 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Leveraging Memory Effects and Gradient Information in Consensus-Based Optimization: On Global Convergence in Mean-Field Law
Nov 22, 2022
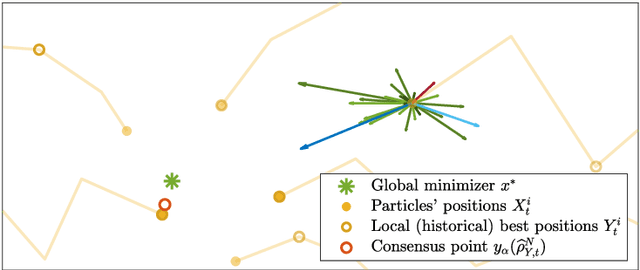
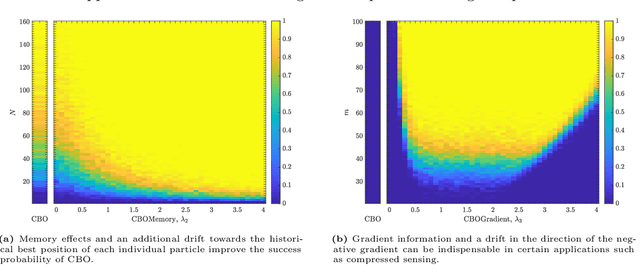
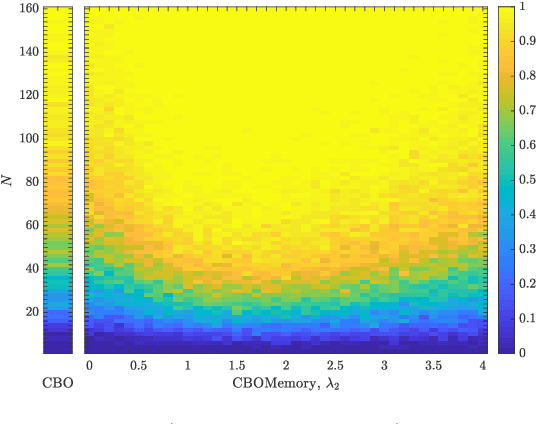

In this paper we study consensus-based optimization (CBO), a versatile, flexibel and customizable optimization method suitable for performing nonconvex and nonsmooth global optimizations in high dimensions. CBO is a multi-particle metaheuristic, which is effective in various applications and at the same time amenable to theoretical analysis thanks to its minimalistic design. The underlying dynamics, however, is flexible enough to incorporate different mechanisms widely used in evolutionary computation and machine learning, as we show by analyzing a variant of CBO which makes use of memory effects and gradient information. We rigorously prove that this dynamics converges to a global minimizer of the objective function in mean-field law for a vast class of functions under minimal assumptions on the initialization of the method. The proof in particular reveals how to leverage further, in some applications advantageous, forces in the dynamics without loosing provable global convergence. To demonstrate the benefit of the herein investigated memory effects and gradient information in certain applications, we present numerical evidence for the superiority of this CBO variant in applications such as machine learning and compressed sensing, which en passant widen the scope of applications of CBO.
Cosmology from Galaxy Redshift Surveys with PointNet
Nov 22, 2022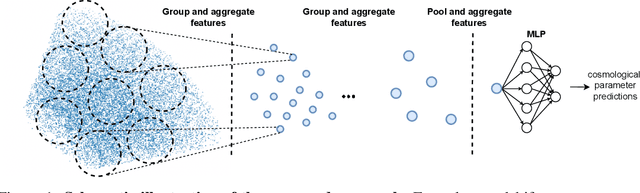
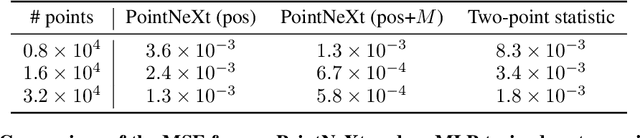
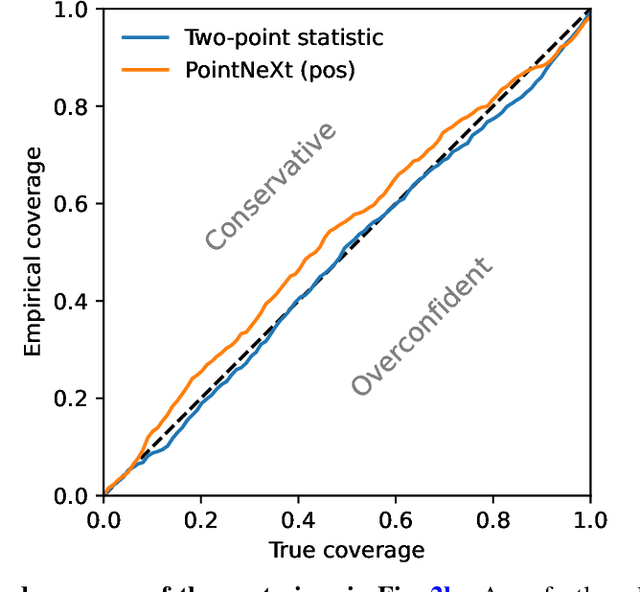
In recent years, deep learning approaches have achieved state-of-the-art results in the analysis of point cloud data. In cosmology, galaxy redshift surveys resemble such a permutation invariant collection of positions in space. These surveys have so far mostly been analysed with two-point statistics, such as power spectra and correlation functions. The usage of these summary statistics is best justified on large scales, where the density field is linear and Gaussian. However, in light of the increased precision expected from upcoming surveys, the analysis of -- intrinsically non-Gaussian -- small angular separations represents an appealing avenue to better constrain cosmological parameters. In this work, we aim to improve upon two-point statistics by employing a \textit{PointNet}-like neural network to regress the values of the cosmological parameters directly from point cloud data. Our implementation of PointNets can analyse inputs of $\mathcal{O}(10^4) - \mathcal{O}(10^5)$ galaxies at a time, which improves upon earlier work for this application by roughly two orders of magnitude. Additionally, we demonstrate the ability to analyse galaxy redshift survey data on the lightcone, as opposed to previously static simulation boxes at a given fixed redshift.
Design and Performance Analysis of Hardware Realization of 3GPP Physical Layer for 5G Cell Search
Nov 22, 2022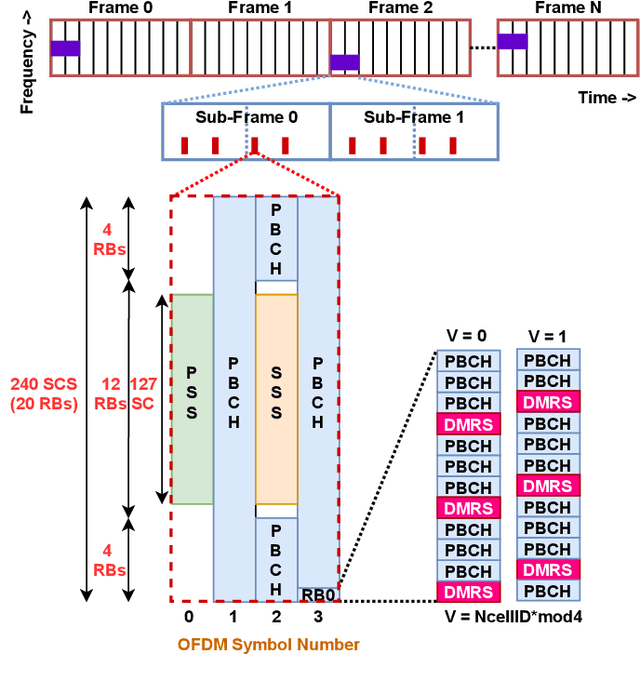
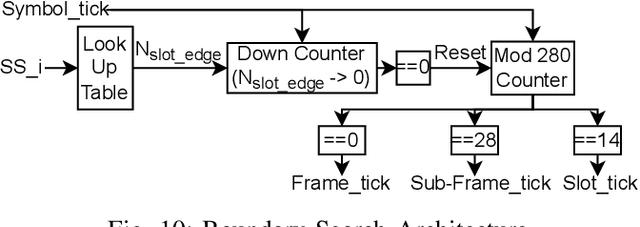
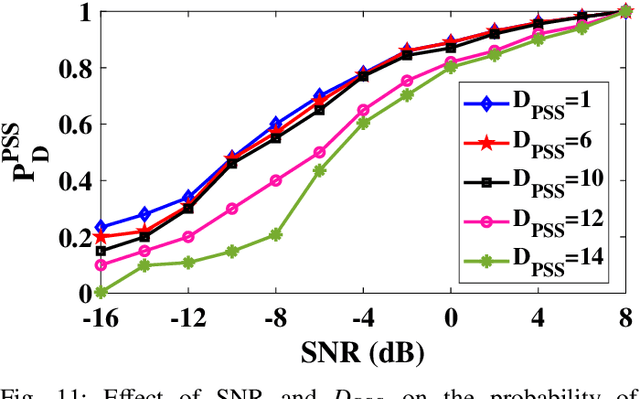
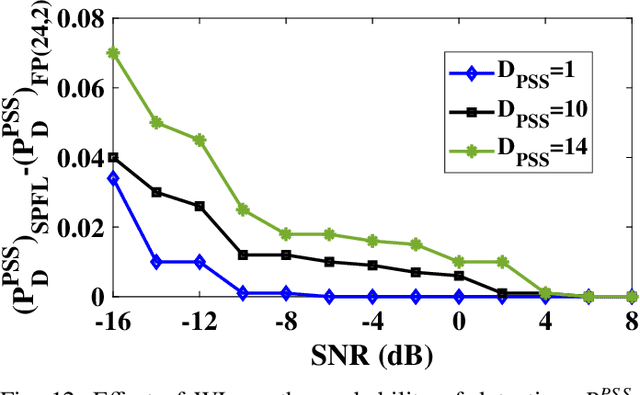
5G Cell Search (CS) is the first step for user equipment (UE) to initiate the communication with the 5G node B (gNB) every time it is powered ON. In cellular networks, CS is accomplished via synchronization signals (SS) broadcasted by gNB. 5G 3rd generation partnership project (3GPP) specifications offer a detailed discussion on the SS generation at gNB but a limited understanding of their blind search, and detection is available. Unlike 4G, 5G SS may not be transmitted at the center of carrier frequency and their frequency location is unknown to UE. In this work, we demonstrate the 5G CS by designing 3GPP compatible hardware realization of the physical layer (PHY) of the gNB transmitter and UE receiver. The proposed SS detection explores a novel down-sampling approach resulting in a significant reduction in complexity and latency. Via detailed performance analysis, we analyze the functional correctness, computational complexity, and latency of the proposed approach for different word lengths, signal-to-noise ratio (SNR), and down-sampling factors. We demonstrate the complete CS functionality on GNU Radio-based RFNoC framework and USRP-FPGA platform. The 3GPP compatibility and demonstration on hardware strengthen the commercial significance of the proposed work.
Solar Power driven EV Charging Optimization with Deep Reinforcement Learning
Nov 17, 2022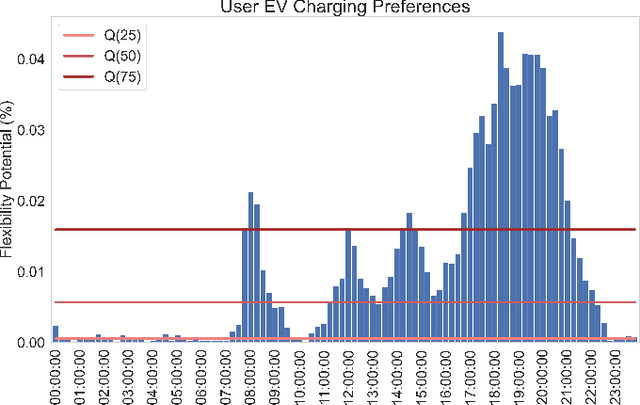
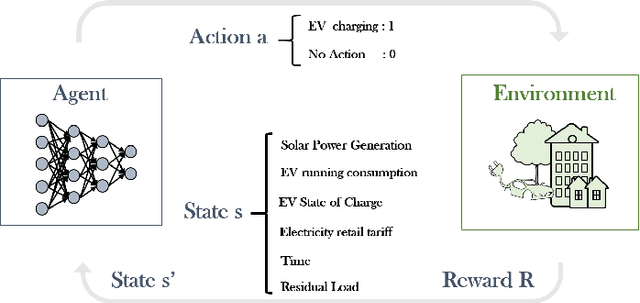
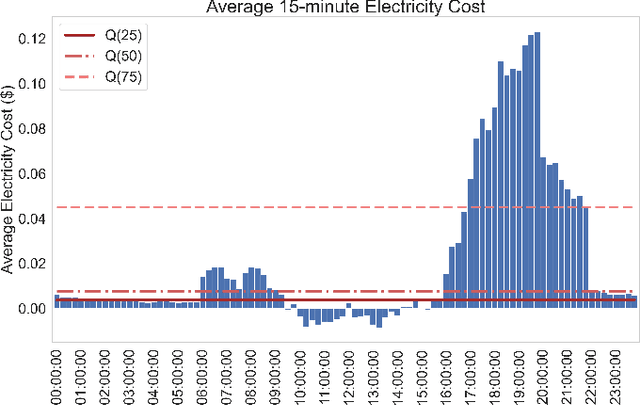
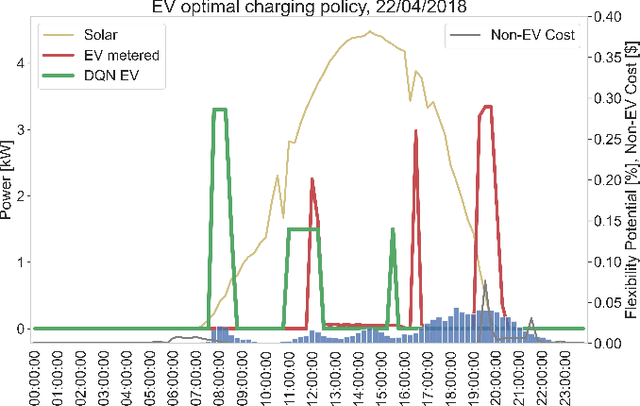
Power sector decarbonization plays a vital role in the upcoming energy transition towards a more sustainable future. Decentralized energy resources, such as Electric Vehicles (EV) and solar photovoltaic systems (PV), are continuously integrated in residential power systems, increasing the risk of bottlenecks in power distribution networks. This paper aims to address the challenge of domestic EV charging while prioritizing clean, solar energy consumption. Real Time-of-Use tariffs are treated as a price-based Demand Response (DR) mechanism that can incentivize end-users to optimally shift EV charging load in hours of high solar PV generation with the use of Deep Reinforcement Learning (DRL). Historical measurements from the Pecan Street dataset are analyzed to shape a flexibility potential reward to describe end-user charging preferences. Experimental results show that the proposed DQN EV optimal charging policy is able to reduce electricity bills by an average 11.5\% by achieving an average utilization of solar power 88.4
Proactive Resilient Transmission and Scheduling Mechanisms for mmWave Networks
Nov 17, 2022
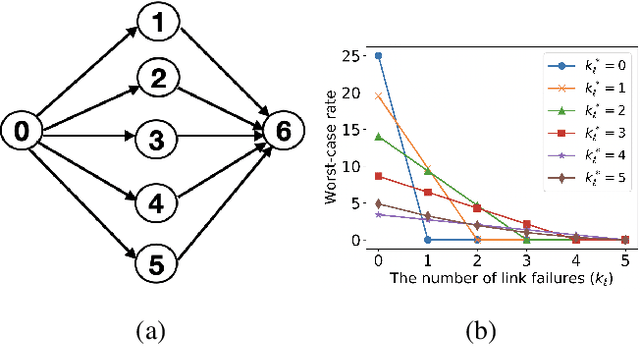
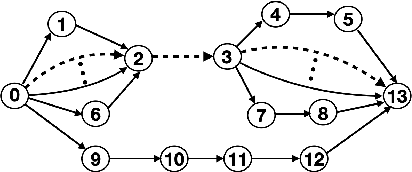
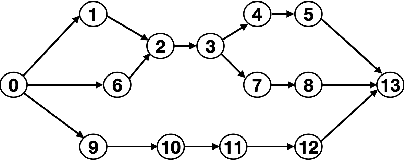
This paper aims to develop resilient transmission mechanisms to suitably distribute traffic across multiple paths in an arbitrary millimeter-wave (mmWave) network. The main contributions include: (a) the development of proactive transmission mechanisms that build resilience against network disruptions in advance, while achieving a high end-to-end packet rate; (b) the design of a heuristic path selection algorithm that efficiently selects (in polynomial time in the network size) multiple proactively resilient paths with high packet rates; and (c) the development of a hybrid scheduling algorithm that combines the proposed path selection algorithm with a deep reinforcement learning (DRL) based online approach for decentralized adaptation to blocked links and failed paths. To achieve resilience to link failures, a state-of-the-art Soft Actor-Critic DRL algorithm, which adapts the information flow through the network, is investigated. The proposed scheduling algorithm robustly adapts to link failures over different topologies, channel and blockage realizations while offering a superior performance to alternative algorithms.
Neural Langevin Dynamics: towards interpretable Neural Stochastic Differential Equations
Nov 17, 2022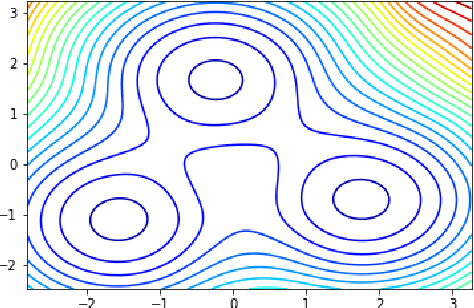
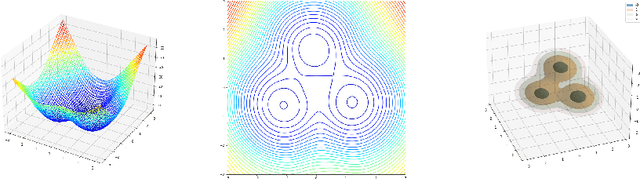
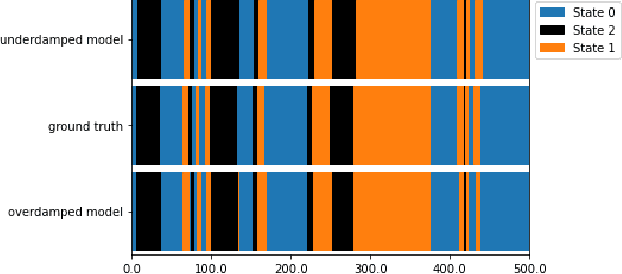
Neural Stochastic Differential Equations (NSDE) have been trained as both Variational Autoencoders, and as GANs. However, the resulting Stochastic Differential Equations can be hard to interpret or analyse due to the generic nature of the drift and diffusion fields. By restricting our NSDE to be of the form of Langevin dynamics, and training it as a VAE, we obtain NSDEs that lend themselves to more elaborate analysis and to a wider range of visualisation techniques than a generic NSDE. More specifically, we obtain an energy landscape, the minima of which are in one-to-one correspondence with latent states underlying the used data. This not only allows us to detect states underlying the data dynamics in an unsupervised manner, but also to infer the distribution of time spent in each state according to the learned SDE. More in general, restricting an NSDE to Langevin dynamics enables the use of a large set of tools from computational molecular dynamics for the analysis of the obtained results.
Dormant Neural Trojans
Nov 02, 2022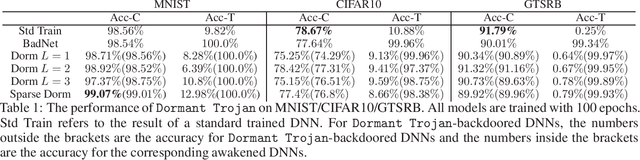
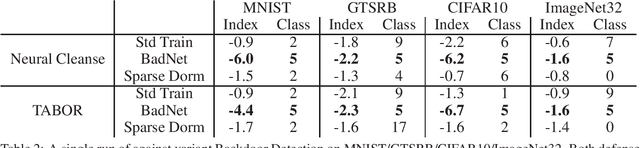

We present a novel methodology for neural network backdoor attacks. Unlike existing training-time attacks where the Trojaned network would respond to the Trojan trigger after training, our approach inserts a Trojan that will remain dormant until it is activated. The activation is realized through a specific perturbation to the network's weight parameters only known to the attacker. Our analysis and the experimental results demonstrate that dormant Trojaned networks can effectively evade detection by state-of-the-art backdoor detection methods.
Learning Recommendations from User Actions in the Item-poor Insurance Domain
Nov 28, 2022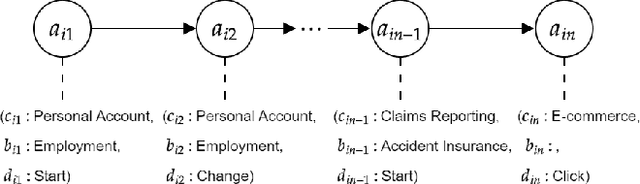

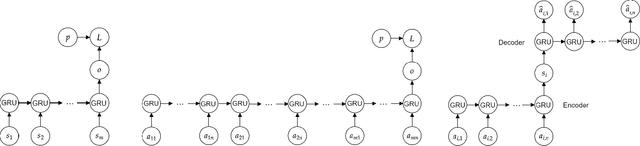
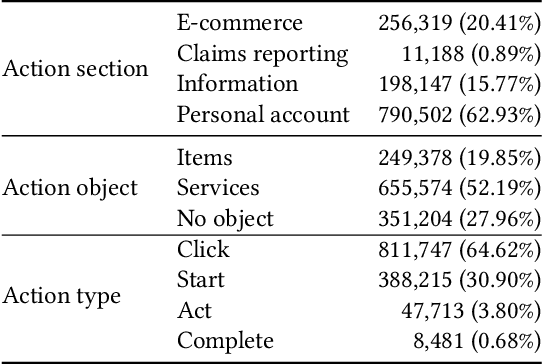
While personalised recommendations are successful in domains like retail, where large volumes of user feedback on items are available, the generation of automatic recommendations in data-sparse domains, like insurance purchasing, is an open problem. The insurance domain is notoriously data-sparse because the number of products is typically low (compared to retail) and they are usually purchased to last for a long time. Also, many users still prefer the telephone over the web for purchasing products, reducing the amount of web-logged user interactions. To address this, we present a recurrent neural network recommendation model that uses past user sessions as signals for learning recommendations. Learning from past user sessions allows dealing with the data scarcity of the insurance domain. Specifically, our model learns from several types of user actions that are not always associated with items, and unlike all prior session-based recommendation models, it models relationships between input sessions and a target action (purchasing insurance) that does not take place within the input sessions. Evaluation on a real-world dataset from the insurance domain (ca. 44K users, 16 items, 54K purchases, and 117K sessions) against several state-of-the-art baselines shows that our model outperforms the baselines notably. Ablation analysis shows that this is mainly due to the learning of dependencies across sessions in our model. We contribute the first ever session-based model for insurance recommendation, and make available our dataset to the research community.
A Critical Analysis of Classifier Selection in Learned Bloom Filters
Nov 28, 2022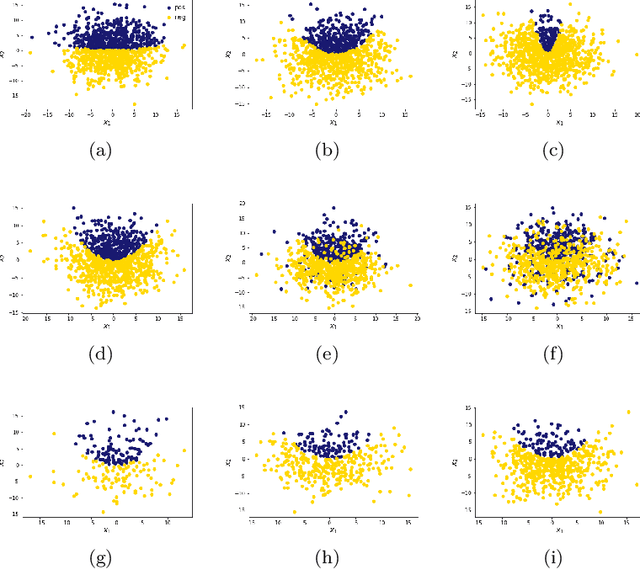

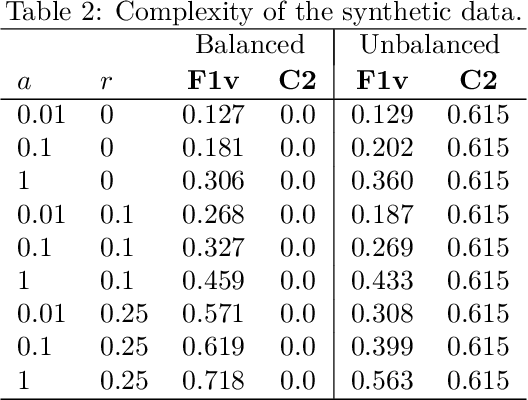
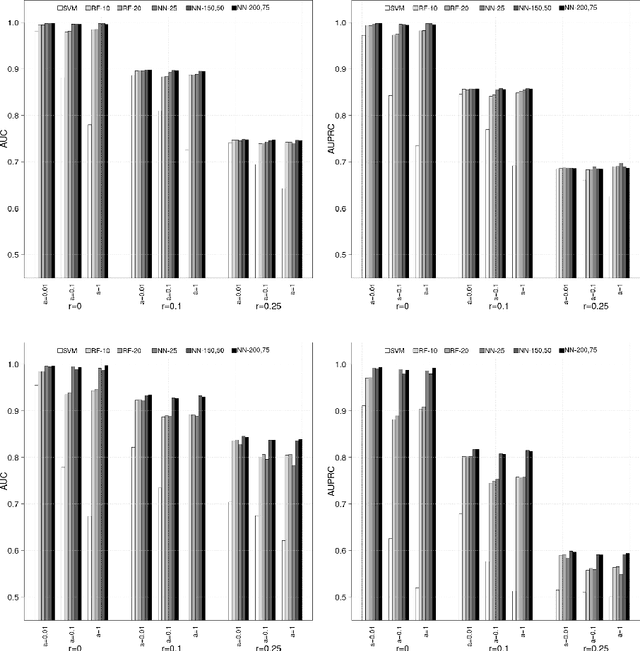
Learned Bloom Filters, i.e., models induced from data via machine learning techniques and solving the approximate set membership problem, have recently been introduced with the aim of enhancing the performance of standard Bloom Filters, with special focus on space occupancy. Unlike in the classical case, the "complexity" of the data used to build the filter might heavily impact on its performance. Therefore, here we propose the first in-depth analysis, to the best of our knowledge, for the performance assessment of a given Learned Bloom Filter, in conjunction with a given classifier, on a dataset of a given classification complexity. Indeed, we propose a novel methodology, supported by software, for designing, analyzing and implementing Learned Bloom Filters in function of specific constraints on their multi-criteria nature (that is, constraints involving space efficiency, false positive rate, and reject time). Our experiments show that the proposed methodology and the supporting software are valid and useful: we find out that only two classifiers have desirable properties in relation to problems with different data complexity, and, interestingly, none of them has been considered so far in the literature. We also experimentally show that the Sandwiched variant of Learned Bloom filters is the most robust to data complexity and classifier performance variability, as well as those usually having smaller reject times. The software can be readily used to test new Learned Bloom Filter proposals, which can be compared with the best ones identified here.
Accelerated Nonnegative Tensor Completion via Integer Programming
Nov 28, 2022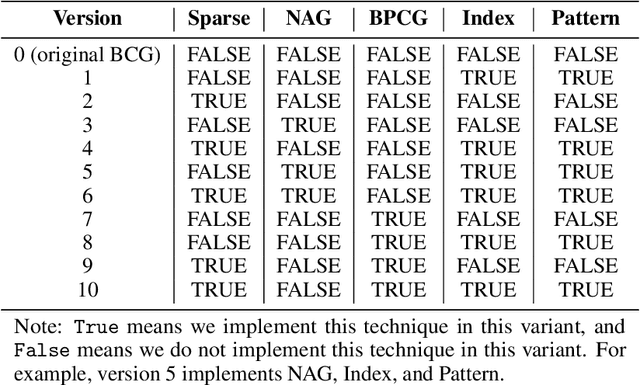
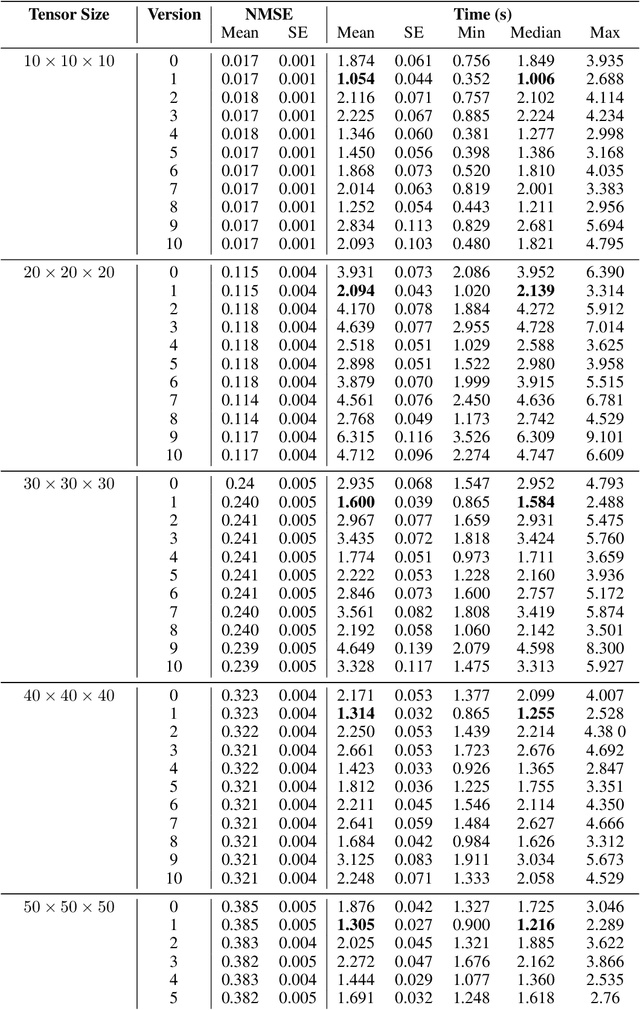
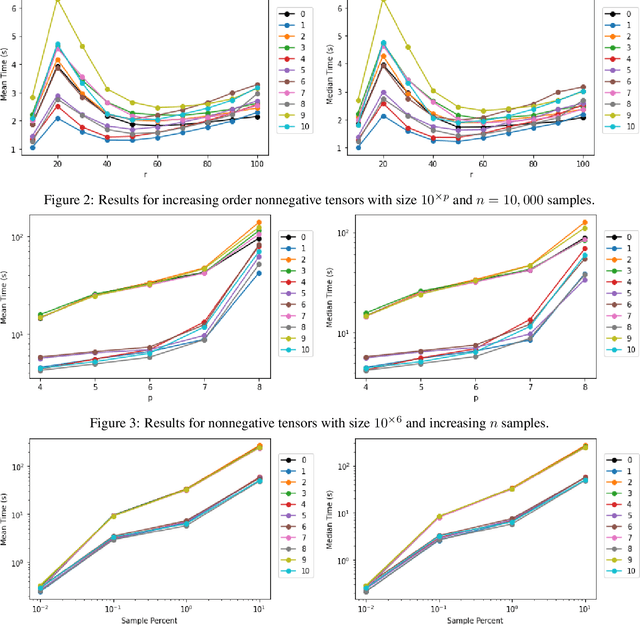
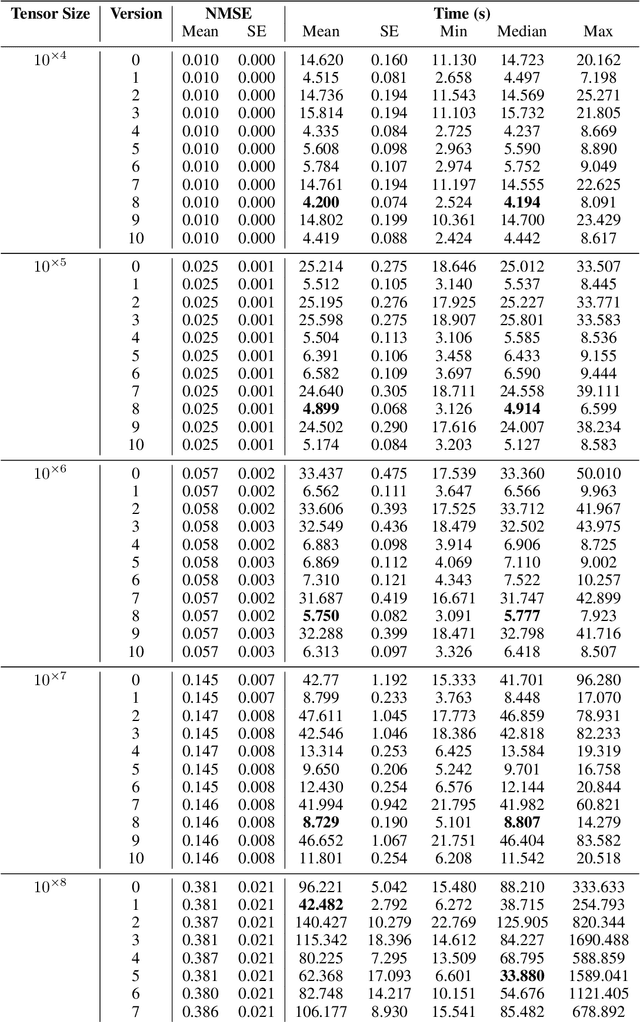
The problem of tensor completion has applications in healthcare, computer vision, and other domains. However, past approaches to tensor completion have faced a tension in that they either have polynomial-time computation but require exponentially more samples than the information-theoretic rate, or they use fewer samples but require solving NP-hard problems for which there are no known practical algorithms. A recent approach, based on integer programming, resolves this tension for nonnegative tensor completion. It achieves the information-theoretic sample complexity rate and deploys the Blended Conditional Gradients algorithm, which requires a linear (in numerical tolerance) number of oracle steps to converge to the global optimum. The tradeoff in this approach is that, in the worst case, the oracle step requires solving an integer linear program. Despite this theoretical limitation, numerical experiments show that this algorithm can, on certain instances, scale up to 100 million entries while running on a personal computer. The goal of this paper is to further enhance this algorithm, with the intention to expand both the breadth and scale of instances that can be solved. We explore several variants that can maintain the same theoretical guarantees as the algorithm, but offer potentially faster computation. We consider different data structures, acceleration of gradient descent steps, and the use of the Blended Pairwise Conditional Gradients algorithm. We describe the original approach and these variants, and conduct numerical experiments in order to explore various tradeoffs in these algorithmic design choices.