 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
AlphaSnake: Policy Iteration on a Nondeterministic NP-hard Markov Decision Process
Nov 17, 2022
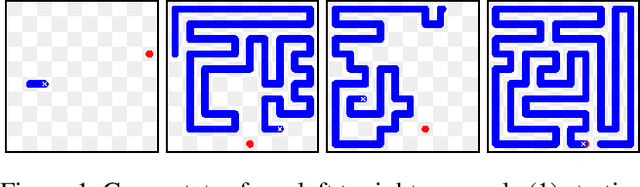
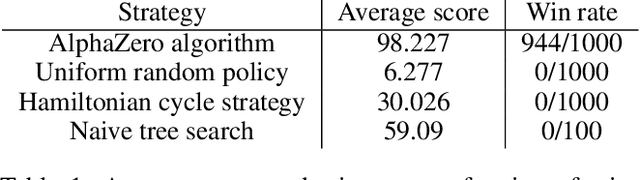
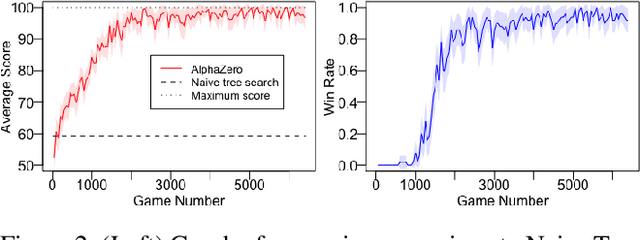
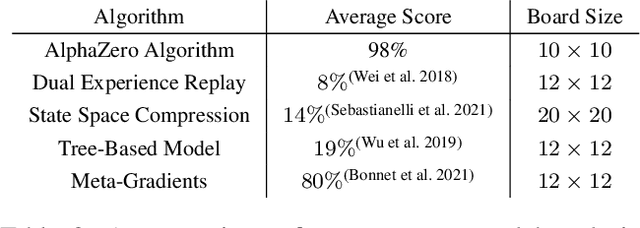
Reinforcement learning has recently been used to approach well-known NP-hard combinatorial problems in graph theory. Among these problems, Hamiltonian cycle problems are exceptionally difficult to analyze, even when restricted to individual instances of structurally complex graphs. In this paper, we use Monte Carlo Tree Search (MCTS), the search algorithm behind many state-of-the-art reinforcement learning algorithms such as AlphaZero, to create autonomous agents that learn to play the game of Snake, a game centered on properties of Hamiltonian cycles on grid graphs. The game of Snake can be formulated as a single-player discounted Markov Decision Process (MDP) where the agent must behave optimally in a stochastic environment. Determining the optimal policy for Snake, defined as the policy that maximizes the probability of winning - or win rate - with higher priority and minimizes the expected number of time steps to win with lower priority, is conjectured to be NP-hard. Performance-wise, compared to prior work in the Snake game, our algorithm is the first to achieve a win rate over $0.5$ (a uniform random policy achieves a win rate $< 2.57 \times 10^{-15}$), demonstrating the versatility of AlphaZero in approaching NP-hard environments.
SpikiLi: A Spiking Simulation of LiDAR based Real-time Object Detection for Autonomous Driving
Jun 06, 2022
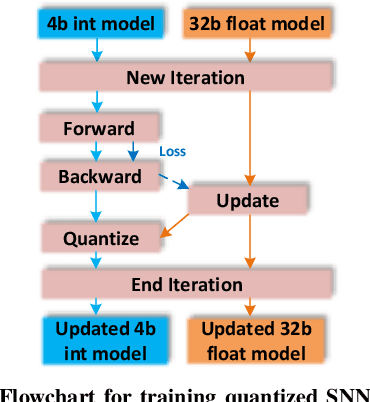
Spiking Neural Networks are a recent and new neural network design approach that promises tremendous improvements in power efficiency, computation efficiency, and processing latency. They do so by using asynchronous spike-based data flow, event-based signal generation, processing, and modifying the neuron model to resemble biological neurons closely. While some initial works have shown significant initial evidence of applicability to common deep learning tasks, their applications in complex real-world tasks has been relatively low. In this work, we first illustrate the applicability of spiking neural networks to a complex deep learning task namely Lidar based 3D object detection for automated driving. Secondly, we make a step-by-step demonstration of simulating spiking behavior using a pre-trained convolutional neural network. We closely model essential aspects of spiking neural networks in simulation and achieve equivalent run-time and accuracy on a GPU. When the model is realized on a neuromorphic hardware, we expect to have significantly improved power efficiency.
A Sequence Agnostic Multimodal Preprocessing for Clogged Blood Vessel Detection in Alzheimer's Diagnosis
Nov 06, 2022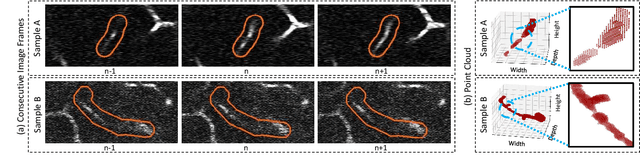
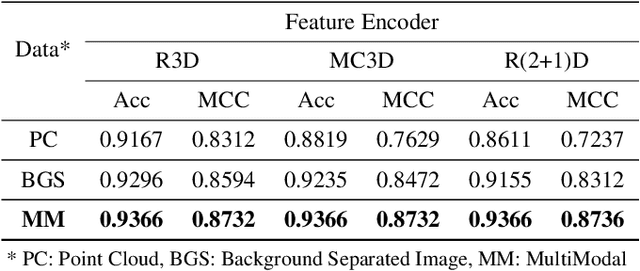

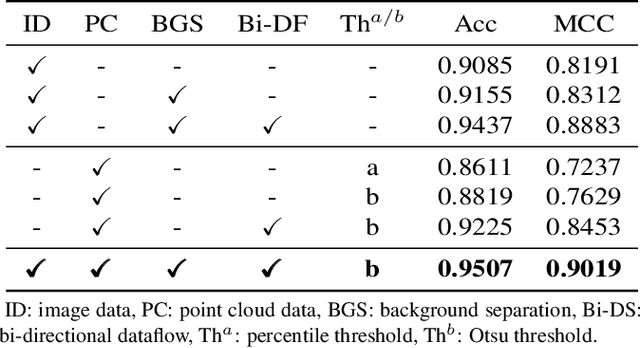
Successful identification of blood vessel blockage is a crucial step for Alzheimer's disease diagnosis. These blocks can be identified from the spatial and time-depth variable Two-Photon Excitation Microscopy (TPEF) images of the brain blood vessels using machine learning methods. In this study, we propose several preprocessing schemes to improve the performance of these methods. Our method includes 3D-point cloud data extraction from image modality and their feature-space fusion to leverage complementary information inherent in different modalities. We also enforce the learned representation to be sequence-order invariant by utilizing bi-direction dataflow. Experimental results on The Clog Loss dataset show that our proposed method consistently outperforms the state-of-the-art preprocessing methods in stalled and non-stalled vessel classification.
Design and Implementation of a Fuzzy Adaptive Controller for Time-Varying Formation Leader-Follower Configuration of Nonholonomic Mobile Robots
May 23, 2022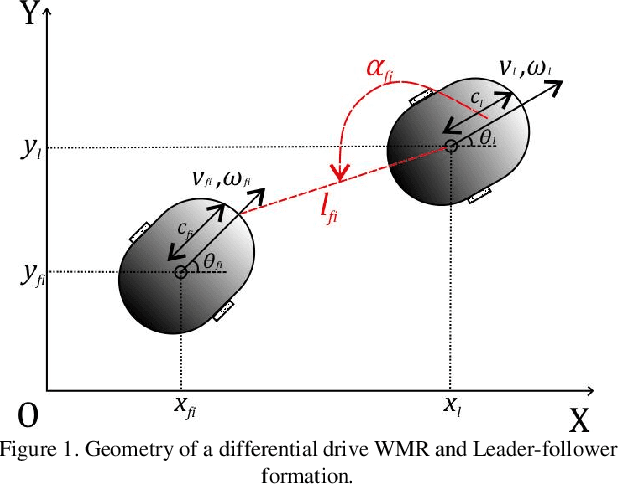


In this paper, a time-varying leader-follower formation control of nonholonomic mobile robots based on a trajectory tracking control strategy is considered. In the time-varying formation, the relative bearing and distance of each follower are variable parameters, and therefore, the followers can carry out various and complex behaviour even without changing the linear and angular velocities of the leader robot. After proposing the kinematic model of the time-varying leader-follower formation, the backstepping control method is exploited to keep the structure of the defined formation. The global stability of the formation is investigated using the Lyapunov theorem. Moreover, the designed nonlinear controller suffers from the ineffectual large input commands at the beginning of the formation. To rectify this problem, a fuzzy adaptive algorithm is proposed to improve the backstepping controller and the global stability of the resulting fuzzy adaptive backstepping controller is guaranteed. Considering the rate change of relative distance and bearing in the kinematic model of the leader-follower formation and controller design procedure, makes the formation more practical in dynamic and clutter environments, as well as capable of defining complicated behaviour for followers, and provides crash and obstacle avoidance without switching between different control strategies. Finally, the performance of the proposed kinematics model and designed controllers are investigated through simulations and experimental studies.
Efficient Neural Mapping for Localisation of Unmanned Ground Vehicles
Nov 09, 2022



Global localisation from visual data is a challenging problem applicable to many robotics domains. Prior works have shown that neural networks can be trained to map images of an environment to absolute camera pose within that environment, learning an implicit neural mapping in the process. In this work we evaluate the applicability of such an approach to real-world robotics scenarios, demonstrating that by constraining the problem to 2-dimensions and significantly increasing the quantity of training data, a compact model capable of real-time inference on embedded platforms can be used to achieve localisation accuracy of several centimetres. We deploy our trained model onboard a UGV platform, demonstrating its effectiveness in a waypoint navigation task. Along with this work we will release a novel localisation dataset comprising simulated and real environments, each with training samples numbering in the tens of thousands.
Monte Carlo Tree Search Algorithms for Risk-Aware and Multi-Objective Reinforcement Learning
Nov 23, 2022
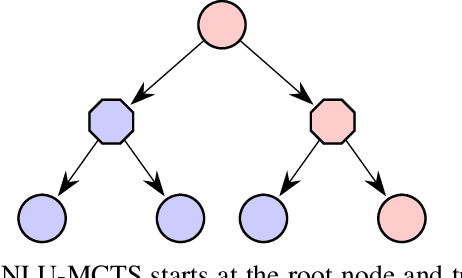
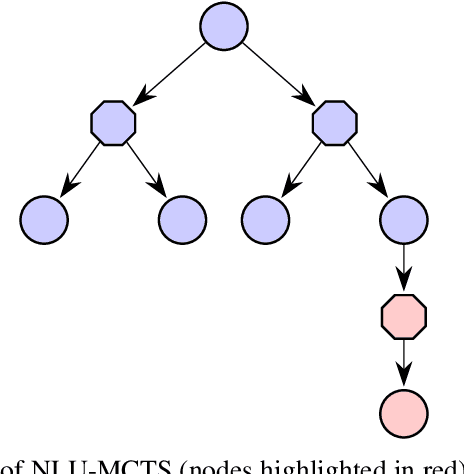
In many risk-aware and multi-objective reinforcement learning settings, the utility of the user is derived from a single execution of a policy. In these settings, making decisions based on the average future returns is not suitable. For example, in a medical setting a patient may only have one opportunity to treat their illness. Making decisions using just the expected future returns -- known in reinforcement learning as the value -- cannot account for the potential range of adverse or positive outcomes a decision may have. Therefore, we should use the distribution over expected future returns differently to represent the critical information that the agent requires at decision time by taking both the future and accrued returns into consideration. In this paper, we propose two novel Monte Carlo tree search algorithms. Firstly, we present a Monte Carlo tree search algorithm that can compute policies for nonlinear utility functions (NLU-MCTS) by optimising the utility of the different possible returns attainable from individual policy executions, resulting in good policies for both risk-aware and multi-objective settings. Secondly, we propose a distributional Monte Carlo tree search algorithm (DMCTS) which extends NLU-MCTS. DMCTS computes an approximate posterior distribution over the utility of the returns, and utilises Thompson sampling during planning to compute policies in risk-aware and multi-objective settings. Both algorithms outperform the state-of-the-art in multi-objective reinforcement learning for the expected utility of the returns.
Are Concept Drift Detectors Reliable Alarming Systems? -- A Comparative Study
Nov 23, 2022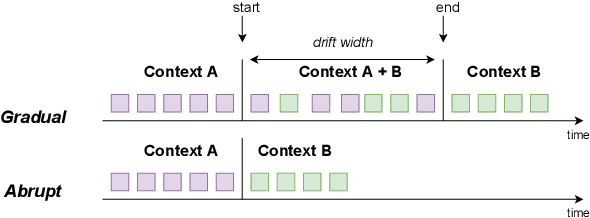
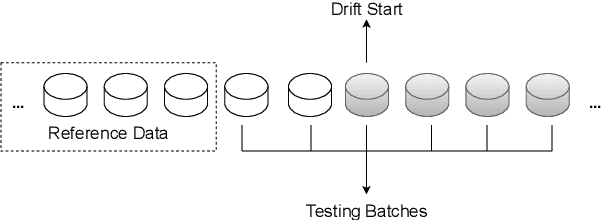
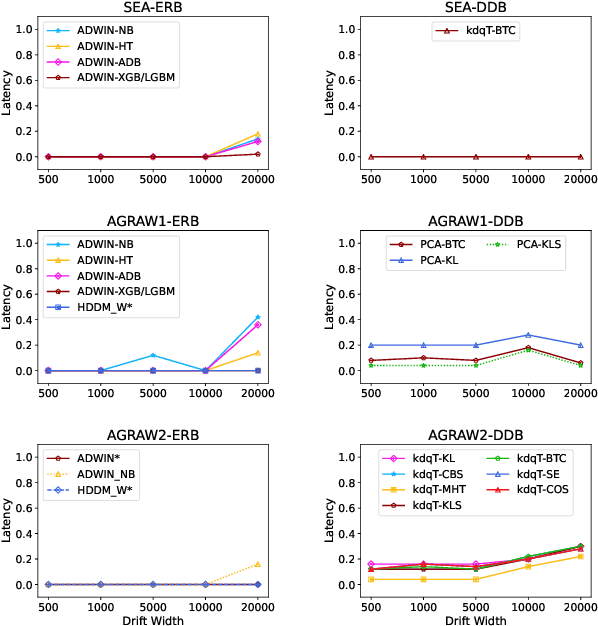
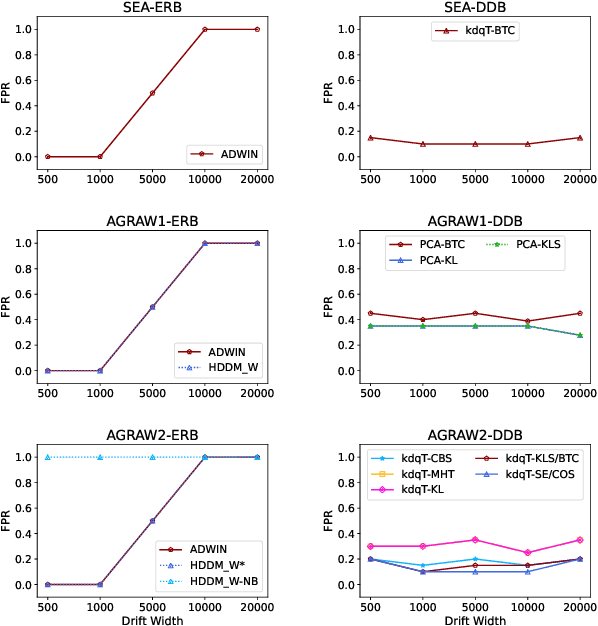
As machine learning models increasingly replace traditional business logic in the production system, their lifecycle management is becoming a significant concern. Once deployed into production, the machine learning models are constantly evaluated on new streaming data. Given the continuous data flow, shifting data, also known as concept drift, is ubiquitous in such settings. Concept drift usually impacts the performance of machine learning models, thus, identifying the moment when concept drift occurs is required. Concept drift is identified through concept drift detectors. In this work, we assess the reliability of concept drift detectors to identify drift in time by exploring how late are they reporting drifts and how many false alarms are they signaling. We compare the performance of the most popular drift detectors belonging to two different concept drift detector groups, error rate-based detectors and data distribution-based detectors. We assess their performance on both synthetic and real-world data. In the case of synthetic data, we investigate the performance of detectors to identify two types of concept drift, abrupt and gradual. Our findings aim to help practitioners understand which drift detector should be employed in different situations and, to achieve this, we share a list of the most important observations made throughout this study, which can serve as guidelines for practical usage. Furthermore, based on our empirical results, we analyze the suitability of each concept drift detection group to be used as alarming system.
Self-Supervised Learning based on Heat Equation
Nov 23, 2022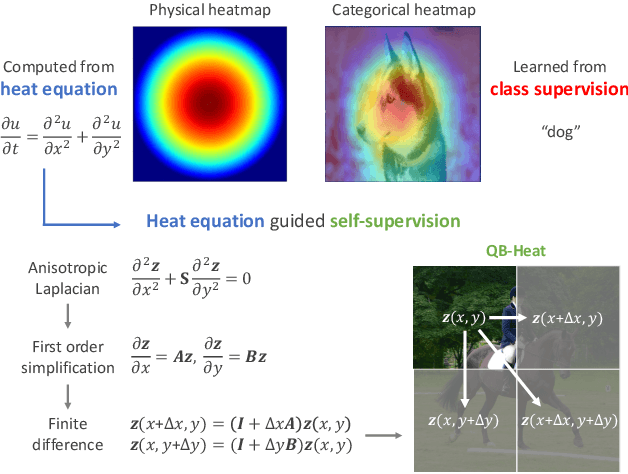

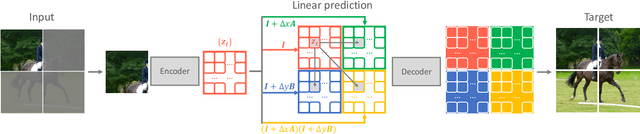
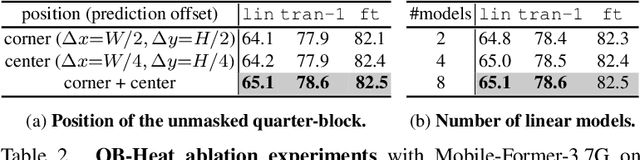
This paper presents a new perspective of self-supervised learning based on extending heat equation into high dimensional feature space. In particular, we remove time dependence by steady-state condition, and extend the remaining 2D Laplacian from x--y isotropic to linear correlated. Furthermore, we simplify it by splitting x and y axes as two first-order linear differential equations. Such simplification explicitly models the spatial invariance along horizontal and vertical directions separately, supporting prediction across image blocks. This introduces a very simple masked image modeling (MIM) method, named QB-Heat. QB-Heat leaves a single block with size of quarter image unmasked and extrapolates other three masked quarters linearly. It brings MIM to CNNs without bells and whistles, and even works well for pre-training light-weight networks that are suitable for both image classification and object detection without fine-tuning. Compared with MoCo-v2 on pre-training a Mobile-Former with 5.8M parameters and 285M FLOPs, QB-Heat is on par in linear probing on ImageNet, but clearly outperforms in non-linear probing that adds a transformer block before linear classifier (65.6% vs. 52.9%). When transferring to object detection with frozen backbone, QB-Heat outperforms MoCo-v2 and supervised pre-training on ImageNet by 7.9 and 4.5 AP respectively. This work provides an insightful hypothesis on the invariance within visual representation over different shapes and textures: the linear relationship between horizontal and vertical derivatives. The code will be publicly released.
SS-CXR: Multitask Representation Learning using Self Supervised Pre-training from Chest X-Rays
Nov 23, 2022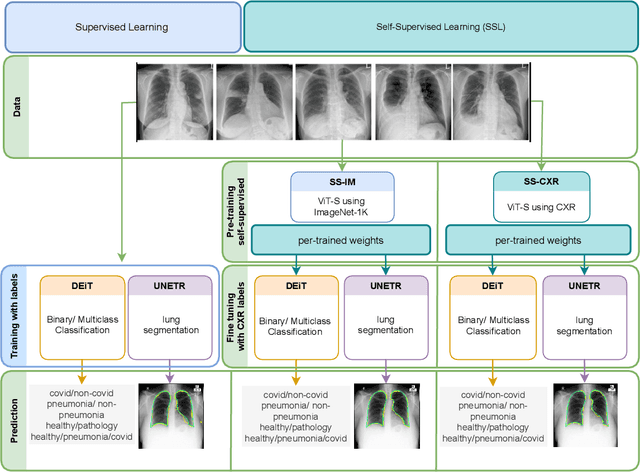

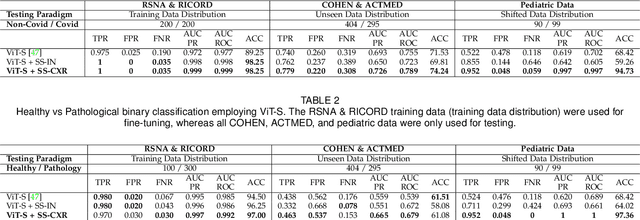

Chest X-rays (CXRs) are a widely used imaging modality for the diagnosis and prognosis of lung disease. The image analysis tasks vary. Examples include pathology detection and lung segmentation. There is a large body of work where machine learning algorithms are developed for specific tasks. A significant recent example is Coronavirus disease (covid-19) detection using CXR data. However, the traditional diagnostic tool design methods based on supervised learning are burdened by the need to provide training data annotation, which should be of good quality for better clinical outcomes. Here, we propose an alternative solution, a new self-supervised paradigm, where a general representation from CXRs is learned using a group-masked self-supervised framework. The pre-trained model is then fine-tuned for domain-specific tasks such as covid-19, pneumonia detection, and general health screening. We show that the same pre-training can be used for the lung segmentation task. Our proposed paradigm shows robust performance in multiple downstream tasks which demonstrates the success of the pre-training. Moreover, the performance of the pre-trained models on data with significant drift during test time proves the learning of a better generic representation. The methods are further validated by covid-19 detection in a unique small-scale pediatric data set. The performance gain in accuracy (~25\%) is significant when compared to a supervised transformer-based method. This adds credence to the strength and reliability of our proposed framework and pre-training strategy.
Comparison of Motion Encoding Frameworks on Human Manipulation Actions
Nov 23, 2022
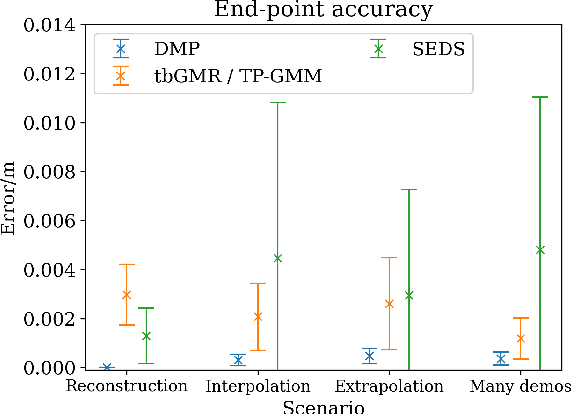
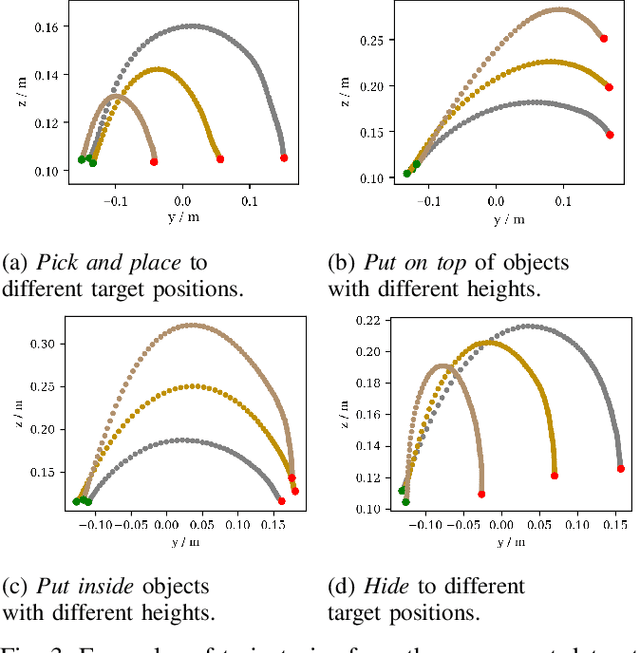
Movement generation, and especially generalisation to unseen situations, plays an important role in robotics. Different types of movement generation methods exist such as spline based methods, dynamical system based methods, and methods based on Gaussian mixture models (GMMs). Using a large, new dataset on human manipulations, in this paper we provide a highly detailed comparison of three most widely used movement encoding and generation frameworks: dynamic movement primitives (DMPs), time based Gaussian mixture regression (tbGMR) and stable estimator of dynamical systems (SEDS). We compare these frameworks with respect to their movement encoding efficiency, reconstruction accuracy, and movement generalisation capabilities. The new dataset consists of nine object manipulation actions performed by 12 humans: pick and place, put on top/take down, put inside/take out, hide/uncover, and push/pull with a total of 7,652 movement examples. Our analysis shows that for movement encoding and reconstruction DMPs are the most efficient framework with respect to the number of parameters and reconstruction accuracy if a sufficient number of kernels is used. In case of movement generalisation to new start- and end-point situations, DMPs and task parameterized GMM (TP-GMM, movement generalisation framework based on tbGMR) lead to similar performance and outperform SEDS. Furthermore we observe that TP-GMM and SEDS suffer from inaccurate convergence to the end-point as compared to DMPs. These different quantitative results will help designing trajectory representations in an improved task-dependent way in future robotic applications.