 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Emotional Brain State Classification on fMRI Data Using Deep Residual and Convolutional Networks
Oct 31, 2022
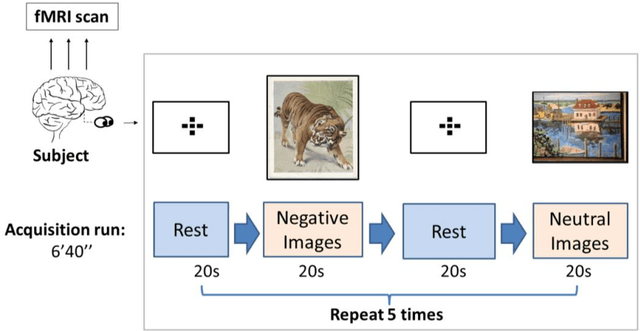
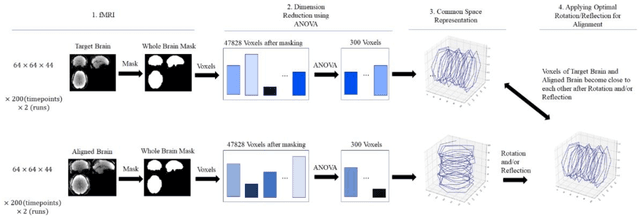
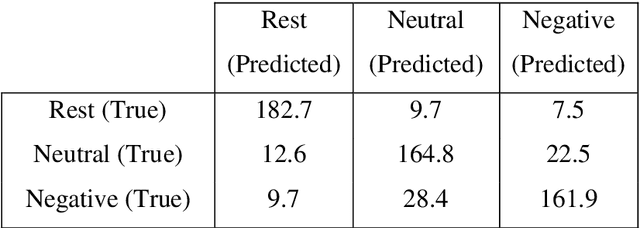
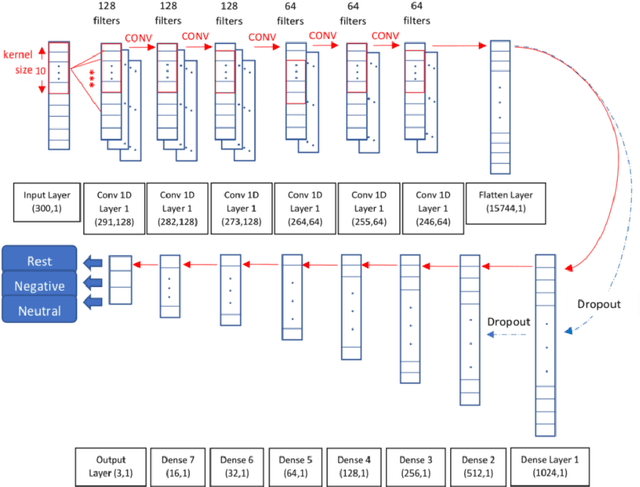
The goal of emotional brain state classification on functional MRI (fMRI) data is to recognize brain activity patterns related to specific emotion tasks performed by subjects during an experiment. Distinguishing emotional brain states from other brain states using fMRI data has proven to be challenging due to two factors: a difficulty to generate fast yet accurate predictions in short time frames, and a difficulty to extract emotion features which generalize to unseen subjects. To address these challenges, we conducted an experiment in which 22 subjects viewed pictures designed to stimulate either negative, neutral or rest emotional responses while their brain activity was measured using fMRI. We then developed two distinct Convolution-based approaches to decode emotional brain states using only spatial information from single, minimally pre-processed (slice timing and realignment) fMRI volumes. In our first approach, we trained a 1D Convolutional Network (84.9% accuracy; chance level 33%) to classify 3 emotion conditions using One-way Analysis of Variance (ANOVA) voxel selection combined with hyperalignment. In our second approach, we trained a 3D ResNet-50 model (78.0% accuracy; chance level 50%) to classify 2 emotion conditions from single 3D fMRI volumes directly. Our Convolutional and Residual classifiers successfully learned group-level emotion features and could decode emotion conditions from fMRI volumes in milliseconds. These approaches could potentially be used in brain computer interfaces and real-time fMRI neurofeedback research.
Semi-Random Sparse Recovery in Nearly-Linear Time
Mar 08, 2022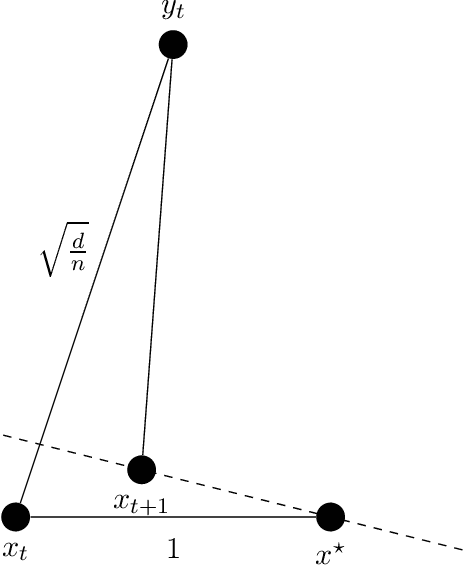
Sparse recovery is one of the most fundamental and well-studied inverse problems. Standard statistical formulations of the problem are provably solved by general convex programming techniques and more practical, fast (nearly-linear time) iterative methods. However, these latter "fast algorithms" have previously been observed to be brittle in various real-world settings. We investigate the brittleness of fast sparse recovery algorithms to generative model changes through the lens of studying their robustness to a "helpful" semi-random adversary, a framework which tests whether an algorithm overfits to input assumptions. We consider the following basic model: let $\mathbf{A} \in \mathbb{R}^{n \times d}$ be a measurement matrix which contains an unknown subset of rows $\mathbf{G} \in \mathbb{R}^{m \times d}$ which are bounded and satisfy the restricted isometry property (RIP), but is otherwise arbitrary. Letting $x^\star \in \mathbb{R}^d$ be $s$-sparse, and given either exact measurements $b = \mathbf{A} x^\star$ or noisy measurements $b = \mathbf{A} x^\star + \xi$, we design algorithms recovering $x^\star$ information-theoretically optimally in nearly-linear time. We extend our algorithm to hold for weaker generative models relaxing our planted RIP assumption to a natural weighted variant, and show that our method's guarantees naturally interpolate the quality of the measurement matrix to, in some parameter regimes, run in sublinear time. Our approach differs from prior fast iterative methods with provable guarantees under semi-random generative models: natural conditions on a submatrix which make sparse recovery tractable are NP-hard to verify. We design a new iterative method tailored to the geometry of sparse recovery which is provably robust to our semi-random model. We hope our approach opens the door to new robust, efficient algorithms for natural statistical inverse problems.
A Novel Frame Structure for Cloud-Based Audio-Visual Speech Enhancement in Multimodal Hearing-aids
Oct 24, 2022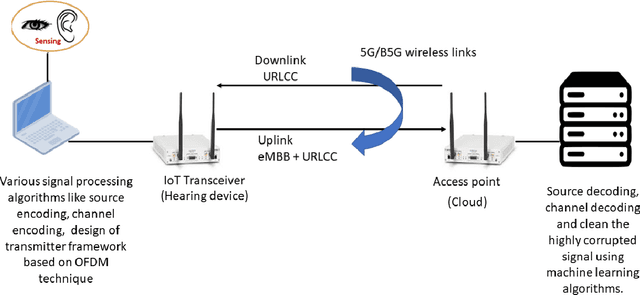
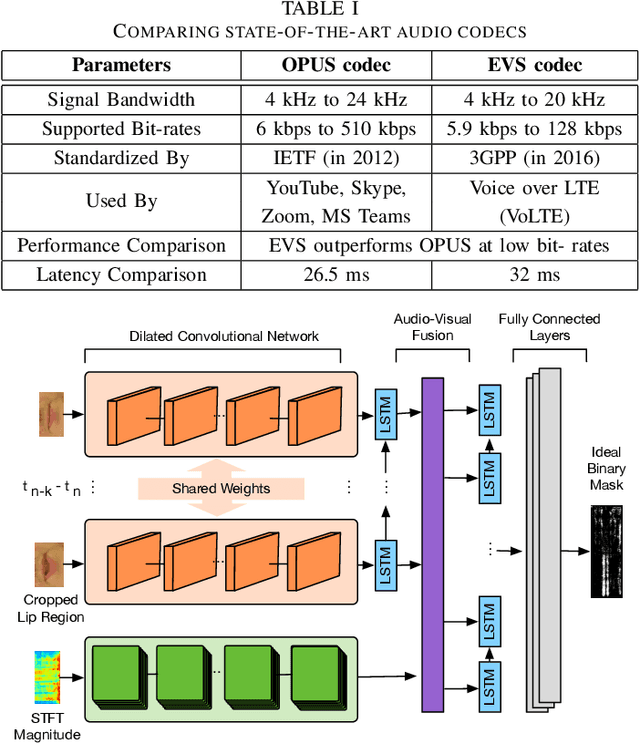
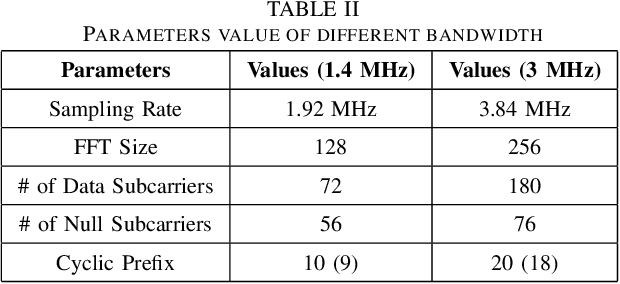
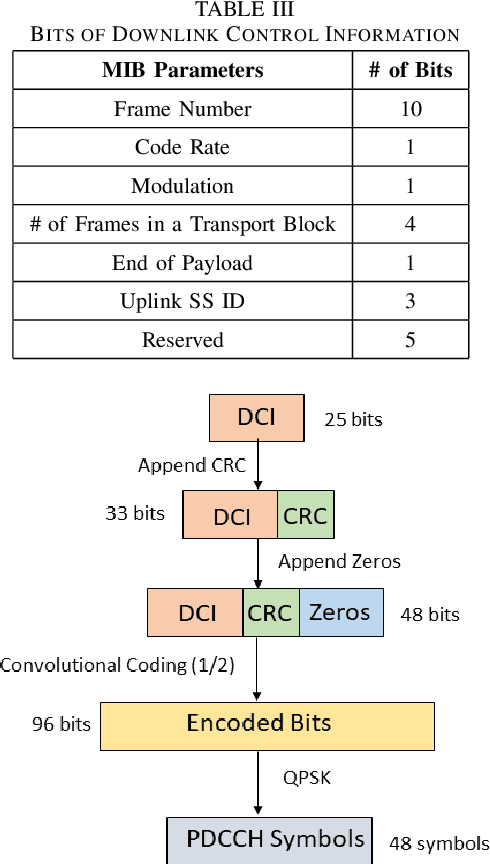
In this paper, we design a first of its kind transceiver (PHY layer) prototype for cloud-based audio-visual (AV) speech enhancement (SE) complying with high data rate and low latency requirements of future multimodal hearing assistive technology. The innovative design needs to meet multiple challenging constraints including up/down link communications, delay of transmission and signal processing, and real-time AV SE models processing. The transceiver includes device detection, frame detection, frequency offset estimation, and channel estimation capabilities. We develop both uplink (hearing aid to the cloud) and downlink (cloud to hearing aid) frame structures based on the data rate and latency requirements. Due to the varying nature of uplink information (audio and lip-reading), the uplink channel supports multiple data rate frame structure, while the downlink channel has a fixed data rate frame structure. In addition, we evaluate the latency of different PHY layer blocks of the transceiver for developed frame structures using LabVIEW NXG. This can be used with software defined radio (such as Universal Software Radio Peripheral) for real-time demonstration scenarios.
A Deep Learning Approach to Generating Photospheric Vector Magnetograms of Solar Active Regions for SOHO/MDI Using SDO/HMI and BBSO Data
Nov 04, 2022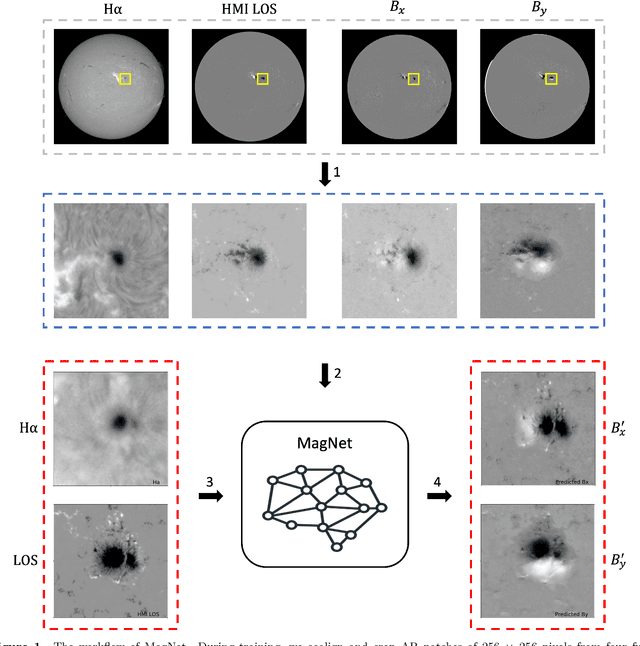

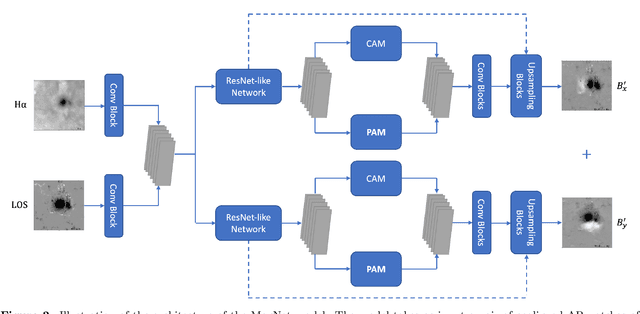
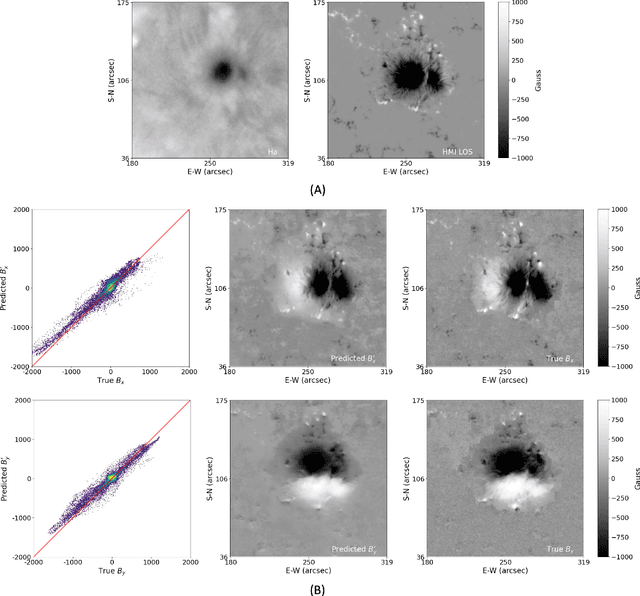
Solar activity is usually caused by the evolution of solar magnetic fields. Magnetic field parameters derived from photospheric vector magnetograms of solar active regions have been used to analyze and forecast eruptive events such as solar flares and coronal mass ejections. Unfortunately, the most recent solar cycle 24 was relatively weak with few large flares, though it is the only solar cycle in which consistent time-sequence vector magnetograms have been available through the Helioseismic and Magnetic Imager (HMI) on board the Solar Dynamics Observatory (SDO) since its launch in 2010. In this paper, we look into another major instrument, namely the Michelson Doppler Imager (MDI) on board the Solar and Heliospheric Observatory (SOHO) from 1996 to 2010. The data archive of SOHO/MDI covers more active solar cycle 23 with many large flares. However, SOHO/MDI data only has line-of-sight (LOS) magnetograms. We propose a new deep learning method, named MagNet, to learn from combined LOS magnetograms, Bx and By taken by SDO/HMI along with H-alpha observations collected by the Big Bear Solar Observatory (BBSO), and to generate vector components Bx' and By', which would form vector magnetograms with observed LOS data. In this way, we can expand the availability of vector magnetograms to the period from 1996 to present. Experimental results demonstrate the good performance of the proposed method. To our knowledge, this is the first time that deep learning has been used to generate photospheric vector magnetograms of solar active regions for SOHO/MDI using SDO/HMI and H-alpha data.
Data-Driven Modeling of Landau Damping by Physics-Informed Neural Networks
Nov 02, 2022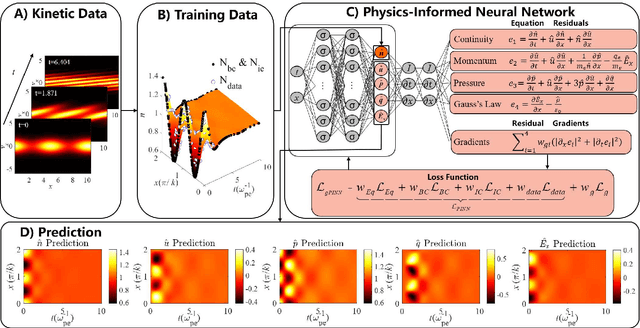
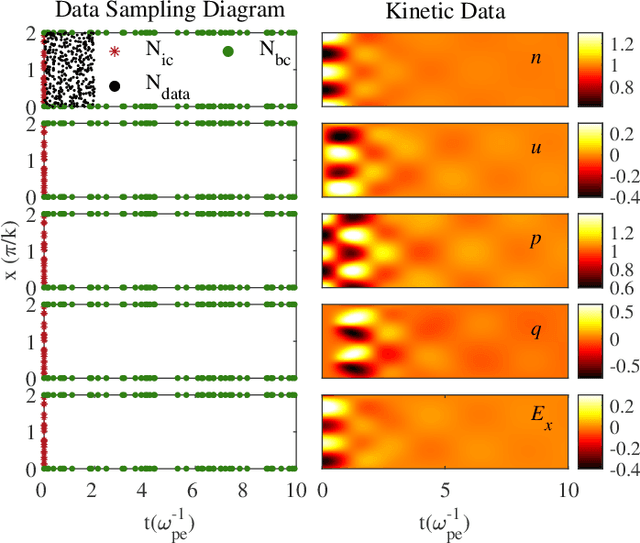
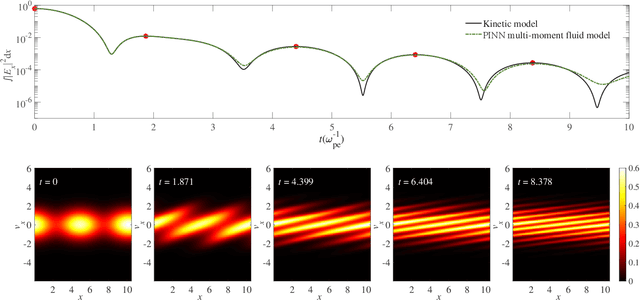
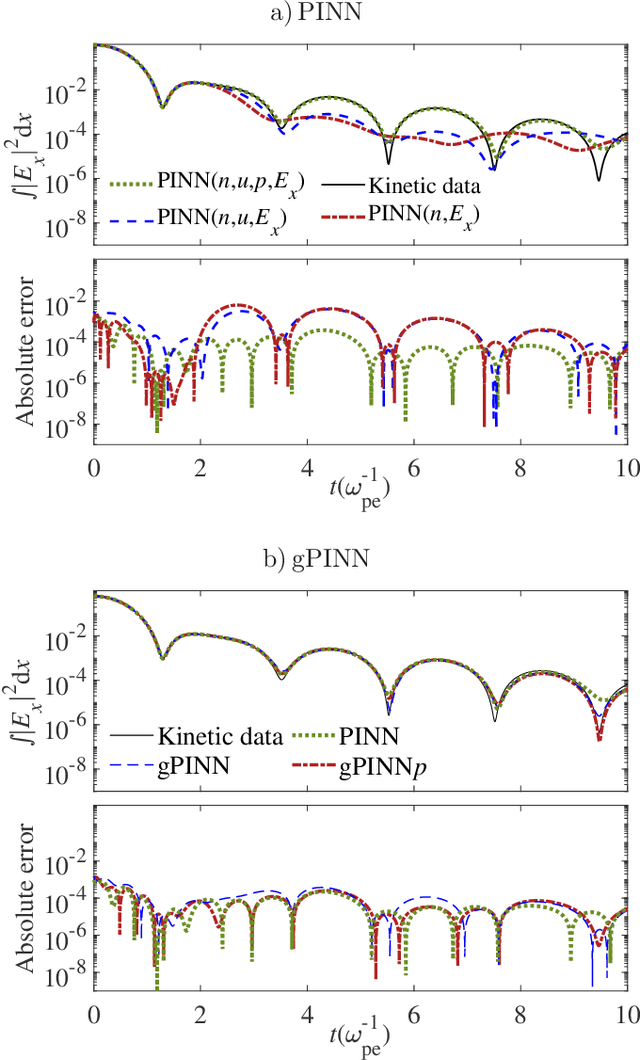
Kinetic approaches are generally accurate in dealing with microscale plasma physics problems but are computationally expensive for large-scale or multiscale systems. One of the long-standing problems in plasma physics is the integration of kinetic physics into fluid models, which is often achieved through sophisticated analytical closure terms. In this study, we successfully construct a multi-moment fluid model with an implicit fluid closure included in the neural network using machine learning. The multi-moment fluid model is trained with a small fraction of sparsely sampled data from kinetic simulations of Landau damping, using the physics-informed neural network (PINN) and the gradient-enhanced physics-informed neural network (gPINN). The multi-moment fluid model constructed using either PINN or gPINN reproduces the time evolution of the electric field energy, including its damping rate, and the plasma dynamics from the kinetic simulations. For the first time, we introduce a new variant of the gPINN architecture, namely, gPINN$p$ to capture the Landau damping process. Instead of including the gradients of all the equation residuals, gPINN$p$ only adds the gradient of the pressure equation residual as one additional constraint. Among the three approaches, the gPINN$p$-constructed multi-moment fluid model offers the most accurate results. This work sheds new light on the accurate and efficient modeling of large-scale systems, which can be extended to complex multiscale laboratory, space, and astrophysical plasma physics problems.
A Reinforcement Learning Approach to Estimating Long-term Treatment Effects
Oct 14, 2022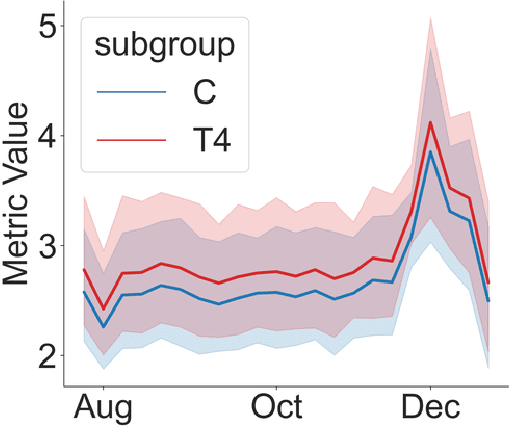

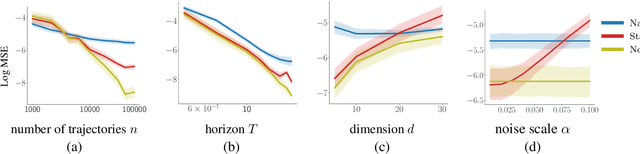
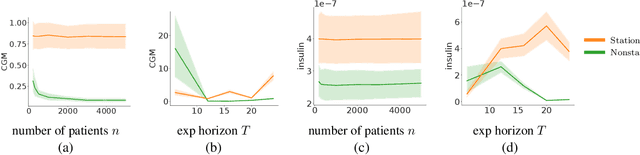
Randomized experiments (a.k.a. A/B tests) are a powerful tool for estimating treatment effects, to inform decisions making in business, healthcare and other applications. In many problems, the treatment has a lasting effect that evolves over time. A limitation with randomized experiments is that they do not easily extend to measure long-term effects, since running long experiments is time-consuming and expensive. In this paper, we take a reinforcement learning (RL) approach that estimates the average reward in a Markov process. Motivated by real-world scenarios where the observed state transition is nonstationary, we develop a new algorithm for a class of nonstationary problems, and demonstrate promising results in two synthetic datasets and one online store dataset.
(When) Are Contrastive Explanations of Reinforcement Learning Helpful?
Nov 14, 2022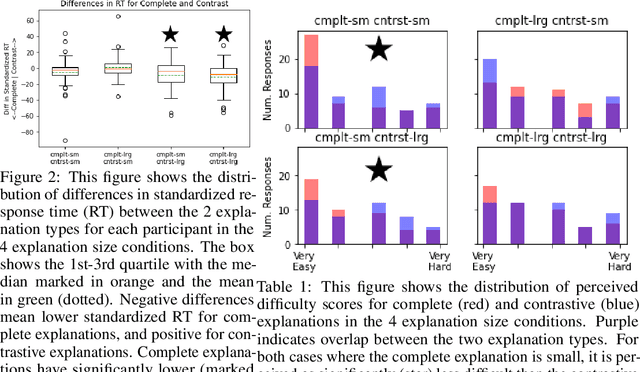


Global explanations of a reinforcement learning (RL) agent's expected behavior can make it safer to deploy. However, such explanations are often difficult to understand because of the complicated nature of many RL policies. Effective human explanations are often contrastive, referencing a known contrast (policy) to reduce redundancy. At the same time, these explanations also require the additional effort of referencing that contrast when evaluating an explanation. We conduct a user study to understand whether and when contrastive explanations might be preferable to complete explanations that do not require referencing a contrast. We find that complete explanations are generally more effective when they are the same size or smaller than a contrastive explanation of the same policy, and no worse when they are larger. This suggests that contrastive explanations are not sufficient to solve the problem of effectively explaining reinforcement learning policies, and require additional careful study for use in this context.
Advancing the State-of-the-Art for ECG Analysis through Structured State Space Models
Nov 14, 2022
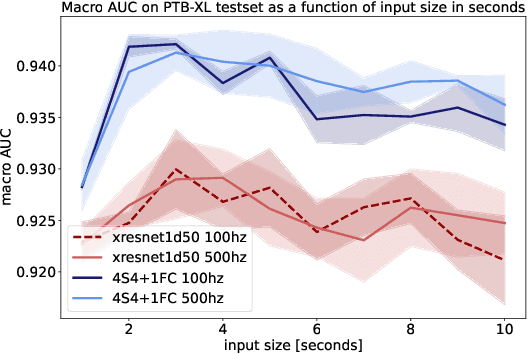
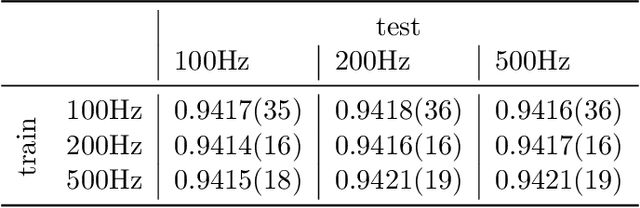
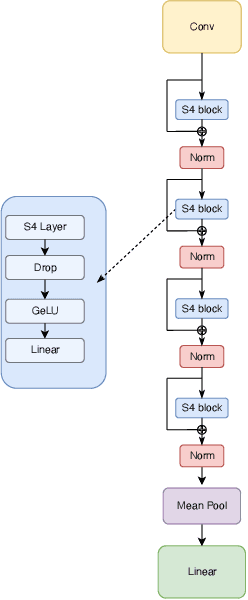
The field of deep-learning-based ECG analysis has been largely dominated by convolutional architectures. This work explores the prospects of applying the recently introduced structured state space models (SSMs) as a particularly promising approach due to its ability to capture long-term dependencies in time series. We demonstrate that this approach leads to significant improvements over the current state-of-the-art for ECG classification, which we trace back to individual pathologies. Furthermore, the model's ability to capture long-term dependencies allows to shed light on long-standing questions in the literature such as the optimal sampling rate or window size to train classification models. Interestingly, we find no evidence for using data sampled at 500Hz as opposed to 100Hz and no advantages from extending the model's input size beyond 3s. Based on this very promising first assessment, SSMs could develop into a new modeling paradigm for ECG analysis.
Summarisation of Electronic Health Records with Clinical Concept Guidance
Nov 14, 2022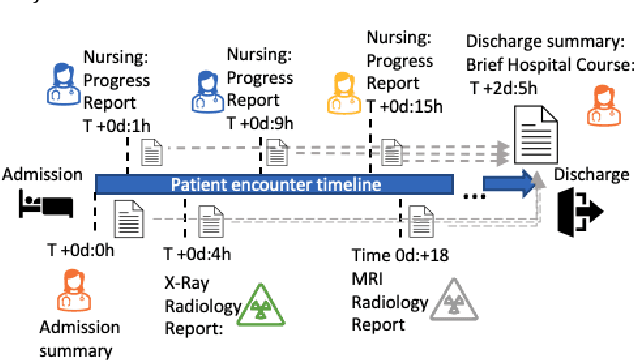
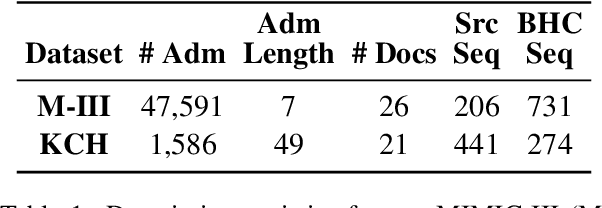
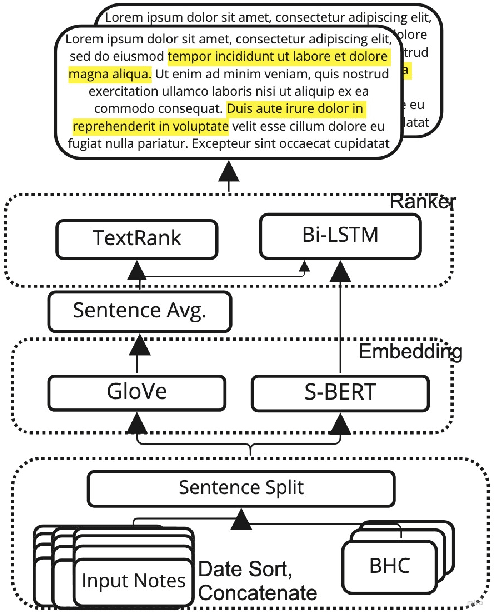
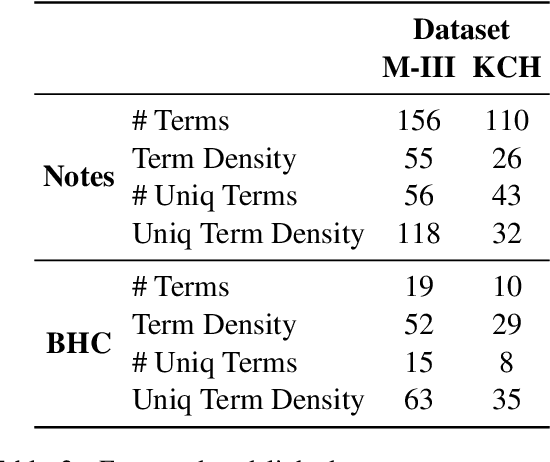
Brief Hospital Course (BHC) summaries are succinct summaries of an entire hospital encounter, embedded within discharge summaries, written by senior clinicians responsible for the overall care of a patient. Methods to automatically produce summaries from inpatient documentation would be invaluable in reducing clinician manual burden of summarising documents under high time-pressure to admit and discharge patients. Automatically producing these summaries from the inpatient course, is a complex, multi-document summarisation task, as source notes are written from various perspectives (e.g. nursing, doctor, radiology), during the course of the hospitalisation. We demonstrate a range of methods for BHC summarisation demonstrating the performance of deep learning summarisation models across extractive and abstractive summarisation scenarios. We also test a novel ensemble extractive and abstractive summarisation model that incorporates a medical concept ontology (SNOMED) as a clinical guidance signal and shows superior performance in 2 real-world clinical data sets.
Data Quality Over Quantity: Pitfalls and Guidelines for Process Analytics
Nov 11, 2022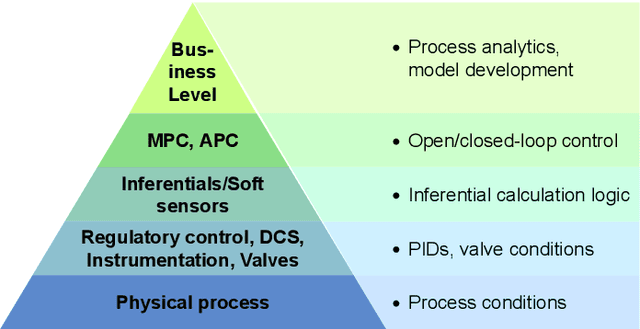
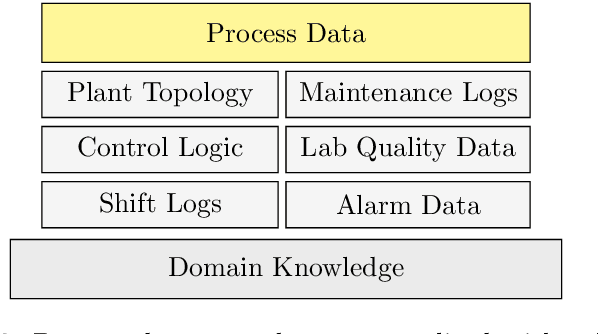
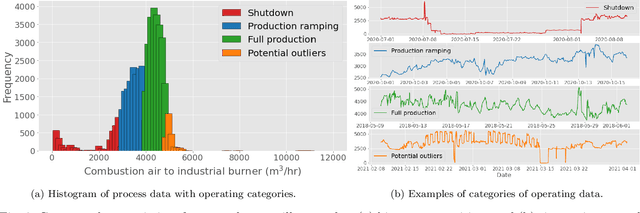
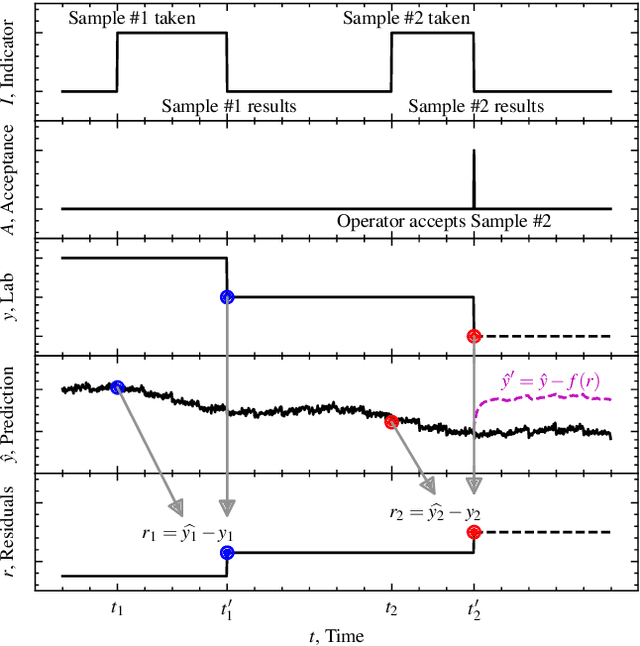
A significant portion of the effort involved in advanced process control, process analytics, and machine learning involves acquiring and preparing data. The published literature often emphasizes increasingly complex modeling techniques with incremental performance improvements. However, when industrial case studies are published they often lack important details on data acquisition and preparation. Although data pre-processing is often unfairly maligned as trivial and technically uninteresting, in practice it has an out-sized influence on the success of real-world artificial intelligence applications. This work describes best practices for acquiring and preparing operating data to pursue data-driven modelling and control opportunities in industrial processes. We present practical considerations for pre-processing industrial time series data to inform the efficient development of reliable soft sensors that provide valuable process insights.