 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Superpoint Transformer for 3D Scene Instance Segmentation
Nov 28, 2022
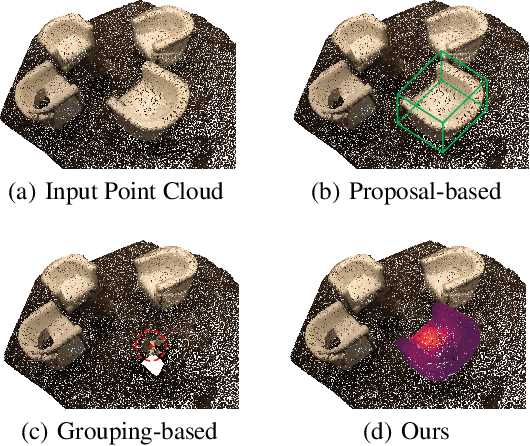
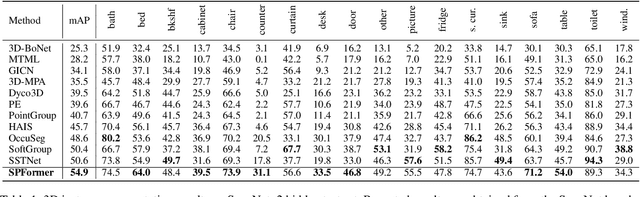
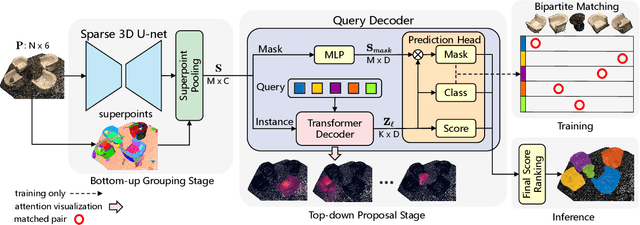
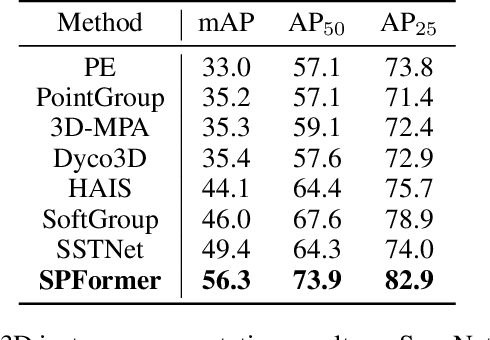
Most existing methods realize 3D instance segmentation by extending those models used for 3D object detection or 3D semantic segmentation. However, these non-straightforward methods suffer from two drawbacks: 1) Imprecise bounding boxes or unsatisfactory semantic predictions limit the performance of the overall 3D instance segmentation framework. 2) Existing method requires a time-consuming intermediate step of aggregation. To address these issues, this paper proposes a novel end-to-end 3D instance segmentation method based on Superpoint Transformer, named as SPFormer. It groups potential features from point clouds into superpoints, and directly predicts instances through query vectors without relying on the results of object detection or semantic segmentation. The key step in this framework is a novel query decoder with transformers that can capture the instance information through the superpoint cross-attention mechanism and generate the superpoint masks of the instances. Through bipartite matching based on superpoint masks, SPFormer can implement the network training without the intermediate aggregation step, which accelerates the network. Extensive experiments on ScanNetv2 and S3DIS benchmarks verify that our method is concise yet efficient. Notably, SPFormer exceeds compared state-of-the-art methods by 4.3% on ScanNetv2 hidden test set in terms of mAP and keeps fast inference speed (247ms per frame) simultaneously. Code is available at https://github.com/sunjiahao1999/SPFormer.
Taming Hyperparameter Tuning in Continuous Normalizing Flows Using the JKO Scheme
Nov 30, 2022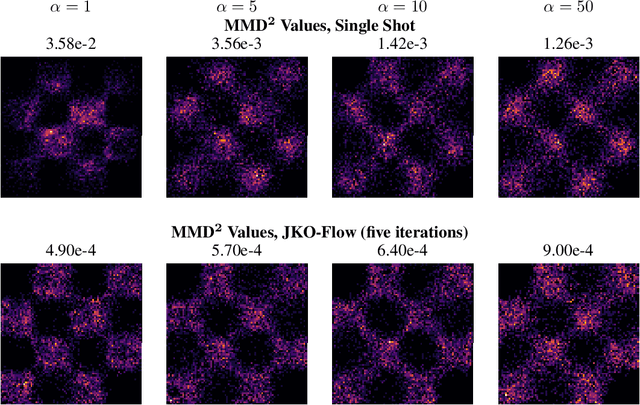
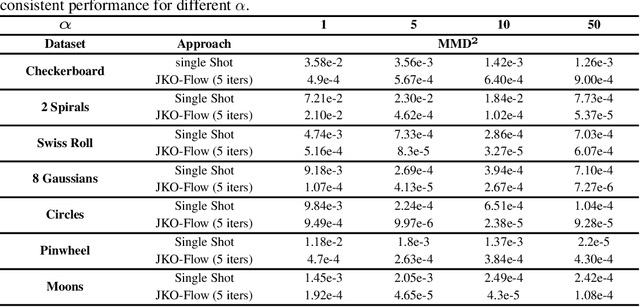

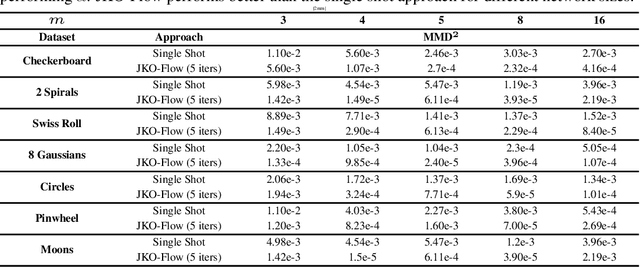
A normalizing flow (NF) is a mapping that transforms a chosen probability distribution to a normal distribution. Such flows are a common technique used for data generation and density estimation in machine learning and data science. The density estimate obtained with a NF requires a change of variables formula that involves the computation of the Jacobian determinant of the NF transformation. In order to tractably compute this determinant, continuous normalizing flows (CNF) estimate the mapping and its Jacobian determinant using a neural ODE. Optimal transport (OT) theory has been successfully used to assist in finding CNFs by formulating them as OT problems with a soft penalty for enforcing the standard normal distribution as a target measure. A drawback of OT-based CNFs is the addition of a hyperparameter, $\alpha$, that controls the strength of the soft penalty and requires significant tuning. We present JKO-Flow, an algorithm to solve OT-based CNF without the need of tuning $\alpha$. This is achieved by integrating the OT CNF framework into a Wasserstein gradient flow framework, also known as the JKO scheme. Instead of tuning $\alpha$, we repeatedly solve the optimization problem for a fixed $\alpha$ effectively performing a JKO update with a time-step $\alpha$. Hence we obtain a "divide and conquer" algorithm by repeatedly solving simpler problems instead of solving a potentially harder problem with large $\alpha$.
How to Train an Accurate and Efficient Object Detection Model on Any Dataset
Nov 30, 2022
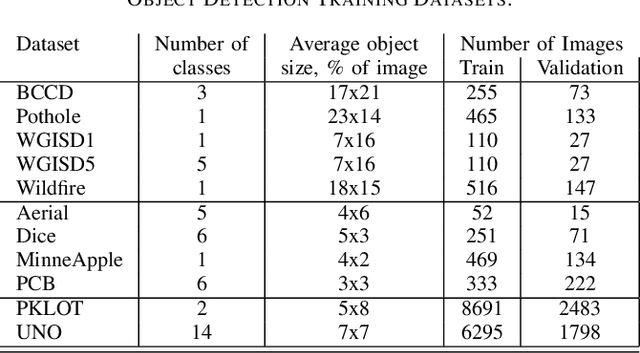
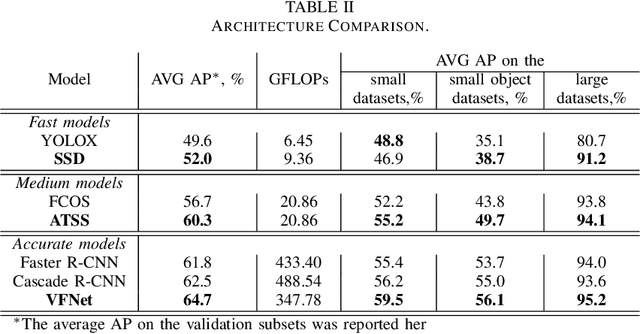
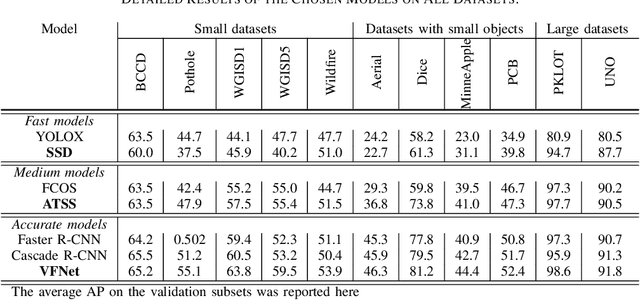
The rapidly evolving industry demands high accuracy of the models without the need for time-consuming and computationally expensive experiments required for fine-tuning. Moreover, a model and training pipeline, which was once carefully optimized for a specific dataset, rarely generalizes well to training on a different dataset. This makes it unrealistic to have carefully fine-tuned models for each use case. To solve this, we propose an alternative approach that also forms a backbone of Intel Geti platform: a dataset-agnostic template for object detection trainings, consisting of carefully chosen and pre-trained models together with a robust training pipeline for further training. Our solution works out-of-the-box and provides a strong baseline on a wide range of datasets. It can be used on its own or as a starting point for further fine-tuning for specific use cases when needed. We obtained dataset-agnostic templates by performing parallel training on a corpus of datasets and optimizing the choice of architectures and training tricks with respect to the average results on the whole corpora. We examined a number of architectures, taking into account the performance-accuracy trade-off. Consequently, we propose 3 finalists, VFNet, ATSS, and SSD, that can be deployed on CPU using the OpenVINO toolkit. The source code is available as a part of the OpenVINO Training Extensions (https://github.com/openvinotoolkit/training_extensions}
Automatic Discovery of Multi-perspective Process Model using Reinforcement Learning
Nov 30, 2022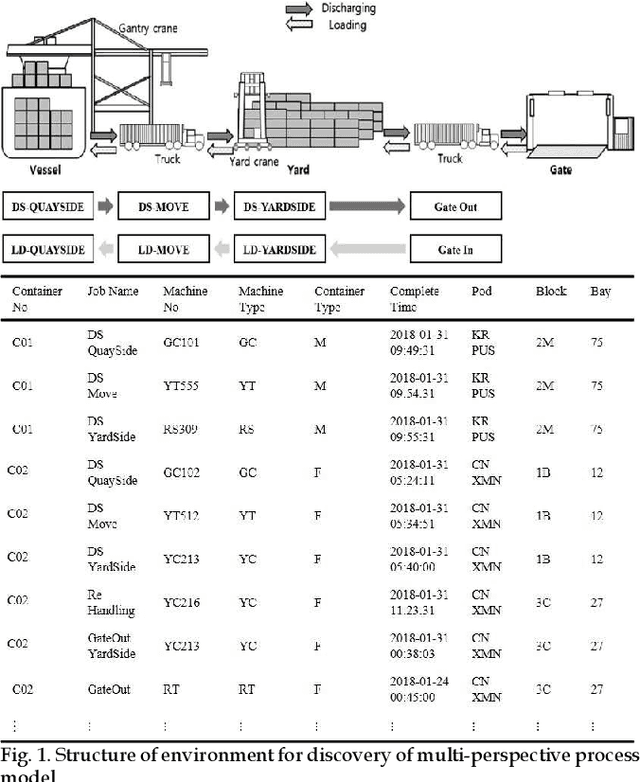
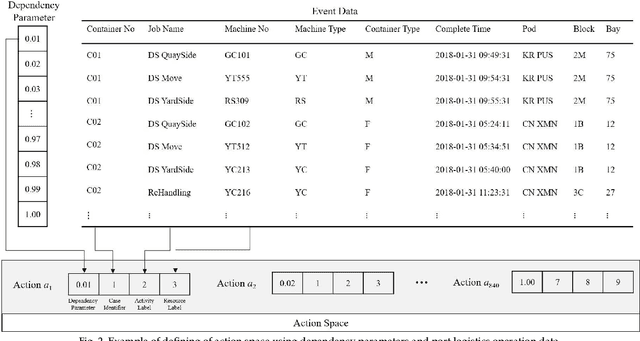
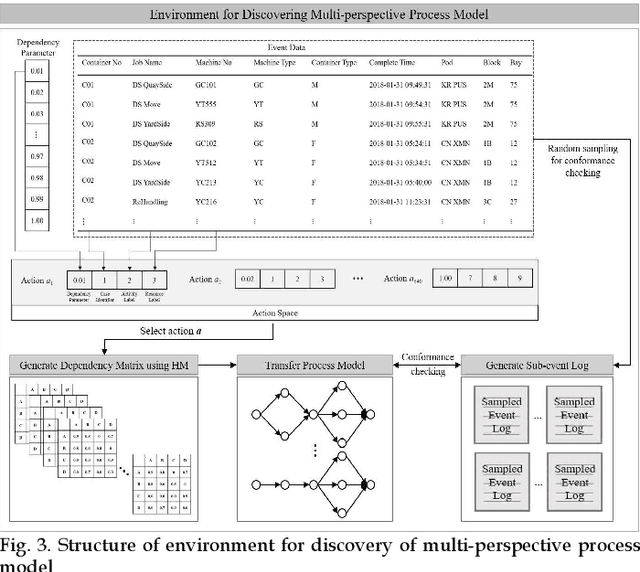
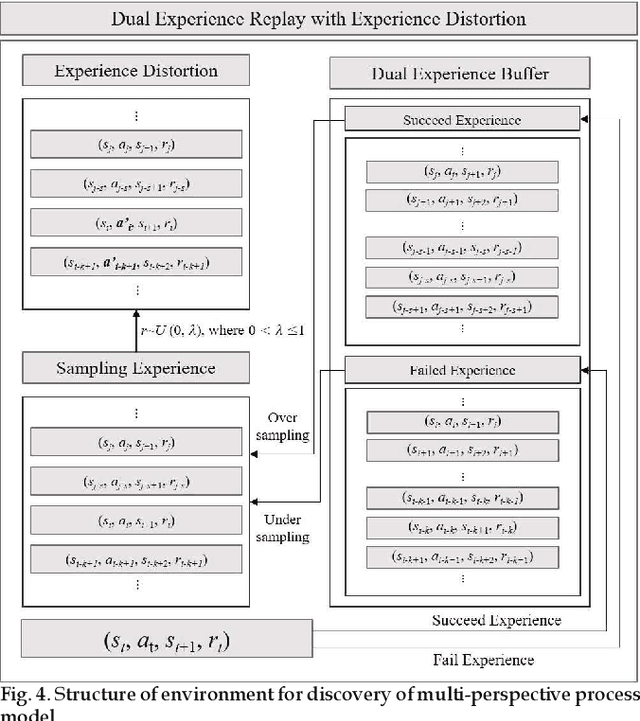
Process mining is a methodology for the derivation and analysis of process models based on the event log. When process mining is employed to analyze business processes, the process discovery step, the conformance checking step, and the enhancements step are repeated. If a user wants to analyze a process from multiple perspectives (such as activity perspectives, originator perspectives, and time perspectives), the above procedure, inconveniently, has to be repeated over and over again. Although past studies involving process mining have applied detailed stepwise methodologies, no attempt has been made to incorporate and optimize multi-perspective process mining procedures. This paper contributes to developing a solution approach to this problem. First, we propose an automatic discovery framework of a multi-perspective process model based on deep Q-Learning. Our Dual Experience Replay with Experience Distribution (DERED) approach can automatically perform process model discovery steps, conformance check steps, and enhancements steps. Second, we propose a new method that further optimizes the experience replay (ER) method, one of the key algorithms of deep Q-learning, to improve the learning performance of reinforcement learning agents. Finally, we validate our approach using six real-world event datasets collected in port logistics, steel manufacturing, finance, IT, and government administration. We show that our DERED approach can provide users with multi-perspective, high-quality process models that can be employed more conveniently for multi-perspective process mining.
SyncNet: Using Causal Convolutions and Correlating Objective for Time Delay Estimation in Audio Signals
Mar 28, 2022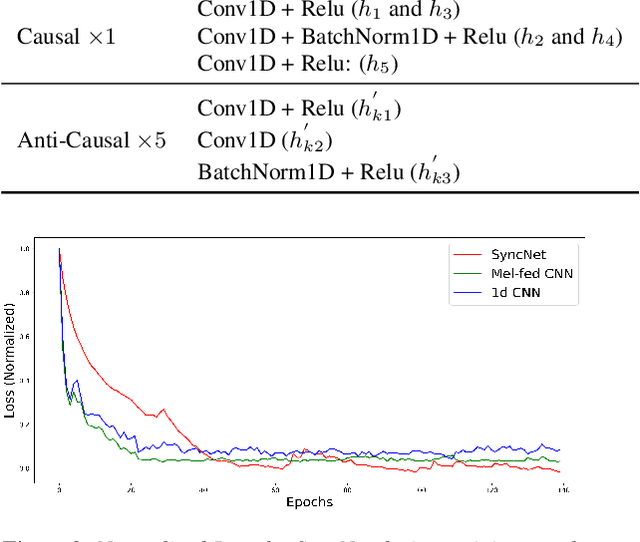
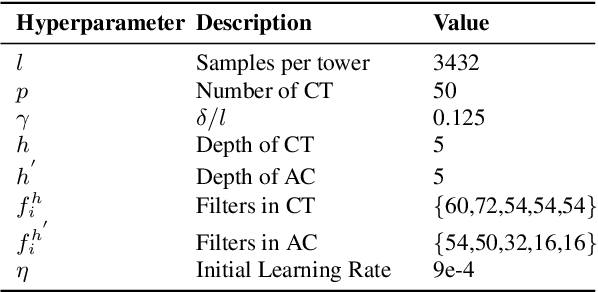
This paper addresses the task of performing robust and reliable time-delay estimation in audio-signals in noisy and reverberating environments. In contrast to the popular signal processing based methods, this paper proposes machine learning based method, i.e., a semi-causal convolutional neural network consisting of a set of causal and anti-causal layers with a novel correlation-based objective function. The causality in the network ensures non-leakage of representations from future time-intervals and the proposed loss function makes the network generate sequences with high correlation at the actual time delay. The proposed approach is also intrinsically interpretable as it does not lose time information. Even a shallow convolution network is able to capture local patterns in sequences, while also correlating them globally. SyncNet outperforms other classical approaches in estimating mutual time delays for different types of audio signals including pulse, speech and musical beats.
HRPose: Real-Time High-Resolution 6D Pose Estimation Network Using Knowledge Distillation
Apr 20, 2022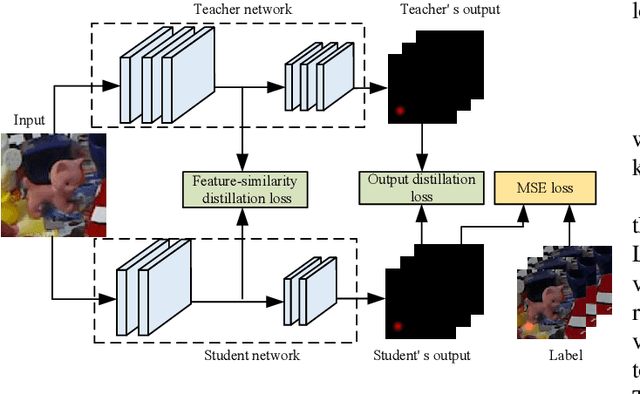
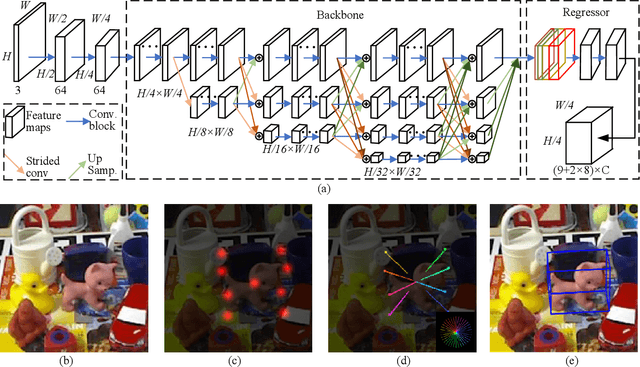


Real-time 6D object pose estimation is essential for many real-world applications, such as robotic grasping and augmented reality. To achieve an accurate object pose estimation from RGB images in real-time, we propose an effective and lightweight model, namely High-Resolution 6D Pose Estimation Network (HRPose). We adopt the efficient and small HRNetV2-W18 as a feature extractor to reduce computational burdens while generating accurate 6D poses. With only 33\% of the model size and lower computational costs, our HRPose achieves comparable performance compared with state-of-the-art models. Moreover, by transferring knowledge from a large model to our proposed HRPose through output and feature-similarity distillations, the performance of our HRPose is improved in effectiveness and efficiency. Numerical experiments on the widely-used benchmark LINEMOD demonstrate the superiority of our proposed HRPose against state-of-the-art methods.
Neural ODEs as Feedback Policies for Nonlinear Optimal Control
Oct 20, 2022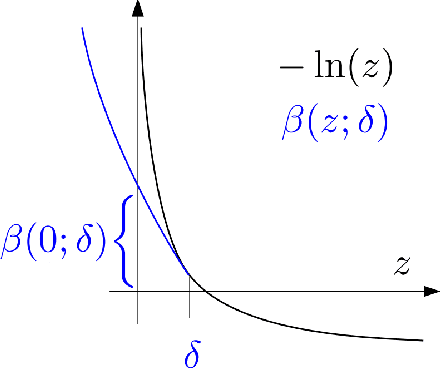
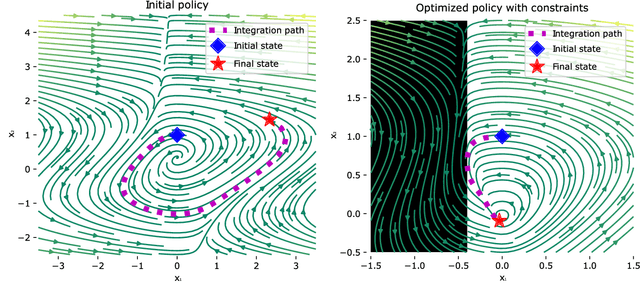
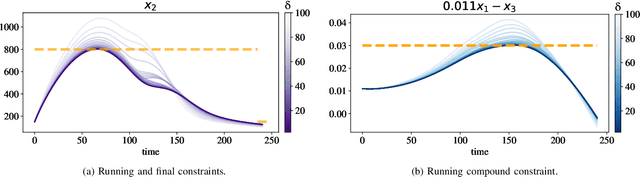

Neural ordinary differential equations (Neural ODEs) model continuous time dynamics as differential equations parametrized with neural networks. Thanks to their modeling flexibility, they have been adopted for multiple tasks where the continuous time nature of the process is specially relevant, as in system identification and time series analysis. When applied in a control setting, it is possible to adapt their use to approximate optimal nonlinear feedback policies. This formulation follows the same approach as policy gradients in reinforcement learning, covering the case where the environment consists of known deterministic dynamics given by a system of differential equations. The white box nature of the model specification allows the direct calculation of policy gradients through sensitivity analysis, avoiding the inexact and inefficient gradient estimation through sampling. In this work we propose the use of a neural control policy posed as a Neural ODE to solve general nonlinear optimal control problems while satisfying both state and control constraints, which are crucial for real world scenarios. Since the state feedback policy partially modifies the model dynamics, the whole space phase of the system is reshaped upon the optimization. This approach is a sensible approximation to the historically intractable closed loop solution of nonlinear control problems that efficiently exploits the availability of a dynamical system model.
Fair and Efficient Distributed Edge Learning with Hybrid Multipath TCP
Nov 03, 2022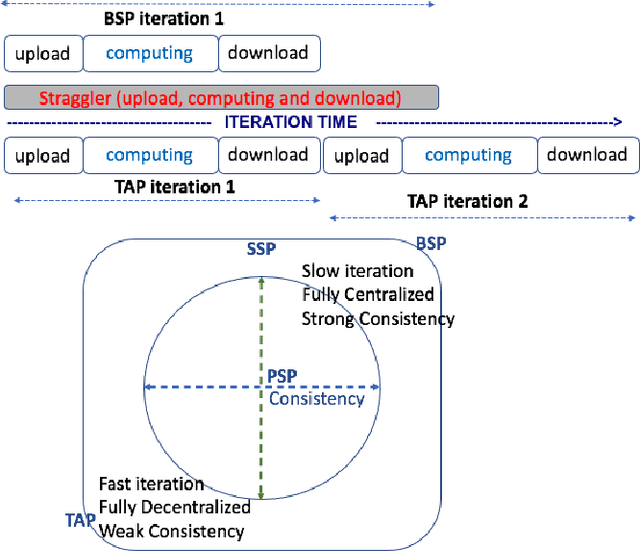
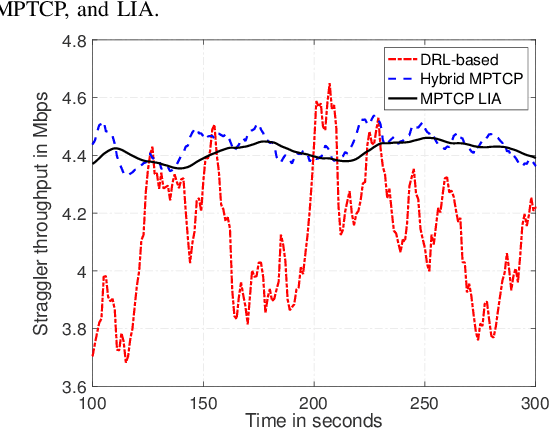
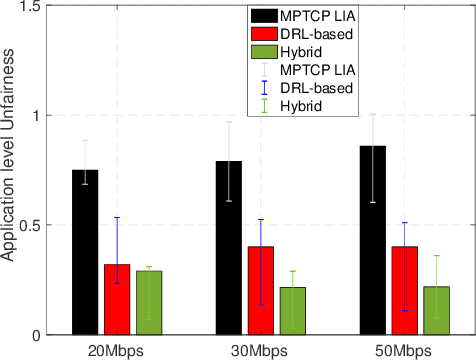
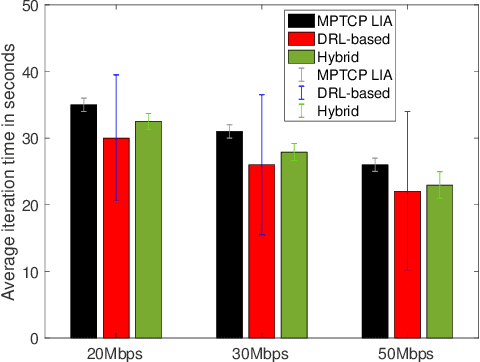
The bottleneck of distributed edge learning (DEL) over wireless has shifted from computing to communication, primarily the aggregation-averaging (Agg-Avg) process of DEL. The existing transmission control protocol (TCP)-based data networking schemes for DEL are application-agnostic and fail to deliver adjustments according to application layer requirements. As a result, they introduce massive excess time and undesired issues such as unfairness and stragglers. Other prior mitigation solutions have significant limitations as they balance data flow rates from workers across paths but often incur imbalanced backlogs when the paths exhibit variance, causing stragglers. To facilitate a more productive DEL, we develop a hybrid multipath TCP (MPTCP) by combining model-based and deep reinforcement learning (DRL) based MPTCP for DEL that strives to realize quicker iteration of DEL and better fairness (by ameliorating stragglers). Hybrid MPTCP essentially integrates two radical TCP developments: i) successful existing model-based MPTCP control strategies and ii) advanced emerging DRL-based techniques, and introduces a novel hybrid MPTCP data transport for easing the communication of the Agg-Avg process. Extensive emulation results demonstrate that the proposed hybrid MPTCP can overcome excess time consumption and ameliorate the application layer unfairness of DEL effectively without injecting additional inconstancy and stragglers.
Certifying Fairness of Probabilistic Circuits
Dec 05, 2022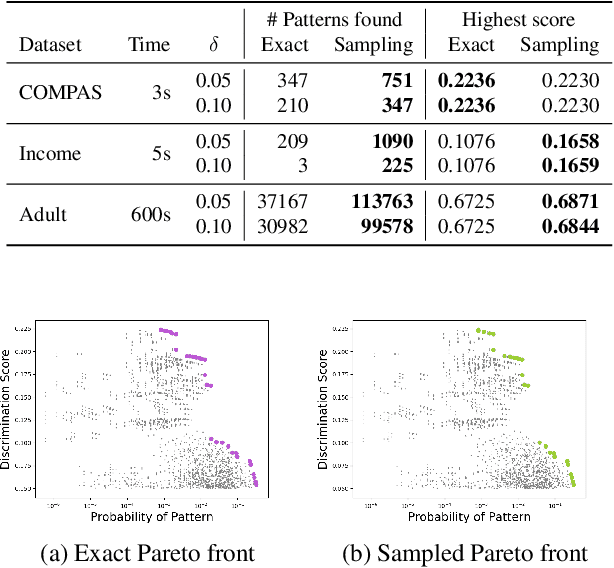
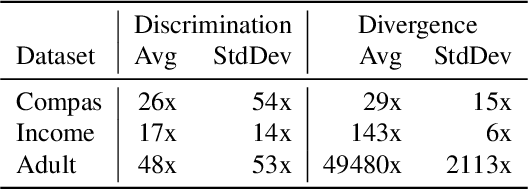
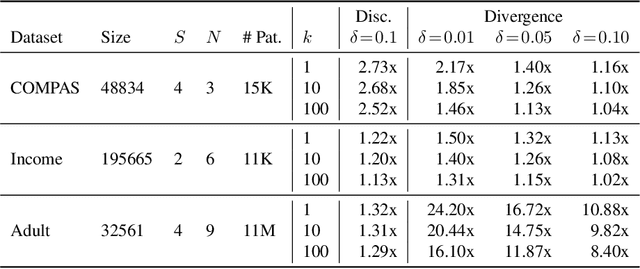
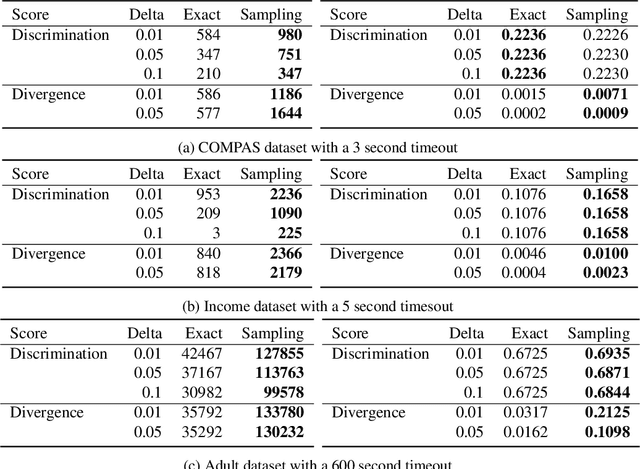
With the increased use of machine learning systems for decision making, questions about the fairness properties of such systems start to take center stage. Most existing work on algorithmic fairness assume complete observation of features at prediction time, as is the case for popular notions like statistical parity and equal opportunity. However, this is not sufficient for models that can make predictions with partial observation as we could miss patterns of bias and incorrectly certify a model to be fair. To address this, a recently introduced notion of fairness asks whether the model exhibits any discrimination pattern, in which an individual characterized by (partial) feature observations, receives vastly different decisions merely by disclosing one or more sensitive attributes such as gender and race. By explicitly accounting for partial observations, this provides a much more fine-grained notion of fairness. In this paper, we propose an algorithm to search for discrimination patterns in a general class of probabilistic models, namely probabilistic circuits. Previously, such algorithms were limited to naive Bayes classifiers which make strong independence assumptions; by contrast, probabilistic circuits provide a unifying framework for a wide range of tractable probabilistic models and can even be compiled from certain classes of Bayesian networks and probabilistic programs, making our method much more broadly applicable. Furthermore, for an unfair model, it may be useful to quickly find discrimination patterns and distill them for better interpretability. As such, we also propose a sampling-based approach to more efficiently mine discrimination patterns, and introduce new classes of patterns such as minimal, maximal, and Pareto optimal patterns that can effectively summarize exponentially many discrimination patterns
WAIR-D: Wireless AI Research Dataset
Dec 05, 2022
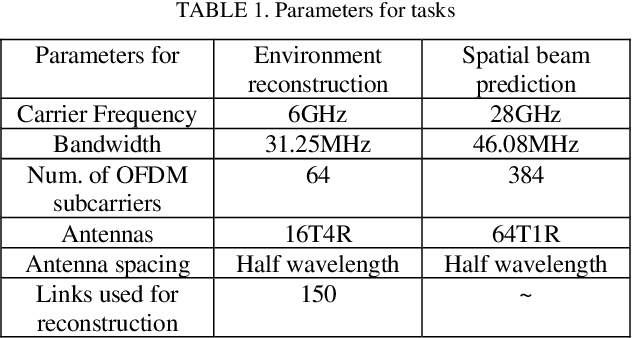

It is a common sense that datasets with high-quality data samples play an important role in artificial intelligence (AI), machine learning (ML) and related studies. However, although AI/ML has been introduced in wireless researches long time ago, few datasets are commonly used in the research community. Without a common dataset, AI-based methods proposed for wireless systems are hard to compare with both the traditional baselines and even each other. The existing wireless AI researches usually rely on datasets generated based on statistical models or ray-tracing simulations with limited environments. The statistical data hinder the trained AI models from further fine-tuning for a specific scenario, and ray-tracing data with limited environments lower down the generalization capability of the trained AI models. In this paper, we present the Wireless AI Research Dataset (WAIR-D)1, which consists of two scenarios. Scenario 1 contains 10,000 environments with sparsely dropped user equipments (UEs), and Scenario 2 contains 100 environments with densely dropped UEs. The environments are randomly picked up from more than 40 cities in the real world map. The large volume of the data guarantees that the trained AI models enjoy good generalization capability, while fine-tuning can be easily carried out on a specific chosen environment. Moreover, both the wireless channels and the corresponding environmental information are provided in WAIR-D, so that extra-information-aided communication mechanism can be designed and evaluated. WAIR-D provides the researchers benchmarks to compare their different designs or reproduce results of others. In this paper, we show the detailed construction of this dataset and examples of using it.