 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Minimum-Time Quadrotor Waypoint Flight in Cluttered Environments
Feb 08, 2022

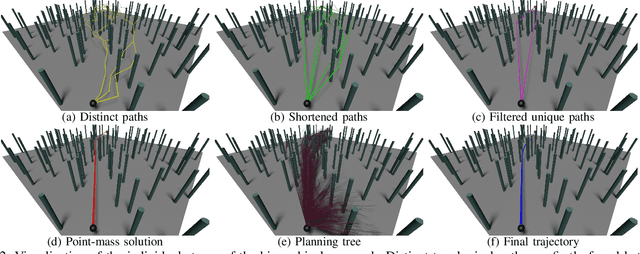
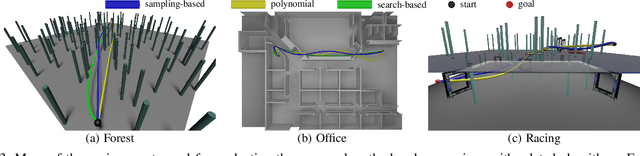

We tackle the problem of planning a minimum-time trajectory for a quadrotor over a sequence of specified waypoints in the presence of obstacles while exploiting the full quadrotor dynamics. This problem is crucial for autonomous search and rescue and drone racing scenarios but was, so far, unaddressed by the robotics community \emph{in its entirety} due to the challenges of minimizing time in the presence of the non-convex constraints posed by collision avoidance. Early works relied on simplified dynamics or polynomial trajectory representations that did not exploit the full actuator potential of a quadrotor and, thus, did not aim at minimizing time. We address this challenging problem by using a hierarchical, sampling-based method with an incrementally more complex quadrotor model. Our method first finds paths in different topologies to guide subsequent trajectory search for a kinodynamic point-mass model. Then, it uses an asymptotically-optimal, kinodynamic sampling-based method based on a full quadrotor model on top of the point-mass solution to find a feasible trajectory with a time-optimal objective. The proposed method is shown to outperform all related baselines in cluttered environments and is further validated in real-world flights at over 60km/h in one of the world's largest motion capture systems. We release the code open source.
Real-Time Packet Loss Concealment With Mixed Generative and Predictive Model
May 11, 2022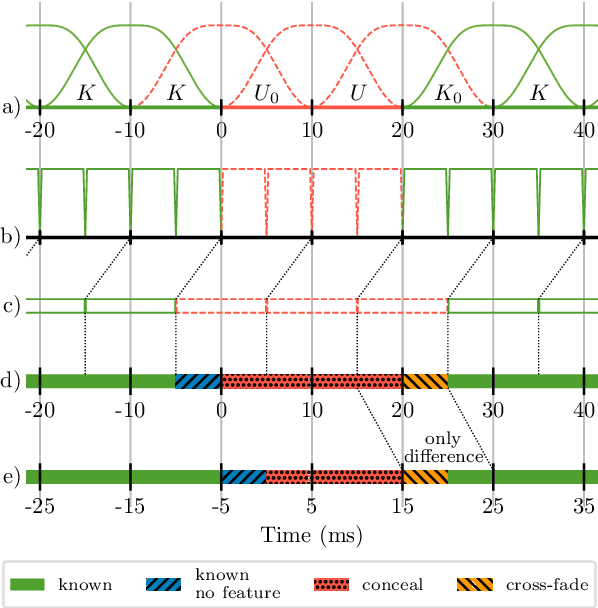

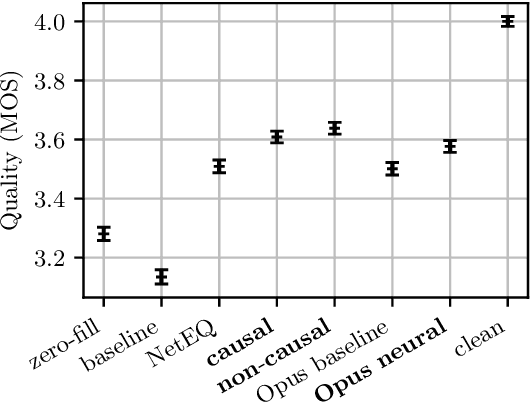
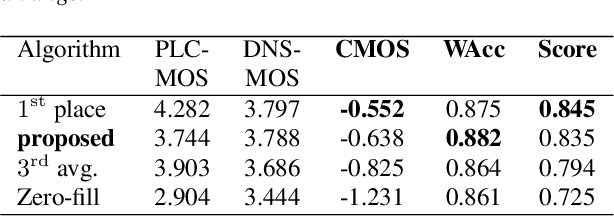
As deep speech enhancement algorithms have recently demonstrated capabilities greatly surpassing their traditional counterparts for suppressing noise, reverberation and echo, attention is turning to the problem of packet loss concealment (PLC). PLC is a challenging task because it not only involves real-time speech synthesis, but also frequent transitions between the received audio and the synthesized concealment. We propose a hybrid neural PLC architecture where the missing speech is synthesized using a generative model conditioned using a predictive model. The resulting algorithm achieves natural concealment that surpasses the quality of existing conventional PLC algorithms and ranked second in the Interspeech 2022 PLC Challenge. We show that our solution not only works for uncompressed audio, but is also applicable to a modern speech codec.
Maximum entropy optimal density control of discrete-time linear systems and Schrödinger bridges
Apr 11, 2022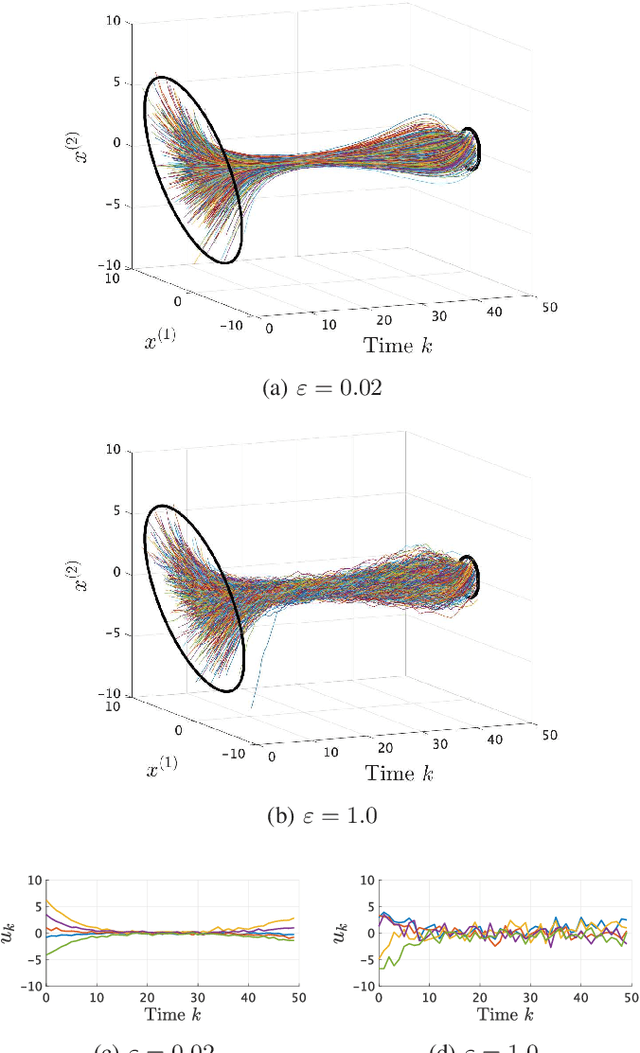
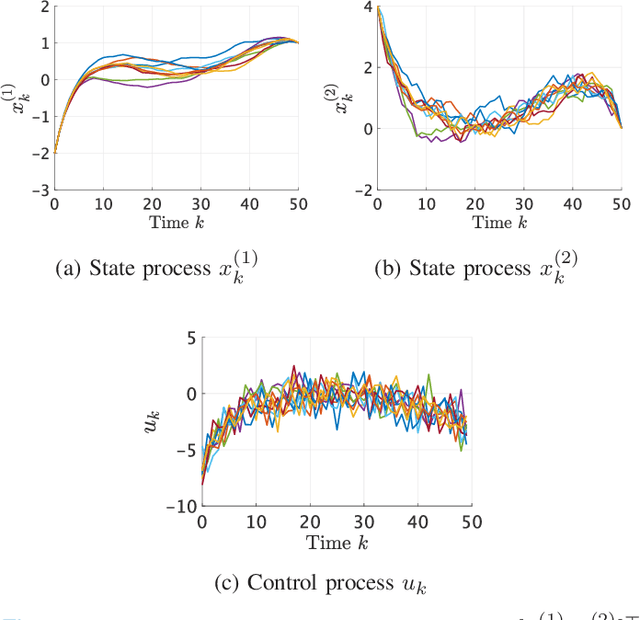
We consider an entropy-regularized version of optimal density control of deterministic discrete-time linear systems. Entropy regularization, or a maximum entropy (MaxEnt) method for optimal control has attracted much attention especially in reinforcement learning due to its many advantages such as a natural exploration strategy. Despite the merits, high-entropy control policies introduce probabilistic uncertainty into systems, which severely limits the applicability of MaxEnt optimal control to safety-critical systems. To remedy this situation, we impose a Gaussian density constraint at a specified time on the MaxEnt optimal control to directly control state uncertainty. Specifically, we derive the explicit form of the MaxEnt optimal density control. In addition, we also consider the case where a density constraint is replaced by a fixed point constraint. Then, we characterize the associated state process as a pinned process, which is a generalization of the Brownian bridge to linear systems. Finally, we reveal that the MaxEnt optimal density control induces the so-called Schr\"odinger bridge associated to a discrete-time linear system.
Learning Motion-Robust Remote Photoplethysmography through Arbitrary Resolution Videos
Dec 01, 2022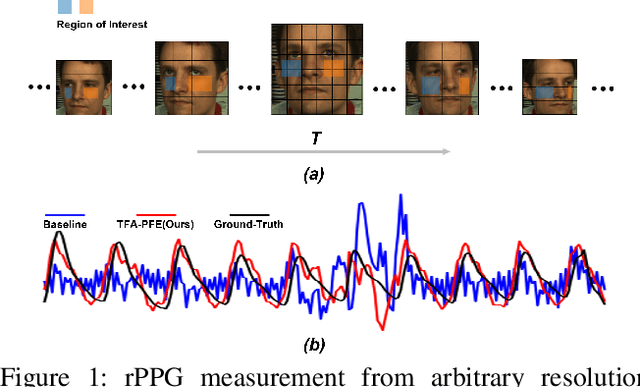
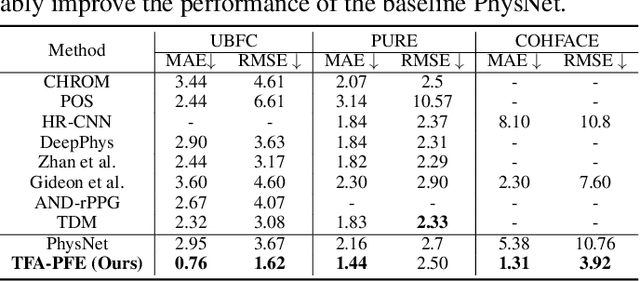
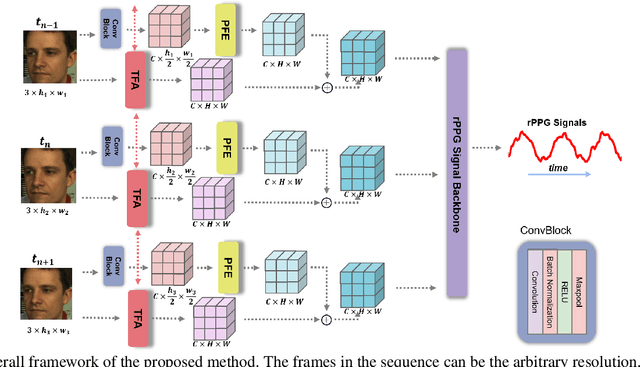
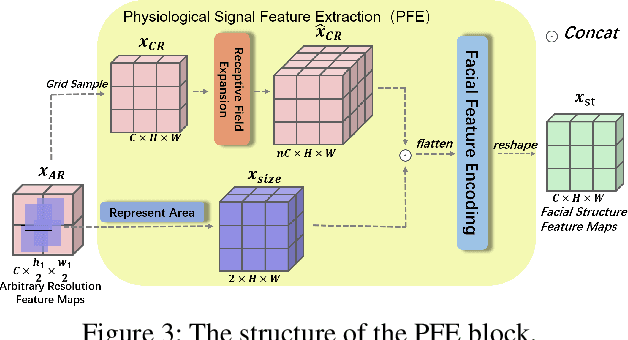
Remote photoplethysmography (rPPG) enables non-contact heart rate (HR) estimation from facial videos which gives significant convenience compared with traditional contact-based measurements. In the real-world long-term health monitoring scenario, the distance of the participants and their head movements usually vary by time, resulting in the inaccurate rPPG measurement due to the varying face resolution and complex motion artifacts. Different from the previous rPPG models designed for a constant distance between camera and participants, in this paper, we propose two plug-and-play blocks (i.e., physiological signal feature extraction block (PFE) and temporal face alignment block (TFA)) to alleviate the degradation of changing distance and head motion. On one side, guided with representative-area information, PFE adaptively encodes the arbitrary resolution facial frames to the fixed-resolution facial structure features. On the other side, leveraging the estimated optical flow, TFA is able to counteract the rPPG signal confusion caused by the head movement thus benefit the motion-robust rPPG signal recovery. Besides, we also train the model with a cross-resolution constraint using a two-stream dual-resolution framework, which further helps PFE learn resolution-robust facial rPPG features. Extensive experiments on three benchmark datasets (UBFC-rPPG, COHFACE and PURE) demonstrate the superior performance of the proposed method. One highlight is that with PFE and TFA, the off-the-shelf spatio-temporal rPPG models can predict more robust rPPG signals under both varying face resolution and severe head movement scenarios. The codes are available at https://github.com/LJW-GIT/Arbitrary_Resolution_rPPG.
Learning to Select from Multiple Options
Dec 01, 2022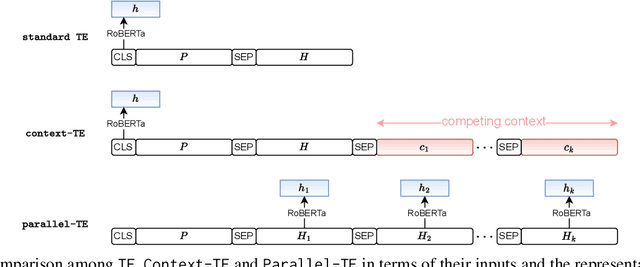
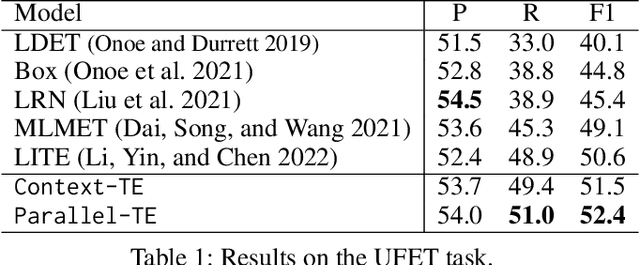
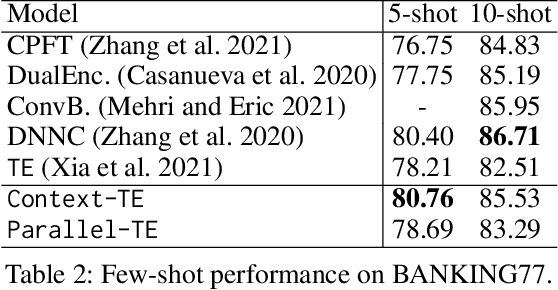
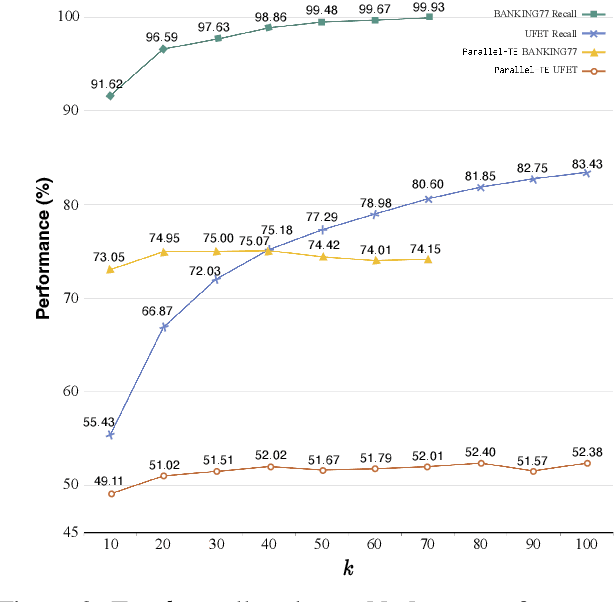
Many NLP tasks can be regarded as a selection problem from a set of options, such as classification tasks, multi-choice question answering, etc. Textual entailment (TE) has been shown as the state-of-the-art (SOTA) approach to dealing with those selection problems. TE treats input texts as premises (P), options as hypotheses (H), then handles the selection problem by modeling (P, H) pairwise. Two limitations: first, the pairwise modeling is unaware of other options, which is less intuitive since humans often determine the best options by comparing competing candidates; second, the inference process of pairwise TE is time-consuming, especially when the option space is large. To deal with the two issues, this work first proposes a contextualized TE model (Context-TE) by appending other k options as the context of the current (P, H) modeling. Context-TE is able to learn more reliable decision for the H since it considers various context. Second, we speed up Context-TE by coming up with Parallel-TE, which learns the decisions of multiple options simultaneously. Parallel-TE significantly improves the inference speed while keeping comparable performance with Context-TE. Our methods are evaluated on three tasks (ultra-fine entity typing, intent detection and multi-choice QA) that are typical selection problems with different sizes of options. Experiments show our models set new SOTA performance; particularly, Parallel-TE is faster than the pairwise TE by k times in inference. Our code is publicly available at https://github.com/jiangshdd/LearningToSelect.
Towards Energy-Efficient, Low-Latency and Accurate Spiking LSTMs
Oct 23, 2022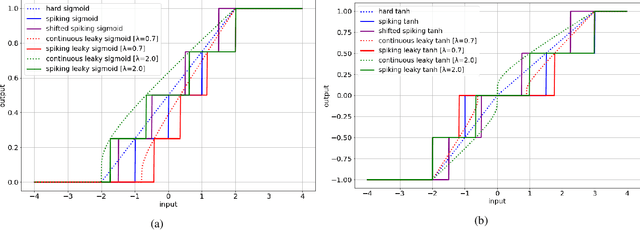
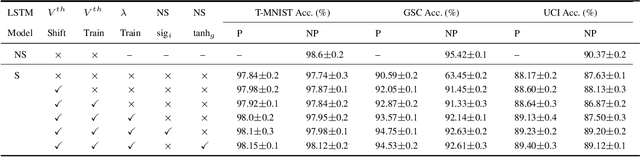

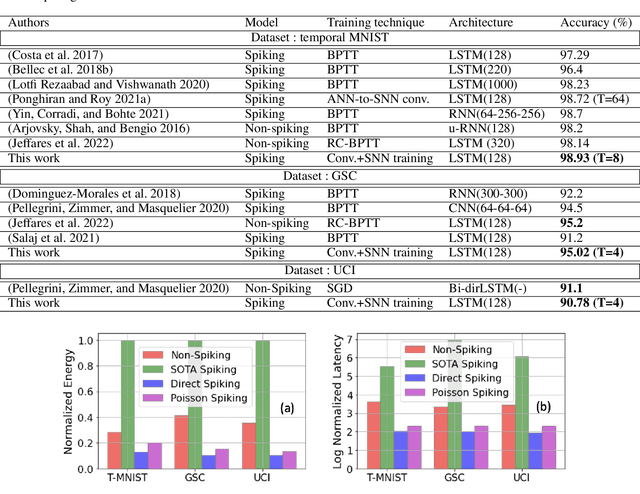
Spiking Neural Networks (SNNs) have emerged as an attractive spatio-temporal computing paradigm for complex vision tasks. However, most existing works yield models that require many time steps and do not leverage the inherent temporal dynamics of spiking neural networks, even for sequential tasks. Motivated by this observation, we propose an \rev{optimized spiking long short-term memory networks (LSTM) training framework that involves a novel ANN-to-SNN conversion framework, followed by SNN training}. In particular, we propose novel activation functions in the source LSTM architecture and judiciously select a subset of them for conversion to integrate-and-fire (IF) activations with optimal bias shifts. Additionally, we derive the leaky-integrate-and-fire (LIF) activation functions converted from their non-spiking LSTM counterparts which justifies the need to jointly optimize the weights, threshold, and leak parameter. We also propose a pipelined parallel processing scheme which hides the SNN time steps, significantly improving system latency, especially for long sequences. The resulting SNNs have high activation sparsity and require only accumulate operations (AC), in contrast to expensive multiply-and-accumulates (MAC) needed for ANNs, except for the input layer when using direct encoding, yielding significant improvements in energy efficiency. We evaluate our framework on sequential learning tasks including temporal MNIST, Google Speech Commands (GSC), and UCI Smartphone datasets on different LSTM architectures. We obtain test accuracy of 94.75% with only 2 time steps with direct encoding on the GSC dataset with 4.1x lower energy than an iso-architecture standard LSTM.
Differentiable Uncalibrated Imaging
Nov 18, 2022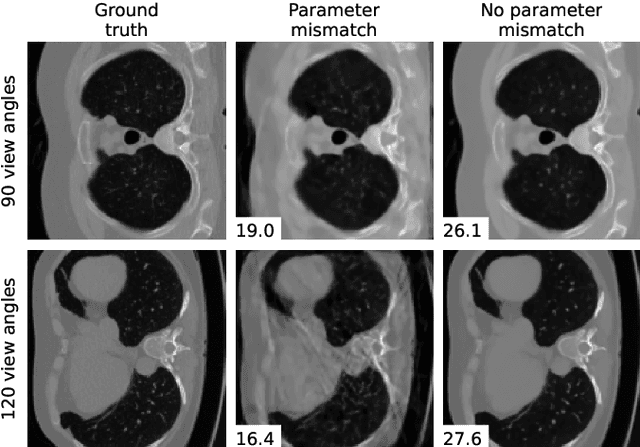
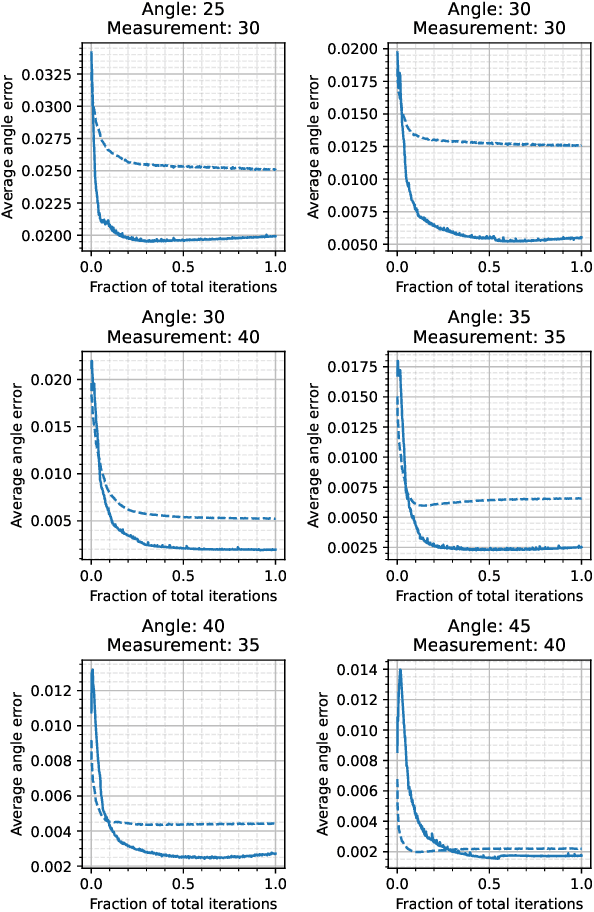
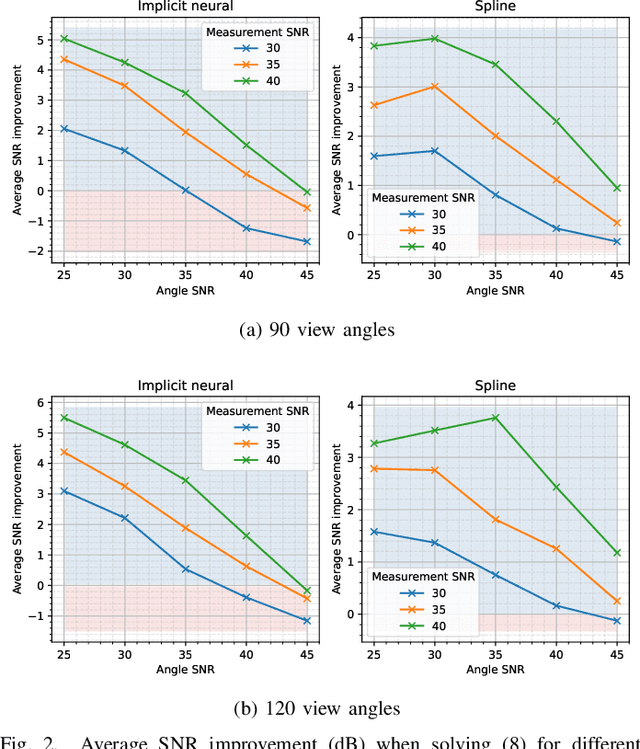
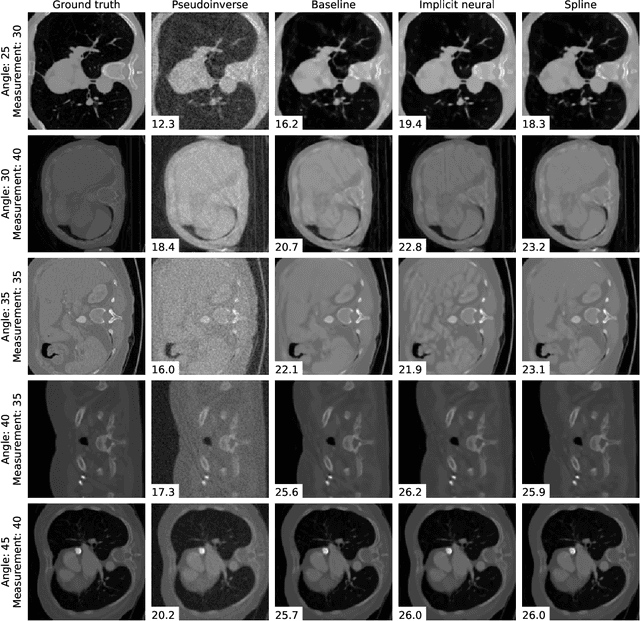
We propose a differentiable imaging framework to address uncertainty in measurement coordinates such as sensor locations and projection angles. We formulate the problem as measurement interpolation at unknown nodes supervised through the forward operator. To solve it we apply implicit neural networks, also known as neural fields, which are naturally differentiable with respect to the input coordinates. We also develop differentiable spline interpolators which perform as well as neural networks, require less time to optimize and have well-understood properties. Differentiability is key as it allows us to jointly fit a measurement representation, optimize over the uncertain measurement coordinates, and perform image reconstruction which in turn ensures consistent calibration. We apply our approach to 2D and 3D computed tomography and show that it produces improved reconstructions compared to baselines that do not account for the lack of calibration. The flexibility of the proposed framework makes it easy to apply to almost arbitrary imaging problems.
Impact of visual assistance for automated audio captioning
Nov 18, 2022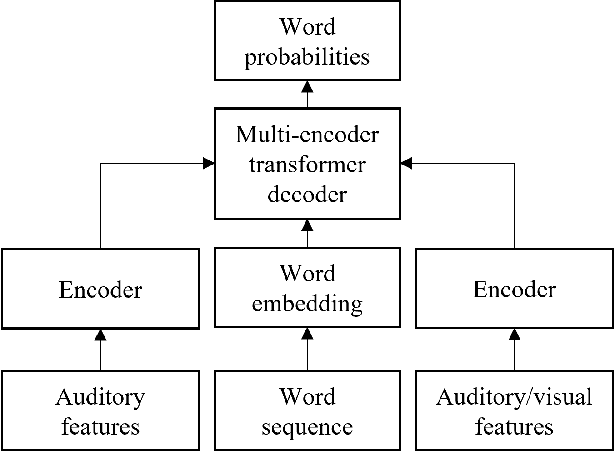
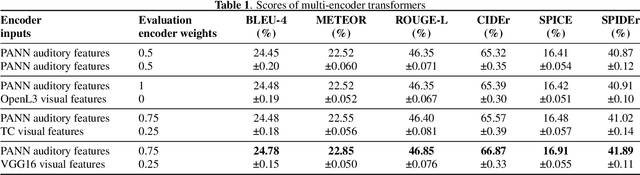
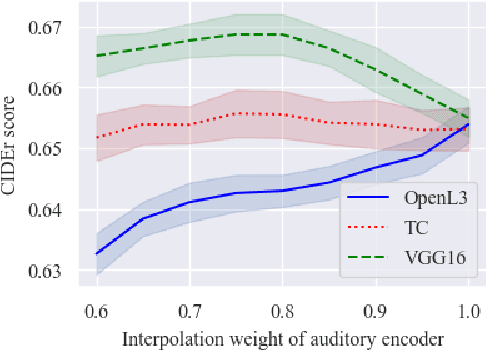
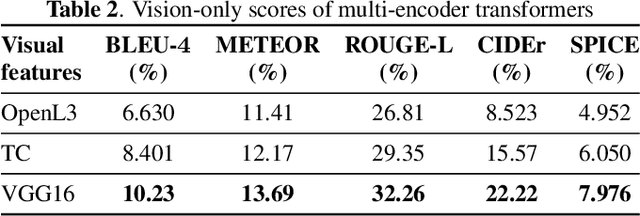
We study the impact of visual assistance for automated audio captioning. Utilizing multi-encoder transformer architectures, which have previously been employed to introduce vision-related information in the context of sound event detection, we analyze the usefulness of incorporating a variety of pretrained features. We perform experiments on a YouTube-based audiovisual data set and investigate the effect of applying the considered transfer learning technique in terms of a variety of captioning metrics. We find that only one of the considered kinds of pretrained features provides consistent improvements, while the others do not provide any noteworthy gains at all. Interestingly, the outcomes of prior research efforts indicate that the exact opposite is true in the case of sound event detection, leading us to conclude that the optimal choice of visual embeddings is strongly dependent on the task at hand. More specifically, visual features focusing on semantics appear appropriate in the context of automated audio captioning, while for sound event detection, time information seems to be more important.
IEEE Big Data Cup 2022: Privacy Preserving Matching of Encrypted Images with Deep Learning
Nov 18, 2022
Smart sensors, devices and systems deployed in smart cities have brought improved physical protections to their citizens. Enhanced crime prevention, and fire and life safety protection are achieved through these technologies that perform motion detection, threat and actors profiling, and real-time alerts. However, an important requirement in these increasingly prevalent deployments is the preservation of privacy and enforcement of protection of personal identifiable information. Thus, strong encryption and anonymization techniques should be applied to the collected data. In this IEEE Big Data Cup 2022 challenge, different masking, encoding and homomorphic encryption techniques were applied to the images to protect the privacy of their contents. Participants are required to develop detection solutions to perform privacy preserving matching of these images. In this paper, we describe our solution which is based on state-of-the-art deep convolutional neural networks and various data augmentation techniques. Our solution achieved 1st place at the IEEE Big Data Cup 2022: Privacy Preserving Matching of Encrypted Images Challenge.
* Keywords: privacy preservation, privacy enhancing, masking, encoding, homomorphic encryption, deep learning, convolutional neural networks
Data-Folding and Hyperspace Coding for Multi-Dimensonal Time-Series Data Imaging
Mar 10, 2022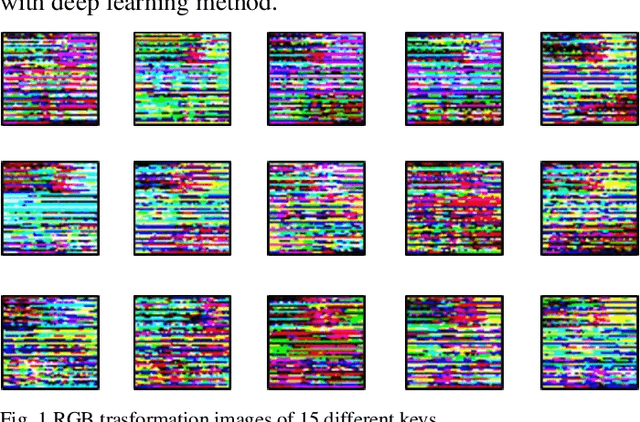
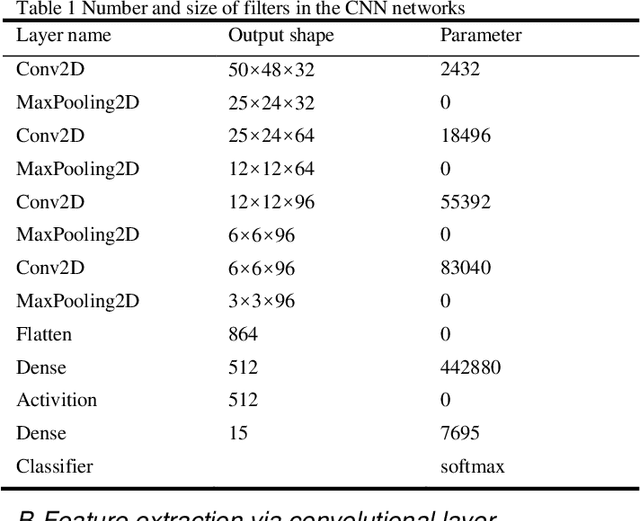
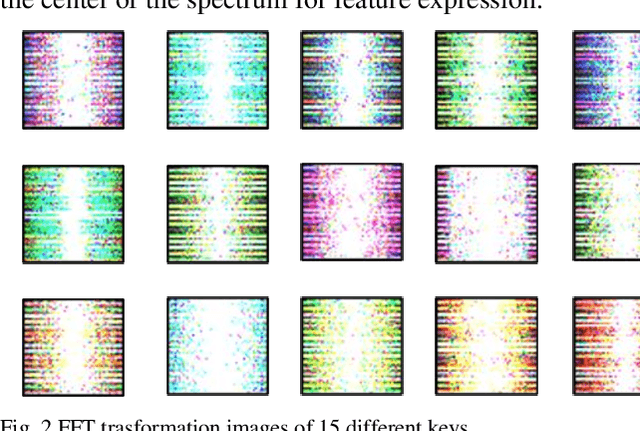
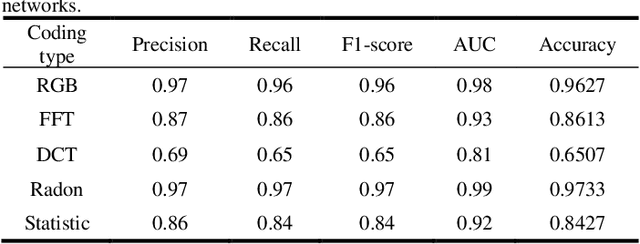
Time-series classification and prediction are widely used in many applications. However, traditional machine learning algorithms, due to their limitations, have difficulty improving the performance of time-series classification and prediction. Inspired by the recent successes of the deep learning technology in computer vision, we develop a new time-series image encoding method for data reconstruction. Featuring data-folding and hyperspace coding this method breaks the barriers between time-series signals and images and establishes a close relationship between them, allowing effective application of the deep learning technology for time-series data. Besides a raw data coding method, we also present other four extended coding methods for other potential applications. For comparison purposes, we present the results of the five different types of image coding methods with our previous keystroke recognition datasets. The results show that our method can achieve an impressive accuracy of 96.27% when RGB coding images are used, and an accuracy of up to 97.33% when using radon coding way. We can expect that this method can also be used and perform well in other classification and prediction applications.