 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A policy gradient approach for Finite Horizon Constrained Markov Decision Processes
Oct 10, 2022
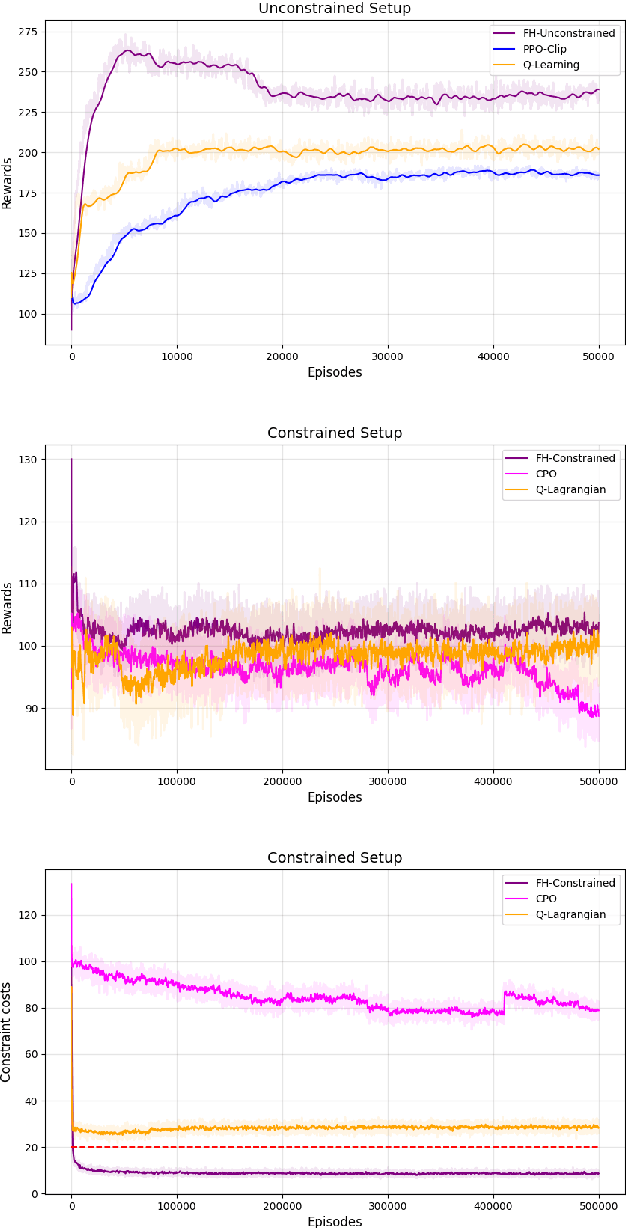
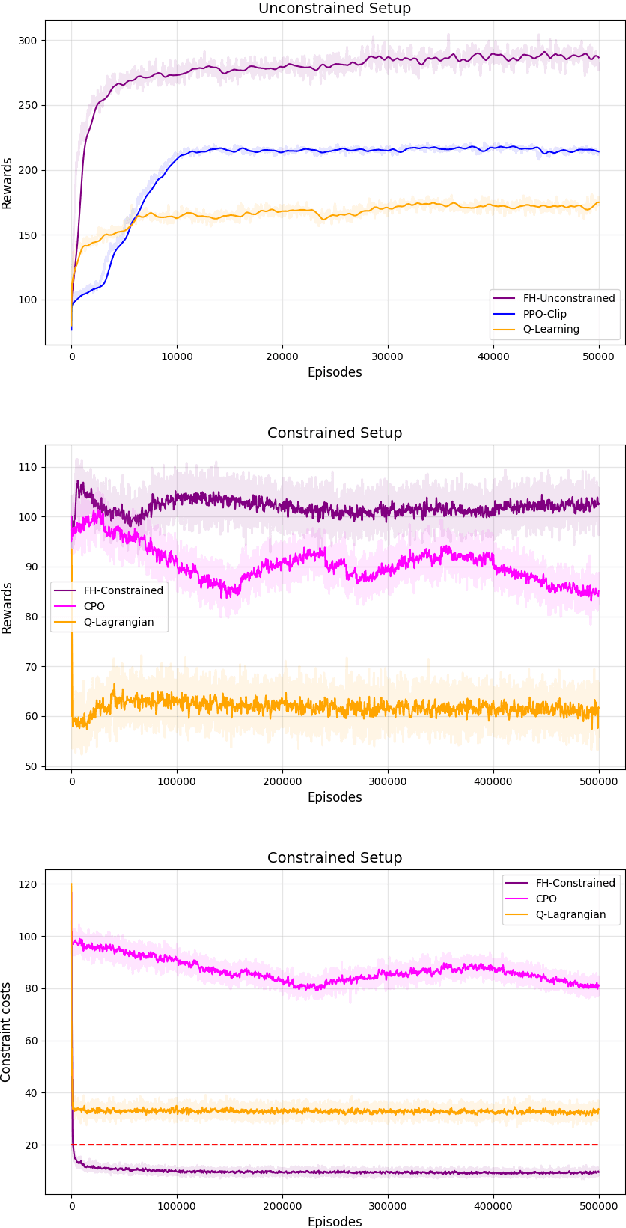
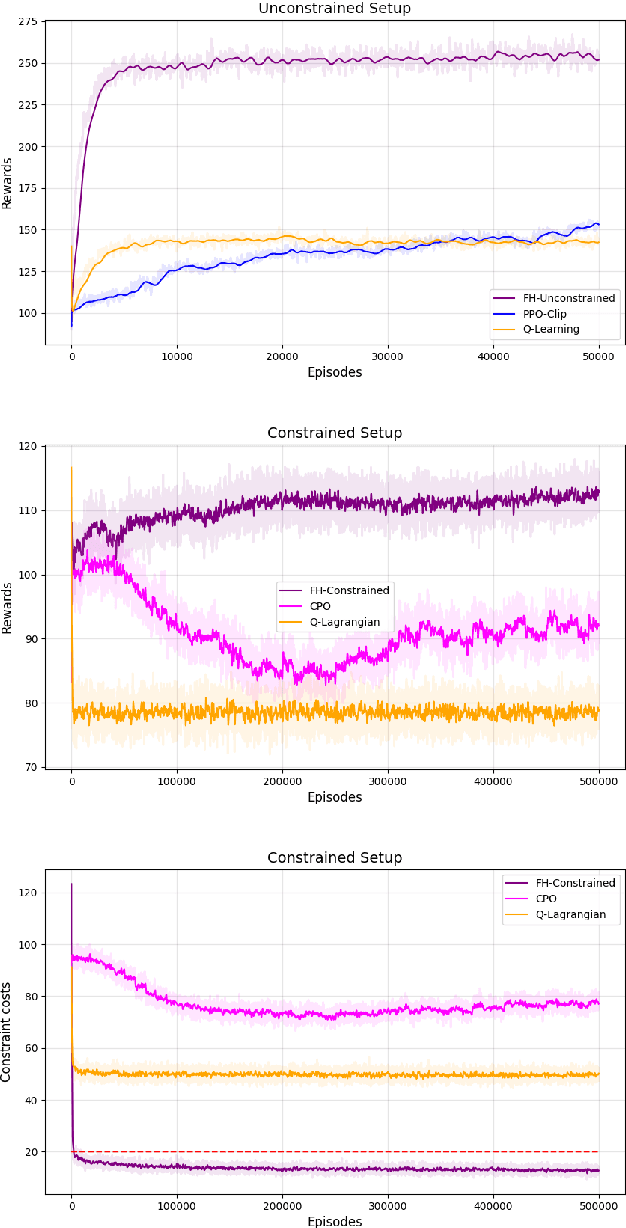
The infinite horizon setting is widely adopted for problems of reinforcement learning (RL). These invariably result in stationary policies that are optimal. In many situations, finite horizon control problems are of interest and for such problems, the optimal policies are time-varying in general. Another setting that has become popular in recent times is of Constrained Reinforcement Learning, where the agent maximizes its rewards while also aims to satisfy certain constraint criteria. However, this setting has only been studied in the context of infinite horizon MDPs where stationary policies are optimal. We present, for the first time, an algorithm for constrained RL in the Finite Horizon Setting where the horizon terminates after a fixed (finite) time. We use function approximation in our algorithm which is essential when the state and action spaces are large or continuous and use the policy gradient method to find the optimal policy. The optimal policy that we obtain depends on the stage and so is time-dependent. To the best of our knowledge, our paper presents the first policy gradient algorithm for the finite horizon setting with constraints. We show the convergence of our algorithm to an optimal policy. We further present a sample complexity result for our algorithm in the unconstrained (i.e., the regular finite horizon MDP) setting. We also compare and analyze the performance of our algorithm through experiments and show that our algorithm performs better than other well known algorithms.
A Differential Attention Fusion Model Based on Transformer for Time Series Forecasting
Feb 23, 2022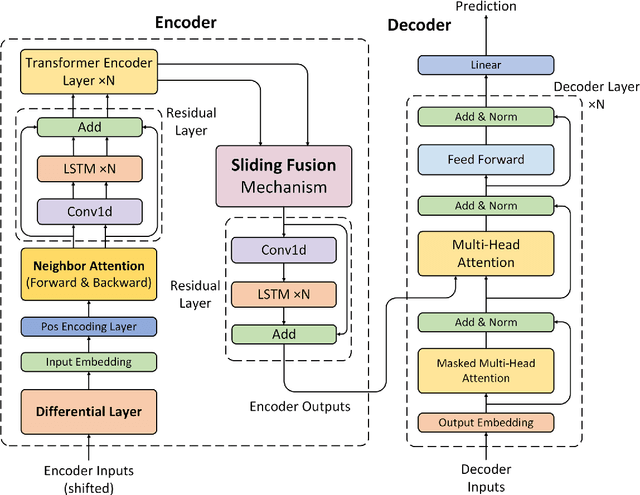
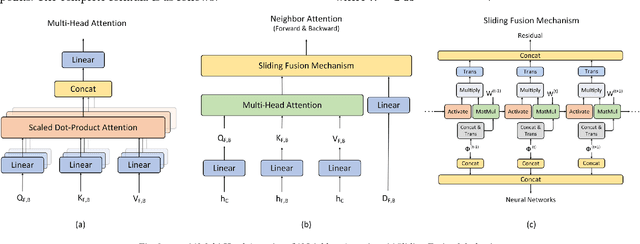
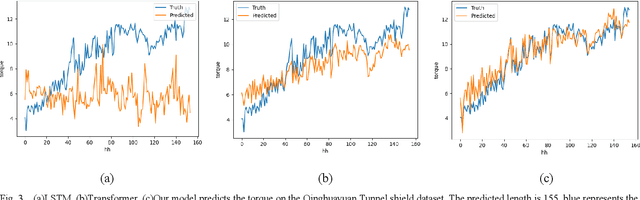
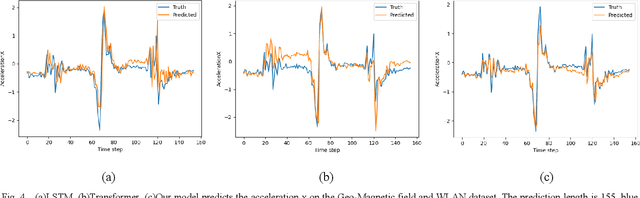
Time series forecasting is widely used in the fields of equipment life cycle forecasting, weather forecasting, traffic flow forecasting, and other fields. Recently, some scholars have tried to apply Transformer to time series forecasting because of its powerful parallel training ability. However, the existing Transformer methods do not pay enough attention to the small time segments that play a decisive role in prediction, making it insensitive to small changes that affect the trend of time series, and it is difficult to effectively learn continuous time-dependent features. To solve this problem, we propose a differential attention fusion model based on Transformer, which designs the differential layer, neighbor attention, sliding fusion mechanism, and residual layer on the basis of classical Transformer architecture. Specifically, the differences of adjacent time points are extracted and focused by difference and neighbor attention. The sliding fusion mechanism fuses various features of each time point so that the data can participate in encoding and decoding without losing important information. The residual layer including convolution and LSTM further learns the dependence between time points and enables our model to carry out deeper training. A large number of experiments on three datasets show that the prediction results produced by our method are favorably comparable to the state-of-the-art.
MidasTouch: Monte-Carlo inference over distributions across sliding touch
Oct 25, 2022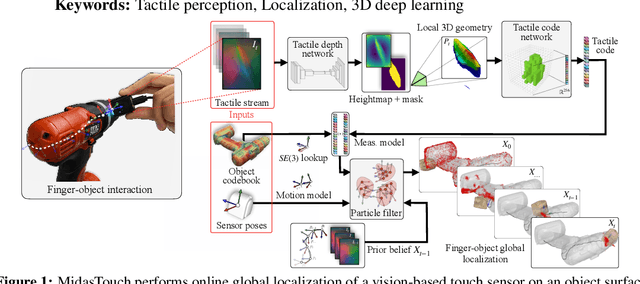
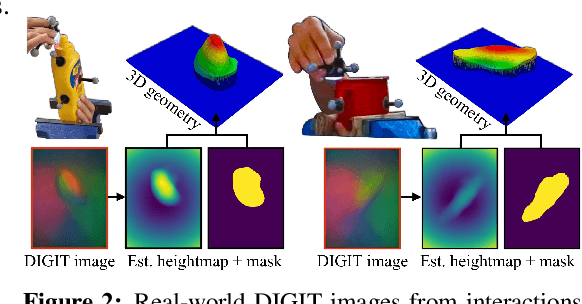


We present MidasTouch, a tactile perception system for online global localization of a vision-based touch sensor sliding on an object surface. This framework takes in posed tactile images over time, and outputs an evolving distribution of sensor pose on the object's surface, without the need for visual priors. Our key insight is to estimate local surface geometry with tactile sensing, learn a compact representation for it, and disambiguate these signals over a long time horizon. The backbone of MidasTouch is a Monte-Carlo particle filter, with a measurement model based on a tactile code network learned from tactile simulation. This network, inspired by LIDAR place recognition, compactly summarizes local surface geometries. These generated codes are efficiently compared against a precomputed tactile codebook per-object, to update the pose distribution. We further release the YCB-Slide dataset of real-world and simulated forceful sliding interactions between a vision-based tactile sensor and standard YCB objects. While single-touch localization can be inherently ambiguous, we can quickly localize our sensor by traversing salient surface geometries. Project page: https://suddhu.github.io/midastouch-tactile/
Characterizing information loss in a chaotic double pendulum with the Information Bottleneck
Oct 25, 2022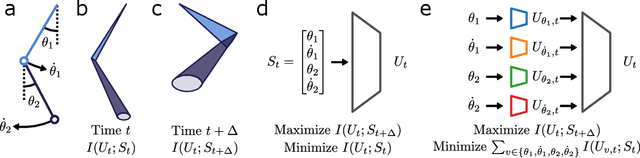

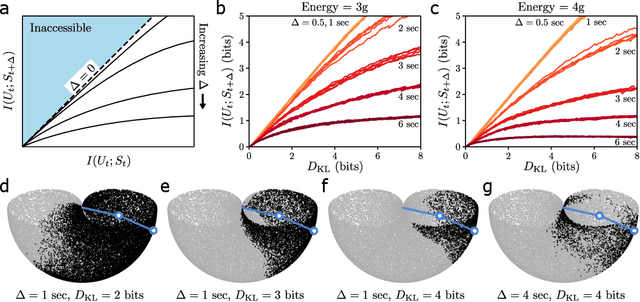
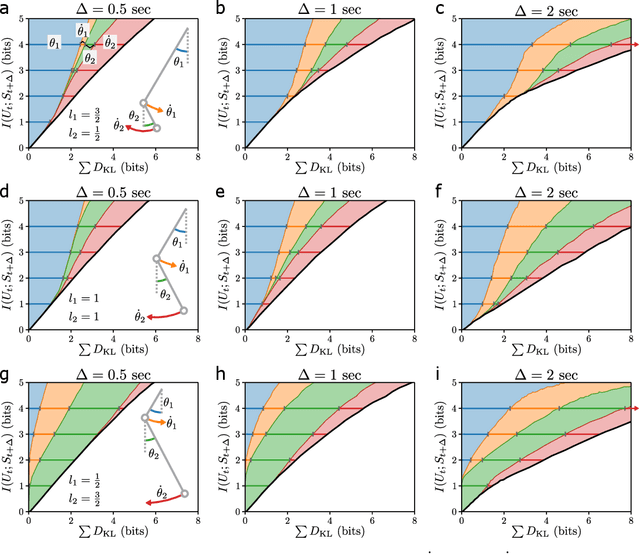
A hallmark of chaotic dynamics is the loss of information with time. Although information loss is often expressed through a connection to Lyapunov exponents -- valid in the limit of high information about the system state -- this picture misses the rich spectrum of information decay across different levels of granularity. Here we show how machine learning presents new opportunities for the study of information loss in chaotic dynamics, with a double pendulum serving as a model system. We use the Information Bottleneck as a training objective for a neural network to extract information from the state of the system that is optimally predictive of the future state after a prescribed time horizon. We then decompose the optimally predictive information by distributing a bottleneck to each state variable, recovering the relative importance of the variables in determining future evolution. The framework we develop is broadly applicable to chaotic systems and pragmatic to apply, leveraging data and machine learning to monitor the limits of predictability and map out the loss of information.
DyOb-SLAM : Dynamic Object Tracking SLAM System
Nov 03, 2022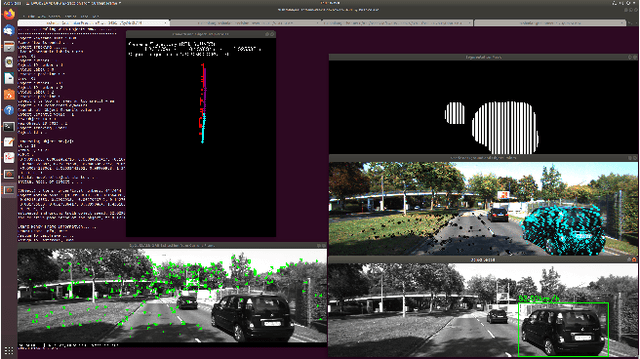
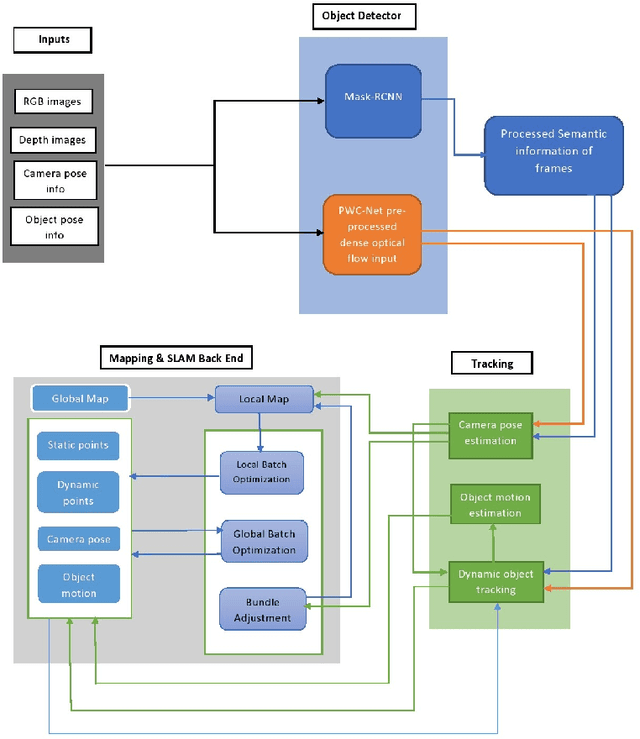
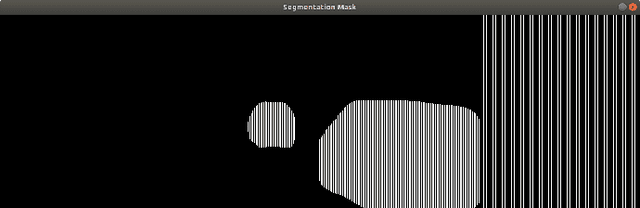
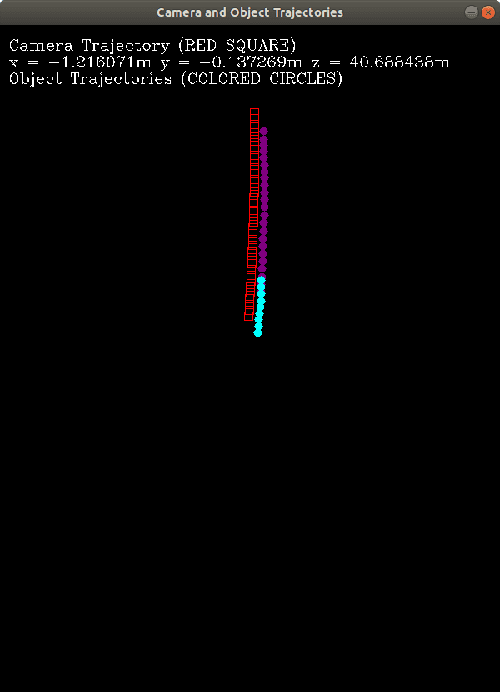
Simultaneous Localization & Mapping (SLAM) is the process of building a mutual relationship between localization and mapping of the subject in its surrounding environment. With the help of different sensors, various types of SLAM systems have developed to deal with the problem of building the relationship between localization and mapping. A limitation in the SLAM process is the lack of consideration of dynamic objects in the mapping of the environment. We propose the Dynamic Object Tracking SLAM (DyOb-SLAM), which is a Visual SLAM system that can localize and map the surrounding dynamic objects in the environment as well as track the dynamic objects in each frame. With the help of a neural network and a dense optical flow algorithm, dynamic objects and static objects in an environment can be differentiated. DyOb-SLAM creates two separate maps for both static and dynamic contents. For the static features, a sparse map is obtained. For the dynamic contents, a trajectory global map is created as output. As a result, a frame to frame real-time based dynamic object tracking system is obtained. With the pose calculation of the dynamic objects and camera, DyOb-SLAM can estimate the speed of the dynamic objects with time. The performance of DyOb-SLAM is observed by comparing it with a similar Visual SLAM system, VDO-SLAM and the performance is measured by calculating the camera and object pose errors as well as the object speed error.
An Efficient Approach with Dynamic Multi-Swarm of UAVs for Forest Firefighting
Nov 03, 2022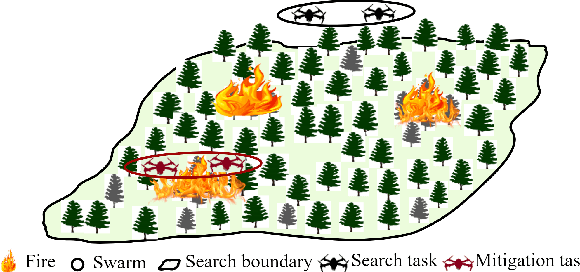
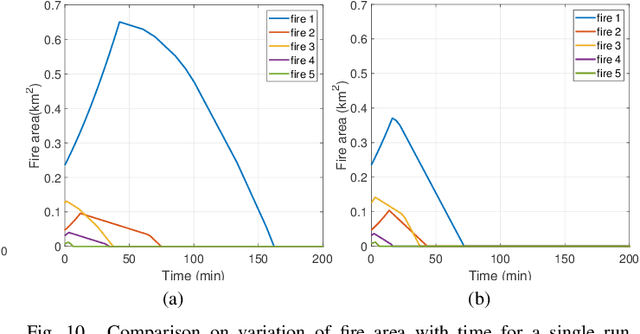
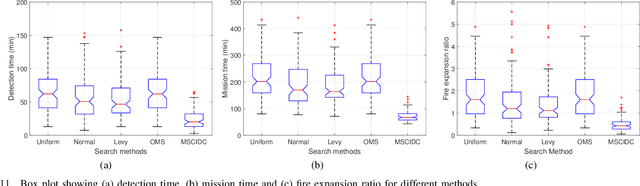
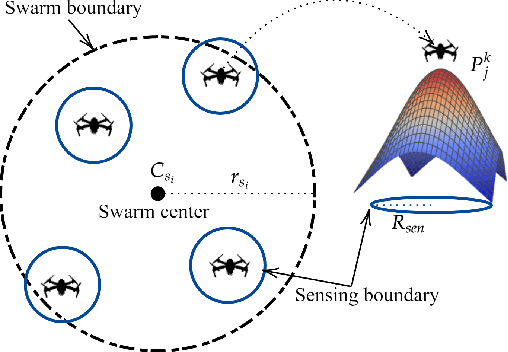
In this paper, the Multi-Swarm Cooperative Information-driven search and Divide and Conquer mitigation control (MSCIDC) approach is proposed for faster detection and mitigation of forest fire by reducing the loss of biodiversity, nutrients, soil moisture, and other intangible benefits. A swarm is a cooperative group of Unmanned Aerial Vehicles (UAVs) that fly together to search and quench the fire effectively. The multi-swarm cooperative information-driven search uses a multi-level search comprising cooperative information-driven exploration and exploitation for quick/accurate detection of fire location. The search level is selected based on the thermal sensor information about the potential fire area. The dynamicity of swarms, aided by global regulative repulsion and merging between swarms, reduces the detection and mitigation time compared to the existing methods. The local attraction among the members of the swarm helps the non-detector members to reach the fire location faster, and divide-and-conquer mitigation control ensures a non-overlapping fire sector allocation for all members quenching the fire. The performance of MSCIDC has been compared with different multi-UAV methods using a simulated environment of pine forest. The performance clearly shows that MSCIDC mitigates fire much faster than the multi-UAV methods. The Monte-Carlo simulation results indicate that the proposed method reduces the average forest area burnt by $65\%$ and mission time by $60\%$ compared to the best result case of the multi-UAV approaches, guaranteeing a faster and successful mission.
Robust Few-shot Learning Without Using any Adversarial Samples
Nov 03, 2022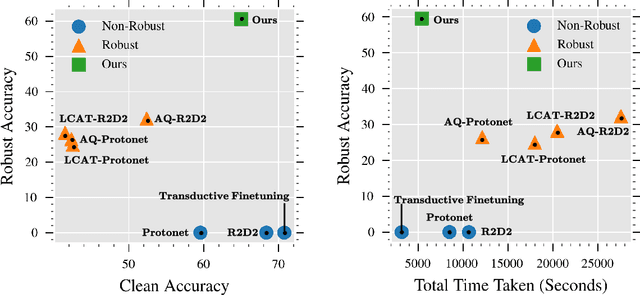
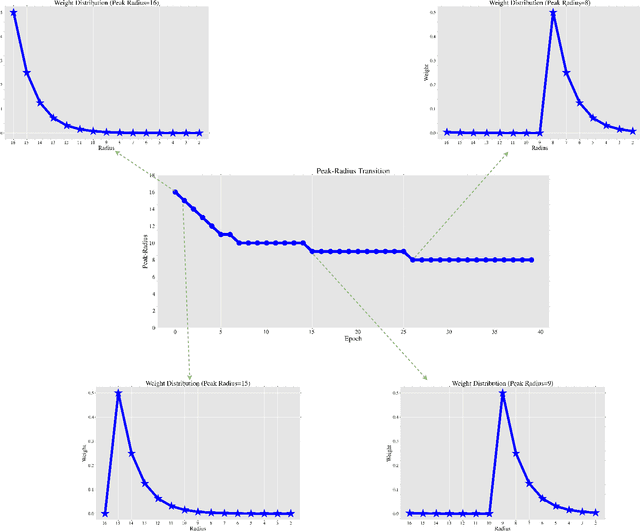
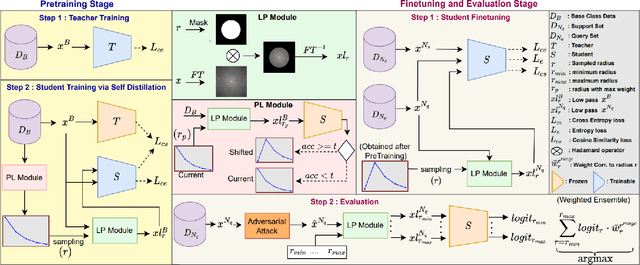

The high cost of acquiring and annotating samples has made the `few-shot' learning problem of prime importance. Existing works mainly focus on improving performance on clean data and overlook robustness concerns on the data perturbed with adversarial noise. Recently, a few efforts have been made to combine the few-shot problem with the robustness objective using sophisticated Meta-Learning techniques. These methods rely on the generation of adversarial samples in every episode of training, which further adds a computational burden. To avoid such time-consuming and complicated procedures, we propose a simple but effective alternative that does not require any adversarial samples. Inspired by the cognitive decision-making process in humans, we enforce high-level feature matching between the base class data and their corresponding low-frequency samples in the pretraining stage via self distillation. The model is then fine-tuned on the samples of novel classes where we additionally improve the discriminability of low-frequency query set features via cosine similarity. On a 1-shot setting of the CIFAR-FS dataset, our method yields a massive improvement of $60.55\%$ & $62.05\%$ in adversarial accuracy on the PGD and state-of-the-art Auto Attack, respectively, with a minor drop in clean accuracy compared to the baseline. Moreover, our method only takes $1.69\times$ of the standard training time while being $\approx$ $5\times$ faster than state-of-the-art adversarial meta-learning methods. The code is available at https://github.com/vcl-iisc/robust-few-shot-learning.
Minimax Concave Penalty Regularized Adaptive System Identification
Nov 07, 2022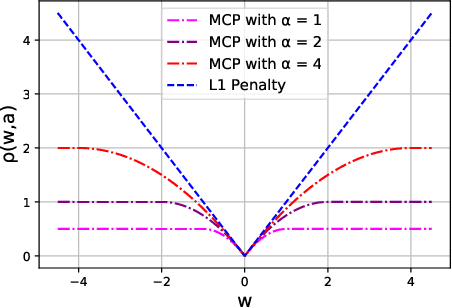
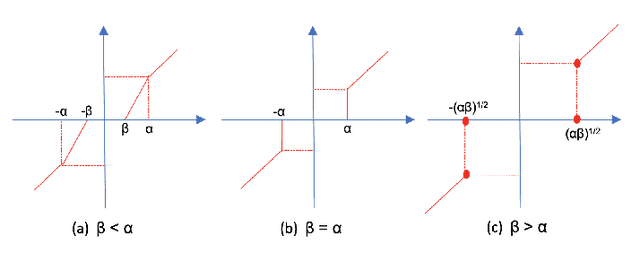
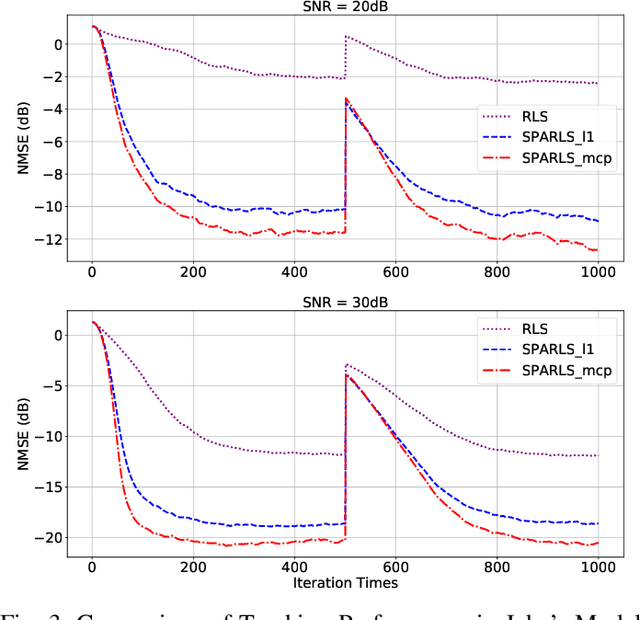
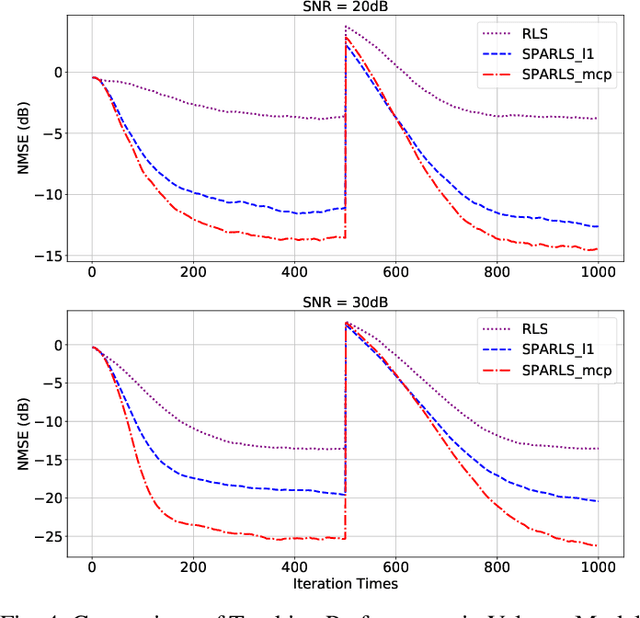
We develop a recursive least square (RLS) type algorithm with a minimax concave penalty (MCP) for adaptive identification of a sparse tap-weight vector that represents a communication channel. The proposed algorithm recursively yields its estimate of the tap-vector, from noisy streaming observations of a received signal, using expectation-maximization (EM) update. We prove the convergence of our algorithm to a local optimum and provide bounds for the steady state error. Using simulation studies of Rayleigh fading channel, Volterra system and multivariate time series model, we demonstrate that our algorithm outperforms, in the mean-squared error (MSE) sense, the standard RLS and the $\ell_1$-regularized RLS.
Error Performance of Rectangular Pulse-shaped OTFS with Practical Receivers
Nov 07, 2022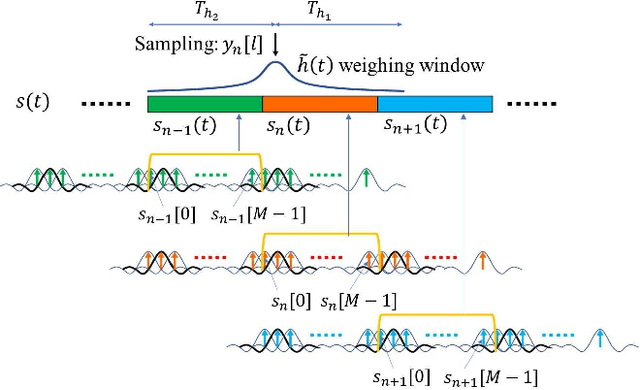
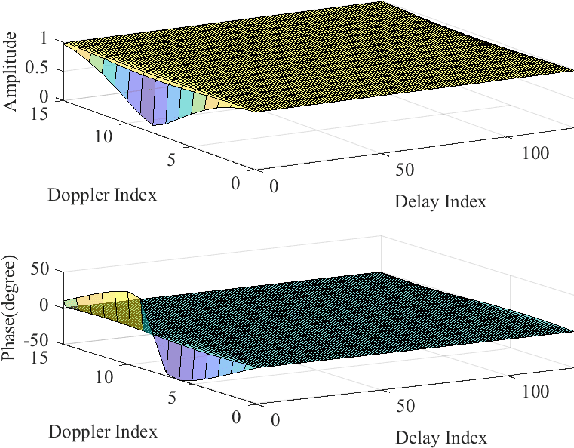
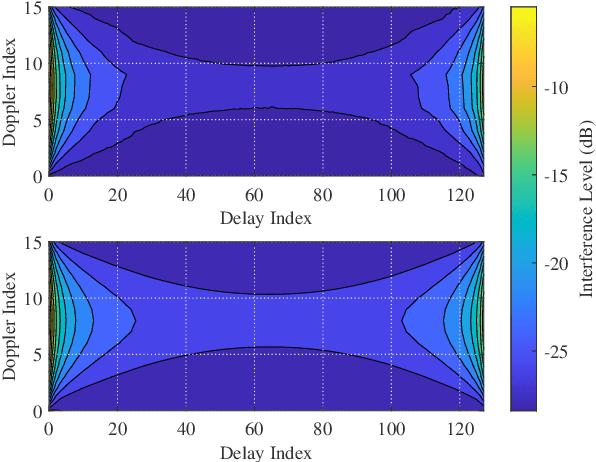
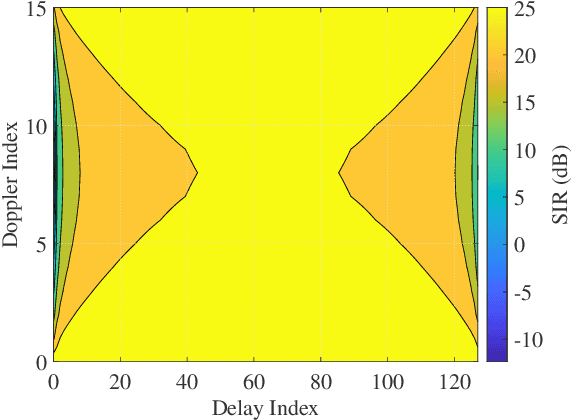
In this letter, we investigate error performance of rectangular pulse-shaped orthogonal time frequency space (OTFS) modulation with a practical receiver. Specifically, we consider an essential bandpass filter at receiver RF front-end, which has been ignored in existing works. We analyse the effect of rectangular pulses on practical OTFS receiver performance, and derive the exact forms of interference in delay-Doppler (DD) domain. We demonstrate that the transmitted information symbols in certain regions of the DD domain are severely contaminated. As a result, there is an error floor in the receiver error performance, which needs to be addressed for such OTFS waveform in practical systems.
LLEDA -- Lifelong Self-Supervised Domain Adaptation
Nov 12, 2022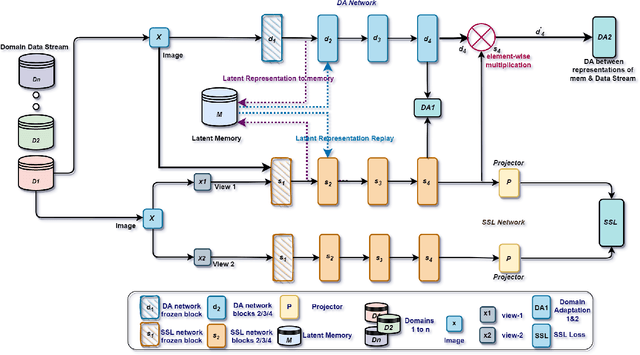
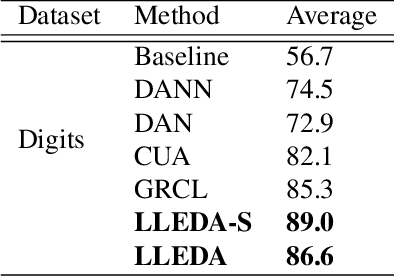
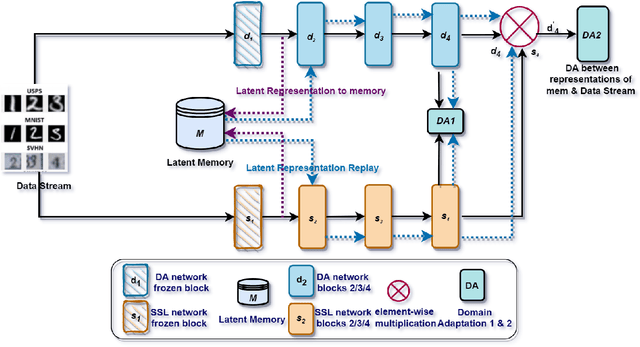
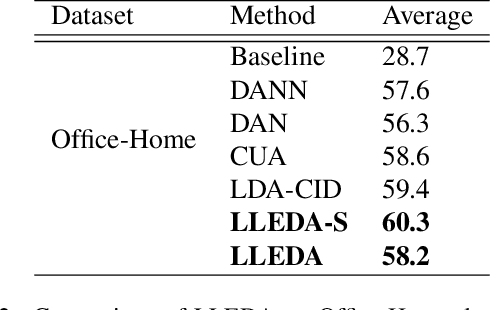
Lifelong domain adaptation remains a challenging task in machine learning due to the differences among the domains and the unavailability of historical data. The ultimate goal is to learn the distributional shifts while retaining the previously gained knowledge. Inspired by the Complementary Learning Systems (CLS) theory, we propose a novel framework called Lifelong Self-Supervised Domain Adaptation (LLEDA). LLEDA addresses catastrophic forgetting by replaying hidden representations rather than raw data pixels and domain-agnostic knowledge transfer using self-supervised learning. LLEDA does not access labels from the source or the target domain and only has access to a single domain at any given time. Extensive experiments demonstrate that the proposed method outperforms several other methods and results in a long-term adaptation, while being less prone to catastrophic forgetting when transferred to new domains.