 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Semi-Supervised U-statistics
Mar 09, 2024
Semi-supervised datasets are ubiquitous across diverse domains where obtaining fully labeled data is costly or time-consuming. The prevalence of such datasets has consistently driven the demand for new tools and methods that exploit the potential of unlabeled data. Responding to this demand, we introduce semi-supervised U-statistics enhanced by the abundance of unlabeled data, and investigate their statistical properties. We show that the proposed approach is asymptotically Normal and exhibits notable efficiency gains over classical U-statistics by effectively integrating various powerful prediction tools into the framework. To understand the fundamental difficulty of the problem, we derive minimax lower bounds in semi-supervised settings and showcase that our procedure is semi-parametrically efficient under regularity conditions. Moreover, tailored to bivariate kernels, we propose a refined approach that outperforms the classical U-statistic across all degeneracy regimes, and demonstrate its optimality properties. Simulation studies are conducted to corroborate our findings and to further demonstrate our framework.
ClinicalMamba: A Generative Clinical Language Model on Longitudinal Clinical Notes
Mar 09, 2024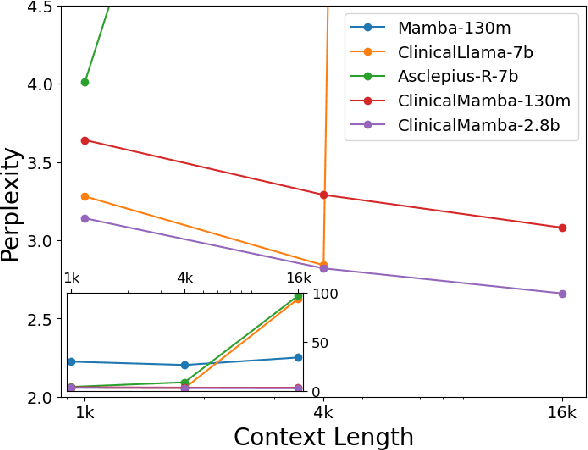
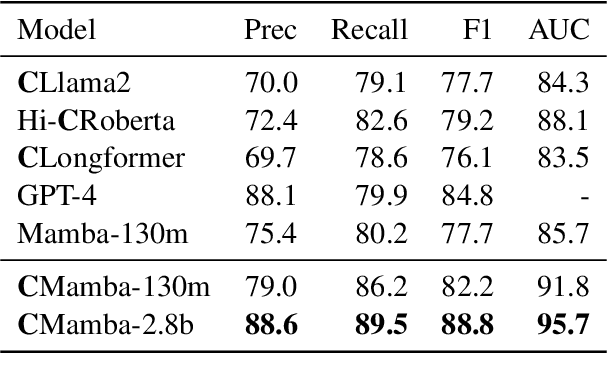
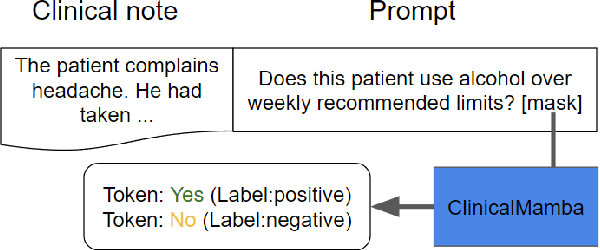
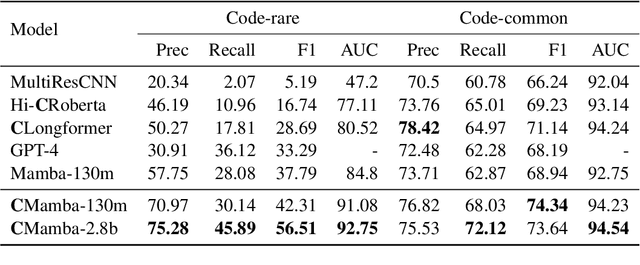
The advancement of natural language processing (NLP) systems in healthcare hinges on language model ability to interpret the intricate information contained within clinical notes. This process often requires integrating information from various time points in a patient's medical history. However, most earlier clinical language models were pretrained with a context length limited to roughly one clinical document. In this study, We introduce ClinicalMamba, a specialized version of the Mamba language model, pretrained on a vast corpus of longitudinal clinical notes to address the unique linguistic characteristics and information processing needs of the medical domain. ClinicalMamba, with 130 million and 2.8 billion parameters, demonstrates a superior performance in modeling clinical language across extended text lengths compared to Mamba and clinical Llama. With few-shot learning, ClinicalMamba achieves notable benchmarks in speed and accuracy, outperforming existing clinical language models and general domain large models like GPT-4 in longitudinal clinical notes information extraction tasks.
Algorithmic progress in language models
Mar 09, 2024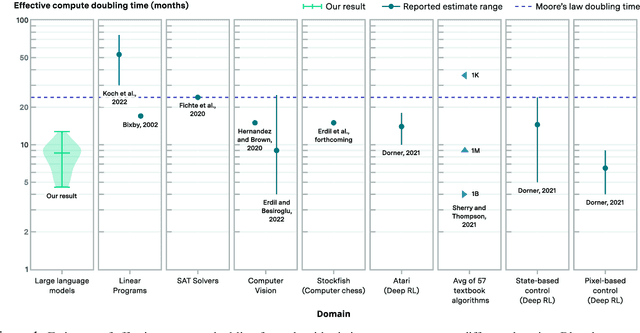
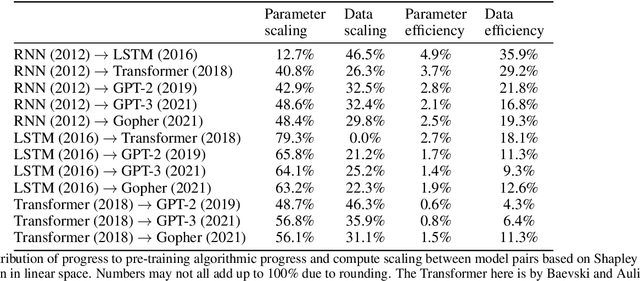
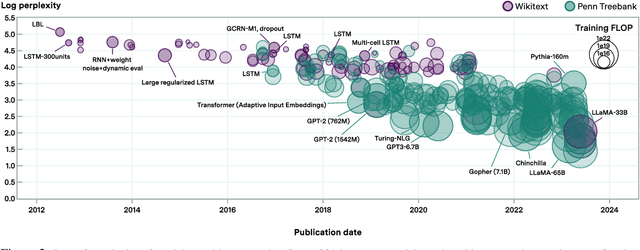

We investigate the rate at which algorithms for pre-training language models have improved since the advent of deep learning. Using a dataset of over 200 language model evaluations on Wikitext and Penn Treebank spanning 2012-2023, we find that the compute required to reach a set performance threshold has halved approximately every 8 months, with a 95% confidence interval of around 5 to 14 months, substantially faster than hardware gains per Moore's Law. We estimate augmented scaling laws, which enable us to quantify algorithmic progress and determine the relative contributions of scaling models versus innovations in training algorithms. Despite the rapid pace of algorithmic progress and the development of new architectures such as the transformer, our analysis reveals that the increase in compute made an even larger contribution to overall performance improvements over this time period. Though limited by noisy benchmark data, our analysis quantifies the rapid progress in language modeling, shedding light on the relative contributions from compute and algorithms.
Variational Continual Test-Time Adaptation
Feb 13, 2024The prior drift is crucial in Continual Test-Time Adaptation (CTTA) methods that only use unlabeled test data, as it can cause significant error propagation. In this paper, we introduce VCoTTA, a variational Bayesian approach to measure uncertainties in CTTA. At the source stage, we transform a pre-trained deterministic model into a Bayesian Neural Network (BNN) via a variational warm-up strategy, injecting uncertainties into the model. During the testing time, we employ a mean-teacher update strategy using variational inference for the student model and exponential moving average for the teacher model. Our novel approach updates the student model by combining priors from both the source and teacher models. The evidence lower bound is formulated as the cross-entropy between the student and teacher models, along with the Kullback-Leibler (KL) divergence of the prior mixture. Experimental results on three datasets demonstrate the method's effectiveness in mitigating prior drift within the CTTA framework.
Day-ahead regional solar power forecasting with hierarchical temporal convolutional neural networks using historical power generation and weather data
Mar 04, 2024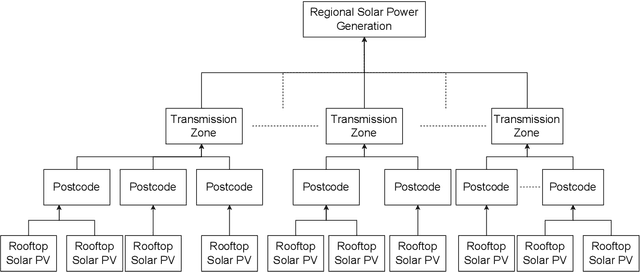
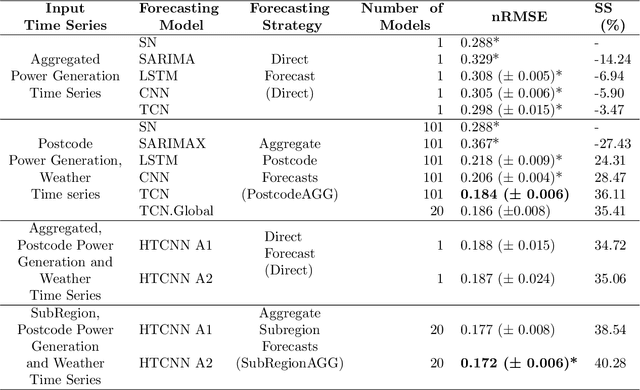
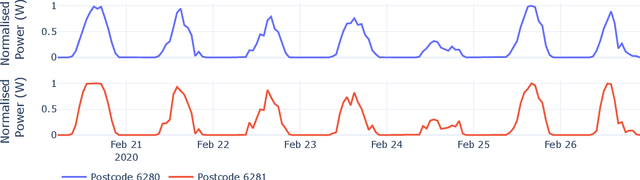
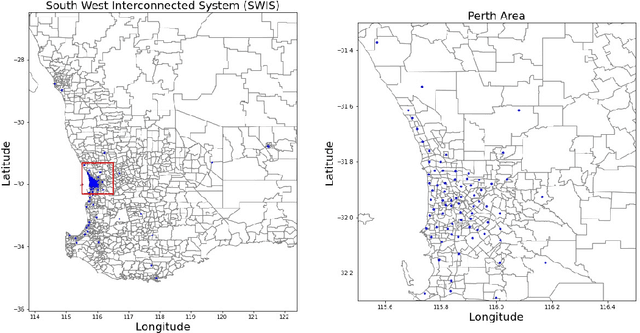
Regional solar power forecasting, which involves predicting the total power generation from all rooftop photovoltaic systems in a region holds significant importance for various stakeholders in the energy sector. However, the vast amount of solar power generation and weather time series from geographically dispersed locations that need to be considered in the forecasting process makes accurate regional forecasting challenging. Therefore, previous work has limited the focus to either forecasting a single time series (i.e., aggregated time series) which is the addition of all solar generation time series in a region, disregarding the location-specific weather effects or forecasting solar generation time series of each PV site (i.e., individual time series) independently using location-specific weather data, resulting in a large number of forecasting models. In this work, we propose two deep-learning-based regional forecasting methods that can effectively leverage both types of time series (aggregated and individual) with weather data in a region. We propose two hierarchical temporal convolutional neural network architectures (HTCNN) and two strategies to adapt HTCNNs for regional solar power forecasting. At first, we explore generating a regional forecast using a single HTCNN. Next, we divide the region into multiple sub-regions based on weather information and train separate HTCNNs for each sub-region; the forecasts of each sub-region are then added to generate a regional forecast. The proposed work is evaluated using a large dataset collected over a year from 101 locations across Western Australia to provide a day ahead forecast. We compare our approaches with well-known alternative methods and show that the sub-region HTCNN requires fewer individual networks and achieves a forecast skill score of 40.2% reducing a statistically significant error by 6.5% compared to the best counterpart.
Protect and Extend -- Using GANs for Synthetic Data Generation of Time-Series Medical Records
Feb 21, 2024Preservation of private user data is of paramount importance for high Quality of Experience (QoE) and acceptability, particularly with services treating sensitive data, such as IT-based health services. Whereas anonymization techniques were shown to be prone to data re-identification, synthetic data generation has gradually replaced anonymization since it is relatively less time and resource-consuming and more robust to data leakage. Generative Adversarial Networks (GANs) have been used for generating synthetic datasets, especially GAN frameworks adhering to the differential privacy phenomena. This research compares state-of-the-art GAN-based models for synthetic data generation to generate time-series synthetic medical records of dementia patients which can be distributed without privacy concerns. Predictive modeling, autocorrelation, and distribution analysis are used to assess the Quality of Generating (QoG) of the generated data. The privacy preservation of the respective models is assessed by applying membership inference attacks to determine potential data leakage risks. Our experiments indicate the superiority of the privacy-preserving GAN (PPGAN) model over other models regarding privacy preservation while maintaining an acceptable level of QoG. The presented results can support better data protection for medical use cases in the future.
Comparison of gait phase detection using traditional machine learning and deep learning techniques
Mar 07, 2024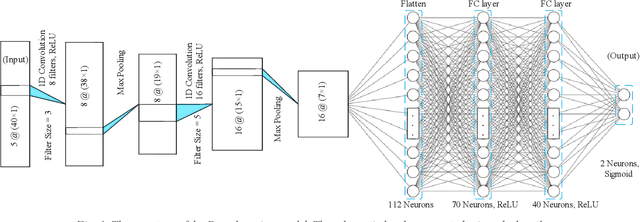
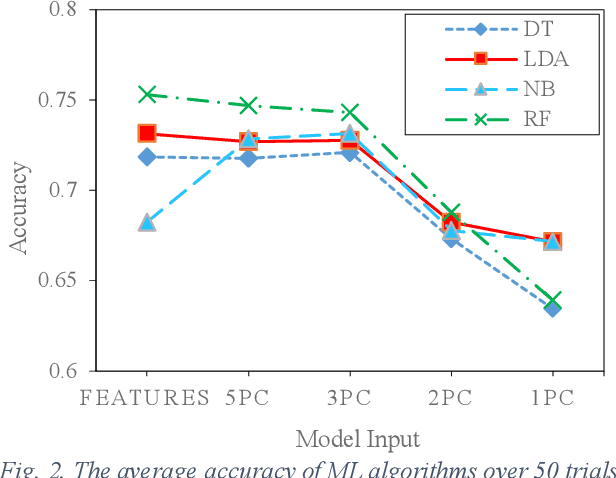
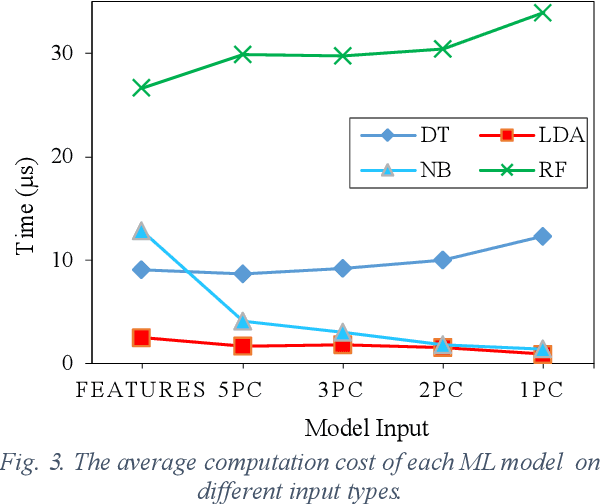
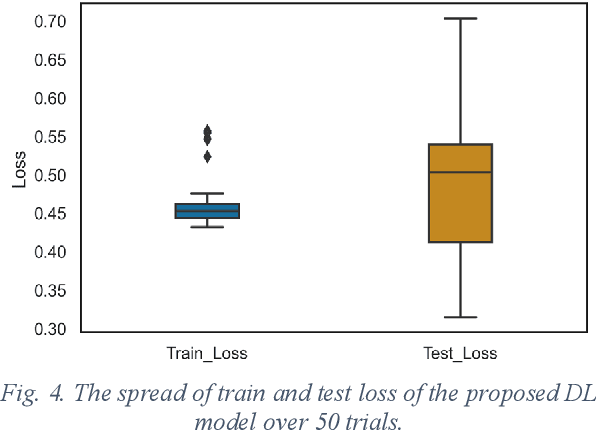
Human walking is a complex activity with a high level of cooperation and interaction between different systems in the body. Accurate detection of the phases of the gait in real-time is crucial to control lower-limb assistive devices like exoskeletons and prostheses. There are several ways to detect the walking gait phase, ranging from cameras and depth sensors to the sensors attached to the device itself or the human body. Electromyography (EMG) is one of the input methods that has captured lots of attention due to its precision and time delay between neuromuscular activity and muscle movement. This study proposes a few Machine Learning (ML) based models on lower-limb EMG data for human walking. The proposed models are based on Gaussian Naive Bayes (NB), Decision Tree (DT), Random Forest (RF), Linear Discriminant Analysis (LDA) and Deep Convolutional Neural Networks (DCNN). The traditional ML models are trained on hand-crafted features or their reduced components using Principal Component Analysis (PCA). On the contrary, the DCNN model utilises convolutional layers to extract features from raw data. The results show up to 75% average accuracy for traditional ML models and 79% for Deep Learning (DL) model. The highest achieved accuracy in 50 trials of the training DL model is 89.5%.
* Copyright \c{opyright} This is the accepted version of an article published in the proceedings of the 2022 IEEE International Conference on Systems, Man, and Cybernetics (SMC)
Lightator: An Optical Near-Sensor Accelerator with Compressive Acquisition Enabling Versatile Image Processing
Mar 08, 2024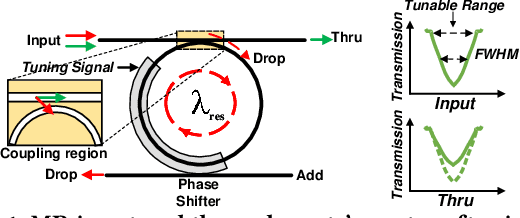
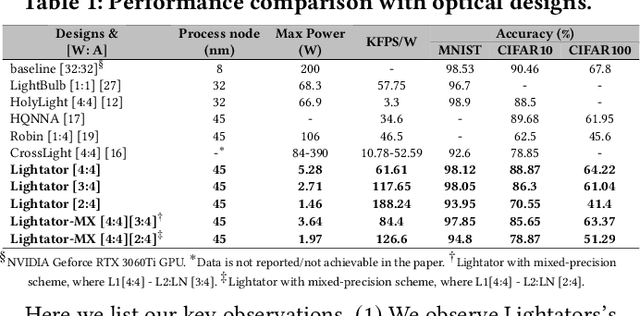
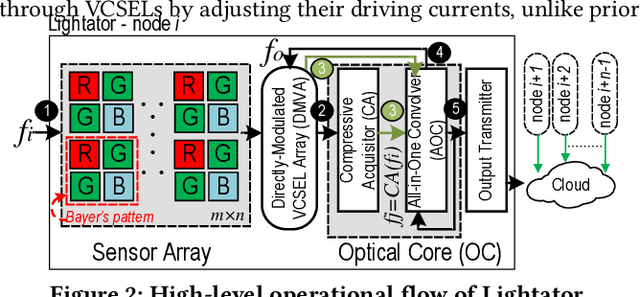
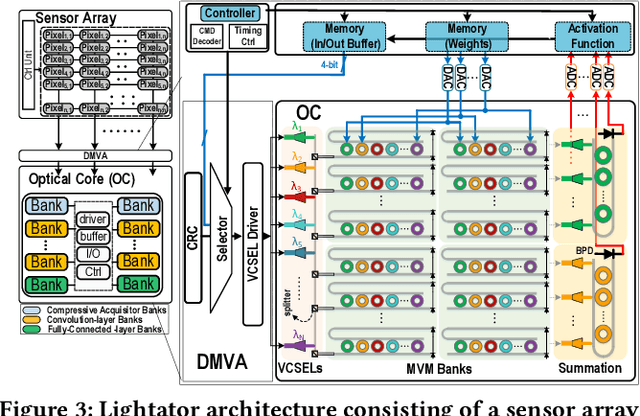
This paper proposes a high-performance and energy-efficient optical near-sensor accelerator for vision applications, called Lightator. Harnessing the promising efficiency offered by photonic devices, Lightator features innovative compressive acquisition of input frames and fine-grained convolution operations for low-power and versatile image processing at the edge for the first time. This will substantially diminish the energy consumption and latency of conversion, transmission, and processing within the established cloud-centric architecture as well as recently designed edge accelerators. Our device-to-architecture simulation results show that with favorable accuracy, Lightator achieves 84.4 Kilo FPS/W and reduces power consumption by a factor of ~24x and 73x on average compared with existing photonic accelerators and GPU baseline.
Fish-inspired tracking of underwater turbulent plumes
Mar 10, 2024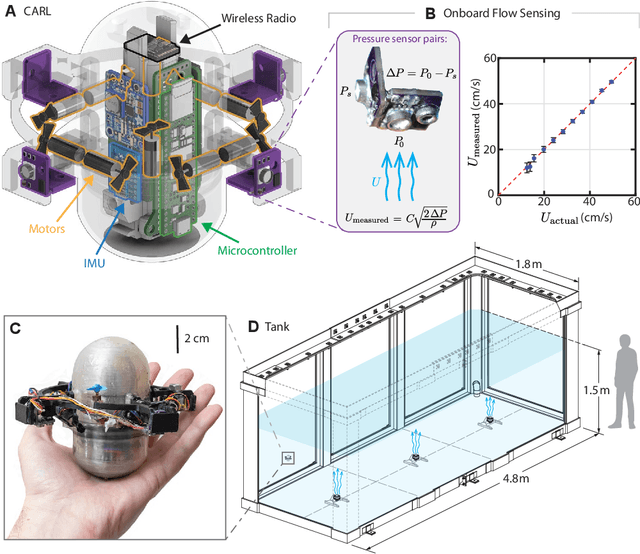
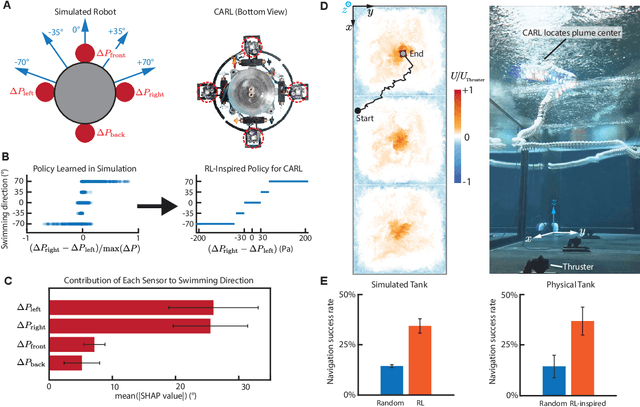
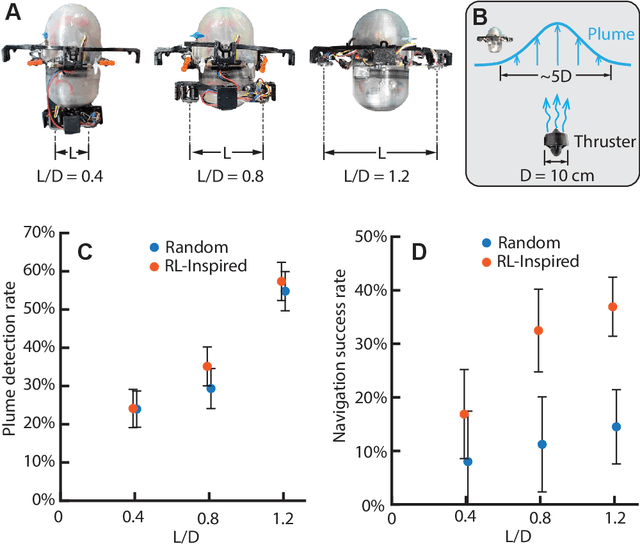
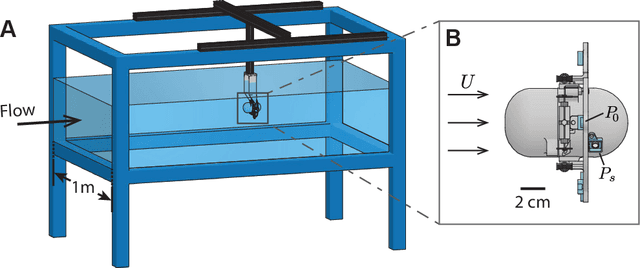
Autonomous ocean-exploring vehicles have begun to take advantage of onboard sensor measurements of water properties such as salinity and temperature to locate oceanic features in real time. Such targeted sampling strategies enable more rapid study of ocean environments by actively steering towards areas of high scientific value. Inspired by the ability of aquatic animals to navigate via flow sensing, this work investigates hydrodynamic cues for accomplishing targeted sampling using a palm-sized robotic swimmer. As proof-of-concept analogy for tracking hydrothermal vent plumes in the ocean, the robot is tasked with locating the center of turbulent jet flows in a 13,000-liter water tank using data from onboard pressure sensors. To learn a navigation strategy, we first implemented Reinforcement Learning (RL) on a simulated version of the robot navigating in proximity to turbulent jets. After training, the RL algorithm discovered an effective strategy for locating the jets by following transverse velocity gradients sensed by pressure sensors located on opposite sides of the robot. When implemented on the physical robot, this gradient following strategy enabled the robot to successfully locate the turbulent plumes at more than twice the rate of random searching. Additionally, we found that navigation performance improved as the distance between the pressure sensors increased, which can inform the design of distributed flow sensors in ocean robots. Our results demonstrate the effectiveness and limits of flow-based navigation for autonomously locating hydrodynamic features of interest.
Finding Visual Saliency in Continuous Spike Stream
Mar 10, 2024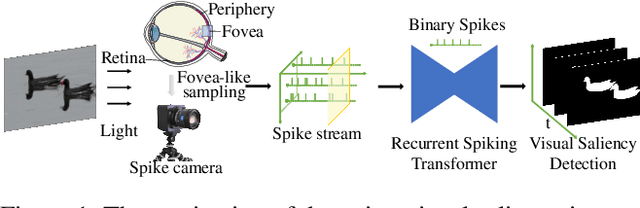
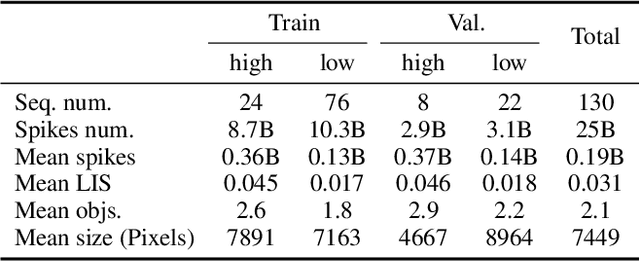
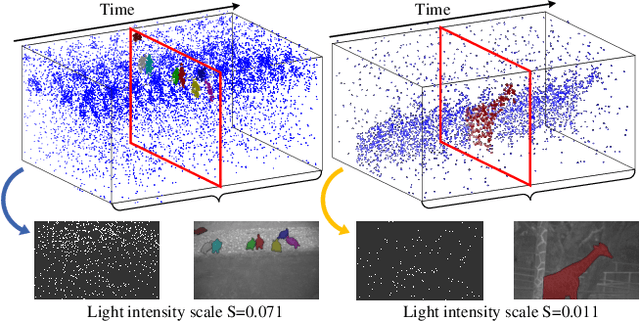
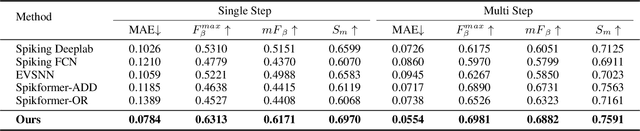
As a bio-inspired vision sensor, the spike camera emulates the operational principles of the fovea, a compact retinal region, by employing spike discharges to encode the accumulation of per-pixel luminance intensity. Leveraging its high temporal resolution and bio-inspired neuromorphic design, the spike camera holds significant promise for advancing computer vision applications. Saliency detection mimics the behavior of human beings and captures the most salient region from the scenes. In this paper, we investigate the visual saliency in the continuous spike stream for the first time. To effectively process the binary spike stream, we propose a Recurrent Spiking Transformer (RST) framework, which is based on a full spiking neural network. Our framework enables the extraction of spatio-temporal features from the continuous spatio-temporal spike stream while maintaining low power consumption. To facilitate the training and validation of our proposed model, we build a comprehensive real-world spike-based visual saliency dataset, enriched with numerous light conditions. Extensive experiments demonstrate the superior performance of our Recurrent Spiking Transformer framework in comparison to other spike neural network-based methods. Our framework exhibits a substantial margin of improvement in capturing and highlighting visual saliency in the spike stream, which not only provides a new perspective for spike-based saliency segmentation but also shows a new paradigm for full SNN-based transformer models. The code and dataset are available at \url{https://github.com/BIT-Vision/SVS}.