 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Seeded iterative clustering for histology region identification
Nov 14, 2022
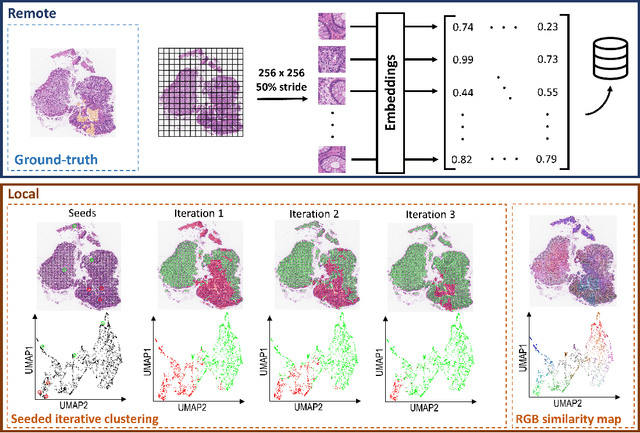
Annotations are necessary to develop computer vision algorithms for histopathology, but dense annotations at a high resolution are often time-consuming to make. Deep learning models for segmentation are a way to alleviate the process, but require large amounts of training data, training times and computing power. To address these issues, we present seeded iterative clustering to produce a coarse segmentation densely and at the whole slide level. The algorithm uses precomputed representations as the clustering space and a limited amount of sparse interactive annotations as seeds to iteratively classify image patches. We obtain a fast and effective way of generating dense annotations for whole slide images and a framework that allows the comparison of neural network latent representations in the context of transfer learning.
Background-Mixed Augmentation for Weakly Supervised Change Detection
Dec 01, 2022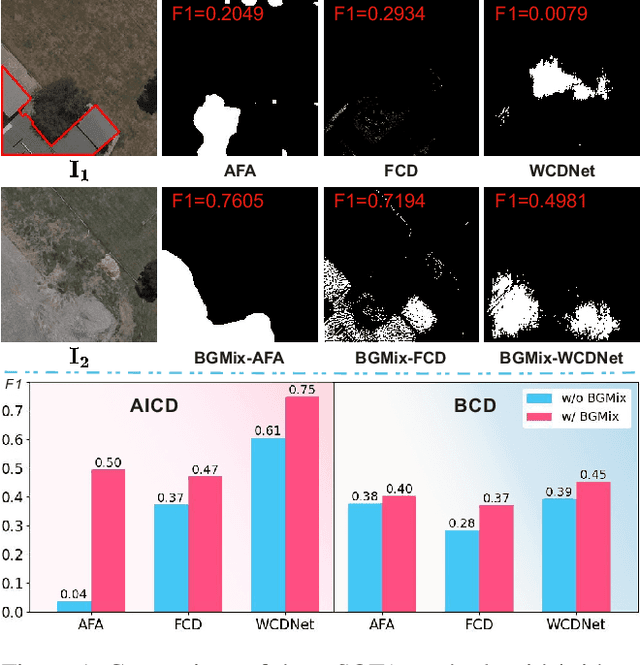
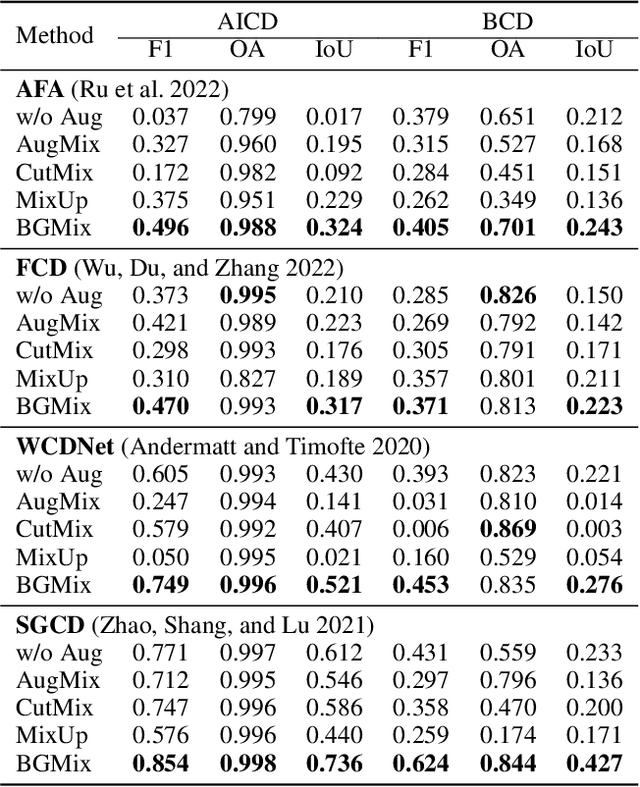

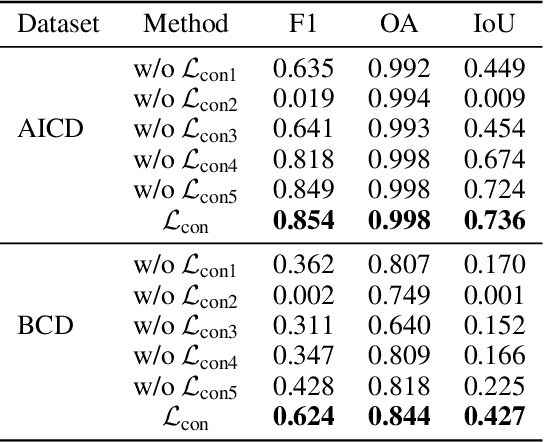
Change detection (CD) is to decouple object changes (i.e., object missing or appearing) from background changes (i.e., environment variations) like light and season variations in two images captured in the same scene over a long time span, presenting critical applications in disaster management, urban development, etc. In particular, the endless patterns of background changes require detectors to have a high generalization against unseen environment variations, making this task significantly challenging. Recent deep learning-based methods develop novel network architectures or optimization strategies with paired-training examples, which do not handle the generalization issue explicitly and require huge manual pixel-level annotation efforts. In this work, for the first attempt in the CD community, we study the generalization issue of CD from the perspective of data augmentation and develop a novel weakly supervised training algorithm that only needs image-level labels. Different from general augmentation techniques for classification, we propose the background-mixed augmentation that is specifically designed for change detection by augmenting examples under the guidance of a set of background-changing images and letting deep CD models see diverse environment variations. Moreover, we propose the augmented & real data consistency loss that encourages the generalization increase significantly. Our method as a general framework can enhance a wide range of existing deep learning-based detectors. We conduct extensive experiments in two public datasets and enhance four state-of-the-art methods, demonstrating the advantages of our method. We release the code at https://github.com/tsingqguo/bgmix.
A Hybrid Statistical-Machine Learning Approach for Analysing Online Customer Behavior: An Empirical Study
Dec 01, 2022
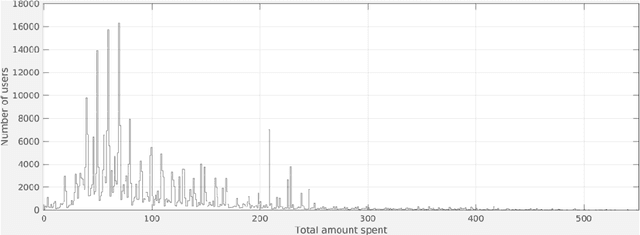
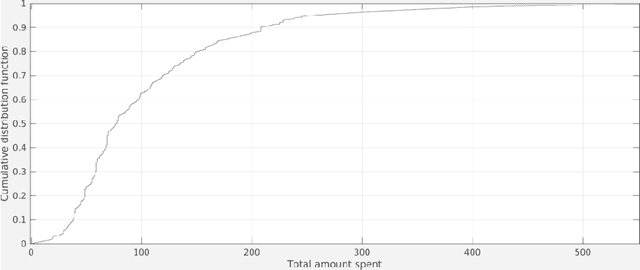
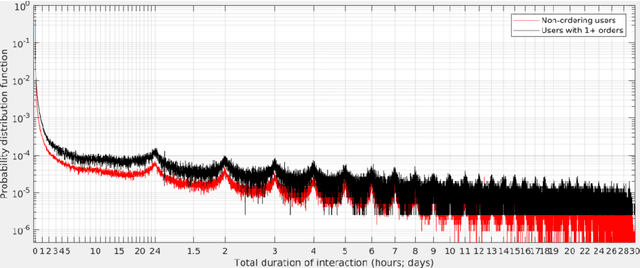
We apply classical statistical methods in conjunction with the state-of-the-art machine learning techniques to develop a hybrid interpretable model to analyse 454,897 online customers' behavior for a particular product category at the largest online retailer in China, that is JD. While most mere machine learning methods are plagued by the lack of interpretability in practice, our novel hybrid approach will address this practical issue by generating explainable output. This analysis involves identifying what features and characteristics have the most significant impact on customers' purchase behavior, thereby enabling us to predict future sales with a high level of accuracy, and identify the most impactful variables. Our results reveal that customers' product choice is insensitive to the promised delivery time, but this factor significantly impacts customers' order quantity. We also show that the effectiveness of various discounting methods depends on the specific product and the discount size. We identify product classes for which certain discounting approaches are more effective and provide recommendations on better use of different discounting tools. Customers' choice behavior across different product classes is mostly driven by price, and to a lesser extent, by customer demographics. The former finding asks for exercising care in deciding when and how much discount should be offered, whereas the latter identifies opportunities for personalized ads and targeted marketing. Further, to curb customers' batch ordering behavior and avoid the undesirable Bullwhip effect, JD should improve its logistics to ensure faster delivery of orders.
A Novel Speech Feature Fusion Algorithm for Text-Independent Speaker Recognition
Dec 01, 2022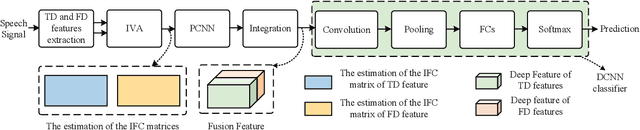
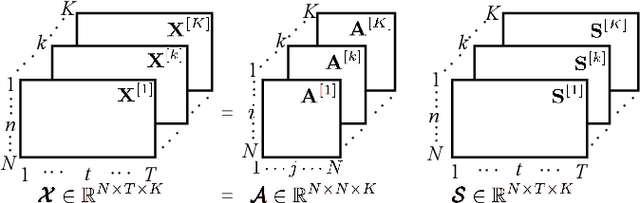
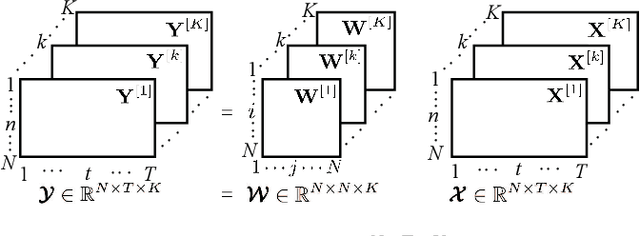
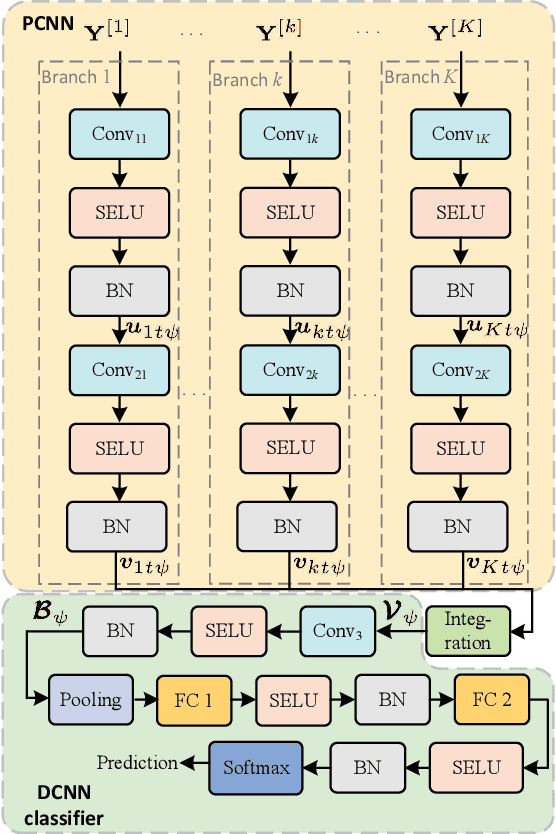
A novel speech feature fusion algorithm with independent vector analysis (IVA) and parallel convolutional neural network (PCNN) is proposed for text-independent speaker recognition. Firstly, some different feature types, such as the time domain (TD) features and the frequency domain (FD) features, can be extracted from a speaker's speech, and the TD and the FD features can be considered as the linear mixtures of independent feature components (IFCs) with an unknown mixing system. To estimate the IFCs, the TD and the FD features of the speaker's speech are concatenated to build the TD and the FD feature matrix, respectively. Then, a feature tensor of the speaker's speech is obtained by paralleling the TD and the FD feature matrix. To enhance the dependence on different feature types and remove the redundancies of the same feature type, the independent vector analysis (IVA) can be used to estimate the IFC matrices of TD and FD features with the feature tensor. The IFC matrices are utilized as the input of the PCNN to extract the deep features of the TD and FD features, respectively. The deep features can be integrated to obtain the fusion feature of the speaker's speech. Finally, the fusion feature of the speaker's speech is employed as the input of a deep convolutional neural network (DCNN) classifier for speaker recognition. The experimental results show the effectiveness and performances of the proposed speaker recognition system.
Kick-motion Training with DQN in AI Soccer Environment
Dec 01, 2022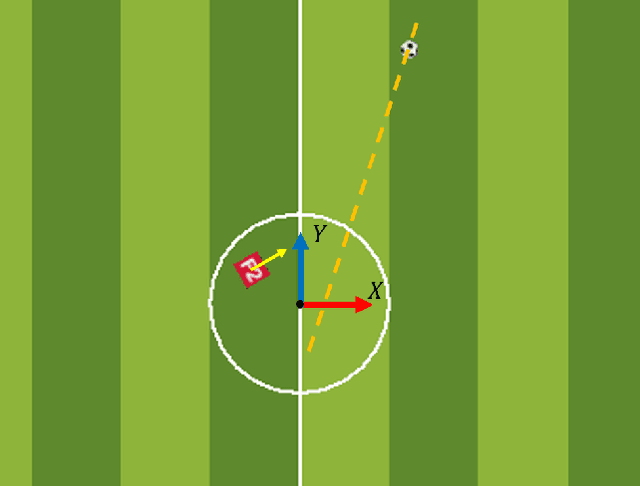
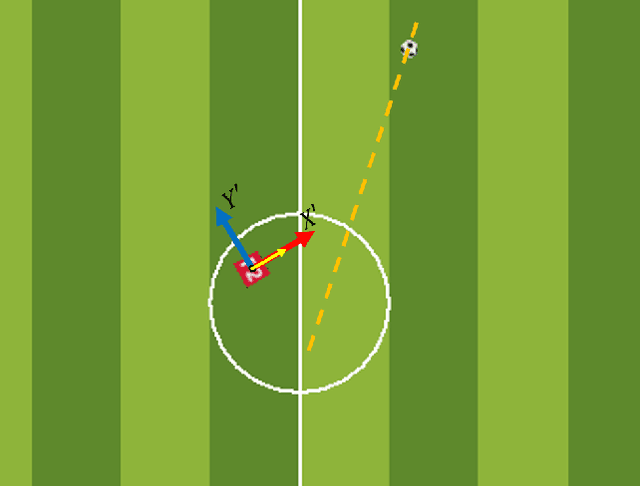
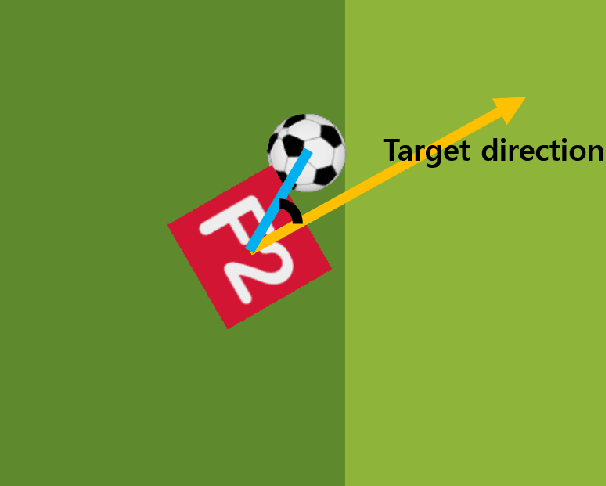
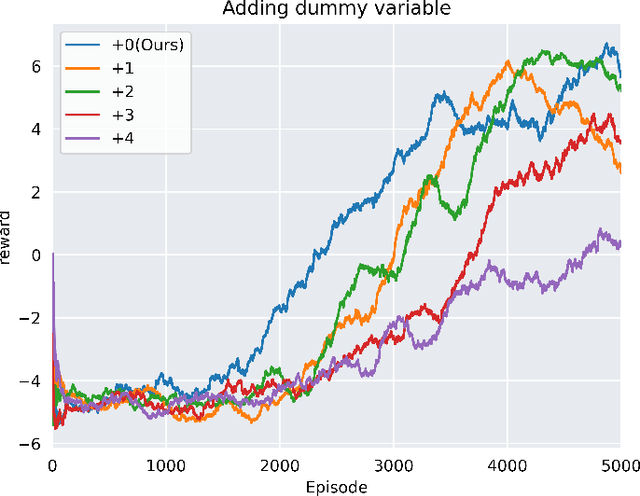
This paper presents a technique to train a robot to perform kick-motion in AI soccer by using reinforcement learning (RL). In RL, an agent interacts with an environment and learns to choose an action in a state at each step. When training RL algorithms, a problem called the curse of dimensionality (COD) can occur if the dimension of the state is high and the number of training data is low. The COD often causes degraded performance of RL models. In the situation of the robot kicking the ball, as the ball approaches the robot, the robot chooses the action based on the information obtained from the soccer field. In order not to suffer COD, the training data, which are experiences in the case of RL, should be collected evenly from all areas of the soccer field over (theoretically infinite) time. In this paper, we attempt to use the relative coordinate system (RCS) as the state for training kick-motion of robot agent, instead of using the absolute coordinate system (ACS). Using the RCS eliminates the necessity for the agent to know all the (state) information of entire soccer field and reduces the dimension of the state that the agent needs to know to perform kick-motion, and consequently alleviates COD. The training based on the RCS is performed with the widely used Deep Q-network (DQN) and tested in the AI Soccer environment implemented with Webots simulation software.
Good helper is around you: Attention-driven Masked Image Modeling
Dec 01, 2022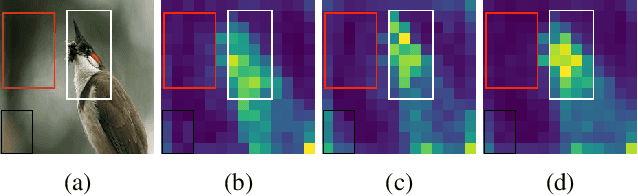

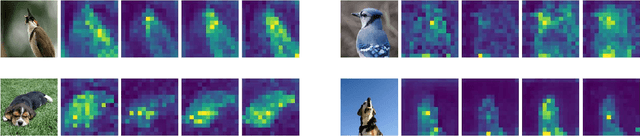
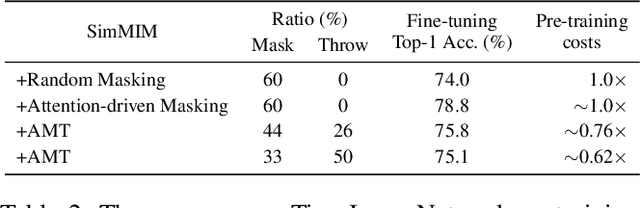
It has been witnessed that masked image modeling (MIM) has shown a huge potential in self-supervised learning in the past year. Benefiting from the universal backbone vision transformer, MIM learns self-supervised visual representations through masking a part of patches of the image while attempting to recover the missing pixels. Most previous works mask patches of the image randomly, which underutilizes the semantic information that is beneficial to visual representation learning. On the other hand, due to the large size of the backbone, most previous works have to spend much time on pre-training. In this paper, we propose \textbf{Attention-driven Masking and Throwing Strategy} (AMT), which could solve both problems above. We first leverage the self-attention mechanism to obtain the semantic information of the image during the training process automatically without using any supervised methods. Masking strategy can be guided by that information to mask areas selectively, which is helpful for representation learning. Moreover, a redundant patch throwing strategy is proposed, which makes learning more efficient. As a plug-and-play module for masked image modeling, AMT improves the linear probing accuracy of MAE by $2.9\% \sim 5.9\%$ on CIFAR-10/100, STL-10, Tiny ImageNet, and ImageNet-1K, and obtains an improved performance with respect to fine-tuning accuracy of MAE and SimMIM. Moreover, this design also achieves superior performance on downstream detection and segmentation tasks. Code is available at https://github.com/guijiejie/AMT.
Nonlinear and Machine Learning Analyses on High-Density EEG data of Math Experts and Novices
Dec 01, 2022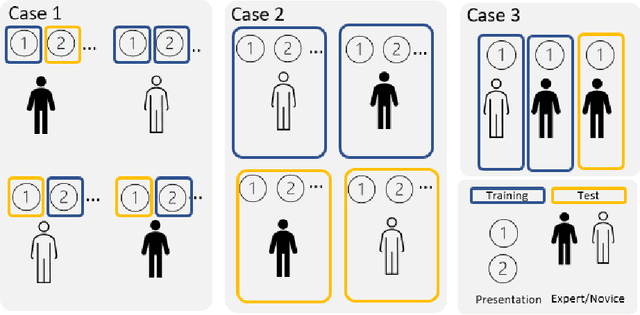

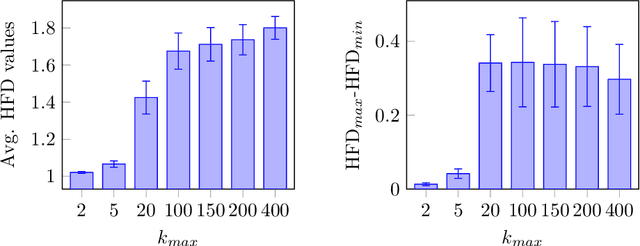
Current trend in neurosciences is to use naturalistic stimuli, such as cinema, class-room biology or video gaming, aiming to understand the brain functions during ecologically valid conditions. Naturalistic stimuli recruit complex and overlapping cognitive, emotional and sensory brain processes. Brain oscillations form underlying mechanisms for such processes, and further, these processes can be modified by expertise. Human cortical oscillations are often analyzed with linear methods despite brain as a biological system is highly nonlinear. This study applies a relatively robust nonlinear method, Higuchi fractal dimension (HFD), to classify cortical oscillations of math experts and novices when they solve long and complex math demonstrations in an EEG laboratory. Brain imaging data, which is collected over a long time span during naturalistic stimuli, enables the application of data-driven analyses. Therefore, we also explore the neural signature of math expertise with machine learning algorithms. There is a need for novel methodologies in analyzing naturalistic data because formulation of theories of the brain functions in the real world based on reductionist and simplified study designs is both challenging and questionable. Data-driven intelligent approaches may be helpful in developing and testing new theories on complex brain functions. Our results clarify the different neural signature, analyzed by HFD, of math experts and novices during complex math and suggest machine learning as a promising data-driven approach to understand the brain processes in expertise and mathematical cognition.
Blind Asynchronous Over-the-Air Federated Edge Learning
Oct 31, 2022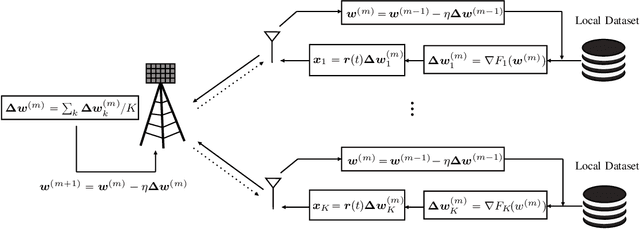

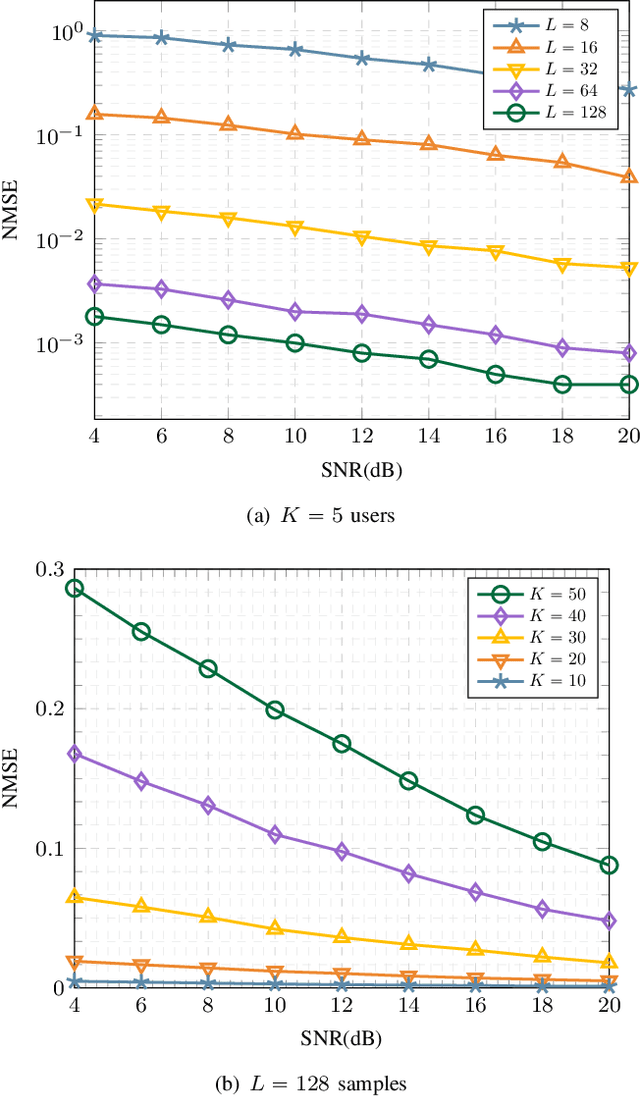
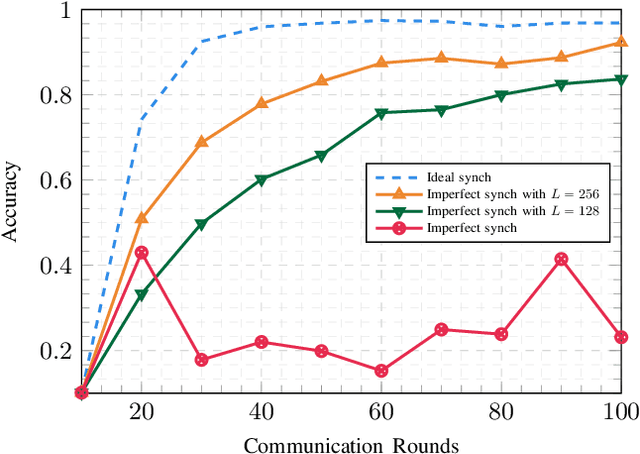
Federated Edge Learning (FEEL) is a distributed machine learning technique where each device contributes to training a global inference model by independently performing local computations with their data. More recently, FEEL has been merged with over-the-air computation (OAC), where the global model is calculated over the air by leveraging the superposition of analog signals. However, when implementing FEEL with OAC, there is the challenge on how to precode the analog signals to overcome any time misalignment at the receiver. In this work, we propose a novel synchronization-free method to recover the parameters of the global model over the air without requiring any prior information about the time misalignments. For that, we construct a convex optimization based on the norm minimization problem to directly recover the global model by solving a convex semi-definite program. The performance of the proposed method is evaluated in terms of accuracy and convergence via numerical experiments. We show that our proposed algorithm is close to the ideal synchronized scenario by $10\%$, and performs $4\times$ better than the simple case where no recovering method is used.
Towards Real-time Traffic Sign and Traffic Light Detection on Embedded Systems
May 05, 2022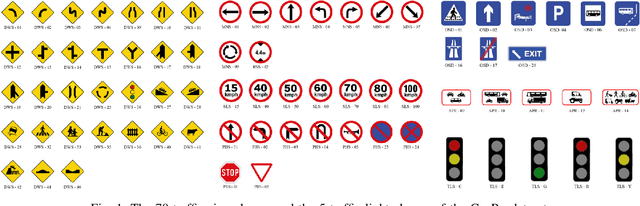
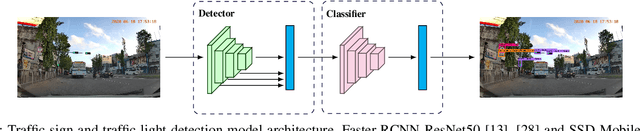


Recent work done on traffic sign and traffic light detection focus on improving detection accuracy in complex scenarios, yet many fail to deliver real-time performance, specifically with limited computational resources. In this work, we propose a simple deep learning based end-to-end detection framework, which effectively tackles challenges inherent to traffic sign and traffic light detection such as small size, large number of classes and complex road scenarios. We optimize the detection models using TensorRT and integrate with Robot Operating System to deploy on an Nvidia Jetson AGX Xavier as our embedded device. The overall system achieves a high inference speed of 63 frames per second, demonstrating the capability of our system to perform in real-time. Furthermore, we introduce CeyRo, which is the first ever large-scale traffic sign and traffic light detection dataset for the Sri Lankan context. Our dataset consists of 7984 total images with 10176 traffic sign and traffic light instances covering 70 traffic sign and 5 traffic light classes. The images have a high resolution of 1920 x 1080 and capture a wide range of challenging road scenarios with different weather and lighting conditions. Our work is publicly available at https://github.com/oshadajay/CeyRo.
Long-Lived Accurate Keypoints in Event Streams
Oct 07, 2022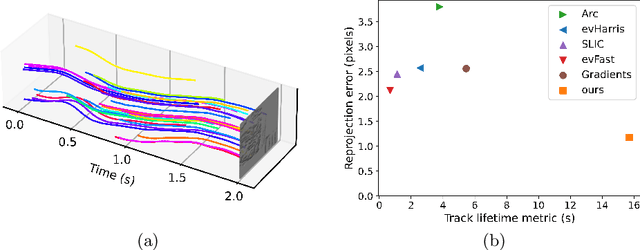
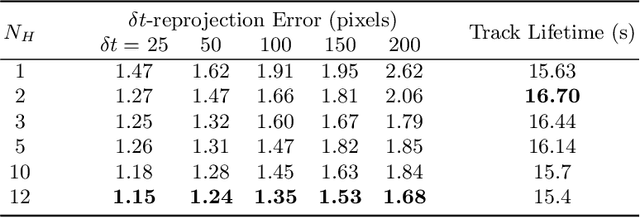
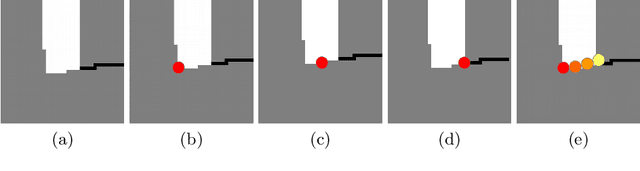
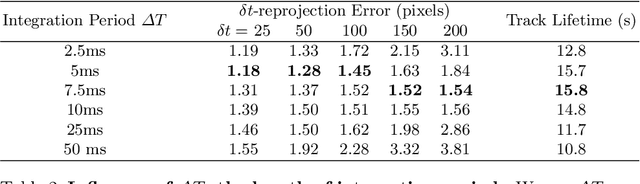
We present a novel end-to-end approach to keypoint detection and tracking in an event stream that provides better precision and much longer keypoint tracks than previous methods. This is made possible by two contributions working together. First, we propose a simple procedure to generate stable keypoint labels, which we use to train a recurrent architecture. This training data results in detections that are very consistent over time. Moreover, we observe that previous methods for keypoint detection work on a representation (such as the time surface) that integrates events over a period of time. Since this integration is required, we claim it is better to predict the keypoints' trajectories for the time period rather than single locations, as done in previous approaches. We predict these trajectories in the form of a series of heatmaps for the integration time period. This improves the keypoint localization. Our architecture can also be kept very simple, which results in very fast inference times. We demonstrate our approach on the HVGA ATIS Corner dataset as well as "The Event-Camera Dataset and Simulator" dataset, and show it results in keypoint tracks that are three times longer and nearly twice as accurate as the best previous state-of-the-art methods. We believe our approach can be generalized to other event-based camera problems, and we release our source code to encourage other authors to explore it.