 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dynamic Bandits with an Auto-Regressive Temporal Structure
Oct 28, 2022
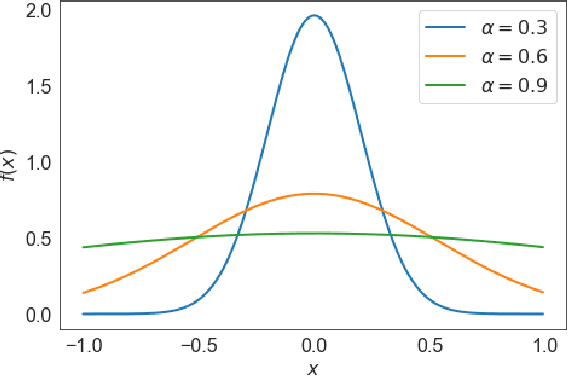
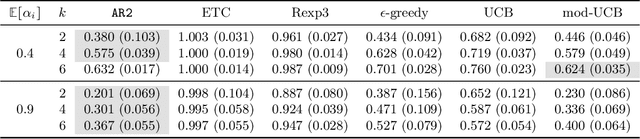
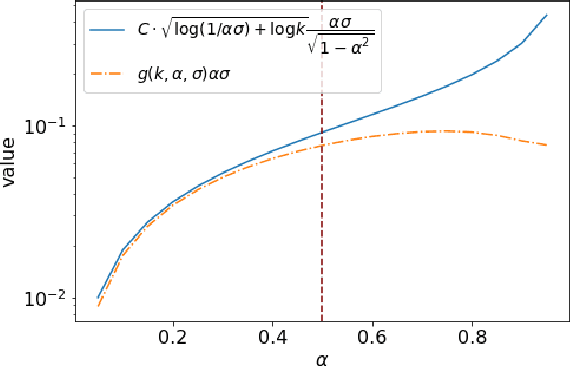
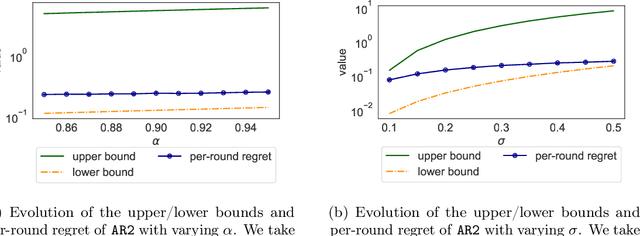
Multi-armed bandit (MAB) problems are mainly studied under two extreme settings known as stochastic and adversarial. These two settings, however, do not capture realistic environments such as search engines and marketing and advertising, in which rewards stochastically change in time. Motivated by that, we introduce and study a dynamic MAB problem with stochastic temporal structure, where the expected reward of each arm is governed by an auto-regressive (AR) model. Due to the dynamic nature of the rewards, simple "explore and commit" policies fail, as all arms have to be explored continuously over time. We formalize this by characterizing a per-round regret lower bound, where the regret is measured against a strong (dynamic) benchmark. We then present an algorithm whose per-round regret almost matches our regret lower bound. Our algorithm relies on two mechanisms: (i) alternating between recently pulled arms and unpulled arms with potential, and (ii) restarting. These mechanisms enable the algorithm to dynamically adapt to changes and discard irrelevant past information at a suitable rate. In numerical studies, we further demonstrate the strength of our algorithm under different types of non-stationary settings.
Stabilizing Machine Learning Prediction of Dynamics: Noise and Noise-inspired Regularization
Nov 09, 2022
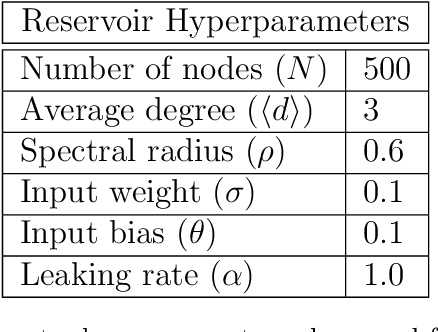
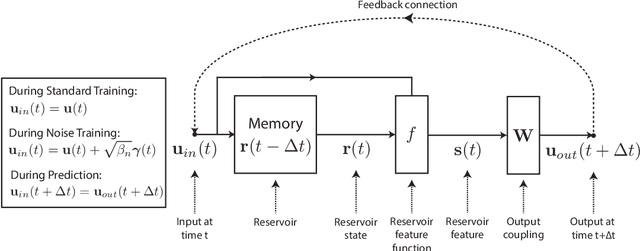
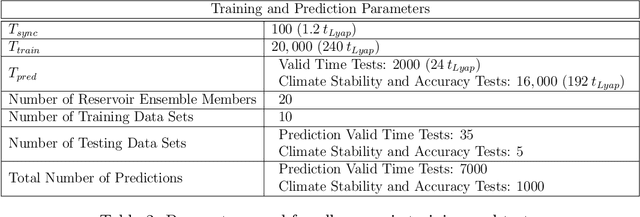
Recent work has shown that machine learning (ML) models can be trained to accurately forecast the dynamics of unknown chaotic dynamical systems. Such ML models can be used to produce both short-term predictions of the state evolution and long-term predictions of the statistical patterns of the dynamics (``climate''). Both of these tasks can be accomplished by employing a feedback loop, whereby the model is trained to predict forward one time step, then the trained model is iterated for multiple time steps with its output used as the input. In the absence of mitigating techniques, however, this technique can result in artificially rapid error growth, leading to inaccurate predictions and/or climate instability. In this article, we systematically examine the technique of adding noise to the ML model input during training as a means to promote stability and improve prediction accuracy. Furthermore, we introduce Linearized Multi-Noise Training (LMNT), a regularization technique that deterministically approximates the effect of many small, independent noise realizations added to the model input during training. Our case study uses reservoir computing, a machine-learning method using recurrent neural networks, to predict the spatiotemporal chaotic Kuramoto-Sivashinsky equation. We find that reservoir computers trained with noise or with LMNT produce climate predictions that appear to be indefinitely stable and have a climate very similar to the true system, while reservoir computers trained without regularization are unstable. Compared with other types of regularization that yield stability in some cases, we find that both short-term and climate predictions from reservoir computers trained with noise or with LMNT are substantially more accurate. Finally, we show that the deterministic aspect of our LMNT regularization facilitates fast hyperparameter tuning when compared to training with noise.
A Critical Analysis of Classifier Selection in Learned Bloom Filters
Nov 28, 2022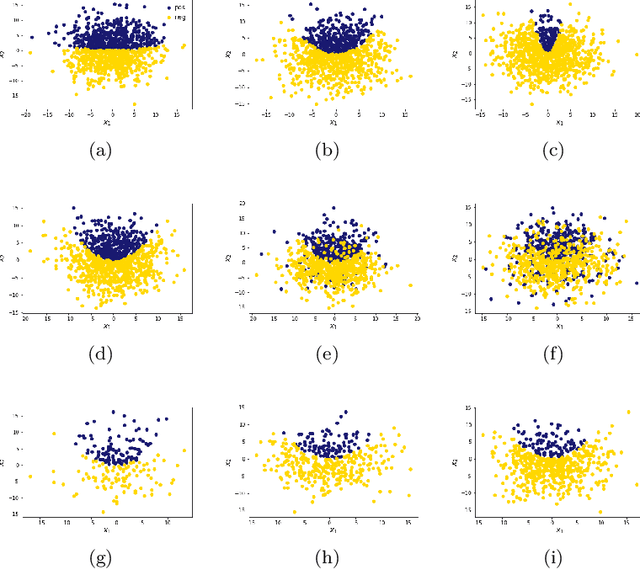

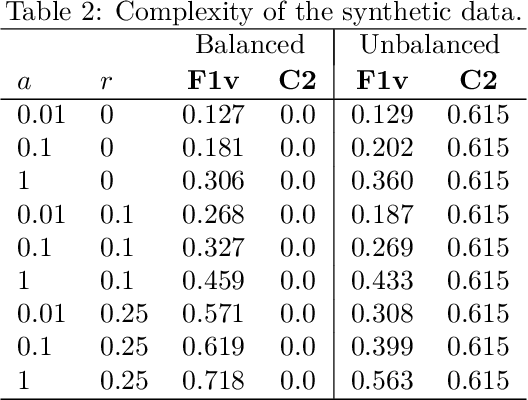
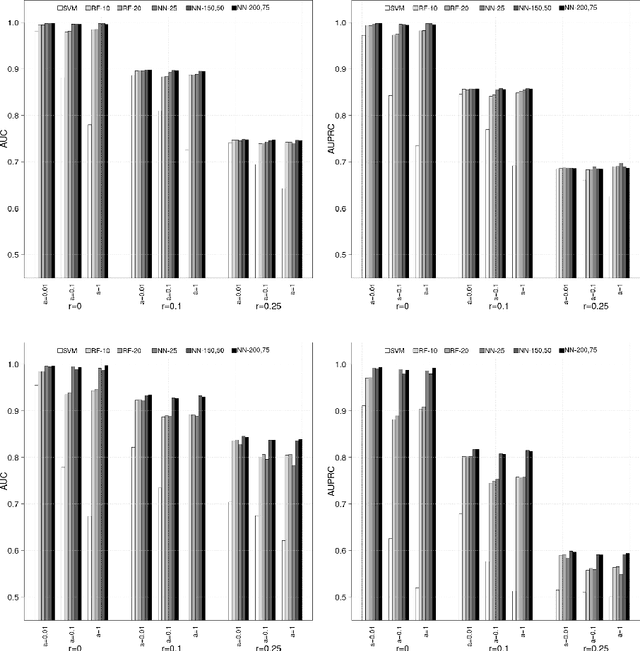
Learned Bloom Filters, i.e., models induced from data via machine learning techniques and solving the approximate set membership problem, have recently been introduced with the aim of enhancing the performance of standard Bloom Filters, with special focus on space occupancy. Unlike in the classical case, the "complexity" of the data used to build the filter might heavily impact on its performance. Therefore, here we propose the first in-depth analysis, to the best of our knowledge, for the performance assessment of a given Learned Bloom Filter, in conjunction with a given classifier, on a dataset of a given classification complexity. Indeed, we propose a novel methodology, supported by software, for designing, analyzing and implementing Learned Bloom Filters in function of specific constraints on their multi-criteria nature (that is, constraints involving space efficiency, false positive rate, and reject time). Our experiments show that the proposed methodology and the supporting software are valid and useful: we find out that only two classifiers have desirable properties in relation to problems with different data complexity, and, interestingly, none of them has been considered so far in the literature. We also experimentally show that the Sandwiched variant of Learned Bloom filters is the most robust to data complexity and classifier performance variability, as well as those usually having smaller reject times. The software can be readily used to test new Learned Bloom Filter proposals, which can be compared with the best ones identified here.
Learning Recommendations from User Actions in the Item-poor Insurance Domain
Nov 28, 2022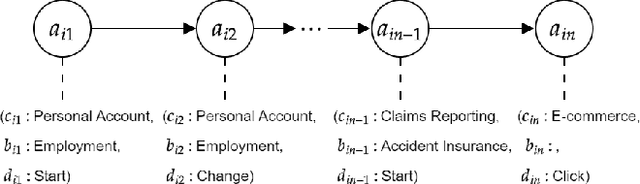

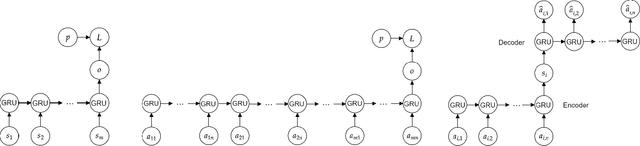
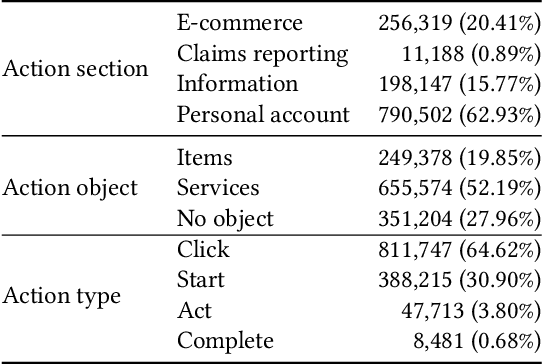
While personalised recommendations are successful in domains like retail, where large volumes of user feedback on items are available, the generation of automatic recommendations in data-sparse domains, like insurance purchasing, is an open problem. The insurance domain is notoriously data-sparse because the number of products is typically low (compared to retail) and they are usually purchased to last for a long time. Also, many users still prefer the telephone over the web for purchasing products, reducing the amount of web-logged user interactions. To address this, we present a recurrent neural network recommendation model that uses past user sessions as signals for learning recommendations. Learning from past user sessions allows dealing with the data scarcity of the insurance domain. Specifically, our model learns from several types of user actions that are not always associated with items, and unlike all prior session-based recommendation models, it models relationships between input sessions and a target action (purchasing insurance) that does not take place within the input sessions. Evaluation on a real-world dataset from the insurance domain (ca. 44K users, 16 items, 54K purchases, and 117K sessions) against several state-of-the-art baselines shows that our model outperforms the baselines notably. Ablation analysis shows that this is mainly due to the learning of dependencies across sessions in our model. We contribute the first ever session-based model for insurance recommendation, and make available our dataset to the research community.
Accelerated Nonnegative Tensor Completion via Integer Programming
Nov 28, 2022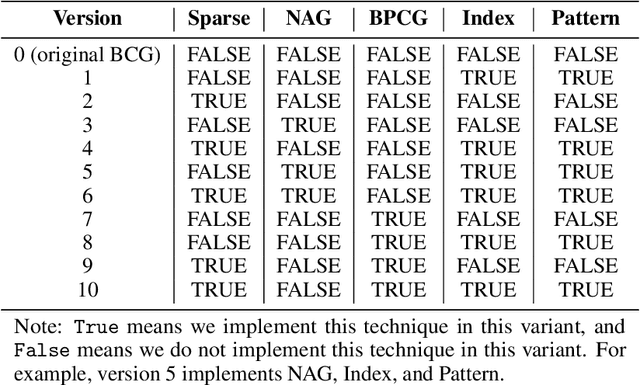
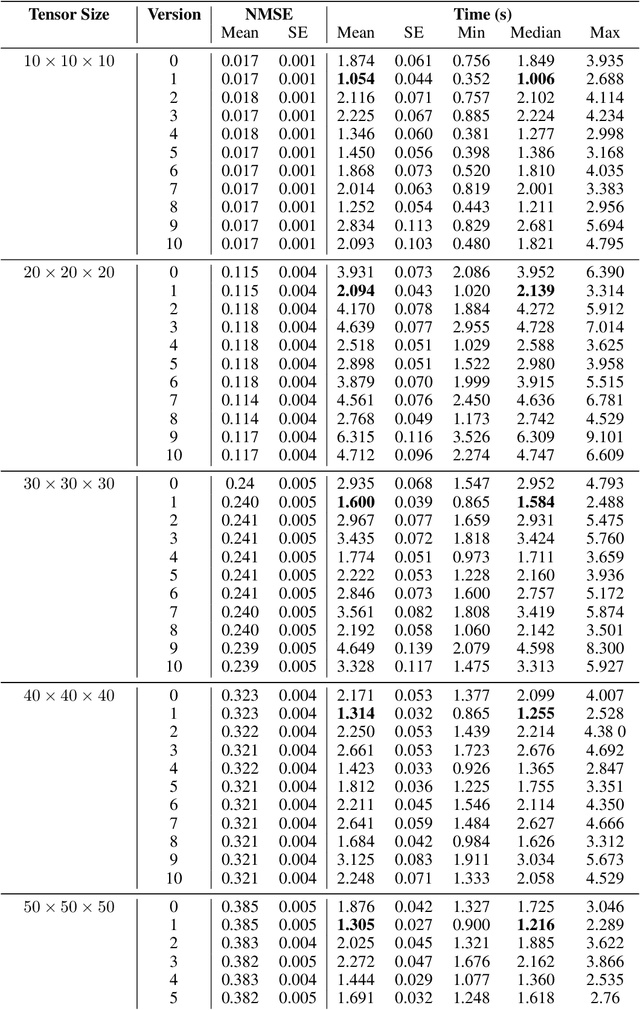
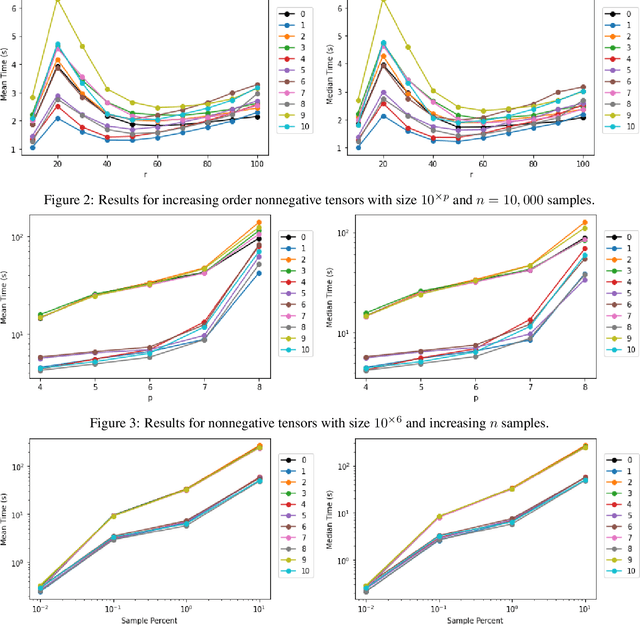
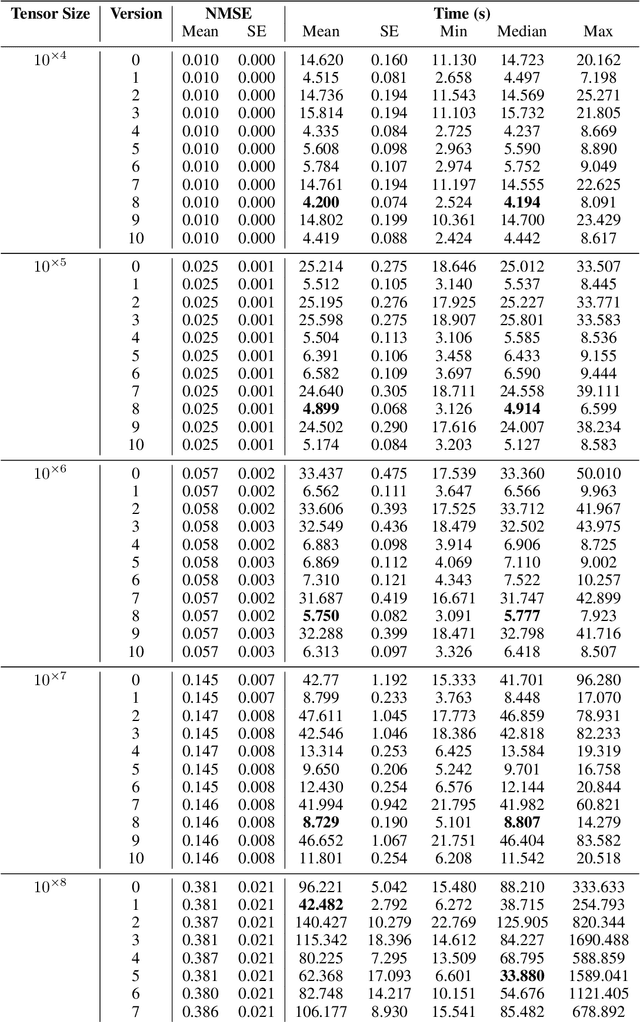
The problem of tensor completion has applications in healthcare, computer vision, and other domains. However, past approaches to tensor completion have faced a tension in that they either have polynomial-time computation but require exponentially more samples than the information-theoretic rate, or they use fewer samples but require solving NP-hard problems for which there are no known practical algorithms. A recent approach, based on integer programming, resolves this tension for nonnegative tensor completion. It achieves the information-theoretic sample complexity rate and deploys the Blended Conditional Gradients algorithm, which requires a linear (in numerical tolerance) number of oracle steps to converge to the global optimum. The tradeoff in this approach is that, in the worst case, the oracle step requires solving an integer linear program. Despite this theoretical limitation, numerical experiments show that this algorithm can, on certain instances, scale up to 100 million entries while running on a personal computer. The goal of this paper is to further enhance this algorithm, with the intention to expand both the breadth and scale of instances that can be solved. We explore several variants that can maintain the same theoretical guarantees as the algorithm, but offer potentially faster computation. We consider different data structures, acceleration of gradient descent steps, and the use of the Blended Pairwise Conditional Gradients algorithm. We describe the original approach and these variants, and conduct numerical experiments in order to explore various tradeoffs in these algorithmic design choices.
Edge-based Monocular Thermal-Inertial Odometry in Visually Degraded Environments
Oct 18, 2022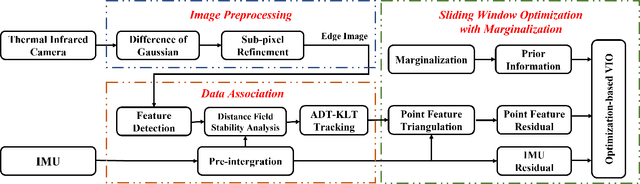
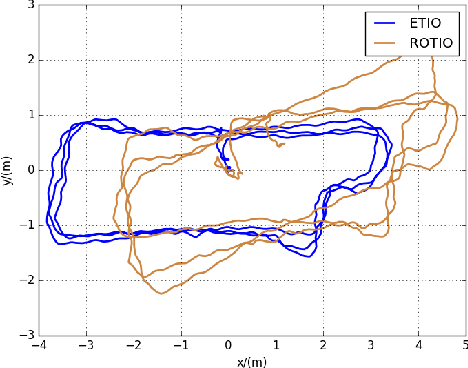
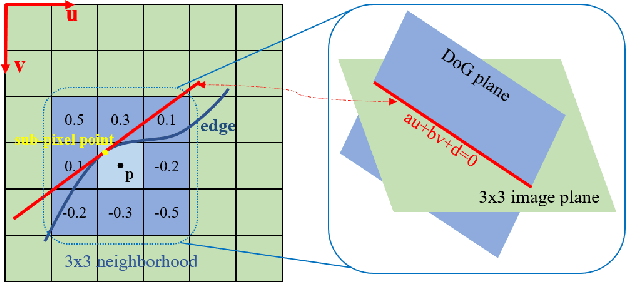
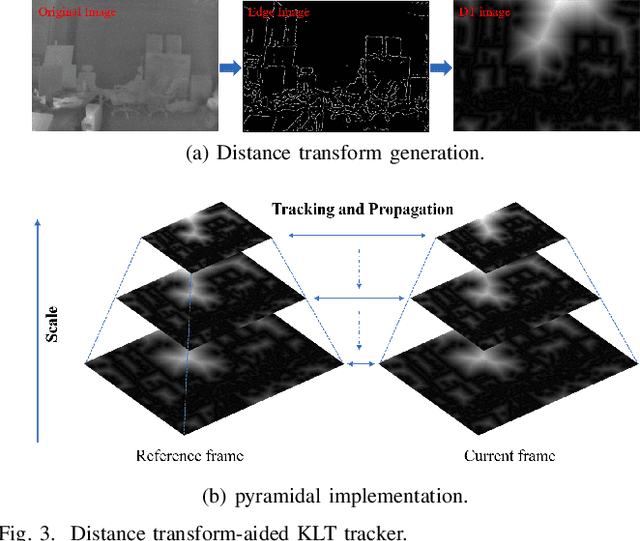
State estimation in complex illumination environments based on conventional visual-inertial odometry is a challenging task due to the severe visual degradation of the visual camera. The thermal infrared camera is capable of all-day time and is less affected by illumination variation. However, most existing visual data association algorithms are incompatible because the thermal infrared data contains large noise and low contrast. Motivated by the phenomenon that thermal radiation varies most significantly at the edges of objects, the study proposes an ETIO, which is the first edge-based monocular thermal-inertial odometry for robust localization in visually degraded environments. Instead of the raw image, we utilize the binarized image from edge extraction for pose estimation to overcome the poor thermal infrared image quality. Then, an adaptive feature tracking strategy ADT-KLT is developed for robust data association based on limited edge information and its distance distribution. Finally, a pose graph optimization performs real-time estimation over a sliding window of recent states by combining IMU pre-integration with reprojection error of all edge feature observations. We evaluated the performance of the proposed system on public datasets and real-world experiments and compared it against state-of-the-art methods. The proposed ETIO was verified with the ability to enable accurate and robust localization all-day time.
Contribution to the initialization of linear non-commensurate fractional-order systems for the joint estimation of parameters and fractional differentiation orders
Oct 18, 2022
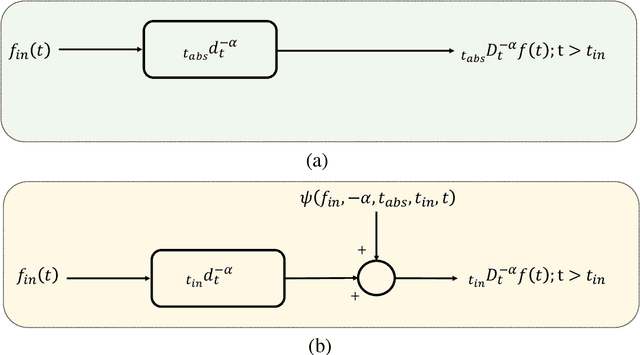
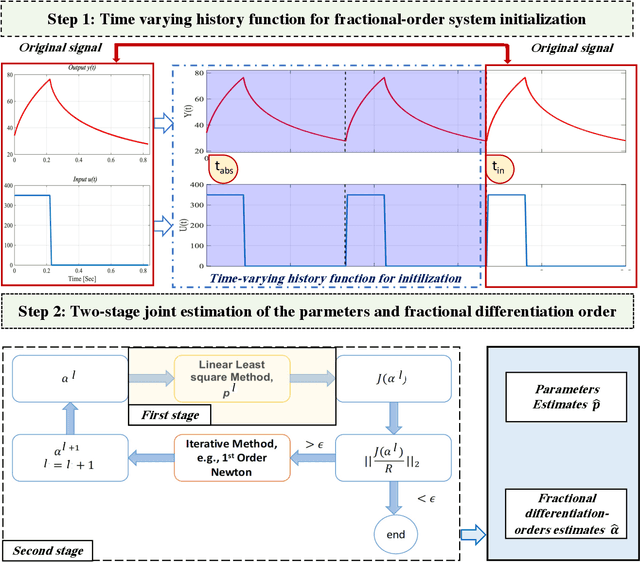
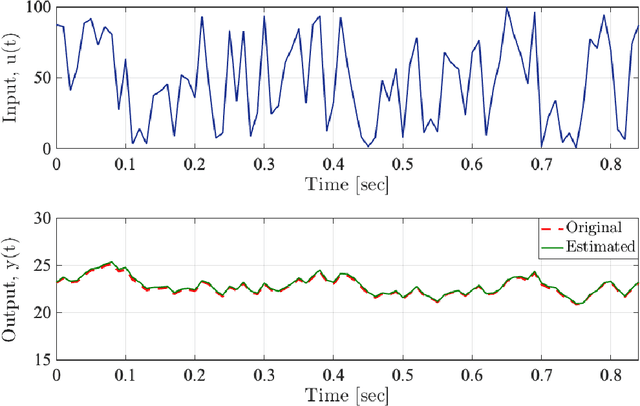
It has been recognized that using time-varying initialization functions to solve the initial value problem of fractional-order systems (FOS) is both complex and essential in defining the dynamical behavior of the states of FOSs. In this paper, we investigate the use of the initialization functions for the purpose of estimating unknown parameters of linear non-commensurate FOSs. In particular, we propose a novel "pre-initial" process that describes the dynamic characteristic of FOSs before the initial state and consists of designing an appropriate time-varying initialization function that ensures accurate convergence of the estimates of the unknown parameters. To do so, we propose an estimation technique that consists of two steps: (i) to design of practical initialization function that is output-dependent and which is employed; (ii) to solve the joint estimation problem of both parameters and fractional differentiation orders (FDOs). A convergence proof has been presented. The performance of the proposed method is illustrated through different numerical examples. Potential applications of the algorithm to joint estimation of parameters and FDOs of the fractional arterial Windkessel and neurovascular models are also presented using both synthetic and real data. The added value of the proposed "pre-initial" process to solve the studied estimation problem is shown through different simulation tests that investigate the sensitivity of estimation results using different time-varying initialization functions.
Data-Driven Distributionally Robust Electric Vehicle Balancing for Autonomous Mobility-on-Demand Systems under Demand and Supply Uncertainties
Nov 24, 2022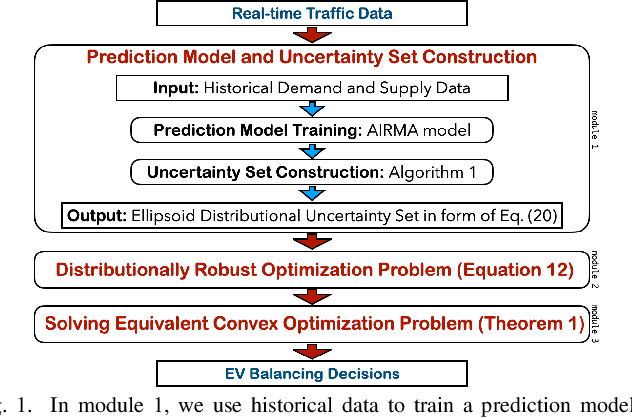
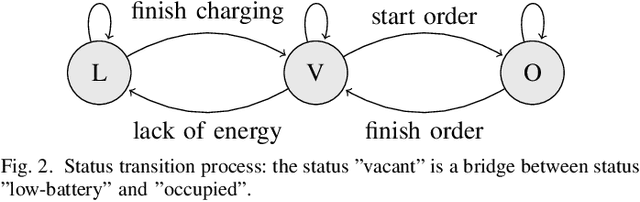
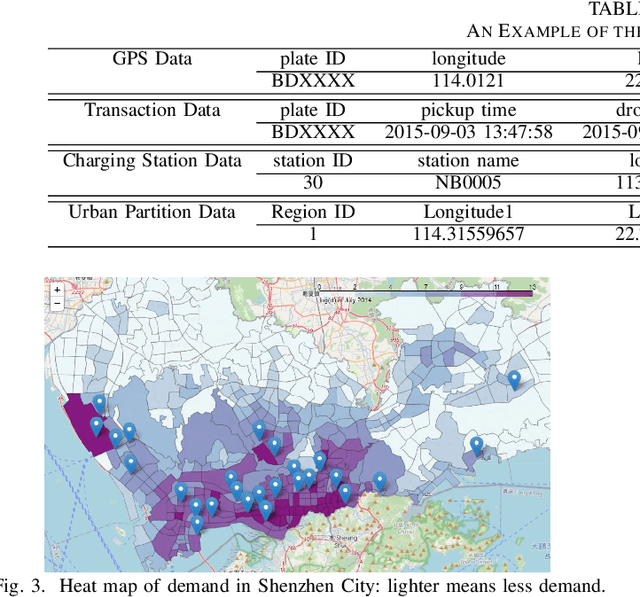
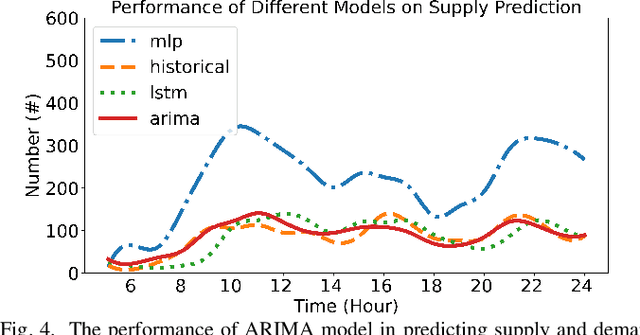
Electric vehicles (EVs) are being rapidly adopted due to their economic and societal benefits. Autonomous mobility-on-demand (AMoD) systems also embrace this trend. However, the long charging time and high recharging frequency of EVs pose challenges to efficiently managing EV AMoD systems. The complicated dynamic charging and mobility process of EV AMoD systems makes the demand and supply uncertainties significant when designing vehicle balancing algorithms. In this work, we design a data-driven distributionally robust optimization (DRO) approach to balance EVs for both the mobility service and the charging process. The optimization goal is to minimize the worst-case expected cost under both passenger mobility demand uncertainties and EV supply uncertainties. We then propose a novel distributional uncertainty sets construction algorithm that guarantees the produced parameters are contained in desired confidence regions with a given probability. To solve the proposed DRO AMoD EV balancing problem, we derive an equivalent computationally tractable convex optimization problem. Based on real-world EV data of a taxi system, we show that with our solution the average total balancing cost is reduced by 14.49%, and the average mobility fairness and charging fairness are improved by 15.78% and 34.51%, respectively, compared to solutions that do not consider uncertainties.
PyTAIL: Interactive and Incremental Learning of NLP Models with Human in the Loop for Online Data
Nov 24, 2022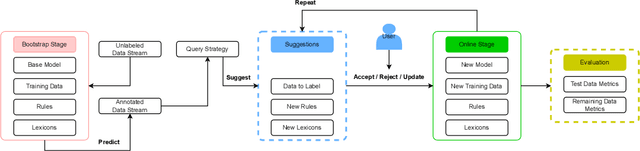
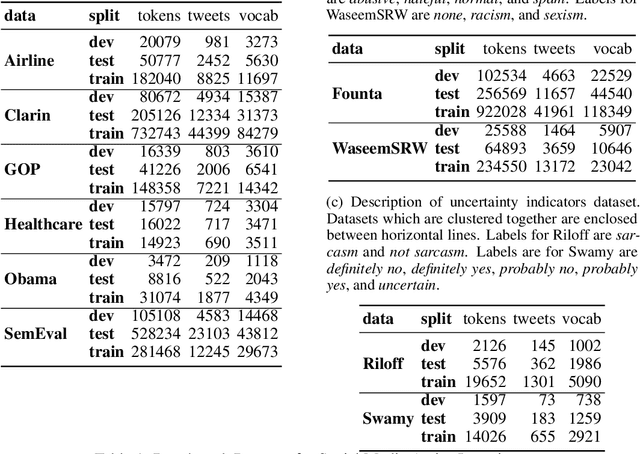
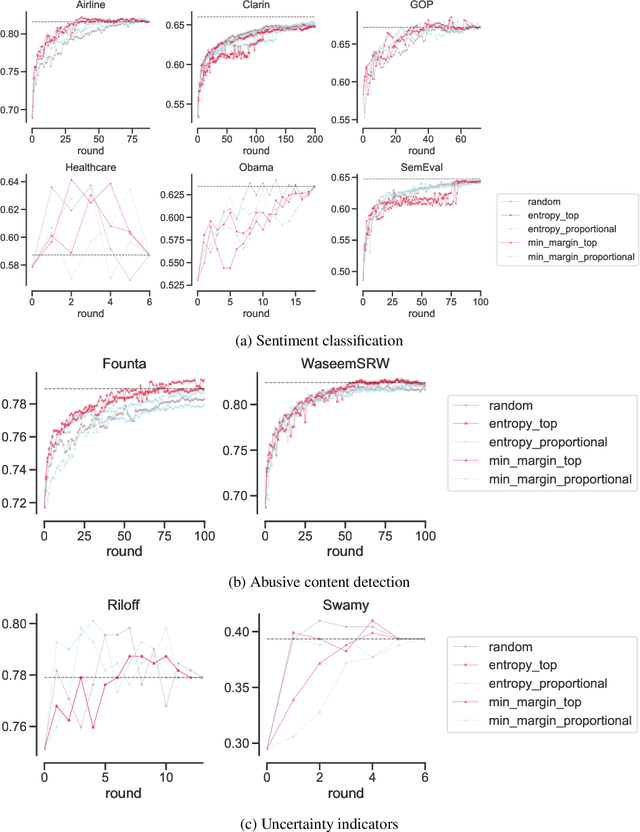
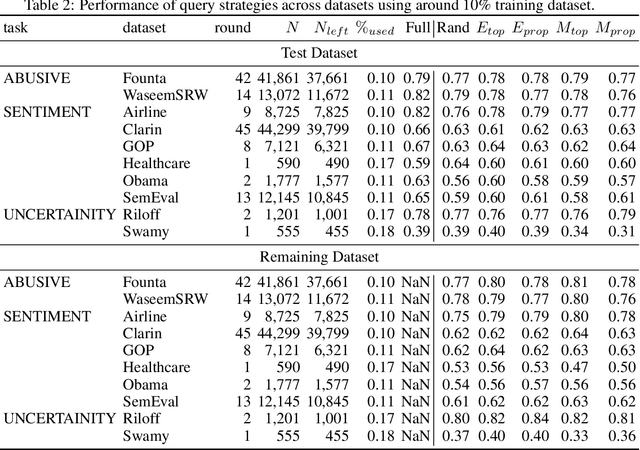
Online data streams make training machine learning models hard because of distribution shift and new patterns emerging over time. For natural language processing (NLP) tasks that utilize a collection of features based on lexicons and rules, it is important to adapt these features to the changing data. To address this challenge we introduce PyTAIL, a python library, which allows a human in the loop approach to actively train NLP models. PyTAIL enhances generic active learning, which only suggests new instances to label by also suggesting new features like rules and lexicons to label. Furthermore, PyTAIL is flexible enough for users to accept, reject, or update rules and lexicons as the model is being trained. Finally, we simulate the performance of PyTAIL on existing social media benchmark datasets for text classification. We compare various active learning strategies on these benchmarks. The model closes the gap with as few as 10% of the training data. Finally, we also highlight the importance of tracking evaluation metric on remaining data (which is not yet merged with active learning) alongside the test dataset. This highlights the effectiveness of the model in accurately annotating the remaining dataset, which is especially suitable for batch processing of large unlabelled corpora. PyTAIL will be available at https://github.com/socialmediaie/pytail.
Learning to Play Trajectory Games Against Opponents with Unknown Objectives
Nov 24, 2022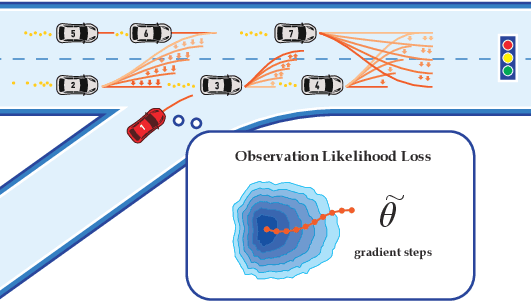
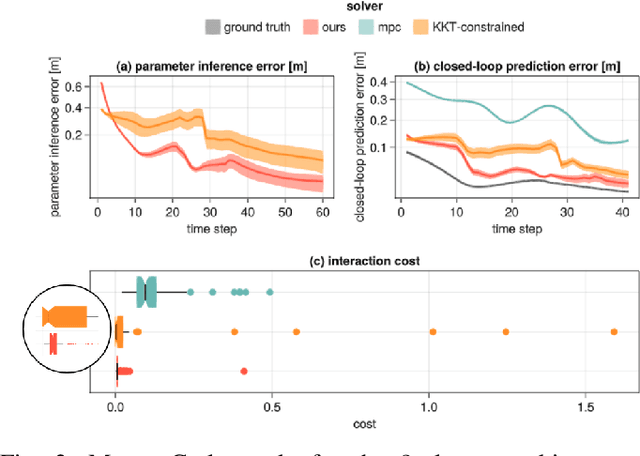
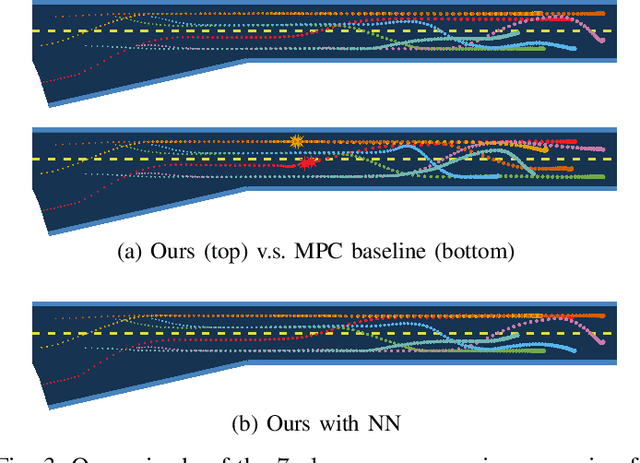
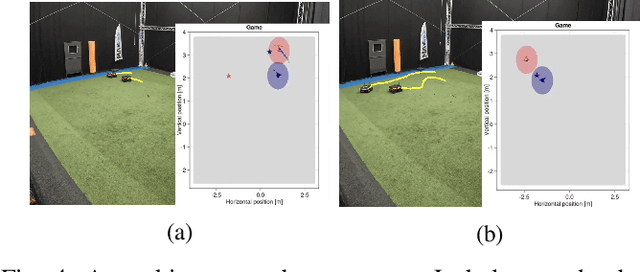
Many autonomous agents, such as intelligent vehicles, are inherently required to interact with one another. Game theory provides a natural mathematical tool for robot motion planning in such interactive settings. However, tractable algorithms for such problems usually rely on a strong assumption, namely that the objectives of all players in the scene are known. To make such tools applicable for ego-centric planning with only local information, we propose an adaptive model-predictive game solver, which jointly infers other players' objectives online and computes a corresponding generalized Nash equilibrium (GNE) strategy. The adaptivity of our approach is enabled by a differentiable trajectory game solver whose gradient signal is used for maximum likelihood estimation (MLE) of opponents' objectives. This differentiability of our pipeline facilitates direct integration with other differentiable elements, such as neural networks (NNs). Furthermore, in contrast to existing solvers for cost inference in games, our method handles not only partial state observations but also general inequality constraints. In two simulated traffic scenarios, we find superior performance of our approach over both existing game-theoretic methods and non-game-theoretic model-predictive control (MPC) approaches. We also demonstrate the real-time planning capabilities and robustness of our approach in a hardware experiment.