 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Impact of Adversarial Training on Robustness and Generalizability of Language Models
Nov 10, 2022

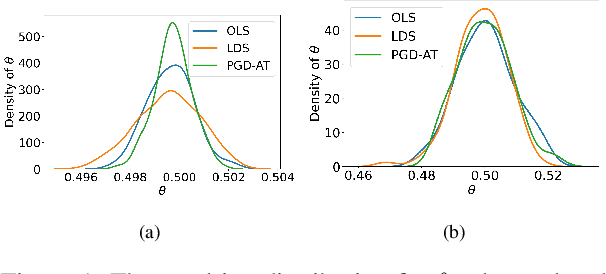
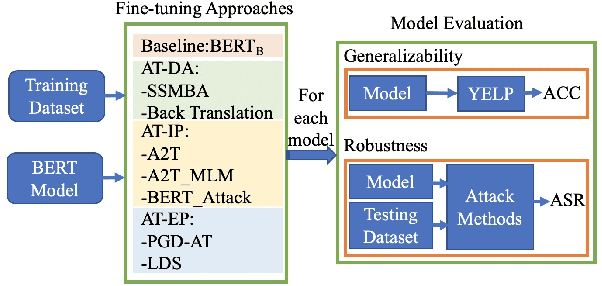
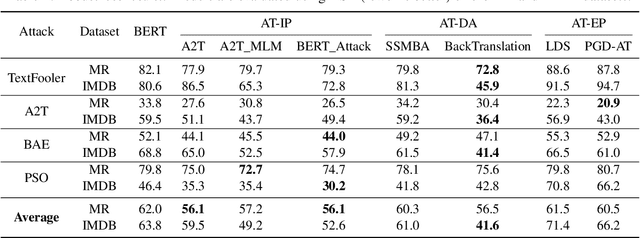
Adversarial training is widely acknowledged as the most effective defense against adversarial attacks. However, it is also well established that achieving both robustness and generalization in adversarially trained models involves a trade-off. The goal of this work is to provide an in depth comparison of different approaches for adversarial training in language models. Specifically, we study the effect of pre-training data augmentation as well as training time input perturbations vs. embedding space perturbations on the robustness and generalization of BERT-like language models. Our findings suggest that better robustness can be achieved by pre-training data augmentation or by training with input space perturbation. However, training with embedding space perturbation significantly improves generalization. A linguistic correlation analysis of neurons of the learned models reveal that the improved generalization is due to `more specialized' neurons. To the best of our knowledge, this is the first work to carry out a deep qualitative analysis of different methods of generating adversarial examples in adversarial training of language models.
DeepParliament: A Legal domain Benchmark & Dataset for Parliament Bills Prediction
Nov 15, 2022
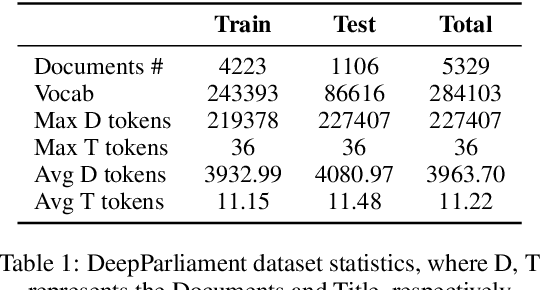
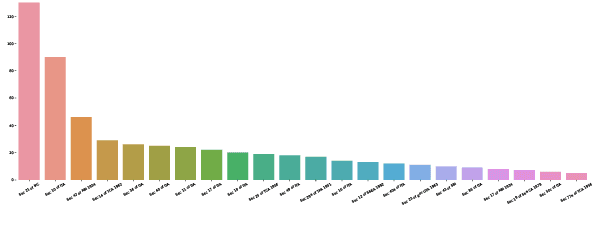
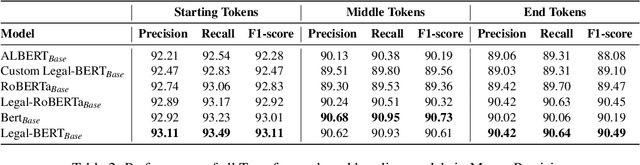
This paper introduces DeepParliament, a legal domain Benchmark Dataset that gathers bill documents and metadata and performs various bill status classification tasks. The proposed dataset text covers a broad range of bills from 1986 to the present and contains richer information on parliament bill content. Data collection, detailed statistics and analyses are provided in the paper. Moreover, we experimented with different types of models ranging from RNN to pretrained and reported the results. We are proposing two new benchmarks: Binary and Multi-Class Bill Status classification. Models developed for bill documents and relevant supportive tasks may assist Members of Parliament (MPs), presidents, and other legal practitioners. It will help review or prioritise bills, thus speeding up the billing process, improving the quality of decisions and reducing the time consumption in both houses. Considering that the foundation of the country's democracy is Parliament and state legislatures, we anticipate that our research will be an essential addition to the Legal NLP community. This work will be the first to present a Parliament bill prediction task. In order to improve the accessibility of legal AI resources and promote reproducibility, we have made our code and dataset publicly accessible at github.com/monk1337/DeepParliament
Collaborative and AI-aided Exam Question Generation using Wikidata in Education
Nov 15, 2022

Since the COVID-19 outbreak, the use of digital learning or education platforms has significantly increased. Teachers now digitally distribute homework and provide exercise questions. In both cases, teachers need to continuously develop novel and individual questions. This process can be very time-consuming and should be facilitated and accelerated both through exchange with other teachers and by using Artificial Intelligence (AI) capabilities. To address this need, we propose a multilingual Wikimedia framework that allows for collaborative worldwide teacher knowledge engineering and subsequent AI-aided question generation, test, and correction. As a proof of concept, we present >>PhysWikiQuiz<<, a physics question generation and test engine. Our system (hosted by Wikimedia at https://physwikiquiz.wmflabs.org) retrieves physics knowledge from the open community-curated database Wikidata. It can generate questions in different variations and verify answer values and units using a Computer Algebra System (CAS). We evaluate the performance on a public benchmark dataset at each stage of the system workflow. For an average formula with three variables, the system can generate and correct up to 300 questions for individual students based on a single formula concept name as input by the teacher.
Deconfounded Imitation Learning
Nov 04, 2022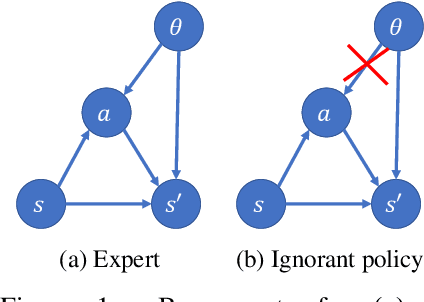


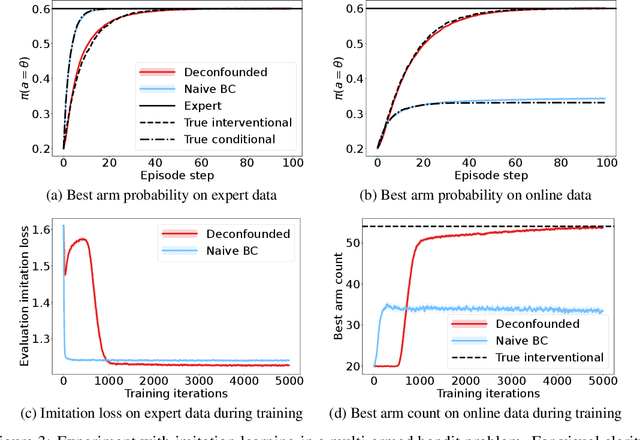
Standard imitation learning can fail when the expert demonstrators have different sensory inputs than the imitating agent. This is because partial observability gives rise to hidden confounders in the causal graph. We break down the space of confounded imitation learning problems and identify three settings with different data requirements in which the correct imitation policy can be identified. We then introduce an algorithm for deconfounded imitation learning, which trains an inference model jointly with a latent-conditional policy. At test time, the agent alternates between updating its belief over the latent and acting under the belief. We show in theory and practice that this algorithm converges to the correct interventional policy, solves the confounding issue, and can under certain assumptions achieve an asymptotically optimal imitation performance.
DynImp: Dynamic Imputation for Wearable Sensing Data Through Sensory and Temporal Relatedness
Sep 26, 2022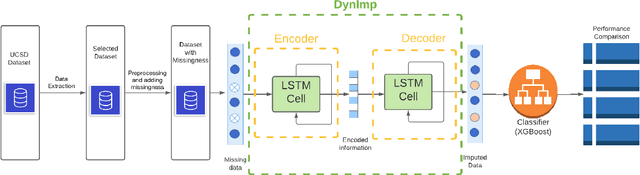

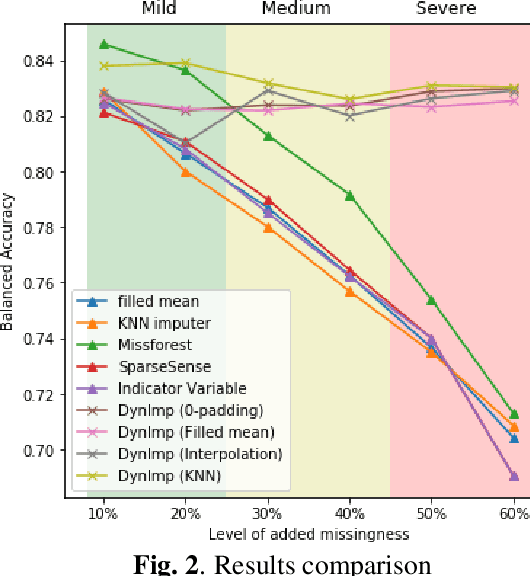
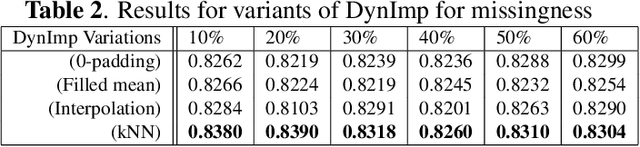
In wearable sensing applications, data is inevitable to be irregularly sampled or partially missing, which pose challenges for any downstream application. An unique aspect of wearable data is that it is time-series data and each channel can be correlated to another one, such as x, y, z axis of accelerometer. We argue that traditional methods have rarely made use of both times-series dynamics of the data as well as the relatedness of the features from different sensors. We propose a model, termed as DynImp, to handle different time point's missingness with nearest neighbors along feature axis and then feeding the data into a LSTM-based denoising autoencoder which can reconstruct missingness along the time axis. We experiment the model on the extreme missingness scenario ($>50\%$ missing rate) which has not been widely tested in wearable data. Our experiments on activity recognition show that the method can exploit the multi-modality features from related sensors and also learn from history time-series dynamics to reconstruct the data under extreme missingness.
Impedance Variation Detection at MISO Receivers
Nov 07, 2022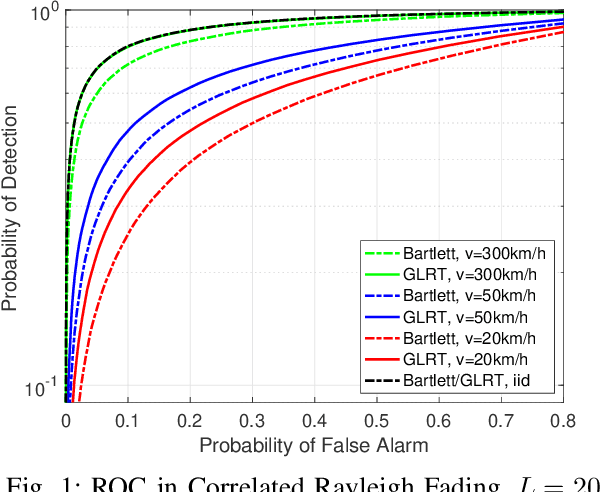
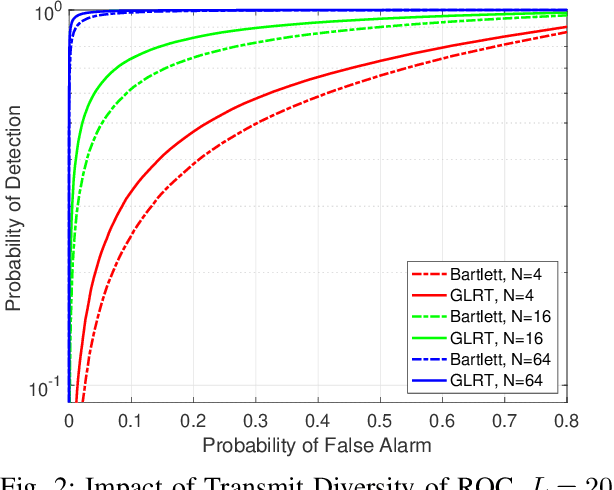
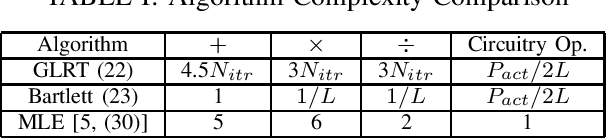
Techniques have been proposed to estimate unknown antenna impedance due to time-varying near-field loading conditions at multiple-input single-output (MISO) receivers. However, it remains unclear when a change occurs and impedance estimation becomes necessary. In this letter, we address this problem by formulating it as a hypothesis test. Our contributions include deriving a generalized likelihood-ratio test (GLRT) detector to decide if the antenna impedance has changed over two groups of packets. This GLRT formulation leads to a novel optimization problem, but we propose a binary search based algorithm to solve it efficiently. Our derived GLRT detector enjoys a better detection and false alarm trade-off when compared with a well-known, reference detector in simulations. As one result, more transmit diversity significantly improves detection accuracy at a given false alarm rate, especially in slow fading channels.
Background-Mixed Augmentation for Weakly Supervised Change Detection
Nov 21, 2022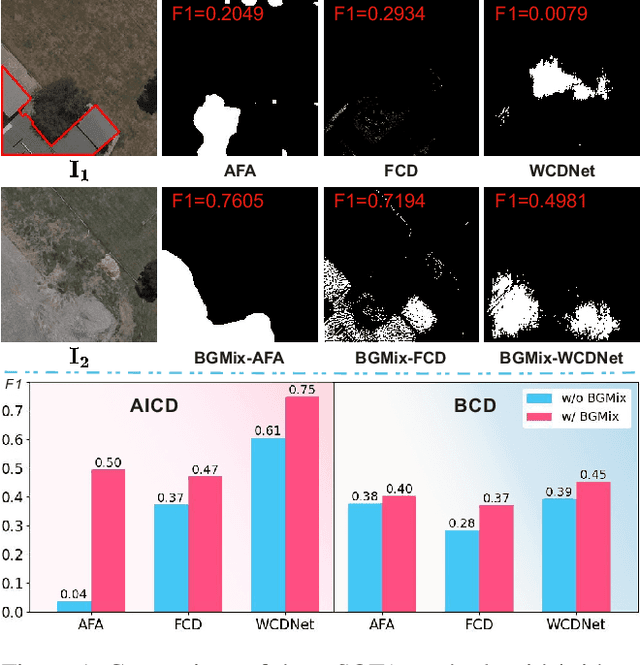
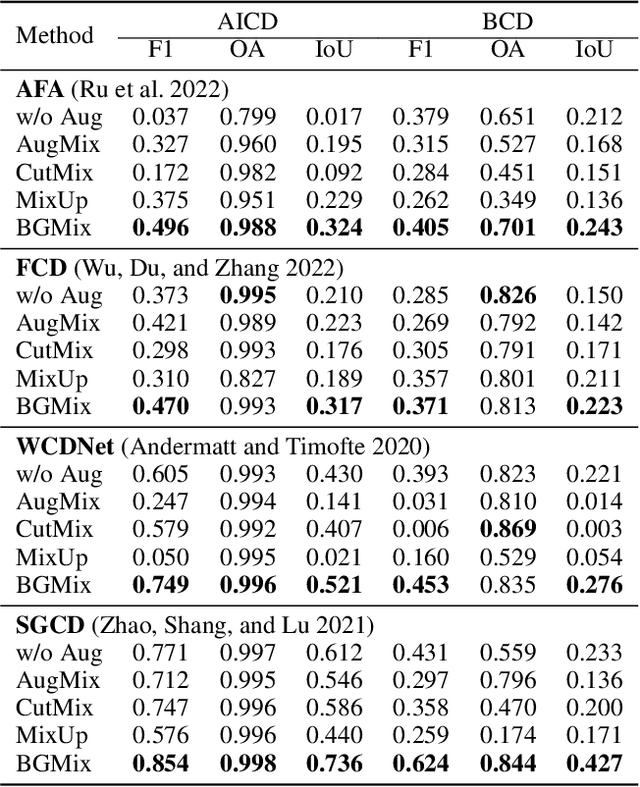

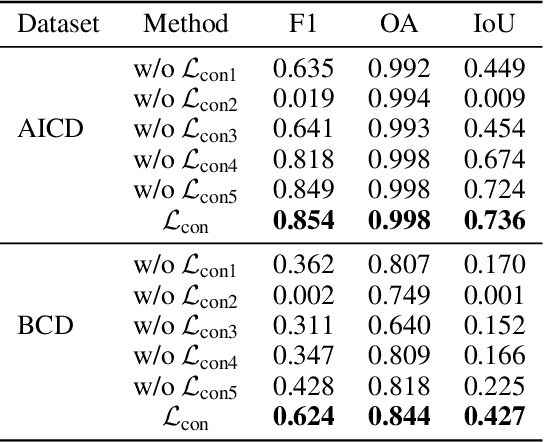
Change detection (CD) is to decouple object changes (i.e., object missing or appearing) from background changes (i.e., environment variations) like light and season variations in two images captured in the same scene over a long time span, presenting critical applications in disaster management, urban development, etc. In particular, the endless patterns of background changes require detectors to have a high generalization against unseen environment variations, making this task significantly challenging. Recent deep learning-based methods develop novel network architectures or optimization strategies with paired-training examples, which do not handle the generalization issue explicitly and require huge manual pixel-level annotation efforts. In this work, for the first attempt in the CD community, we study the generalization issue of CD from the perspective of data augmentation and develop a novel weakly supervised training algorithm that only needs image-level labels. Different from general augmentation techniques for classification, we propose the background-mixed augmentation that is specifically designed for change detection by augmenting examples under the guidance of a set of background changing images and letting deep CD models see diverse environment variations. Moreover, we propose the augmented & real data consistency loss that encourages the generalization increase significantly. Our method as a general framework can enhance a wide range of existing deep learning-based detectors. We conduct extensive experiments in two public datasets and enhance four state-of-the-art methods, demonstrating the advantages of
Self-supervised Trajectory Representation Learning with Temporal Regularities and Travel Semantics
Nov 21, 2022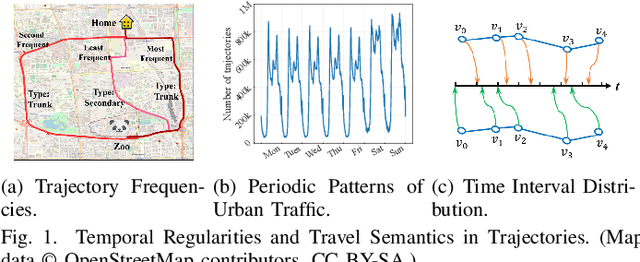
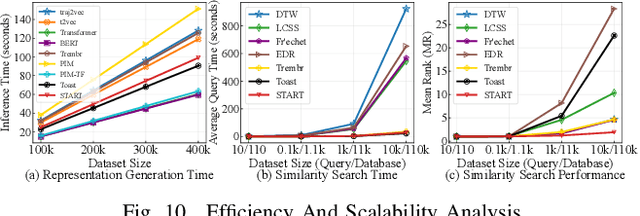
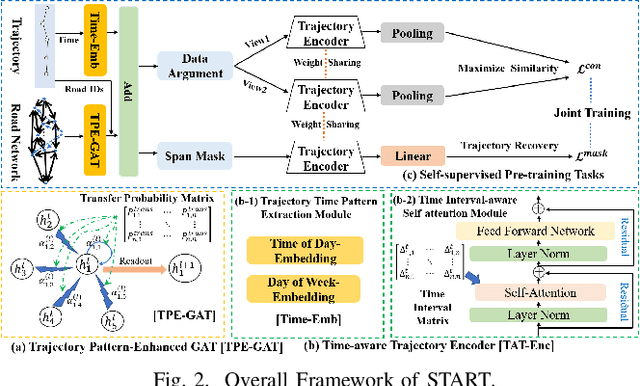
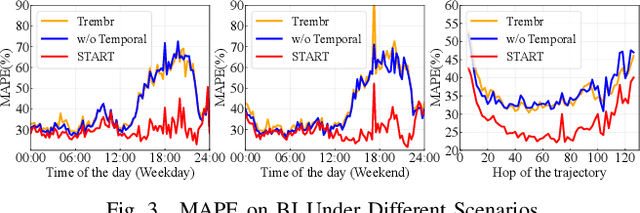
Trajectory Representation Learning (TRL) is a powerful tool for spatial-temporal data analysis and management. TRL aims to convert complicated raw trajectories into low-dimensional representation vectors, which can be applied to various downstream tasks, such as trajectory classification, clustering, and similarity computation. Existing TRL works usually treat trajectories as ordinary sequence data, while some important spatial-temporal characteristics, such as temporal regularities and travel semantics, are not fully exploited. To fill this gap, we propose a novel Self-supervised trajectory representation learning framework with TemporAl Regularities and Travel semantics, namely START. The proposed method consists of two stages. The first stage is a Trajectory Pattern-Enhanced Graph Attention Network (TPE-GAT), which converts the road network features and travel semantics into representation vectors of road segments. The second stage is a Time-Aware Trajectory Encoder (TAT-Enc), which encodes representation vectors of road segments in the same trajectory as a trajectory representation vector, meanwhile incorporating temporal regularities with the trajectory representation. Moreover, we also design two self-supervised tasks, i.e., span-masked trajectory recovery and trajectory contrastive learning, to introduce spatial-temporal characteristics of trajectories into the training process of our START framework. The effectiveness of the proposed method is verified by extensive experiments on two large-scale real-world datasets for three downstream tasks. The experiments also demonstrate that our method can be transferred across different cities to adapt heterogeneous trajectory datasets.
Learning Robust Real-Time Cultural Transmission without Human Data
Mar 01, 2022
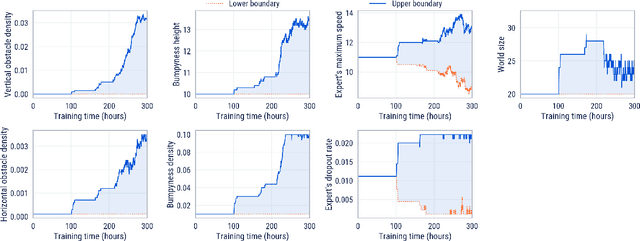
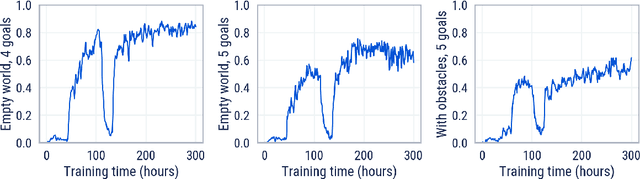
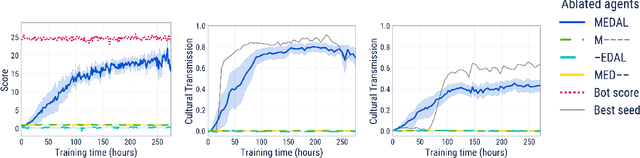
Cultural transmission is the domain-general social skill that allows agents to acquire and use information from each other in real-time with high fidelity and recall. In humans, it is the inheritance process that powers cumulative cultural evolution, expanding our skills, tools and knowledge across generations. We provide a method for generating zero-shot, high recall cultural transmission in artificially intelligent agents. Our agents succeed at real-time cultural transmission from humans in novel contexts without using any pre-collected human data. We identify a surprisingly simple set of ingredients sufficient for generating cultural transmission and develop an evaluation methodology for rigorously assessing it. This paves the way for cultural evolution as an algorithm for developing artificial general intelligence.
An Advantage Using Feature Selection with a Quantum Annealer
Nov 17, 2022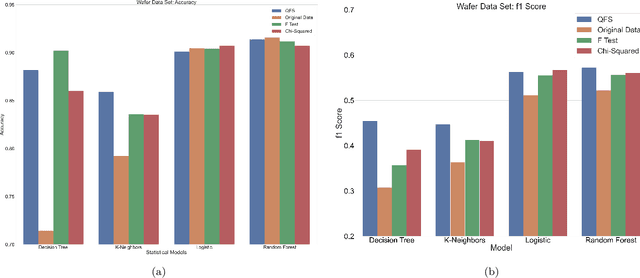
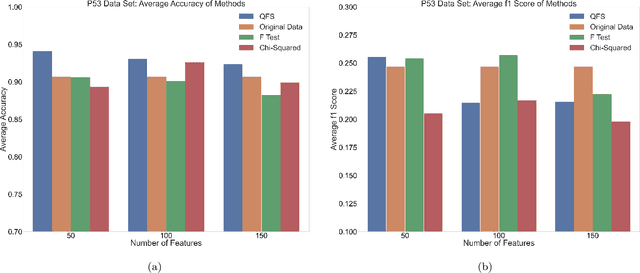
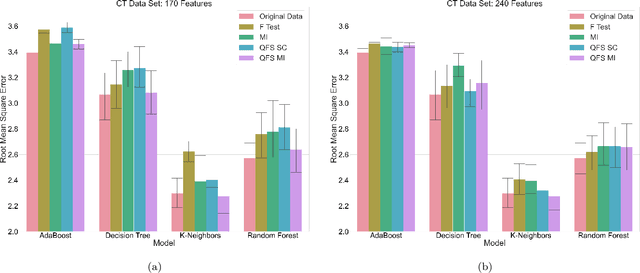
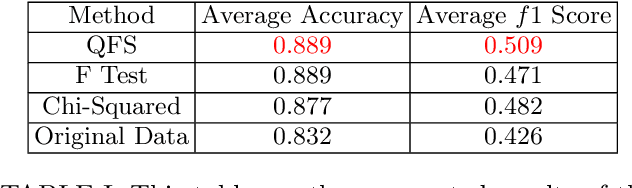
Feature selection is a technique in statistical prediction modeling that identifies features in a record with a strong statistical connection to the target variable. Excluding features with a weak statistical connection to the target variable in training not only drops the dimension of the data, which decreases the time complexity of the algorithm, it also decreases noise within the data which assists in avoiding overfitting. In all, feature selection assists in training a robust statistical model that performs well and is stable. Given the lack of scalability in classical computation, current techniques only consider the predictive power of the feature and not redundancy between the features themselves. Recent advancements in feature selection that leverages quantum annealing (QA) gives a scalable technique that aims to maximize the predictive power of the features while minimizing redundancy. As a consequence, it is expected that this algorithm would assist in the bias/variance trade-off yielding better features for training a statistical model. This paper tests this intuition against classical methods by utilizing open-source data sets and evaluate the efficacy of each trained statistical model well-known prediction algorithms. The numerical results display an advantage utilizing the features selected from the algorithm that leveraged QA.