 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Active Learning for Multi-Label Classification of Remote Sensing Images
Dec 02, 2022
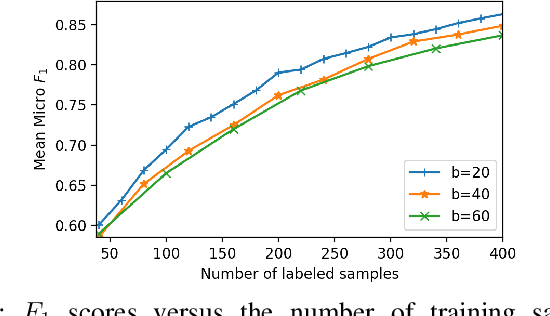

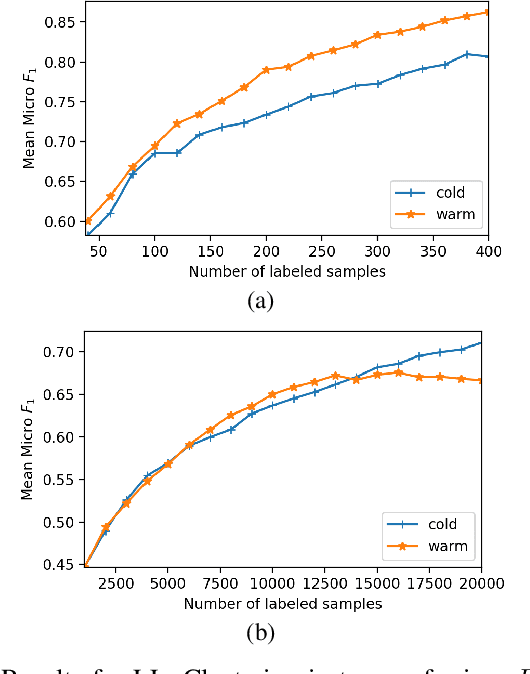
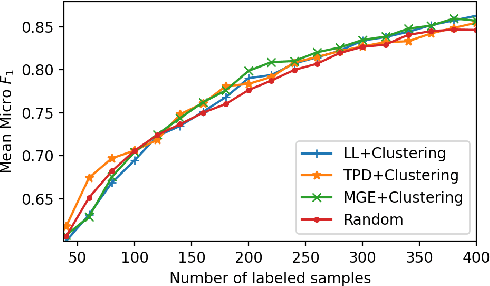
The use of deep neural networks (DNNs) has recently attracted great attention in the framework of the multi-label classification (MLC) of remote sensing (RS) images. To optimize the large number of parameters of DNNs a high number of reliable training images annotated with multi-labels is often required. However, the collection of a large training set is time-consuming, complex and costly. To minimize annotation efforts for data-demanding DNNs, in this paper we present several query functions for active learning (AL) in the context of DNNs for the MLC of RS images. Unlike the AL query functions defined for single-label classification or semantic segmentation problems, each query function presented in this paper is based on the evaluation of two criteria: i) multi-label uncertainty; and ii) multi-label diversity. The multi-label uncertainty criterion is associated to the confidence of the DNNs in correctly assigning multi-labels to each image. To assess the multi-label uncertainty, we present and adapt to the MLC problems three strategies: i) learning multi-label loss ordering; ii) measuring temporal discrepancy of multi-label prediction; and iii) measuring magnitude of approximated gradient embedding. The multi-label diversity criterion aims at selecting a set of uncertain images that are as diverse as possible to reduce the redundancy among them. To assess this criterion we exploit a clustering based strategy. We combine each of the above-mentioned uncertainty strategy with the clustering based diversity strategy, resulting in three different query functions. Experimental results obtained on two benchmark archives show that our query functions result in the selection of a highly informative set of samples at each iteration of the AL process in the context of MLC.
Occlusion-Aware MPC for Guaranteed Safe Robot Navigation with Unseen Dynamic Obstacles
Nov 16, 2022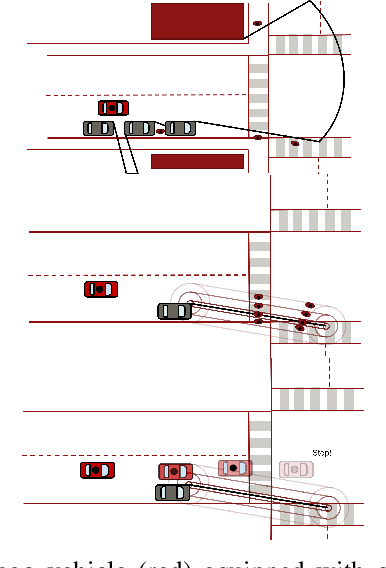
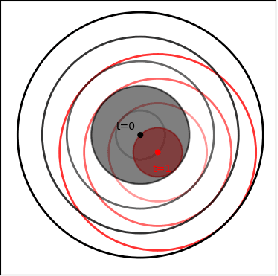
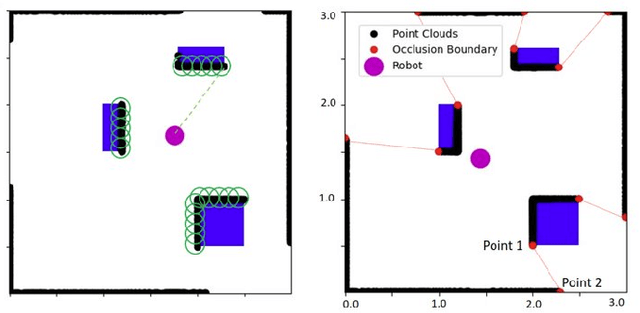

For safe navigation in dynamic uncertain environments, robotic systems rely on the perception and prediction of other agents. Particularly, in occluded areas where cameras and LiDAR give no data, the robot must be able to reason about potential movements of invisible dynamic agents. This work presents a provably safe motion planning scheme for real-time navigation in an a priori unmapped environment, where occluded dynamic agents are present. Safety guarantees are provided based on reachability analysis. Forward reachable sets associated with potential occluded agents, such as pedestrians, are computed and incorporated into planning. An iterative optimization-based planner is presented that alternates between two optimizations: nonlinear Model Predictive Control (NMPC) and collision avoidance. Recursive feasibility of the MPC is guaranteed by introducing a terminal stopping constraint. The effectiveness of the proposed algorithm is demonstrated through simulation studies and hardware experiments with a TurtleBot robot. A video of experimental results is available at \url{https://youtu.be/OUnkB5Feyuk}.
Leveraging Heteroscedastic Uncertainty in Learning Complex Spectral Mapping for Single-channel Speech Enhancement
Nov 16, 2022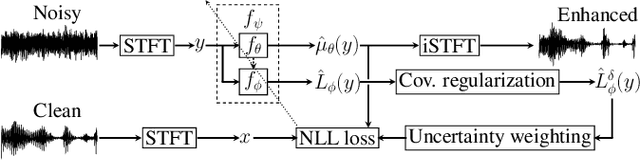
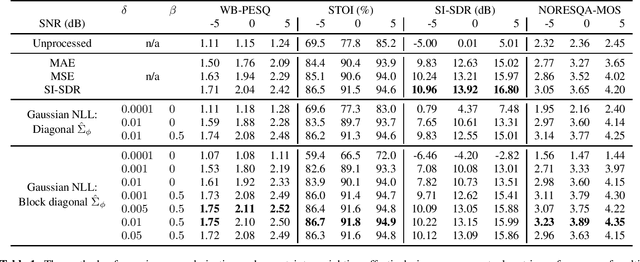
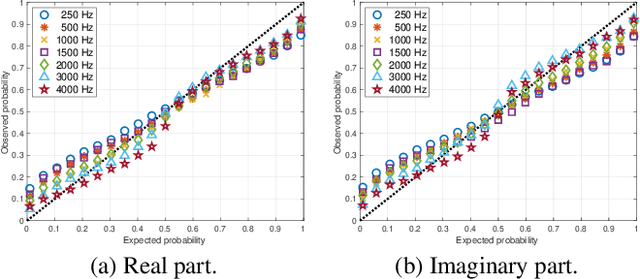
Most speech enhancement (SE) models learn a point estimate, and do not make use of uncertainty estimation in the learning process. In this paper, we show that modeling heteroscedastic uncertainty by minimizing a multivariate Gaussian negative log-likelihood (NLL) improves SE performance at no extra cost. During training, our approach augments a model learning complex spectral mapping with a temporary submodel to predict the covariance of the enhancement error at each time-frequency bin. Due to unrestricted heteroscedastic uncertainty, the covariance introduces an undersampling effect, detrimental to SE performance. To mitigate undersampling, our approach inflates the uncertainty lower bound and weights each loss component with their uncertainty, effectively compensating severely undersampled components with more penalties. Our multivariate setting reveals common covariance assumptions such as scalar and diagonal matrices. By weakening these assumptions, we show that the NLL achieves superior performance compared to popular losses including the mean squared error (MSE), mean absolute error (MAE), and scale-invariant signal-to-distortion ratio (SI-SDR).
Energy Reconstruction in Analysis of Cherenkov Telescopes Images in TAIGA Experiment Using Deep Learning Methods
Nov 16, 2022
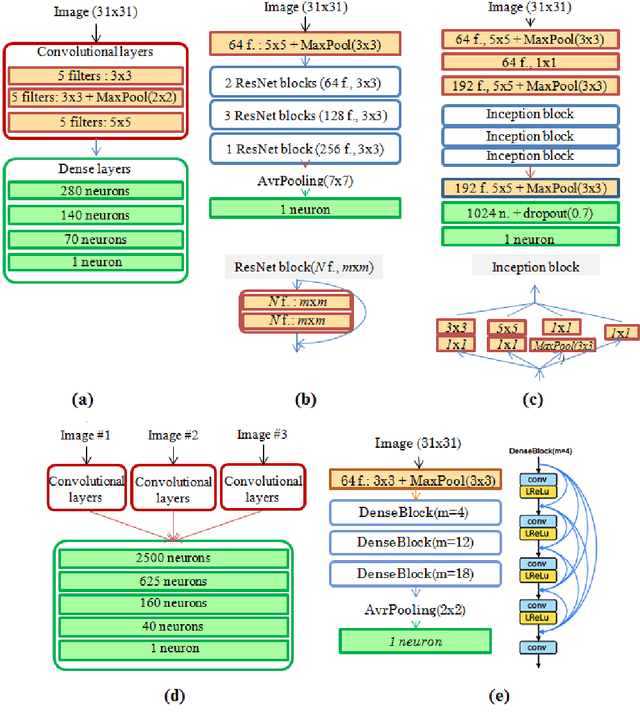
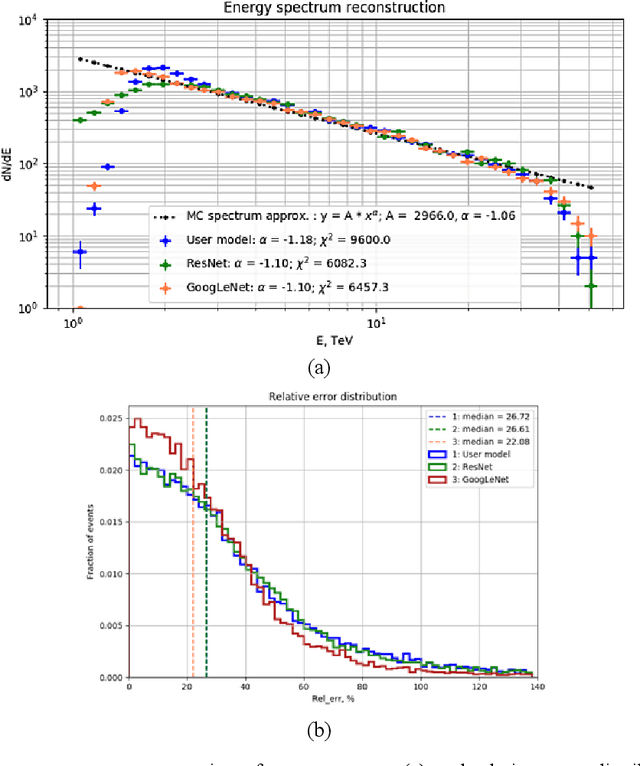
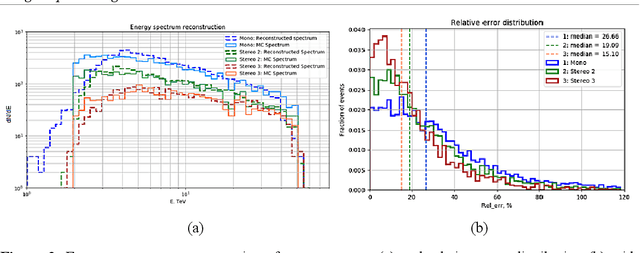
Imaging Atmospheric Cherenkov Telescopes (IACT) of TAIGA astrophysical complex allow to observe high energy gamma radiation helping to study many astrophysical objects and processes. TAIGA-IACT enables us to select gamma quanta from the total cosmic radiation flux and recover their primary parameters, such as energy and direction of arrival. The traditional method of processing the resulting images is an image parameterization - so-called the Hillas parameters method. At the present time Machine Learning methods, in particular Deep Learning methods have become actively used for IACT image processing. This paper presents the analysis of simulated Monte Carlo images by several Deep Learning methods for a single telescope (mono-mode) and multiple IACT telescopes (stereo-mode). The estimation of the quality of energy reconstruction was carried out and their energy spectra were analyzed using several types of neural networks. Using the developed methods the obtained results were also compared with the results obtained by traditional methods based on the Hillas parameters.
A policy gradient approach for Finite Horizon Constrained Markov Decision Processes
Oct 10, 2022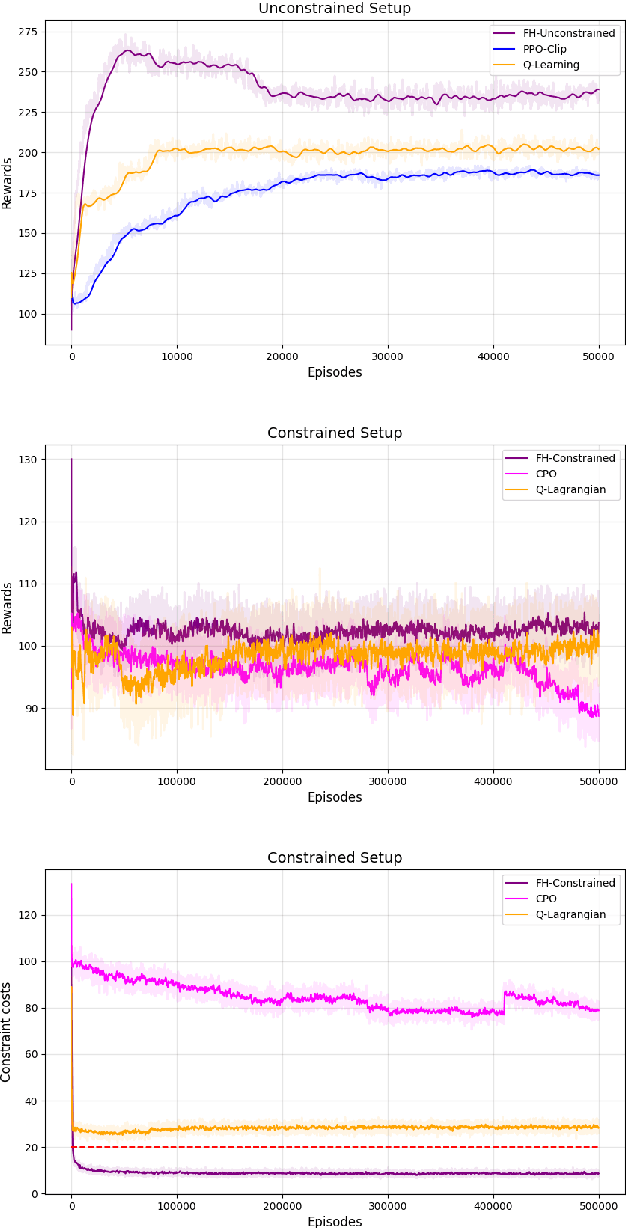
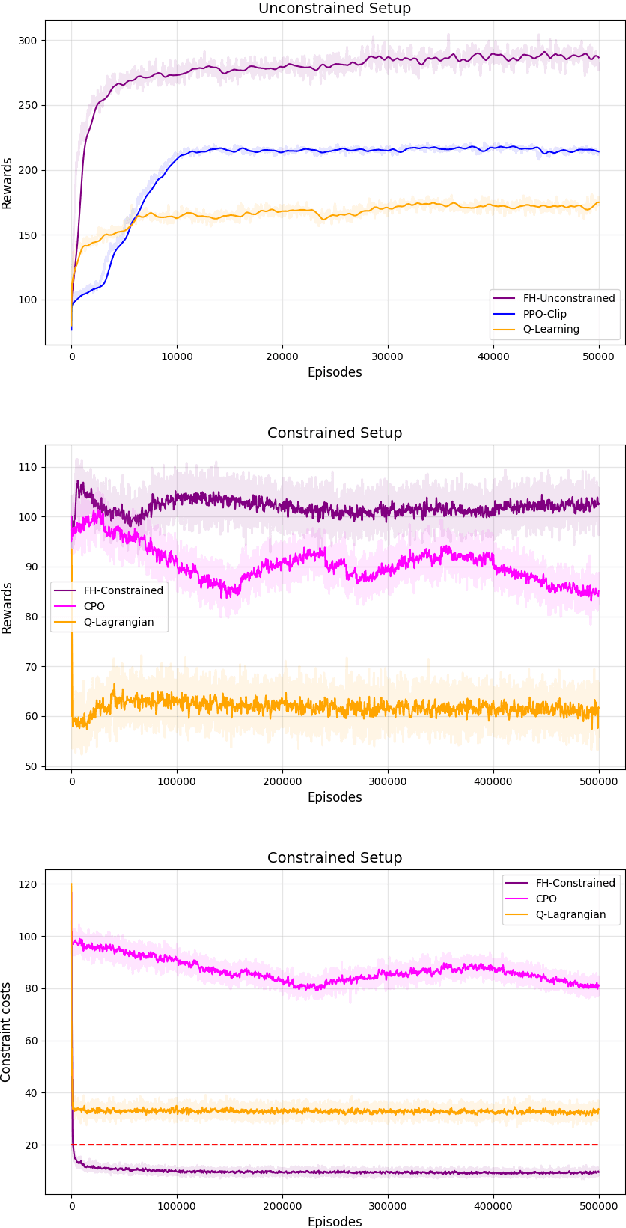
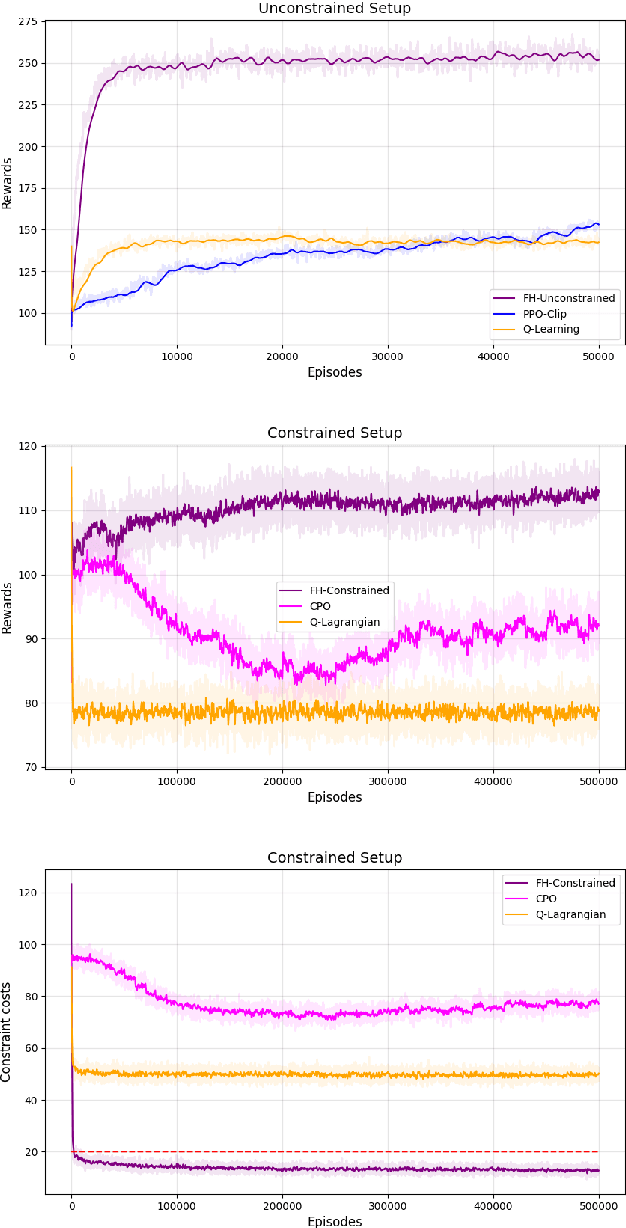
The infinite horizon setting is widely adopted for problems of reinforcement learning (RL). These invariably result in stationary policies that are optimal. In many situations, finite horizon control problems are of interest and for such problems, the optimal policies are time-varying in general. Another setting that has become popular in recent times is of Constrained Reinforcement Learning, where the agent maximizes its rewards while also aims to satisfy certain constraint criteria. However, this setting has only been studied in the context of infinite horizon MDPs where stationary policies are optimal. We present, for the first time, an algorithm for constrained RL in the Finite Horizon Setting where the horizon terminates after a fixed (finite) time. We use function approximation in our algorithm which is essential when the state and action spaces are large or continuous and use the policy gradient method to find the optimal policy. The optimal policy that we obtain depends on the stage and so is time-dependent. To the best of our knowledge, our paper presents the first policy gradient algorithm for the finite horizon setting with constraints. We show the convergence of our algorithm to an optimal policy. We further present a sample complexity result for our algorithm in the unconstrained (i.e., the regular finite horizon MDP) setting. We also compare and analyze the performance of our algorithm through experiments and show that our algorithm performs better than other well known algorithms.
EPIK: Eliminating multi-model Pipelines with Knowledge-distillation
Nov 27, 2022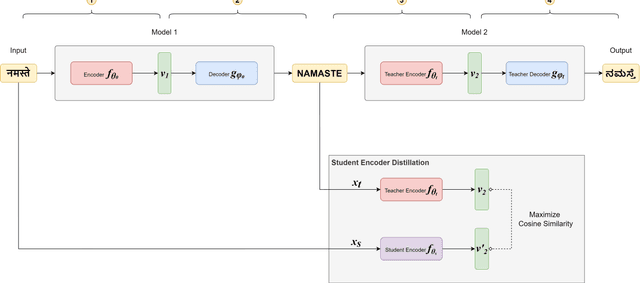
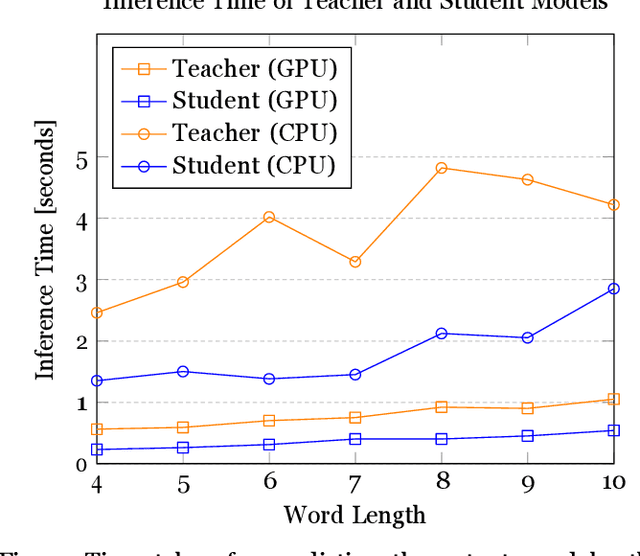

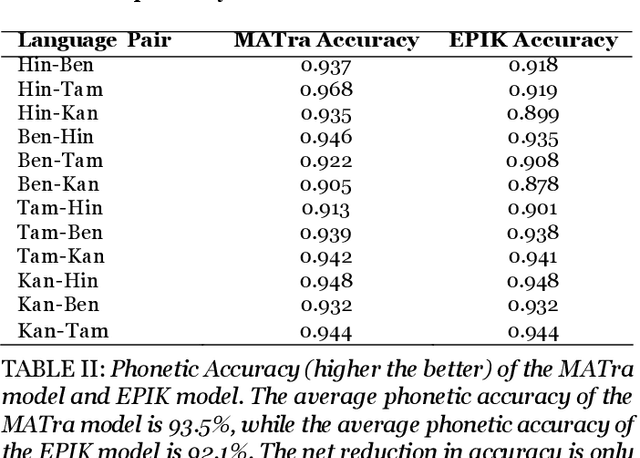
Real-world tasks are largely composed of multiple models, each performing a sub-task in a larger chain of tasks, i.e., using the output from a model as input for another model in a multi-model pipeline. A model like MATRa performs the task of Crosslingual Transliteration in two stages, using English as an intermediate transliteration target when transliterating between two indic languages. We propose a novel distillation technique, EPIK, that condenses two-stage pipelines for hierarchical tasks into a single end-to-end model without compromising performance. This method can create end-to-end models for tasks without needing a dedicated end-to-end dataset, solving the data scarcity problem. The EPIK model has been distilled from the MATra model using this technique of knowledge distillation. The MATra model can perform crosslingual transliteration between 5 languages - English, Hindi, Tamil, Kannada and Bengali. The EPIK model executes the task of transliteration without any intermediate English output while retaining the performance and accuracy of the MATra model. The EPIK model can perform transliteration with an average CER score of 0.015 and average phonetic accuracy of 92.1%. In addition, the average time for execution has reduced by 54.3% as compared to the teacher model and has a similarity score of 97.5% with the teacher encoder. In a few cases, the EPIK model (student model) can outperform the MATra model (teacher model) even though it has been distilled from the MATra model.
MGDoc: Pre-training with Multi-granular Hierarchy for Document Image Understanding
Nov 27, 2022
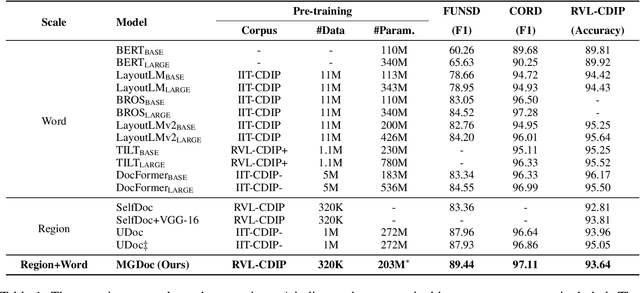
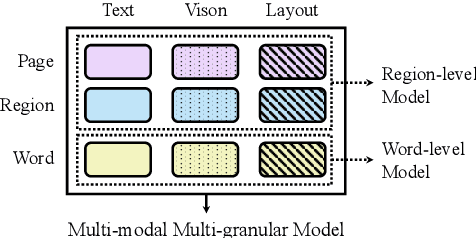
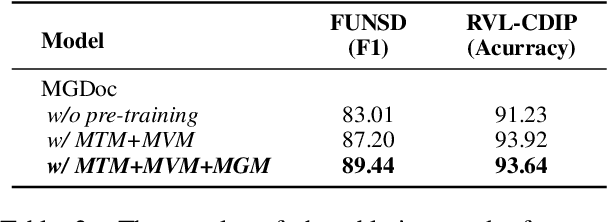
Document images are a ubiquitous source of data where the text is organized in a complex hierarchical structure ranging from fine granularity (e.g., words), medium granularity (e.g., regions such as paragraphs or figures), to coarse granularity (e.g., the whole page). The spatial hierarchical relationships between content at different levels of granularity are crucial for document image understanding tasks. Existing methods learn features from either word-level or region-level but fail to consider both simultaneously. Word-level models are restricted by the fact that they originate from pure-text language models, which only encode the word-level context. In contrast, region-level models attempt to encode regions corresponding to paragraphs or text blocks into a single embedding, but they perform worse with additional word-level features. To deal with these issues, we propose MGDoc, a new multi-modal multi-granular pre-training framework that encodes page-level, region-level, and word-level information at the same time. MGDoc uses a unified text-visual encoder to obtain multi-modal features across different granularities, which makes it possible to project the multi-granular features into the same hyperspace. To model the region-word correlation, we design a cross-granular attention mechanism and specific pre-training tasks for our model to reinforce the model of learning the hierarchy between regions and words. Experiments demonstrate that our proposed model can learn better features that perform well across granularities and lead to improvements in downstream tasks.
Representation Learning for Continuous Action Spaces is Beneficial for Efficient Policy Learning
Nov 23, 2022
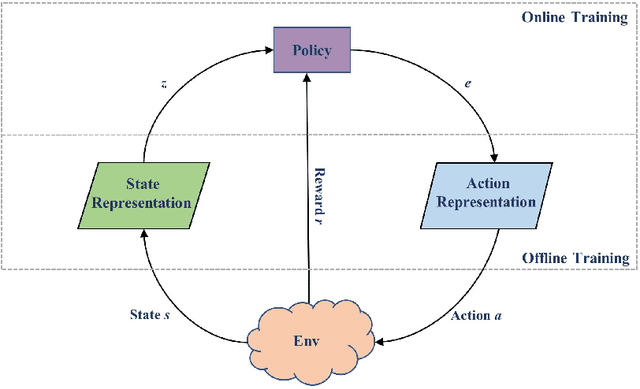
Deep reinforcement learning (DRL) breaks through the bottlenecks of traditional reinforcement learning (RL) with the help of the perception capability of deep learning and has been widely applied in real-world problems.While model-free RL, as a class of efficient DRL methods, performs the learning of state representations simultaneously with policy learning in an end-to-end manner when facing large-scale continuous state and action spaces. However, training such a large policy model requires a large number of trajectory samples and training time. On the other hand, the learned policy often fails to generalize to large-scale action spaces, especially for the continuous action spaces. To address this issue, in this paper we propose an efficient policy learning method in latent state and action spaces. More specifically, we extend the idea of state representations to action representations for better policy generalization capability. Meanwhile, we divide the whole learning task into learning with the large-scale representation models in an unsupervised manner and learning with the small-scale policy model in the RL manner.The small policy model facilitates policy learning, while not sacrificing generalization and expressiveness via the large representation model. Finally,the effectiveness of the proposed method is demonstrated by MountainCar,CarRacing and Cheetah experiments.
MEGAN: Multi-Explanation Graph Attention Network
Nov 23, 2022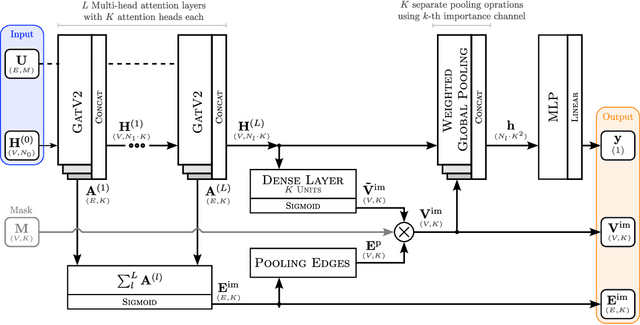
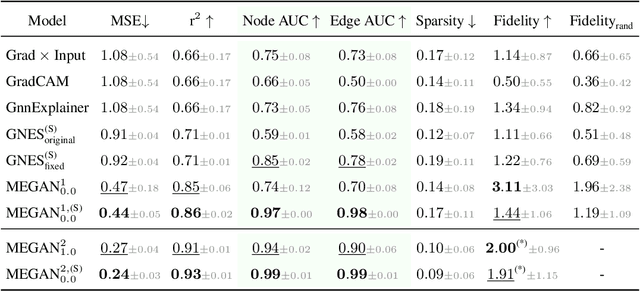
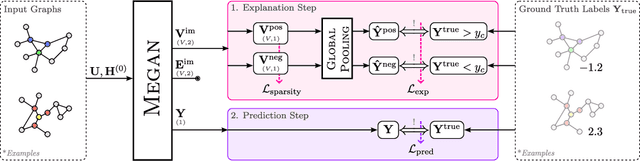
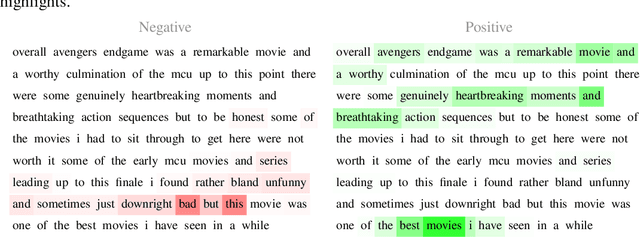
Explainable artificial intelligence (XAI) methods are expected to improve trust during human-AI interactions, provide tools for model analysis and extend human understanding of complex problems. Explanation-supervised training allows to improve explanation quality by training self-explaining XAI models on ground truth or human-generated explanations. However, existing explanation methods have limited expressiveness and interoperability due to the fact that only single explanations in form of node and edge importance are generated. To that end we propose the novel multi-explanation graph attention network (MEGAN). Our fully differentiable, attention-based model features multiple explanation channels, which can be chosen independently of the task specifications. We first validate our model on a synthetic graph regression dataset. We show that for the special single explanation case, our model significantly outperforms existing post-hoc and explanation-supervised baseline methods. Furthermore, we demonstrate significant advantages when using two explanations, both in quantitative explanation measures as well as in human interpretability. Finally, we demonstrate our model's capabilities on multiple real-world datasets. We find that our model produces sparse high-fidelity explanations consistent with human intuition about those tasks and at the same time matches state-of-the-art graph neural networks in predictive performance, indicating that explanations and accuracy are not necessarily a trade-off.
On "Deep Learning" Misconduct
Nov 23, 2022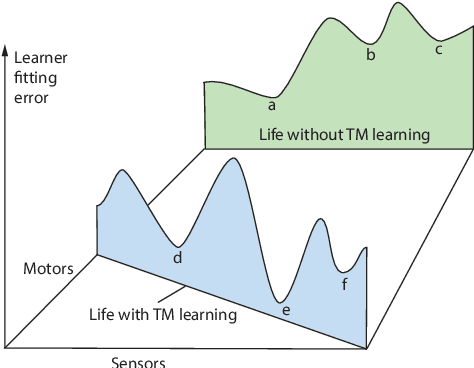
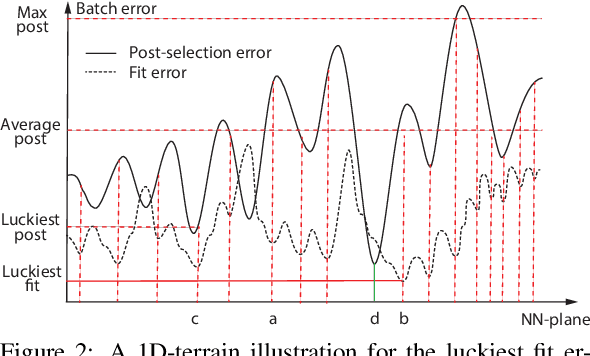

This is a theoretical paper, as a companion paper of the plenary talk for the same conference ISAIC 2022. In contrast to conscious learning, which develops a single network for a normal life and is the main topic of the plenary talk, it is necessary to address the currently widespread approach, so-called "Deep Learning". Although "Deep Learning" may use different learning modes, including supervised, reinforcement and adversarial modes, almost all "Deep Learning" projects apparently suffer from the same misconduct, called "data deletion" and "test on training data". Consequently, Deep Learning almost always was not tested at all. Why? The so-called "test set" was used in the Post-Selection step of the training stage. This paper establishes a theorem that a simple method called Pure-Guess Nearest Neighbor (PGNN) reaches any required errors on validation set and test set, including zero-error requirements, through the "Deep Learning" misconduct, as long as the test set is in the possession of the author and both the amount of storage space and the time of training are finite but unbounded. However, Deep Learning methods, like the PGNN method, apparently are not generalizable since they have never been tested at all by a valid test set.