 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CL2R: Compatible Lifelong Learning Representations
Nov 16, 2022
In this paper, we propose a method to partially mimic natural intelligence for the problem of lifelong learning representations that are compatible. We take the perspective of a learning agent that is interested in recognizing object instances in an open dynamic universe in a way in which any update to its internal feature representation does not render the features in the gallery unusable for visual search. We refer to this learning problem as Compatible Lifelong Learning Representations (CL2R) as it considers compatible representation learning within the lifelong learning paradigm. We identify stationarity as the property that the feature representation is required to hold to achieve compatibility and propose a novel training procedure that encourages local and global stationarity on the learned representation. Due to stationarity, the statistical properties of the learned features do not change over time, making them interoperable with previously learned features. Extensive experiments on standard benchmark datasets show that our CL2R training procedure outperforms alternative baselines and state-of-the-art methods. We also provide novel metrics to specifically evaluate compatible representation learning under catastrophic forgetting in various sequential learning tasks. Code at https://github.com/NiccoBiondi/CompatibleLifelongRepresentation.
Parameter-Efficient Tuning on Layer Normalization for Pre-trained Language Models
Nov 16, 2022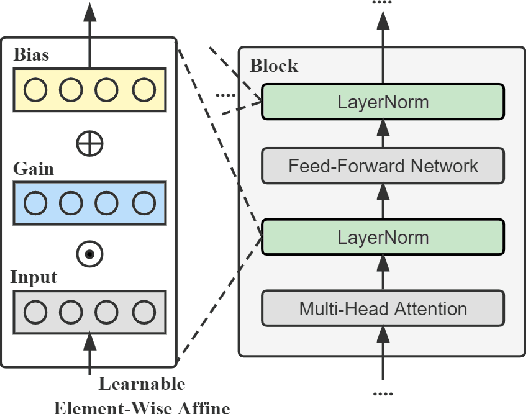
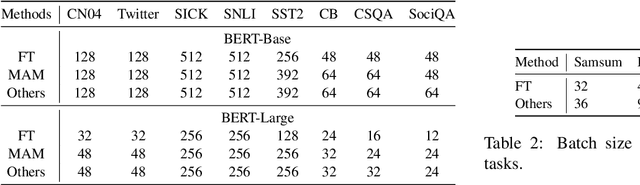
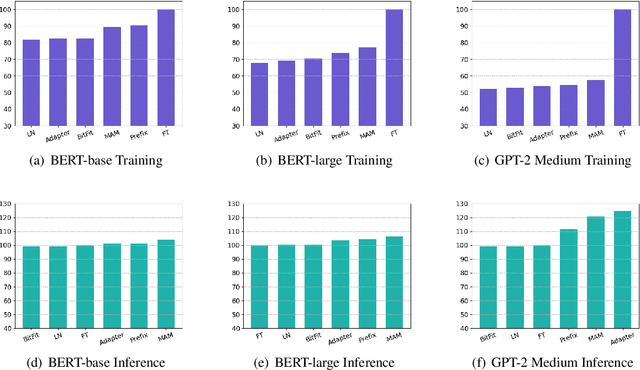
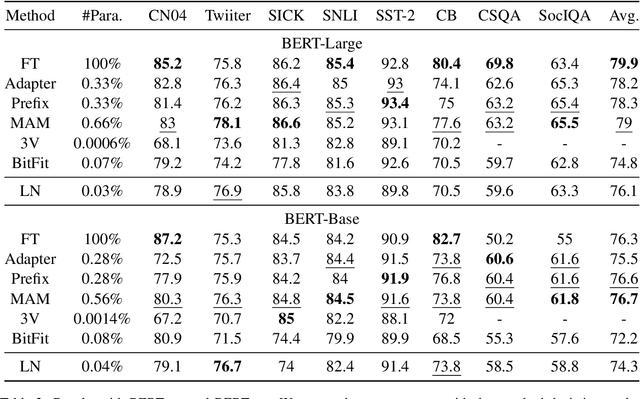
Conventional fine-tuning encounters increasing difficulties given the size of current Pre-trained Language Models, which makes parameter-efficient tuning become the focal point of frontier research. Previous methods in this field add tunable adapters into MHA or/and FFN of Transformer blocks to enable PLMs achieve transferability. However, as an important part of Transformer architecture, the power of layer normalization for parameter-efficent tuning is ignored. In this paper, we first propose LN-tuning, by tuning the gain and bias term of Layer Normalization module with only 0.03\% parameters, which is of high time-efficency and significantly superior to baselines which are less than 0.1\% tunable parameters. Further, we study the unified framework of combining LN-tuning with previous ones and we find that: (1) the unified framework of combining prefix-tuning, the adapter-based method working on MHA, and LN-tuning achieves SOTA performance. (2) unified framework which tunes MHA and LayerNorm simultaneously can get performance improvement but those which tune FFN and LayerNorm simultaneous will cause performance decrease. Ablation study validates LN-tuning is of no abundant parameters and gives a further understanding of it.
Semi-Supervised and Self-Supervised Collaborative Learning for Prostate 3D MR Image Segmentation
Nov 16, 2022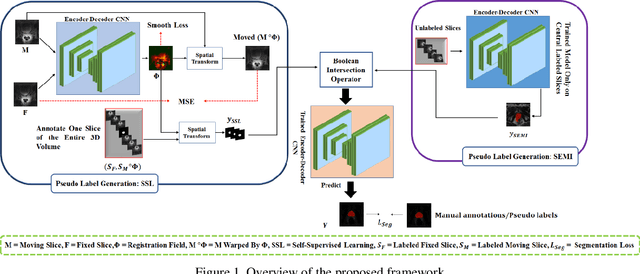
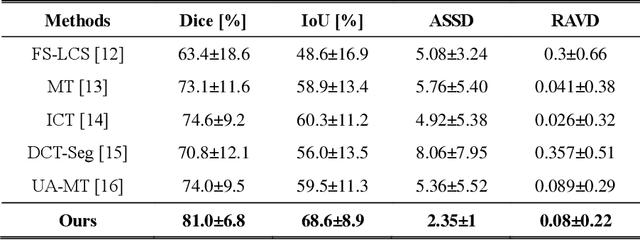
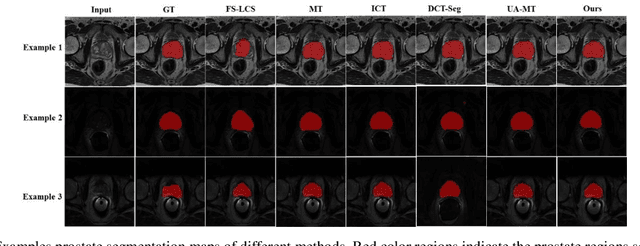
Volumetric magnetic resonance (MR) image segmentation plays an important role in many clinical applications. Deep learning (DL) has recently achieved state-of-the-art or even human-level performance on various image segmentation tasks. Nevertheless, manually annotating volumetric MR images for DL model training is labor-exhaustive and time-consuming. In this work, we aim to train a semi-supervised and self-supervised collaborative learning framework for prostate 3D MR image segmentation while using extremely sparse annotations, for which the ground truth annotations are provided for just the central slice of each volumetric MR image. Specifically, semi-supervised learning and self-supervised learning methods are used to generate two independent sets of pseudo labels. These pseudo labels are then fused by Boolean operation to extract a more confident pseudo label set. The images with either manual or network self-generated labels are then employed to train a segmentation model for target volume extraction. Experimental results on a publicly available prostate MR image dataset demonstrate that, while requiring significantly less annotation effort, our framework generates very encouraging segmentation results. The proposed framework is very useful in clinical applications when training data with dense annotations are difficult to obtain.
Dueling Bandits: From Two-dueling to Multi-dueling
Nov 16, 2022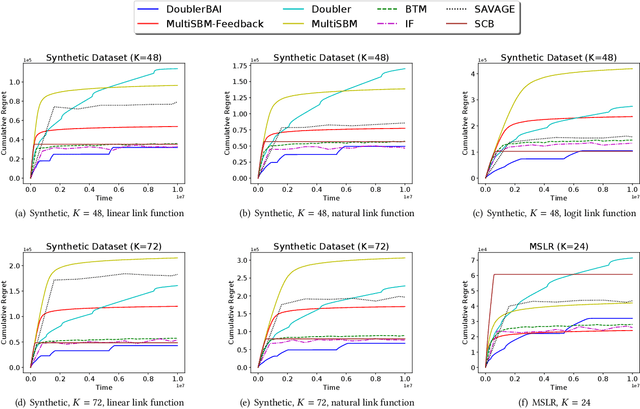
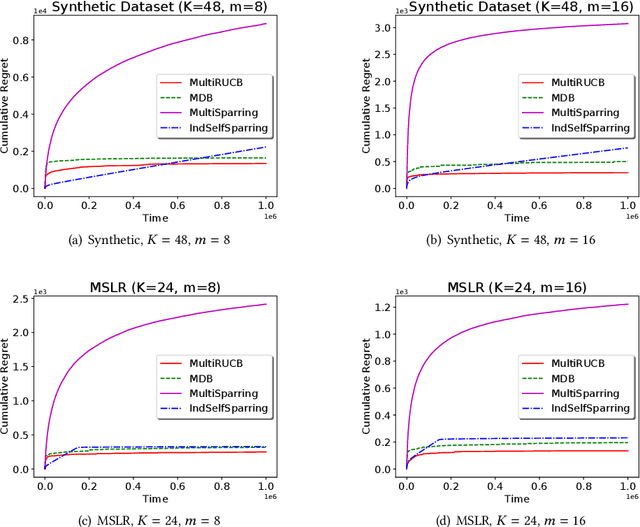
We study a general multi-dueling bandit problem, where an agent compares multiple options simultaneously and aims to minimize the regret due to selecting suboptimal arms. This setting generalizes the traditional two-dueling bandit problem and finds many real-world applications involving subjective feedback on multiple options. We start with the two-dueling bandit setting and propose two efficient algorithms, DoublerBAI and MultiSBM-Feedback. DoublerBAI provides a generic schema for translating known results on best arm identification algorithms to the dueling bandit problem, and achieves a regret bound of $O(\ln T)$. MultiSBM-Feedback not only has an optimal $O(\ln T)$ regret, but also reduces the constant factor by almost a half compared to benchmark results. Then, we consider the general multi-dueling case and develop an efficient algorithm MultiRUCB. Using a novel finite-time regret analysis for the general multi-dueling bandit problem, we show that MultiRUCB also achieves an $O(\ln T)$ regret bound and the bound tightens as the capacity of the comparison set increases. Based on both synthetic and real-world datasets, we empirically demonstrate that our algorithms outperform existing algorithms.
Pushing the limits of self-supervised speaker verification using regularized distillation framework
Nov 08, 2022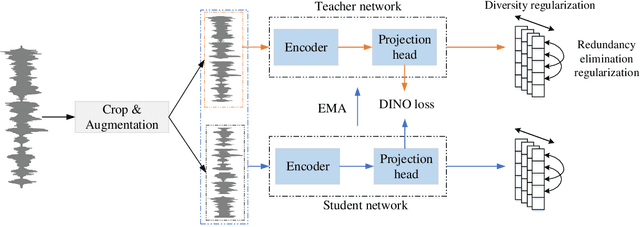
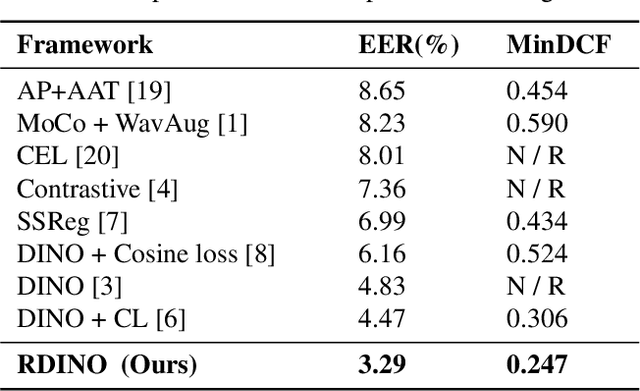
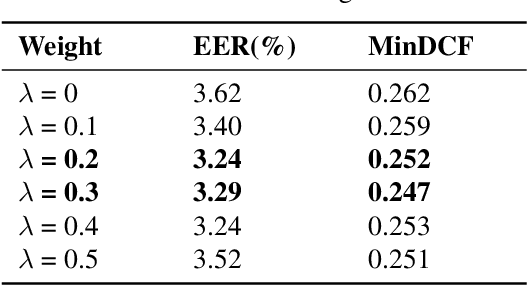
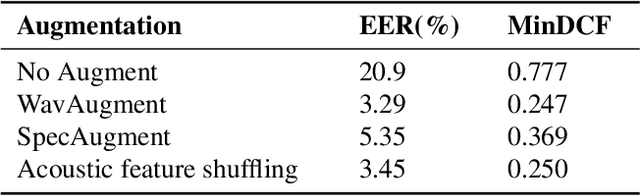
Training robust speaker verification systems without speaker labels has long been a challenging task. Previous studies observed a large performance gap between self-supervised and fully supervised methods. In this paper, we apply a non-contrastive self-supervised learning framework called DIstillation with NO labels (DINO) and propose two regularization terms applied to embeddings in DINO. One regularization term guarantees the diversity of the embeddings, while the other regularization term decorrelates the variables of each embedding. The effectiveness of various data augmentation techniques are explored, on both time and frequency domain. A range of experiments conducted on the VoxCeleb datasets demonstrate the superiority of the regularized DINO framework in speaker verification. Our method achieves the state-of-the-art speaker verification performance under a single-stage self-supervised setting on VoxCeleb. The codes will be made publicly-available.
Evaluation of Color Anomaly Detection in Multispectral Images For Synthetic Aperture Sensing
Nov 08, 2022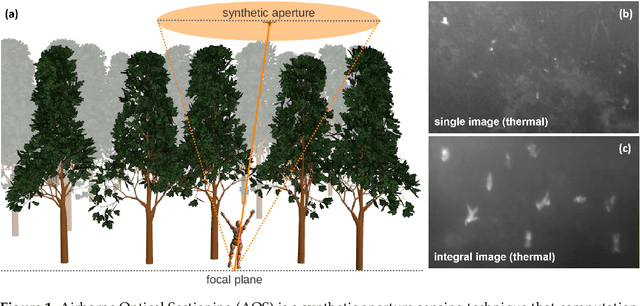
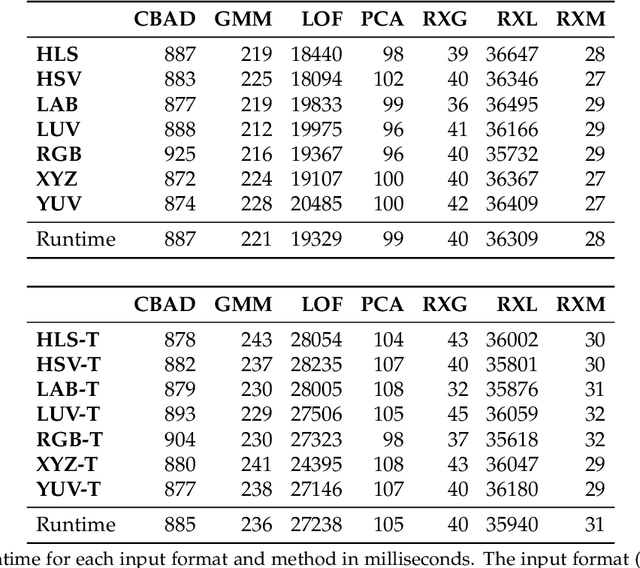

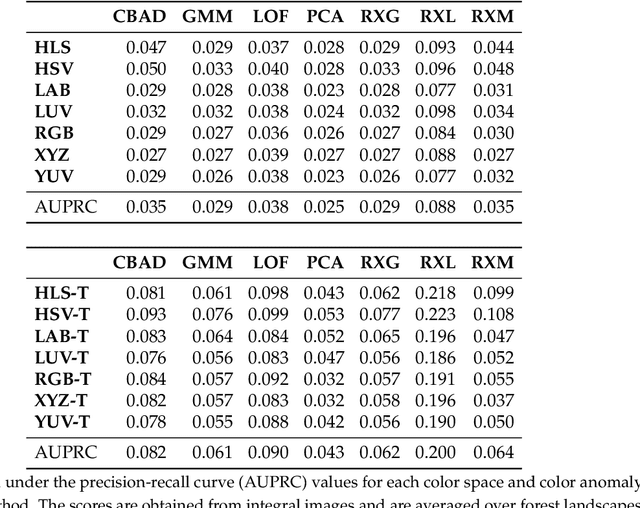
In this article, we evaluate unsupervised anomaly detection methods in multispectral images obtained with a wavelength-independent synthetic aperture sensing technique, called Airborne Optical Sectioning (AOS). With a focus on search and rescue missions that apply drones to locate missing or injured persons in dense forest and require real-time operation, we evaluate runtime vs. quality of these methods. Furthermore, we show that color anomaly detection methods that normally operate in the visual range always benefit from an additional far infrared (thermal) channel. We also show that, even without additional thermal bands, the choice of color space in the visual range already has an impact on the detection results. Color spaces like HSV and HLS have the potential to outperform the widely used RGB color space, especially when color anomaly detection is used for forest-like environments.
Predicting adverse outcomes following catheter ablation treatment for atrial fibrillation
Nov 22, 2022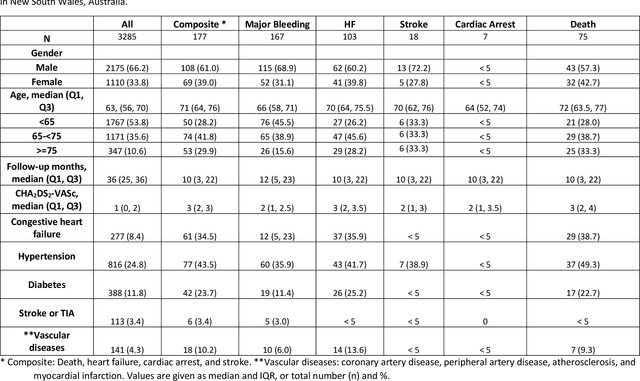
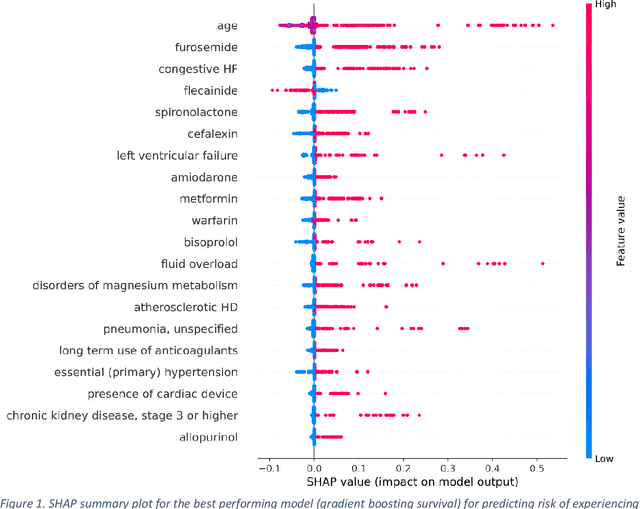
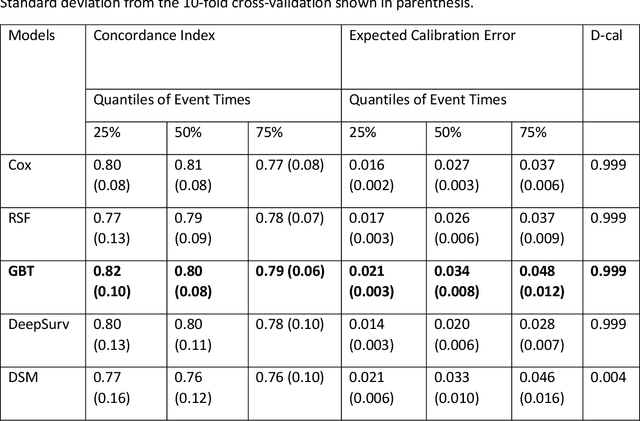
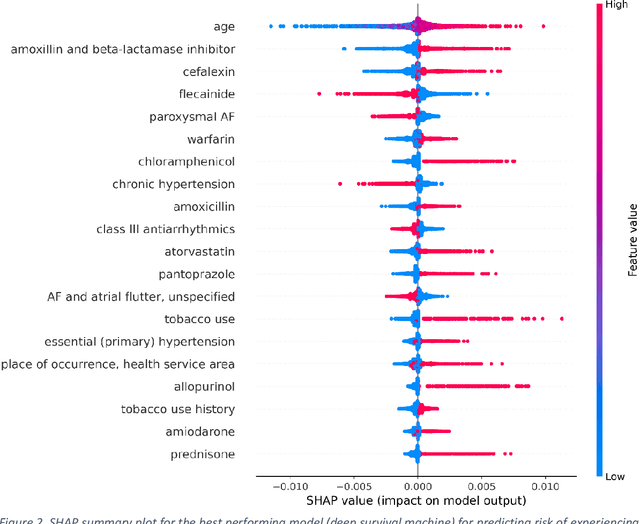
Objective: To develop prognostic survival models for predicting adverse outcomes after catheter ablation treatment for non-valvular atrial fibrillation (AF). Methods: We used a linked dataset including hospital administrative data, prescription medicine claims, emergency department presentations, and death registrations of patients in New South Wales, Australia. The cohort included patients who received catheter ablation for AF. Traditional and deep survival models were trained to predict major bleeding events and a composite of heart failure, stroke, cardiac arrest, and death. Results: Out of a total of 3285 patients in the cohort, 177 (5.3%) experienced the composite outcomeheart failure, stroke, cardiac arrest, deathand 167 (5.1%) experienced major bleeding events after catheter ablation treatment. Models predicting the composite outcome had high risk discrimination accuracy, with the best model having a concordance index > 0.79 at the evaluated time horizons. Models for predicting major bleeding events had poor risk discrimination performance, with all models having a concordance index < 0.66. The most impactful features for the models predicting higher risk were comorbidities indicative of poor health, older age, and therapies commonly used in sicker patients to treat heart failure and AF. Conclusions: Diagnosis and medication history did not contain sufficient information for precise risk prediction of experiencing major bleeding events. The models for predicting the composite outcome have the potential to enable clinicians to identify and manage high-risk patients following catheter ablation proactively. Future research is needed to validate the usefulness of these models in clinical practice.
GDPR Compliant Collection of Therapist-Patient-Dialogues
Nov 22, 2022According to the Global Burden of Disease list provided by the World Health Organization (WHO), mental disorders are among the most debilitating disorders.To improve the diagnosis and the therapy effectiveness in recent years, researchers have tried to identify individual biomarkers. Gathering neurobiological data however, is costly and time-consuming. Another potential source of information, which is already part of the clinical routine, are therapist-patient dialogues. While there are some pioneering works investigating the role of language as predictors for various therapeutic parameters, for example patient-therapist alliance, there are no large-scale studies. A major obstacle to conduct these studies is the availability of sizeable datasets, which are needed to train machine learning models. While these conversations are part of the daily routine of clinicians, gathering them is usually hindered by various ethical (purpose of data usage), legal (data privacy) and technical (data formatting) limitations. Some of these limitations are particular to the domain of therapy dialogues, like the increased difficulty in anonymisation, or the transcription of the recordings. In this paper, we elaborate on the challenges we faced in starting our collection of therapist-patient dialogues in a psychiatry clinic under the General Data Privacy Regulation of the European Union with the goal to use the data for Natural Language Processing (NLP) research. We give an overview of each step in our procedure and point out the potential pitfalls to motivate further research in this field.
AdaptDHM: Adaptive Distribution Hierarchical Model for Multi-Domain CTR Prediction
Nov 22, 2022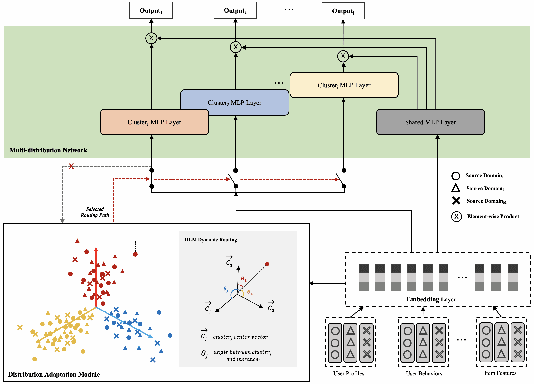
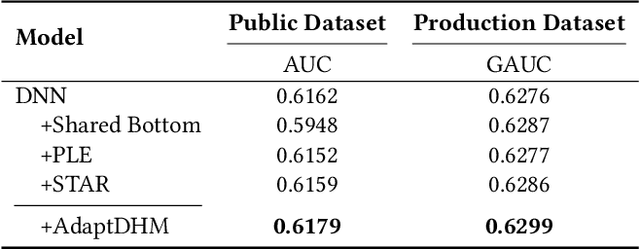
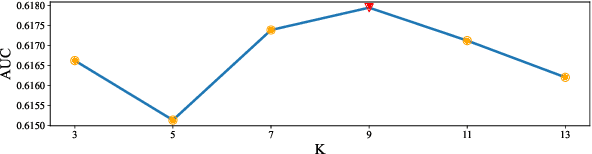
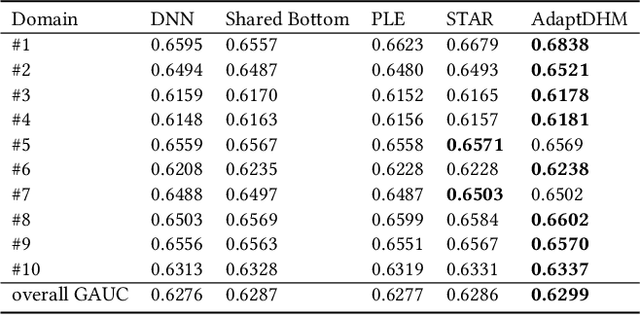
Large-scale commercial platforms usually involve numerous business domains for diverse business strategies and expect their recommendation systems to provide click-through rate (CTR) predictions for multiple domains simultaneously. Existing promising and widely-used multi-domain models discover domain relationships by explicitly constructing domain-specific networks, but the computation and memory boost significantly with the increase of domains. To reduce computational complexity, manually grouping domains with particular business strategies is common in industrial applications. However, this pre-defined data partitioning way heavily relies on prior knowledge, and it may neglect the underlying data distribution of each domain, hence limiting the model's representation capability. Regarding the above issues, we propose an elegant and flexible multi-distribution modeling paradigm, named Adaptive Distribution Hierarchical Model (AdaptDHM), which is an end-to-end optimization hierarchical structure consisting of a clustering process and classification process. Specifically, we design a distribution adaptation module with a customized dynamic routing mechanism. Instead of introducing prior knowledge for pre-defined data allocation, this routing algorithm adaptively provides a distribution coefficient for each sample to determine which cluster it belongs to. Each cluster corresponds to a particular distribution so that the model can sufficiently capture the commonalities and distinctions between these distinct clusters. Extensive experiments on both public and large-scale Alibaba industrial datasets verify the effectiveness and efficiency of AdaptDHM: Our model achieves impressive prediction accuracy and its time cost during the training stage is more than 50% less than that of other models.
Uncertainty-aware Vision-based Metric Cross-view Geolocalization
Nov 22, 2022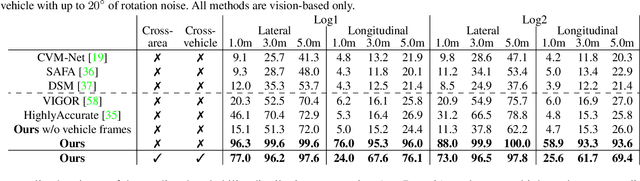
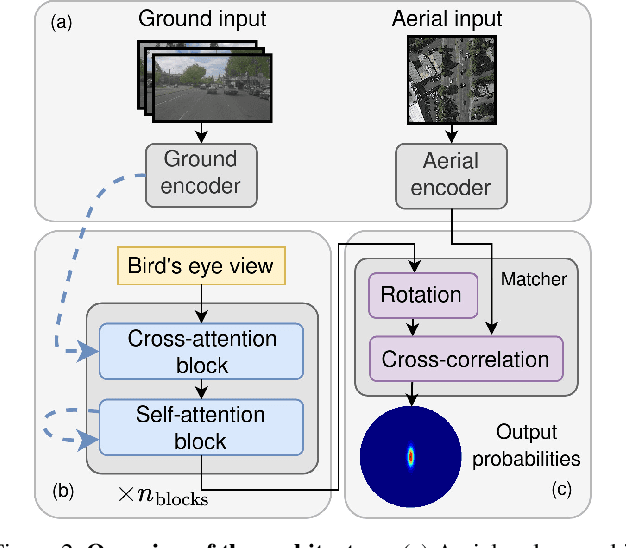
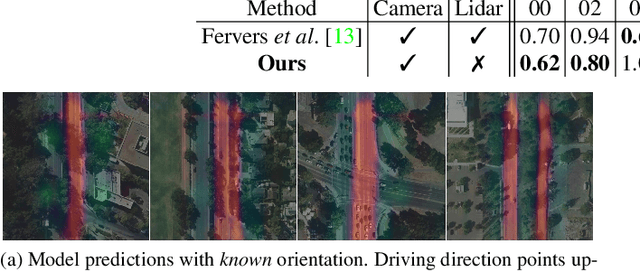
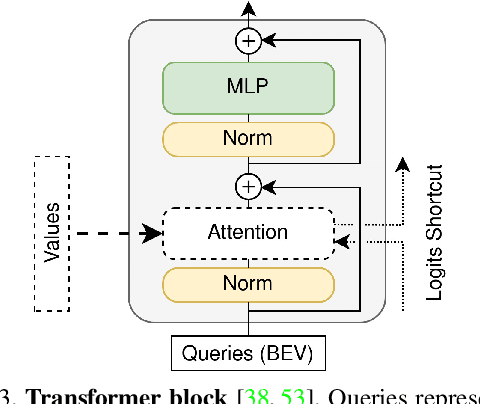
This paper proposes a novel method for vision-based metric cross-view geolocalization (CVGL) that matches the camera images captured from a ground-based vehicle with an aerial image to determine the vehicle's geo-pose. Since aerial images are globally available at low cost, they represent a potential compromise between two established paradigms of autonomous driving, i.e. using expensive high-definition prior maps or relying entirely on the sensor data captured at runtime. We present an end-to-end differentiable model that uses the ground and aerial images to predict a probability distribution over possible vehicle poses. We combine multiple vehicle datasets with aerial images from orthophoto providers on which we demonstrate the feasibility of our method. Since the ground truth poses are often inaccurate w.r.t. the aerial images, we implement a pseudo-label approach to produce more accurate ground truth poses and make them publicly available. While previous works require training data from the target region to achieve reasonable localization accuracy (i.e. same-area evaluation), our approach overcomes this limitation and outperforms previous results even in the strictly more challenging cross-area case. We improve the previous state-of-the-art by a large margin even without ground or aerial data from the test region, which highlights the model's potential for global-scale application. We further integrate the uncertainty-aware predictions in a tracking framework to determine the vehicle's trajectory over time resulting in a mean position error on KITTI-360 of 0.78m.