 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Generalizability Under Sensor Failure: Tokenization + Transformers Enable More Robust Latent Spaces
Feb 29, 2024
A major goal in neuroscience is to discover neural data representations that generalize. This goal is challenged by variability along recording sessions (e.g. environment), subjects (e.g. varying neural structures), and sensors (e.g. sensor noise), among others. Recent work has begun to address generalization across sessions and subjects, but few study robustness to sensor failure which is highly prevalent in neuroscience experiments. In order to address these generalizability dimensions we first collect our own electroencephalography dataset with numerous sessions, subjects, and sensors, then study two time series models: EEGNet (Lawhern et al., 2018) and TOTEM (Talukder et al., 2024). EEGNet is a widely used convolutional neural network, while TOTEM is a discrete time series tokenizer and transformer model. We find that TOTEM outperforms or matches EEGNet across all generalizability cases. Finally through analysis of TOTEM's latent codebook we observe that tokenization enables generalization
Target Localization and Performance Trade-Offs in Cooperative ISAC Systems: A Scheme Based on 5G NR OFDM Signals
Mar 04, 2024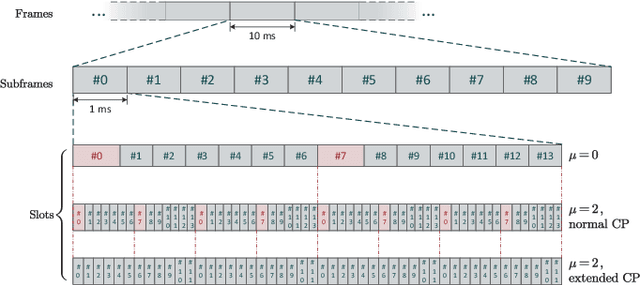
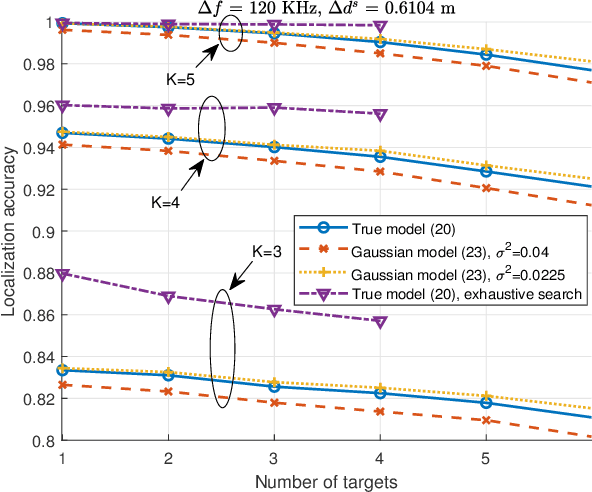
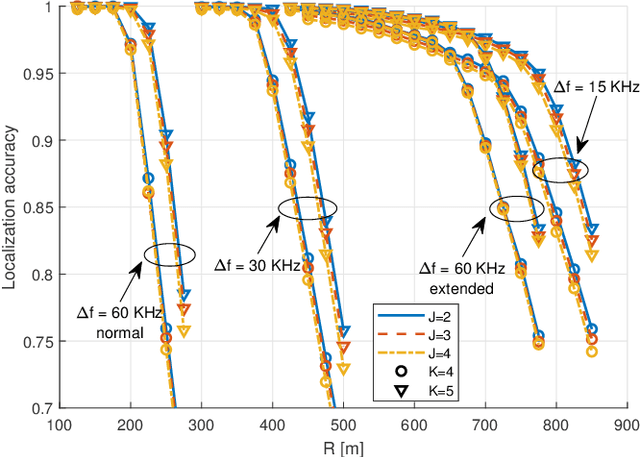
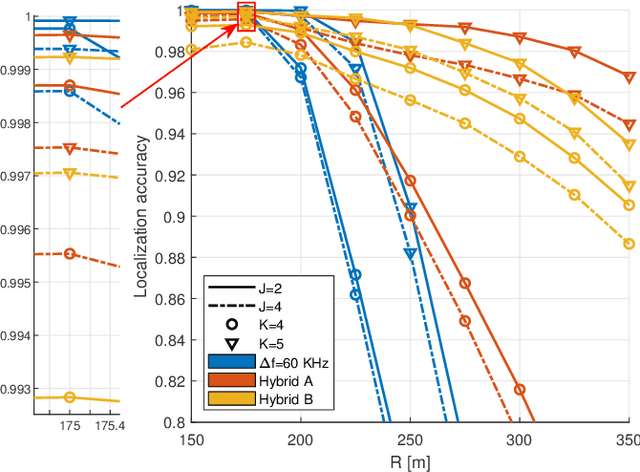
The integration of sensing capabilities into communication systems, by sharing physical resources, has a significant potential for reducing spectrum, hardware, and energy costs while inspiring innovative applications. Cooperative networks, in particular, are expected to enhance sensing services by enlarging the coverage area and enriching sensing measurements, thus improving the service availability and accuracy. This paper proposes a cooperative integrated sensing and communication (ISAC) framework by leveraging information-carrying orthogonal frequency division multiplexing (OFDM) signals transmitted by access points (APs). Specifically, we propose a two-stage scheme for target localization, where communication signals are reused as sensing reference signals based on the system information shared at the central processing unit (CPU). In Stage I, we measure the ranges of scattered paths induced by targets, through the extraction of time-delay information from the received signals at APs. Then, the target locations are estimated in Stage II based on these range measurements. Considering that the scattered paths corresponding to some targets may not be detectable by all APs, we propose an effective algorithm to match the range measurements with the targets and achieve the target location estimation. Notably, by analyzing the OFDM numerologies defined in fifth generation (5G) standards, we elucidate the flexibility and consistency of performance trade-offs in both communication and sensing aspects. Finally, numerical results confirm the effectiveness of our sensing scheme and the cooperative gain of the ISAC framework.
Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve
Mar 04, 2024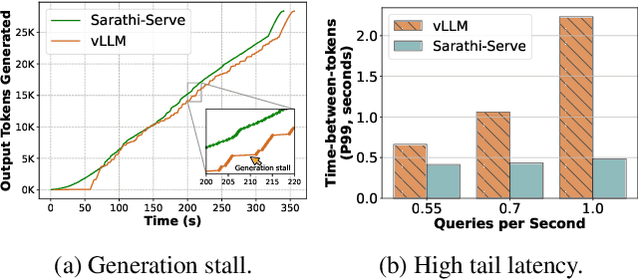

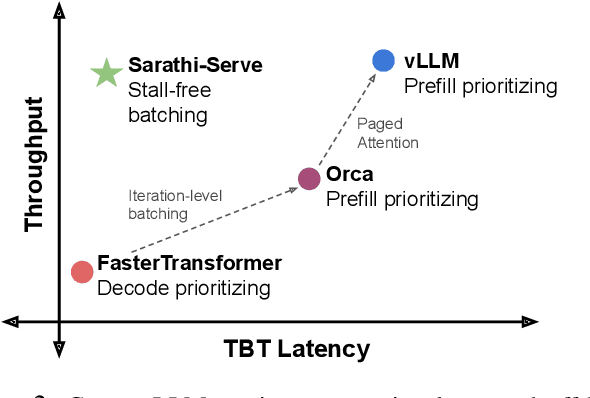

Each LLM serving request goes through two phases. The first is prefill which processes the entire input prompt to produce one output token and the second is decode which generates the rest of output tokens, one-at-a-time. Prefill iterations have high latency but saturate GPU compute due to parallel processing of the input prompt. In contrast, decode iterations have low latency but also low compute utilization because a decode iteration processes only a single token per request. This makes batching highly effective for decodes and consequently for overall throughput. However, batching multiple requests leads to an interleaving of prefill and decode iterations which makes it challenging to achieve both high throughput and low latency. We introduce an efficient LLM inference scheduler Sarathi-Serve inspired by the techniques we originally proposed for optimizing throughput in Sarathi. Sarathi-Serve leverages chunked-prefills from Sarathi to create stall-free schedules that can add new requests in a batch without pausing ongoing decodes. Stall-free scheduling unlocks the opportunity to improve throughput with large batch sizes while minimizing the effect of batching on latency. Our evaluation shows that Sarathi-Serve improves serving throughput within desired latency SLOs of Mistral-7B by up to 2.6x on a single A100 GPU and up to 6.9x for Falcon-180B on 8 A100 GPUs over Orca and vLLM.
Unlearnable Examples For Time Series
Feb 03, 2024Unlearnable examples (UEs) refer to training samples modified to be unlearnable to Deep Neural Networks (DNNs). These examples are usually generated by adding error-minimizing noises that can fool a DNN model into believing that there is nothing (no error) to learn from the data. The concept of UE has been proposed as a countermeasure against unauthorized data exploitation on personal data. While UE has been extensively studied on images, it is unclear how to craft effective UEs for time series data. In this work, we introduce the first UE generation method to protect time series data from unauthorized training by deep learning models. To this end, we propose a new form of error-minimizing noise that can be \emph{selectively} applied to specific segments of time series, rendering them unlearnable to DNN models while remaining imperceptible to human observers. Through extensive experiments on a wide range of time series datasets, we demonstrate that the proposed UE generation method is effective in both classification and generation tasks. It can protect time series data against unauthorized exploitation, while preserving their utility for legitimate usage, thereby contributing to the development of secure and trustworthy machine learning systems.
Learning time-dependent PDE via graph neural networks and deep operator network for robust accuracy on irregular grids
Feb 13, 2024Scientific computing using deep learning has seen significant advancements in recent years. There has been growing interest in models that learn the operator from the parameters of a partial differential equation (PDE) to the corresponding solutions. Deep Operator Network (DeepONet) and Fourier Neural operator, among other models, have been designed with structures suitable for handling functions as inputs and outputs, enabling real-time predictions as surrogate models for solution operators. There has also been significant progress in the research on surrogate models based on graph neural networks (GNNs), specifically targeting the dynamics in time-dependent PDEs. In this paper, we propose GraphDeepONet, an autoregressive model based on GNNs, to effectively adapt DeepONet, which is well-known for successful operator learning. GraphDeepONet exhibits robust accuracy in predicting solutions compared to existing GNN-based PDE solver models. It maintains consistent performance even on irregular grids, leveraging the advantages inherited from DeepONet and enabling predictions on arbitrary grids. Additionally, unlike traditional DeepONet and its variants, GraphDeepONet enables time extrapolation for time-dependent PDE solutions. We also provide theoretical analysis of the universal approximation capability of GraphDeepONet in approximating continuous operators across arbitrary time intervals.
Denoising Time Cycle Modeling for Recommendation
Feb 05, 2024Recently, modeling temporal patterns of user-item interactions have attracted much attention in recommender systems. We argue that existing methods ignore the variety of temporal patterns of user behaviors. We define the subset of user behaviors that are irrelevant to the target item as noises, which limits the performance of target-related time cycle modeling and affect the recommendation performance. In this paper, we propose Denoising Time Cycle Modeling (DiCycle), a novel approach to denoise user behaviors and select the subset of user behaviors that are highly related to the target item. DiCycle is able to explicitly model diverse time cycle patterns for recommendation. Extensive experiments are conducted on both public benchmarks and a real-world dataset, demonstrating the superior performance of DiCycle over the state-of-the-art recommendation methods.
NeuroFlux: Memory-Efficient CNN Training Using Adaptive Local Learning
Mar 04, 2024Efficient on-device Convolutional Neural Network (CNN) training in resource-constrained mobile and edge environments is an open challenge. Backpropagation is the standard approach adopted, but it is GPU memory intensive due to its strong inter-layer dependencies that demand intermediate activations across the entire CNN model to be retained in GPU memory. This necessitates smaller batch sizes to make training possible within the available GPU memory budget, but in turn, results in substantially high and impractical training time. We introduce NeuroFlux, a novel CNN training system tailored for memory-constrained scenarios. We develop two novel opportunities: firstly, adaptive auxiliary networks that employ a variable number of filters to reduce GPU memory usage, and secondly, block-specific adaptive batch sizes, which not only cater to the GPU memory constraints but also accelerate the training process. NeuroFlux segments a CNN into blocks based on GPU memory usage and further attaches an auxiliary network to each layer in these blocks. This disrupts the typical layer dependencies under a new training paradigm - $\textit{`adaptive local learning'}$. Moreover, NeuroFlux adeptly caches intermediate activations, eliminating redundant forward passes over previously trained blocks, further accelerating the training process. The results are twofold when compared to Backpropagation: on various hardware platforms, NeuroFlux demonstrates training speed-ups of 2.3$\times$ to 6.1$\times$ under stringent GPU memory budgets, and NeuroFlux generates streamlined models that have 10.9$\times$ to 29.4$\times$ fewer parameters.
PAVITS: Exploring Prosody-aware VITS for End-to-End Emotional Voice Conversion
Mar 03, 2024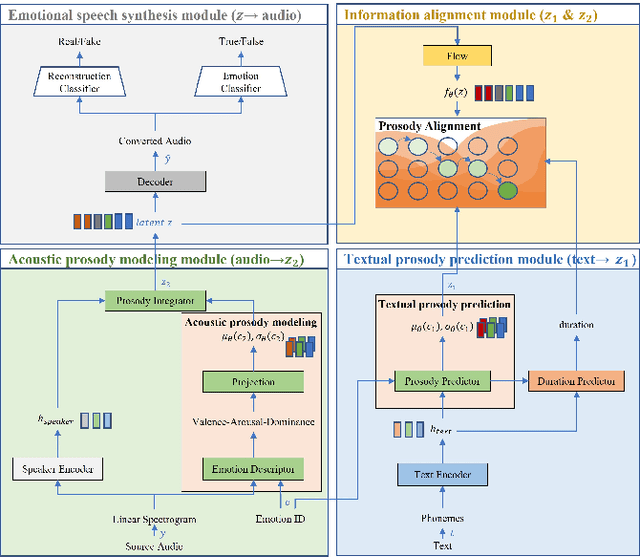
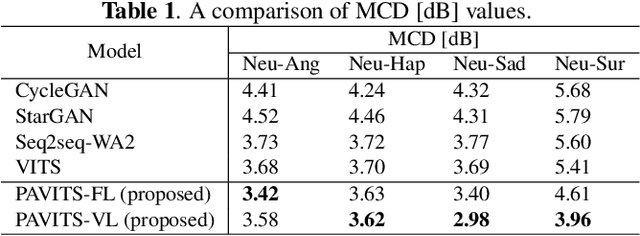
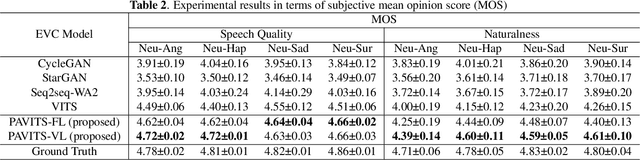
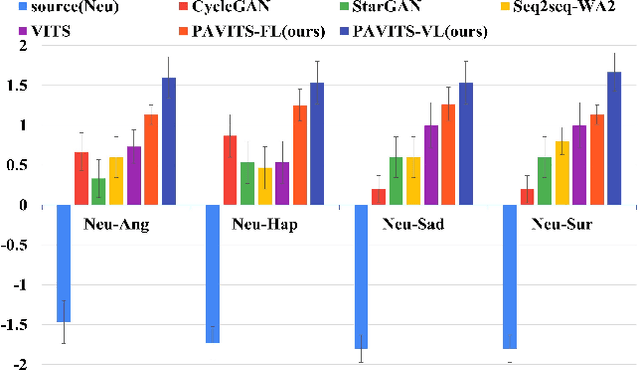
In this paper, we propose Prosody-aware VITS (PAVITS) for emotional voice conversion (EVC), aiming to achieve two major objectives of EVC: high content naturalness and high emotional naturalness, which are crucial for meeting the demands of human perception. To improve the content naturalness of converted audio, we have developed an end-to-end EVC architecture inspired by the high audio quality of VITS. By seamlessly integrating an acoustic converter and vocoder, we effectively address the common issue of mismatch between emotional prosody training and run-time conversion that is prevalent in existing EVC models. To further enhance the emotional naturalness, we introduce an emotion descriptor to model the subtle prosody variations of different speech emotions. Additionally, we propose a prosody predictor, which predicts prosody features from text based on the provided emotion label. Notably, we introduce a prosody alignment loss to establish a connection between latent prosody features from two distinct modalities, ensuring effective training. Experimental results show that the performance of PAVITS is superior to the state-of-the-art EVC methods. Speech Samples are available at https://jeremychee4.github.io/pavits4EVC/ .
Learning from Time Series under Temporal Label Noise
Feb 06, 2024Many sequential classification tasks are affected by label noise that varies over time. Such noise can cause label quality to improve, worsen, or periodically change over time. We first propose and formalize temporal label noise, an unstudied problem for sequential classification of time series. In this setting, multiple labels are recorded in sequence while being corrupted by a time-dependent noise function. We first demonstrate the importance of modelling the temporal nature of the label noise function and how existing methods will consistently underperform. We then propose methods that can train noise-tolerant classifiers by estimating the temporal label noise function directly from data. We show that our methods lead to state-of-the-art performance in the presence of diverse temporal label noise functions using real and synthetic data.
Airport take-off and landing optimization through genetic algorithms
Feb 29, 2024This research addresses the crucial issue of pollution from aircraft operations, focusing on optimizing both gate allocation and runway scheduling simultaneously, a novel approach not previously explored. The study presents an innovative genetic algorithm-based method for minimizing pollution from fuel combustion during aircraft take-off and landing at airports. This algorithm uniquely integrates the optimization of both landing gates and take-off/landing runways, considering the correlation between engine operation time and pollutant levels. The approach employs advanced constraint handling techniques to manage the intricate time and resource limitations inherent in airport operations. Additionally, the study conducts a thorough sensitivity analysis of the model, with a particular emphasis on the mutation factor and the type of penalty function, to fine-tune the optimization process. This dual-focus optimization strategy represents a significant advancement in reducing environmental impact in the aviation sector, establishing a new standard for comprehensive and efficient airport operation management.
* Preprint submitted and accepted in Expert Systems