 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robust Anomaly Detection for Time-series Data
Feb 06, 2022
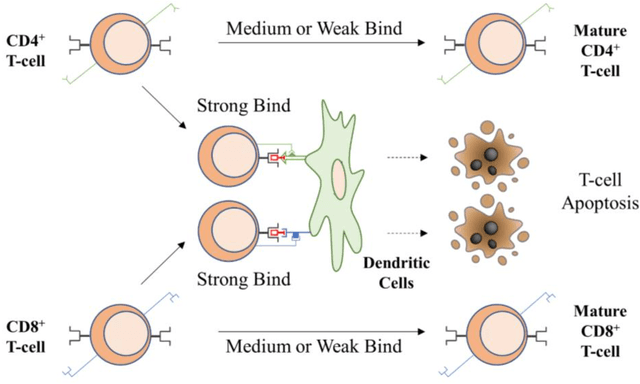
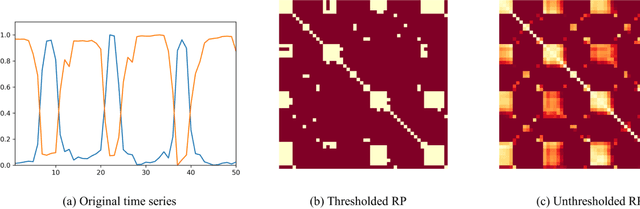
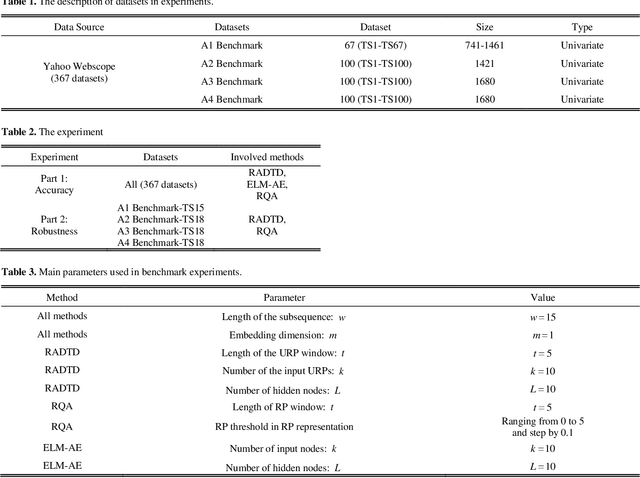
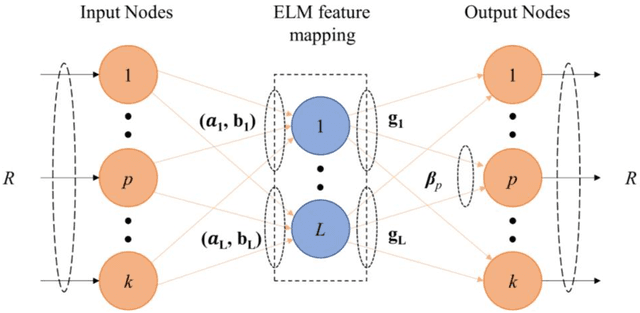
Time-series anomaly detection plays a vital role in monitoring complex operation conditions. However, the detection accuracy of existing approaches is heavily influenced by pattern distribution, existence of multiple normal patterns, dynamical features representation, and parameter settings. For the purpose of improving the robustness and guaranteeing the accuracy, this research combined the strengths of negative selection, unthresholded recurrence plots, and an extreme learning machine autoencoder and then proposed robust anomaly detection for time-series data (RADTD), which can automatically learn dynamical features in time series and recognize anomalies with low label dependency and high robustness. Yahoo benchmark datasets and three tunneling engineering simulation experiments were used to evaluate the performance of RADTD. The experiments showed that in benchmark datasets RADTD possessed higher accuracy and robustness than recurrence qualification analysis and extreme learning machine autoencoder, respectively, and that RADTD accurately detected the occurrence of tunneling settlement accidents, indicating its remarkable performance in accuracy and robustness.
Efficient Hair Style Transfer with Generative Adversarial Networks
Oct 22, 2022
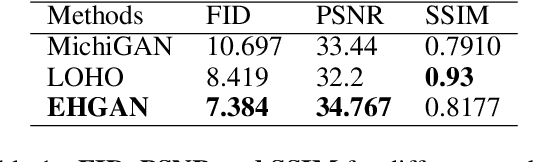
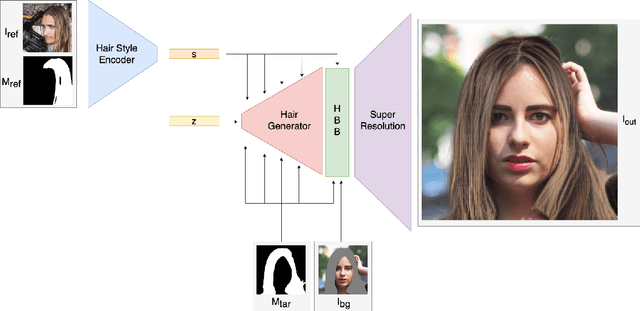

Despite the recent success of image generation and style transfer with Generative Adversarial Networks (GANs), hair synthesis and style transfer remain challenging due to the shape and style variability of human hair in in-the-wild conditions. The current state-of-the-art hair synthesis approaches struggle to maintain global composition of the target style and cannot be used in real-time applications due to their high running costs on high-resolution portrait images. Therefore, We propose a novel hairstyle transfer method, called EHGAN, which reduces computational costs to enable real-time processing while improving the transfer of hairstyle with better global structure compared to the other state-of-the-art hair synthesis methods. To achieve this goal, we train an encoder and a low-resolution generator to transfer hairstyle and then, increase the resolution of results with a pre-trained super-resolution model. We utilize Adaptive Instance Normalization (AdaIN) and design our novel Hair Blending Block (HBB) to obtain the best performance of the generator. EHGAN needs around 2.7 times and over 10,000 times less time consumption than the state-of-the-art MichiGAN and LOHO methods respectively while obtaining better photorealism and structural similarity to the desired style than its competitors.
Monotonic segmental attention for automatic speech recognition
Oct 26, 2022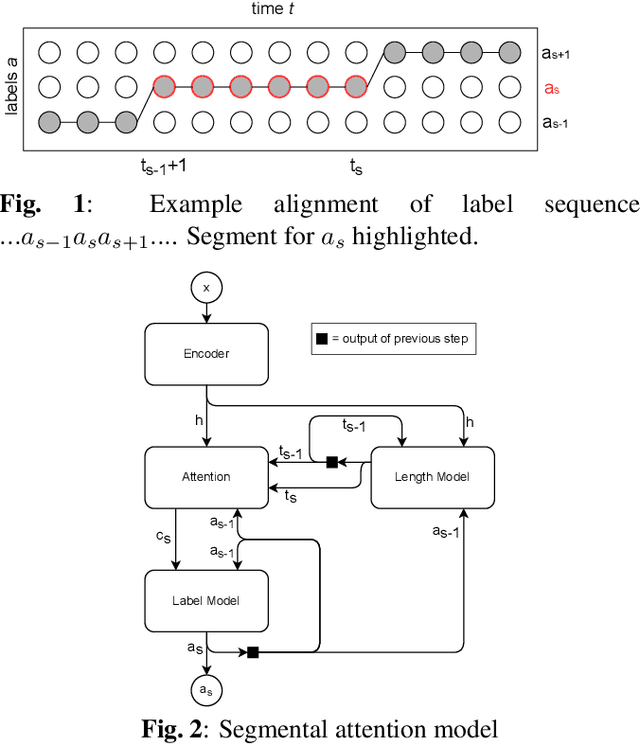
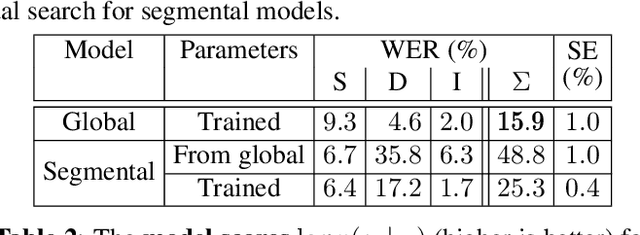
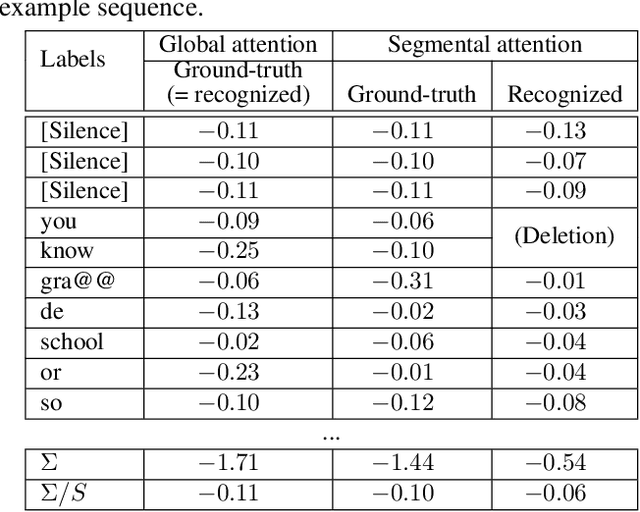
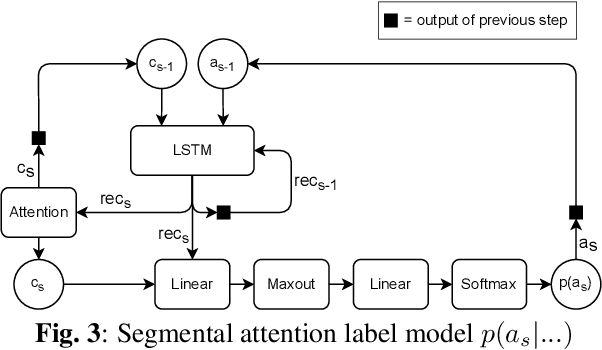
We introduce a novel segmental-attention model for automatic speech recognition. We restrict the decoder attention to segments to avoid quadratic runtime of global attention, better generalize to long sequences, and eventually enable streaming. We directly compare global-attention and different segmental-attention modeling variants. We develop and compare two separate time-synchronous decoders, one specifically taking the segmental nature into account, yielding further improvements. Using time-synchronous decoding for segmental models is novel and a step towards streaming applications. Our experiments show the importance of a length model to predict the segment boundaries. The final best segmental-attention model using segmental decoding performs better than global-attention, in contrast to other monotonic attention approaches in the literature. Further, we observe that the segmental model generalizes much better to long sequences of up to several minutes.
Efficient Feature Extraction for High-resolution Video Frame Interpolation
Nov 25, 2022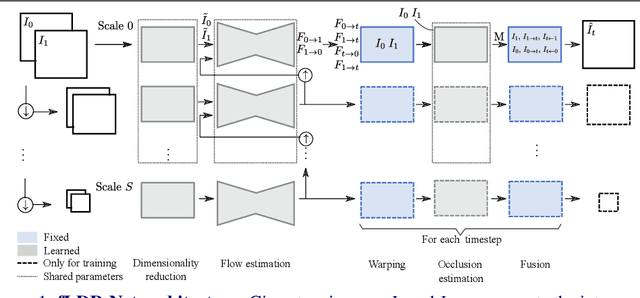
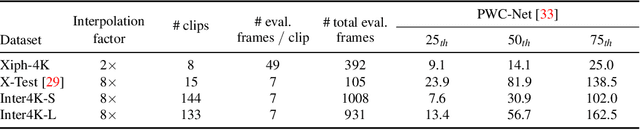
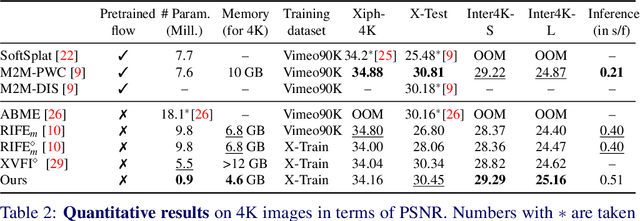
Most deep learning methods for video frame interpolation consist of three main components: feature extraction, motion estimation, and image synthesis. Existing approaches are mainly distinguishable in terms of how these modules are designed. However, when interpolating high-resolution images, e.g. at 4K, the design choices for achieving high accuracy within reasonable memory requirements are limited. The feature extraction layers help to compress the input and extract relevant information for the latter stages, such as motion estimation. However, these layers are often costly in parameters, computation time, and memory. We show how ideas from dimensionality reduction combined with a lightweight optimization can be used to compress the input representation while keeping the extracted information suitable for frame interpolation. Further, we require neither a pretrained flow network nor a synthesis network, additionally reducing the number of trainable parameters and required memory. When evaluating on three 4K benchmarks, we achieve state-of-the-art image quality among the methods without pretrained flow while having the lowest network complexity and memory requirements overall.
Automating Cobb Angle Measurement for Adolescent Idiopathic Scoliosis using Instance Segmentation
Nov 25, 2022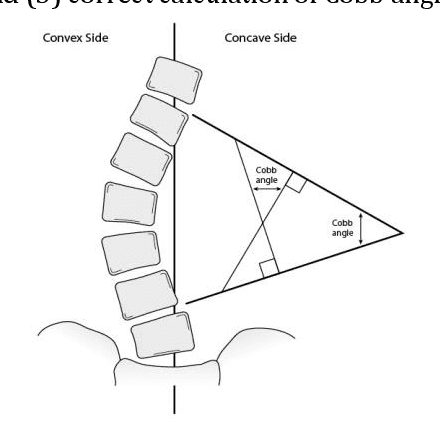
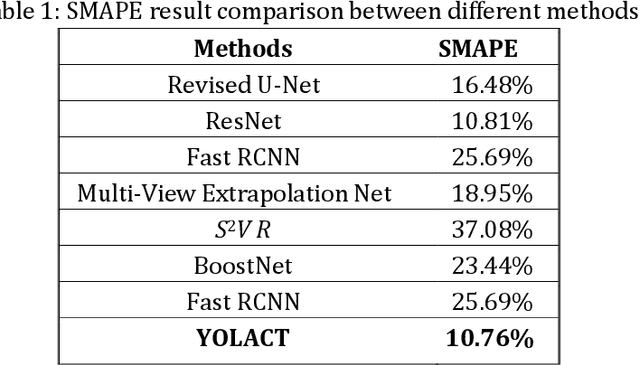
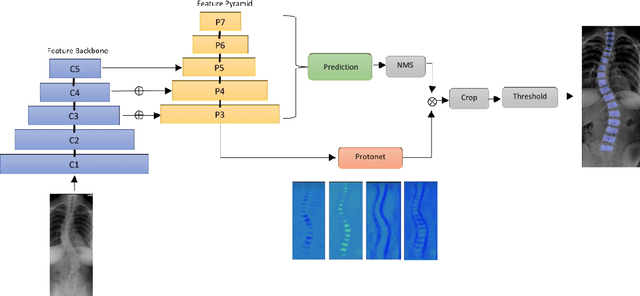

Scoliosis is a three-dimensional deformity of the spine, most often diagnosed in childhood. It affects 2-3% of the population, which is approximately seven million people in North America. Currently, the reference standard for assessing scoliosis is based on the manual assignment of Cobb angles at the site of the curvature center. This manual process is time consuming and unreliable as it is affected by inter- and intra-observer variance. To overcome these inaccuracies, machine learning (ML) methods can be used to automate the Cobb angle measurement process. This paper proposes to address the Cobb angle measurement task using YOLACT, an instance segmentation model. The proposed method first segments the vertebrae in an X-Ray image using YOLACT, then it tracks the important landmarks using the minimum bounding box approach. Lastly, the extracted landmarks are used to calculate the corresponding Cobb angles. The model achieved a Symmetric Mean Absolute Percentage Error (SMAPE) score of 10.76%, demonstrating the reliability of this process in both vertebra localization and Cobb angle measurement.
Evaluation of the impact of the indiscernibility relation on the fuzzy-rough nearest neighbours algorithm
Nov 25, 2022

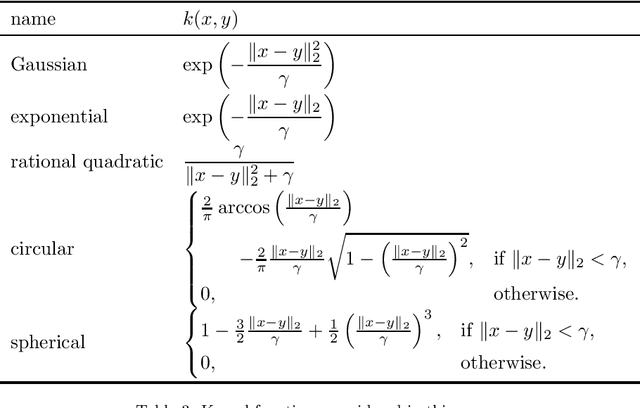

Fuzzy rough sets are well-suited for working with vague, imprecise or uncertain information and have been succesfully applied in real-world classification problems. One of the prominent representatives of this theory is fuzzy-rough nearest neighbours (FRNN), a classification algorithm based on the classical k-nearest neighbours algorithm. The crux of FRNN is the indiscernibility relation, which measures how similar two elements in the data set of interest are. In this paper, we investigate the impact of this indiscernibility relation on the performance of FRNN classification. In addition to relations based on distance functions and kernels, we also explore the effect of distance metric learning on FRNN for the first time. Furthermore, we also introduce an asymmetric, class-specific relation based on the Mahalanobis distance which uses the correlation within each class, and which shows a significant improvement over the regular Mahalanobis distance, but is still beaten by the Manhattan distance. Overall, the Neighbourhood Components Analysis algorithm is found to be the best performer, trading speed for accuracy.
Enhanced Tracking and Beamforming Codebook Design for Wideband Terahertz Massive MIMO System
Nov 25, 2022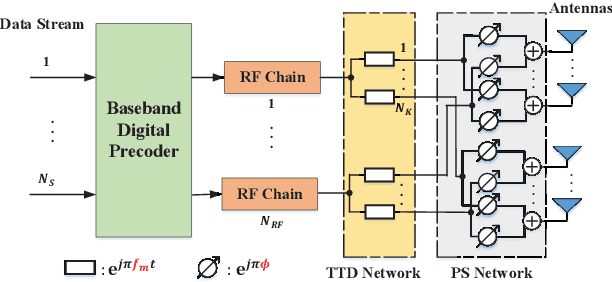
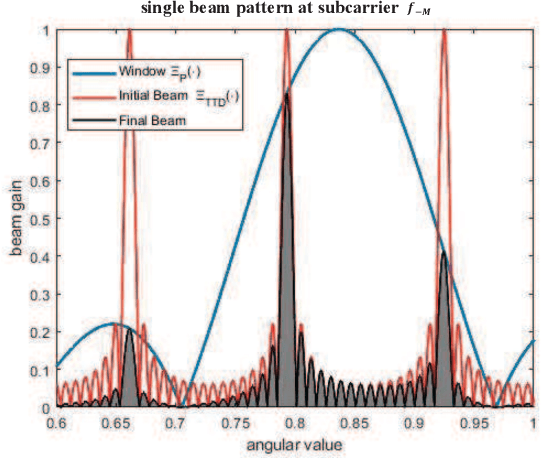
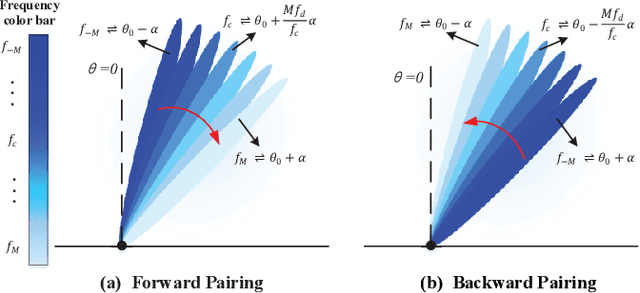
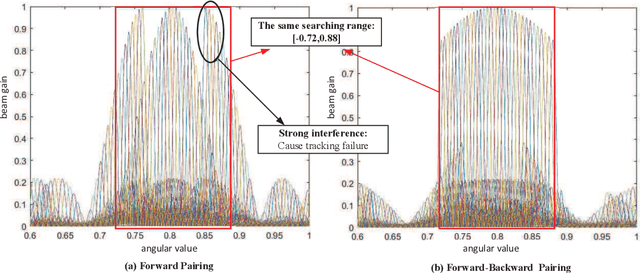
True-time-delay (TTD) lines are recently applied inside Terahertz (THz) hybrid-precoding transceiver to acquire high beamforming gain against beam squint effect. However, beam tracking turns into a challenging puzzle where enormous potential beam directions bring about unacceptable overhead consumption. Frequency-scanning-based beam tracking is initially explored but still imperfect in previous studies. In this paper, based on TTD-aided hybrid precoding structure, we give an enhanced frequency-scanning-based tracking scheme. Multiple beams are generated and utilized simultaneously via several subcarriers for tracking at one timeslot. The squint beams' angular coverage at all subcarriers can be flexibly controlled by two different subcarrier-angular mapping policies, named forward-pairing and backward-pairing. Then multiple physical directions can be simultaneously searched in one timeslot for lower overhead consumption. Besides, closed-form searching radius bound, parameter configuration and interferences are theoretically analyzed. Furthermore, we provide the coupled codebook design for TTDs and phase shifters (PSs), with joint consideration of both beamforming and tracking. Analytical and numerical results demonstrate the superiority of the new frequency-scanning-based tracking scheme and beamforming codebook.
PaCMO: Partner Dependent Human Motion Generation in Dyadic Human Activity using Neural Operators
Nov 25, 2022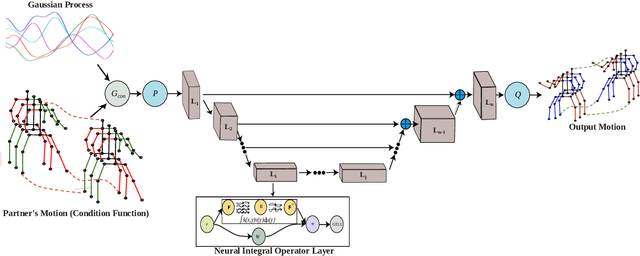

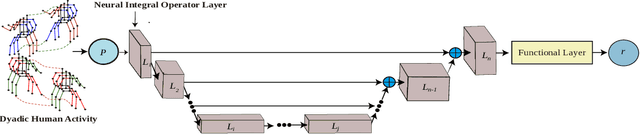

We address the problem of generating 3D human motions in dyadic activities. In contrast to the concurrent works, which mainly focus on generating the motion of a single actor from the textual description, we generate the motion of one of the actors from the motion of the other participating actor in the action. This is a particularly challenging, under-explored problem, that requires learning intricate relationships between the motion of two actors participating in an action and also identifying the action from the motion of one actor. To address these, we propose partner conditioned motion operator (PaCMO), a neural operator-based generative model which learns the distribution of human motion conditioned by the partner's motion in function spaces through adversarial training. Our model can handle long unlabeled action sequences at arbitrary time resolution. We also introduce the "Functional Frechet Inception Distance" ($F^2ID$) metric for capturing similarity between real and generated data for function spaces. We test PaCMO on NTU RGB+D and DuetDance datasets and our model produces realistic results evidenced by the $F^2ID$ score and the conducted user study.
Collection and Evaluation of a Long-Term 4D Agri-Robotic Dataset
Nov 25, 2022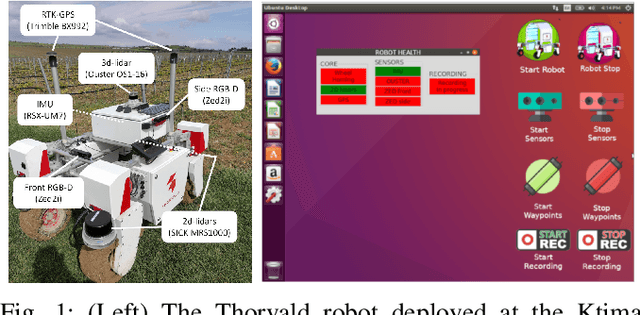


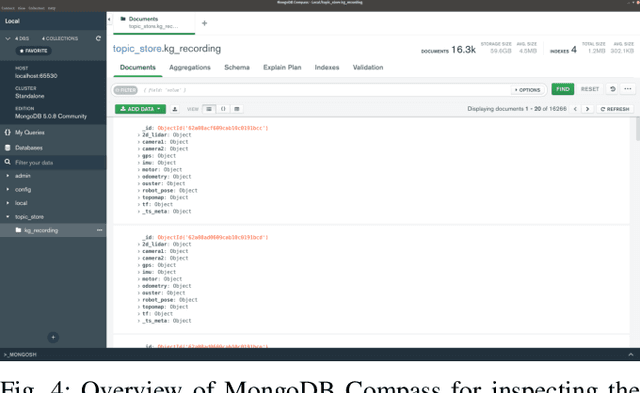
Long-term autonomy is one of the most demanded capabilities looked into a robot. The possibility to perform the same task over and over on a long temporal horizon, offering a high standard of reproducibility and robustness, is appealing. Long-term autonomy can play a crucial role in the adoption of robotics systems for precision agriculture, for example in assisting humans in monitoring and harvesting crops in a large orchard. With this scope in mind, we report an ongoing effort in the long-term deployment of an autonomous mobile robot in a vineyard for data collection across multiple months. The main aim is to collect data from the same area at different points in time so to be able to analyse the impact of the environmental changes in the mapping and localisation tasks. In this work, we present a map-based localisation study taking 4 data sessions. We identify expected failures when the pre-built map visually differs from the environment's current appearance and we anticipate LTS-Net, a solution pointed at extracting stable temporal features for improving long-term 4D localisation results.
Policy-Adaptive Estimator Selection for Off-Policy Evaluation
Nov 25, 2022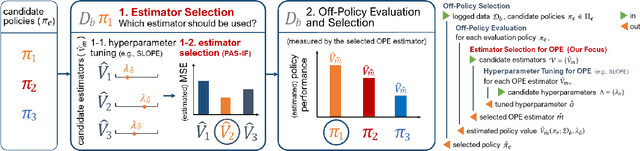
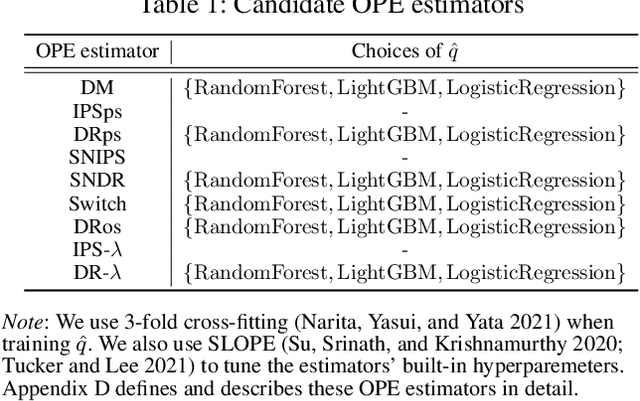
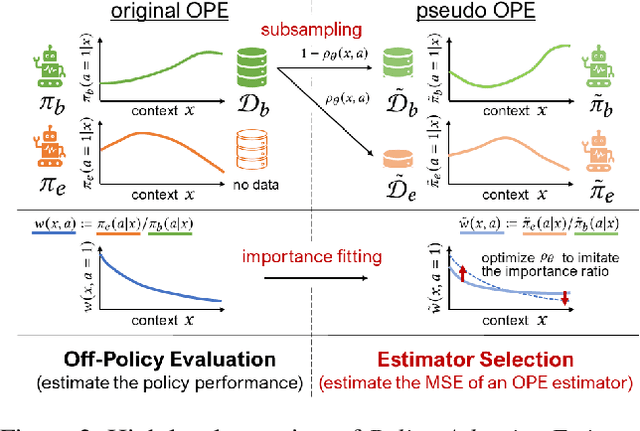

Off-policy evaluation (OPE) aims to accurately evaluate the performance of counterfactual policies using only offline logged data. Although many estimators have been developed, there is no single estimator that dominates the others, because the estimators' accuracy can vary greatly depending on a given OPE task such as the evaluation policy, number of actions, and noise level. Thus, the data-driven estimator selection problem is becoming increasingly important and can have a significant impact on the accuracy of OPE. However, identifying the most accurate estimator using only the logged data is quite challenging because the ground-truth estimation accuracy of estimators is generally unavailable. This paper studies this challenging problem of estimator selection for OPE for the first time. In particular, we enable an estimator selection that is adaptive to a given OPE task, by appropriately subsampling available logged data and constructing pseudo policies useful for the underlying estimator selection task. Comprehensive experiments on both synthetic and real-world company data demonstrate that the proposed procedure substantially improves the estimator selection compared to a non-adaptive heuristic.