 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
YORO -- Lightweight End to End Visual Grounding
Nov 15, 2022
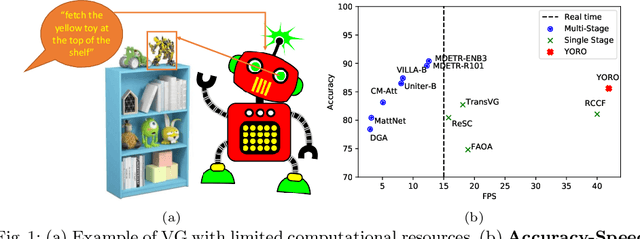
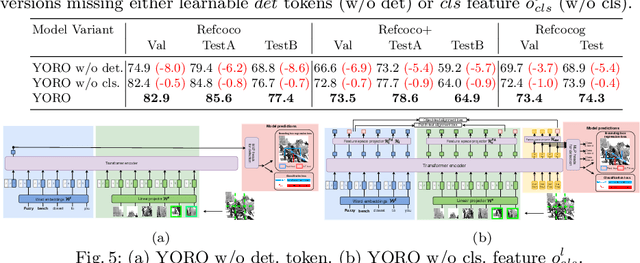
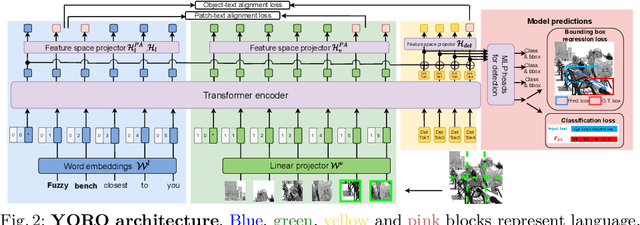

We present YORO - a multi-modal transformer encoder-only architecture for the Visual Grounding (VG) task. This task involves localizing, in an image, an object referred via natural language. Unlike the recent trend in the literature of using multi-stage approaches that sacrifice speed for accuracy, YORO seeks a better trade-off between speed an accuracy by embracing a single-stage design, without CNN backbone. YORO consumes natural language queries, image patches, and learnable detection tokens and predicts coordinates of the referred object, using a single transformer encoder. To assist the alignment between text and visual objects, a novel patch-text alignment loss is proposed. Extensive experiments are conducted on 5 different datasets with ablations on architecture design choices. YORO is shown to support real-time inference and outperform all approaches in this class (single-stage methods) by large margins. It is also the fastest VG model and achieves the best speed/accuracy trade-off in the literature.
Scene-to-Patch Earth Observation: Multiple Instance Learning for Land Cover Classification
Nov 15, 2022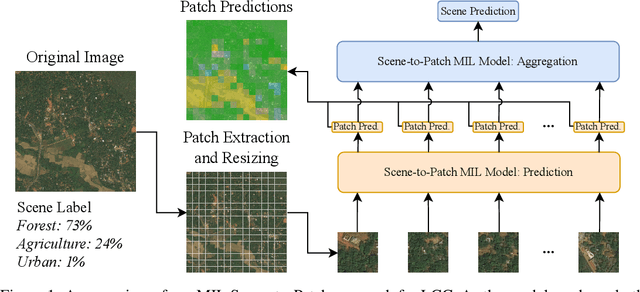
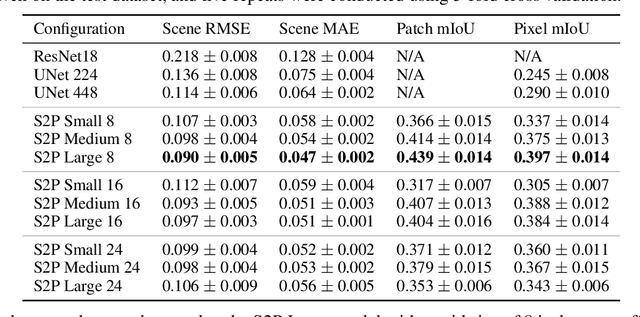
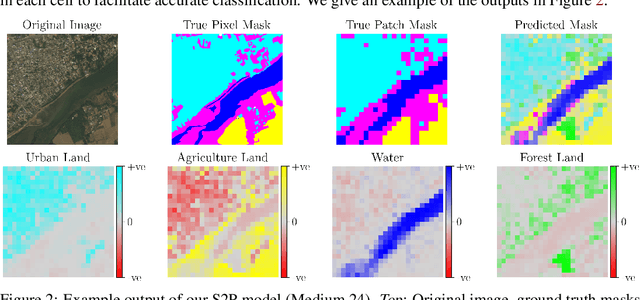
Land cover classification (LCC), and monitoring how land use changes over time, is an important process in climate change mitigation and adaptation. Existing approaches that use machine learning with Earth observation data for LCC rely on fully-annotated and segmented datasets. Creating these datasets requires a large amount of effort, and a lack of suitable datasets has become an obstacle in scaling the use of LCC. In this study, we propose Scene-to-Patch models: an alternative LCC approach utilising Multiple Instance Learning (MIL) that requires only high-level scene labels. This enables much faster development of new datasets whilst still providing segmentation through patch-level predictions, ultimately increasing the accessibility of using LCC for different scenarios. On the DeepGlobe-LCC dataset, our approach outperforms non-MIL baselines on both scene- and patch-level prediction. This work provides the foundation for expanding the use of LCC in climate change mitigation methods for technology, government, and academia.
Exploring the Joint Use of Rehearsal and Knowledge Distillation in Continual Learning for Spoken Language Understanding
Nov 15, 2022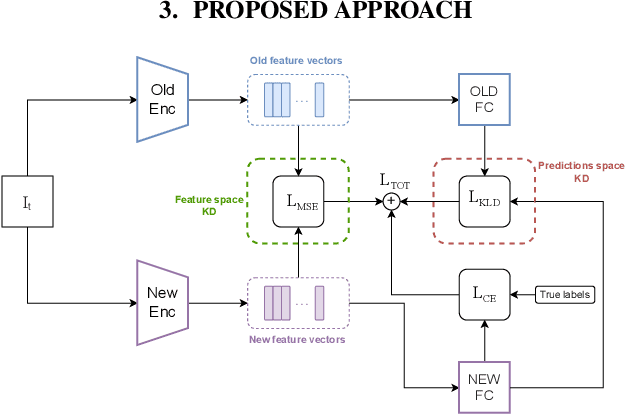

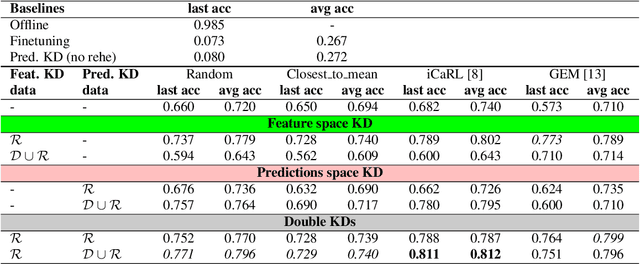
Continual learning refers to a dynamical framework in which a model or agent receives a stream of non-stationary data over time and must adapt to new data while preserving previously acquired knowledge. Unfortunately, deep neural networks fail to meet these two desiderata, incurring the so-called catastrophic forgetting phenomenon. Whereas a vast array of strategies have been proposed to attenuate forgetting in the computer vision domain, for speech-related tasks, on the other hand, there is a dearth of works. In this paper, we turn our attention toward the joint use of rehearsal and knowledge distillation (KD) approaches for spoken language understanding under a class-incremental learning scenario. We report on multiple KD combinations at different levels in the network, showing that combining feature-level and predictions-level KDs leads to the best results. Finally, we provide an ablation study on the effect of the size of the rehearsal memory that corroborates the appropriateness of our approach for low-resource devices.
Transform Once: Efficient Operator Learning in Frequency Domain
Nov 26, 2022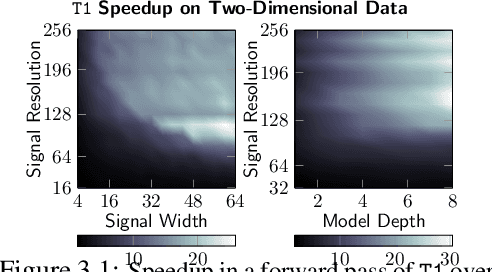
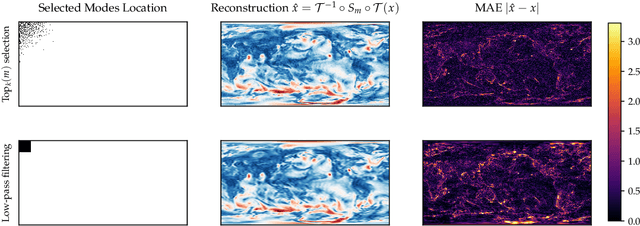
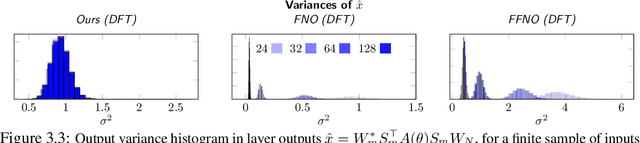
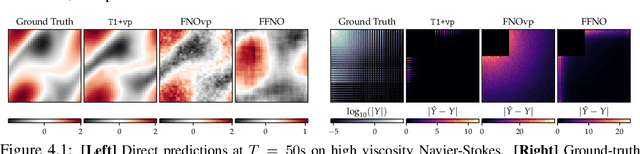
Spectral analysis provides one of the most effective paradigms for information-preserving dimensionality reduction, as simple descriptions of naturally occurring signals are often obtained via few terms of periodic basis functions. In this work, we study deep neural networks designed to harness the structure in frequency domain for efficient learning of long-range correlations in space or time: frequency-domain models (FDMs). Existing FDMs are based on complex-valued transforms i.e. Fourier Transforms (FT), and layers that perform computation on the spectrum and input data separately. This design introduces considerable computational overhead: for each layer, a forward and inverse FT. Instead, this work introduces a blueprint for frequency domain learning through a single transform: transform once (T1). To enable efficient, direct learning in the frequency domain we derive a variance-preserving weight initialization scheme and investigate methods for frequency selection in reduced-order FDMs. Our results noticeably streamline the design process of FDMs, pruning redundant transforms, and leading to speedups of 3x to 10x that increase with data resolution and model size. We perform extensive experiments on learning the solution operator of spatio-temporal dynamics, including incompressible Navier-Stokes, turbulent flows around airfoils and high-resolution video of smoke. T1 models improve on the test performance of FDMs while requiring significantly less computation (5 hours instead of 32 for our large-scale experiment), with over 20% reduction in average predictive error across tasks.
Beyond the Limitation of Pulse Width in Optical Time-domain Reflectometry
Mar 14, 2022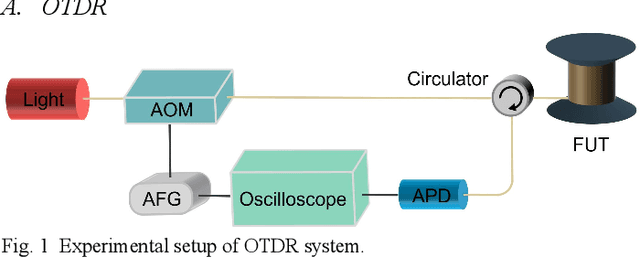
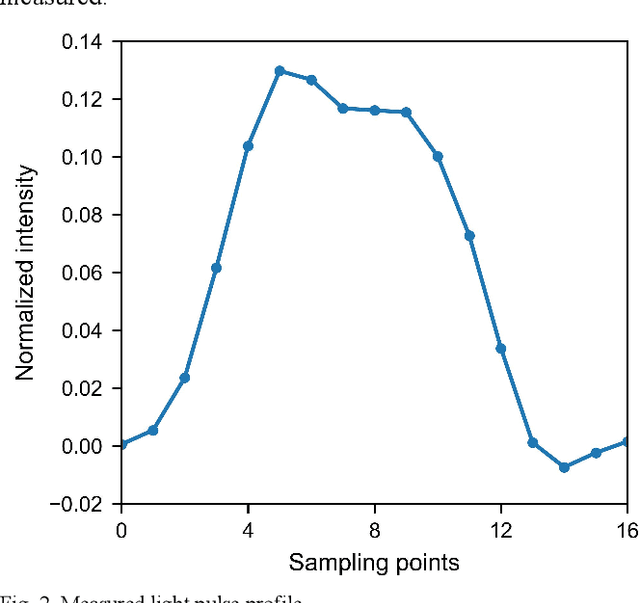
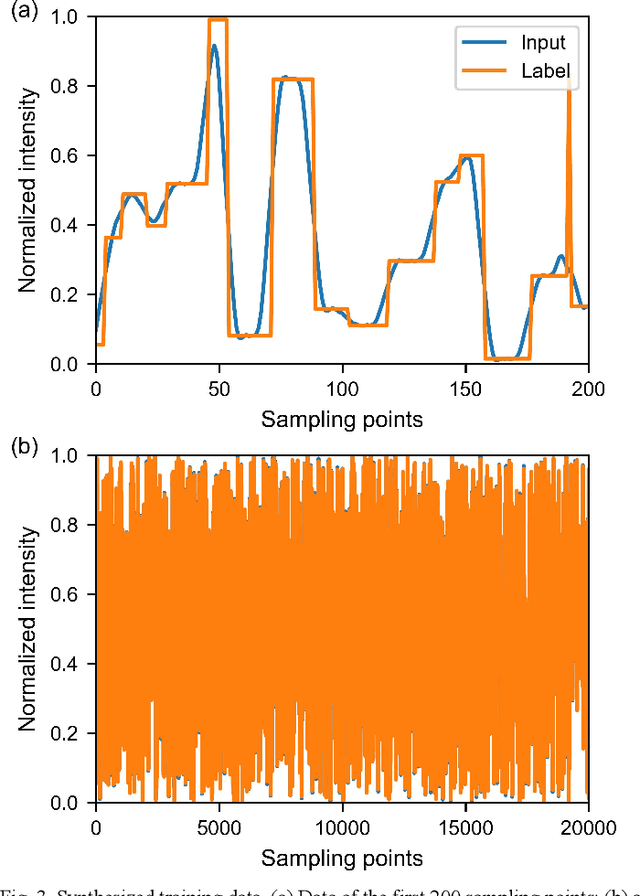
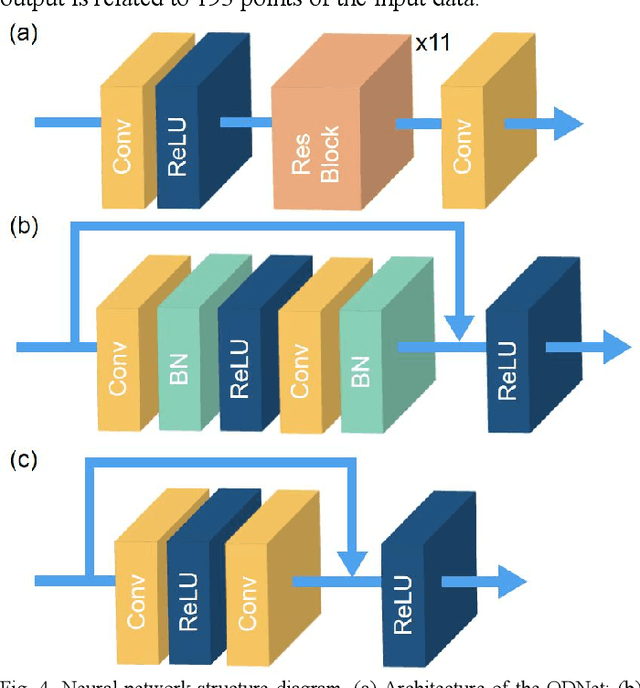
Optical time-domain reflectometry (OTDR) is the basis for distributed time-domain optical fiber sensing techniques. By injecting pulse light into an optical fiber, the distance information of an event can be obtained based on the time of light flight. The minimum distinguishable event separation along the fiber length is called the spatial resolution, which is determined by the optical pulse width. By reducing the pulse width, the spatial resolution can be improved. However, at the same time, the signal-to-noise ratio of the system is degraded, and higher speed equipment is required. To solve this problem, data processing methods such as iterative subdivision, deconvolution, and neural networks have been proposed. However, they all have some shortcomings and thus have not been widely applied. Here, we propose and experimentally demonstrate an OTDR deconvolution neural network based on deep convolutional neural networks. A simplified OTDR model is built to generate a large amount of training data. By optimizing the network structure and training data, an effective OTDR deconvolution is achieved. The simulation and experimental results show that the proposed neural network can achieve more accurate deconvolution than the conventional deconvolution algorithm with a higher signal-to-noise ratio.
Polynomial-Time Algorithms for Counting and Sampling Markov Equivalent DAGs with Applications
May 05, 2022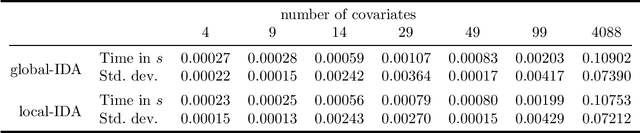
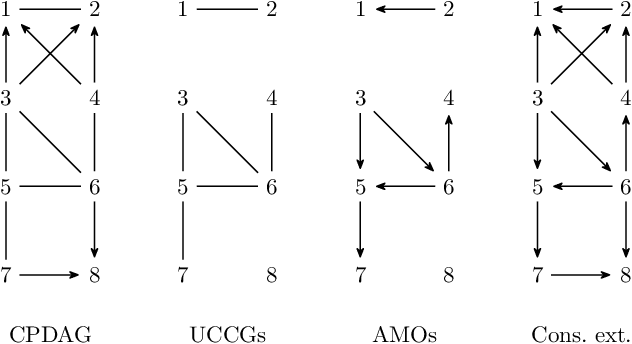
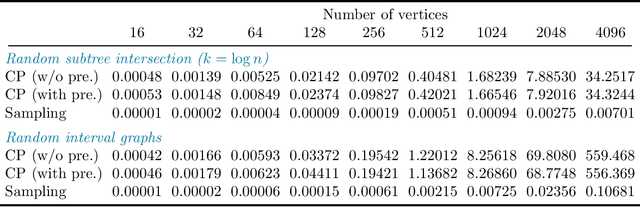
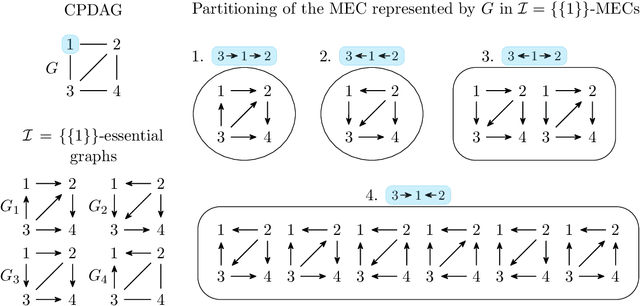
Counting and sampling directed acyclic graphs from a Markov equivalence class are fundamental tasks in graphical causal analysis. In this paper we show that these tasks can be performed in polynomial time, solving a long-standing open problem in this area. Our algorithms are effective and easily implementable. As we show in experiments, these breakthroughs make thought-to-be-infeasible strategies in active learning of causal structures and causal effect identification with regard to a Markov equivalence class practically applicable.
Highly Accurate FMRI ADHD Classification using time distributed multi modal 3D CNNs
May 24, 2022
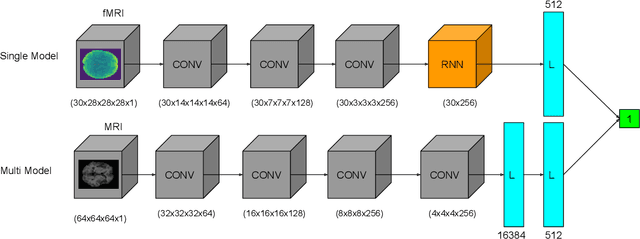
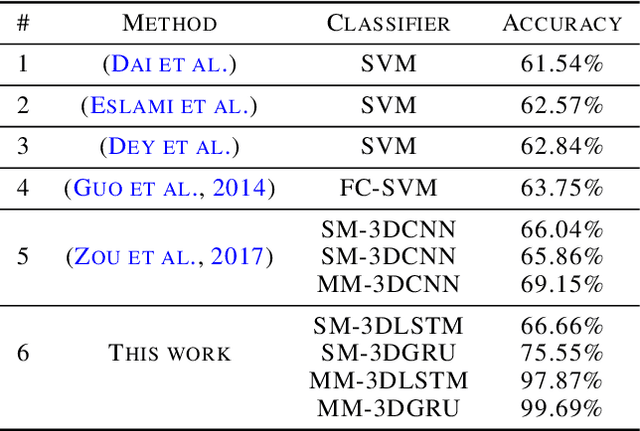
This work proposes an algorithm for fMRI data analysis for the classification of ADHD disorders. There have been several breakthroughs in the analysis of fMRI via 3D convolutional neural networks (CNNs). With these new techniques it is possible to preserve the 3D spatial data of fMRI data. Additionally there have been recent advances in the use of 3D generative adversarial neural networks (GANs) for the generation of normal MRI data. This work utilizes multi modal 3D CNNs with data augmentation from 3D GAN for ADHD prediction from fMRI. By leveraging a 3D-GAN it would be possible to use deepfake data to enhance the accuracy of 3D CNN classification of brain disorders. A comparison will be made between a time distributed single modal 3D CNN model for classification and the modified multi modal model with MRI data as well.
Maximum entropy optimal density control of discrete-time linear systems and Schrödinger bridges
Apr 11, 2022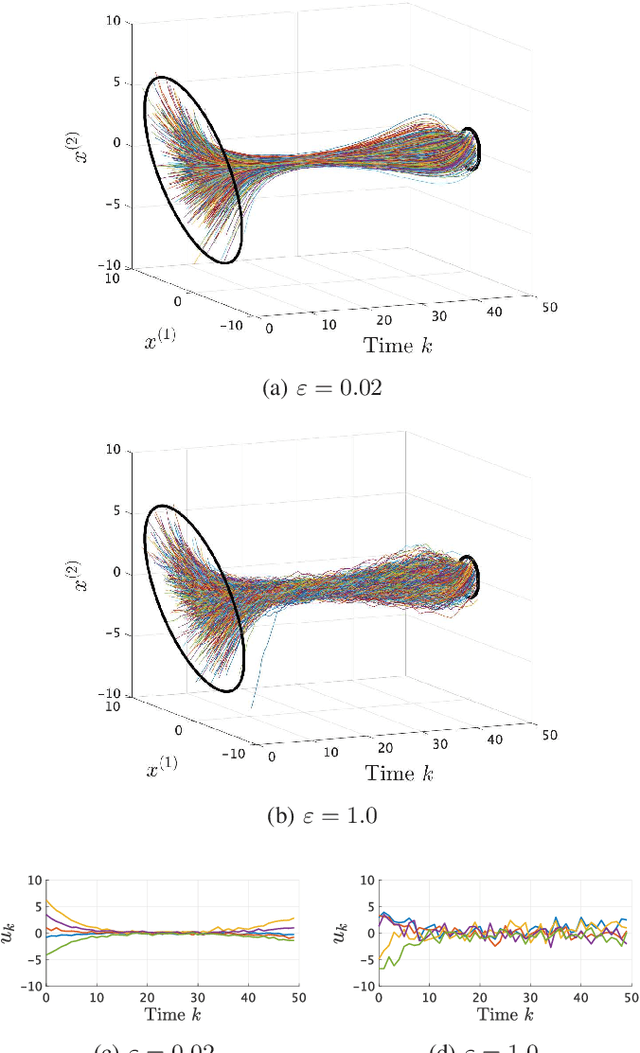
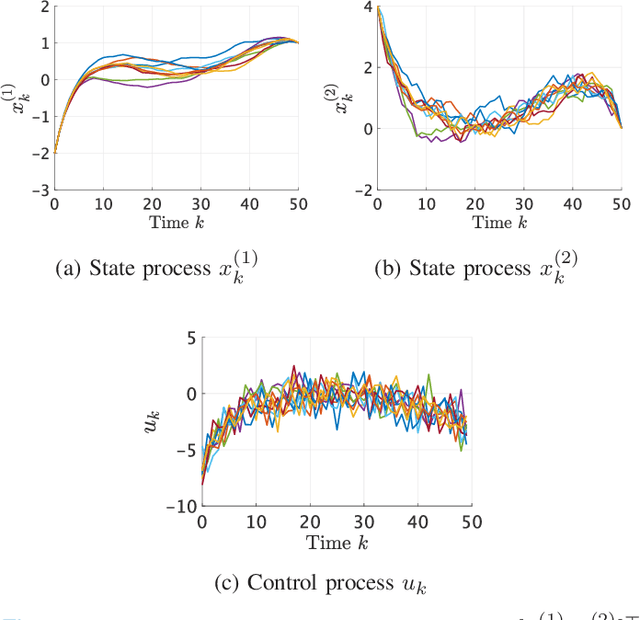
We consider an entropy-regularized version of optimal density control of deterministic discrete-time linear systems. Entropy regularization, or a maximum entropy (MaxEnt) method for optimal control has attracted much attention especially in reinforcement learning due to its many advantages such as a natural exploration strategy. Despite the merits, high-entropy control policies introduce probabilistic uncertainty into systems, which severely limits the applicability of MaxEnt optimal control to safety-critical systems. To remedy this situation, we impose a Gaussian density constraint at a specified time on the MaxEnt optimal control to directly control state uncertainty. Specifically, we derive the explicit form of the MaxEnt optimal density control. In addition, we also consider the case where a density constraint is replaced by a fixed point constraint. Then, we characterize the associated state process as a pinned process, which is a generalization of the Brownian bridge to linear systems. Finally, we reveal that the MaxEnt optimal density control induces the so-called Schr\"odinger bridge associated to a discrete-time linear system.
Active Learning with Convolutional Gaussian Neural Processes for Environmental Sensor Placement
Nov 22, 2022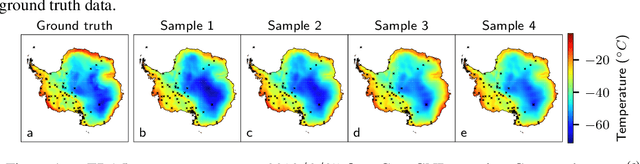

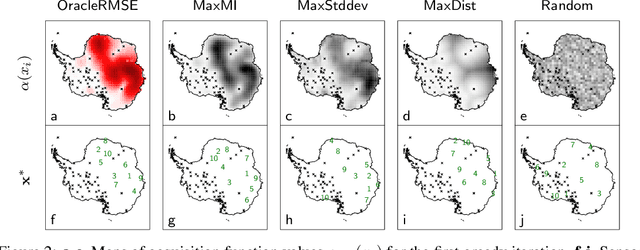
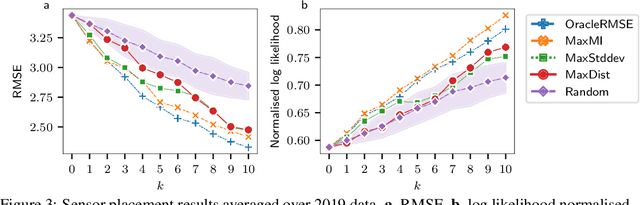
Deploying environmental measurement stations can be a costly and time-consuming procedure, especially in remote regions that are difficult to access, such as Antarctica. Therefore, it is crucial that sensors are placed as efficiently as possible, maximising the informativeness of their measurements. This can be tackled by fitting a probabilistic model to existing data and identifying placements that would maximally reduce the model's uncertainty. The models most widely used for this purpose are Gaussian processes (GPs). However, designing a GP covariance which captures the complex behaviour of non-stationary spatiotemporal data is a difficult task. Further, the computational cost of GPs makes them challenging to scale to large environmental datasets. In this work, we explore using a convolutional Gaussian neural process (ConvGNP) to address these issues. A ConvGNP is a meta-learning model that uses neural networks to parameterise a GP predictive. Our model is data-driven, flexible, efficient, and permits multiple input predictors of gridded or scattered modalities. Using simulated surface air temperature fields over Antarctica as ground truth, we show that a ConvGNP significantly outperforms a non-stationary GP baseline in terms of predictive performance. We then use the ConvGNP in an Antarctic sensor placement toy experiment, yielding promising results.
Attacking Image Splicing Detection and Localization Algorithms Using Synthetic Traces
Nov 22, 2022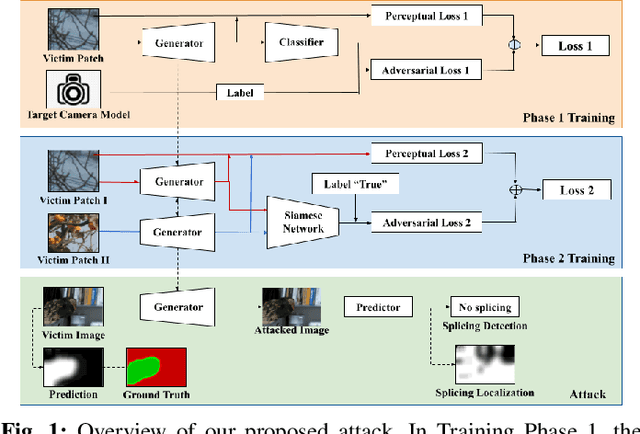


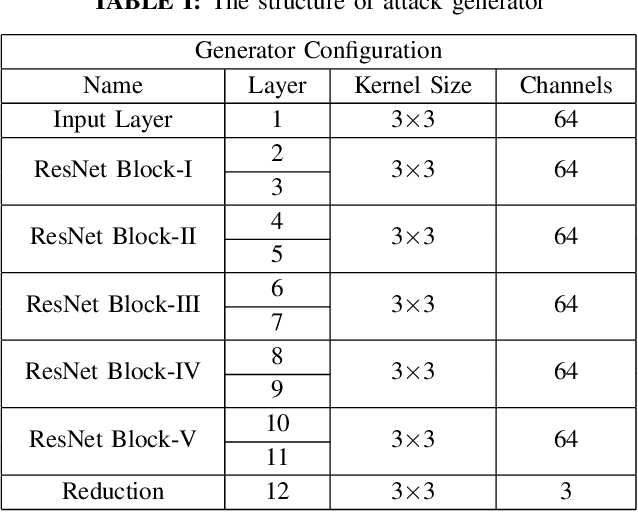
Recent advances in deep learning have enabled forensics researchers to develop a new class of image splicing detection and localization algorithms. These algorithms identify spliced content by detecting localized inconsistencies in forensic traces using Siamese neural networks, either explicitly during analysis or implicitly during training. At the same time, deep learning has enabled new forms of anti-forensic attacks, such as adversarial examples and generative adversarial network (GAN) based attacks. Thus far, however, no anti-forensic attack has been demonstrated against image splicing detection and localization algorithms. In this paper, we propose a new GAN-based anti-forensic attack that is able to fool state-of-the-art splicing detection and localization algorithms such as EXIF-Net, Noiseprint, and Forensic Similarity Graphs. This attack operates by adversarially training an anti-forensic generator against a set of Siamese neural networks so that it is able to create synthetic forensic traces. Under analysis, these synthetic traces appear authentic and are self-consistent throughout an image. Through a series of experiments, we demonstrate that our attack is capable of fooling forensic splicing detection and localization algorithms without introducing visually detectable artifacts into an attacked image. Additionally, we demonstrate that our attack outperforms existing alternative attack approaches. %