 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bi-directional Feature Reconstruction Network for Fine-Grained Few-Shot Image Classification
Nov 30, 2022
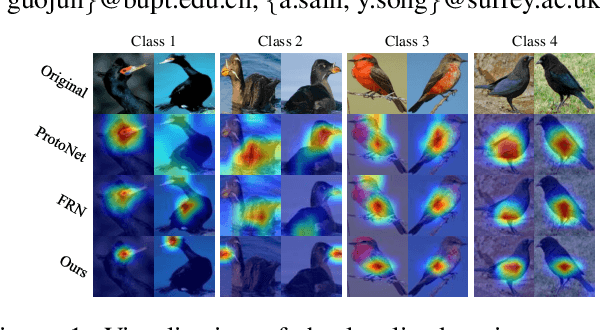
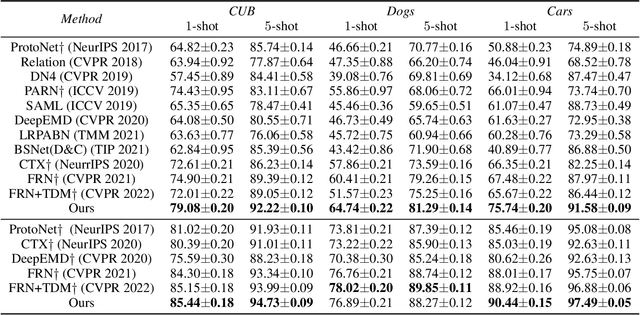
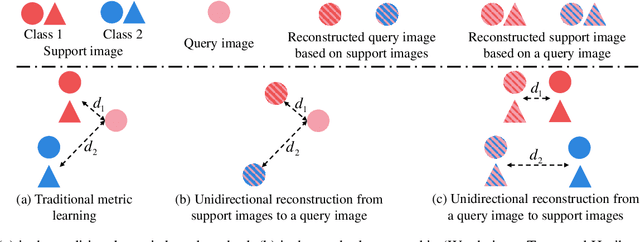
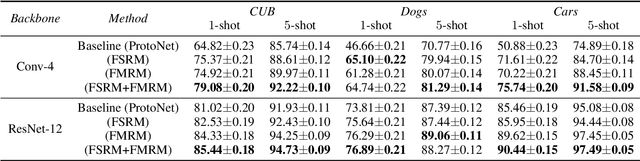
The main challenge for fine-grained few-shot image classification is to learn feature representations with higher inter-class and lower intra-class variations, with a mere few labelled samples. Conventional few-shot learning methods however cannot be naively adopted for this fine-grained setting -- a quick pilot study reveals that they in fact push for the opposite (i.e., lower inter-class variations and higher intra-class variations). To alleviate this problem, prior works predominately use a support set to reconstruct the query image and then utilize metric learning to determine its category. Upon careful inspection, we further reveal that such unidirectional reconstruction methods only help to increase inter-class variations and are not effective in tackling intra-class variations. In this paper, we for the first time introduce a bi-reconstruction mechanism that can simultaneously accommodate for inter-class and intra-class variations. In addition to using the support set to reconstruct the query set for increasing inter-class variations, we further use the query set to reconstruct the support set for reducing intra-class variations. This design effectively helps the model to explore more subtle and discriminative features which is key for the fine-grained problem in hand. Furthermore, we also construct a self-reconstruction module to work alongside the bi-directional module to make the features even more discriminative. Experimental results on three widely used fine-grained image classification datasets consistently show considerable improvements compared with other methods. Codes are available at: https://github.com/PRIS-CV/Bi-FRN.
Capturing long-range interaction with reciprocal space neural network
Nov 30, 2022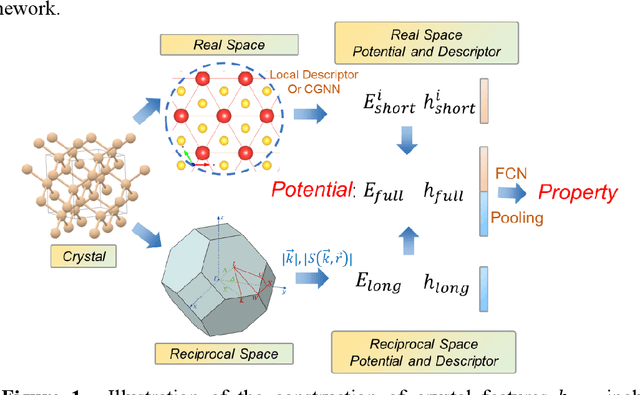
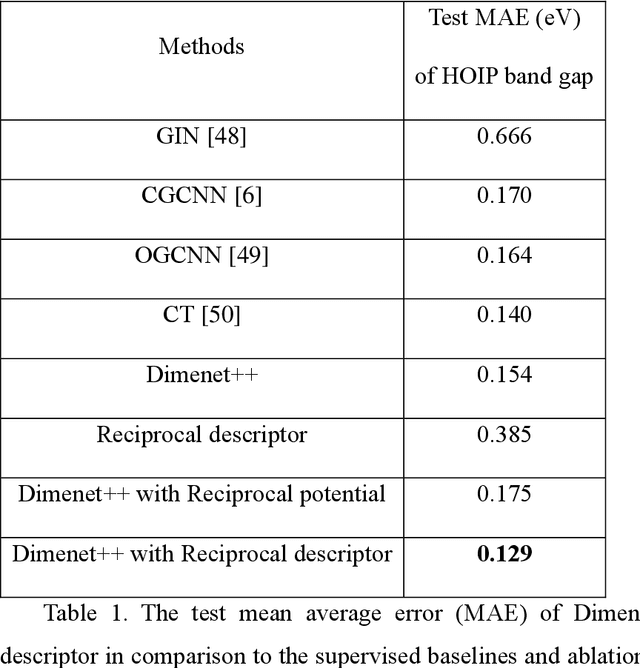
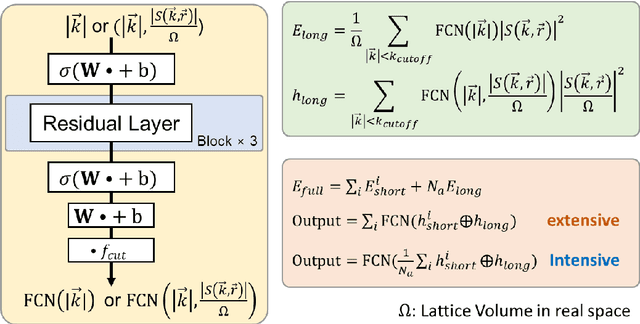
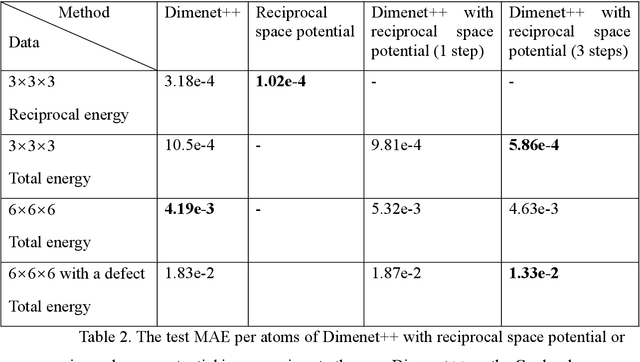
Machine Learning (ML) interatomic models and potentials have been widely employed in simulations of materials. Long-range interactions often dominate in some ionic systems whose dynamics behavior is significantly influenced. However, the long-range effect such as Coulomb and Van der Wales potential is not considered in most ML interatomic potentials. To address this issue, we put forward a method that can take long-range effects into account for most ML local interatomic models with the reciprocal space neural network. The structure information in real space is firstly transformed into reciprocal space and then encoded into a reciprocal space potential or a global descriptor with full atomic interactions. The reciprocal space potential and descriptor keep full invariance of Euclidean symmetry and choice of the cell. Benefiting from the reciprocal-space information, ML interatomic models can be extended to describe the long-range potential including not only Coulomb but any other long-range interaction. A model NaCl system considering Coulomb interaction and the GaxNy system with defects are applied to illustrate the advantage of our approach. At the same time, our approach helps to improve the prediction accuracy of some global properties such as the band gap where the full atomic interaction beyond local atomic environments plays a very important role. In summary, our work has expanded the ability of current ML interatomic models and potentials when dealing with the long-range effect, hence paving a new way for accurate prediction of global properties and large-scale dynamic simulations of systems with defects.
Real-time semantic segmentation on FPGAs for autonomous vehicles with hls4ml
May 16, 2022

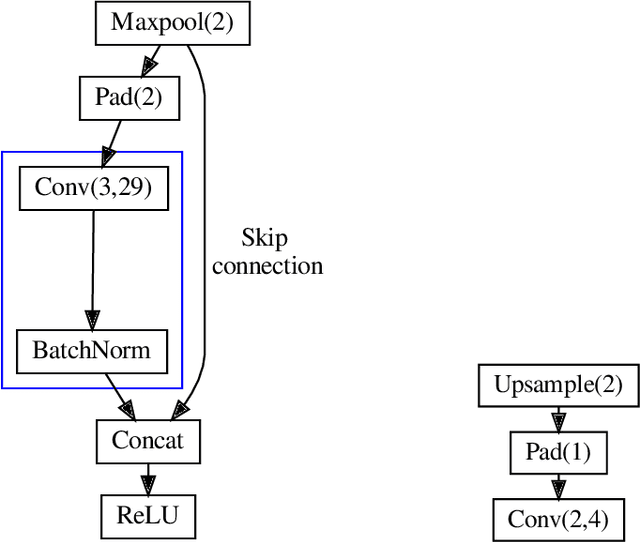
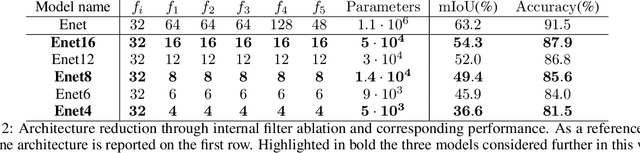
In this paper, we investigate how field programmable gate arrays can serve as hardware accelerators for real-time semantic segmentation tasks relevant for autonomous driving. Considering compressed versions of the ENet convolutional neural network architecture, we demonstrate a fully-on-chip deployment with a latency of 4.9 ms per image, using less than 30% of the available resources on a Xilinx ZCU102 evaluation board. The latency is reduced to 3 ms per image when increasing the batch size to ten, corresponding to the use case where the autonomous vehicle receives inputs from multiple cameras simultaneously. We show, through aggressive filter reduction and heterogeneous quantization-aware training, and an optimized implementation of convolutional layers, that the power consumption and resource utilization can be significantly reduced while maintaining accuracy on the Cityscapes dataset.
Spectral Propagation Graph Network for Few-shot Time Series Classification
Feb 08, 2022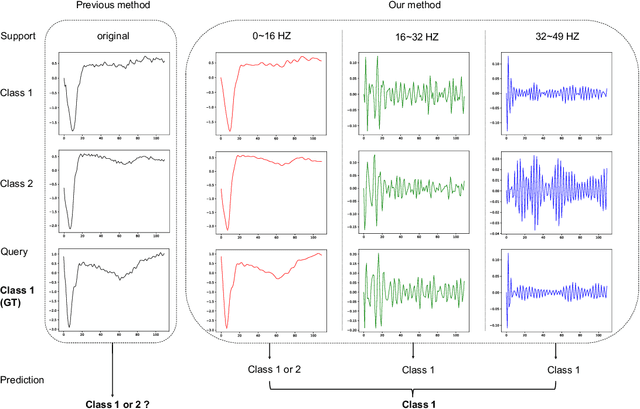
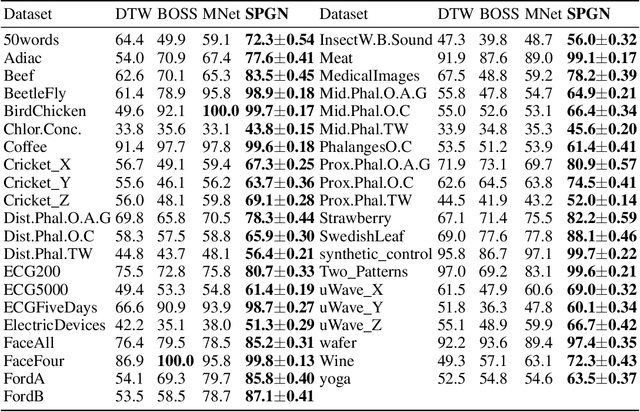
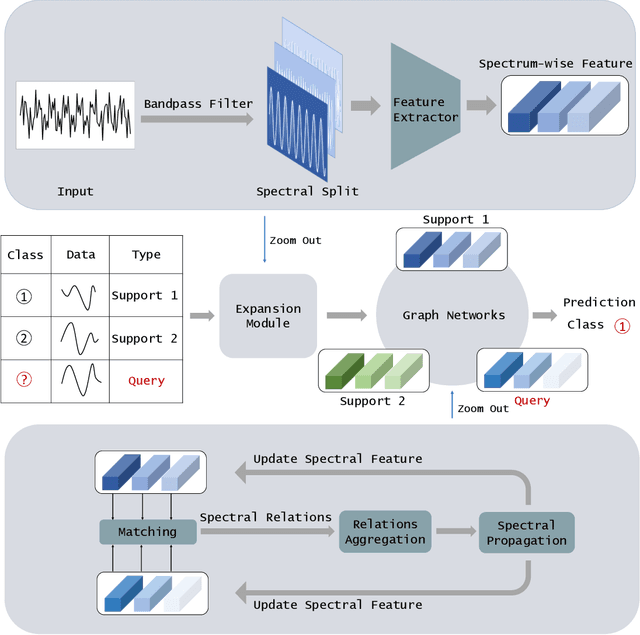
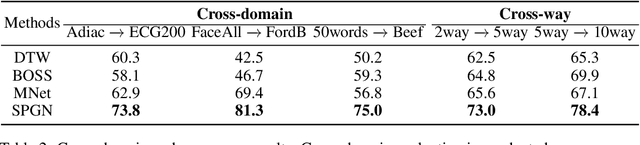
Few-shot Time Series Classification (few-shot TSC) is a challenging problem in time series analysis. It is more difficult to classify when time series of the same class are not completely consistent in spectral domain or time series of different classes are partly consistent in spectral domain. To address this problem, we propose a novel method named Spectral Propagation Graph Network (SPGN) to explicitly model and propagate the spectrum-wise relations between different time series with graph network. To the best of our knowledge, SPGN is the first to utilize spectral comparisons in different intervals and involve spectral propagation across all time series with graph networks for few-shot TSC. SPGN first uses bandpass filter to expand time series in spectral domain for calculating spectrum-wise relations between time series. Equipped with graph networks, SPGN then integrates spectral relations with label information to make spectral propagation. The further study conveys the bi-directional effect between spectral relations acquisition and spectral propagation. We conduct extensive experiments on few-shot TSC benchmarks. SPGN outperforms state-of-the-art results by a large margin in $4\% \sim 13\%$. Moreover, SPGN surpasses them by around $12\%$ and $9\%$ under cross-domain and cross-way settings respectively.
Branch-and-Bound with Barrier: Dominance and Suboptimality Detection for DD-Based Branch-and-Bound
Nov 22, 2022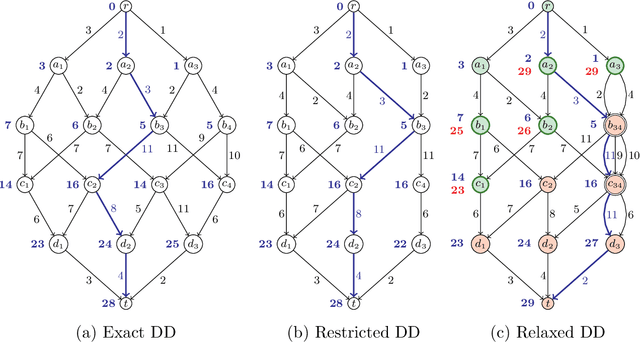
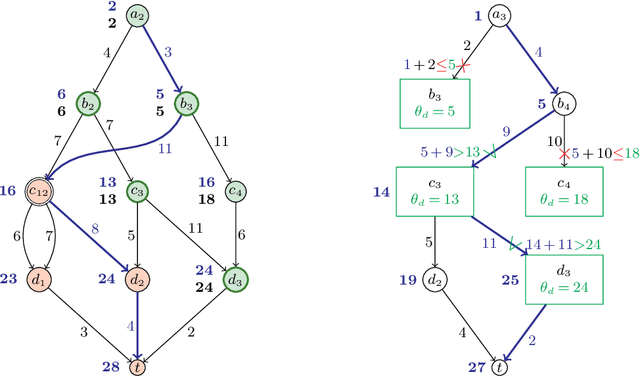
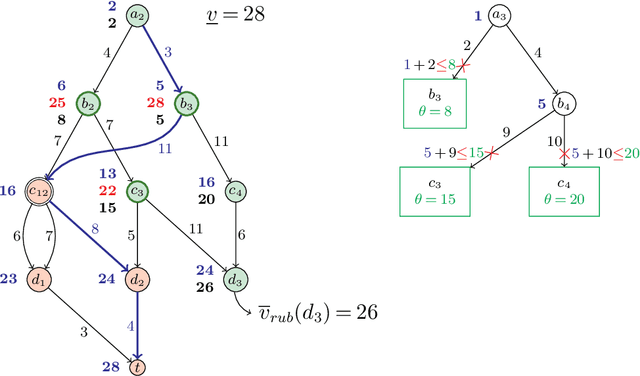
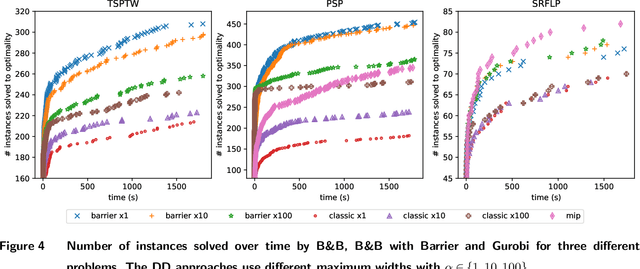
The branch-and-bound algorithm based on decision diagrams introduced by Bergman et al. in 2016 is a framework for solving discrete optimization problems with a dynamic programming formulation. It works by compiling a series of bounded-width decision diagrams that can provide lower and upper bounds for any given subproblem. Eventually, every part of the search space will be either explored or pruned by the algorithm, thus proving optimality. This paper presents new ingredients to speed up the search by exploiting the structure of dynamic programming models. The key idea is to prevent the repeated exploration of nodes corresponding to the same dynamic programming states by storing and querying thresholds in a data structure called the Barrier. These thresholds are based on dominance relations between partial solutions previously found. They can be further strengthened by integrating the filtering techniques introduced by Gillard et al. in 2021. Computational experiments show that the pruning brought by the Barrier allows to significantly reduce the number of nodes expanded by the algorithm. This results in more benchmark instances of difficult optimization problems being solved in less time while using narrower decision diagrams.
Leveraging Memory Effects and Gradient Information in Consensus-Based Optimization: On Global Convergence in Mean-Field Law
Nov 22, 2022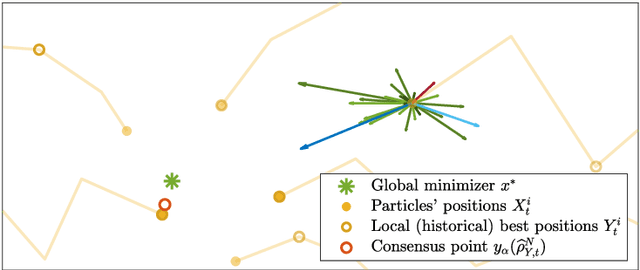
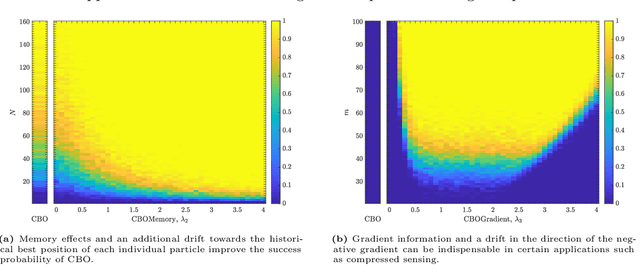
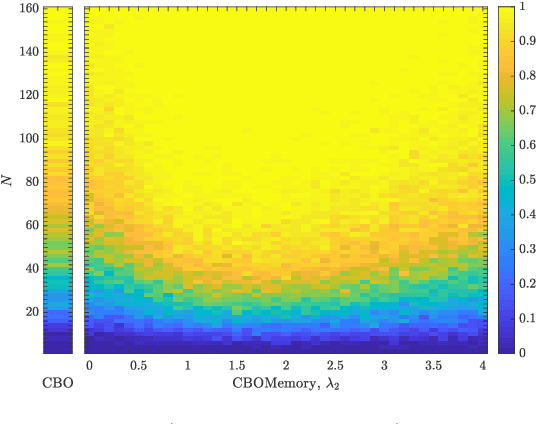

In this paper we study consensus-based optimization (CBO), a versatile, flexibel and customizable optimization method suitable for performing nonconvex and nonsmooth global optimizations in high dimensions. CBO is a multi-particle metaheuristic, which is effective in various applications and at the same time amenable to theoretical analysis thanks to its minimalistic design. The underlying dynamics, however, is flexible enough to incorporate different mechanisms widely used in evolutionary computation and machine learning, as we show by analyzing a variant of CBO which makes use of memory effects and gradient information. We rigorously prove that this dynamics converges to a global minimizer of the objective function in mean-field law for a vast class of functions under minimal assumptions on the initialization of the method. The proof in particular reveals how to leverage further, in some applications advantageous, forces in the dynamics without loosing provable global convergence. To demonstrate the benefit of the herein investigated memory effects and gradient information in certain applications, we present numerical evidence for the superiority of this CBO variant in applications such as machine learning and compressed sensing, which en passant widen the scope of applications of CBO.
Cosmology from Galaxy Redshift Surveys with PointNet
Nov 22, 2022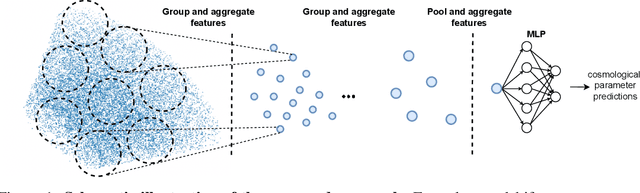
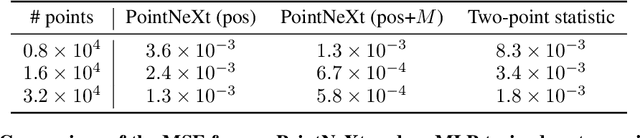
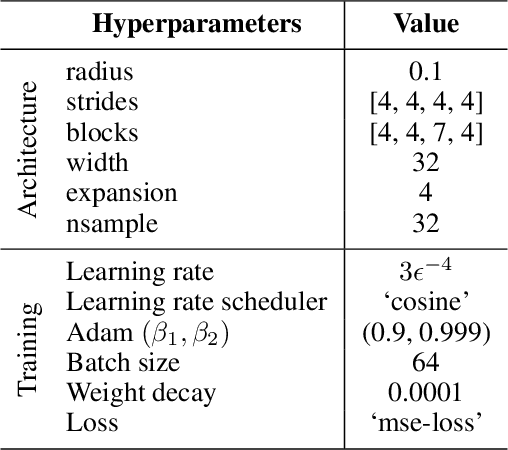
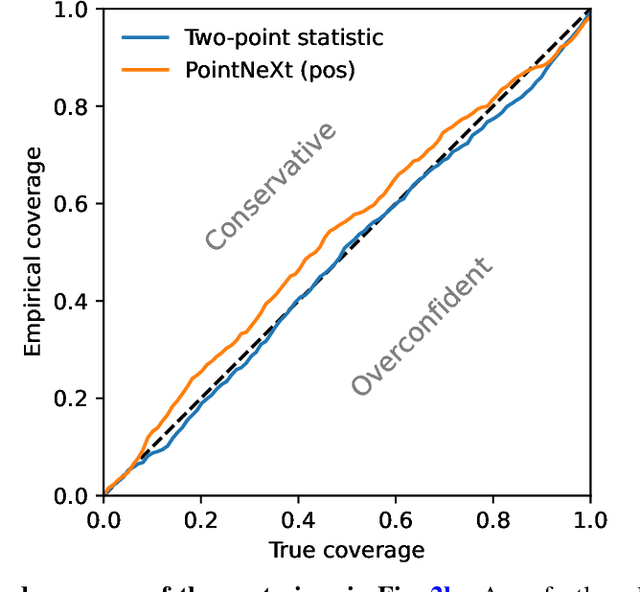
In recent years, deep learning approaches have achieved state-of-the-art results in the analysis of point cloud data. In cosmology, galaxy redshift surveys resemble such a permutation invariant collection of positions in space. These surveys have so far mostly been analysed with two-point statistics, such as power spectra and correlation functions. The usage of these summary statistics is best justified on large scales, where the density field is linear and Gaussian. However, in light of the increased precision expected from upcoming surveys, the analysis of -- intrinsically non-Gaussian -- small angular separations represents an appealing avenue to better constrain cosmological parameters. In this work, we aim to improve upon two-point statistics by employing a \textit{PointNet}-like neural network to regress the values of the cosmological parameters directly from point cloud data. Our implementation of PointNets can analyse inputs of $\mathcal{O}(10^4) - \mathcal{O}(10^5)$ galaxies at a time, which improves upon earlier work for this application by roughly two orders of magnitude. Additionally, we demonstrate the ability to analyse galaxy redshift survey data on the lightcone, as opposed to previously static simulation boxes at a given fixed redshift.
Design and Performance Analysis of Hardware Realization of 3GPP Physical Layer for 5G Cell Search
Nov 22, 2022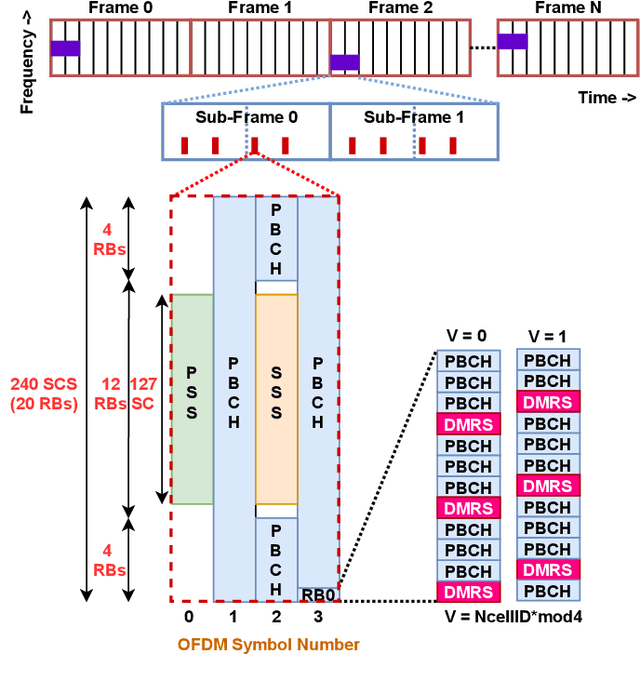
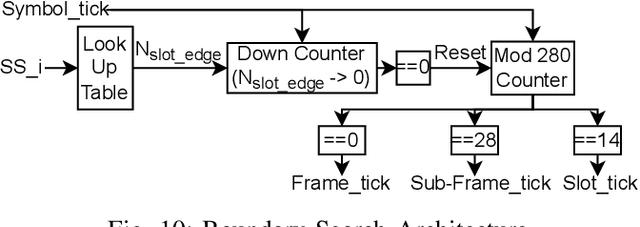
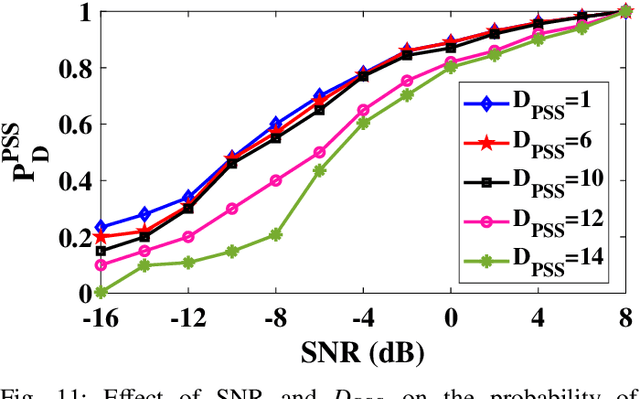
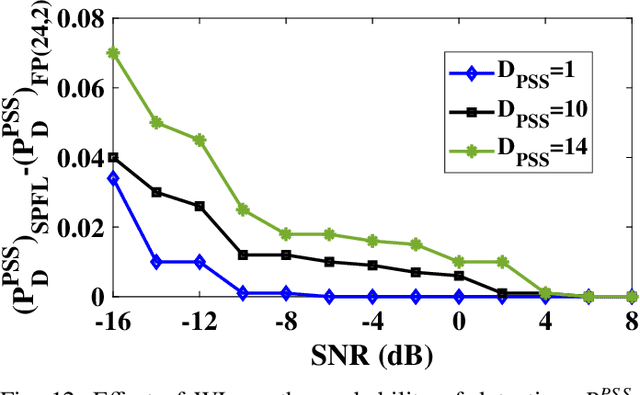
5G Cell Search (CS) is the first step for user equipment (UE) to initiate the communication with the 5G node B (gNB) every time it is powered ON. In cellular networks, CS is accomplished via synchronization signals (SS) broadcasted by gNB. 5G 3rd generation partnership project (3GPP) specifications offer a detailed discussion on the SS generation at gNB but a limited understanding of their blind search, and detection is available. Unlike 4G, 5G SS may not be transmitted at the center of carrier frequency and their frequency location is unknown to UE. In this work, we demonstrate the 5G CS by designing 3GPP compatible hardware realization of the physical layer (PHY) of the gNB transmitter and UE receiver. The proposed SS detection explores a novel down-sampling approach resulting in a significant reduction in complexity and latency. Via detailed performance analysis, we analyze the functional correctness, computational complexity, and latency of the proposed approach for different word lengths, signal-to-noise ratio (SNR), and down-sampling factors. We demonstrate the complete CS functionality on GNU Radio-based RFNoC framework and USRP-FPGA platform. The 3GPP compatibility and demonstration on hardware strengthen the commercial significance of the proposed work.
Dormant Neural Trojans
Nov 02, 2022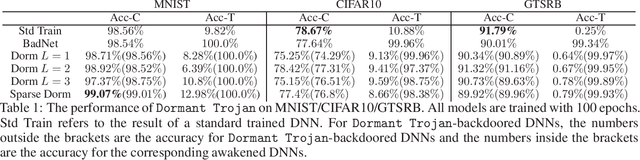
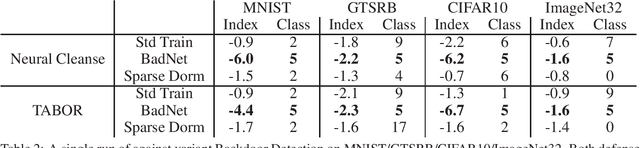

We present a novel methodology for neural network backdoor attacks. Unlike existing training-time attacks where the Trojaned network would respond to the Trojan trigger after training, our approach inserts a Trojan that will remain dormant until it is activated. The activation is realized through a specific perturbation to the network's weight parameters only known to the attacker. Our analysis and the experimental results demonstrate that dormant Trojaned networks can effectively evade detection by state-of-the-art backdoor detection methods.
Parameter-free Online Test-time Adaptation
Jan 15, 2022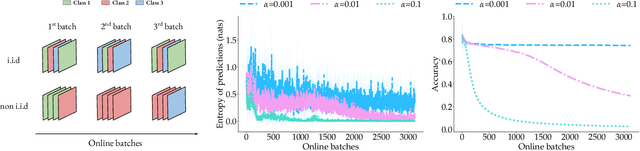
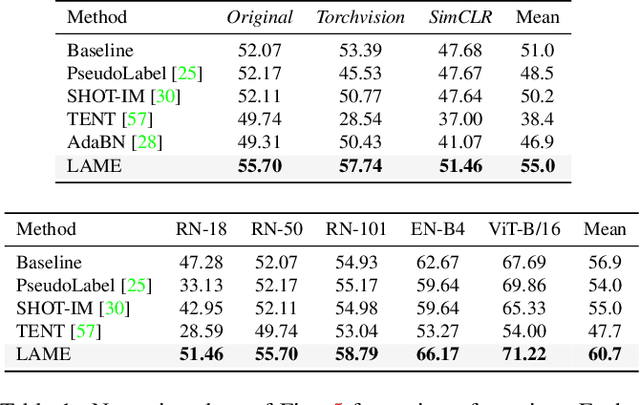

Training state-of-the-art vision models has become prohibitively expensive for researchers and practitioners. For the sake of accessibility and resource reuse, it is important to focus on adapting these models to a variety of downstream scenarios. An interesting and practical paradigm is online test-time adaptation, according to which training data is inaccessible, no labelled data from the test distribution is available, and adaptation can only happen at test time and on a handful of samples. In this paper, we investigate how test-time adaptation methods fare for a number of pre-trained models on a variety of real-world scenarios, significantly extending the way they have been originally evaluated. We show that they perform well only in narrowly-defined experimental setups and sometimes fail catastrophically when their hyperparameters are not selected for the same scenario in which they are being tested. Motivated by the inherent uncertainty around the conditions that will ultimately be encountered at test time, we propose a particularly "conservative" approach, which addresses the problem with a Laplacian Adjusted Maximum-likelihood Estimation (LAME) objective. By adapting the model's output (not its parameters), and solving our objective with an efficient concave-convex procedure, our approach exhibits a much higher average accuracy across scenarios than existing methods, while being notably faster and have a much lower memory footprint. Code available at https://github.com/fiveai/LAME.