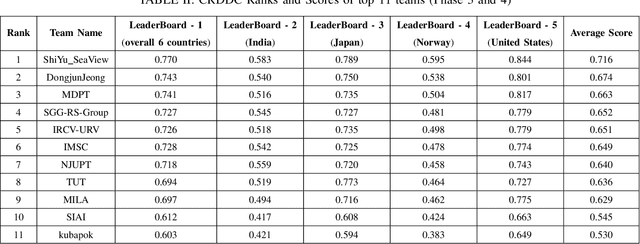
This paper summarizes the Crowdsensing-based Road Damage Detection Challenge (CRDDC), a Big Data Cup organized as a part of the IEEE International Conference on Big Data'2022. The Big Data Cup challenges involve a released dataset and a well-defined problem with clear evaluation metrics. The challenges run on a data competition platform that maintains a real-time online evaluation system for the participants. In the presented case, the data constitute 47,420 road images collected from India, Japan, the Czech Republic, Norway, the United States, and China to propose methods for automatically detecting road damages in these countries. More than 60 teams from 19 countries registered for this competition. The submitted solutions were evaluated using five leaderboards based on performance for unseen test images from the aforementioned six countries. This paper encapsulates the top 11 solutions proposed by these teams. The best-performing model utilizes ensemble learning based on YOLO and Faster-RCNN series models to yield an F1 score of 76% for test data combined from all 6 countries. The paper concludes with a comparison of current and past challenges and provides direction for the future.
Evaluating the Knowledge Dependency of Questions
Nov 21, 2022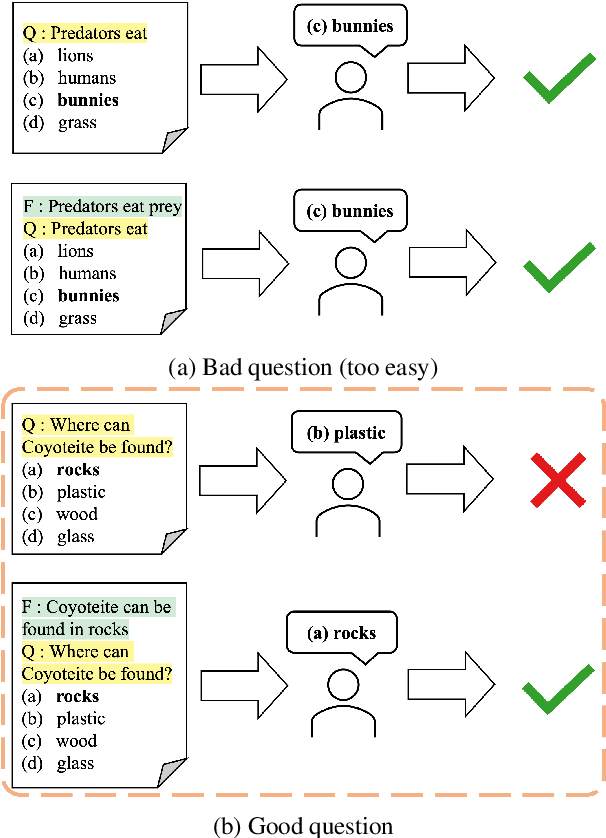

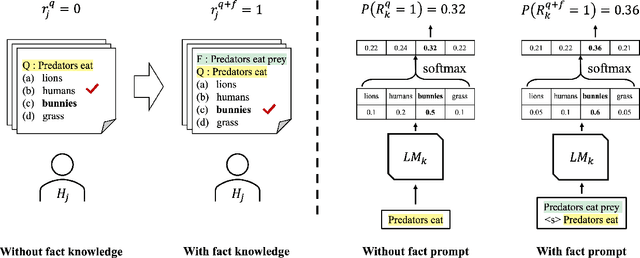
The automatic generation of Multiple Choice Questions (MCQ) has the potential to reduce the time educators spend on student assessment significantly. However, existing evaluation metrics for MCQ generation, such as BLEU, ROUGE, and METEOR, focus on the n-gram based similarity of the generated MCQ to the gold sample in the dataset and disregard their educational value. They fail to evaluate the MCQ's ability to assess the student's knowledge of the corresponding target fact. To tackle this issue, we propose a novel automatic evaluation metric, coined Knowledge Dependent Answerability (KDA), which measures the MCQ's answerability given knowledge of the target fact. Specifically, we first show how to measure KDA based on student responses from a human survey. Then, we propose two automatic evaluation metrics, KDA_disc and KDA_cont, that approximate KDA by leveraging pre-trained language models to imitate students' problem-solving behavior. Through our human studies, we show that KDA_disc and KDA_soft have strong correlations with both (1) KDA and (2) usability in an actual classroom setting, labeled by experts. Furthermore, when combined with n-gram based similarity metrics, KDA_disc and KDA_cont are shown to have a strong predictive power for various expert-labeled MCQ quality measures.
Coordinate-Based Seismic Interpolation in Irregular Land Survey: A Deep Internal Learning Approach
Nov 21, 2022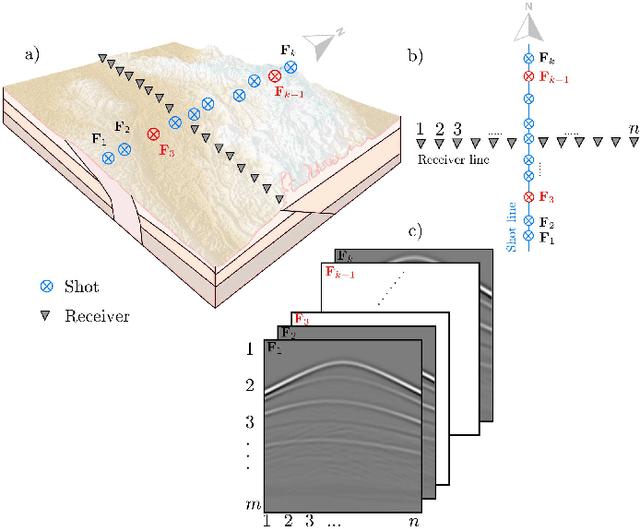
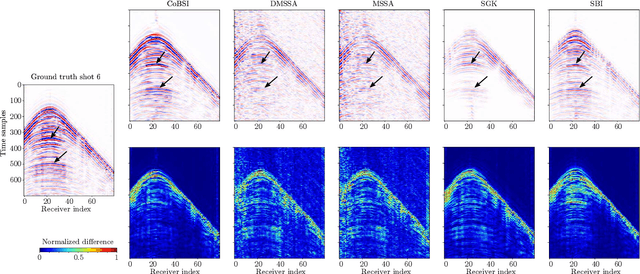
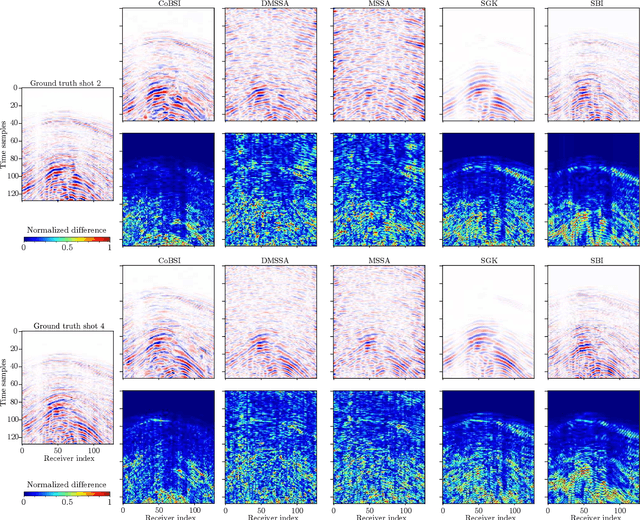

Physical and budget constraints often result in irregular sampling, which complicates accurate subsurface imaging. Pre-processing approaches, such as missing trace or shot interpolation, are typically employed to enhance seismic data in such cases. Recently, deep learning has been used to address the trace interpolation problem at the expense of large amounts of training data to adequately represent typical seismic events. Nonetheless, state-of-the-art works have mainly focused on trace reconstruction, with little attention having been devoted to shot interpolation. Furthermore, existing methods assume regularly spaced receivers/sources failing in approximating seismic data from real (irregular) surveys. This work presents a novel shot gather interpolation approach which uses a continuous coordinate-based representation of the acquired seismic wavefield parameterized by a neural network. The proposed unsupervised approach, which we call coordinate-based seismic interpolation (CoBSI), enables the prediction of specific seismic characteristics in irregular land surveys without using external data during neural network training. Experimental results on real and synthetic 3D data validate the ability of the proposed method to estimate continuous smooth seismic events in the time-space and frequency-wavenumber domains, improving sparsity or low rank-based interpolation methods.
Machine-learned climate model corrections from a global storm-resolving model
Nov 21, 2022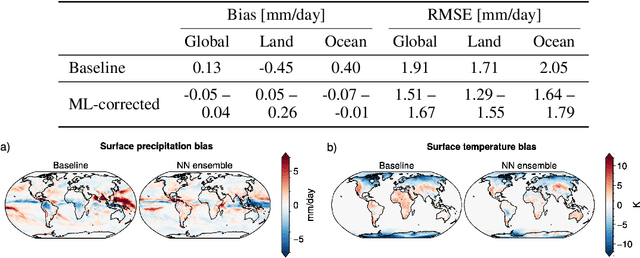
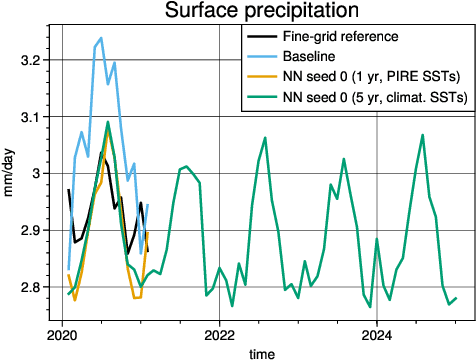

Due to computational constraints, running global climate models (GCMs) for many years requires a lower spatial grid resolution (${\gtrsim}50$ km) than is optimal for accurately resolving important physical processes. Such processes are approximated in GCMs via subgrid parameterizations, which contribute significantly to the uncertainty in GCM predictions. One approach to improving the accuracy of a coarse-grid global climate model is to add machine-learned state-dependent corrections at each simulation timestep, such that the climate model evolves more like a high-resolution global storm-resolving model (GSRM). We train neural networks to learn the state-dependent temperature, humidity, and radiative flux corrections needed to nudge a 200 km coarse-grid climate model to the evolution of a 3~km fine-grid GSRM. When these corrective ML models are coupled to a year-long coarse-grid climate simulation, the time-mean spatial pattern errors are reduced by 6-25% for land surface temperature and 9-25% for land surface precipitation with respect to a no-ML baseline simulation. The ML-corrected simulations develop other biases in climate and circulation that differ from, but have comparable amplitude to, the baseline simulation.