 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
I still have Time(s): Extending HeidelTime for German Texts
Apr 19, 2022
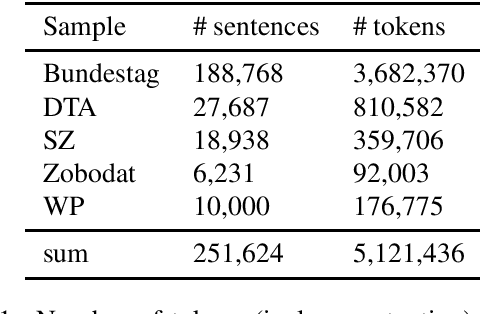
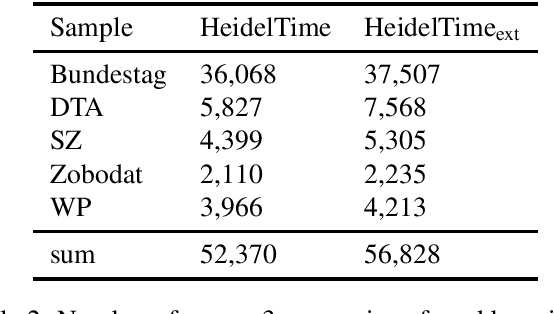
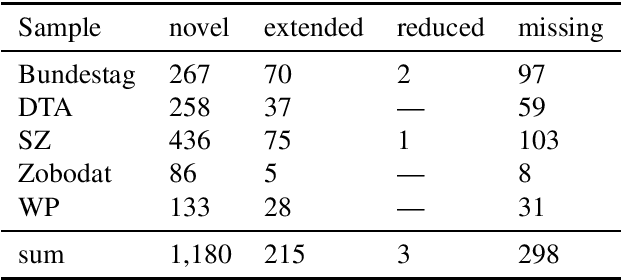
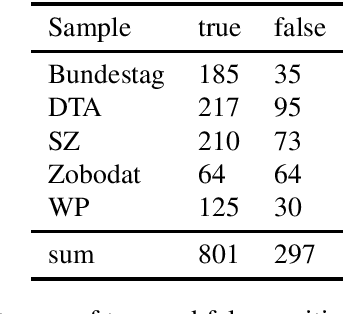
HeidelTime is one of the most widespread and successful tools for detecting temporal expressions in texts. Since HeidelTime's pattern matching system is based on regular expression, it can be extended in a convenient way. We present such an extension for the German resources of HeidelTime: HeidelTime-EXT . The extension has been brought about by means of observing false negatives within real world texts and various time banks. The gain in coverage is 2.7% or 8.5%, depending on the admitted degree of potential overgeneralization. We describe the development of HeidelTime-EXT, its evaluation on text samples from various genres, and share some linguistic observations. HeidelTime ext can be obtained from https://github.com/texttechnologylab/heideltime.
CMT: Interpretable Model for Rapid Recognition Pneumonia from Chest X-Ray Images by Fusing Low Complexity Multilevel Attention Mechanism
Oct 29, 2022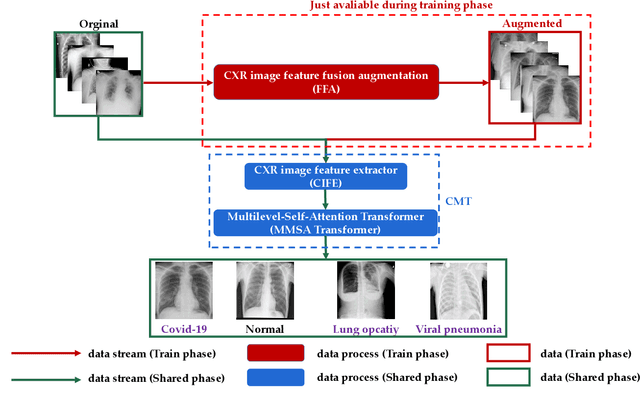
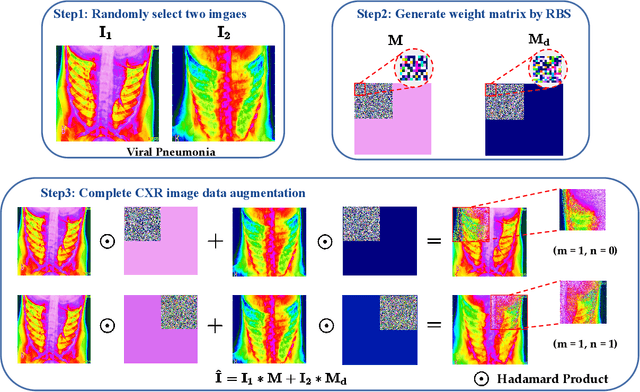
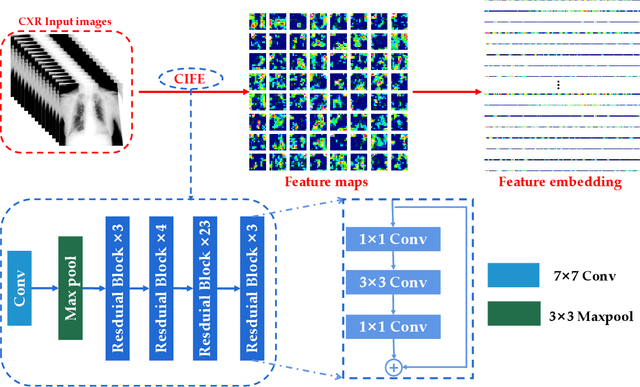
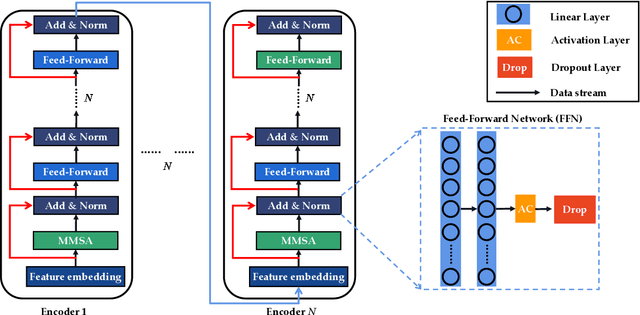
Chest imaging plays an essential role in diagnosing and predicting patients with COVID-19 with evidence of worsening respiratory status. Many deep learning-based diagnostic models for pneumonia have been developed to enable computer-aided diagnosis. However, the long training and inference time make them inflexible. In addition, the lack of interpretability reduces their credibility in clinical medical practice. This paper presents CMT, a model with interpretability and rapid recognition of pneumonia, especially COVID-19 positive. Multiple convolutional layers in CMT are first used to extract features in CXR images, and then Transformer is applied to calculate the possibility of each symptom. To improve the model's generalization performance and to address the problem of sparse medical image data, we propose Feature Fusion Augmentation (FFA), a plug-and-play method for image augmentation. It fuses the features of the two images to varying degrees to produce a new image that does not deviate from the original distribution. Furthermore, to reduce the computational complexity and accelerate the convergence, we propose Multilevel Multi-Head Self-Attention (MMSA), which computes attention on different levels to establish the relationship between global and local features. It significantly improves the model performance while substantially reducing its training and inference time. Experimental results on the largest COVID-19 dataset show the proposed CMT has state-of-the-art performance. The effectiveness of FFA and MMSA is demonstrated in the ablation experiments. In addition, the weights and feature activation maps of the model inference process are visualized to show the CMT's interpretability.
Boosting Monocular 3D Object Detection with Object-Centric Auxiliary Depth Supervision
Oct 29, 2022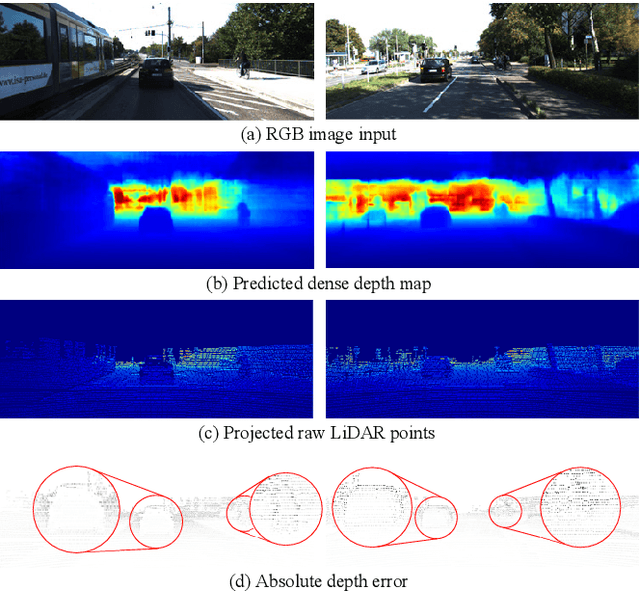
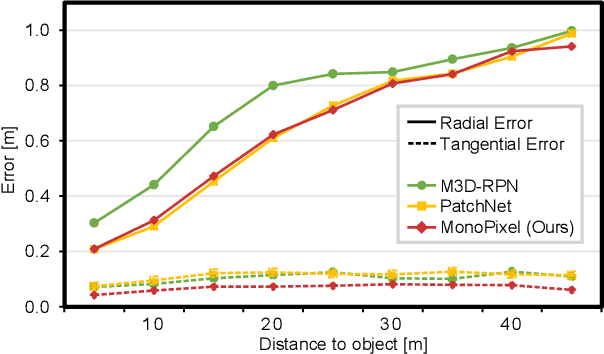
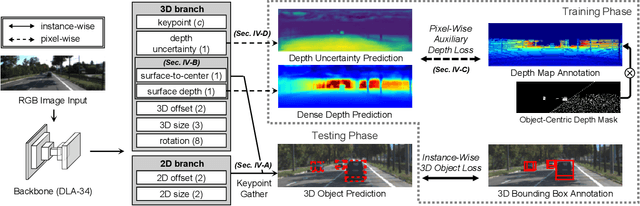
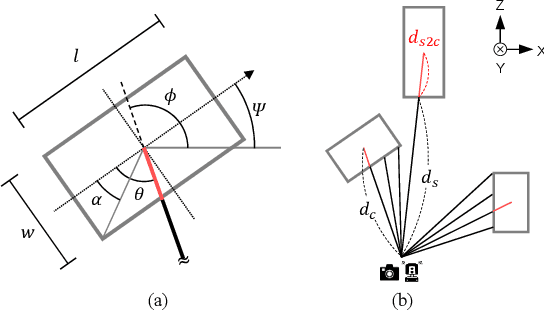
Recent advances in monocular 3D detection leverage a depth estimation network explicitly as an intermediate stage of the 3D detection network. Depth map approaches yield more accurate depth to objects than other methods thanks to the depth estimation network trained on a large-scale dataset. However, depth map approaches can be limited by the accuracy of the depth map, and sequentially using two separated networks for depth estimation and 3D detection significantly increases computation cost and inference time. In this work, we propose a method to boost the RGB image-based 3D detector by jointly training the detection network with a depth prediction loss analogous to the depth estimation task. In this way, our 3D detection network can be supervised by more depth supervision from raw LiDAR points, which does not require any human annotation cost, to estimate accurate depth without explicitly predicting the depth map. Our novel object-centric depth prediction loss focuses on depth around foreground objects, which is important for 3D object detection, to leverage pixel-wise depth supervision in an object-centric manner. Our depth regression model is further trained to predict the uncertainty of depth to represent the 3D confidence of objects. To effectively train the 3D detector with raw LiDAR points and to enable end-to-end training, we revisit the regression target of 3D objects and design a network architecture. Extensive experiments on KITTI and nuScenes benchmarks show that our method can significantly boost the monocular image-based 3D detector to outperform depth map approaches while maintaining the real-time inference speed.
2D and 3D CT Radiomic Features Performance Comparison in Characterization of Gastric Cancer: A Multi-center Study
Oct 29, 2022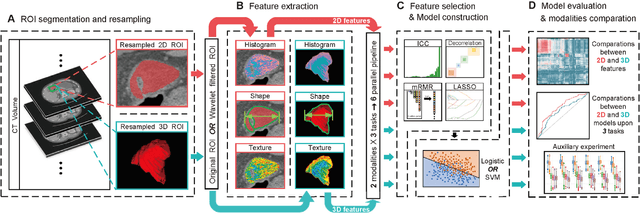
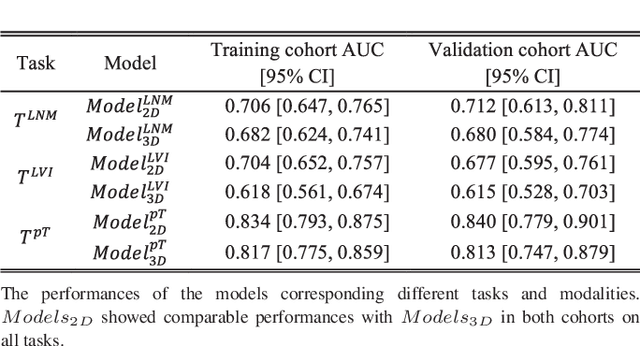
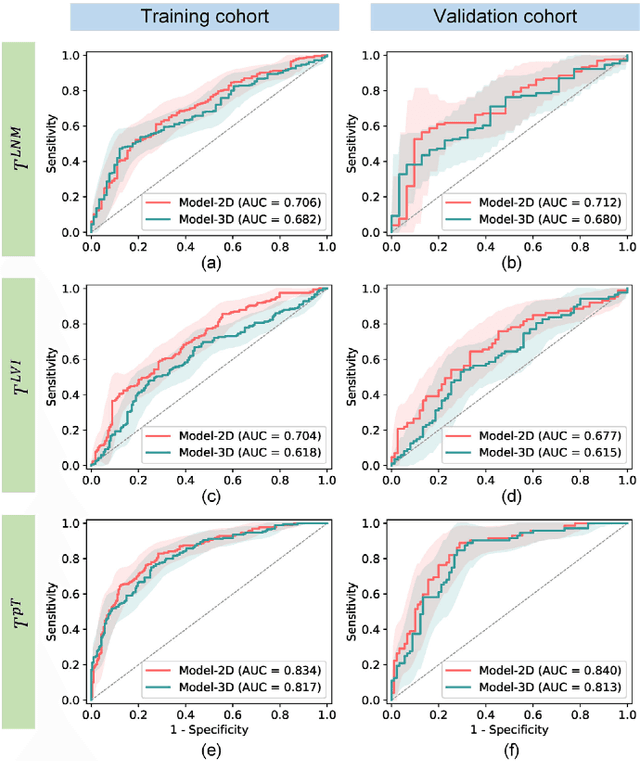
Objective: Radiomics, an emerging tool for medical image analysis, is potential towards precisely characterizing gastric cancer (GC). Whether using one-slice 2D annotation or whole-volume 3D annotation remains a long-time debate, especially for heterogeneous GC. We comprehensively compared 2D and 3D radiomic features' representation and discrimination capacity regarding GC, via three tasks. Methods: Four-center 539 GC patients were retrospectively enrolled and divided into the training and validation cohorts. From 2D or 3D regions of interest (ROIs) annotated by radiologists, radiomic features were extracted respectively. Feature selection and model construction procedures were customed for each combination of two modalities (2D or 3D) and three tasks. Subsequently, six machine learning models (Model_2D^LNM, Model_3D^LNM; Model_2D^LVI, Model_3D^LVI; Model_2D^pT, Model_3D^pT) were derived and evaluated to reflect modalities' performances in characterizing GC. Furthermore, we performed an auxiliary experiment to assess modalities' performances when resampling spacing is different. Results: Regarding three tasks, the yielded areas under the curve (AUCs) were: Model_2D^LNM's 0.712 (95% confidence interval, 0.613-0.811), Model_3D^LNM's 0.680 (0.584-0.775); Model_2D^LVI's 0.677 (0.595-0.761), Model_3D^LVI's 0.615 (0.528-0.703); Model_2D^pT's 0.840 (0.779-0.901), Model_3D^pT's 0.813 (0.747-0.879). Moreover, the auxiliary experiment indicated that Models_2D are statistically more advantageous than Models3D with different resampling spacings. Conclusion: Models constructed with 2D radiomic features revealed comparable performances with those constructed with 3D features in characterizing GC. Significance: Our work indicated that time-saving 2D annotation would be the better choice in GC, and provided a related reference to further radiomics-based researches.
* Published in IEEE Journal of Biomedical and Health Informatics
Time-coded Spiking Fourier Transform in Neuromorphic Hardware
Feb 25, 2022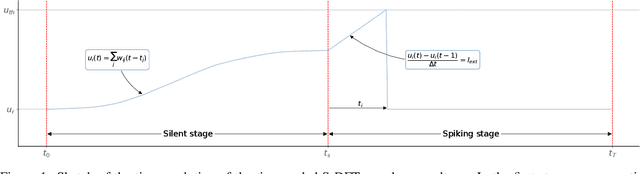

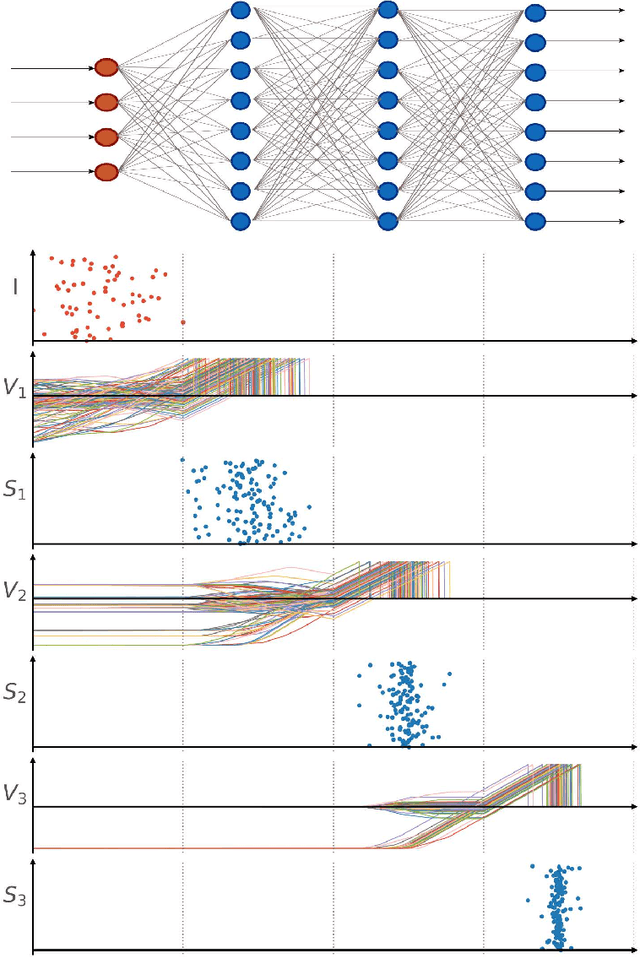

After several decades of continuously optimizing computing systems, the Moore's law is reaching itsend. However, there is an increasing demand for fast and efficient processing systems that can handlelarge streams of data while decreasing system footprints. Neuromorphic computing answers thisneed by creating decentralized architectures that communicate with binary events over time. Despiteits rapid growth in the last few years, novel algorithms are needed that can leverage the potential ofthis emerging computing paradigm and can stimulate the design of advanced neuromorphic chips.In this work, we propose a time-based spiking neural network that is mathematically equivalent tothe Fourier transform. We implemented the network in the neuromorphic chip Loihi and conductedexperiments on five different real scenarios with an automotive frequency modulated continuouswave radar. Experimental results validate the algorithm, and we hope they prompt the design of adhoc neuromorphic chips that can improve the efficiency of state-of-the-art digital signal processorsand encourage research on neuromorphic computing for signal processing.
Improved Stein Variational Gradient Descent with Importance Weights
Oct 04, 2022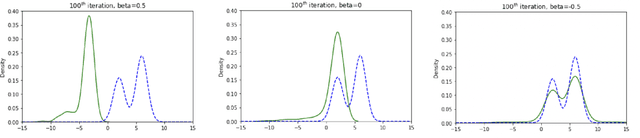
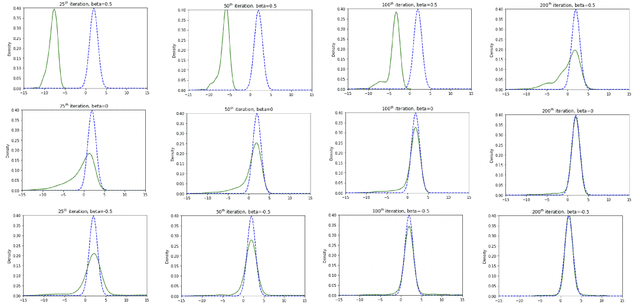
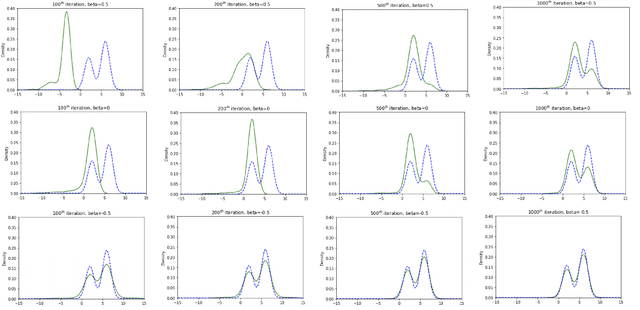
Stein Variational Gradient Descent (SVGD) is a popular sampling algorithm used in various machine learning tasks. It is well known that SVGD arises from a discretization of the kernelized gradient flow of the Kullback-Leibler divergence $D_{KL}\left(\cdot\mid\pi\right)$, where $\pi$ is the target distribution. In this work, we propose to enhance SVGD via the introduction of importance weights, which leads to a new method for which we coin the name $\beta$-SVGD. In the continuous time and infinite particles regime, the time for this flow to converge to the equilibrium distribution $\pi$, quantified by the Stein Fisher information, depends on $\rho_0$ and $\pi$ very weakly. This is very different from the kernelized gradient flow of Kullback-Leibler divergence, whose time complexity depends on $D_{KL}\left(\rho_0\mid\pi\right)$. Under certain assumptions, we provide a descent lemma for the population limit $\beta$-SVGD, which covers the descent lemma for the population limit SVGD when $\beta\to 0$. We also illustrate the advantages of $\beta$-SVGD over SVGD by simple experiments.
Learning Perception-Aware Agile Flight in Cluttered Environments
Oct 04, 2022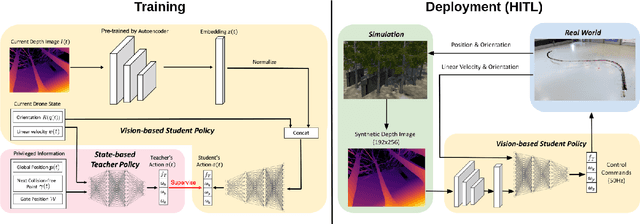

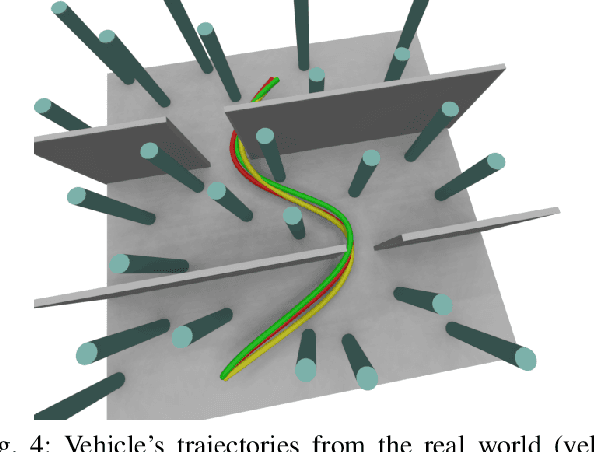
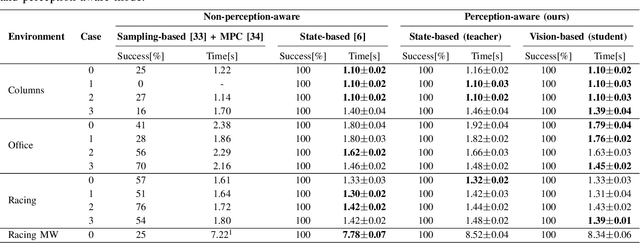
Recently, neural control policies have outperformed existing model-based planning-and-control methods for autonomously navigating quadrotors through cluttered environments in minimum time. However, they are not perception aware, a crucial requirement in vision-based navigation due to the camera's limited field of view and the underactuated nature of a quadrotor. We propose a method to learn neural network policies that achieve perception-aware, minimum-time flight in cluttered environments. Our method combines imitation learning and reinforcement learning (RL) by leveraging a privileged learning-by-cheating framework. Using RL, we first train a perception-aware teacher policy with full-state information to fly in minimum time through cluttered environments. Then, we use imitation learning to distill its knowledge into a vision-based student policy that only perceives the environment via a camera. Our approach tightly couples perception and control, showing a significant advantage in computation speed (10x faster) and success rate. We demonstrate the closed-loop control performance using a physical quadrotor and hardware-in-the-loop simulation at speeds up to 50km/h.
ConchShell: A Generative Adversarial Networks that Turns Pictures into Piano Music
Oct 11, 2022

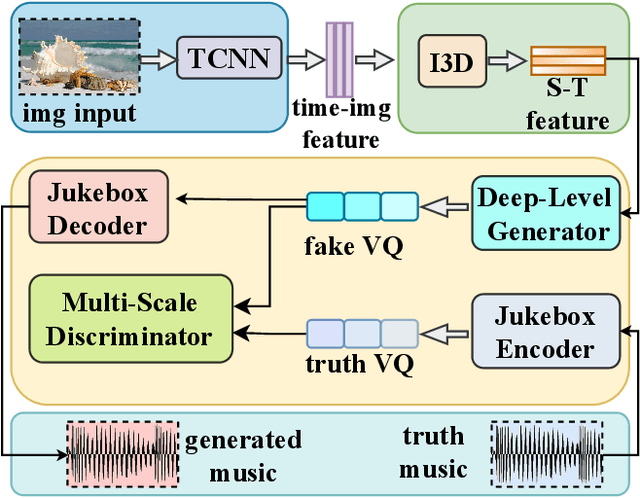
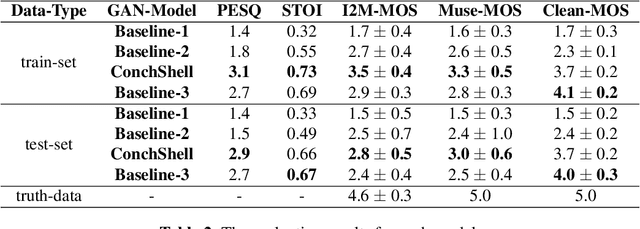
We present ConchShell, a multi-modal generative adversarial framework that takes pictures as input to the network and generates piano music samples that match the picture context. Inspired by I3D, we introduce a novel image feature representation method: time-convolutional neural network (TCNN), which is used to forge features for images in the temporal dimension. Although our image data consists of only six categories, our proposed framework will be innovative and commercially meaningful. The project will provide technical ideas for work such as 3D game voice overs, short-video soundtracks, and real-time generation of metaverse background music.We have also released a new dataset, the Beach-Ocean-Piano Dataset (BOPD) 1, which contains more than 3,000 images and more than 1,500 piano pieces. This dataset will support multimodal image-to-music research.
Semantic Metadata Extraction from Dense Video Captioning
Nov 05, 2022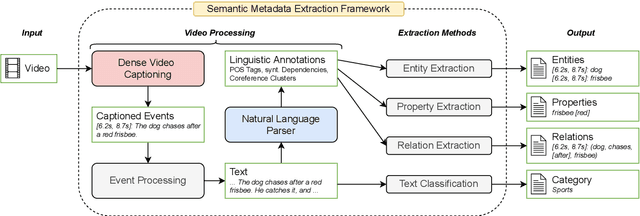

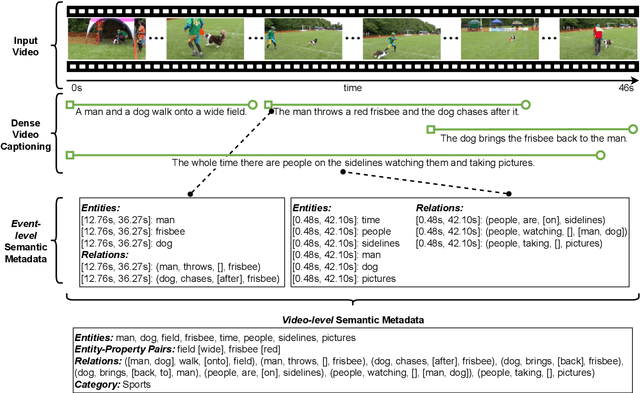
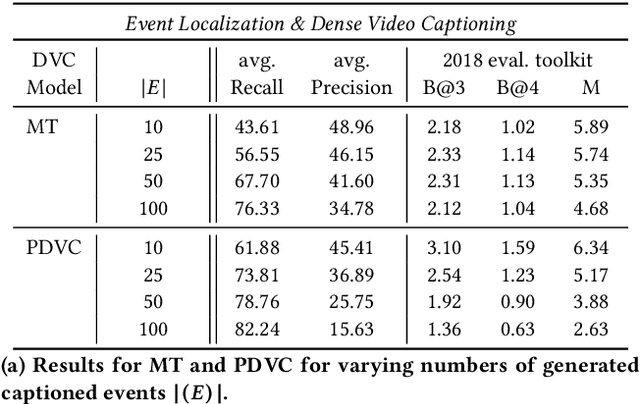
Annotation of multimedia data by humans is time-consuming and costly, while reliable automatic generation of semantic metadata is a major challenge. We propose a framework to extract semantic metadata from automatically generated video captions. As metadata, we consider entities, the entities' properties, relations between entities, and the video category. We employ two state-of-the-art dense video captioning models with masked transformer (MT) and parallel decoding (PVDC) to generate captions for videos of the ActivityNet Captions dataset. Our experiments show that it is possible to extract entities, their properties, relations between entities, and the video category from the generated captions. We observe that the quality of the extracted information is mainly influenced by the quality of the event localization in the video as well as the performance of the event caption generation.
PriMask: Cascadable and Collusion-Resilient Data Masking for Mobile Cloud Inference
Nov 12, 2022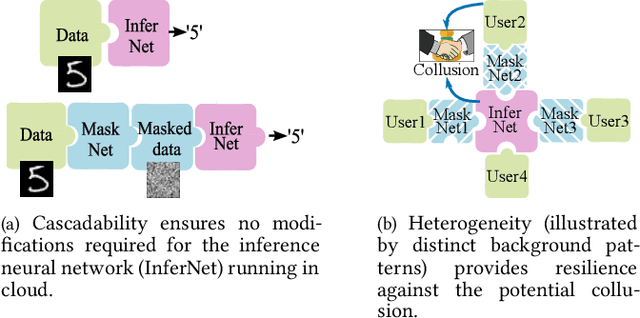
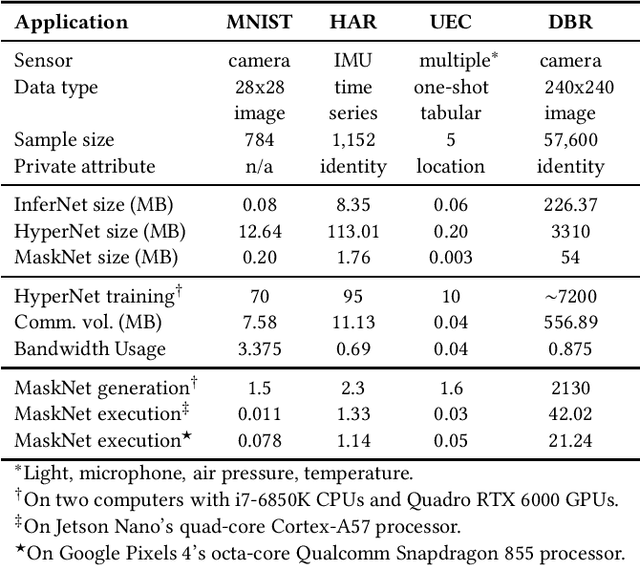
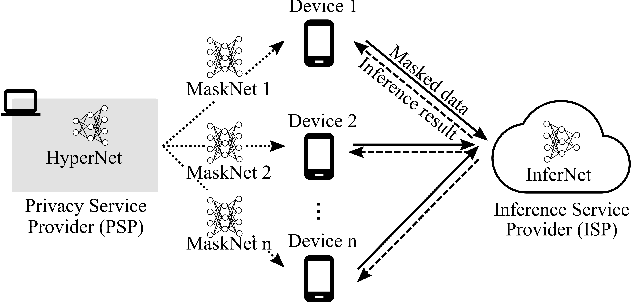

Mobile cloud offloading is indispensable for inference tasks based on large-scale deep models. However, transmitting privacy-rich inference data to the cloud incurs concerns. This paper presents the design of a system called PriMask, in which the mobile device uses a secret small-scale neural network called MaskNet to mask the data before transmission. PriMask significantly weakens the cloud's capability to recover the data or extract certain private attributes. The MaskNet is em cascadable in that the mobile can opt in to or out of its use seamlessly without any modifications to the cloud's inference service. Moreover, the mobiles use different MaskNets, such that the collusion between the cloud and some mobiles does not weaken the protection for other mobiles. We devise a {\em split adversarial learning} method to train a neural network that generates a new MaskNet quickly (within two seconds) at run time. We apply PriMask to three mobile sensing applications with diverse modalities and complexities, i.e., human activity recognition, urban environment crowdsensing, and driver behavior recognition. Results show PriMask's effectiveness in all three applications.