 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Motif-aware temporal GCN for fraud detection in signed cryptocurrency trust networks
Nov 22, 2022
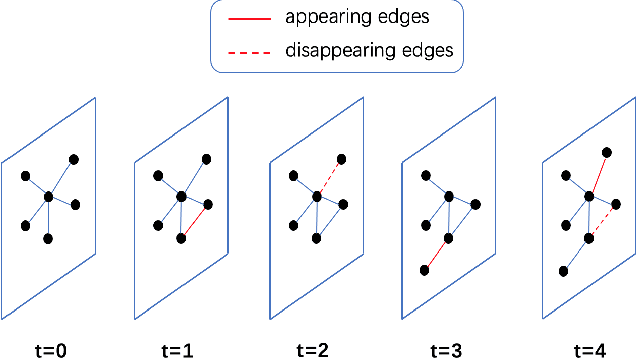

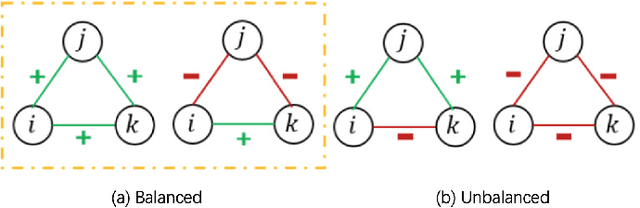
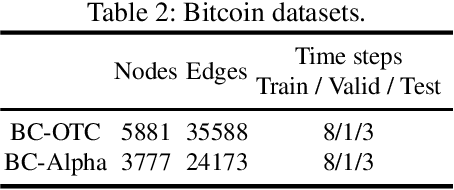
Graph convolutional networks (GCNs) is a class of artificial neural networks for processing data that can be represented as graphs. Since financial transactions can naturally be constructed as graphs, GCNs are widely applied in the financial industry, especially for financial fraud detection. In this paper, we focus on fraud detection on cryptocurrency truct networks. In the literature, most works focus on static networks. Whereas in this study, we consider the evolving nature of cryptocurrency networks, and use local structural as well as the balance theory to guide the training process. More specifically, we compute motif matrices to capture the local topological information, then use them in the GCN aggregation process. The generated embedding at each snapshot is a weighted average of embeddings within a time window, where the weights are learnable parameters. Since the trust networks is signed on each edge, balance theory is used to guide the training process. Experimental results on bitcoin-alpha and bitcoin-otc datasets show that the proposed model outperforms those in the literature.
Real-time semantic segmentation on FPGAs for autonomous vehicles with hls4ml
May 16, 2022

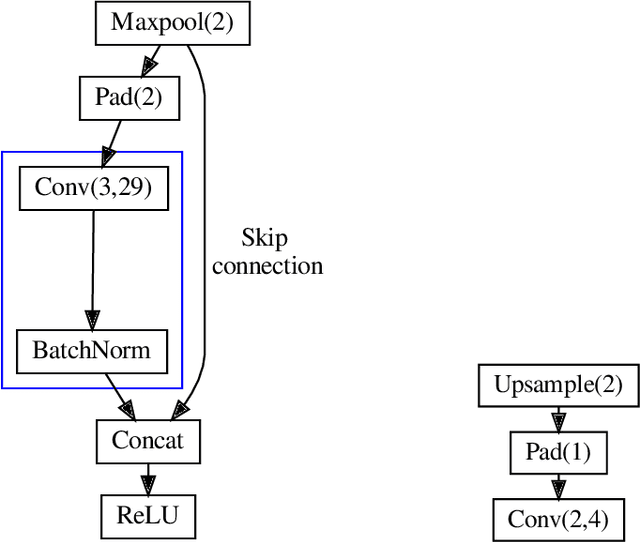
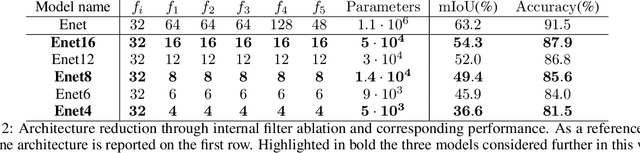
In this paper, we investigate how field programmable gate arrays can serve as hardware accelerators for real-time semantic segmentation tasks relevant for autonomous driving. Considering compressed versions of the ENet convolutional neural network architecture, we demonstrate a fully-on-chip deployment with a latency of 4.9 ms per image, using less than 30% of the available resources on a Xilinx ZCU102 evaluation board. The latency is reduced to 3 ms per image when increasing the batch size to ten, corresponding to the use case where the autonomous vehicle receives inputs from multiple cameras simultaneously. We show, through aggressive filter reduction and heterogeneous quantization-aware training, and an optimized implementation of convolutional layers, that the power consumption and resource utilization can be significantly reduced while maintaining accuracy on the Cityscapes dataset.
Scalable and Real-time Multi-Camera Vehicle Detection, Re-Identification, and Tracking
Apr 15, 2022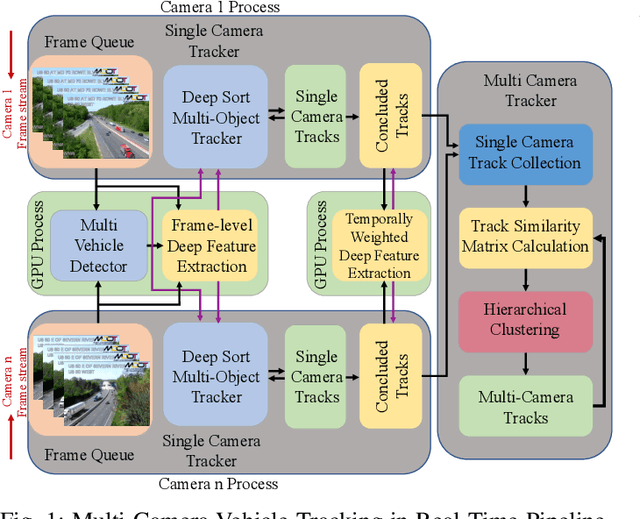

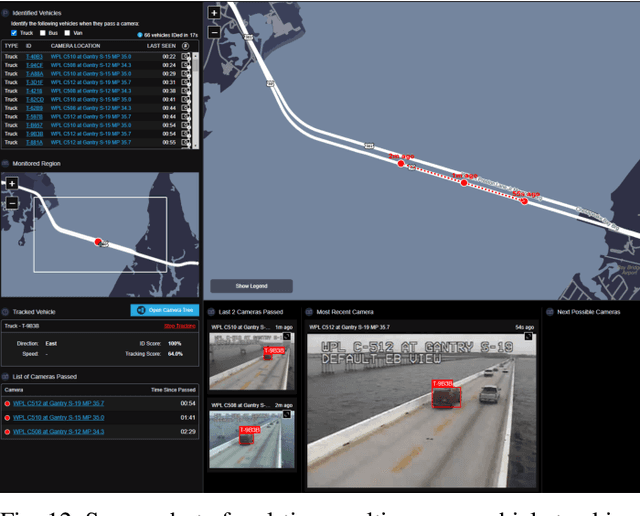
Multi-camera vehicle tracking is one of the most complicated tasks in Computer Vision as it involves distinct tasks including Vehicle Detection, Tracking, and Re-identification. Despite the challenges, multi-camera vehicle tracking has immense potential in transportation applications including speed, volume, origin-destination (O-D), and routing data generation. Several recent works have addressed the multi-camera tracking problem. However, most of the effort has gone towards improving accuracy on high-quality benchmark datasets while disregarding lower camera resolutions, compression artifacts and the overwhelming amount of computational power and time needed to carry out this task on its edge and thus making it prohibitive for large-scale and real-time deployment. Therefore, in this work we shed light on practical issues that should be addressed for the design of a multi-camera tracking system to provide actionable and timely insights. Moreover, we propose a real-time city-scale multi-camera vehicle tracking system that compares favorably to computationally intensive alternatives and handles real-world, low-resolution CCTV instead of idealized and curated video streams. To show its effectiveness, in addition to integration into the Regional Integrated Transportation Information System (RITIS), we participated in the 2021 NVIDIA AI City multi-camera tracking challenge and our method is ranked among the top five performers on the public leaderboard.
On-the-Fly Test-time Adaptation for Medical Image Segmentation
Mar 10, 2022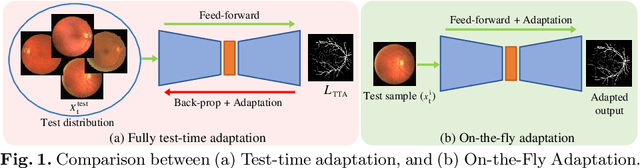

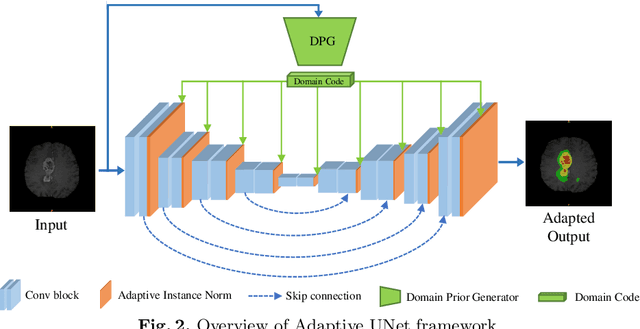
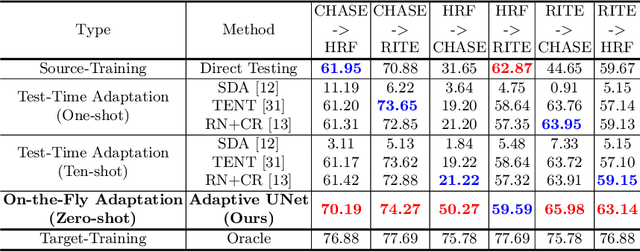
One major problem in deep learning-based solutions for medical imaging is the drop in performance when a model is tested on a data distribution different from the one that it is trained on. Adapting the source model to target data distribution at test-time is an efficient solution for the data-shift problem. Previous methods solve this by adapting the model to target distribution by using techniques like entropy minimization or regularization. In these methods, the models are still updated by back-propagation using an unsupervised loss on complete test data distribution. In real-world clinical settings, it makes more sense to adapt a model to a new test image on-the-fly and avoid model update during inference due to privacy concerns and lack of computing resource at deployment. To this end, we propose a new setting - On-the-Fly Adaptation which is zero-shot and episodic (i.e., the model is adapted to a single image at a time and also does not perform any back-propagation during test-time). To achieve this, we propose a new framework called Adaptive UNet where each convolutional block is equipped with an adaptive batch normalization layer to adapt the features with respect to a domain code. The domain code is generated using a pre-trained encoder trained on a large corpus of medical images. During test-time, the model takes in just the new test image and generates a domain code to adapt the features of source model according to the test data. We validate the performance on both 2D and 3D data distribution shifts where we get a better performance compared to previous test-time adaptation methods. Code is available at https://github.com/jeya-maria-jose/On-The-Fly-Adaptation
GANStrument: Adversarial Instrument Sound Synthesis with Pitch-invariant Instance Conditioning
Nov 10, 2022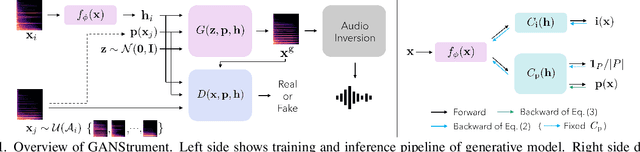
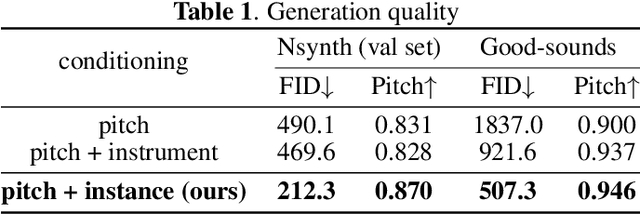
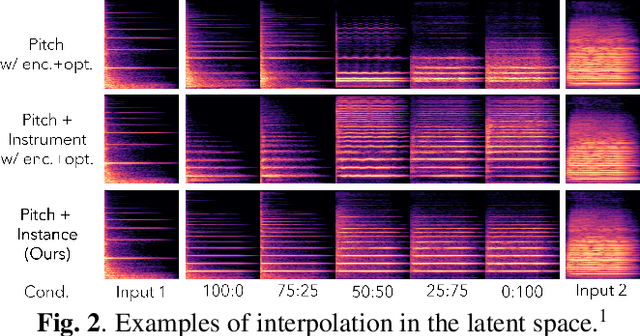
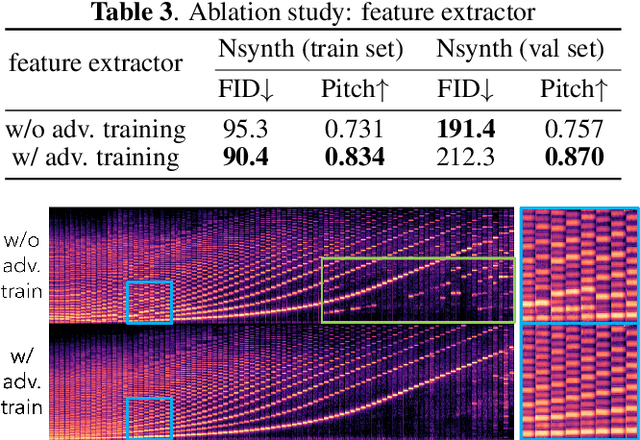
We propose GANStrument, a generative adversarial model for instrument sound synthesis. Given a one-shot sound as input, it is able to generate pitched instrument sounds that reflect the timbre of the input within an interactive time. By exploiting instance conditioning, GANStrument achieves better fidelity and diversity of synthesized sounds and generalization ability to various inputs. In addition, we introduce an adversarial training scheme for a pitch-invariant feature extractor that significantly improves the pitch accuracy and timbre consistency. Experimental results show that GANStrument outperforms strong baselines that do not use instance conditioning in terms of generation quality and input editability. Qualitative examples are available online.
SRNR: Training neural networks for Super-Resolution MRI using Noisy high-resolution Reference data
Nov 10, 2022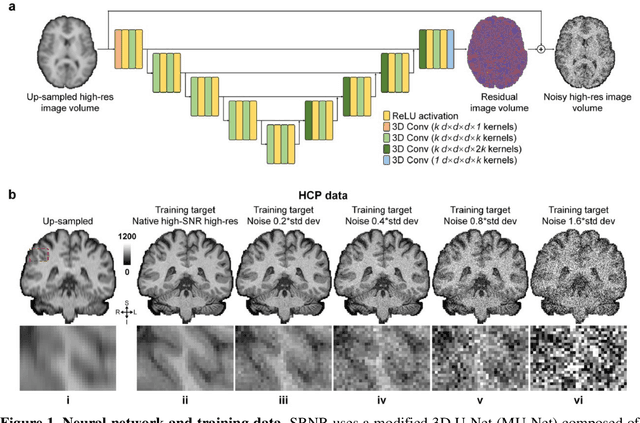
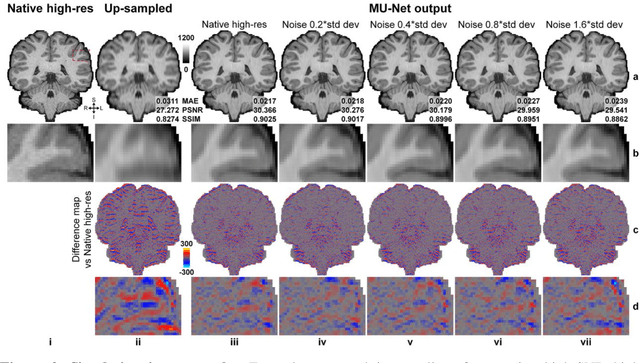
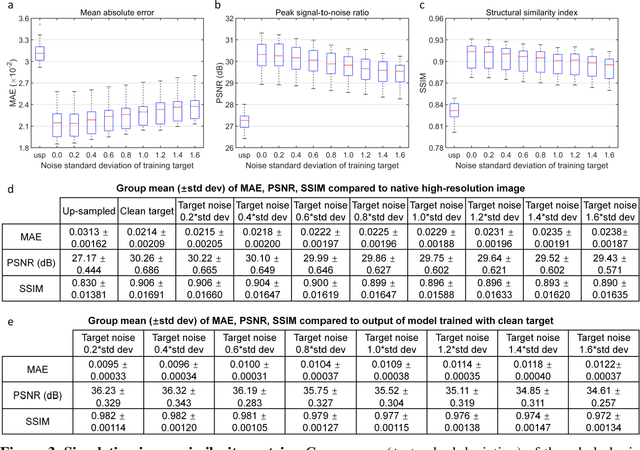
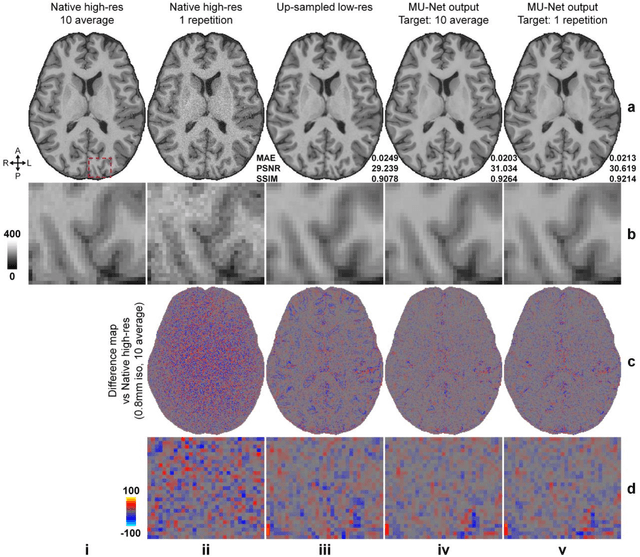
Neural network (NN) based approaches for super-resolution MRI typically require high-SNR high-resolution reference data acquired in many subjects, which is time consuming and a barrier to feasible and accessible implementation. We propose to train NNs for Super-Resolution using Noisy Reference data (SRNR), leveraging the mechanism of the classic NN-based denoising method Noise2Noise. We systematically demonstrate that results from NNs trained using noisy and high-SNR references are similar for both simulated and empirical data. SRNR suggests a smaller number of repetitions of high-resolution reference data can be used to simplify the training data preparation for super-resolution MRI.
Omnidirectional robot modeling and simulation
Nov 15, 2022
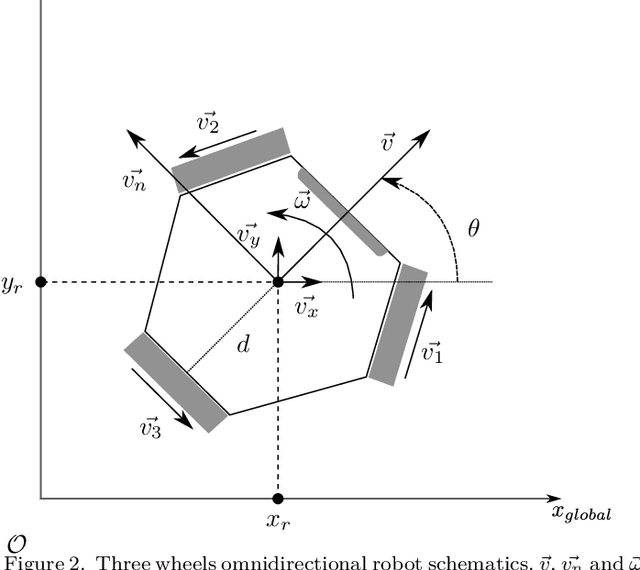
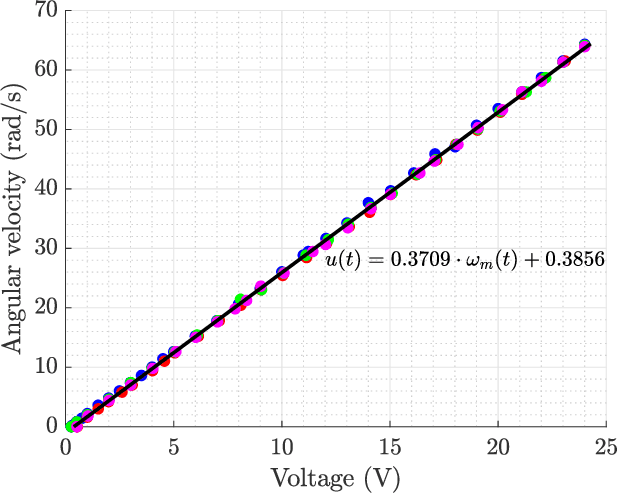
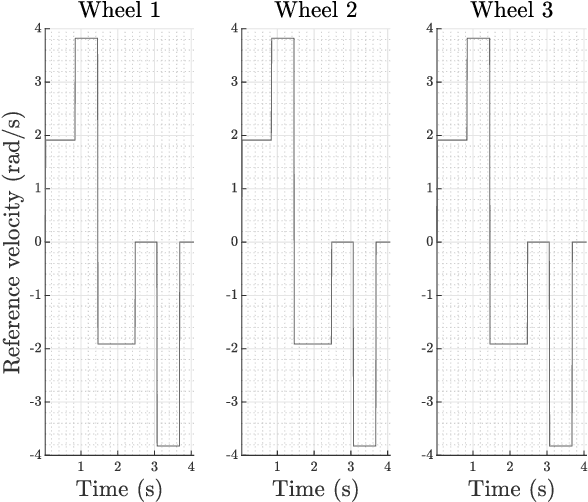
A robot simulation system is a basic need for any robotics application. With it, developers' teams of robots can test their algorithms and make initial calibrations without risk of damage to the real robots, assuring safety. However, building these simulation environments is usually time-consuming work, and when considering robot fleets, the simulation reveals to be computing expensive. With it, developers building teams of robots can test their algorithms and make initial calibrations without risk of damage to the real robots, assuring safety. An omnidirectional robot from the 5DPO robotics soccer team served to test this approach. The modeling issue was divided into two steps: modeling the motor's non-linear features and modeling the general behavior of the robot. A proper fitting of the robot was reached, considering the velocity robot's response.
* Conference proceedings ICARSC; 6 pages
Autonomous Golf Putting with Data-Driven and Physics-Based Methods
Nov 15, 2022
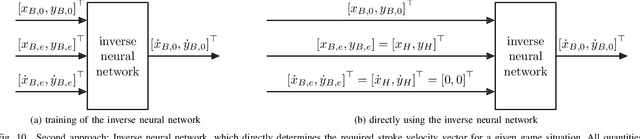
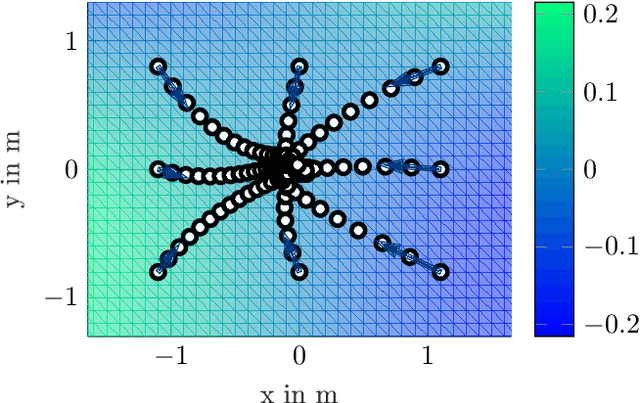

We are developing a self-learning mechatronic golf robot using combined data-driven and physics-based methods, to have the robot autonomously learn to putt the ball from an arbitrary point on the green. Apart from the mechatronic control design of the robot, this task is accomplished by a camera system with image recognition and a neural network for predicting the stroke velocity vector required for a successful hole-in-one. To minimize the number of time-consuming interactions with the real system, the neural network is pretrained by evaluating basic physical laws on a model, which approximates the golf ball dynamics on the green surface in a data-driven manner. Thus, we demonstrate the synergetic combination of data-driven and physics-based methods on the golf robot as a mechatronic example system.
Cross-Reality Re-Rendering: Manipulating between Digital and Physical Realities
Nov 15, 2022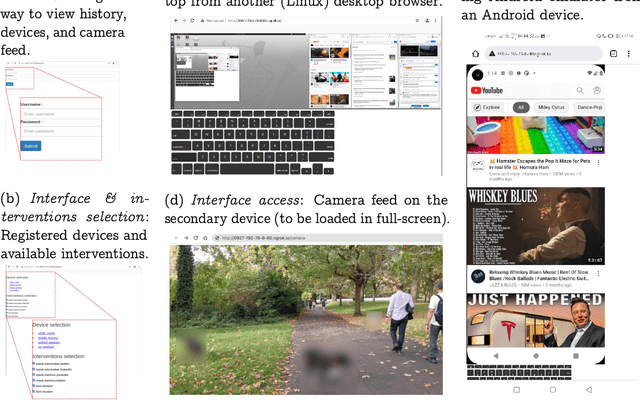


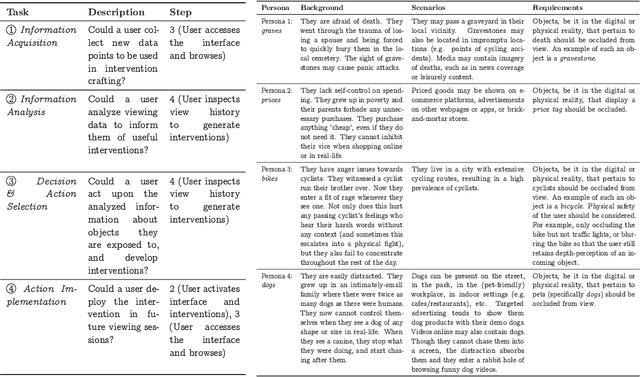
The advent of personalized reality has arrived. Rapid development in AR/MR/VR enables users to augment or diminish their perception of the physical world. Robust tooling for digital interface modification enables users to change how their software operates. As digital realities become an increasingly-impactful aspect of human lives, we investigate the design of a system that enables users to manipulate the perception of both their physical realities and digital realities. Users can inspect their view history from either reality, and generate interventions that can be interoperably rendered cross-reality in real-time. Personalized interventions can be generated with mask, text, and model hooks. Collaboration between users scales the availability of interventions. We verify our implementation against our design requirements with cognitive walkthroughs, personas, and scalability tests.
SpectroMap: Peak detection algorithm for audio fingerprinting
Nov 02, 2022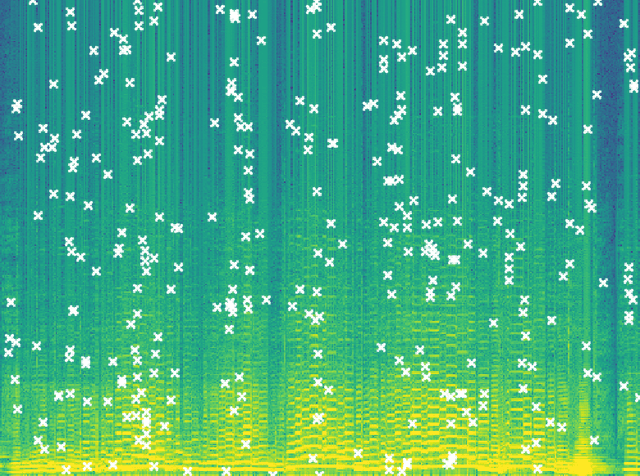
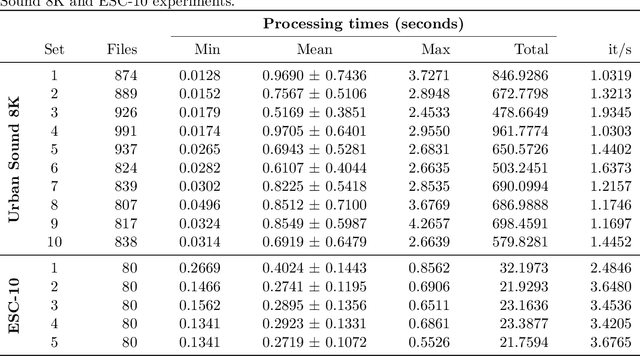

We present SpectroMap, an open source GitHub repository for audio fingerprinting written in Python programming language. It is composed of a peak search algorithm that extracts topological prominences from a spectrogram via time-frequency bands. In this paper, we introduce the algorithm functioning with two experimental applications in a high-quality urban sound dataset and environmental audio recordings to describe how it works and how effective it is in handling the input data.