 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Wheel Impact Test by Deep Learning: Prediction of Location and Magnitude of Maximum Stress
Oct 03, 2022
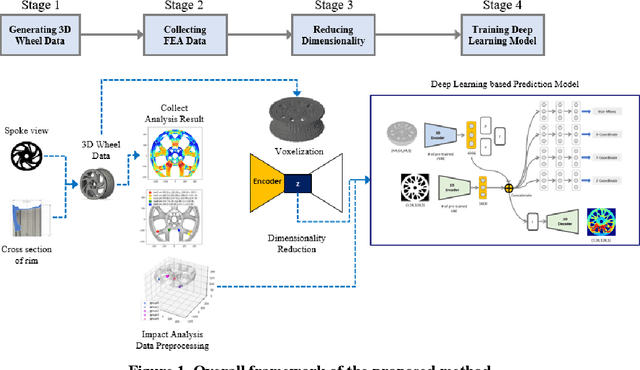
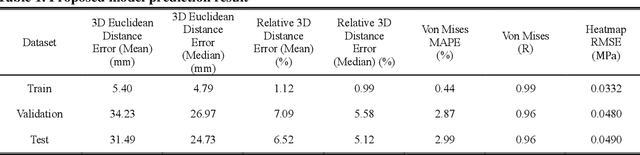
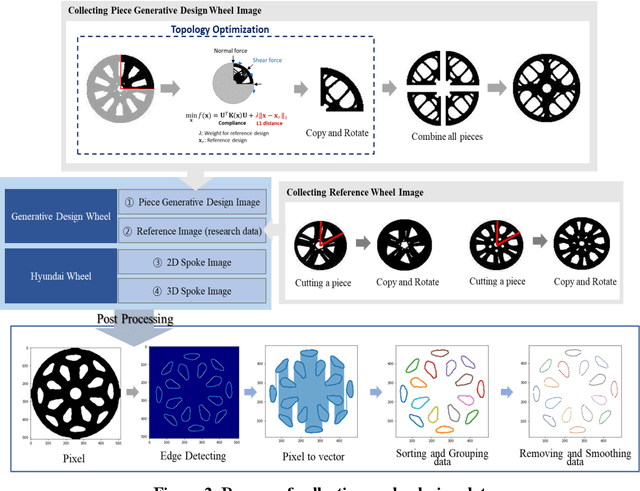
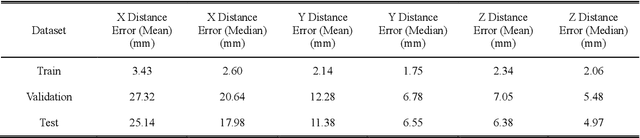
The impact performance of the wheel during wheel development must be ensured through a wheel impact test for vehicle safety. However, manufacturing and testing a real wheel take a significant amount of time and money because developing an optimal wheel design requires numerous iterative processes of modifying the wheel design and verifying the safety performance. Accordingly, the actual wheel impact test has been replaced by computer simulations, such as Finite Element Analysis (FEA), but it still requires high computational costs for modeling and analysis. Moreover, FEA experts are needed. This study presents an aluminum road wheel impact performance prediction model based on deep learning that replaces the computationally expensive and time-consuming 3D FEA. For this purpose, 2D disk-view wheel image data, 3D wheel voxel data, and barrier mass value used for wheel impact test are utilized as the inputs to predict the magnitude of maximum von Mises stress, corresponding location, and the stress distribution of 2D disk-view. The wheel impact performance prediction model can replace the impact test in the early wheel development stage by predicting the impact performance in real time and can be used without domain knowledge. The time required for the wheel development process can be shortened through this mechanism.
Magic3D: High-Resolution Text-to-3D Content Creation
Nov 18, 2022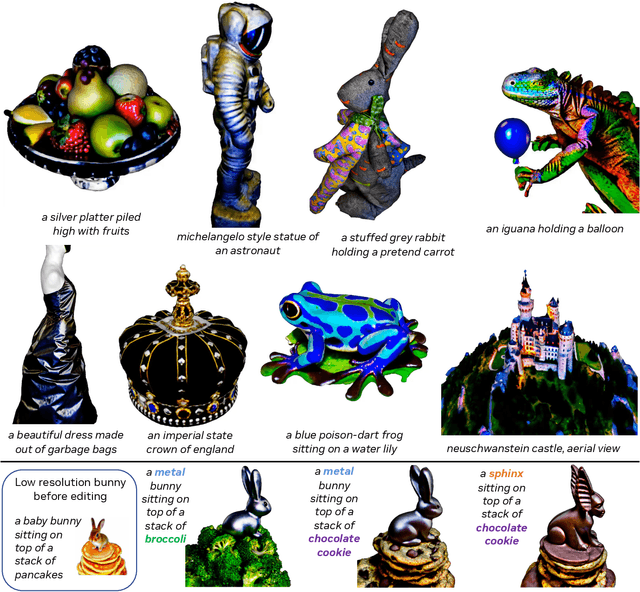

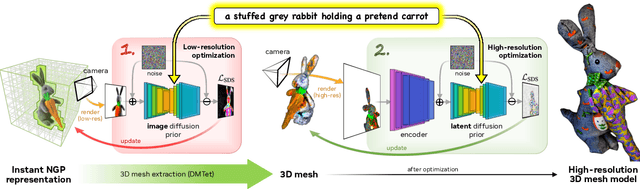

DreamFusion has recently demonstrated the utility of a pre-trained text-to-image diffusion model to optimize Neural Radiance Fields (NeRF), achieving remarkable text-to-3D synthesis results. However, the method has two inherent limitations: (a) extremely slow optimization of NeRF and (b) low-resolution image space supervision on NeRF, leading to low-quality 3D models with a long processing time. In this paper, we address these limitations by utilizing a two-stage optimization framework. First, we obtain a coarse model using a low-resolution diffusion prior and accelerate with a sparse 3D hash grid structure. Using the coarse representation as the initialization, we further optimize a textured 3D mesh model with an efficient differentiable renderer interacting with a high-resolution latent diffusion model. Our method, dubbed Magic3D, can create high quality 3D mesh models in 40 minutes, which is 2x faster than DreamFusion (reportedly taking 1.5 hours on average), while also achieving higher resolution. User studies show 61.7% raters to prefer our approach over DreamFusion. Together with the image-conditioned generation capabilities, we provide users with new ways to control 3D synthesis, opening up new avenues to various creative applications.
Context Variance Evaluation of Pretrained Language Models for Prompt-based Biomedical Knowledge Probing
Nov 18, 2022
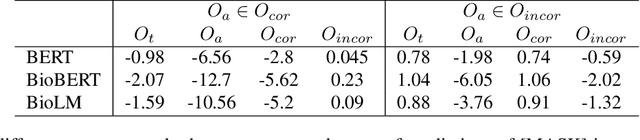
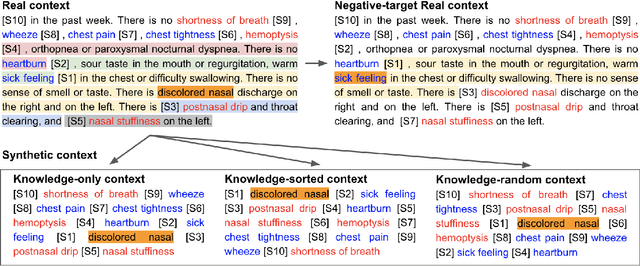
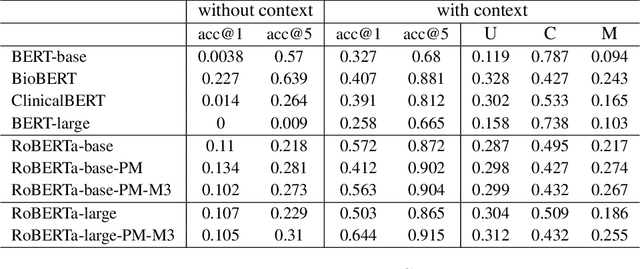
Pretrained language models (PLMs) have motivated research on what kinds of knowledge these models learn. Fill-in-the-blanks problem (e.g., cloze tests) is a natural approach for gauging such knowledge. BioLAMA generates prompts for biomedical factual knowledge triples and uses the Top-k accuracy metric to evaluate different PLMs' knowledge. However, existing research has shown that such prompt-based knowledge probing methods can only probe a lower bound of knowledge. Many factors like prompt-based probing biases make the LAMA benchmark unreliable and unstable. This problem is more prominent in BioLAMA. The severe long-tailed distribution in vocabulary and large-N-M relation make the performance gap between LAMA and BioLAMA remain notable. To address these, we introduce context variance into the prompt generation and propose a new rank-change-based evaluation metric. Different from the previous known-unknown evaluation criteria, we propose the concept of "Misunderstand" in LAMA for the first time. Through experiments on 12 PLMs, our context variance prompts and Understand-Confuse-Misunderstand (UCM) metric makes BioLAMA more friendly to large-N-M relations and rare relations. We also conducted a set of control experiments to disentangle "understand" from just "read and copy".
Active Learning with Convolutional Gaussian Neural Processes for Environmental Sensor Placement
Nov 18, 2022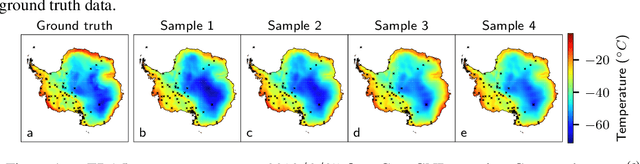

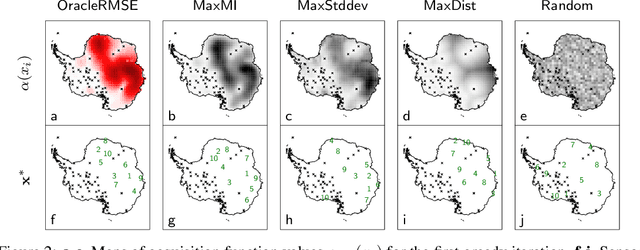
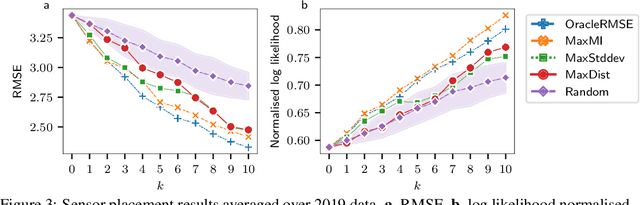
Deploying environmental measurement stations can be a costly and time consuming procedure, especially in regions which are remote or otherwise difficult to access, such as Antarctica. Therefore, it is crucial that sensors are placed as efficiently as possible, maximising the informativeness of their measurements. Previous approaches for identifying salient placement locations typically model the data with a Gaussian process (GP). However, designing a GP covariance which captures the complex behaviour of non-stationary spatiotemporal data is a difficult task. Further, the computational cost of these models make them challenging to scale to large environmental datasets. In this work, we explore using convolutional Gaussian neural processes (ConvGNPs) to address these issues. A ConvGNP is a meta-learning model which uses a neural network to parameterise a GP predictive. Our model is data-driven, flexible, efficient, and permits gridded or off-grid input data. Using simulated surface temperature fields over Antarctica as ground truth, we show that a ConvGNP substantially outperforms a non-stationary GP baseline in terms of predictive performance. We then use the ConvGNP in a temperature sensor placement toy experiment, yielding promising results.
Development and validation of deep learning based embryo selection across multiple days of transfer
Oct 05, 2022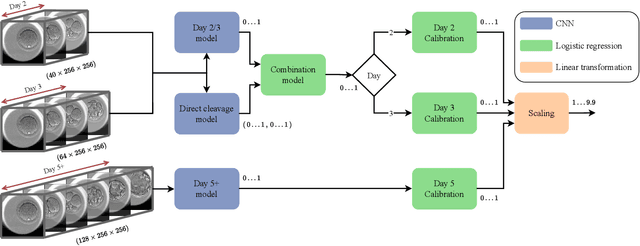


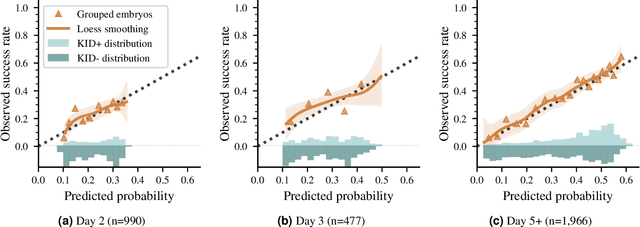
This work describes the development and validation of a fully automated deep learning model, iDAScore v2.0, for the evaluation of embryos incubated for 2, 3, and 5 or more days. The model is trained and evaluated on an extensive and diverse dataset including 181,428 embryos from 22 IVF clinics across the world. For discriminating transferred embryos with known outcome (KID), we show AUCs ranging from 0.621 to 0.708 depending on the day of transfer. Predictive performance increased over time and showed a strong correlation with morphokinetic parameters. The model has equivalent performance to KIDScore D3 on day 3 embryos while significantly surpassing the performance of KIDScore D5 v3 on day 5+ embryos. This model provides an analysis of time-lapse sequences without the need for user input, and provides a reliable method for ranking embryos for likelihood to implant, at both cleavage and blastocyst stages. This greatly improves embryo grading consistency and saves time compared to traditional embryo evaluation methods.
Federated Learning Under Intermittent Client Availability and Time-Varying Communication Constraints
May 13, 2022
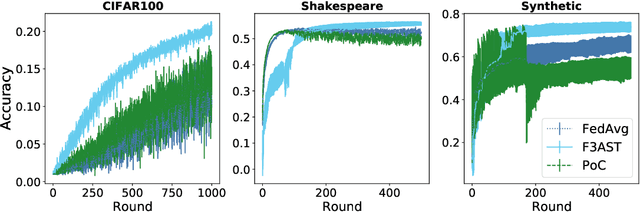
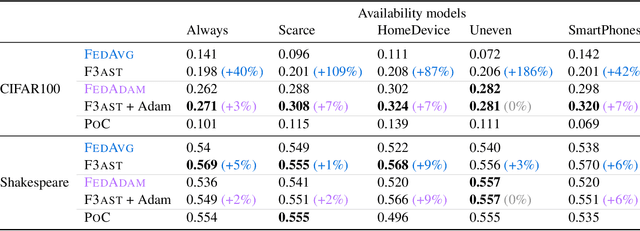
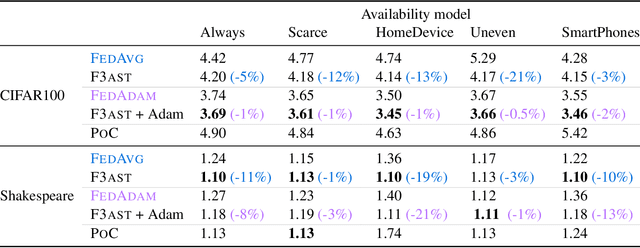
Federated learning systems facilitate training of global models in settings where potentially heterogeneous data is distributed across a large number of clients. Such systems operate in settings with intermittent client availability and/or time-varying communication constraints. As a result, the global models trained by federated learning systems may be biased towards clients with higher availability. We propose F3AST, an unbiased algorithm that dynamically learns an availability-dependent client selection strategy which asymptotically minimizes the impact of client-sampling variance on the global model convergence, enhancing performance of federated learning. The proposed algorithm is tested in a variety of settings for intermittently available clients under communication constraints, and its efficacy demonstrated on synthetic data and realistically federated benchmarking experiments using CIFAR100 and Shakespeare datasets. We show up to 186% and 8% accuracy improvements over FedAvg, and 8% and 7% over FedAdam on CIFAR100 and Shakespeare, respectively.
Mention Annotations Alone Enable Efficient Domain Adaptation for Coreference Resolution
Oct 14, 2022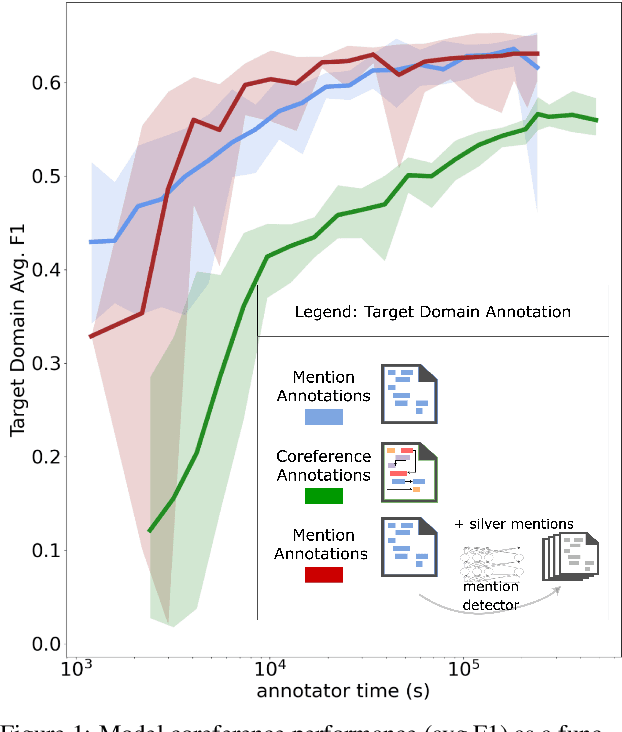

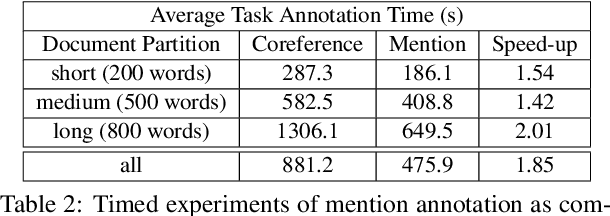
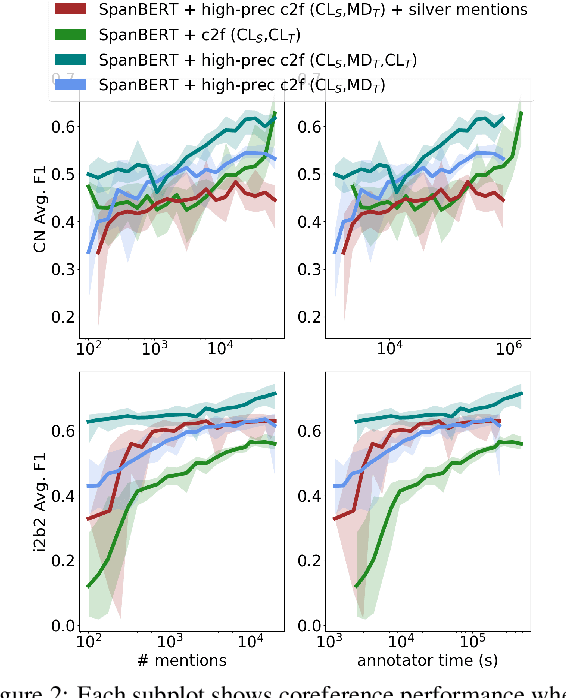
Although, recent advances in neural network models for coreference resolution have led to substantial improvements on benchmark datasets, it remains a challenge to successfully transfer those models to new target domains containing many out-of-vocabulary spans and requiring differing annotation schemes. Typical approaches for domain adaptation involve continued training on coreference annotations in the target domain, but obtaining those annotations is costly and time-consuming. In this work, we show that adapting mention detection is the key component to successful domain adaptation of coreference models, rather than antecedent linking. Through timed annotation experiments, we also show annotating mentions alone is nearly twice as fast as annotating full coreference chains. Based on these insights, we propose a method for effectively adapting coreference models that requires only mention annotations in the target domain. We use an auxiliary mention detection objective trained with mention examples in the target domain resulting in higher mention precision. We demonstrate that our approach facilitates sample- and time-efficient transfer to new annotation schemes and lexicons in extensive evaluation across three English coreference datasets: CoNLL-2012 (news/conversation), i2b2/VA (medical case notes), and a dataset of child welfare case notes. We show that annotating mentions results in 7-14% improvement in average F1 over annotating coreference over an equivalent amount of time.
Simultaneous Estimation of Hand Configurations and Finger Joint Angles using Forearm Ultrasound
Nov 29, 2022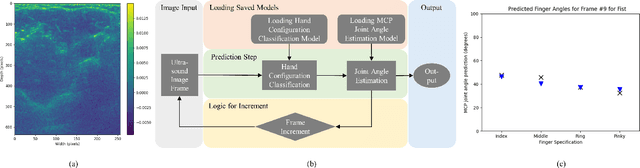
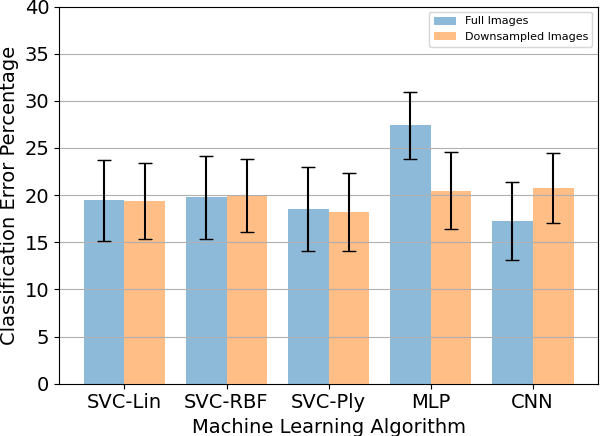
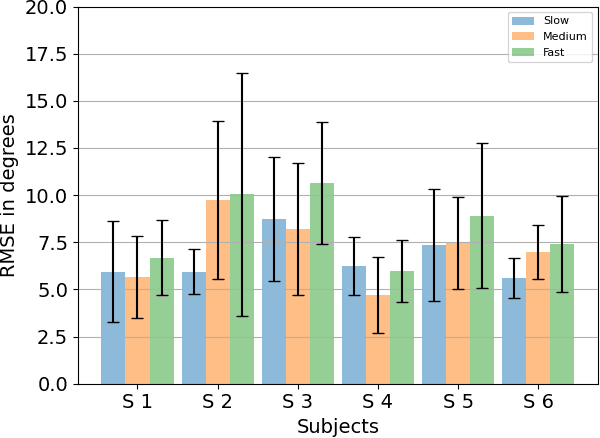
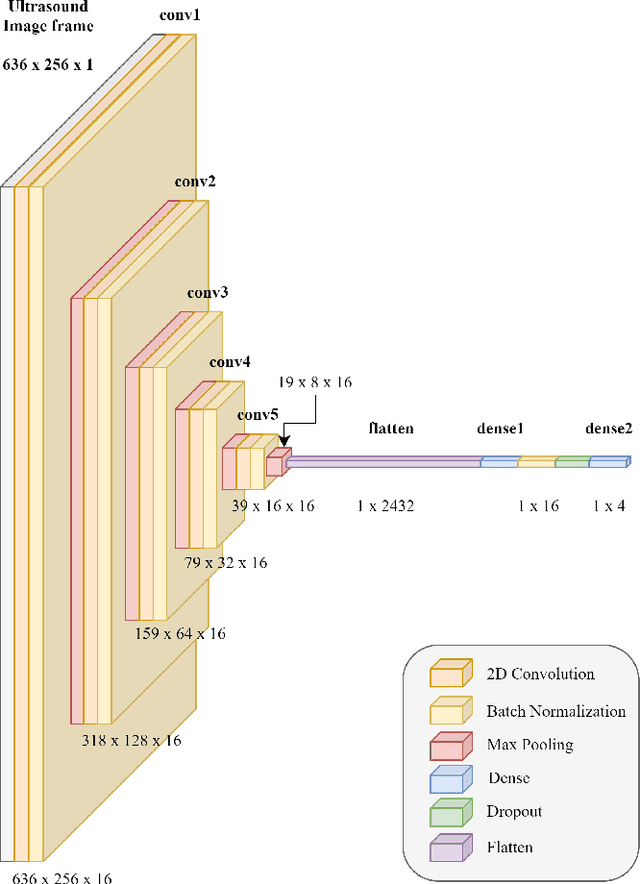
With the advancement in computing and robotics, it is necessary to develop fluent and intuitive methods for interacting with digital systems, augmented/virtual reality (AR/VR) interfaces, and physical robotic systems. Hand motion recognition is widely used to enable these interactions. Hand configuration classification and MCP joint angle detection is important for a comprehensive reconstruction of hand motion. sEMG and other technologies have been used for the detection of hand motions. Forearm ultrasound images provide a musculoskeletal visualization that can be used to understand hand motion. Recent work has shown that these ultrasound images can be classified using machine learning to estimate discrete hand configurations. Estimating both hand configuration and MCP joint angles based on forearm ultrasound has not been addressed in the literature. In this paper, we propose a CNN based deep learning pipeline for predicting the MCP joint angles. The results for the hand configuration classification were compared by using different machine learning algorithms. SVC with different kernels, MLP, and the proposed CNN have been used to classify the ultrasound images into 11 hand configurations based on activities of daily living. Forearm ultrasound images were acquired from 6 subjects instructed to move their hands according to predefined hand configurations. Motion capture data was acquired to get the finger angles corresponding to the hand movements at different speeds. Average classification accuracy of 82.7% for the proposed CNN and over 80% for SVC for different kernels was observed on a subset of the dataset. An average RMSE of 7.35 degrees was obtained between the predicted and the true MCP joint angles. A low latency (6.25 - 9.1 Hz) pipeline has been proposed for estimating both MCP joint angles and hand configuration aimed at real-time control of human-machine interfaces.
Penalized Langevin and Hamiltonian Monte Carlo Algorithms for Constrained Sampling
Nov 29, 2022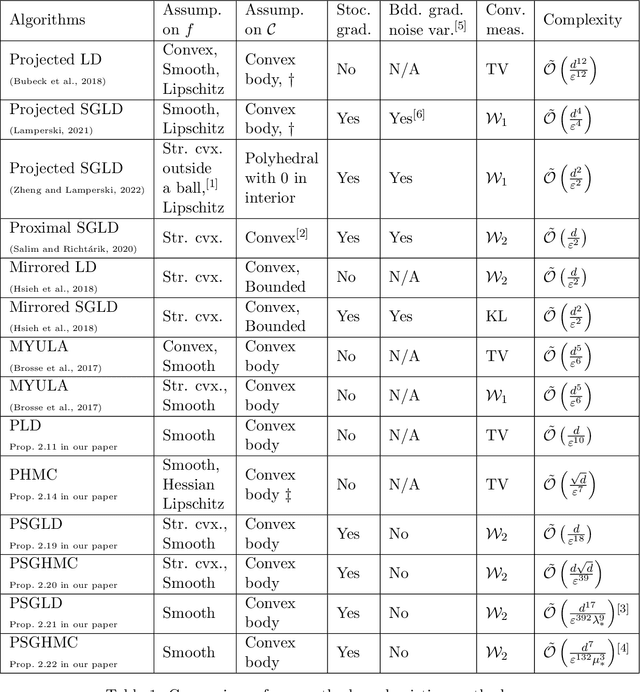
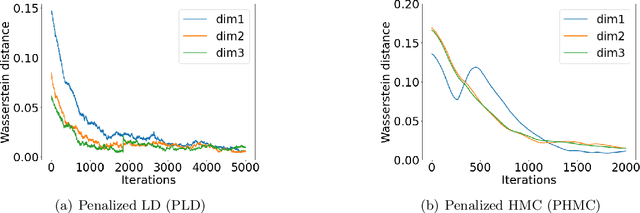
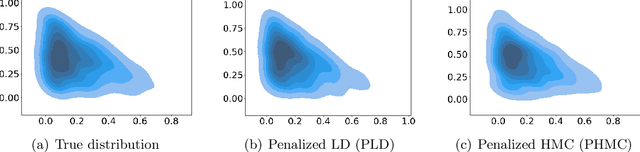
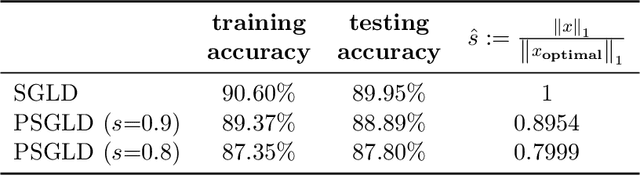
We consider the constrained sampling problem where the goal is to sample from a distribution $\pi(x)\propto e^{-f(x)}$ and $x$ is constrained on a convex body $\mathcal{C}\subset \mathbb{R}^d$. Motivated by penalty methods from optimization, we propose penalized Langevin Dynamics (PLD) and penalized Hamiltonian Monte Carlo (PHMC) that convert the constrained sampling problem into an unconstrained one by introducing a penalty function for constraint violations. When $f$ is smooth and the gradient is available, we show $\tilde{\mathcal{O}}(d/\varepsilon^{10})$ iteration complexity for PLD to sample the target up to an $\varepsilon$-error where the error is measured in terms of the total variation distance and $\tilde{\mathcal{O}}(\cdot)$ hides some logarithmic factors. For PHMC, we improve this result to $\tilde{\mathcal{O}}(\sqrt{d}/\varepsilon^{7})$ when the Hessian of $f$ is Lipschitz and the boundary of $\mathcal{C}$ is sufficiently smooth. To our knowledge, these are the first convergence rate results for Hamiltonian Monte Carlo methods in the constrained sampling setting that can handle non-convex $f$ and can provide guarantees with the best dimension dependency among existing methods with deterministic gradients. We then consider the setting where unbiased stochastic gradients are available. We propose PSGLD and PSGHMC that can handle stochastic gradients without Metropolis-Hasting correction steps. When $f$ is strongly convex and smooth, we obtain an iteration complexity of $\tilde{\mathcal{O}}(d/\varepsilon^{18})$ and $\tilde{\mathcal{O}}(d\sqrt{d}/\varepsilon^{39})$ respectively in the 2-Wasserstein distance. For the more general case, when $f$ is smooth and non-convex, we also provide finite-time performance bounds and iteration complexity results. Finally, we test our algorithms on Bayesian LASSO regression and Bayesian constrained deep learning problems.
Sketch-Guided Text-to-Image Diffusion Models
Nov 24, 2022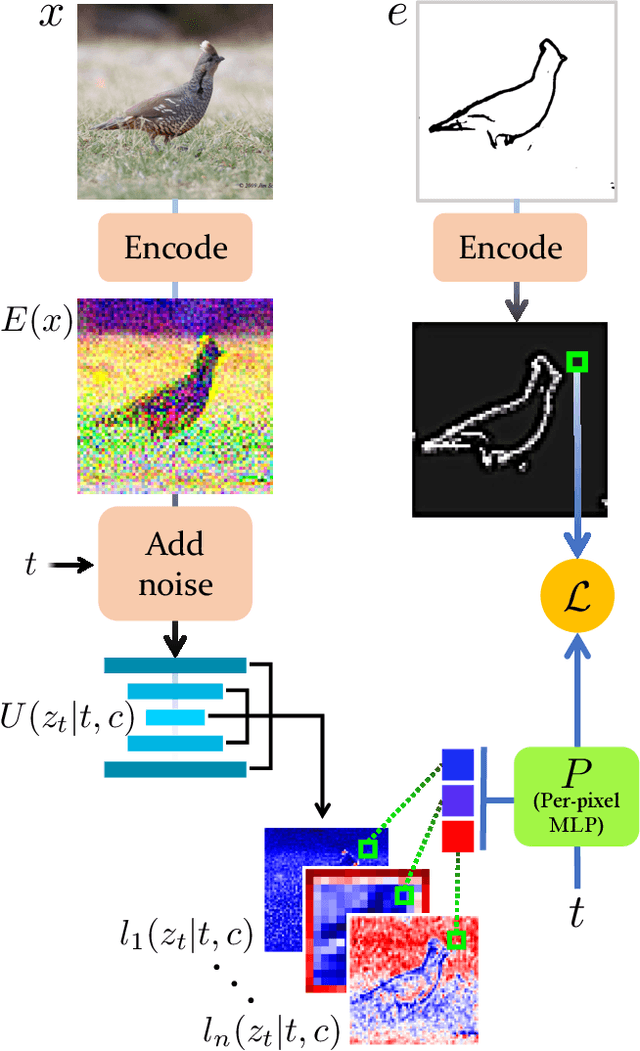
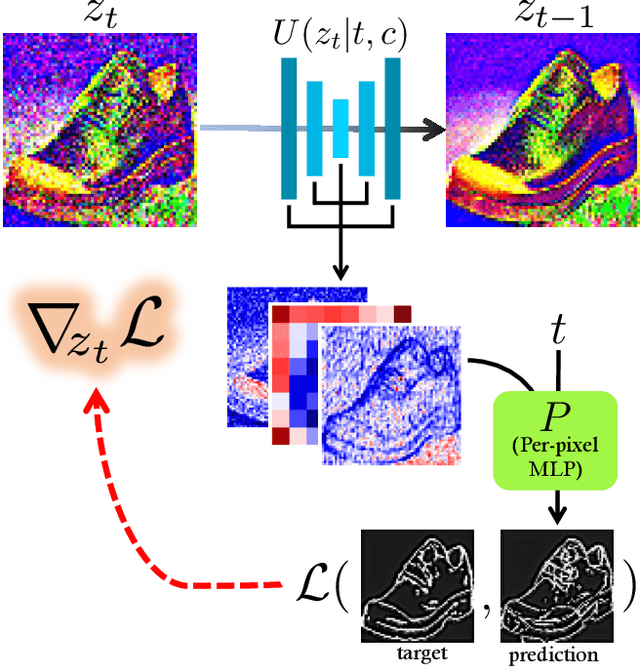

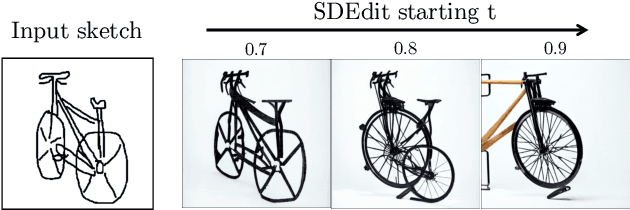
Text-to-Image models have introduced a remarkable leap in the evolution of machine learning, demonstrating high-quality synthesis of images from a given text-prompt. However, these powerful pretrained models still lack control handles that can guide spatial properties of the synthesized images. In this work, we introduce a universal approach to guide a pretrained text-to-image diffusion model, with a spatial map from another domain (e.g., sketch) during inference time. Unlike previous works, our method does not require to train a dedicated model or a specialized encoder for the task. Our key idea is to train a Latent Guidance Predictor (LGP) - a small, per-pixel, Multi-Layer Perceptron (MLP) that maps latent features of noisy images to spatial maps, where the deep features are extracted from the core Denoising Diffusion Probabilistic Model (DDPM) network. The LGP is trained only on a few thousand images and constitutes a differential guiding map predictor, over which the loss is computed and propagated back to push the intermediate images to agree with the spatial map. The per-pixel training offers flexibility and locality which allows the technique to perform well on out-of-domain sketches, including free-hand style drawings. We take a particular focus on the sketch-to-image translation task, revealing a robust and expressive way to generate images that follow the guidance of a sketch of arbitrary style or domain. Project page: sketch-guided-diffusion.github.io